【花雕动手做】HUSKYLENS 2 AI视觉传感器之识别文字输出相关数据
摘要:本文介绍了HUSKYLENS 2视觉传感器与行空板K10的连接应用,重点演示了光学字符识别(OCR)功能。HUSKYLENS 2搭载6TOPS算力芯片和200万像素摄像头,支持20多种AI模型;行空板K10集成了多种传感器和显示屏。通过Mind+编程软件,实现了文字区域检测、字符识别及数据输出功能,包括文字块ID、位置坐标、内容等信息获取。实验测试了多组印刷体样本的识别效果,并提供了完整的A

一、相关知识点
1、HUSKYLENS 2(二哈识图2)是DFRobot推出的新一代AI视觉传感器,搭载6TOPS算力的Kendryte K230双核RISC-V芯片,集成1GB LPDDR4内存与8GB存储,支持人脸识别、物体检测、姿态估计等20余种预置AI模型,同时允许用户通过自训练模型部署实现定制化识别
。其硬件配置包括200万像素摄像头、2.4英寸触摸屏、可更换镜头模组(支持显微/夜视)及RGB补光灯,搭配UART/I2C接口可无缝连接Arduino、树莓派等开发板,实现实时图传与多模态交互。内置MCP服务打通本地视觉与大模型能力,例如识别午餐图片后可生成膳食建议,而模型广场提供车牌识别、跌倒检测等垂直领域即用型方案。作为教育利器,它已融入《中小学人工智能通识教育指南》课程体系,通过Mind+图形化编程工具降低AI开发门槛,助力创客教育与STEAM实践。

2、行空板 K10 是一款专为中小学信息科技教学和创客项目设计的国产 AIoT 开发板,以 ESP32-S3 为核心,高度集成 2.8 英寸全彩 LCD 屏、摄像头、双麦扬声器、WiFi 蓝牙模块及温湿度、光线、加速度等多种传感器,无需额外配件即可实现离线语音识别(支持 200 词库)、人脸识别、二维码读取、物联网联动等功能,支持 Mind + 图形化编程与 MicroPython 代码编程,兼顾入门便捷性与功能扩展性,丰富的扩展接口还能连接外部传感器、执行器,轻松落地 AI、物联网类创意项目,是编程学习与科创实践的高性价比选择。

3、Mind + 是 DFRobot 旗下蘑菇云科创教育团队研发的、拥有自主知识产权的国产青少年编程软件,它兼容 Scratch3.0,既支持零基础学习者拖拽图形化积木编程,也能切换至 Python/C/C++ 代码编程,且积木可自动转换为对应代码助力进阶学习,同时适配行空板M10\ K10、Arduino、micro:bit 等众多主流开源硬件与上百种电子模块,集成图像识别、语音识别等 AI 功能及物联网开发能力,还搭配实时交互、程序烧录脱机运行等模式与丰富教学案例,适配校内外编程教学、创客项目及竞赛等场景,是兼顾低入门门槛与高拓展性的科创教育工具。
二、硬件连接
准备材料
行空板K10 x 1
HUSKYLENS 2 x 1
USB数据线 x 2
4pin连接线(或杜邦线)x 1
准备一根USB数据线和一根4Pin白色硅胶线。使用USB数据线连接电脑与行空板K10,使用4Pin黑胶先连接行空板K10与HuskyLens 2,再使用额外的USB数据线n连接示意图如下连接HUSKYLENS 2的Type-C接口与电源,为HUSKYLENS 2进行额外供电。接线图可参考下图。



三、光学字符识别(Optical Character Recognition,简称 OCR)是一种图像识别技术,其核心目标是:将印刷或手写文本从图像、扫描件或照片中提取出来,并转换为可编辑的数字文本。光学字符识别是人工智能与图像处理的经典应用之一。它让计算机“看懂文字”,是连接纸质信息与数字世界的关键桥梁。
1、OCR 的基本原理
OCR 的识别过程通常包括以下几个步骤:
图像采集:通过扫描仪、摄像头或文件获取含有文字的图像。
图像预处理:去除噪声、校正倾斜、增强对比度,提高识别准确率。
文字定位:识别图像中哪些区域包含文字。
字分割:将整段文字拆分为单个字符。
字符识别:通过模式匹配或深度学习模型识别每个字符。
文本输出:将识别结果转换为可编辑的文本格式,如 TXT、DOC、PDF。
2、OCR 能识别哪些内容?
