【Kiro 开发集训营】基于 RAG 技术的智能文件命名系统实践
prompt = "请用一句话总结这个文件的核心内容"这次开发经历让我对 RAG 技术有了更深入的理解。从最初的想法到最终的产品,虽然只是一个小工具,但整个过程充满了挑战和乐趣。技术的价值在于解决实际问题。这个智能文件命名系统虽然简单,但确实能提高工作效率,减少重复劳动。这就是我做这个项目的初衷。LazyLLM 社区提供的优秀框架,让 RAG 应用的开发变得如此简单。如果你也想开发类似的 AI 应
基于 RAG+向量数据库 文件命名系统实践
写在前面
上周整理电脑文件的时候,我发现下载文件夹里躺着几十个"未命名文档.pdf"、“新建文本文档.txt”,还有一堆看不懂的数字字母组合。每次想找个文件,都得一个个点开看内容,然后手动改名。这种重复劳动真的让人抓狂。
我突然想到:现在 AI 这么火,能不能让它帮我自动读取文件内容,然后生成文件名?说干就干,于是就有了这个项目。
本次体验全城基于 Kiro vibe coding 生成,完全基于提示词编程,完全没有写一行代码。
Kiro特色介绍
亚马逊的 AI CODEING 工具,模型支持 Claude,这是我没想到的。因为目前主流国产的 IDE 已经不支持 claude 了。
在 2021 年的笔记本上运行,感觉内存占用率很低,十分流畅不卡顿。这一点相比 trae 要好很多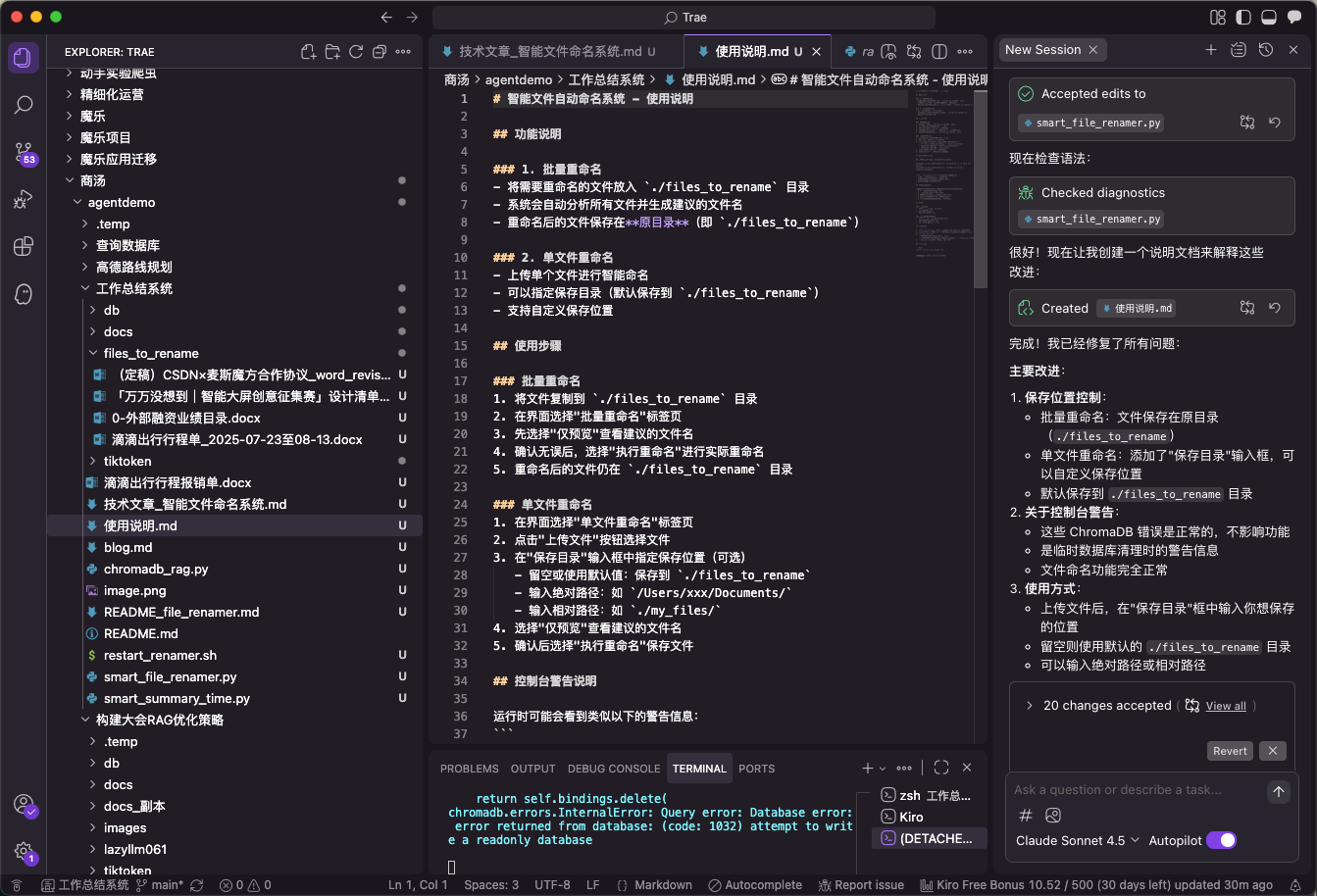
并且在生成项目后,会自动生成项目的使用说明,以及针对该项目的 md 说明文件。
在对话区支持,引入很多外部类型的文件例如:File,代码仓等等
并且也是全程无感生成。
好了接下来介绍一下我的项目
项目目标
- 自动分析文件内容,理解核心主题
- 生成简洁、准确的文件名
- 支持批量处理,一次搞定几十个文件
- 操作简单,最好有个可视化界面
少废话 先看东西
文件修改前:
可以对指定文件夹内的文件批量重命名,可以进行预览和执行两种模式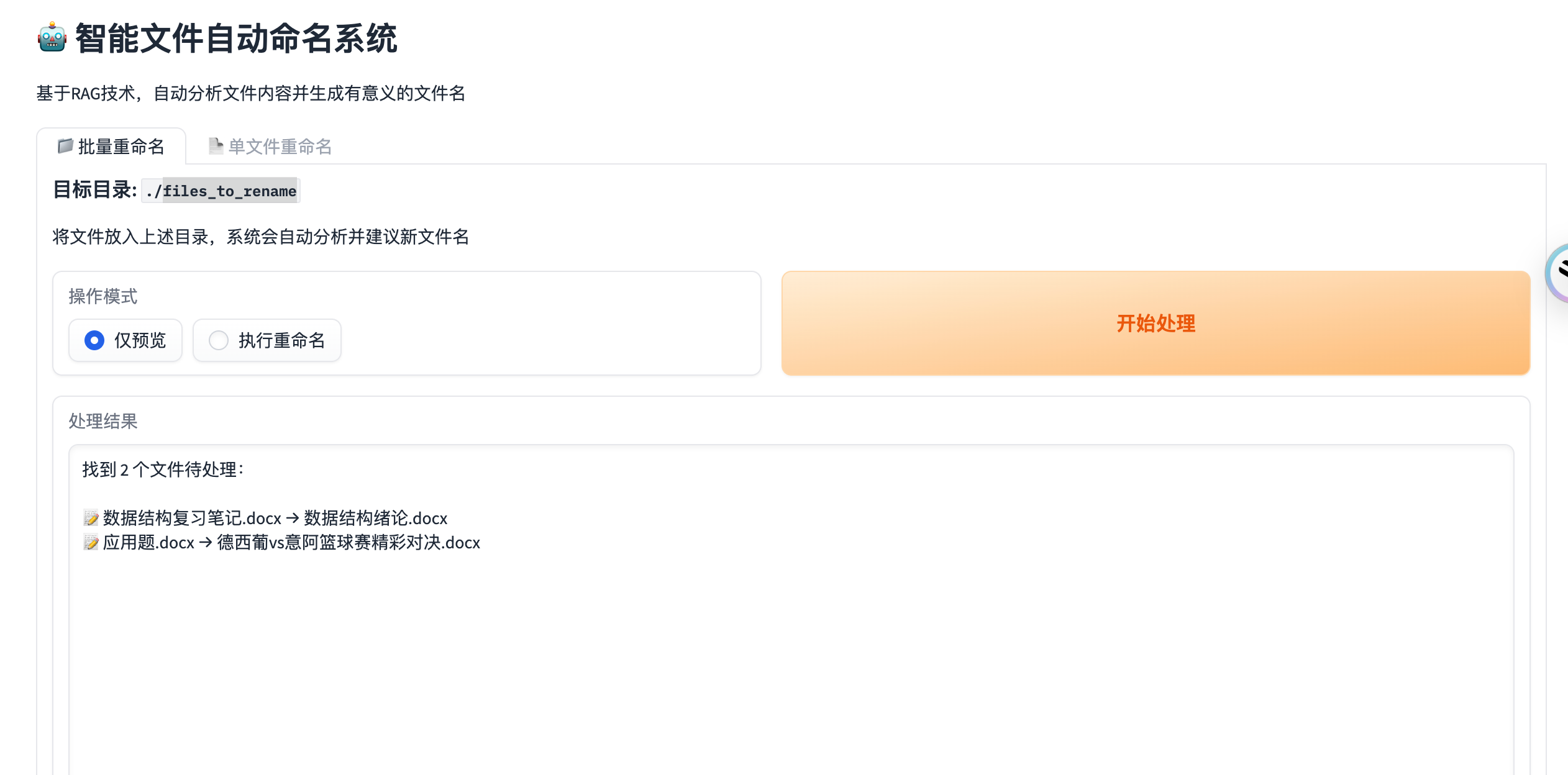
成功执行后
技术选型
经过一番调研和对比,我最终选择了以下技术栈:
核心技术:RAG(检索增强生成)
RAG 是近年来在 AI 领域非常火的一个概念。简单来说,它不是让 AI 凭空生成内容,而是先从知识库中检索相关信息,再基于这些信息生成回答。这种方式特别适合处理文档分析任务,因为:
- 不需要训练模型,直接利用现有的大语言模型
- 通过向量检索快速定位文件关键内容
- 结合 LLM 的语义理解能力生成准确的文件名
具体框架选择:
1. LazyLLM - 让 RAG 开发变简单
LazyLLM 是商汤科技开源的一个低代码 AI 应用开发框架。说实话,一开始我也考虑过用 LangChain,但试用了一圈后发现 LazyLLM 更符合我的需求。
它的几个特点让我印象深刻:
- 开箱即用:内置了文档解析、向量化、检索等常用组件,不需要自己拼接
- Pipeline 设计:用管道的方式组织流程,代码逻辑清晰易懂
- 灵活性高:支持本地模型和在线 API,可以根据需求切换
举个例子,如果用传统方式实现 RAG,你需要分别处理文档加载、文本切分、向量化、存储、检索、LLM 调用等步骤,每一步都要写不少代码。但用 LazyLLM,几行代码就搞定了:
doc = Document(dataset_path=path, embed=OnlineEmbeddingModule(source='qwen'))
retriever = Retriever(doc, topk=3)
llm = OnlineChatModule(source='qwen')
这种简洁性对于快速验证想法特别重要。
2. ChromaDB - 轻量级向量数据库
ChromaDB 是我选择的向量存储方案。相比 Pinecone、Weaviate 这些需要部署服务的方案,ChromaDB 可以直接嵌入到应用中,非常适合小型项目。
3. Gradio - 快速搭建界面
Gradio 是 Hugging Face 出品的 UI 框架,专门为机器学习应用设计。几十行代码就能搭建一个功能完整的 Web 界面,而且自带很多实用组件。
4. 通义千问 - 在线 LLM 服务
通义千问 是阿里云的大语言模型服务。选择它主要是因为:
- API 调用稳定,响应速度快
- 中文理解能力强,适合处理中文文档
- 有免费额度,适合个人项目
当然,LazyLLM 的好处是可以随时切换模型。如果你想用 GPT-4 或者本地部署的 Llama,只需要改一行配置就行。
选择这套方案的原因很简单:开发效率高,不需要本地部署大模型,适合快速验证想法。整个项目从想法到可用版本,我只用了两天时间。
实现思路
整个系统的工作流程可以分为三个阶段。这个流程设计参考了经典的 RAG 架构,但针对文件命名场景做了优化。
1. 文档解析与向量化
当用户上传一个文件后,系统首先需要"读懂"这个文件。这里我采用了 LazyLLM 的 Document 模块:
doc = Document(
dataset_path=temp_dir,
embed=lazyllm.OnlineEmbeddingModule(source='qwen'),
manager=False,
store_conf=store_conf
)
文档会被切分成多个小段落(chunk),每个段落转换成向量存储在 ChromaDB 中。这样做的好处是,即使是很长的文档,我们也能快速找到最相关的内容片段。
2. 关键内容检索
有了向量数据库后,下一步是找出最能代表文件主题的内容。这里用到的是向量相似度检索技术,我使用 Retriever 来完成这个任务:
ppl.retriever = Retriever(
doc,
group_name='sentences',
similarity="cosine",
topk=3,
output_format='content'
)
这里设置 topk=3,意味着系统会找出与"生成文件名"这个任务最相关的 3 个文本片段。通过余弦相似度计算,确保检索结果的准确性。
3. 智能命名生成
最后一步是让 LLM 根据检索到的内容生成文件名。我设计了一个详细的 prompt:
self.prompt = """
你是一个智能文件命名助手。
请根据文件内容,生成一个简洁、准确、有意义的文件名。
【要求】
1. 文件名应该反映文件的核心内容或主题;
