YOLOv8【特征融合Neck篇·第19节】GiraffeDet长颈鹿特征网络,此文帮你搞懂!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。 ✨ 特惠福利
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
💖 一、温故知新:上期内容回顾 (DetectoRS递归特征融合)
嘿,最勤奋的探索者们,欢迎回到我们的深度学习之旅!在我们一同迎接今天这位优雅的“长颈鹿”之前,让我们先驻足回望上一座巍峨的高峰——DetectoRS。那是一个将“递归”思想运用到极致,为了追求性能巅峰而打造的“重装猛兽”!
1.1 DetectoRS的宏大叙事:双重递归的威力
DetectoRS的设计哲学可以概括为“精益求精,反复打磨”。它认为,传统的“Backbone -> Neck -> Head”单向信息流是不够的,特征应该在整个网络中得到更充分、更深度的迭代和精炼。为此,它构建了一个前所未有的宏观反馈循环,实现了Backbone和Neck之间的双向对话。
1.2 核心机制(1): 递归特征金字塔 (RFP)
这是DetectoRS在宏观层面的递归。传统的FPN只是对Backbone的输出进行一次加工,而RFP则勇敢地打破了这种单向流:
- 初次前传:图像首先正常通过Backbone和FPN,得到第一版的特征金字塔。
- 信息反馈:RFP将FPN输出的、已经融合了多尺度信息的特征,通过一个特殊的转换模块,反馈回Backbone的早期阶段。
- 二次精炼:Backbone现在接收的输入,不仅仅是原始图像的浅层特征,还包含了来自高层的、全局的上下文信息。在这个“高起点”上,Backbone进行第二次特征提取,生成质量更高、语义更丰富的特征图。
- 最终输出:这些被深度精炼过的特征图,再次送入FPN,产生最终的、用于检测的特征金字塔。
这个过程,就像一个经验丰富的侦探,在初步勘查现场后,带着对全局的理解,回头重新审视每一个细节,从而得出更精准的结论。
1.3 核心机制(2): 可切换空洞卷积 (SAC)
这是DetectoRS在微观层面(算子层面)的创新。为了让Backbone能更好地处理RFP反馈回来的高级特征,DetectoRS设计了SAC。
- 动态感受野:SAC可以让卷积层自适应地在不同的空洞率(即不同的感受野大小)之间进行选择。它通过一个简单的注意力机制,根据输入特征来决定当前位置最适合用哪种空洞率的卷积进行处理。
- 软切换:这种选择是一种“软切换”,即最终的输出是不同空洞率卷积结果的加权平均。
SAC赋予了Backbone动态调整其观察尺度的能力,使其在处理RFP带来的复杂特征时更加游刃有余。
1.4 DetectoRS的启示:性能巅峰的代价
DetectoRS通过这种极致的双重递归和动态算子设计,在COCO等多个榜单上取得了当时SOTA的惊人成绩。它雄辩地证明了,通过增加模型的计算深度和迭代次数,可以显著提升检测性能。
然而,这种强大性能的背后,是巨大的计算开销。整个模型几乎需要前传两次,训练和推理的成本都非常高昂。这让我们不禁思考:
有没有一种方法,既能实现跨越层级的、长距离的信息交互,又能将计算成本控制在更合理的范围内呢?
