智能体工厂:大小模型协作学习
智能体工厂:大小模型协作学习
注:本文为基于《计算》期刊2025年第5期 李书缘, 童咏昕, 杨强, 等. 智能体工厂:大小模型协作学习[J]. 计算, 2025, 1(5): 83−90. DOI: 10.11991/cccf.202509010论文并添加个人想法的阅读笔记。
- 摘要
当前,大模型与智能体的发展面临“模型孤岛”与“数据流通困境”两大核心挑战。商业竞争导致高价值模型闭源,形成模型能力壁垒;同时,公域数据濒临枯竭,而大量高价值的私域数据因隐私和安全顾虑未能有效利用。为此,本文探索了前沿的“智能体工厂”(FAgent)技术,其通过整合多个小模型的领域数据与算法资源,并将其汇总至指定大模型进行统一优化,实现对数据与计算资源的集中调度与高效运作。
“智能体工厂”(factory of Agent ,FAgent)的核心在于大小模型间的双向协作学习机制:“学模型”指大模型通过强大的泛化能力将知识提炼给小模型,以提升小模型的性能;“学数据”则是多个小模型将其宝贵的专业领域知识迁移给大模型,以弥补大模型在特定领域的数据短板。为实现这一协作范式,本文系统阐述了联邦学习、迁移学习、知识蒸馏与强化学习四大关键技术的支撑作用,确保在保护模型参数与数据隐私的前提下,完成知识的共享与融合。
研究表明,FAgent通过促进模型间的相互学习,能够有效突破现有发展瓶颈,为构建下一代高效、安全且可扩展的人工智能系统提供了可行的技术路径。
2 研究背景
大模型技术不断迭代更新,其展现出颠覆多个行业的巨大潜力。根据国务院2025年8月发布的《关于深入实施“人工智能+”行动的意见》,至2030年,我国人工智能全面赋能高质量发展,新一代智能终端、智能体等应用普及率超90%[1];OpenAI联合创始人兼首席执行官萨姆·奥尔特慢(Sam Altman)在2025年2月10日发表的观点中预测“智能体将成为与人类并肩工作的虚拟同事”。可见,大模型不仅是技术发展的热点,更是未来全球资源与战略布局的必争之地。然而随着政策与技术的变化,大模型与智能体在两大核心——模型与数据上都面临重重挑战[2]。
一方面是商业竞争行为形成的模型孤岛问题。根据斯坦福大学李飞飞教授团队发布的2024年度AI Index报告估算,OpenAI公司的GPT-4开发成本约为7800万美元,谷歌公司的Gemini Ultra开发成本约为1.91亿美元。面对如此高昂的开发成本,各大公司多选择将商业模型闭源。即各个模型间闭塞,拒绝进行数据交互和算法相互学习。因此,如何在保护高价值、高敏感模型参数前提下,共享模型能力成为进一步推广应用的关键问题。
