全面解析模型微调技术
模型微调是连接通用大模型与垂直领域应用的关键技术,通过针对性参数优化使预训练模型适配专业场景需求。其核心应用场景包括医疗诊断、金融分析等高度专业化领域,以及小样本学习、输出规范定制等特殊需求。技术路径分为全参数微调和参数高效微调(PEFT)两类,其中LoRA、QLoRA等PEFT技术因低资源消耗成为主流选择。标准微调流程包含模型选择、数据准备、训练优化等步骤,需根据任务特点选择合适方法。当前技术仍
在人工智能技术落地的浪潮中,预训练大模型如GPT、LLaMA、ViT等凭借海量数据学习的通用能力,构建了AI应用的技术基座。然而,这些"通才"模型在面对医疗诊断、法律文书解析、金融风险预测等垂直场景时,往往因缺乏领域专属知识而显得力不从心。模型微调(Fine-Tuning)作为连接通用能力与专业需求的关键技术,通过针对性的参数优化,让大模型完成从"博学"到"专精"的蜕变,成为行业智能化升级的核心驱动力。
一、什么是模型微调?
模型微调是指在经过大规模无监督学习训练的预训练模型基础上,使用特定任务或领域的标注数据进行二次训练,通过调整模型参数使其适配目标场景的技术范式。其本质是迁移学习(TransferLearning)在深度学习领域的典型应用——将预训练阶段习得的通用特征表示(如语言语义、图像结构)迁移到特定任务中,再通过少量数据的训练实现知识的"特化"。
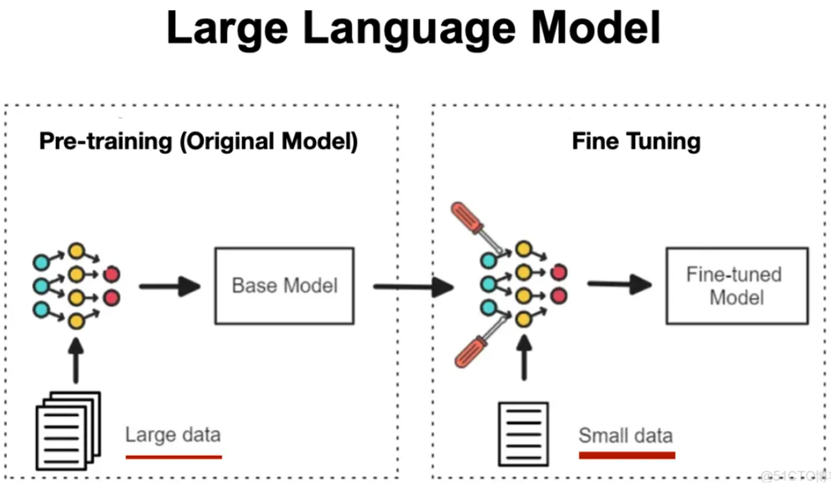
可以用一个生动的类比理解这一过程:预训练模型如同一位博览群书的通识学者,掌握了语言逻辑、基础科学等通用知识;而微调则相当于为这位学者提供短期专项培训,使其快速掌握医学、法律等特定领域的专业技能,最终成为能够解决实际问题的行业专家。
从技术本质看,微调通过最小化任务专属的损失函数,使模型参数在保留通用知识的前提下,向适配目标数据分布的方向更新。这种参数更新机制既避免了从零训练的资源浪费,又能实现模型性能的精准提升。
二、什么情景下需要进行模型微调?
