机器学习笔记
使用网格搜索 (GridSearchCV) 和交叉验证 (CV) 找最好的 K 值。回归: MSE (均方误差), MAE (平均绝对误差)。智能体 (Agent) 通过与环境交互,赚取奖励 (Reward)。欧氏距离 (平方开根号)、曼哈顿距离 (绝对值)、切比雪夫距离。看最近的 K 个样本是什么类别,我就选什么类别。K 值的选择是 KNN 中最重要的超参数,它直接决定了模型的表现。,将输出映射
🌟 第一部分:宏观视角——机器学习是什么?
核心逻辑: 先搞懂定位,再看三要素。
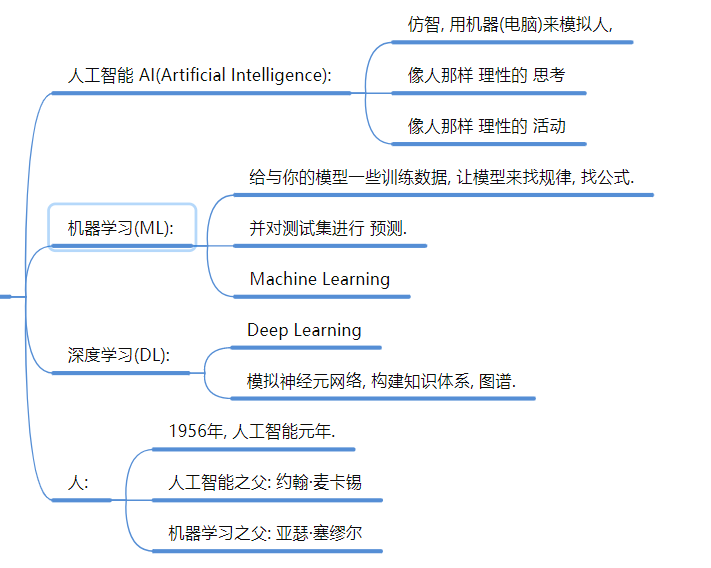
1. AI、ML、DL 的关系
- 人工智能 (AI): 大概念,模拟人的思考和行动(1956年提出,AI元年) 。
-
机器学习 (ML): AI的子集。核心思想是给数据,让机器找规律(公式),对未知数据进行预测
-
深度学习 (DL): ML的子集。模拟神经元网络,构建知识图谱
| 概念 | 通俗解释 | 场景 |
| 人工智能 (AI) | 目标:让机器做所有“聪明”的事情。 | 科幻电影中会思考的机器人。 |
| 机器学习 (ML) | 方法:让机器从数据中“学习”规律,而不是被硬性编程。 | 机器看了 1 万张猫狗照片,自己学会了分清猫和狗。 |