带着这个问题,我们迎来了今天的主角——GiraffeDet。它将用一种截然不同的、更具“巧思”的方式,来回答这个挑战。
🌟 二、今日主角:GiraffeDet (长颈鹿检测器)
欢迎来到本期的核心殿堂!今天,我们要深入探索的GiraffeDet,是一个在思想上与DetectoRS殊途同归,但在实现上却另辟蹊径的优雅设计。它的名字——“长颈鹿”,生动地描绘了其核心能力:像长颈鹿伸长脖子一样,轻松地跨越障碍,看到远方,建立起特征金字塔中遥远层级之间的直接联系。
2.1 FPN的“近视”问题:信息传递的“短板”
自FPN问世以来,它通过“自顶向下”的路径,让高层语义信息得以流向底层。然而,这个过程是逐级、间接的。
想象一下,位于最底层C2(或P2)的特征,它富含最精细的边缘和纹理细节。如果它想与位于最顶层C5(或P5)的、代表“这是一辆汽车”的全局语义信息进行一次“深度对话”,信息需要走过一条多么漫长的道路:C2 -> ... -> C5 -> P5 -> P4 -> P3 -> P2
信息在这一长串的上采样、下采样、卷积和相加过程中,不可避免地会发生稀释和失真。这就好比一个传话游戏,话传到最后,可能已经不是原来的意思了。
这种长距离依赖建模 (Long-Range Dependency Modeling) 的低效,是所有基于局部连接(如卷积)和逐级传递的FPN类架构共同面临的“近视”问题。它们能看清邻近层级的信息,但很难一步到位地、清晰地看到遥远层级的信息。
2.2 GiraffeDet的灵感:“长颈”的意义在于看得更远
如何解决“近视”问题?最直接的办法,就是建立一条信息高速公路,让C2和C5可以“打电话”,而不是“寄平信”。
- DetectoRS的方案:通过RFP,让整个Backbone和Neck再走一遍,相当于让信使“坐飞机”跑了一个大圈,虽然最终送达了,但成本高昂。
- FPT (Feature Pyramid Transformer)的方案:用Transformer的全局自注意力机制,将所有层级的特征“拉到一个会议室”,让大家自由讨论。这相当于建立了一个“视频会议系统”,效果很好,但对“带宽”(计算资源)的要求也很高。
GiraffeDet则提出了一个更具性价比的方案。它认为,网络中的信息交互需求是异构的:
- 大部分信息交互是局部的:邻近层级之间的特征融合需求,是最频繁也是最基础的。
- 小部分关键信息交互是全局的:跨越遥远层级的长距离依赖,虽然不是每时每刻都需要,但对于理解复杂场景和大目标至关重要。
基于这个洞察,GiraffeDet的灵感油然而生:我们何不设计一个双轨制的系统呢?
2.3 核心思想:轻重结合,局部与全局的“双轨制”
GiraffeDet的核心思想是构建一个并行的、异构的Neck架构:
- 一条轻量级、FPN-like的“快速通道”:专门负责处理局部的、邻近层级的特征融合。这条路径追求速度和效率,结构可以非常简单,甚至就是一个基础的FPN。
- 一条重量级、全局连接的“长颈通道” (G-FPN):专门负责处理全局的、跨越所有层级的长距离信息交互。这条路径的核心是一个高效的全局注意力模块,它将所有层级的特征汇集起来,进行一次全局上下文建模,然后再将“吸收了全局视野”的信息分发回各个层级。
最后,将这两条路径的输出进行融合,得到最终的特征金字塔。
这个设计就像一个高效的物流系统:
- 同城快递(轻量级路径):使用摩托车,快速处理大量的、短途的包裹。
- 跨国空运(重量级路径):使用货机,专门处理少数的、需要长途运输的重要包裹。
通过这种“轻重结合”的“双轨制”,GiraffeDet在保证了强大的长距离依赖建模能力的同时,将昂贵的全局计算控制在了一个合理的范围内,实现了在性能和效率之间的精妙平衡。
🚀 三、GiraffeDet架构深度解析:构建信息高速公路
理解了GiraffeDet“双轨制”的核心思想后,让我们深入其架构的每一个角落,看看这条信息高速公路是如何铺设的。
3.1 异构双轨宏观架构
GiraffeDet Neck的起点是来自Backbone的一系列特征图,例如{C2, C3, C4, C5}。与传统Neck不同,这些特征图会被同时送入两个并行的处理路径。
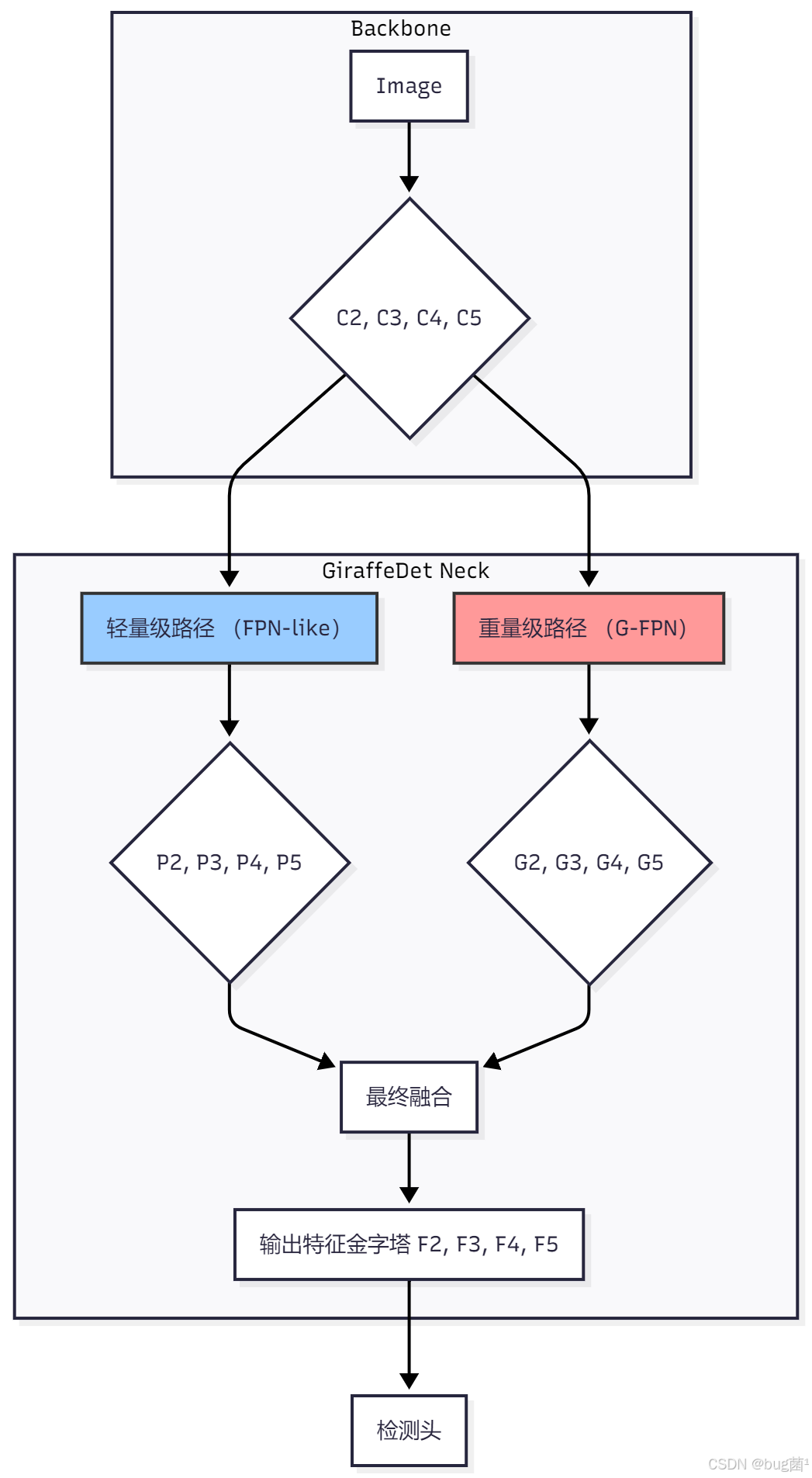
这个图清晰地展示了其并行、异构的设计哲学。接下来,我们将分别深入两条路径的内部。