另一方面是公域语料枯竭导致的数据缺口问题。大模型等新一代人工智能技术对数据的需求与日俱增,其对于数据资源的消耗正呈指数速度飞速增长,Pablo等人根据研究结果表明:预计到2028年,互联网公域数据资源存量即将消耗殆尽[3]。因此数据缺口已成为制约大模型发展的关键瓶颈。然而互联网中还存在大量私域数据尚为得到有效利用,96%的深域数据无法通过标准搜索引擎直接检索得到,此外金融、医疗与交通等行业产生的数据价值高、隐私强,多存储在企业内部,未参与数据交易与流通。缓解大模型数据缺口问题,已成为国际人工智能领域共识的前沿挑战。

图1 模型孤岛和数据壁垒示意图
综上所述,整体目前仍面临模型孤岛与数据流通困境两大挑战。针对此问题,前沿研究提出“智能体工厂”(factory of Agent ,FAgent)这一概念,通过整合多个小模型领域数据和算法资源,将其汇总至指定大模型进行统一优化,进而实现对数据与计算资源的集中调度与高效运作,其运作模式正如一个高度交互协同的工厂。形成FAgent的核心技术,需要借助联邦学习[4]、迁移学习[5]、知识蒸馏[6]与强化学习[7]等工具。接下来本文将从FAgent运作原理出发,介绍模型协作学习这一新范式。
3 FAgent运作原理概述
传统的机器学习多为输入的特征向标签学习、后反馈层向前反馈层学习、后时间步长向前步长学习,多为对模型自身特性进行学习;而FAgent核心突破在于实现模型和模型间相互学习(一个大模型向多个小模型学习、一个小模型向一个大模型学习、一个大模型向一个小模型等),旨在构建一种基于模型间知识协同的新一代生产范式[2]。
在理解FAgent的概述思路后,下文将从运作原理作为切入点,探究大小模型之间如何进行协作学习。
3.1 大模型教小模型——学模型
在FAgent中,大模型教小模型称为学模型,旨在通过将大模型的“经验”总结提炼给小模型,通过大规模数据分析和计算,提供最优参数给小模型,高效提高小模型性能。源智能体以大模型M1为核心,虽具有较强的数据学习能力与完备的算法权重抉择流程,但其训练数据集通用性较强且缺乏领域深度。目标智能体则基于模型M2构建,其数据处理能力较弱,但拥有大量的珍贵且优质的私域数据。