| 深度学习 (DL) | 工具:使用复杂的“神经网络”进行学习。 | 谷歌的 AlphaGo 下围棋,就是通过深度学习实现的。 |
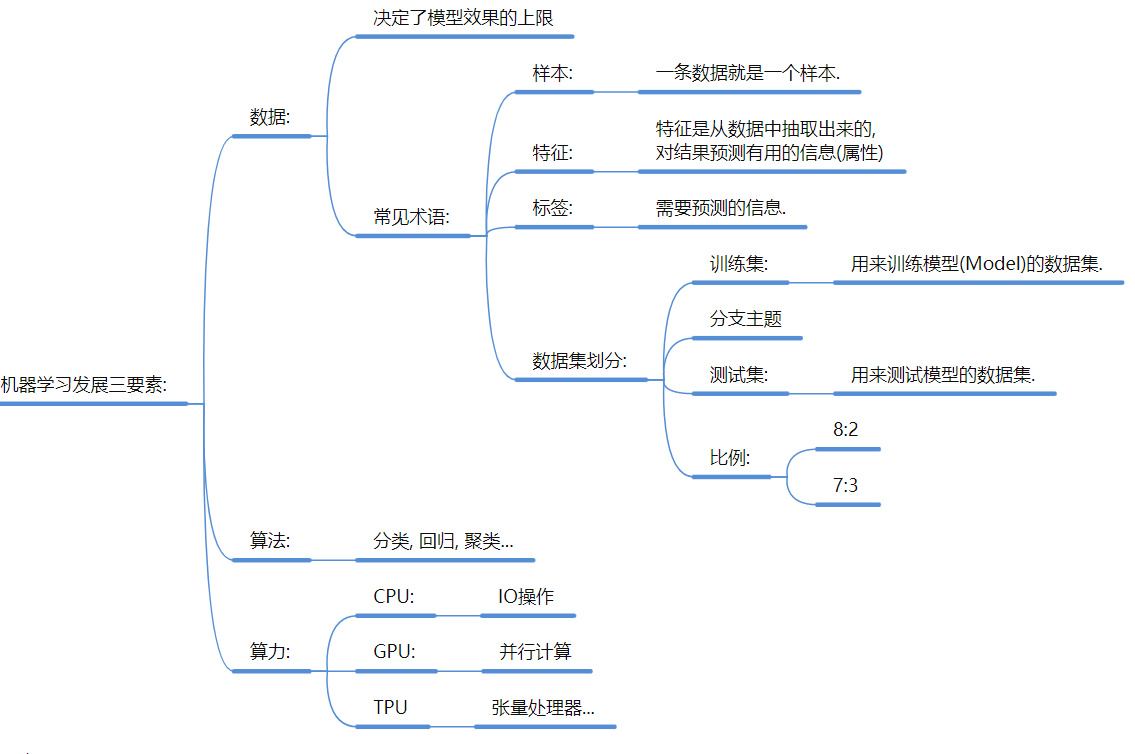
2. 机器学习的三大基石
这决定了你模型能不能跑,跑得好不好。
-
数据 (Data): 决定了模型效果的上限 。
术语: 样本 (一条数据)、特征 (属性)、标签 (答案)。
划分: 训练集 (学习用) vs 测试集 (考试用),常用比例 8:2 或 7:3 。 -
算法 (Algorithm): 也就是方法,如分类、回归、聚类 。
-
算力 (Computing Power): CPU (IO操作) vs GPU (并行计算,深度学习必备)
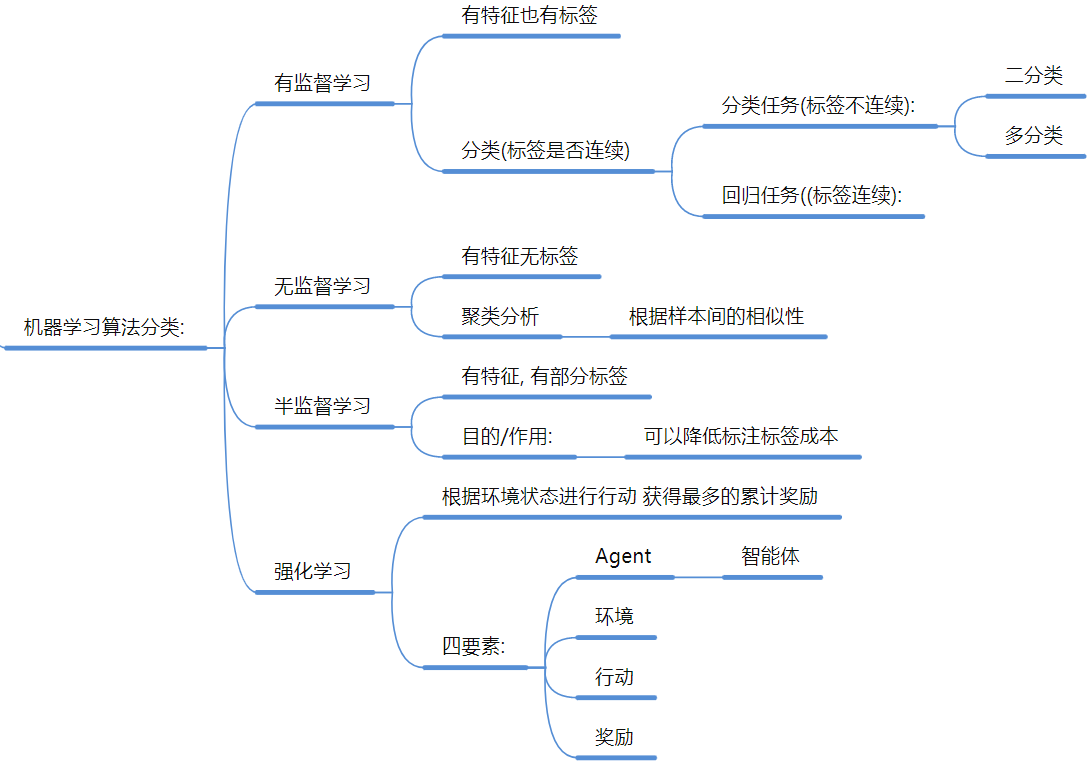
3. 任务分类 (四大门派)
-
有监督学习: 有特征、有标签。
-
分类: 预测离散值(如:猫/狗,二分类/多分类)。
-
回归: 预测连续值(如:房价、气温)。
-
-
无监督学习: 有特征、无标签。核心是聚类(找相似性) 。
-
半监督学习: 降低标注成本,利用少量标签数据和大量无标签数据 。
-
强化学习: 智能体 (Agent) 通过与环境交互,赚取奖励 (Reward) 。
| 门派 | 学习特点 | 生活例子 |
