不止是 “提问”:掌握 LLM 核心逻辑,让 AI 成为你的高效工具
摘要: 大语言模型(LLM)的核心是文本预测,基于Transformer架构实现长文本理解,通过预训练(通用知识)和微调(专项技能)获得能力。用户需了解其四大限制:幻觉(编造信息)、上下文窗口有限(长文本记忆不足)、知识截止(无法获取最新信息)和推理深度不足。应用时需掌握提示词工程三原则:明确具体指令、提供参考示例、设定专业角色,并针对不同任务(内容创作、信息整理等)适配策略。通过分步骤提问、交叉
对于普通AI LLM(大语言模型)使用者,无需深入钻研数学公式(如梯度下降、注意力权重计算)或工程实现(如分布式训练框架),但理解核心原理逻辑和关键应用规则,能显著提升对AI的判断力(避免误解/滥用)和使用效率(产出更高质量结果)。以下从「原理认知」和「应用实践」两大维度,梳理必须了解的知识点,全程用通俗语言+实际场景举例,避免技术堆砌。
一、原理认知:搞懂「AI为什么能干活」的核心逻辑
这部分的目标是:知道LLM的「能力来源」和「天生局限」,不把AI当“万能神”,也不因偶尔出错而否定其价值。核心围绕「LLM是什么、怎么来的、怎么工作的」三个问题展开。
1. 基础概念:LLM的本质是「高级文本预测器」
首先要破除一个误区:LLM不是“会思考的大脑”,而是「基于海量文本,预测“下一个词该是什么”的程序」。
- 本质逻辑:比如你输入“今天天气很好,我打算去”,LLM会根据它学过的所有类似文本(如“去公园”“去爬山”“去散步”),计算出“最可能符合语境”的下一个词/短语,最终连起来形成完整回答。
- 关键类比:就像你看到“床前明月光,疑是”,会自然想到“地上霜”——LLM的“预测”,只是基于更庞大的文本库(从书籍、网页、论文到对话),且预测精度更高、上下文更长。
这一点是理解所有LLM行为的基础:比如AI“答非所问”,本质是它预测的“下一个词”偏离了你的需求;AI“说假话(幻觉)”,是它在“没学过准确信息”时,仍强行预测了“看似合理但错误的内容”。
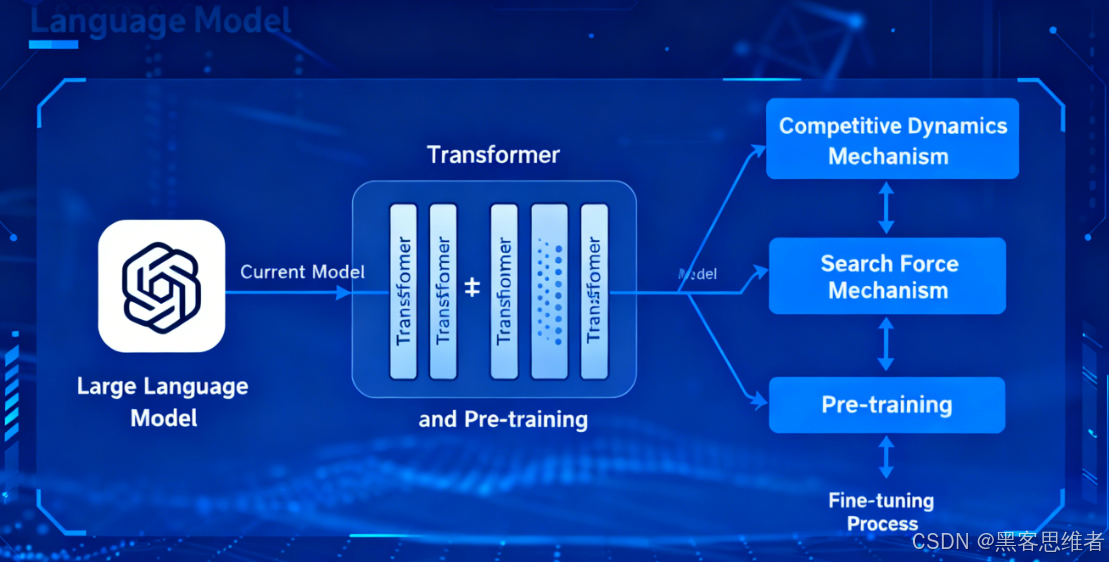
2. 核心技术:Transformer架构(LLM的“骨架”)
Transformer是所有主流LLM(如GPT、文心一言、LLaMA)的核心架构,无需懂细节,但要知道它的核心优势——解决了“长文本理解”问题,这是LLM能写文章、做对话的关键。
其中最关键的子模块是「注意力机制(Attention)」,通俗理解就是:
- AI处理文本时,会像人看书一样“有重点”:比如处理句子“小明带小红去买冰淇淋,她很喜欢香草味”,注意力机制会让AI知道“她”指的是“小红”,而不是“小明”或“冰淇淋”。
- 没有注意力机制的早期AI(如RNN),处理长文本时会“记不住前面的内容”(比如写1000字文章,后面会忘了开头的设定),而Transformer通过注意力机制,能“关联上下文所有信息”,所以能处理更长的输入(如几万字的文档)。
3. 能力来源:预训练+微调(LLM的“学习过程”)
LLM的“本事”不是天生的,而是分两步学来的,知道这两步能帮你理解:为什么有的AI擅长写代码(如CodeLlama),有的擅长写论文(如GPT-4o Academic)。