预训练模型的通用性使其难以满足所有场景需求,以下四类典型情景成为模型微调的核心应用场域:
1.垂直领域专业需求场景
当应用涉及医疗、金融、法律等高度专业化领域时,通用模型往往因缺乏领域知识而输出不准确内容。例如,通用模型对"房室传导阻滞"的解释可能停留在基础定义层面,而经过心电图数据和临床指南微调的模型,能够结合具体波形特征给出分型判断和诊疗建议。这类场景的核心需求是将行业知识库注入模型,通常需要使用领域专属数据集(如电子病历、金融年报、判例文书)进行微调。
2.特定任务适配场景
预训练模型主要学习通用特征,而文本分类、问答系统、图像分割等具体任务需要专用的输出结构和特征提取逻辑。以情感分析任务为例,通用语言模型能理解文本含义,但无法直接输出"正面"、"负面"的分类结果;通过标注有情感标签的数据集(如电商评论+情感极性)微调后,模型可在输出层生成符合分类需求的概率分布。此类场景中,微调的核心价值是让模型掌握任务专属的决策逻辑。
3.小样本与低资源场景
在许多实际应用中,大规模标注数据的获取成本极高(如罕见病诊断数据、小众语言翻译数据)。模型微调能够通过"少量数据+通用知识"的组合,高效构建可用模型。例如,针对某地方言的语音识别任务,只需数千条标注语音数据,结合预训练的通用语音模型进行微调,即可达到商用级准确率,而无需从零训练所需的数十万条数据。参数高效微调技术(PEFT)的发展进一步降低了此类场景的应用门槛。
4.输出规范与风格定制场景
企业级应用往往对模型输出的格式、风格、合规性有严格要求。例如,客服机器人需要使用固定话术模板回复用户咨询,财务机器人需生成符合会计准则的报表分析,创作类模型需模仿特定作者的文风。通过包含格式规范和风格特征的数据集微调,可使模型输出严格符合应用场景的规范要求,避免通用模型输出的随机性问题。
三、模型微调的分类和基本原理
根据参数调整范围和技术路径的差异,模型微调可分为全参数微调与参数高效微调两大类,二者在原理、成本和适用场景上存在显著区别。
1.全参数微调(FullFine-Tuning,FFT)
全参数微调是指解冻预训练模型的所有参数,使用目标任务数据对其进行全面更新的微调方式。其核心原理是假设目标任务与预训练任务存在较大差异,需要模型从底层特征到高层决策的全链路适配。
在训练过程中,全参数微调通常采用低于预训练阶段的学习率(一般为1e-5至1e-4),配合AdamW等优化器和余弦退火学习率调度策略,避免剧烈参数更新破坏已习得的通用知识。以7B参数的LLaMA模型为例,全参数微调需存储模型权重(14GB,bfloat16精度)、训练梯度(14GB)和优化器状态(28GB),总显存需求超过56GB,对GPU算力要求极高。
优势在于性能天花板高,能最充分地拟合目标任务的数据分布,适合目标任务与预训练任务差异大的场景(如通用文本模型适配代码生成)。局限性则表现为成本高昂、灾难性遗忘风险高(微调后模型可能丢失原有通用能力),且多个任务需维护多个模型副本,部署难度大。
2.参数高效微调(Parameter-EfficientFine-Tuning,PEFT)
参数高效微调是当前主流的微调范式,通过冻结99%以上的预训练参数,仅调整少量新增或特定参数实现任务适配。其核心原理是利用"模型参数变化具有低秩性"或"任务知识可通过少量模块注入"的特性,以极低的参数成本实现性能提升,同时缓解灾难性遗忘问题。主流PEFT技术包括以下几种:
(1)LoRA与QLoRA
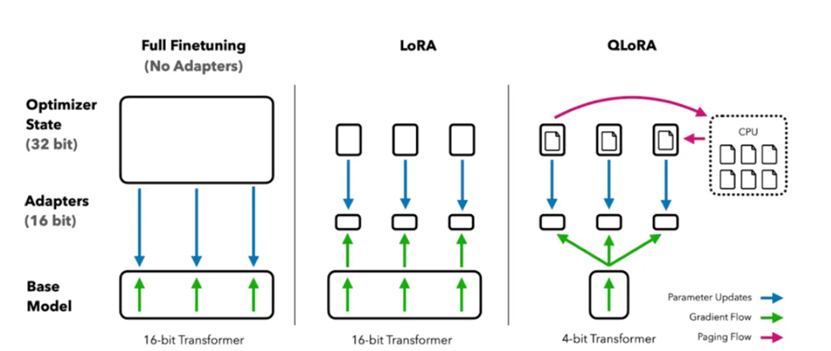