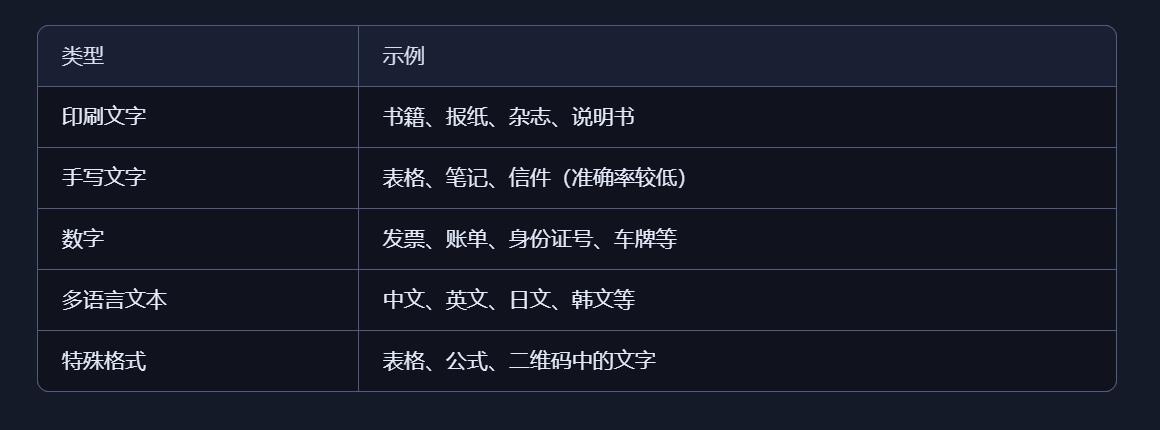
3、应用场景举例
扫描纸质文档并转为电子档
发票、收据自动录入系统
手机拍照识别文字(如翻译、搜索)
银行、政府机构的档案数字化
车牌识别系统中的字符提取
教育实验中的图像识别训练
4、相关场景

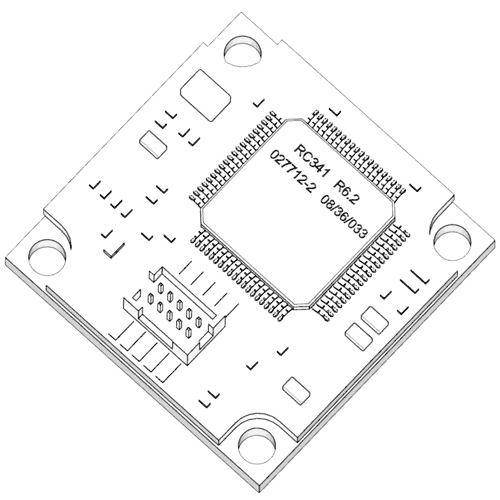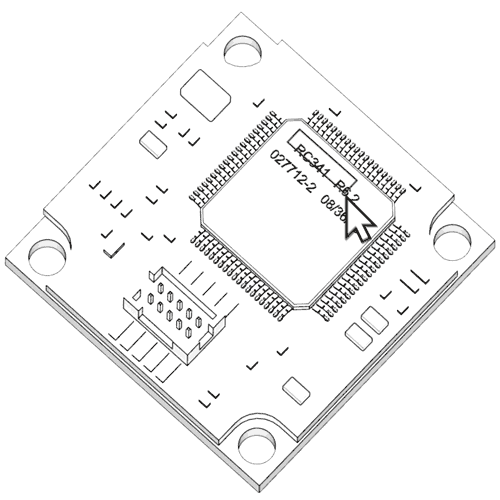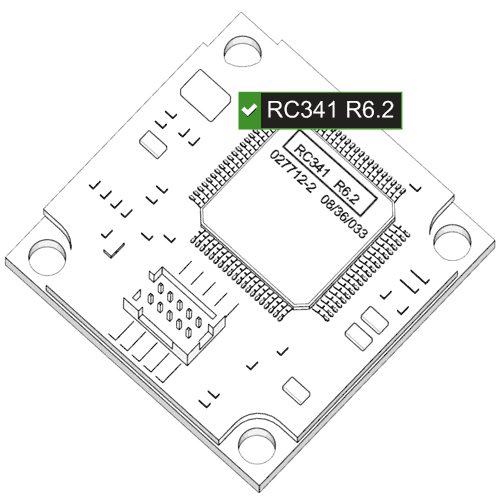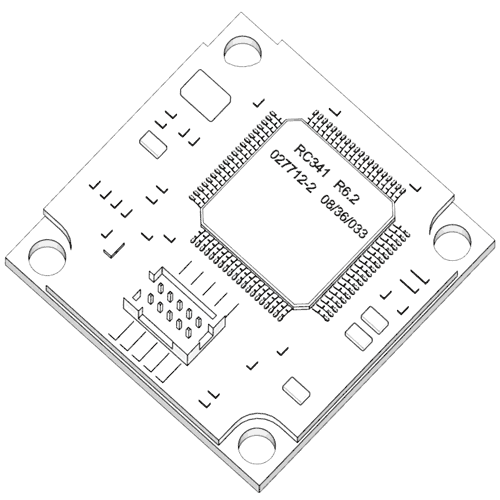
四、在光学字符识别功能下,HUSKYLENS 2 可识别并框出视野内文字块出现的区域,并将识别到的文字显示在屏幕上,可使用以下示例程序,统计画面中可识别文字块的总数、获取画面中离十字光标最近的文字块相关数据,可以读取的数据有:文字块的ID 、名称、内容、中心点X坐标和Y坐标、文字块宽度和高度。
1、实际测试的几个范本




2、测试实验代码
/*【花雕动手做】HUSKYLENS 2 AI视觉传感器之识别文字输出相关数据
* MindPlus
* esp32s3bit
*/
#include "unihiker_k10.h" // 引入UniHiker开发板库,提供显示屏控制接口
#include "DFRobot_HuskylensV2.h" // 引入HUSKYLENS AI视觉传感器库,封装OCR识别算法
// 创建全局对象实例
HuskylensV2 huskylens; // HUSKYLENS视觉传感器对象,负责图像采集和文字识别
UNIHIKER_K10 k10; // UniHiker开发板对象,控制TFT显示屏和用户交互
uint8_t screen_dir=2; // 屏幕显示方向参数(2通常表示横向显示模式)
// 系统初始化函数 - 在设备上电时执行一次
void setup() {
k10.begin(); // 初始化UniHiker开发板基础硬件(GPIO、时钟、外设)
Wire.begin(); // 初始化I2C通信总线,默认引脚SDA=8, SCL=9
// HUSKYLENS传感器初始化重试循环
// 确保视觉传感器连接稳定并完成自检
while (!huskylens.begin(Wire)) {
delay(100); // 等待100ms后重试,避免I2C总线竞争
}
k10.initScreen(screen_dir); // 按照指定方向初始化LCD显示屏驱动
k10.creatCanvas(); // 创建图形画布缓冲区,实现双缓冲显示机制