3.2 轻量级路径:FPN的“快速通道”
这条路径的目标是“快”和“高效”。它负责完成大部分基础的、局部的特征融合任务。
其结构可以非常灵活,通常是一个简化版的FPN或PANet。例如,可以只包含:
- 横向连接:用
1x1卷积统一输入特征{C_i}的通道数。 - 自顶向下路径:通过上采样和逐元素相加,将高层语义信息传递下来。
- 输出卷积:用
3x3卷积对融合后的特征进行平滑处理。
这条路径的设计重点是减少层数和计算量,因为它假设更复杂的、全局的交互任务将由重量级路径来完成。
3.3 重量级路径:G-FPN的“全局视野”
这是GiraffeDet的“长颈”所在,也是其创新的核心。G-FPN (Generalized-FPN) 的目标是打破层级壁垒,实现所有特征之间的“点对点”直接通信。
它的工作流程可以分为三步:收集 -> 全局处理 -> 分发。
-
收集 (Collect):
- 统一维度:首先,使用
1x1卷积将所有输入的特征图{C2, C3, C4, C5}投影到相同的、较低的通道维度d。 - 展平与拼接:然后,将每一张二维的特征图
H_i x W_i x d展平(Flatten)成一个一维的Token序列,长度为H_i * W_i,将所有层级的Token序列拼接(Concatenate)在一起,形成一个包含了所有尺度、所有空间位置信息的“超级序列”。
- 统一维度:首先,使用
-
全局处理 (Process):
- 将这个超级序列输入到一个高效全局注意力模块中。在这个模块里,来自
C2的一个像素Token,可以直接与来自C5的一个像素Token计算注意力得分,并交换信息。这是实现长距离依赖建模的关键。
- 将这个超级序列输入到一个高效全局注意力模块中。在这个模块里,来自
-
分发 (Distribute):
- 切分与重塑:将经过全局处理后、信息得到增强的超级序列,按照原始的空间尺寸切分开,并重塑(Reshape)回
{G2, G3, G4, G5}这几张二维的特征图。
- 切分与重塑:将经过全局处理后、信息得到增强的超级序列,按照原始的空间尺寸切分开,并重塑(Reshape)回
这个过程,与我们之前讲过的FPT非常相似,但GiraffeDet在全局注意力模块的设计上,做了一些效率上的优化。
3.4 G-FPN核心:高效全局注意力机制
标准的全局自注意力(如Transformer中)计算复杂度是序列长度N的平方,即O(N^2)。当把所有特征图展平后,N会变得巨大,计算开销难以承受。
GiraffeDet采用了一种简化的、类似查询-内容 (Query-Content) 的注意力机制来降低复杂度。其核心思想是:
- 稀疏采样Key和Value:不使用序列中的所有Token来生成
Key (K)和Value (V)矩阵,而是从超级序列中进行稀疏采样(例如,通过一个固定步长的采样或可学习的采样),得到一个数量少得多的K和V。这极大地减小了后续计算的矩阵大小。 - 全量Query:
Query (Q)矩阵则由完整的、未经采样的超级序列生成。 - 计算注意力:用完整的
Q去和稀疏的K计算注意力得分,然后用这个得分去加权求和稀疏的V。
数学上,如果原始序列长度为N,采样后的序列长度为M(M << N),那么计算复杂度就从O(^2)降低到了O(N * M),这是一个巨大的优化。
这个机制可以理解为:让每一个像素点(Query)都去咨询一组“全局信息代表”(稀疏的Key/Value),而不是去和每一个其他像素点都单独“聊天”。
3.5 信息融合:双轨并行的终点
在两条路径都完成各自的处理后,我们会得到两组特征金字塔:
- 来自轻量级路径的、富含局部信息的
{P2, P3, P4, P5}。 - 来自重量级路径的、富含全局上下文的
{G2, G3, G4, G5}。
最后一步,就是将这两组特征进行逐层融合。最简单的融合方式就是逐元素相加:
F_i = P_i + G_i
得到的{F2, F3, F4, F5}就是GiraffeDet Neck最终的输出,它既包含了通过“快速通道”高效处理的局部细节,也包含了通过“长颈”获取的全局视野,兼具二者之长。
💻 四、GiraffeDet代码实战:用PyTorch优雅地“伸长脖子”
理论的翅膀已经展开,现在让我们用代码的双手来赋予它生命!我们将用PyTorch一步步构建GiraffeDet Neck,重点是实现其核心的G-FPN模块。