| 阶段 | 目标 | 通俗解释 | 例子 |
|---|---|---|---|
| 预训练 | 打基础(学“通用知识”) | 让AI读遍互联网上的海量文本(书籍、网页、论文等),学会语言逻辑、常识、概念(比如“地球是圆的”“水在0℃结冰”),但不针对具体任务。 | GPT-4的预训练:读了数万亿token的文本,学会了多语言、基础科学、历史等。 |
| 微调 | 定向优化(学“专项技能”) | 用特定领域的数据集“训练”预训练后的模型,让它专注于某类任务(如写代码、做医疗咨询、生成营销文案)。 | CodeLlama:在预训练基础上,用海量代码库(Python/Java等)微调,所以擅长写代码。 |
对使用者的价值:选择AI时,要匹配“微调方向”——比如写代码别用主打“诗歌创作”的模型,效率会更高。
4. 关键限制:LLM的“天生短板”(避免踩坑)
理解限制比理解能力更重要,能帮你避免“轻信错误信息”或“浪费时间做不可能的事”。核心限制有4个:
-
幻觉(Hallucination):AI会“一本正经地说假话”。
- 原因:当AI对某个问题没有足够的训练数据时,仍会按“预测逻辑”生成“看似合理但错误的内容”(比如编造不存在的论文作者、错误的历史年份)。
- 场景:你问“2023年诺贝尔物理学奖得主的具体贡献”,如果AI没学过准确信息,可能会编造一个“听起来很专业”但错误的贡献描述。
- 应对:涉及事实性内容(如数据、引用、事件),必须交叉验证(查权威网站、论文库)。
-
上下文窗口有限:AI“记不住太长的内容”。
- 概念:每个LLM都有“上下文长度限制”(比如GPT-3.5是4k token,GPT-4o是128k token),1个token约等于0.7个中文字(即4k token≈2800字)。
- 场景:你给AI上传一篇5000字的报告,让它总结“第三章的观点”,如果报告超过AI的上下文窗口,AI可能会漏看第三章内容,导致总结错误。
- 应对:超长文本分段落输入,或选择上下文窗口更大的模型(如GPT-4o、Claude 3 Opus)。
-
知识截止日期(Knowledge Cutoff):AI“不知道截止日期后的事”。
- 原因:LLM的预训练数据有“截止时间”,之后发生的事件、数据它都不知道(比如2024年5月预训练的模型,不知道2024年6月的新政策、新事件)。
- 场景:你问“2024年世界杯冠军是谁”,如果模型截止日期是2024年5月(世界杯6月举办),它会告诉你“无法预测”,而不是正确答案。
- 应对:涉及实时/最新信息(如新闻、政策、股市),需让AI结合“实时搜索工具”(如GPT-4联网版、豆包的实时搜索功能)。
-
缺乏“逻辑推理深度”:AI不擅长“复杂多步推理”。
- 原因:LLM的预测逻辑是“逐词生成”,没有“主动拆解问题”的能力(比如数学题、逻辑题,容易在中间步骤出错)。
- 场景:你让AI算“小明有5个苹果,分给3个朋友,每人分1个后,还剩几个”,AI可能算对;但如果是更复杂的“鸡兔同笼”问题,AI可能会给出错误公式。
- 应对:复杂推理题“分步骤提问”(比如先让AI列出解题思路,再算每一步结果),或用专门的“推理型模型”(如GPT-4o、Gemini Pro)。
