大模型对话模版
各阶段使用的对话模版如下:由于微调框架修改了大模型,故后续都要以微调框架的对话模版为主!!!vllmvllm默认使用大模型自带的对话模版,若要使用自动以的对话模版,需要添加参数。利用现有对话模板,直接配置一个如下的json文件使用。model_name为必填项,可以是LMDeploy内置对话模板名(通过可查阅),也可以是新名字。其他字段可选填。当model_name是内置对话模板名时,json文件
大模型对话模版
一、生成式模型的对话模板
对话模板(prompt template)是用户和大模型进交互或者对话的一种格式化样板。因为模型在训练时候遵循了这套格式,因此为了保持训练和推理一致性,用户在聊天时候也应该严格遵循对话模板。
最有名的对话模板或者说最常用的对话模板应该就是 chatML 格式的对话模板了。如下所示:
[{"role": "system",
"content" : "You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-02"},
{"role": "user",
"content" : "How are you?"},
{"role": "assistant",
"content" : "I am doing well"},
{"role": "user",
"content" : "What is the mission of the company OpenAI?"}]
上面是一个多轮对话的案例。可以发现包括如下元素
role:表示角色,代表当前这个内容是哪一个角色,不同角色有不同作用,角色一共包括 3 种system:表示系统角色,它的作用是给模型设定一些全局的前置条件,例如你设置这个 gpt 为一个翻译助手,那么在后续对话时候就可以实现翻译功能。值得注意的是,该字段在多轮对话中只会出现一次,即在第一轮。当然你也可以不设置系统角色,此时这个字段的content就是空字符user:表示用户角色,也就是你和他对话的输入信息。在多轮对话中这个字段的内容可以输入多次assistant:表示助手角色,实际上就是模型的预测输出
在单轮对话中,只会包括 1 个 system,1 个 user 和 1 个 assistant 内容,在多轮对话中会包括 1 个 system,n 个 user 和 n 个 assistant 内容。
让我们通过一个快速的示例来具体说明:
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
输出结果是:
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
二、模型微调与部署阶段输出不一致
2.1 问题引出
我们使用LlamaFactory微调模型之后,在它的chat界面做对话测试的时候,它的答复是没有问题的,然后用微调后的模型合并后去做部署,结果发现:在LlamaFactory里面测试它的答复是没有问题的,但是把它单独使用vllm或 lmdeploy推理框架部署后,它的回答就不一样了,这其实是对话模板导致的。
不同的框架用的话模板是不一样的,这种对话模板的差异性就导致了模型的答复不一致。
下面是openweb-UI做的一个集成的前端,适合于个人独立开发网站,但企业或者说做项目一般不会用这种东西,因为企业的前端需要做一些定制化的自主开发。
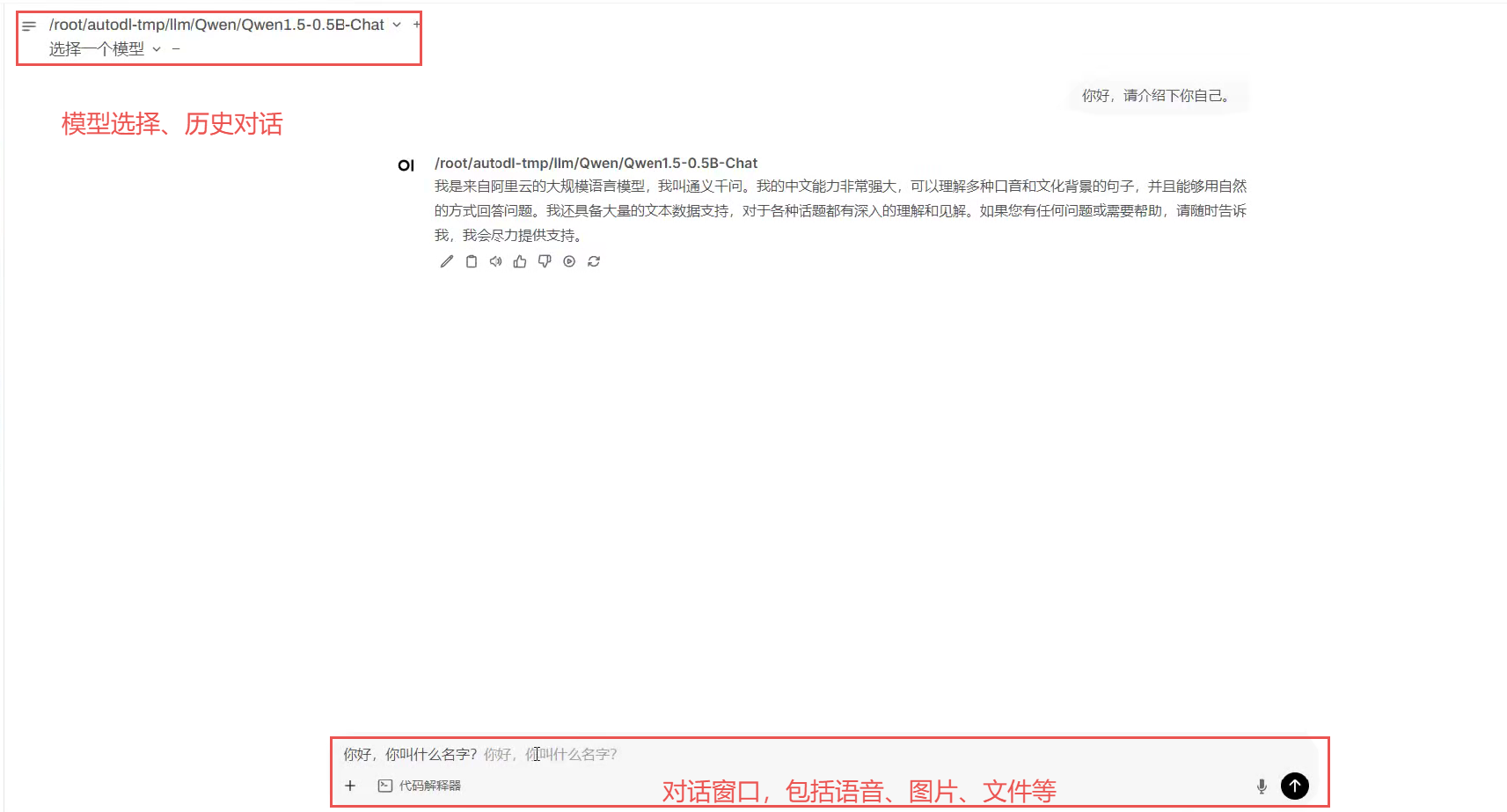
我们用 openweb-UI 作为前端接收用户的数据,然后把用户的数据封装成一个message对象传递给我们的后端。在这个过程中,其实就需要定一个提示词模板(对话模板),用户每次跟 openweb-UI 对话的时候都会有一个对话模版,这是由openweb-UI定义好的,这套模板其实就在规定消息的固定格式。
<im_start>:固定开头<im_end>:固定结尾system:表示系统角色,它的作用是给模型设定一些全局的前置条件user:表示用户角色,也就是用户和他对话的输入信息assistant:就是模型的预测输出history:多轮对话中携带的历史信息
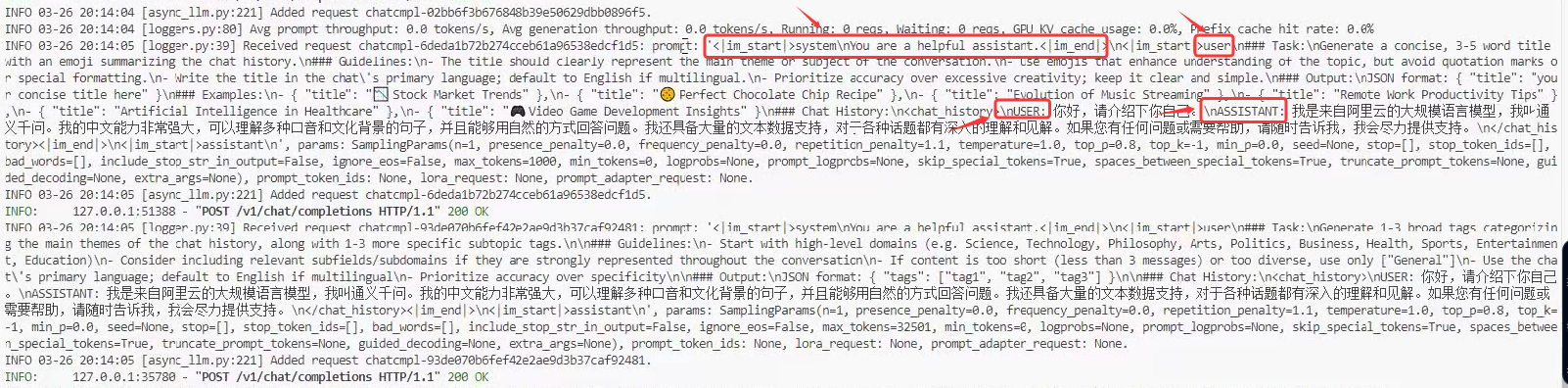
LlamaFactory有一个奇怪的操作:既然微调的是本地大模型,那我直接把本地大模型路径传进去就可以了呀,为什么还要传递对话模版?其实这是告诉 LlamaFactory 限定当前大模型微调训练时所采用的提示词模板,因为不同的对话模板格式不同,它会影响到模型训练时候的数据集的格式。
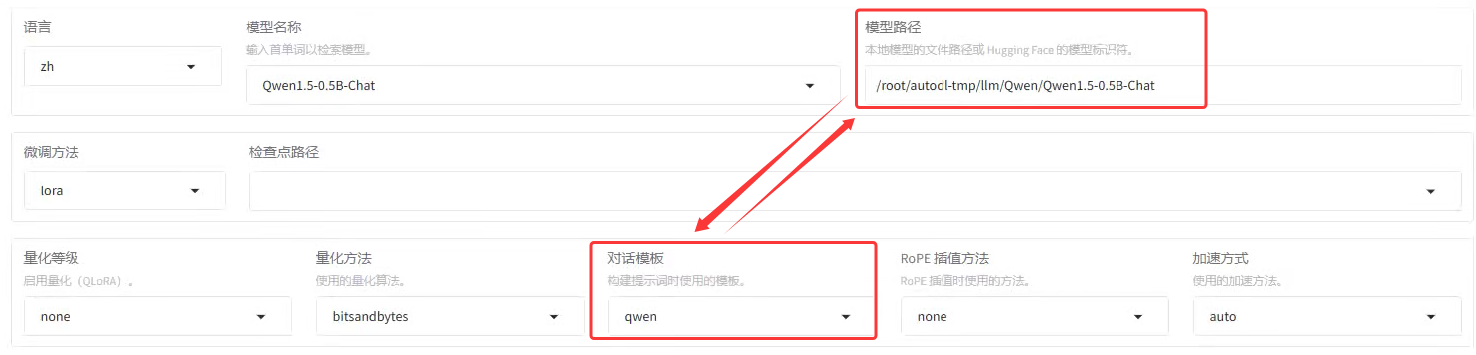
2.2 各阶段的对话模版
目前大模型百花齐放,但是大模型的对话模板没有统一的标准,所以就会导致每个大模型都有自己的对话模版(甚至Qwen-0.5B与3B都不相同)。对话模板一旦发生变化,那么模型输出的内容就会发生变化。如果模型训练时的对话模板与推理时不一致,那模型法输出的内容就会发生变化。
即大模型本身的对话模版、微调框架的对话模版、推理框架(vllm、ollma)的对话模版、前端 openweb-ui 对应的对话模版都有可能不同。这几个框架在推理大模型的时候可能用的提示词模板都不一样,所以就会导致一个问题:LlamaFactory微调后测试没有问题的,但是使用推理框架部署之后效果不一样。