| 有监督学习 | 有“老师”指导。数据带有明确的标签(答案)。 | 预测房价(这是回归,连续值)或判断邮件是否为垃圾邮件(这是分类,离散值)。 |
| 无监督学习 | 没有“老师”指导。机器自己从数据中找结构。 | 客户细分:把所有用户分成“高消费人群”、“只看不买人群”等几类。 |
| 半监督学习 | 少量标签 + 大量无标签。 | 你只给 100 张图片标注了“猫/狗”,让机器用这 100 张学会后再去分析剩下的 10000 张未标注图片。 |
| 强化学习 | 边试错边学习。通过“奖励”和“惩罚”来学习最优策略。 | 机器玩超级马里奥,吃到金币给奖励,掉到坑里给惩罚。 |
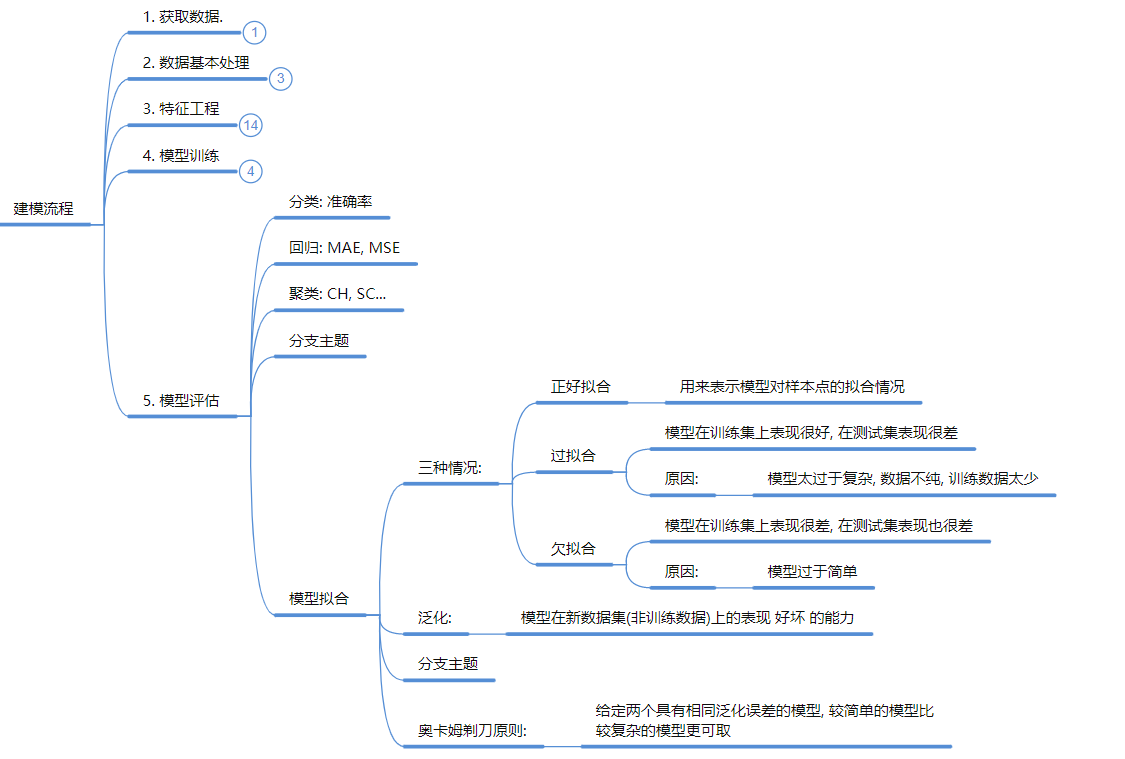
🛠️ 第二部分:工业级建模流程 (Standard Workflow)
核心逻辑: 做项目的标准步骤,缺一不可。
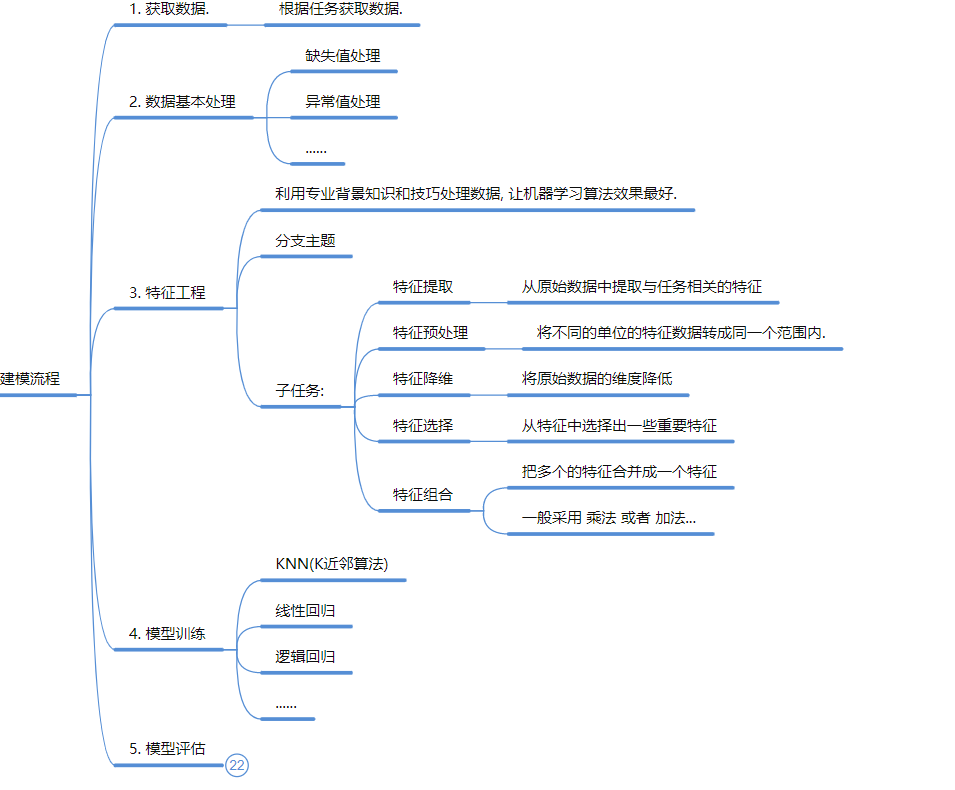
1、获取数据: 根据任务目标找数据 。
2、数据基本处理: 必须处理缺失值和异常值 。
3、特征工程 (核心):
特征提取: 从原始数据拿信息。
特征预处理: 归一化/标准化 (让不同单位的数据在同一范围内) 。
特征降维: 减少维度。
特征选择/组合: 挑重要的,或者把几个特征加减乘除组合成新的 。