二、应用实践:让AI“听话、出活”的核心技巧
原理是“知其所以然”,应用技巧是“知其如何用”。这部分知识点直接决定你的使用效率,核心围绕「如何让AI理解你的需求」和「如何引导AI输出高质量结果」。
1. 提示词工程(Prompt Engineering):AI的“指令说明书”
提示词(你输入给AI的文字)是你与AI的“唯一沟通渠道”,好的提示词能让AI从“答非所问”变成“精准输出”。普通使用者无需学复杂的“提示词模板”,但必须掌握3个核心原则:
原则1:指令“明确具体”,拒绝“模糊需求”
- 反面例子(模糊):“帮我写一篇关于环保的文章。”(AI不知道写多少字、面向谁、侧重哪个方向,可能写得泛泛而谈)。
- 正面例子(明确):“帮我写一篇800字的环保科普文章,面向初中生,重点讲‘塑料污染对海洋生物的危害’,开头用‘海龟误食塑料袋’的案例引入,语言要口语化,避免专业术语。”
- 关键:明确「任务类型(科普文章)+ 受众(初中生)+ 核心内容(塑料污染)+ 形式要求(800字、案例开头)」,AI的预测方向会更精准。
原则2:给“参考示例”,让AI“照猫画虎”
如果任务有“特定格式/风格”,直接给AI示例,比文字描述更有效(这叫“少样本提示 Few-shot Prompting”)。
- 场景:让AI帮你整理“会议纪要”,但你需要特定格式(时间、参会人、待办事项、负责人)。
- 提示词:“请按以下格式整理会议纪要:
【时间】2024年5月20日 14:00-16:00
【参会人】张三(产品)、李四(技术)
【核心结论】1. 产品V2.0版本延期至6月上线;2. 新增“用户反馈”模块。
【待办事项】1. 李四:5月25日前提交技术方案;2. 张三:5月22日前同步延期通知给客户。
现在,请整理以下会议内容:(此处粘贴会议记录)”
- 原理:示例帮AI明确了“预测的格式边界”,避免它自由发挥出不符合你需求的格式。
原则3:用“角色设定”,让AI“代入场景”
给AI赋予一个“专业角色”,能让它的输出更贴合该场景的专业度(这叫“角色提示 Role Prompting”)。
- 反面例子:“帮我改一下这封邮件。”(AI可能只改语法,不会考虑商务礼仪)。
- 正面例子:“请你扮演‘互联网公司商务经理’,帮我修改以下邮件:(粘贴邮件内容)。要求:1. 语气正式、礼貌,体现合作诚意;2. 重点突出‘合作方案的核心优势’(降低对方成本30%);3. 结尾明确‘希望下周3前沟通反馈’。”
- 原理:角色设定帮AI锁定了“预测的语言风格和专业重点”(商务经理 vs 普通用户,输出逻辑完全不同)。
2. 任务适配:不同场景的“AI使用策略”
LLM不是“万能工具”,不同任务的效率和效果差异很大,要学会“扬长避短”,选择合适的模型/方法。
| 任务类型 | 核心需求 | 推荐策略 | 注意事项 |
|---|---|---|---|
| 内容创作 | 文案、诗歌、故事、PPT | 用“角色设定+明确风格”(如“扮演广告文案师,写3条奶茶店宣传语,风格年轻化、有网感”) | 避免让AI写“高度原创性”内容(如学术论文核心观点),需自己二次创作。 |