LoRA(Low-RankAdaptation)的核心假设是模型适配新任务时,参数的更新量可通过低秩矩阵近似表示。它在原始权重矩阵W旁新增两个低秩矩阵A(维度d×r)和B(维度r×d,r≪d),训练时仅更新A和B,推理时将AB与W相加(W′=W+AB),不引入额外延迟。其参数量仅为原模型的0.1%-1%,极大降低了显存需求。
QLoRA是LoRA的量化优化版本,通过将预训练模型权重量化至4位(如NF4数据类型)存储,进一步减少显存占用。例如,13B参数模型的QLoRA微调可在单张24GB显存的显卡上完成,而全参数微调需多张80GB显卡集群。该技术已成为中小算力场景下的首选方案。
(2)适配器调整(AdapterTuning)
适配器调整通过在Transformer层之间插入小型"适配器模块"实现微调,这些模块通常采用"下采样-激活-上采样"的瓶颈结构(如1024→256→1024)。训练时冻结原始模型参数,仅更新适配器权重,参数量占比约3%-5%。
与LoRA的并行结构不同,适配器采用串行插入方式,使其更适合复杂任务(如命名实体识别、多轮问答)。但其缺点是增加了模型深度,导致推理速度略有下降,模块化设计使其便于多任务的适配器组合使用。
(3)提示类微调(PromptTuning/PrefixTuning)
这类方法通过在输入层添加可训练的虚拟Token(VirtualToken)引导模型行为,完全冻结原始模型参数。PrefixTuning在输入序列前端添加连续的前缀向量,为模型提供任务上下文;PromptTuning则使用少量虚拟Token模拟自然语言提示,更适合生成任务。
P-Tuning作为改进版本,通过LSTM等小型编码器动态生成虚拟Token,解决了固定提示对复杂任务适配不足的问题;P-Tuningv2进一步将提示向量应用到模型各层,提升了任务适配的稳定性。此类方法参数量极低(<0.1%),但对提示长度和位置敏感,需通过验证集优化配置。
(4)其他PEFT技术
BitFit仅微调模型的偏置项(BiasTerms),参数量占比<0.1%,计算成本最低,适合简单分类任务和低资源场景,但复杂任务效果有限。IA³(InfusedAdapterbyInhibitingandAmplifyingInnerActivations)通过调整激活值的缩放因子实现微调,参数极少且对多任务适配性好,但对数据分布变化敏感。
主流微调方法对比
|
方法 |
参数量占比 |
推理速度 |
显存需求 |
适用场景 |
核心优势 |
|
全参数微调 |
100% |
无影响 |
极高 |
复杂任务、任务差异大场景 |
性能天花板高 |
|
LoRA |
0.1%-1% |
无影响 |
低 |
多任务、生成/分类任务 |
高效灵活,结构无损 |
|
QLoRA |
0.1%-1% |
无影响 |
极低 |
低算力场景、大模型微调 |
硬件门槛低,成本可控 |
|
Adapter |
3%-5% |
略慢 |
中 |
复杂任务(NER、QA) |
模块化,扩展性强 |
|
PromptTuning |
<0.1% |
无影响 |
极低 |
生成任务、多任务场景 |
无需修改模型结构 |
|
BitFit |
<0.1% |
无影响 |
极低 |
简单分类、低资源场景 |
计算成本最低 |
四、微调之前:分析是否需要微调
在投入资源之前,首要任务是进行判断是否需要微调。微调并非解决所有问题的唯一方法。面对一个业务需求,我们通常有三种技术路径可选:微调、RAG还是提示工程?