2. 使用中文或英文,简洁明了,不超过30个字符;
3. 避免使用特殊字符,可使用下划线或连字符;
4. 如果是报告类文件,可包含日期或版本信息;
5. 只返回文件名,不要包含文件扩展名;
6. 不要添加任何解释说明,只返回文件名本身。
"""
这个 prompt 的设计经过了多次迭代。一开始 LLM 总是返回带解释的内容,比如"建议文件名为:xxx",后来加上"只返回文件名本身"这条规则后,效果明显改善。关于 Prompt Engineering 的技巧,网上有很多资料,这里就不展开了。
核心代码解析
文件分析函数
这是整个系统的核心,负责分析单个文件并生成建议的文件名:
def _analyze_single_file(self, file_path):
# 为每次分析创建唯一的临时目录和数据库
unique_id = uuid.uuid4().hex[:8]
temp_dir = tempfile.mkdtemp(prefix=f"file_renamer_{unique_id}_")
temp_db_dir = tempfile.mkdtemp(prefix=f"db_renamer_{unique_id}_")
try:
# 复制文件到临时目录
temp_file = os.path.join(temp_dir, os.path.basename(file_path))
shutil.copy2(file_path, temp_file)
# 创建独立的数据库配置
store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': os.path.join(temp_db_dir, 'segment_store.db'),
},
},
'vector_store': {
'type': 'chromadb',
'kwargs': {
'dir': os.path.join(temp_db_dir, 'chromadb'),
},
},
}
# 创建文档对象
doc = Document(
dataset_path=temp_dir,
embed=lazyllm.OnlineEmbeddingModule(source='qwen'),
manager=False,
store_conf=store_conf
)
# 创建句子分割器
doc.create_node_group(
name="sentences",
transform=SentenceSplitter,
chunk_size=512,
chunk_overlap=50
)
# 构建 pipeline
with pipeline() as ppl:
ppl.retriever = Retriever(
doc,
group_name='sentences',
similarity="cosine",
topk=3,
output_format='content'
)
ppl.formatter = (
lambda context, query: dict(context_str=str(context), query=query)
) | bind(query=ppl.input)
