超越思维链!邱锡鹏团队定义AI推理新范式:“视频思考”,让GPT-4o看到都得点赞!
【摘要】复旦大学邱锡鹏团队提出创新性"视频思考"范式,突破现有"文本/图像思考"在动态推理和多模态融合上的局限。研究构建了包含4149个样本的VideoThinkBench基准测试集,涵盖视觉中心与文本中心两大任务类别。实验显示,Sora-2在视觉推理任务上与主流视觉语言模型性能相当,在文本推理任务上取得MATH 92%、MMMU 75.53%的准确率。研究
投中嘉川CVSource显示,由复旦大学知名教授邱锡鹏(其专著《神经网络与深度学习》是国内人工智能入门必读书,2023年还带领团队发布开源中文大语言模型MOSS)与其学生创办的上海模思智能科技有限公司完成首轮融资,投资方包括IDG资本、华为哈勃、元禾控股及智谱系机构星连资本,该公司主营语音大模型研发,标志着国产AI进入“真语音到语音交互”新阶段。

Mosi Intelligence
接下来给大家介绍一下邱锡鹏团队的最新研究!相关论文源码有需要的可自取~
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/KZCANHz9jxm9w4_oYNHF1w
https://mp.weixin.qq.com/s/KZCANHz9jxm9w4_oYNHF1w
1. 【导读】

论文信息
论文标题:Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
作者:邱锡鹏团队
作者机构:复旦大学、上海创新研究院、哈尔滨工业大学、香港中文大学
论文来源:模思智能
论文链接:https://arxiv.org/abs/2511.04570
项目链接:
-
网站:https://thinking-with-video.github.io
-
代码仓库:https://github.com/tongjingqi/Thinking-with-Video
-
基准测试集:https://huggingface.co/datasets/fnlp/VideoThinkBench
2. 【论文速读】
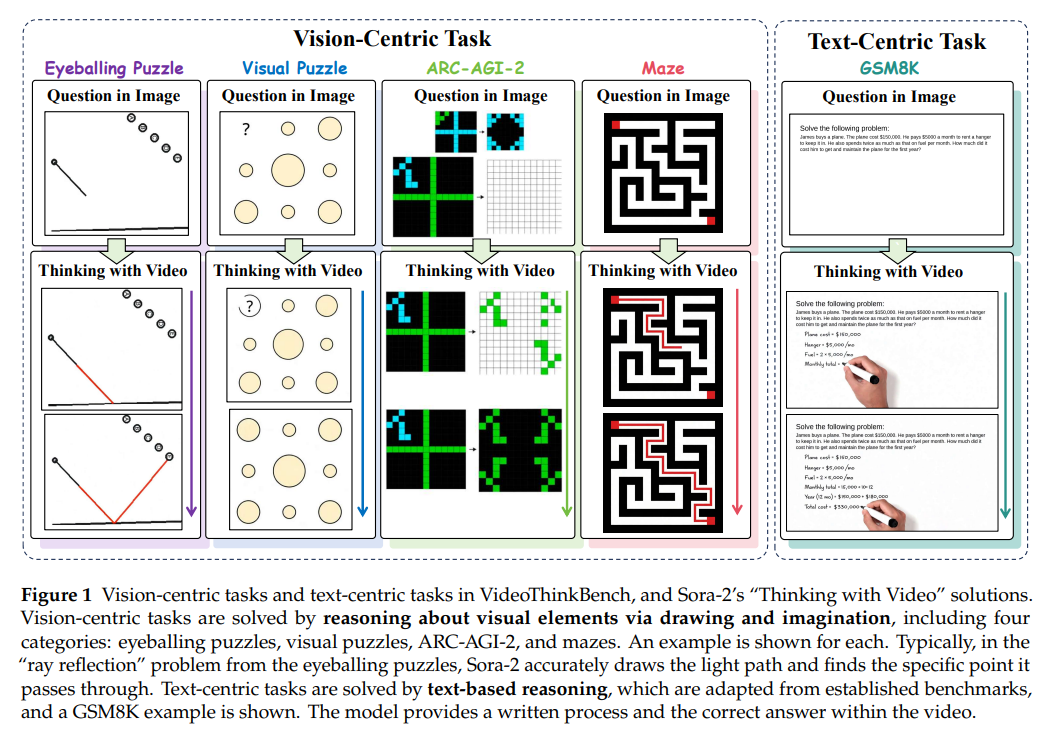