(1)提示词工程 (Prompt Engineering):最轻量级的方法。通过精心设计输入给模型的指令(Prompt),引导其产生期望的输出。
适用场景:任务相对简单,模型已有能力完成,只需正确引导。例如,生成特定格式的周报、进行通用文本翻译。
优点:成本最低,无需训练,即时生效。
(2)检索增强生成 (Retrieval-Augmented Generation, RAG):当任务需要模型访问外部、动态变化的知识时,RAG是首选。它将用户问题与一个外部知识库(如公司文档、实时数据库)相结合,将检索到的相关信息作为上下文提供给模型,以生成答案。
适用场景:知识密集型问答、需要引用信源、知识库频繁更新的场景。
优点:有效对抗“模型幻觉”,知识可实时更新,答案可溯源。
(3)微调 (Fine-Tuning):当核心目标是改变模型的内在行为、风格或使其掌握特定领域的“语感”时,微调的价值才能最大化。
适用场景:
风格/语气模仿:让模型以特定品牌、角色或人物的口吻进行对话(如模仿莎士比亚风格写作)。
复杂指令遵循:教会模型理解并执行多步骤、领域专属的复杂指令。
领域知识内化:让模型学习特定领域的术语、逻辑和推理模式,而非简单地从外部文本中检索。
纠正模型偏见:通过高质量的平衡数据,修正模型在某些话题上的不当偏见或重复性问题。
电商客服场景的深度剖析
假设我们需要一个能处理退货申请的AI客服。
提示工程:可以写一个长提示:“你是一个专业的客服,请根据以下用户评论判断是否同意退货,并生成安抚性话语…”。这能解决一部分问题,但无法处理复杂情况。
RAG:可以外挂一个“退货政策”知识库。当用户问“我买的衣服洗了一次就掉色了,能退吗?”,RAG会检索到“商品影响二次销售不予退货,但质量问题除外”的条款,并据此回答。
微调:真正的挑战在于,用户的话语是模糊的。“太大”、“质量不错但物流慢”,这些评论背后是怎样的情感和意图?微调能让模型学习这些细微的情感线索和领域内的隐式规则。微调后的模型不仅知道“质量问题可退”,更能从“洗了一次就掉色”中推理出这属于质量问题,并主动、共情地生成“非常抱歉给您带来了不愉快的体验,根据我们的政策,质量问题是完全可以退货的,请您…”这样的回复。
微调与RAG的协同作战: 这两者并非完全对立,而是可以强强联合。例如,我们可以微调模型,使其更擅长理解RAG检索出的上下文,或者生成更精准的关键词去检索知识库。
选择对比与建议
|
场景特性 |
优先考虑微调 (Fine-Tuning) |
优先考虑RAG |
|
核心目标 |
改变模型行为 :学习特定风格、语气、复杂推理模式。 |
提供外部知识 :回答基于特定、可变文档的问题。 |
|
知识库类型 |
静态或缓变知识(行业术语、写作风格、通用法规)。 |
动态或实时知识(新闻、股价、公司最新政策)。 |
|
数据要求 |
需要大量高质量的“指令-响应”或对话数据。 |
仅需结构化或非结构化的文档库。 |
|
可解释性 |
低(模型决策过程是黑盒)。 |
高(答案可明确追溯到检索的原文)。 |
|
幻觉控制 |
改善领域内的幻觉,但对未知领域仍可能产生幻觉。 |
极大减少幻觉,答案被限定在所提供的上下文中。 |
|
知识更新 |
成本高,需重新训练模型。 |
成本低,只需更新外部知识库。 |
|
数据隐私 |
敏感知识被“内化”到模型权重中。 |
敏感知识存储在本地,检索过程可控。 |
四、模型微调的流程步骤
模型微调是一个包含数据准备、模型配置、训练优化、评估部署的系统工程,各步骤的执行质量直接决定最终效果。以下是标准化的微调流程:
1.预训练模型选择
根据任务类型和数据特征选择合适的预训练模型是微调的基础。文本理解类任务(如情感分析、命名实体识别)优先选择BERT、RoBERTa等编码器模型;文本生成类任务(如摘要、对话)适合GPT、T5等解码器/编码器-解码器模型;图像类任务则常用ViT、ResNet等视觉模型。
模型规模的选择需平衡性能与成本:7B-13B参数的模型适合中小规模任务,65B以上参数的模型则用于高复杂度场景。此外,还需考虑模型许可证(如商用需选择Apache2.0许可的Qwen系列)和社区支持度(如LLaMA系列有丰富的微调工具链)。
2.数据集准备与预处理