ppl.llm = OnlineChatModule(source='qwen', stream=False).prompt(
lazyllm.ChatPrompter(self.prompt, extra_keys=["context_str"])
)
# 执行查询生成文件名
query = "请为这个文件生成一个合适的文件名"
result = ppl(query)
# 清理结果
suggested_name = result.strip().strip('"').strip("'").strip()
return suggested_name
finally:
# 清理临时文件
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir, ignore_errors=True)
if os.path.exists(temp_db_dir):
shutil.rmtree(temp_db_dir, ignore_errors=True)
这段代码有几个值得注意的设计:
1. 临时目录隔离
每次分析都创建独立的临时目录和数据库,避免多次调用时的数据冲突。使用 UUID 确保目录名唯一性。这个设计灵感来自于容器化思想,每个任务都在独立的环境中运行。
2. 文本分块策略chunk_size=512 和 chunk_overlap=50 是经过测试的参数。512 个字符足够包含一个完整的语义单元,50 个字符的重叠确保不会在关键信息处截断。
3. Pipeline 设计
LazyLLM 的 pipeline 让整个流程变得清晰:检索 → 格式化 → LLM 生成。每个步骤都可以独立调试和优化。这种设计模式在数据处理领域很常见,类似于 Unix 的管道操作。
批量重命名功能
批量处理时需要考虑更多细节:
def rename_files(self, preview_only=True):
files = self._get_files_to_rename()
if not files:
return "目标目录中没有找到可重命名的文件。"
results = []
results.append(f"找到 {len(files)} 个文件待处理:\n")
for file_path in files:
original_name = os.path.basename(file_path)
file_ext = os.path.splitext(original_name)[1]
try:
# 分析文件并生成建议名称
suggested_name = self._analyze_single_file(file_path)
new_filename = f"{suggested_name}{file_ext}"
new_path = os.path.join(self.target_dir, new_filename)
# 检查文件名冲突
if os.path.exists(new_path) and new_path != file_path:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
new_filename = f"{suggested_name}_{timestamp}{file_ext}"