4、模型训练: 也就是“喂数据” 。
5、模型评估:
分类: 准确率 (Accuracy)。
回归: MSE (均方误差), MAE (平均绝对误差)。
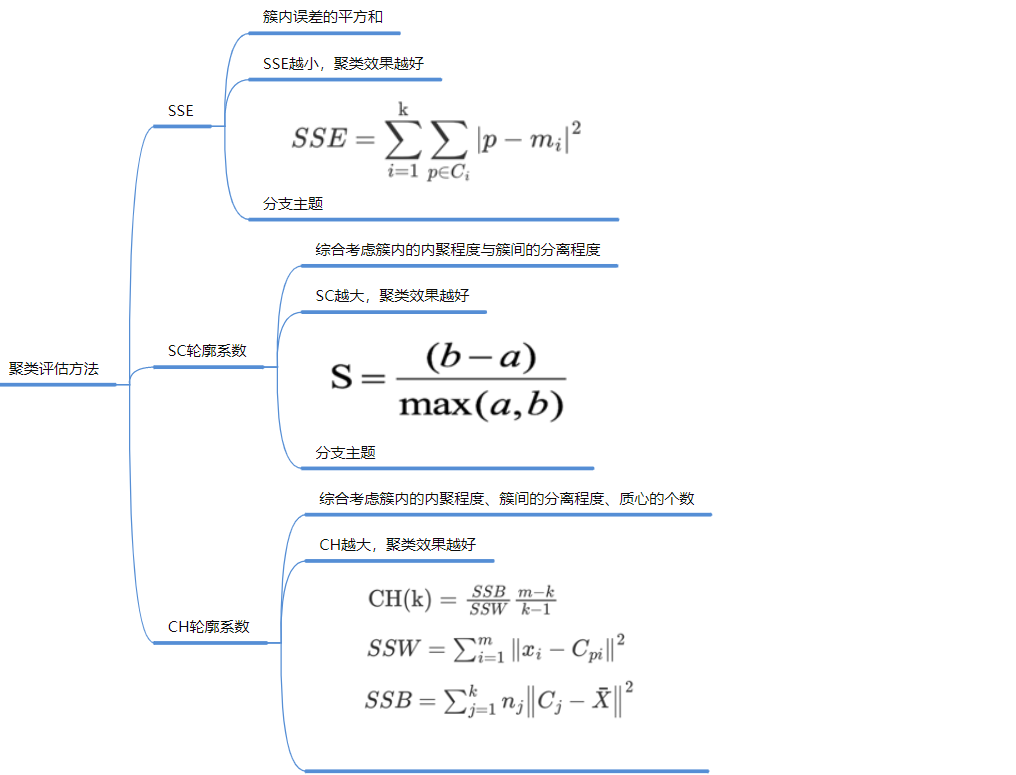
聚类: 轮廓系数 (SC), CH分数 。
🧠 第三部分:经典算法详解 (Core Algorithms)
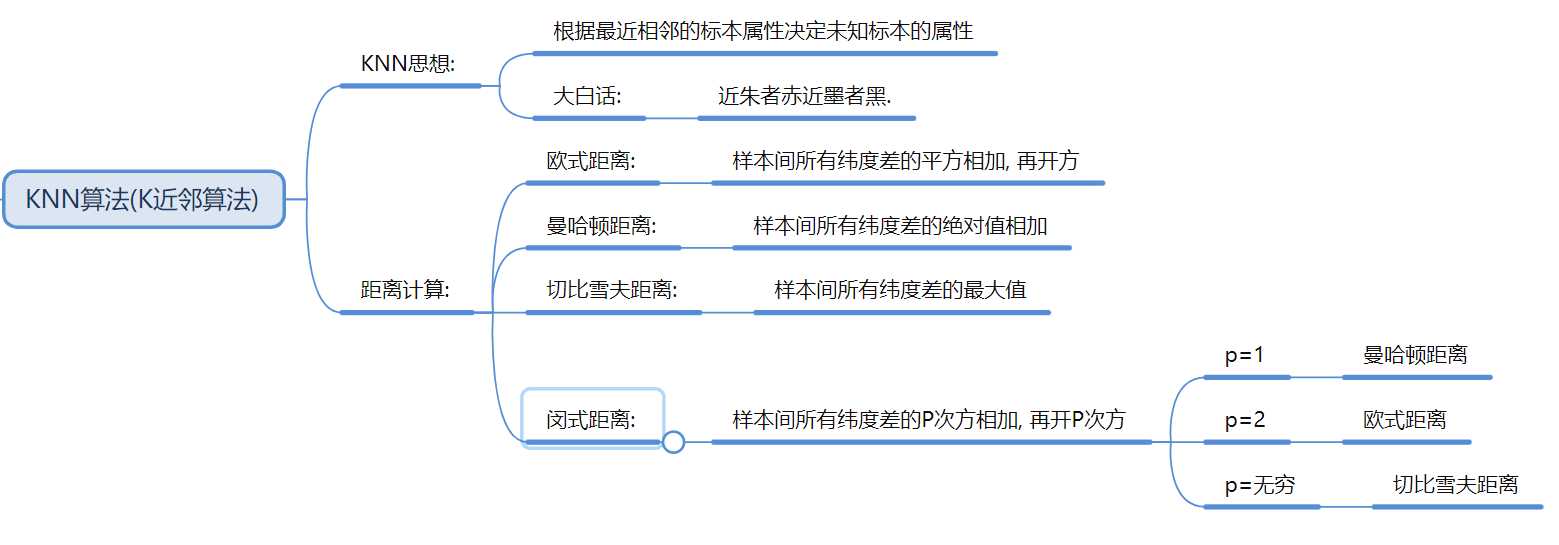
1. KNN (K-近邻算法) —— 懒人算法
-
核心思想: “近朱者赤”。看最近的 K 个样本是什么类别,我就选什么类别 。
-
关键点:
-
距离计算: 欧氏距离 (平方开根号)、曼哈顿距离 (绝对值)、切比雪夫距离 。
-
预处理: 必须做标准化,否则数值大的特征会主导距离计算 20。
-
调优: 使用网格搜索 (GridSearchCV) 和交叉验证 (CV) 找最好的 K 值 。
-
K 值的选择与影响(核心调优点)
K 值的选择是 KNN 中最重要的超参数,它直接决定了模型的表现。
| K 值大小 | 模型特性 | 偏差-方差 权衡 |
| K 值很小 (如 K=1) | 模型复杂度高,只关注最近邻居。 | 低偏差 (Low Bias),高方差 (High Variance)。 容易过拟合。 |