此时,可通过大模型教小模型的协作学习方式,使小模型学习大模型的基础能力,增强小模型智能体对数据的学习能力、语义理解能力与推理能力,从而充分发挥自身所持数据价值,优化在相关专业应用场景的表现。
值得注意的是,在该过程中推进FAgent的实现,大模型自身的模型参数与模型内涵的训练数据成为重点隐私保护目标,需实现在大模型向小模型迁移能力(权重、参数等)的同时,保护大模型的参数与训练数据。
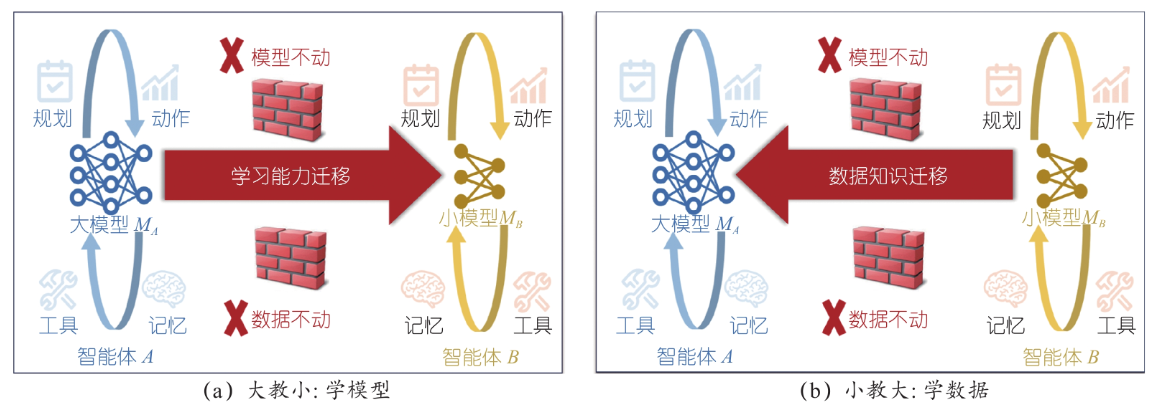
图2 大小模型协作学习原理示意图
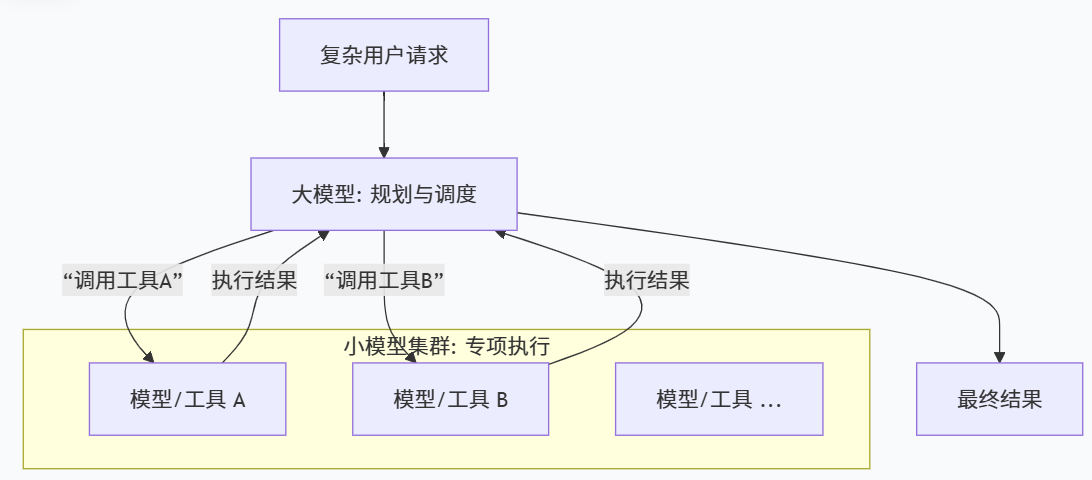
图3 大小模型协作学习流程图
3.2 小模型教大模型——学数据
在FAgent中,小模型教大模型这一过程称为学数据,旨在通过小模型的优质、专业领域数据完善大模型细节,使得大模型更加完善补充。源智能体以小模型M2为核心,拥有高价值私域数据;而目标智能体则以大模型M1为核心,虽然其具有较强的学习与泛化能力,但缺乏训练数据。
此时,可通过小模型教大模型,迁移相关领域知识与能力(对应标签、权重等),从而增强大模型在相关场景下的能力。例如:以金融公司的理财客服为小模型,其持有宝贵的客户征信、财务等私域金融数据信息;以某科技企业的通用问答智能体(如豆包、文心一言)为例,其虽具备较强的学习能力、良好的语义理解与推理能力,但由于其在金融领域的专业知识与数据积累不足,导致在回答涉及专业问题时,知识准确性与信息时效性均难以保证,制约了其在垂直领域的实际表现。因此,通过实现大小模型协作学习机制,能够有效实现知识的迁移与能力互补,进而显著增强问答大模型在专业领域输出的精准性。
不难看出,此场景下若想实现FAgent,小模型蕴含的宝贵领域数据成为重点隐私保护对象,尤其是可能存在多个小模型联合增强大模型的场景。为实现上述目标并确保参与方数据的隐私安全,需引入引入联邦学习等技术作为核心机制,共同增强中央大模型的性能。
4 技术工具
4.1 联邦学习
联邦学习提供相应的体系结构和应用程序,基于联盟机制的组织之间建立数据网络,在保护数据隐私的前提下,利用在分布在多个客户端的数据协同训练FAgent模型,使知识可以在不损害用户隐私的情况下进行共享[9]。
推动联邦学习的发展,意味着将AI开发的重点从改善模型性能(这是大多数AI领域目前正在做的事情)转移到研究符合数据隐私和更为安全的数据集成上,进一步使得在原始数据不出本地约束下,各方协同展开学习分析,促进模型间的交流、优势互补。