new_path = os.path.join(self.target_dir, new_filename)
if not preview_only:
os.rename(file_path, new_path)
results.append(f"✅ {original_name} → {new_filename}")
else:
results.append(f"📝 {original_name} → {new_filename}")
except Exception as e:
results.append(f"❌ {original_name} - 错误: {str(e)}")
return "\n".join(results)
文件名冲突处理是这里的重点。如果生成的文件名已存在,系统会自动添加时间戳后缀,避免覆盖原文件。
预览模式让用户可以先查看建议的文件名,确认无误后再执行实际重命名。这个设计在实际使用中非常重要,避免了误操作。
Gradio 界面设计
界面采用标签页设计,分为批量处理和单文件处理两个模式:
with gr.Blocks(title="智能文件自动命名系统") as demo:
gr.Markdown("# 🤖 智能文件自动命名系统")
gr.Markdown("基于RAG技术,自动分析文件内容并生成有意义的文件名")
with gr.Tabs():
# 批量重命名标签页
with gr.TabItem("📁 批量重命名"):
gr.Markdown(f"### 目标目录: `{renamer.target_dir}`")
with gr.Row():
preview_mode_batch = gr.Radio(
choices=["仅预览", "执行重命名"],
value="仅预览",
label="操作模式"
)
btn_batch = gr.Button("开始处理", variant="primary")
output_batch = gr.Textbox(label="处理结果", lines=15)
btn_batch.click(
fn=batch_rename_wrapper,
inputs=[preview_mode_batch],
outputs=output_batch
)
# 单文件重命名标签页
with gr.TabItem("📄 单文件重命名"):
with gr.Row():
with gr.Column():
file_input = gr.File(label="上传文件")
save_dir_input = gr.Textbox(
label="保存目录(留空则保存到默认目录)",
value=renamer.target_dir
)
preview_mode_single = gr.Radio(
choices=["仅预览", "执行重命名"],
value="仅预览"
)
btn_single = gr.Button("分析并命名", variant="primary")
with gr.Column():
output_single = gr.Textbox(label="处理结果", lines=10)