4.1 核心组件:Generalized-FPN (G-FPN) 模块实现
G-FPN是重量级路径的核心,我们先来实现它。这里我们将实现一个简化的、但思想一致的全局注意力机制。
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List
class GFPN_Module(nn.Module):
"""
GiraffeDet的核心组件:广义特征金字塔网络 (G-FPN) 模块。
它负责实现长距离、跨尺度的特征交互。
"""
def __init__(self, in_channels_list: List[int], out_channels: int,
attention_channels: int, key_sampling_rate: int = 4):
"""
初始化G-FPN模块。
参数:
in_channels_list (List[int]): 输入特征图的通道数列表, e.g., [256, 512, 1024, 2048]
out_channels (int): G-FPN输出所有层级特征图的统一通道数
attention_channels (int): 注意力机制内部的工作维度 (Q, K, V的维度)
key_sampling_rate (int): 对Key和Value进行下采样的比率,用于降低计算量
"""
super().__init__()
self.out_channels = out_channels
self.key_sampling_rate = key_sampling_rate
# 1. 输入投影层:将不同通道数的输入特征图统一到 out_channels 维度
self.input_projs = nn.ModuleList([
nn.Conv2d(in_channels, out_channels, kernel_size=1) for in_channels in in_channels_list
])
# 2. Q, K, V 的生成器 (线性层)
self.query_proj = nn.Linear(out_channels, attention_channels)
self.key_proj = nn.Linear(out_channels, attention_channels)
self.value_proj = nn.Linear(out_channels, attention_channels)
# 3. 输出投影层:将注意力结果映射回 out_channels 维度
self.output_proj = nn.Linear(attention_channels, out_channels)
# 归一化因子
self.scale = attention_channels ** -0.5
def forward(self, features: List[torch.Tensor]) -> List[torch.Tensor]:
# --- 步骤1: 收集、展平、拼接 (Collect, Flatten, Concat) ---
bs = features[0].shape[0]
# 记录每个层级的原始空间尺寸,用于后续重塑
spatial_shapes = [feat.shape[2:] for feat in features]
# 投影并展平
projected_feats = [proj(feat).flatten(2).transpose(1, 2) for proj, feat in zip(self.input_projs, features)]
# 拼接成一个超级序列
all_tokens = torch.cat(projected_feats, dim=1) # (bs, N_total, C)
# --- 步骤2: 高效全局注意力 ---
# 2a. 生成全量的 Query
query = self.query_proj(all_tokens) # (bs, N_total, attn_C)
# 2b. 对Key和Value进行稀疏采样
# 这里使用简单的步长采样来模拟
sampled_tokens = all_tokens[:, ::self.key_sampling_rate, :]