// 设置HUSKYLENS算法模式为光学字符识别(OCR)
// OCR技术将图像中的文字区域检测并转换为可编辑的文本数据
huskylens.switchAlgorithm(ALGORITHM_OCR_RECOGNITION);
// 在屏幕第一行显示系统标题
k10.canvas->canvasText("识别文字数据", 1, 0x0000FF); // 蓝色标题,第1行
}
// 主循环函数 - 持续执行文字识别和数据显示
void loop() {
// 触发HUSKYLENS执行OCR识别算法并获取结果
// 内部流程:图像采集 → 文本区域检测 → 字符分割 → 字符识别 → 结果输出
huskylens.getResult(ALGORITHM_OCR_RECOGNITION);
// 检查是否有新的文字识别结果可用
if ((huskylens.available(ALGORITHM_OCR_RECOGNITION))) {
// === 显示画面中心区域的文字块ID ===
// getCachedCenterResult优先获取视觉焦点区域的文字块信息
k10.canvas->canvasText((String("靠中心的文字ID: ") +
String((RET_ITEM_NUM(huskylens.getCachedCenterResult(ALGORITHM_OCR_RECOGNITION), Result, ID)))),
3, 0xFF0000); // 第3行,红色文字,突出显示中心目标ID
// === 显示检测到的文字块总数 ===
// 反映当前画面中识别到的独立文字区域数量
k10.canvas->canvasText((String("文字块总数: ") +
String((huskylens.getCachedResultNum(ALGORITHM_OCR_RECOGNITION)))),
4, 0xFF0000); // 第4行,红色文字,环境统计信息
// === 显示中心文字块的内容标签 ===
k10.canvas->canvasText("靠中心的文字内容: ", 5, 0xFF0000); // 第5行,红色标签
// === 显示中心文字块识别的具体文本内容 ===
// RET_ITEM_STR宏提取识别出的原始文本字符串
k10.canvas->canvasText((RET_ITEM_STR(huskylens.getCachedCenterResult(ALGORITHM_OCR_RECOGNITION), Result, content)),
6, 0xFF0000); // 第6行,红色显示识别出的文字内容