高质量数据是微调成功的关键,该阶段包含数据收集、清洗、标注和格式转换四个环节:
(1)数据收集:优先选择高质量、领域相关的数据集,如医疗任务可用MIMIC-III电子病历库,法律任务可用中国裁判文书网数据。
(2)数据清洗:去除噪声数据(如重复文本、乱码内容),标准化格式(如统一医学术语、金融指标名称),处理缺失值(如用领域均值填充)。
(3)数据标注:对于无标注数据,可采用"小样本标注+人工校验"的方式;专业领域数据需由行业专家参与标注,确保标签准确性。
(4)格式转换:根据模型输入要求转换数据格式,如分类任务采用"文本+标签"格式,问答任务采用"问题+上下文+答案"格式,并划分训练集(70%-80%)、验证集(10%-15%)和测试集(10%-15%)。
数据增强技术可进一步提升微调效果,如文本任务采用同义词替换、句子重排,图像任务采用裁剪、旋转,语音任务采用语速调整等。
3.模型结构适配与参数配置
根据目标任务调整模型结构,核心是适配输出层:
(1)分类任务:在预训练模型输出层后添加全连接层和Softmax激活函数,输出类别概率。
(2)生成任务:保留解码器结构,调整输出层的词表大小(如添加领域专属词汇)。
(3)检测任务:在视觉模型后添加锚点生成和边界框预测模块。
参数配置需重点关注:
(1)学习率:全参数微调通常设为1e-5至1e-4,PEFT技术设为1e-4至1e-3(LoRA常用2e-4)。
(2)批量大小(BatchSize):根据显存大小调整,常用8、16或32,可配合梯度累积提升实际批次大小。
(3)训练轮次(Epoch):一般设为3-10轮,通过早停策略(EarlyStopping)避免过拟合(如验证集性能连续3轮无提升则停止训练)。
(4)正则化策略:采用Dropout(比例0.1-0.3)、权重衰减(WeightDecay,常用1e-4)减少过拟合风险。
4.微调训练执行
训练过程需结合硬件环境选择合适的工具链:
(1)硬件选择:全参数微调需多卡GPU集群(如8×A100),PEFT微调可使用单张消费级显卡(如RTX4090)。
(2)框架与工具:PyTorch为核心框架,配套工具包括Transformers(模型加载)、PEFT(参数高效微调)、Accelerate(分布式训练)、LlamaFactory(一站式微调平台)。
(3)训练监控:使用TensorBoard或Weights&Biases(W&B)实时监控损失值、评估指标变化,及时发现训练异常(如损失不下降、过拟合)。
对于大模型微调,可采用混合精度训练(如bfloat16)进一步降低显存占用,配合梯度检查点技术减少内存消耗。
5.模型评估与调优
评估阶段需采用任务专属的指标体系,核心步骤包括:
(1)指标计算:分类任务用准确率、F1值、AUC;生成任务用BLEU、ROUGE、CIDEr;问答任务用EM(精确匹配)、F1值;图像任务用mAP、IoU。
(2)错误分析:通过混淆矩阵、错误案例抽样等方式定位问题,如模型在"罕见类别"上的分类准确率低,需补充该类数据。
(3)超参数调优:采用网格搜索或贝叶斯优化调整学习率、批量大小等参数,提升模型性能。
若评估结果不理想,需回溯前序步骤:性能过低可能是数据量不足,过拟合可能是训练轮次过多,泛化性差可能是数据分布与真实场景不符。
6.模型部署与迭代
微调后的模型需经过优化才能部署:
(1)模型压缩:采用量化(如INT8/INT4)、剪枝等技术减少模型体积,提升推理速度。
(2)部署框架:根据场景选择TensorRT(高吞吐量)、ONNXRuntime(跨平台)、TritonInferenceServer(大规模部署)。
(3)持续迭代:收集部署后的真实反馈数据,定期进行增量微调,使模型适应数据分布变化(如新增的医疗指南、金融政策)。
五、模型微调的案例分析
1.医疗领域:基于ViT的医学影像诊断模型微调
背景:某医院需构建肺结节自动检测系统,通用ViT模型对微小肺结节(<5mm)的检出率仅65%,无法满足临床需求。
微调实施:
1.模型选择:选用在ImageNet上预训练的ViT-Base模型,其通用图像特征提取能力适合医学影像任务。
2.数据准备:收集10000例胸部CT影像,由3名放射科医生标注肺结节位置(含500例微小结节数据),划分训练集8000例、验证集1000例、测试集1000例。