2.2.1 大模型的对话模版
对话模板是由大模型本身提供的,以Qwen-2.5-0.5B-Instruct为例,可以看到 tokenizer_config.json 文件中定义了 chat_template 对话模版:
"bos_token": null,
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
"clean_up_tokenization_spaces": false,
"eos_token": "<|im_end|>",
"errors": "replace",
"model_max_length": 131072,
"pad_token": "<|endoftext|>",
"split_special_tokens": false,
"tokenizer_class": "Qwen2Tokenizer",
"unk_token": null
2.2.2 微调框架的对话模版
LlamaFactory 微调框架用的对话模板是框架中自己定义的,即参考了各个大模型本身的对话模板来定义的。具体在 src/llamafactory/data/template.py 中定义,以qwen模型的对话模版为例:
# copied from qwen template
register_template(
name="mimo",
format_user=StringFormatter(slots=["<|im_start|>user\n{{content}}<|im_end|>\n<|im_start|>assistant\n"]),
format_assistant=StringFormatter(slots=["{{content}}<|im_end|>\n"]),
format_system=StringFormatter(slots=["<|im_start|>system\n{{content}}<|im_end|>\n"]),
format_function=FunctionFormatter(slots=["{{content}}<|im_end|>\n"], tool_format="qwen"),
format_observation=StringFormatter(
slots=["<|im_start|>user\n<tool_response>\n{{content}}\n</tool_response><|im_end|>\n<|im_start|>assistant\n"]