key = self.key_proj(sampled_tokens) # (bs, N_sampled, attn_C)
value = self.value_proj(sampled_tokens) # (bs, N_sampled, attn_C)
# 2c. 计算注意力
# (bs, N_total, attn_C) @ (bs, attn_C, N_sampled) -> (bs, N_total, N_sampled)
attn_scores = torch.matmul(query, key.transpose(-2, -1)) * self.scale
attn_probs = F.softmax(attn_scores, dim=-1)
# (bs, N_total, N_sampled) @ (bs, N_sampled, attn_C) -> (bs, N_total, attn_C)
attn_output = torch.matmul(attn_probs, value)
# 2d. 最终的特征增强
# 加上残差连接,并进行输出投影
enhanced_tokens = all_tokens + self.output_proj(attn_output)
# --- 步骤3: 分发与重塑 (Distribute, Reshape) ---
output_features = []
start_idx = 0
for h, w in spatial_shapes:
num_tokens = h * w
# 切分
level_tokens = enhanced_tokens[:, start_idx : start_idx + num_tokens]
start_idx += num_tokens
# 重塑: (bs, H*W, C) -> (bs, C, H, W)
level_feat = level_tokens.transpose(1, 2).reshape(bs, self.out_channels, h, w)
output_features.append(level_feat)
return output_features
代码解析:
-
__init__:input_projs:1x1卷积列表,负责将输入的{C_i}统一到out_channels。query_proj,key_proj,value_proj:nn.Linear层,用于从Token特征生成Q, K, V向量。output_proj: 另一个nn.Linear层,用于将注意力模块的输出维度还原,并与原始Token进行残差连接。
-
forward:-
收集阶段:代码清晰地展示了如何将多层特征图
features经过投影、展平(flatten)、转置(transpose)、拼接(cat),最终得到超级序列all_tokens。 -
注意力阶段:
query = self.query_proj(all_tokens),Query是全量的。sampled_tokens = all_tokens[:, ::self.key_sampling_rate, :],这是实现稀疏采样的关键,我们用Python的切片语法,每隔key_sampling_rate个Token取一个,极大地减少了key和value的数量。- 后续的
torch.matmul和softmax是标准的注意力计算流程,但由于K和V的维度大大减小,计算效率很高。 enhanced_tokens = all_tokens + self.output_proj(attn_output)实现了一个重要的残差连接,保证了信息的稳定传递。
-
分发阶段:这是收集阶段的逆过程。我们根据之前保存的
spatial_shapes,精确地从enhanced_tokens中切分出属于每个层级的部分,并通过transpose和reshape恢复成二维特征图的形状。
-
4.2 轻重结合:GiraffeDet Neck整体架构搭建
现在,我们将G-FPN模块和一条轻量级的FPN路径组合起来,构建完整的GiraffeDet Neck。
# 复用上一篇的BasicFPN作为轻量级路径
class BasicFPN(nn.Module):