3.技术路径:采用LoRA进行参数高效微调,在ViT的注意力层插入低秩矩阵(秩r=8),冻结原始模型99%参数。
4.训练配置:学习率2e-4,批量大小16,训练5轮,采用Dice损失函数(适配医学分割任务)。
效果:微调后模型的肺结节检出率提升至92%,其中微小结节检出率达88%,推理时间保持在0.1秒/张,满足临床实时诊断需求。该模型已集成到医院PACS系统,日均处理CT影像200余例,减少放射科医生30%的阅片时间。
2.金融领域:基于LLaMA的风险舆情分析模型微调
背景:某券商需实时分析财经新闻、社交媒体中的风险信息,通用LLM对"信用债违约信号"的识别准确率仅70%,易遗漏隐性风险。
微调实施:
1.模型选择:选用7B参数的LLaMA-2模型,其文本理解能力适合舆情分析任务。
2.数据准备:收集2018-2024年的5000条信用债相关舆情数据,标注"违约风险""无风险""不确定"三类标签,补充1000条包含"担保不足""现金流恶化"等关键词的隐性风险数据。
3.技术路径:采用QLoRA(4位量化)进行微调,在单张3090显卡上完成训练,参数量仅占原模型的0.5%。
4.训练优化:针对金融文本特点,添加领域词表(如"城投债""展期""交叉违约"),采用F1损失函数优化类别不平衡问题。
效果:微调后模型的风险识别准确率达89%,隐性风险信号检出率提升40%,能提前3-7天识别潜在违约事件。该模型已接入券商风控系统,2024年成功预警3起信用债违约事件,减少损失约2亿元。
3.企业服务领域:基于GPT的智能客服模型微调
背景:某电商平台客服机器人需处理订单查询、售后维权等标准化问题,通用GPT模型的回复准确率80%,但格式不规范,需人工二次整理。
微调实施:
1.模型选择:选用GPT-3.5-turbo基础模型,其生成能力适合对话任务。
2.数据准备:收集10000条历史客服对话,按"用户问题+标准回复"格式整理,包含订单查询、退款申请等8类场景,统一回复格式(如"【订单状态】XXX【处理建议】XXX")。
3.技术路径:采用PromptTuning技术,训练512个虚拟提示Token,冻结原模型参数。
4.训练配置:学习率1e-3,批量大小32,训练4轮,采用困惑度(Perplexity)监控训练效果。
效果:微调后模型回复准确率提升至95%,格式规范率达100%,客服人工介入率从40%降至15%,日均处理咨询量提升至5万条,单条咨询处理时间从60秒缩短至15秒。
六、挑战与未来趋势
模型微调技术虽已广泛应用,但仍面临三大核心挑战:灾难性遗忘(微调后模型丢失原有通用能力)、数据质量依赖(低质量标注数据导致性能下降)、多任务适配难题(单一模型难以兼顾多个异构任务)。针对这些问题,行业正朝着三大方向发展:
1.高效微调技术深化:QLoRA、IA³等技术的持续优化将进一步降低显存需求,预计未来可在消费级显卡上实现百亿参数模型的微调;动态低秩调整技术将解决固定秩设置的适配问题。
2.多任务联合微调:通过共享基础模型、独立任务适配器的架构设计,实现"一次微调适配多任务",降低企业部署成本,尤其适合客服、医疗等多场景融合的应用。
3.持续学习与增量微调:基于记忆replay或参数隔离技术,使模型能在不遗忘旧知识的前提下吸收新数据(如新增的医学指南、金融政策),实现模型的终身进化。
结语
模型微调作为释放大模型价值的核心技术,构建了从通用人工智能到行业应用的关键桥梁。微调技术的发展持续降低AI的应用门槛。随着高效微调技术的不断突破,大模型将真正渗透到千行百业的毛细血管中,成为推动智能化转型的核心引擎。对于技术从业者而言,掌握微调的原理与实践方法,将是把握AI落地机遇的关键能力。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等
一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等
😝有需要的小伙伴,可以 下方小卡片领取🆓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献252条内容
已为社区贡献252条内容

所有评论(0)