| 信息整理 | 总结报告、提取关键点 | 超长文本“分段输入”,明确“提取维度”(如“总结以下报告的‘问题、原因、建议’三点”) | 交叉验证关键数据(如报告中的数值、日期),避免AI漏提/错提。 |
| 问题解答 | 常识、概念解释、学习辅助 | 复杂问题“分步骤问”(如“先解释什么是‘区块链’,再举1个生活中的应用例子”) | 实时/专业问题(如医疗、法律),需结合权威工具(如让AI联网查最新法规),不直接采信。 |
| 工具协同 | 文档处理、数据可视化 | 结合AI的“工具调用能力”(如让AI“读取Excel表格,生成销售数据柱状图”“将PDF文档转为Word并排版”) | 敏感文档(如合同、身份证),优先用“本地部署的AI”(如豆包本地版),避免数据泄露。 |
3. 结果优化:如何让AI“迭代输出”
AI第一次输出可能不完美,不要直接放弃,而是通过“反馈调整”让它优化(这叫“迭代提示 Iterative Prompting”)。
- 场景:让AI写一篇“产品推广文案”,第一次输出太笼统,没有突出“产品价格优势”。
- 调整提示词:“你之前写的文案很好,但请补充以下内容:1. 突出‘产品原价299元,现在活动价199元’,用‘限时3天’制造紧迫感;2. 增加‘用户评价’(如‘90%用户反馈“使用后效率提升50%”’)。请基于此修改文案。”
- 关键:明确「哪里不好(没突出价格)+ 怎么改(补充价格、用户评价)」,AI能根据你的反馈调整“下一轮预测方向”,逐步逼近你的需求。
三、进阶认知:伦理与安全(避免风险)
作为普通使用者,了解基本的“AI安全规则”,能避免个人信息泄露或被AI误导。
-
数据隐私:不向AI上传敏感信息
- 风险:你输入给AI的文本(如身份证号、银行卡号、公司机密),可能会被用于模型训练(除非明确说明“本地处理”)。
- 应对:涉及隐私信息(如简历中的手机号、合同中的商业机密),要么“打码后输入”,要么用“本地部署的AI工具”(如豆包本地版、LLaMA 2本地版)。
-
信息验证:不把AI当“权威来源”
- 场景:AI回答“某药物的副作用”“某法律条款的具体内容”“某历史事件的细节”时,必须交叉验证(查医院官网、政府法规库、权威史书)。
- 原因:LLM的“知识”来自训练数据,可能包含错误信息(如过时的医疗指南、片面的历史解读),且没有“主动纠错”能力。
-
避免滥用:不让AI做“违规/有害”的事
- 规则:所有正规LLM都有“内容安全过滤机制”,不会帮你写“恶意代码、虚假新闻、违法攻略”(如“如何制作假证件”“如何网络诈骗”)。
- 责任:使用者需主动拒绝“违规需求”,避免因依赖AI而触碰法律/道德红线。
总结:普通使用者的“知识地图”
无需死记硬背,记住以下核心逻辑即可:
- 原理层面:LLM是“文本预测器”,能力来自“预训练+微调”,天生有“幻觉、上下文有限、知识截止”的短板;
- 应用层面:用“明确指令+示例+角色设定”写提示词,不同任务适配不同策略,不完美就迭代优化;
- 安全层面:隐私不泄露、信息要验证、不做违规事。
理解这些后,你不仅能更高效地用AI解决工作/学习问题(如写报告、改文案、整理资料),还能理性判断AI输出的可靠性,避免“盲目依赖”或“因噎废食”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)