| K 值很大 (如 K=N) | 模型复杂度低,相当于取全局平均,决策边界平滑。 | 高偏差 (High Bias),低方差 (Low Variance)。 容易欠拟合。 |
| K 值适中 | 模型的性能通常达到最佳平衡点。 | 偏差和方差达到平衡。 |
✅ 如何选择 K 值?
-
交叉验证 (Cross-Validation): 最可靠的方法。在不同的 K 值下进行交叉验证,选择验证集上性能最好的 $K$ 值。
-
奇数 K: 在二分类问题中,通常选择奇数 K,以避免平票(Tie)问题。
-
网格搜索
总结回顾:KNN 的优缺点
| 优点 (Pros) | 缺点 (Cons) |
| 原理简单,易于实现和理解。 | 预测速度慢,计算量大(懒惰学习特性)。 |
| 不需要训练过程,对数据没有假设。 | 对内存开销大(需存储整个数据集)。 |
| 可以处理多分类问题。 |
对异常值和噪声敏感(因为只看局部邻居)。 对特征的量纲敏感(必须进行特征缩放)。 |
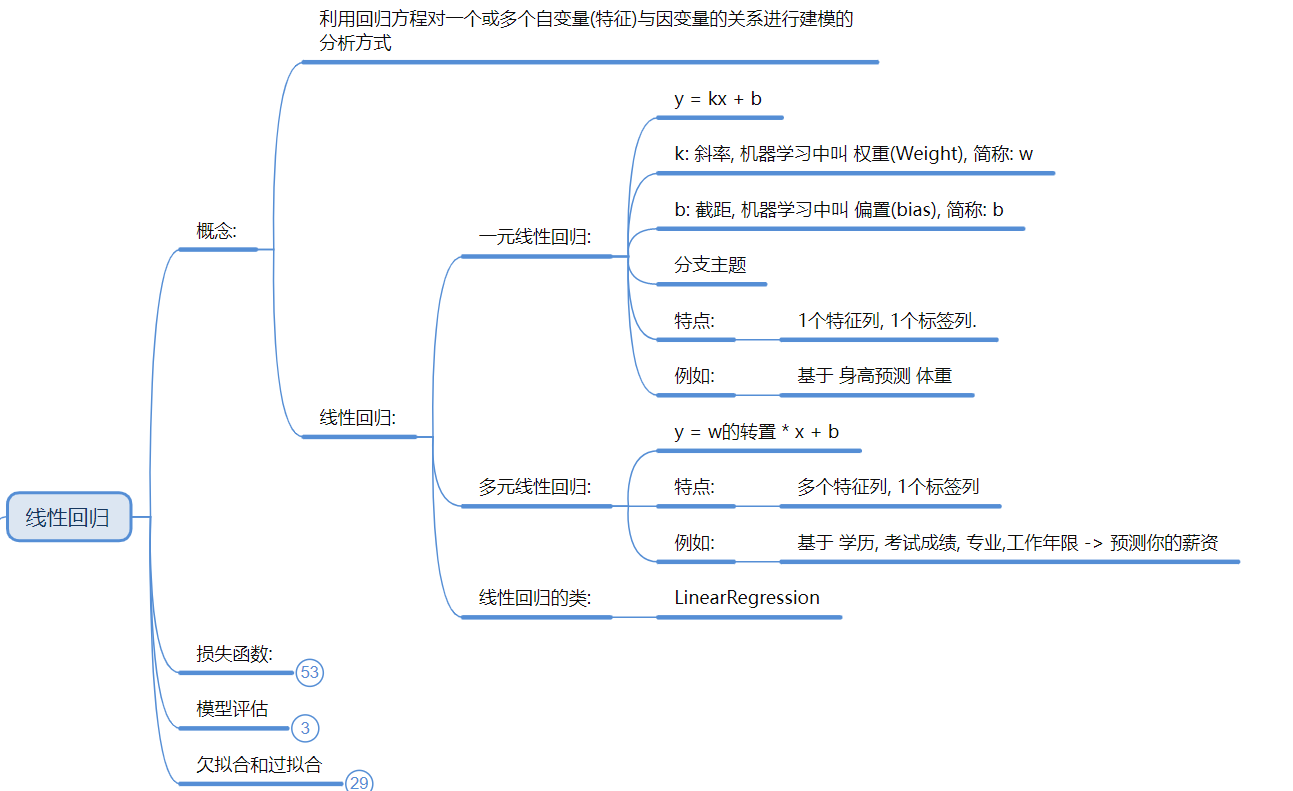
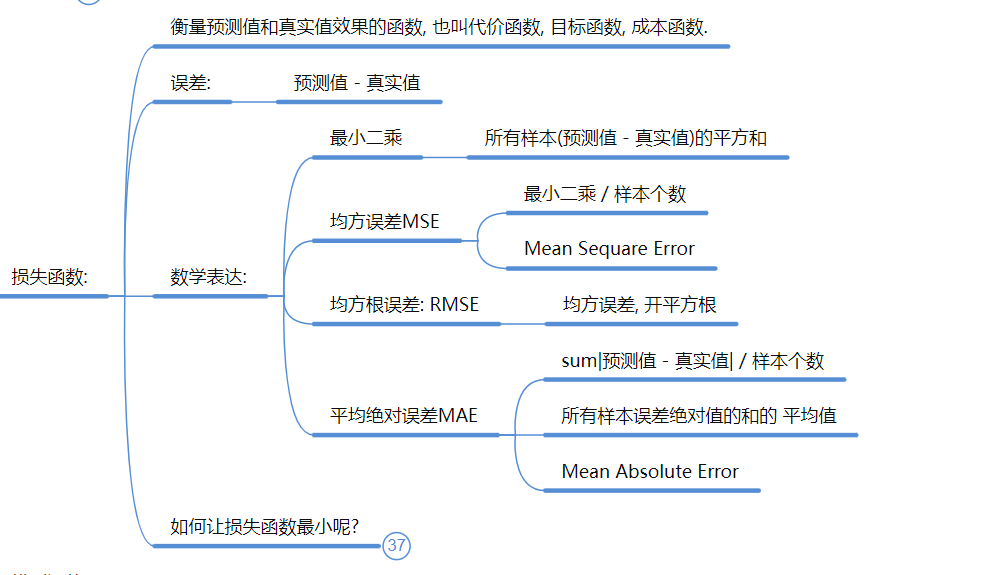
2. 线性回归 (Linear Regression) —— 预测数值


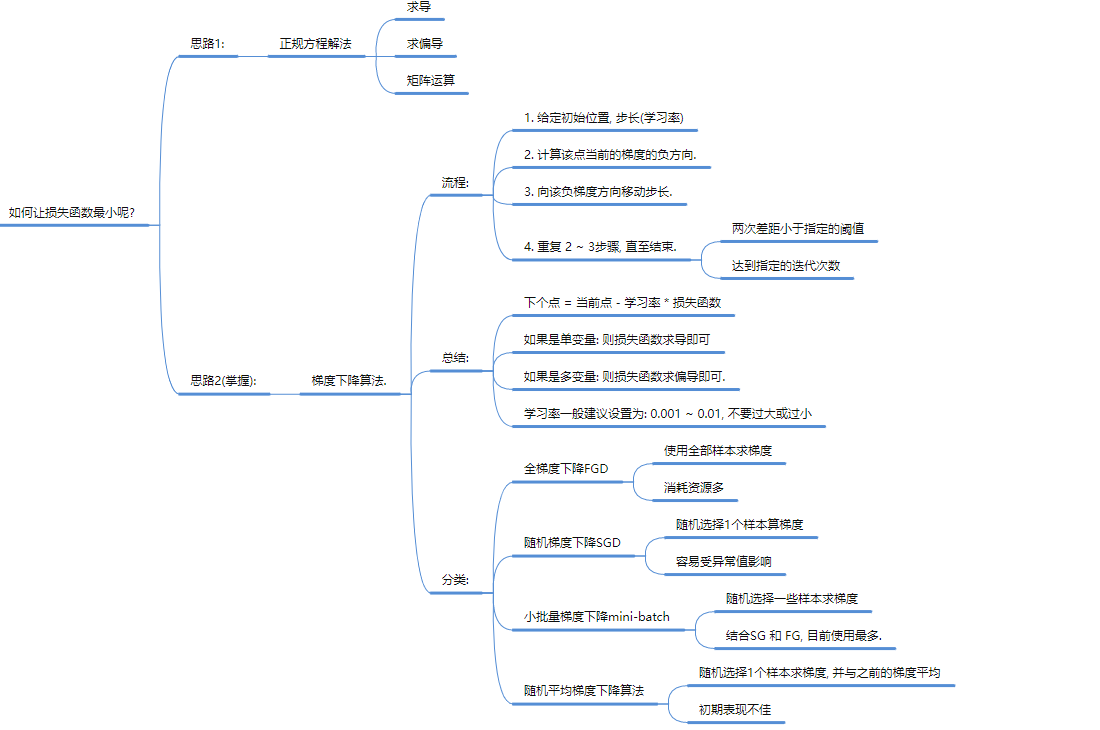