# (代码与第94篇中的BasicFPN完全相同,此处为简洁省略,实际使用时需包含该类定义)
# ...
def __init__(self, in_channels_list: List[int], out_channels: int):
super().__init__()
self.lateral_convs = nn.ModuleList([nn.Conv2d(c, out_channels, 1) for c in in_channels_list])
self.fpn_convs = nn.ModuleList([nn.Conv2d(out_channels, out_channels, 3, padding=1) for _ in in_channels_list])
def forward(self, inputs: List[torch.Tensor]) -> List[torch.Tensor]:
laterals = [lat_conv(inputs[i]) for i, lat_conv in enumerate(self.lateral_convs)]
for i in range(len(laterals) - 1, 0, -1):
prev_shape = laterals[i-1].shape[2:]
laterals[i-1] = laterals[i-1] + F.interpolate(laterals[i], size=prev_shape, mode='nearest')
outputs = [self.fpn_convs[i](laterals[i]) for i in range(len(laterals))]
return outputs
class GiraffeDetNeck(nn.Module):
"""
GiraffeDet Neck的完整实现,包含并行的轻量级路径和重量级G-FPN路径。
"""
def __init__(self, in_channels_list: List[int], out_channels: int,
attention_channels: int, key_sampling_rate: int = 4):
super().__init__()
# 1. 轻量级路径 (Lightweight Path)
self.lightweight_fpn = BasicFPN(in_channels_list, out_channels)
# 2. 重量级路径 (Heavyweight Path)
self.heavyweight_gfpn = GFPN_Module(
in_channels_list=in_channels_list,
out_channels=out_channels,
attention_channels=attention_channels,
key_sampling_rate=key_sampling_rate
)
def forward(self, features: List[torch.Tensor]) -> List[torch.Tensor]:
"""
前向传播,并行处理两条路径并融合。
参数:
features (List[torch.Tensor]): 来自骨干网络的特征列表, e.g., [C2, C3, C4, C5]
返回:
List[torch.Tensor]: 最终融合后的特征金字塔列表
"""
# 1. 数据同时进入两条路径
lightweight_output = self.lightweight_fpn(features) # [P2, P3, P4, P5]
heavyweight_output = self.heavyweight_gfpn(features) # [G2, G3, G4, G5]
# 2. 逐层融合输出
final_output = []
for p_feat, g_feat in zip(lightweight_output, heavyweight_output):
final_output.append(p_feat + g_feat) # 逐元素相加
return final_output
代码解析:
-
__init__:结构清晰地体现了双轨制思想。我们实例化了一个BasicFPN作为轻量级路径,一个GFPN_Module作为重量级路径。 -
forward:lightweight_output = self.lightweight_fpn(features)和heavyweight_output = self.heavyweight_gfpn(features)这两行代码完美地展示了并行处理的模式。- 最后的循环使用
zip将两条路径的输出p_feat和g_feat配对,并简单地通过+号进行融合。
4.3 完整使用示例与解析
最后,我们来测试一下整个GiraffeDetNeck。
