【AI大模型大厂面试真题】阿里大模型一面:“RAG是什么?”看完这一篇你就知道怎么回答了!!
文章详细介绍了RAG(检索增强生成)技术,解释了开放域问答系统的三种类型,重点阐述了RAG的基本框架,包括检索器和生成器两个阶段。随着大模型参数量增加,纯生成方法虽效果好但存在幻觉和知识截止时间等问题,而结合RAG技术可有效解决这些问题,成为大模型应用的典型方案。
前言
随着大模型技术的蓬勃发展,催生了很多基于大模型的应用,就比如现在比较火的 RAG(检索增强生成)。
然而 RAG 并不是一个新的概念,这个方法早在大模型出现之前就被提出了,本质上是一个开放域问答系统(Open-domain Question Answering System)。所谓开放域是指可以回答任何事实性的问题,对应的封闭域问答系统则只能回答特定领域的问题,比如银行的客服机器人,电商平台的智能客服等。
翁荔在《How to Build an Open-Domain Question Answering System?》中将开放域的问答系统分为了 3 类。如下图所示
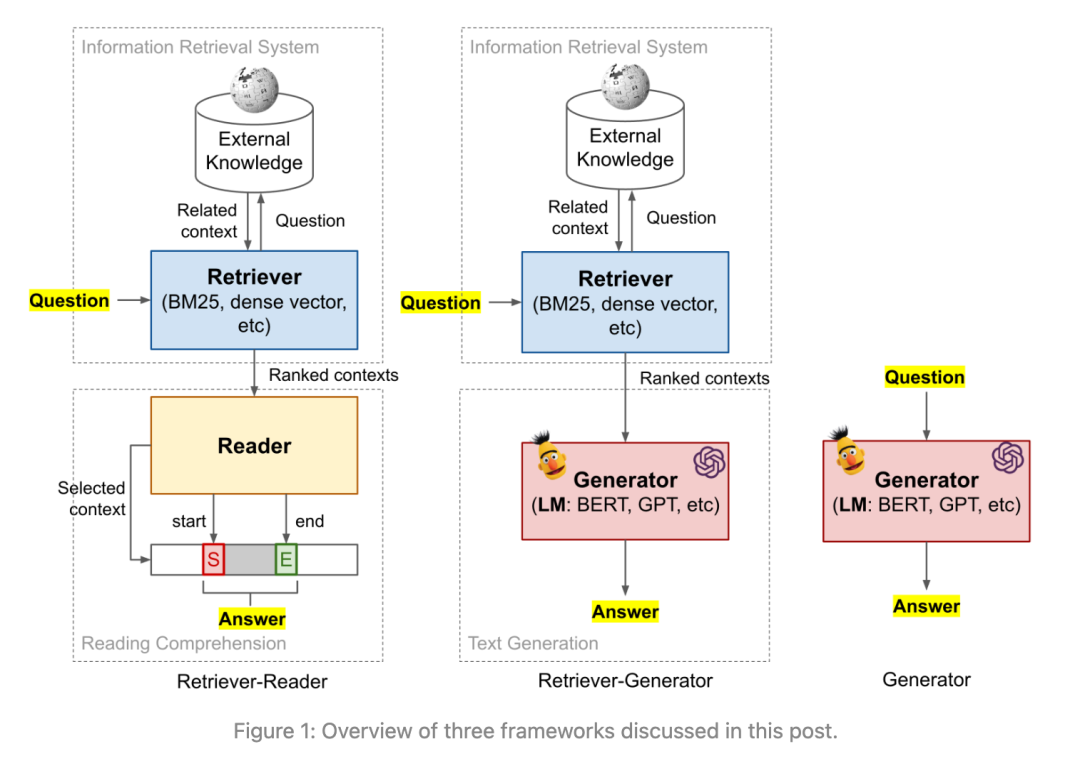
image src: https://lilianweng.github.io/posts/2020-10-29-odqa/
第一种: Retriever-Reader
根据问题进行检索,然后通过一个模型做阅读理解,从检索结果中把能回答问题的原文提取出来。由于这一种和 RAG 关系不大,就不再展开讲了。
第二种: Retriever-Generator
根据问题进行检索,根据问题和检索结果利用一个生成模型将答案生成出来。这其实就是 RAG 的基本框架。
论文《Retrieval-augmented generation for knowledge-intensive nlp tasks》第一次提出了 RAG 的概念。
文中将 RAG 建模为两个阶段:
Step1