3. 逻辑回归 (Logistic Regression) —— 其实是分类
-
原理: 在线性回归外套一个 Sigmoid 函数,将输出映射到 $(0, 1)$ 区间,表示概率 26。
-
应用: 二分类(如垃圾邮件、癌症预测)。
-
评估指标:
-
准确率 (Accuracy): 猜对的比例。
-
精确率 (Precision): 查准率。
-
召回率 (Recall): 查全率。
-
AUC/ROC: AUC=0.5 是瞎猜,AUC=1 是完美 。
-

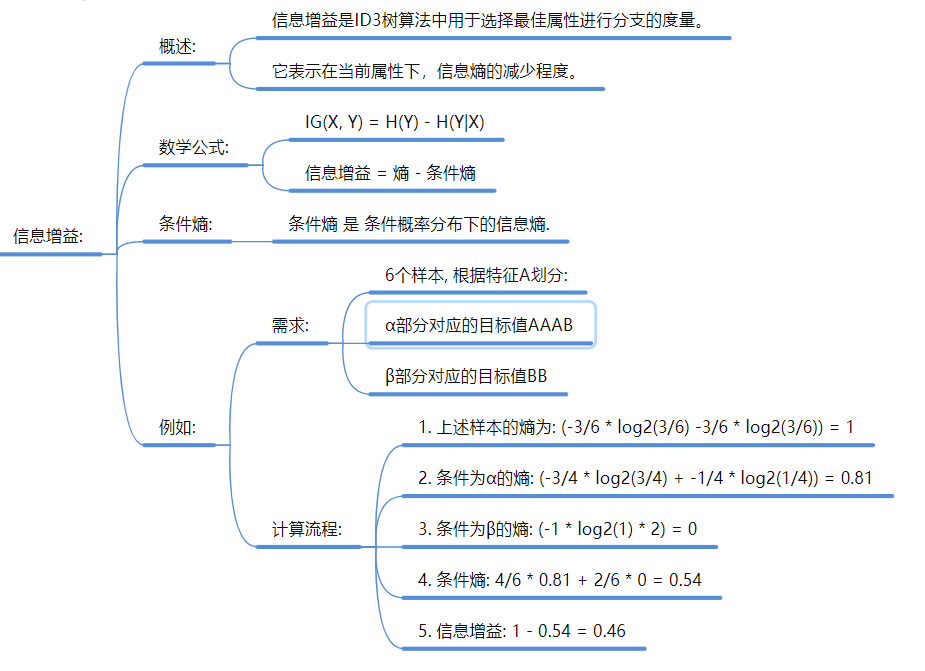
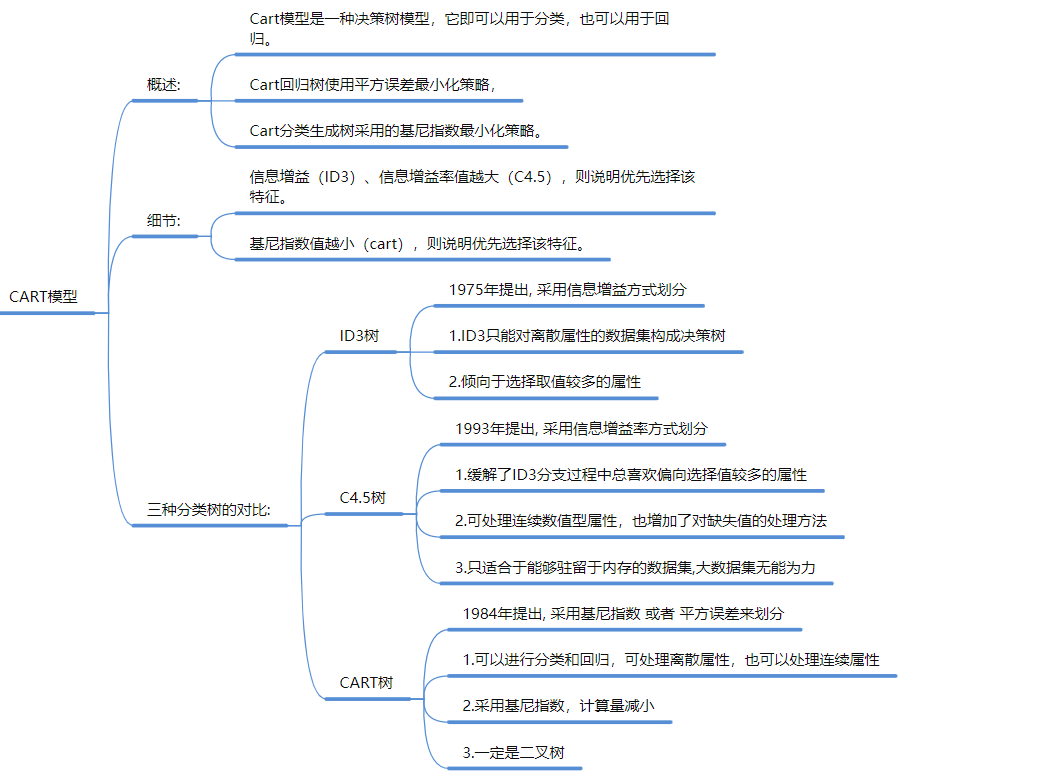
4. 决策树 (Decision Tree) —— 规则系统
-
核心: 像“相亲”一样,通过一系列 if/else 问题把数据切分 28。
-
切分标准 (怎么选问题?):
-
ID3: 信息增益 (基于信息熵,熵越大越混乱)。
-
C4.5: 信息增益率 (解决了ID3偏向多值特征的问题)。
-
CART: 基尼指数 (Gini) 或 平方误差 。
-
-
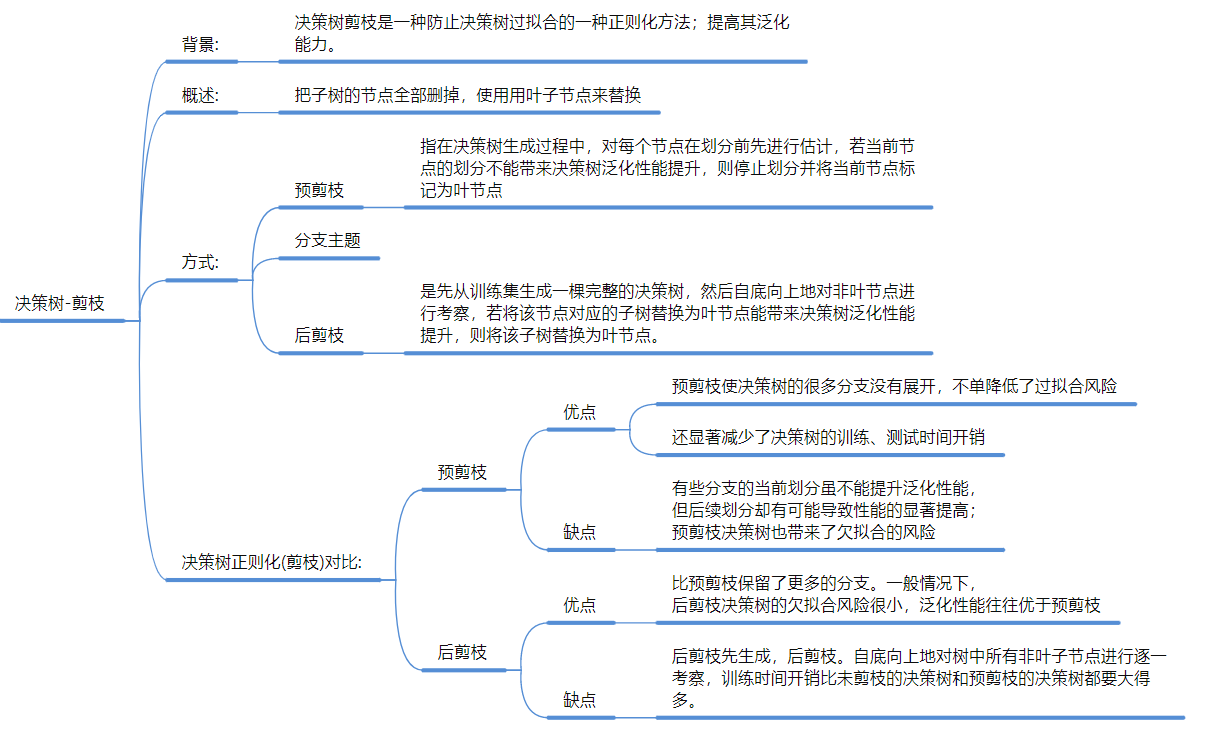
关键操作: 剪枝 (Pruning)。
-
预剪枝: 边建树边剪(防过拟合,快,但容易欠拟合)。
-