if __name__ == '__main__':
# --- 1. 定义模型配置 ---
# 假设Backbone输出C2, C3, C4, C5
backbone_channels = [256, 512, 1024, 2048]
neck_out_channels = 256 # Neck所有输出层的统一通道数
attention_channels = 128 # 注意力机制的内部维度
key_sampling_rate = 4 # K, V的采样率
# --- 2. 实例化GiraffeDet Neck ---
giraffe_neck = GiraffeDetNeck(
in_channels_list=backbone_channels,
out_channels=neck_out_channels,
attention_channels=attention_channels,
key_sampling_rate=key_sampling_rate
)
giraffe_neck.eval()
print("--- GiraffeDet Neck 实例化成功!---")
# print(giraffe_neck)
# --- 3. 模拟输入 ---
print("\n--- 模拟输入 ---")
bs = 2
# 假设输入图像 640x640, C2~C5 分辨率依次减半
c2 = torch.randn(bs, backbone_channels[0], 160, 160)
c3 = torch.randn(bs, backbone_channels[1], 80, 80)
c4 = torch.randn(bs, backbone_channels[2], 40, 40)
c5 = torch.randn(bs, backbone_channels[3], 20, 20)
dummy_inputs = [c2, c3, c4, c5]
# --- 4. 前向传播测试 ---
with torch.no_grad():
output_features = giraffe_neck(dummy_inputs)
# --- 5. 验证输出 ---
print("\n--- 验证输出 ---")
assert isinstance(output_features, list) and len(output_features) == len(dummy_inputs)
print("GiraffeDet Neck 输出特征图尺寸:")
for i, out_feat in enumerate(output_features):
print(f" F{i+2} 尺寸: {out_feat.shape}")
# 验证输出通道数和空间尺寸
assert out_feat.shape[1] == neck_out_channels
assert out_feat.shape[2:] == dummy_inputs[i].shape[2:]
print("\n✅ 所有测试通过!GiraffeDet Neck 正常工作!")
代码与结果解析:
- 我们成功地实例化了
GiraffeDetNeck,并传入了4个不同分辨率的模拟输入。 - 前向传播后,我们得到了一个包含4个特征图的列表,代表了最终融合后的
{F2, F3, F4, F5}。 - 验证代码显示,所有输出特征图的通道数都被统一到了
neck_out_channels(256),并且它们的空间分辨率与输入的{C2, C3, C4, C5}一一对应。这证明我们的双轨并行Neck完美地工作了!
⚖️ 五、性能与效率:GiraffeDet的平衡艺术
GiraffeDet的设计充满了智慧的权衡。它既不像FPN那样“目光短浅”,也不像DetectoRS或FPT那样“不计成本”。它在性能和效率之间走出了一条独特的道路。
5.1 性能优势:长距离依赖建模的力量
GiraffeDet最核心的性能优势,来自于其强大的长距离依赖建模能力。
- 改善大目标检测:对于尺寸巨大的物体,其不同部位可能分布在特征图的遥远两端。G-FPN的全局注意力机制可以轻易地将这些部位的特征关联起来,形成对物体的整体认知,从而提高检测和分割的完整性。
- 利用全局上下文:当识别一个被遮挡或模糊的物体时,其周围的上下文信息至关重要。G-FPN能够让该物体的特征“看到”整个场景的上下文,从而做出更准确的推断。例如,在拥挤的街道场景中,一个只露出部分轮廓的物体,可以借助周围“道路”、“建筑”等全局信息,被更准确地识别为“汽车”。
- 优化小目标检测:虽然全局注意力通常被认为对大目标更友好,但它同样可以惠及小目标。G-FPN可以将来自高层的、强烈的语义信息(如“天空”),直接、无损地传递给底层特征图上一个可能是“风筝”的小目标区域,为其提供强有力的分类依据。
5.2 效率分析:“准单阶段”的代价与收益