),
format_tools=ToolFormatter(tool_format="qwen"),
default_system="You are a helpful assistant.",
stop_words=["<|im_end|>"],
replace_eos=True,
template_class=ReasoningTemplate,
)
LlamaFactory 用的是自定义的对话模板,如果模型微调合并后使用推理框架 vllm 部署后,由于vllm推理框架常规情况下用的是模型自带的对话模版,这就会导模型效果不一致。
2.2.3 推理框架的对话模版
下面推理框架以 vllm 为例进行介绍。
vllm推理框架使用的是大模型不是自身的对话模版。

为了使语言模型支持聊天协议,vLLM 要求模型在其分词器配置中包含聊天模板。聊天模板是一个 Jinja2 模板,指定了角色、消息和其他聊天特定 token 在输入中的编码方式。
有些模型即使经过指令/聊天微调也没有提供聊天模板。对于这些模型,您可以在 --chat-template 参数中手动指定聊天模板,参数可以是模板文件的路径,也可以是模板字符串形式。没有聊天模板,服务器将无法处理聊天请求,所有聊天请求都会出错。
> vllm serve <model> --chat-template ./path-to-chat-template.jinja
我们现在要解决的问题是:LlamaFactory微调框架与推理框架vllm对话模板的统一性,一般在业内叫对话模板对齐,就是模型在训练微调和推理时候得用同一个模板,这样才能够保证它们的输出结果是一致的。
2.2.4 前端openweb-ui的对话模版
使用 openweb-ui 询问自我认知,发现之前的微调没起作用。

查看
vllm的日志可以看到,openweb-ui使用自己的对话模版将后端的对话模版覆盖了。
<im_start> system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<im_end>
<im_start> user
你好,请介绍一下你自己。<im_end>
......

目前openweb-ui不支持用户自定义模板,官方文档官方文档上面并没有提供自定义对话模板。
2.3 对话模版总结
各阶段使用的对话模版如下: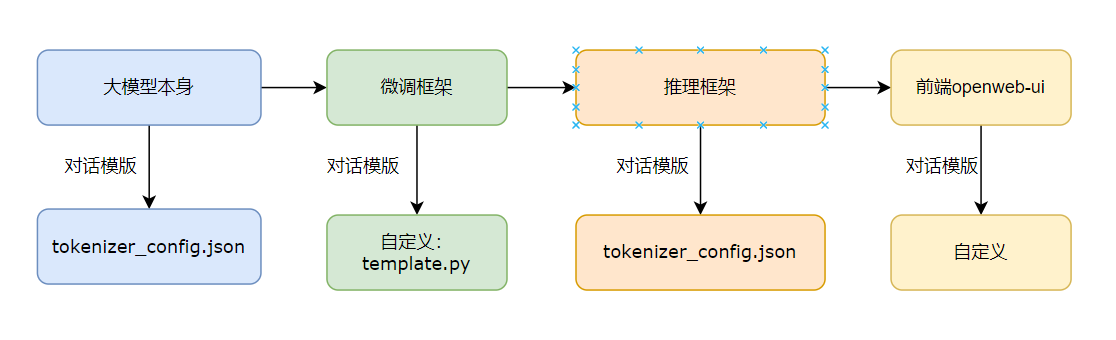
由于微调框架修改了大模型,故后续都要以微调框架的对话模版为主!!!