根据问题 x 和检索内容 z 构建一个检索器 ,参数为 , 返回一个概率分布(实践中采用 topK 截断)。
论文中检索器采用了 DPR(Dense Passage Retrieval) ,建模如下:
DPR 采用了两个 Bert 分别对 x 和 z 进行 encode,然后训练一个向量表示,使得相关的 x 和 z 比不相关的具有更高的 cosine 相似度。
Step 2
构建一个语言模型 作为 generator。 文中采用了两种不同的生成方式来生成最终的答案。
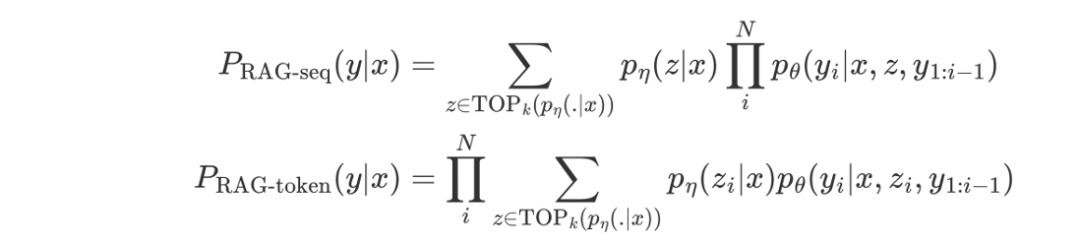
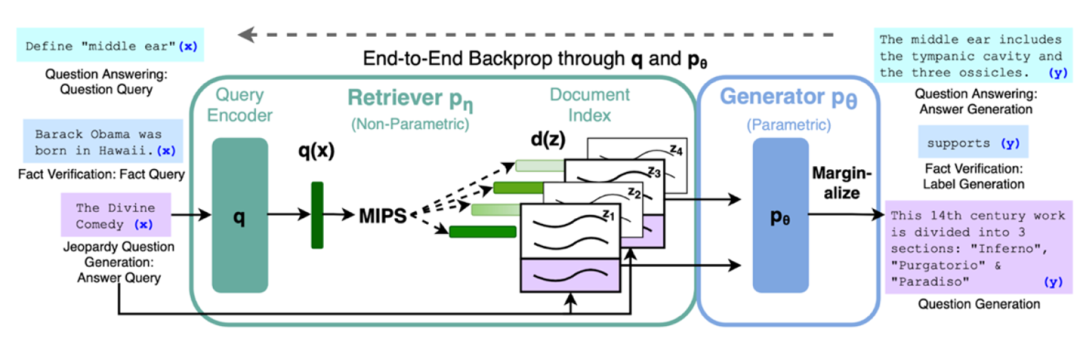
整个流程图下图所示,注意这是一个端到端的模型,需要进行训练:
第三种: Generator
不借助外部检索工具,直接根据问题生成答案,这其实就是 ChatGPT 的雏形。
早期的时候,纯生成方法的效果其实没有前两种好,包括 T5 和 GPT-3 的效果都与前两种有很大差距。
后来大模型的参数量越来越大之后,纯生成的方法逐渐就比前两种方法要好了。
然而大家在使用纯生成的模型中也发现了一些问题,比如大模型存在幻觉,大模型的知识有截止时间等。
之前的文章也有提到过,大模型通过 Prompt Engineering 可以展现出惊人的能力,此时灵机一动,把 RAG 第二步的 generator 直接换成大模型可以不可以?这样大模型的输入中就包含了与问题相关的知识,而且可以补充大模型截断时间之后的内容。
答案当然是可以,而且 RAG 迅速火爆出圈,成为典型的大模型应用。
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇


面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献283条内容
已为社区贡献283条内容

所有评论(0)