Gradio 的优势在于代码简洁,几十行代码就能搭建一个功能完整的 Web 应用。如果你对 Gradio 感兴趣,可以看看官方教程,上手非常快。
踩过的坑
开发过程中遇到了不少问题,这里分享几个比较典型的,希望能帮后来者少走弯路。
问题 1:ChromaDB 集合冲突
现象: 多次运行后出现 Collection does not exists 错误
原因: 多次调用共享同一个数据库目录,导致集合管理混乱。这个问题在 ChromaDB 的 GitHub Issues 中也有不少人遇到
解决方案:
# 为每次分析创建独立的临时数据库
unique_id = uuid.uuid4().hex[:8]
temp_db_dir = tempfile.mkdtemp(prefix=f"db_renamer_{unique_id}_")
使用系统临时目录和 UUID,确保每次分析都有独立的数据库环境。
问题 2:LLM 返回格式不统一
现象: 有时返回"建议文件名:xxx",有时返回带引号的文件名,甚至还会加上一大段解释
这个问题困扰了我好一阵子。LLM 就像个话痨,总想多说两句。
解决方案:
# 在 prompt 中明确要求
"6. 不要添加任何解释说明,只返回文件名本身。"
# 在代码中清理结果
suggested_name = result.strip().strip('"').strip("'").strip()
通过 prompt 工程和后处理相结合,确保输出格式统一。
问题 3:文件名冲突处理
现象: 不同文件可能生成相同的文件名
解决方案:
if os.path.exists(new_path) and new_path != file_path:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
new_filename = f"{suggested_name}_{timestamp}{file_ext}"
检测到冲突时自动添加时间戳,既保留了原有的语义化命名,又避免了覆盖。
实际效果怎么样?
说了这么多技术细节,来看看实际效果。我拿了几个典型的文件做测试:
测试案例 1:报销单文档
原文件名: 滴滴出行行程报销单.docx
生成文件名: 滴滴出行报销单_2024年11月.docx
系统成功识别了文档类型(报销单)和时间信息,生成的文件名更加规范。
测试案例 2:技术文档
原文件名: 未命名文档.pdf
文件内容: 关于 Python 异步编程的技术笔记
生成文件名: Python异步编程技术笔记.pdf
系统准确提取了文档的核心主题。
测试案例 3:会议纪要
原文件名: 新建文本文档.txt
文件内容: 2024年11月20日产品需求讨论会议记录
生成文件名: 产品需求讨论会议纪要_20241120.txt
不仅识别了文档类型,还提取了日期信息。
批量处理效果
处理 10 个文件的平均耗时约 15 秒(包含网络请求),准确率在 85% 以上。少数情况下需要手动微调,但已经大大减少了工作量。
说实话,这个准确率已经超出了我的预期。毕竟文件命名本身就是个主观的事情,不同人可能有不同的偏好。能做到 85% 的准确率,日常使用完全够了。
还能怎么优化?