三、导出LLamaFactory的对话模板
LLamaFactory 的源码预留了转换对话模版的接口,但是没有给我们直接提供API。在 src/llamafactory/data/template.py 文件下有一个私有化方法_get_jinja_template(),它会直接把模型所对应的提示词模板转换成 jinja 的格式:
def _get_jinja_template(self, tokenizer: "PreTrainedTokenizer") -> str:
r"""Return the jinja template."""
prefix = self._convert_slots_to_jinja(self.format_prefix.apply(), tokenizer)
system = self._convert_slots_to_jinja(self.format_system.apply(), tokenizer, placeholder="system_message")
user = self._convert_slots_to_jinja(self.format_user.apply(), tokenizer)
assistant = self._convert_slots_to_jinja(self.format_assistant.apply(), tokenizer)
jinja_template = ""
if prefix:
jinja_template += "{{ " + prefix + " }}"
if self.default_system:
jinja_template += "{% set system_message = '" + self._jinja_escape(self.default_system) + "' %}"
jinja_template += (
"{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}"
"{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% endif %}"
"{% if system_message is defined %}{{ " + system + " }}{% endif %}"
"{% for message in loop_messages %}"
"{% set content = message['content'] %}"
"{% if message['role'] == 'user' %}"
"{{ " + user + " }}"
"{% elif message['role'] == 'assistant' %}"
"{{ " + assistant + " }}"
"{% endif %}"
"{% endfor %}"
)
return jinja_template
在 fix_jinja_template() 函数中实现了 _get_jinja_template() 私有函数的调用。
def fix_jinja_template(self, tokenizer: "PreTrainedTokenizer") -> None:
r"""Replace the jinja template in the tokenizer."""
if tokenizer.chat_template is None or self.replace_jinja_template:
try:
tokenizer.chat_template = self._get_jinja_template(tokenizer)
except ValueError as e:
logger.info_rank0(f"Cannot add this chat template to tokenizer: {e}.")
接下来我们自己编程去实现导出 LlamaFactory 上面自己所定义的对话模板。将代码拷贝到fix_jinja_template() 函数的统计目录方便调用此函数。
# mytest.py
import sys
import os
# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)
from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer
# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/llm/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")
# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]
# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)
# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)
最后的输出就是 jinja 格式的输出,将输出的内容拷贝并保存到 xxx.jinji 文件,使用 vllm 推理框架时加入–-chat-template ./xxx.jinji启动即可。
不管是
vllm还是LMdeploy框架只是用来跑模型的,它不用来改变模型,所以推理框架一定要以训练的结果为依据,而不是以模型原有官方的结果为依据,因此对话模板这块一定要跟训练的框架对齐,训练框架用的啥对话模板,在推理的时候就要用啥模板。
对话模板简单来说是控制模型输出的样式或者输出的格式,详细点来说就是对数据做格式化操作,并不会影响到模型的能力。
四、自定义对话模版
4.1 vllm自定义对话模版
vllm默认使用大模型自带的对话模版,若要使用自动以的对话模版,需要添加--chat-template参数。
> vllm serve <model> --chat-template ./path-to-chat-template.jinja
4.2 LMDeploy自定义对话模版
利用现有对话模板,直接配置一个如下的 json 文件使用。
{
"model_name": "your awesome chat template name",
"system": "<|im_start|>system\n",
"meta_instruction": "You are a robot developed by LMDeploy.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": ["<|im_end|>"]
}
model_name 为必填项,可以是 LMDeploy 内置对话模板名(通过 lmdeploy list可查阅),也可以是新名字。其他字段可选填。 当 model_name 是内置对话模板名时,json文件中各非 null字段会覆盖原有对话模板的对应属性。 而当 model_name 是新名字时,它会把将BaseChatTemplate 直接注册成新的对话模板。
这样一个模板将会以下面的形式进行拼接。
{system}{meta_instruction}{eosys}{user}{user_content}{eoh}{assistant}
{assistant_content}{eoa}{separator}{user}...
可以通过 --chat-template 传入自定义对话模板
> lmdeploy serve api_server internlm/internlm2_5-7b-chat --chat-template
${JSON_FILE}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)