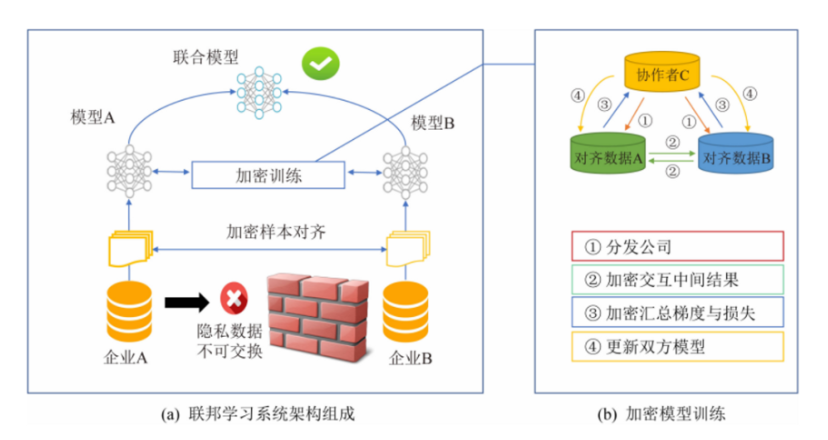
图4 联邦学习原理示意图
4.2 迁移学习
在机器学习的传统算法有一个根深蒂固的假设:训练数据和测试数据必须来自相同的特征空间,并且服从相同的分布。然而现实场景往往更加复杂,这些挑战催生了迁移学习(Transfer Learning)这一全新框架,其核心目标是利用源领域的知识提升目标领域的学习效果,打破“数据同分布”的枷锁[5]。
迁移学习的核心价值在于打破数据壁垒,让机器学习系统具备“举一反三”的能力。从实例层面的样本筛选,到特征层面的通用表示,再到模型层面的参数共享,迁移学习通过不同策略实现了跨域知识的有效复用。随着异构迁移、自动化策略等方向的突破,这一技术将在更多复杂场景中发挥关键作用,成为构建FAgent的重要基石。
迁移学习示意图如下所示:
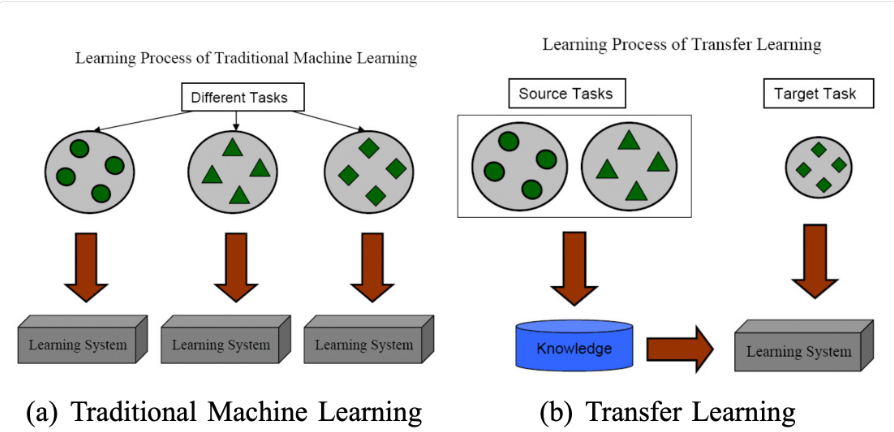
图5 迁移学习原理示意图
根据“迁移什么”,迁移学习可分为四大策略,下表总结了各自的核心思想与适用场景:
表1. 迁移学习四大策略
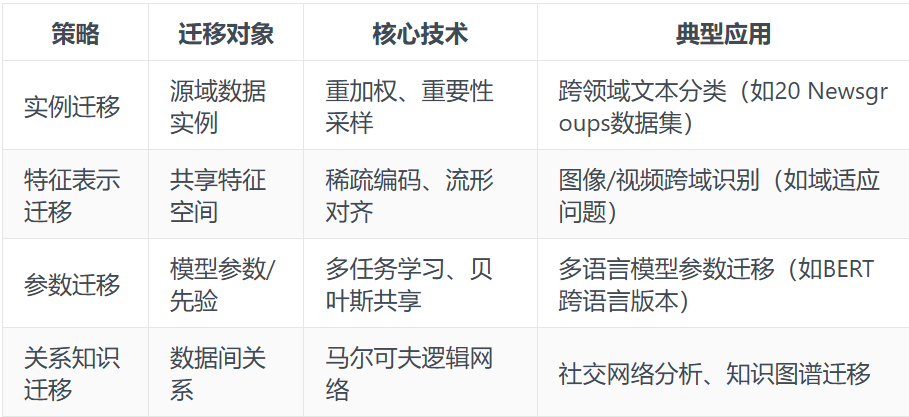
以社交软件小红书为例,采用参数迁移技术提取并迁移其他应用的加密参数,并结合多种神经网络算法推算出个性化的商品推荐结果;同时通过关系知识迁移开展社交网络分析,在基于兴趣相似度、共同关注、互动行为等多维度的基础上,实现对好友、关注对象、内容或话题的精准推荐。
下面以关系知识迁移为例:
建模关系:从用户-用户、用户-内容、用户-社群等多模态关系构建图结构。
关系对齐与转移:在源域(如社交网络中的好友关系)学到的关系特征,映射到目标域(如好友推荐、内容推荐)中。
核心算法:通常涉及监督学习、无监督学习、图神经网络、嵌入对齐、跨域表示学习等。
4.3 知识蒸馏
在传统的机器学习中,提升模型效果的一种常用方法是集成学习,即在相同的数据集训练多个不同的模型,最后对各组的预测结果取均值。然而,当单个网络结构规模较大时,集成模型的空间复杂度和时间复杂度较高,导致计算资源消耗过高。这一限制使得该模型难以部署至资源受限的用户端[6],从而降低其实际应用的便捷性和普及度。