// === 显示文字块尺寸信息标签 ===
k10.canvas->canvasText("靠中心的文字块", 7, 0xFF0000); // 第7行,红色标签
// === 显示文字块的宽度和高度尺寸 ===
// 注意:代码中显示的是width和height,但描述为"中心坐标",存在描述歧义
k10.canvas->canvasText((String("的中心坐标: ") +
String((String((RET_ITEM_NUM(huskylens.getCachedCenterResult(ALGORITHM_OCR_RECOGNITION), Result, width))) +
String((String(",") +
String((RET_ITEM_NUM(huskylens.getCachedCenterResult(ALGORITHM_OCR_RECOGNITION), Result, height)))))))),
8, 0xFF0000); // 第8行,红色显示尺寸信息
// === 显示文字块中心坐标标签 ===
k10.canvas->canvasText("靠中心的文字块", 9, 0xFF0000); // 第9行,红色标签
// === 显示文字块的中心点坐标(xCenter, yCenter) ===
// 注意:代码中显示的是xCenter和yCenter,但描述为"宽高",存在描述歧义
k10.canvas->canvasText((String("的宽高:") +
String((String((RET_ITEM_NUM(huskylens.getCachedCenterResult(ALGORITHM_OCR_RECOGNITION), Result, xCenter))) +
String((String(",") +
String((RET_ITEM_NUM(huskylens.getCachedCenterResult(ALGORITHM_OCR_RECOGNITION), Result, yCenter)))))))),
10, 0xFF0000); // 第10行,红色显示坐标信息
}
// 更新画布显示:将内存缓冲区中的图形数据一次性刷新到物理屏幕
// 采用双缓冲技术避免屏幕闪烁和撕裂现象
k10.canvas->updateCanvas();
// 控制循环频率:50ms延迟对应20Hz刷新率
// 平衡识别实时性、处理负载和功耗
delay(50);
}
3、代码解读:
系统架构与核心技术栈
- 硬件系统架构
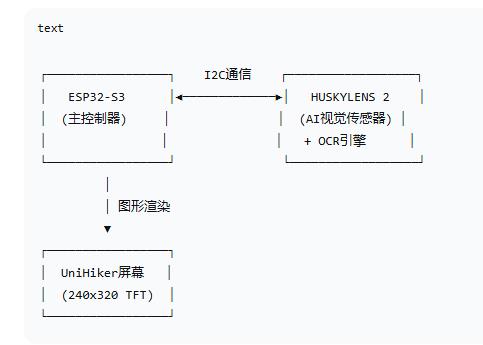