后剪枝: 建完再剪(保留更多信息,慢) 。
-



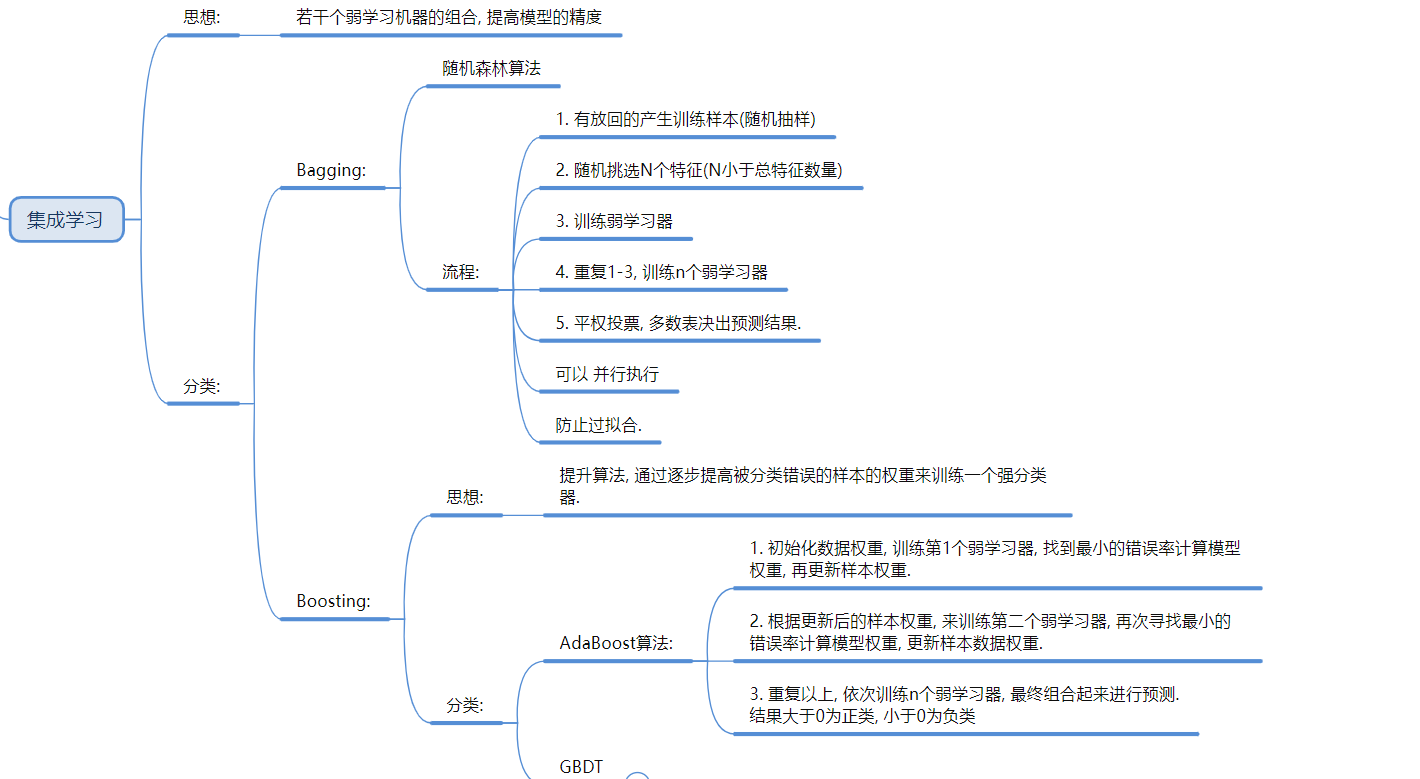
5. 集成学习 (Ensemble Learning) —— 团结就是力量
-
Bagging (并行): 随机森林。
-
原理: 有放回采样 (Bootstrap),训练多棵树,少数服从多数。防止过拟合 。
-
-
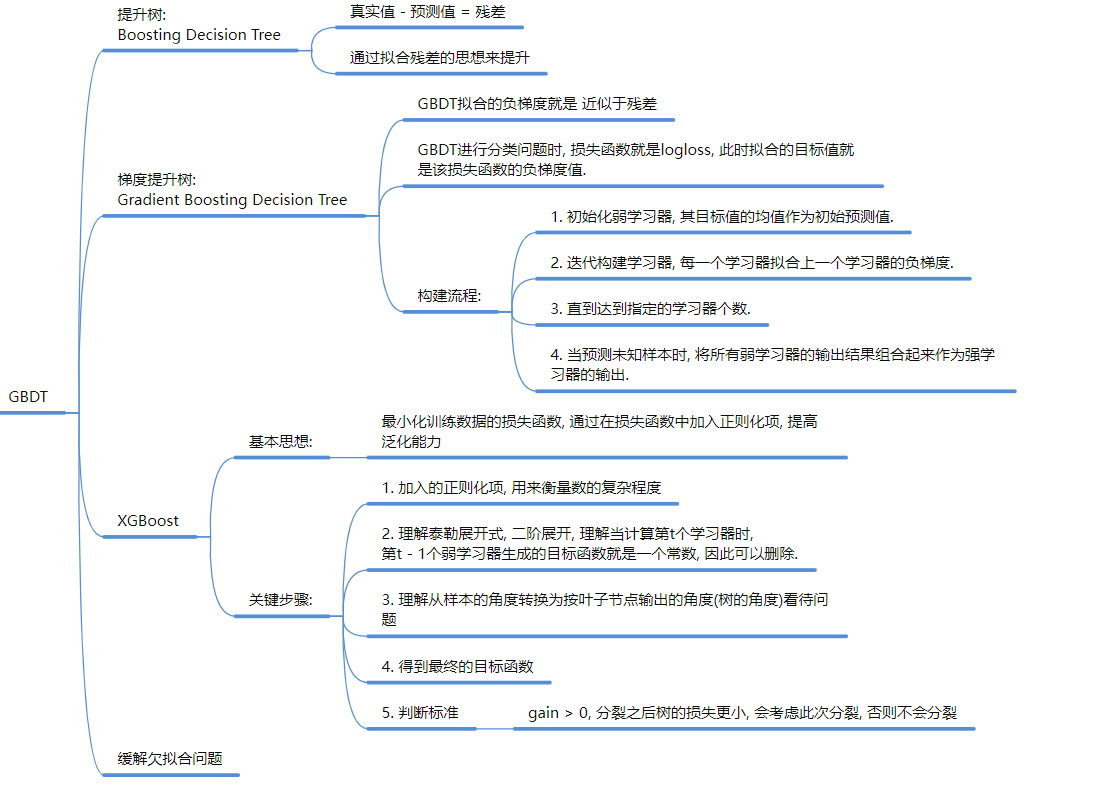
Boosting (串行): XGBoost, GBDT, AdaBoost。
-
原理: 接力赛。后一个模型专门修正前一个模型的错误(拟合残差)。追求高准确率,但容易过拟合 。
-
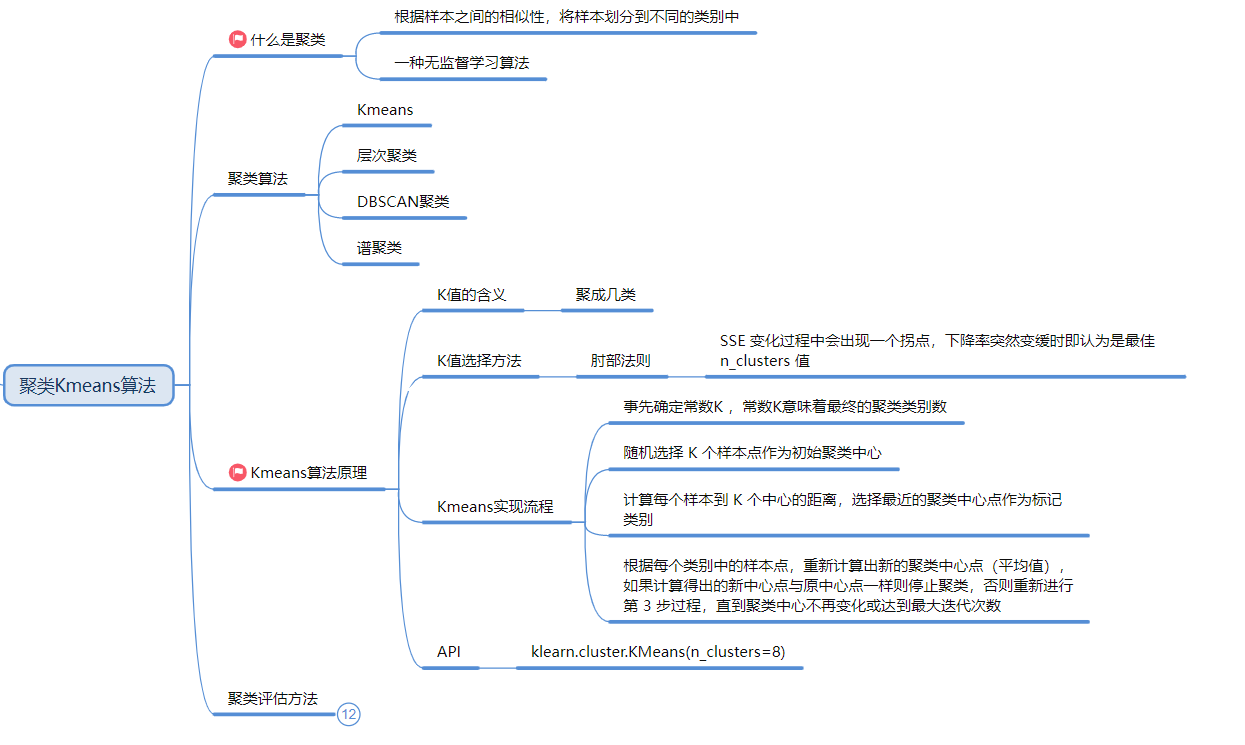
6. K-Means 聚类 —— 无监督
-
流程: 随机选K个中心 -> 分配样本到最近中心 -> 重新算中心 -> 重复直到稳定 。
-
K值怎么选? 肘部法则 (SSE拐点) 。
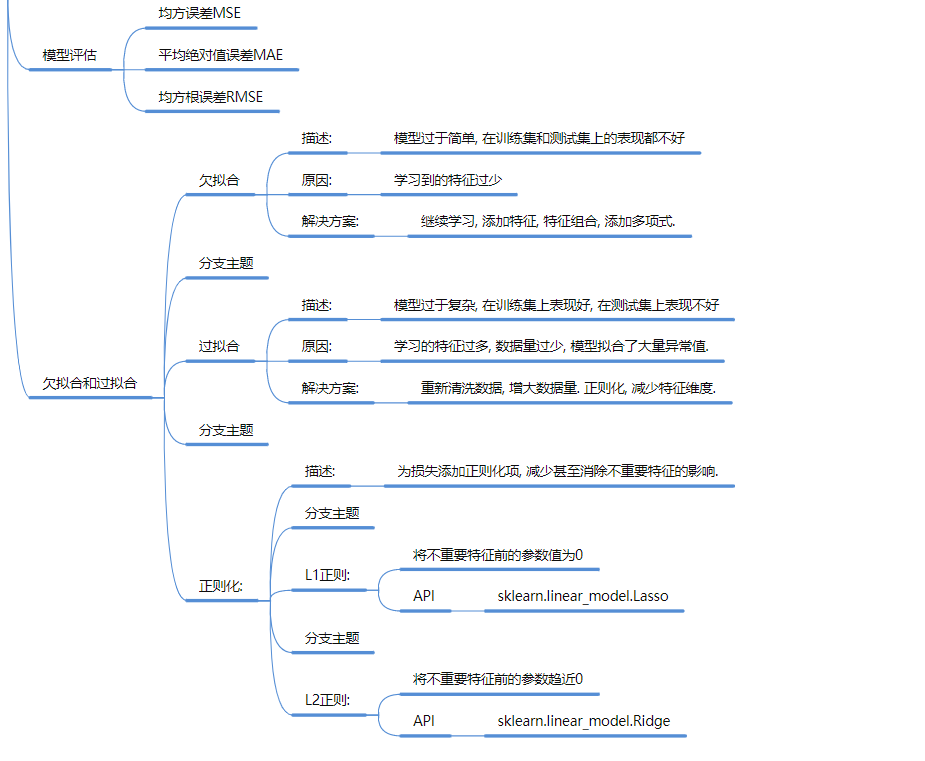
📉 第四部分:模型诊断与优化 (Optimization)
核心逻辑: 模型不准怎么办?
-
过拟合 (Overfitting): 表现为训练集极好,测试集很差。
-
原因: 模型太复杂,特征太多,数据太少。
-
解法: 加数据、正则化、剪枝、Dropout 。
-
-
欠拟合 (Underfitting): 训练集和测试集都差。
-
原因: 模型太简单。
-
解法: 加特征、加多项式特征、换更复杂的模型 。
-
-
奥卡姆剃刀原则: 效果相同时,选简单的模型 。
| 状态 | 症状表现 | 病因 | 药方(解决方案) |
| 欠拟合 (Underfitting) | 训练集和测试集得分都很低。 | 模型太简单了,连数据中最基本的规律都没学会。 | 换更复杂的模型,增加新特征,减少正则化。 |
| 过拟合 (Overfitting) | 训练集得分极高,测试集得分极低。 | 模型太复杂,死记硬背了训练数据的“噪音”和“怪癖”。 | 增加数据量(首选),正则化 (L1/L2),限制决策树深度,神经网络使用 Dropout。 |
注:因为我跟着黑马程序员学的,所以笔记知识也是来自这里,有同学想去学习的话就去https://www.bilibili.com/video/BV1Fzszz4Ek7?spm_id_from=333.788.videopod.episodes&vd_source=fdfdf5e9691f656b18406f27e15aa5f0


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)