GiraffeDet的计算复杂度介于传统的FPN和完全基于Transformer的FPT之间。
-
代价:
- 相比于纯粹的轻量级FPN/PANet,GiraffeDet增加了一条重量级的G-FPN路径,其计算量和参数量都显著增加。
- 全局注意力机制(即便是稀疏的)的计算开销,仍然比卷积要大得多,尤其是在处理高分辨率输入时,Token总数
N会很大。
-
收益:
- 性价比高:它通过稀疏采样和双轨制,将最昂贵的全局计算的范围控制得很好。大部分特征处理由高效的轻量级路径完成。因此,它以远低于DetectoRS或FPT的计算成本,实现了接近甚至超越它们的性能。
- 可扩展性:GiraffeDet的设计非常灵活。我们可以通过调整
attention_channels和key_sampling_rate等超参数,来方便地在性能和效率之间进行权衡,以适应不同硬件资源和任务需求。
5.3 与FPT、DetectoRS的对比:殊途同归
这三者都致力于解决长距离依赖问题,但路径截然不同:
- DetectoRS (迭代精炼):通过时间(计算步骤)的重复来增强信息交互。它让信息在固定的(但可切换的)Backbone和Neck结构中“多跑几圈”。
- FPT (全局通信):通过Transformer的全局连接来增强信息交互。它用一个强大的Transformer,在一次前向传播中,让所有Token自由“对话”。
- GiraffeDet (混合动力):通过结构的并行与混合来实现。它认为局部和全局通信的需求不同,因此设计了不同的“车道”来分别处理,是一种非常务实和高效的工程思想。
三者殊途同归,都取得了卓越的性能,为我们展示了通往SOTA道路的多样性。
🎓 六、总结与展望
在今天的长颈鹿探索之旅中,我们共同见证了一个充满创造力和工程智慧的杰作。它优雅地解决了FPN的“近视”问题,为特征融合领域带来了新的启示。让我们一同回顾这次旅程的满满收获:
- 我们从回顾“重装猛兽”DetectoRS开始,理解了通过宏观递归来追求性能极限的设计哲学,并由此引出了对更高效率长距离建模的思考。
- 我们深入GiraffeDet的世界,剖析了传统FPN在长距离信息传递上的“短板”,并领会了GiraffeDet“轻重结合、双轨并行”的核心思想。
- 我们深度剖析了GiraffeDet的异构架构,详细拆解了其轻量级的FPN路径和重量级的G-FPN路径,特别是G-FPN内部高效的稀疏全局注意力机制。
- 在激动人心的代码实践中,我们用PyTorch从零开始,先实现了核心的
GFPN_Module,再将其与BasicFPN组合,成功构建并验证了一个完整的GiraffeDetNeck。 - 最后,我们全方位地探讨了GiraffeDet的平衡艺术,分析了它在性能上的巨大优势,以及在计算效率上的聪明权衡,并将其与DetectoRS、FPT等顶尖模型进行了比较。
GiraffeDet教会我们,在面对复杂的系统设计问题时,差异化处理和混合设计是一种极其强大的思想。并非所有问题都需要用最强大的“锤子”去解决,为不同类型的子问题匹配最合适的解决方案,往往能得到最高效、最优雅的系统。为你今天的深度学习和思考点赞!👍
🔔 七、蓄势待发:下期内容预告 (SSD-Lite轻量级多尺度检测)
今天,我们探索了GiraffeDet如何用“巧劲”来平衡性能与效率。在接下来的旅程中,我们将把视线从这些追求SOTA性能的“重量级”或“次重量级”选手,转向一个全新的领域——为移动端和边缘设备设计的极致轻量化检测。
当计算资源被压缩到极致,当每一毫秒的延迟都至关重要时,我们还能构建有效的多尺度检测器吗?答案是肯定的!而其中的经典代表,就是我们下一期的主角——SSD-Lite!
在第20篇中,我们将一起探索:
- SSD的经典思想:回顾经典的一阶段检测器SSD (Single Shot Detector)是如何在没有FPN的时代,直接利用Backbone的多尺度特征图进行检测的。
- “Lite”的奥秘:SSD-Lite是如何通过深度可分离卷积 (Depthwise Separable Convolution) 这一利器,对标准SSD进行“脱胎换骨”的改造,大幅削减其参数量和计算量的?
- 移动端优化:我们将深入探讨针对移动端CPU/GPU特性进行网络结构优化的设计原则。
- 实时检测的魅力:亲手构建一个SSD-Lite,感受它在保持可接受精度的同时,所带来的惊人推理速度。
如果说GiraffeDet是为服务器GPU设计的“跑车”,那么SSD-Lite就是为手机设计的“卡丁车”——小巧、灵活、极致高效。准备好切换赛道,体验速度与激情的另一面了吗?我们下期再会!👋😊
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是计算机视觉、图像识别等领域的讲师 & 技术专家博客作者,笔名bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)