相比之下,知识蒸馏提供了一种更高效的解决方法。在FAgent应用中,该技术通过把一个大的模型(定义为“教师模型”)中所蕴含的知识进行萃取和蒸馏,将其浓缩到一个轻量级的模型(定义为“学生模型”)。这一过程可理解为教师模型将知识的精华部分“传授”给了学生模型。基于此,极大程度上提升了FAgent模型的运算速度和资源利用率。
知识蒸馏概念图如下所示:
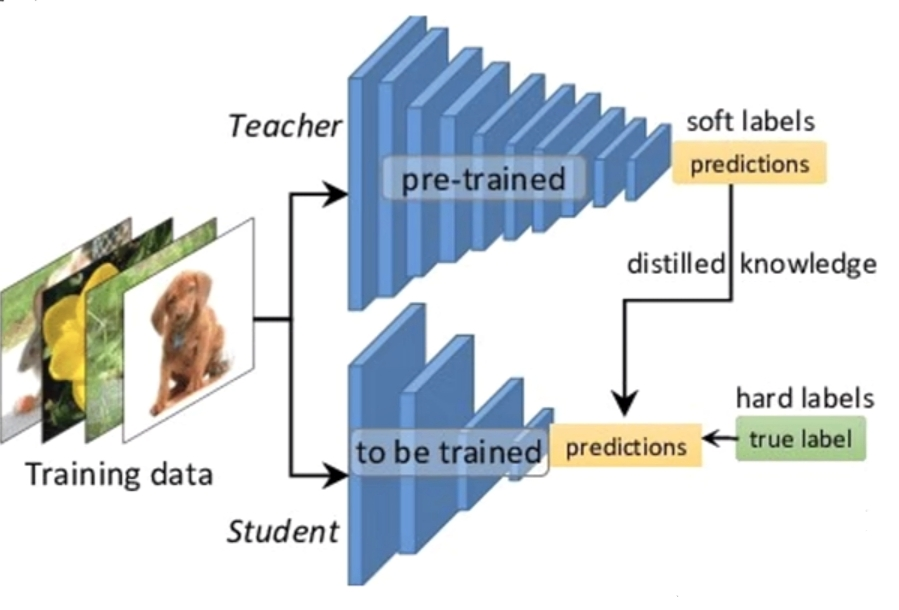
图6 知识蒸馏过程示意图
知识蒸馏的分类如下图所示:
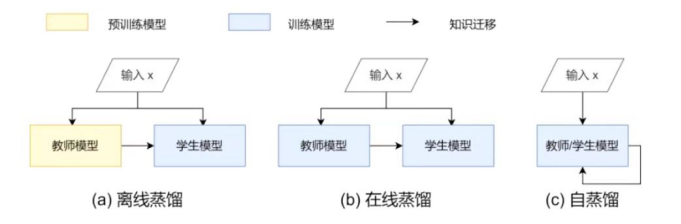
图7 知识蒸馏种类
4.4 强化学习
强化学习作为一种基于自主学习机制的机器学习方法,帮助FAgent在多个相关但独立的任务间进行知识学习与迁移[7][8]。
与传统的静态参数配置策略相比,强化学习允许智能体与环境进行动态交互。即系统通过状态空间与动作空间匹配搜寻,结合反馈机制调整策略网络参数,逐步逼近最佳行动方案,以追求长期效益最优解。该技术有效减少在搜索过程陷入局部开发的程度,进而避免全局探索陷入失衡状态[9],进一步实现FAgent模型在策略迭代过程中累计收益的最大化。
4.5 小结
值得注意的是,在FAgent系统实际应用中,上述技术并非孤立运行,而是构成了一个紧密协作的技术流程。例如,迁移学习通过强化学习选择最优参数并执行数据迁移;而知识蒸馏作为前置筛选步骤,确定迁移学习的知识范畴。这些核心技术运用于FAgent模型,共同赋能模型间的互监督学习与协同工作。
5 结论
综上所述,FAgent基于联邦学习、迁移学习、知识蒸馏、强化学习等技术,构建了一套高效协同的智能体生产新范式。该范式实现了大模型与多个小模型之间的安全交互和知识共享,有力应对模型孤岛与数据流通两大挑战。通过大小模型的协作学习,不仅显著提升了模型的全局优化能力与适应性,也为人工智能的未来研究提供了一种创新性强、可拓展的研究范式。
参考文献:
[1]《国务院关于深入实施“人工智能+”行动的意见》中国政府网 2025-08-27
[2]李书缘, 童咏昕, 杨强, 等. 智能体工厂:大小模型协作学习[J]. 计算, 2025, 1(5): 83−90. DOI: 10.11991/cccf.202509010
[3] Pablo Villalobos, Anson Ho, Jaime Sevilla, et al. Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data[C]//Forty-first International Conference on Machine Learning. Vienna: ICML, 2024: 1−22.
[4] Qiang Yang, Yang Liu, Tianjian Chen, et al. Federated Machine Learning: Concept and Applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019, 10(2): 1−19.
[5] Sinno Jialin Pan, Qiang Yang. A Survey on Transfer Learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345−1359. DOI: 10.1109/TKDE.2009.191
[6] Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. Distilling the Knowledge in a Neural Network[EB/OL]. (2015−03−09)[2025−05−01]. https://arxiv.org/abs/1503.02531v1.
[7] Leslie Pack Kaelbling, Michael L. Littman, Andrew W. Moore. Reinforcement Learning: A Survey[J]. Journal of Artificial Intelligence Research, 1996, 4: 237−285. DOI: 10.1613/jair.301
[8]潘嘉豪,冯翔,虞慧群. 基于多任务强化学习的优先级加权软模块化方法 [J/OL]. 计算机科学, 1-10[2025-11-08]. https://link.cnki.net/urlid/50.1075.TP.20251107.1347.008.
[9]韩煜熊,宋尚校,许攀,等.基于强化学习的自适应动态策略粒子群优化算法[J/OL].计算机应用,1-14[2025-11-08].https://link.cnki.net/urlid/51.1307.TP.20251106.1934.009.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)