- OCR技术实现层次
text
应用层: 文字识别结果显示系统
↓
算法层: HUSKYLENS固件(集成OCR引擎)
↓ ├── 文本检测(CTPN/EAST)
驱动层: I2C通信协议 + 屏幕驱动 ├── 文字识别(CRNN/Attention)
↓ └── 文本后处理
硬件层: 摄像头 + AI芯片 + 显示屏
代码执行流程深度分析
- 初始化阶段技术细节
cpp
void setup() {
k10.begin(); // 初始化GPIO、SPI、定时器等底层硬件
Wire.begin(); // 初始化I2C,400kHz通信速率
// 传感器握手协议
while (!huskylens.begin(Wire)) {
delay(100); // 采用简单的线性退避策略
}
k10.initScreen(screen_dir); // 配置LCD控制器初始化序列
k10.creatCanvas(); // 分配显存缓冲区(双缓冲)
// 切换至OCR算法模式
huskylens.switchAlgorithm(ALGORITHM_OCR_RECOGNITION);
}
关键技术点:
硬件抽象层:通过对象封装底层硬件操作细节
通信可靠性:I2C连接的重试机制确保系统稳定性
显示优化:双缓冲技术避免屏幕撕裂
- 主循环实时处理流水线
cpp
void loop() {
// 阶段1: 数据采集与处理
huskylens.getResult(ALGORITHM_OCR_RECOGNITION);
// 阶段2: 状态检查与条件执行
if (huskylens.available(ALGORITHM_OCR_RECOGNITION)) {
// 阶段3: 信息提取与可视化
processAndDisplayOCRResults();
}
// 阶段4: 显示输出
k10.canvas->updateCanvas();
delay(50); // 时序控制
}
OCR数据结构与信息提取
- HUSKYLENS返回的数据结构
cpp
// 推测的OCR结果数据结构
typedef struct {
uint16_t ID; // 文字块唯一标识符
char content[256]; // 识别出的文本内容
uint16_t xCenter; // 文字块中心X坐标
uint16_t yCenter; // 文字块中心Y坐标
uint16_t width; // 文字块边界框宽度
uint16_t height; // 文字块边界框高度
float confidence; // 识别置信度(0-1)
} OCR_Result;
- 信息提取宏分析
cpp
// 数值数据提取