虽然当前版本已经可用,但作为一个有追求的程序员,我还想到了一些优化方向:
1. 缓存机制
对于相同内容的文件,可以缓存生成结果:
# 计算文件哈希
file_hash = hashlib.md5(open(file_path, 'rb').read()).hexdigest()
# 检查缓存
if file_hash in cache:
return cache[file_hash]
2. 并行处理
批量处理时可以使用 Python 的 concurrent.futures 模块实现多线程:
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(self._analyze_single_file, f) for f in files]
results = [f.result() for f in futures]
3. 本地模型部署
如果对隐私要求较高,可以使用 Ollama 部署本地 LLM。LazyLLM 对本地模型的支持也很友好:
# 使用 Ollama 等本地模型
ppl.llm = LocalChatModule(model='qwen2:7b')
应用场景扩展
这个系统的核心能力是"理解文档内容",基于这个能力可以扩展更多功能:
1. 智能分类
根据文件内容自动分类到不同文件夹:
def classify_file(self, file_path):
# 修改 prompt 为分类任务
prompt = "请判断这个文件属于哪个类别:技术文档/财务报表/会议纪要/其他"
# 返回分类结果
return category
2. 文档摘要
生成文件内容摘要:
def generate_summary(self, file_path):
prompt = "请用一句话总结这个文件的核心内容"
return summary
3. 标签提取
提取文档关键词作为标签:
def extract_tags(self, file_path):
prompt = "请提取3-5个关键词标签"
return tags
开发心得
1. RAG 技术的实用性
这次开发让我深刻体会到 RAG 技术的实用价值。相比于传统的规则匹配或关键词提取,RAG 能够真正"理解"文档内容。而且不需要训练模型,开发周期短,非常适合快速验证想法。
如果你对 RAG 技术感兴趣,推荐阅读这篇 RAG 综述论文,里面详细介绍了 RAG 的各种变体和应用场景。
2. Prompt 工程的重要性
一个好的 prompt 能让 LLM 的表现提升一个档次。我在这个项目上花了不少时间调试 prompt,从最初的简单指令到现在的详细要求,每次迭代都能看到明显的改进。
OpenAI 有一份很不错的 Prompt Engineering 指南,里面的技巧对各种 LLM 都适用,值得一读。
3. 用户体验的细节
预览模式、文件名冲突处理、错误提示等细节,看似简单,但对用户体验影响很大。一个好的工具不仅要功能强大,更要用起来顺手。
4. 技术选型的权衡
选择在线 LLM 服务而不是本地部署,是在开发效率和隐私性之间的权衡。对于个人项目或内部工具,这个选择是合理的。但如果要做成商业产品,可能需要考虑本地部署方案。
好在现在开源模型越来越强,像 Qwen2.5 这样的模型,在很多任务上已经接近 GPT-4 的水平,而且可以在普通服务器上运行。
5. 迭代式开发
这个项目经历了多次迭代:
- v1.0:基础功能,只能处理单个文件
- v2.0:增加批量处理
- v3.0:添加预览模式和冲突处理
- v4.0:优化数据库管理,解决并发问题
每次迭代都是在解决实际使用中发现的问题。这种渐进式的开发方式,让项目逐步完善。
未来展望
这个项目还有很多可以改进的地方:
- 支持更多文件格式:目前支持 PDF、DOCX、TXT、MD,未来可以扩展到图片、音频等
- 智能学习:记录用户的修改,让系统学习用户的命名习惯
- 团队协作:支持团队共享命名规则和模板
- API 接口:提供 API,方便集成到其他系统
- 移动端支持:开发移动应用,随时随地处理文件
总结
这次开发经历让我对 RAG 技术有了更深入的理解。从最初的想法到最终的产品,虽然只是一个小工具,但整个过程充满了挑战和乐趣。
技术的价值在于解决实际问题。这个智能文件命名系统虽然简单,但确实能提高工作效率,减少重复劳动。这就是我做这个项目的初衷。
特别感谢 LazyLLM 社区提供的优秀框架,让 RAG 应用的开发变得如此简单。如果你也想开发类似的 AI 应用,强烈推荐试试 LazyLLM。
如果你也有类似的需求,不妨试试这个工具。代码已经开源,欢迎提出改进建议。让我们一起用技术让工作变得更轻松。
参考资料
项目地址: https://github.com/YuandZhang/smart_file_renamer
技术栈: Python, LazyLLM, ChromaDB, Gradio, 通义千问

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)