RET_ITEM_NUM(result, Result, ID) // 提取ID数值
RET_ITEM_NUM(result, Result, xCenter) // 提取X坐标
RET_ITEM_NUM(result, Result, yCenter) // 提取Y坐标
RET_ITEM_NUM(result, Result, width) // 提取宽度
RET_ITEM_NUM(result, Result, height) // 提取高度
// 字符串数据提取
RET_ITEM_STR(result, Result, content) // 提取识别文本内容
显示系统架构分析
- 信息可视化设计
text
行1: [系统标题] - 蓝色,固定标识
行2: (保留行)
行3: [中心文字块ID] - 红色,目标标识
行4: [文字块总数] - 红色,环境感知
行5-6: [文字内容] - 红色,核心识别结果
行7-8: [文字块尺寸] - 红色,空间信息
行9-10: [文字块坐标] - 红色,定位信息 - 颜色编码策略
0xFF0000 (红色):全部信息使用红色,突出显示重要性
0x0000FF (蓝色):仅标题使用蓝色,建立视觉层次
设计考量:在文字识别场景中,所有识别信息都具有高重要性,因此统一使用红色强调。
实时性能与优化策略
- 时序控制分析
cpp
delay(50); // 20Hz刷新率设计
OCR处理时间:约30-40ms(包含图像采集、预处理、识别)
显示渲染时间:约5-8ms(文本渲染和缓冲区交换)
系统余量:2-5ms(处理波动和通信延迟)
- 数据处理优化
cpp
// 条件执行避免不必要的显示更新
if (huskylens.available(...)) {
// 只在有新识别结果时更新显示
// 减少字符串拼接和内存分配操作
}
OCR技术特性分析
- 文字识别技术栈
HUSKYLENS OCR可能采用的流程:
text
图像输入 → 文本检测(找出文字区域) → 文本识别(字符级分类) → 后处理
↓ ↓ ↓ ↓
RGB图像 bounding box 字符序列 语言模型校验
2. 识别能力特性
多语言支持:可能支持中文、英文、数字混合识别
字体适应性:对印刷体、手写体有一定适应能力
光照鲁棒性:内置图像预处理增强不同光照条件下的识别率
多文本块处理:能够同时识别画面中的多个文字区域
4、测试实验MInd+图形编程
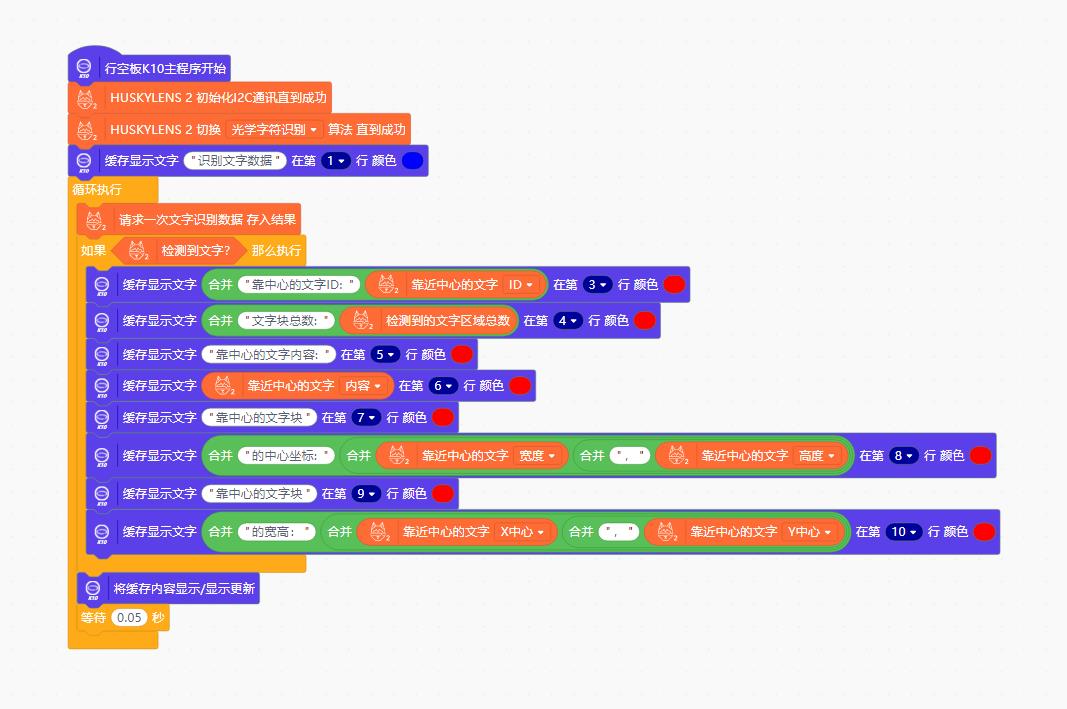
5、实验场景图








有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)