本文指出“文本思考”与“图像思考”范式在提升大语言模型和视觉语言模型推理能力的同时,存在图像无法体现动态过程、模态分离的固有局限;为此提出“视频思考”新范式,借助Sora-2等视频生成模型,在统一时间框架内连接视觉与文本推理,并构建VideoThinkBench基准(含视觉中心、文本中心任务)用于评估。实验表明,Sora-2在视觉中心任务上与主流视觉语言模型相当且部分任务表现更优,文本中心任务上MATH准确率达92%、MMMU达75.53%,且自一致性与上下文学习可提升其性能;研究最终证实视频生成模型具备统一多模态理解与生成的潜力,确立“视频思考”为统一多模态推理范式。
3. 从“文本/图像思考”到“视频思考”:多模态推理新突破
3.1 研究背景
-
现有范式局限:“文本思考”“图像思考”无法体现动态过程,且模态分离,缺乏统一推理框架。
-
新范式动因:提出“视频思考”,借助视频生成模型整合动态推理与多模态融合,贴合人类认知。
-
评估需求:构建VideoThinkBench基准,覆盖视觉、文本两类中心任务,支撑范式验证。
3.2 相关工作
-
视频生成模型:Sora-2等闭源模型性能领先,Stable Video Diffusion等开源项目逐步普及,闭源属性限制机制研究。
-
推理范式迁移:思维链提升文本推理,“图像思考”实现文本-视觉初步连接,部分多模态模型探索交错推理。
-
视频推理评估:少数研究显示视频模型具备推理潜力,但缺乏系统数据集、未与VLMs对比、局限于视觉任务。
4. 解锁“视频思考”能力:VideoThinkBench基准与评估方法论
4.1 基准测试集(VideoThinkBench)整体设计
-
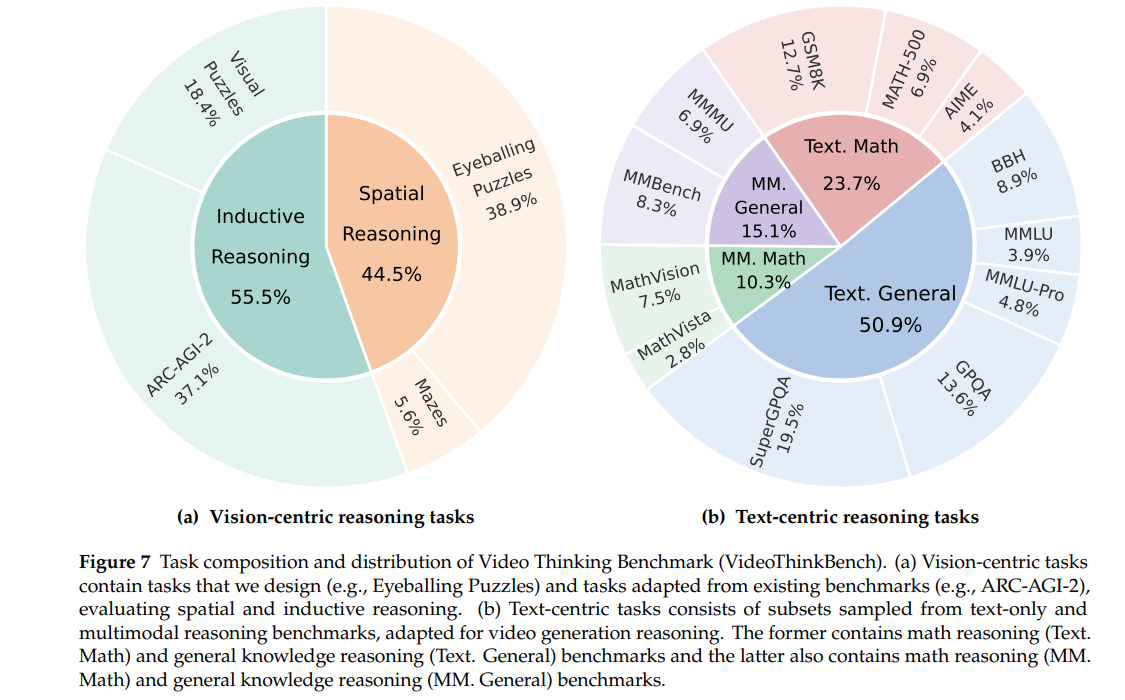
核心定位:专为评估视频生成模型多模态推理能力构建的综合基准,涵盖视觉中心与文本中心两大任务类别,总计4149个测试样本。
- 任务构成:
-
视觉中心任务(2696个样本):含空间推理(eyeballing puzzles 1050个、迷宫150个)与归纳推理(ARC-AGI-2 1000个、视觉谜题496个),部分任务可通过程序批量生成,多数任务支持结果验证。
-
文本中心任务(1453个样本):含文本仅推理(GSM8K、MATH-500等数学与常识任务)与多模态推理(MathVista、MMMU等),均从现有基准中采样子集并适配视频生成模型评估场景。
-
4.2 视觉中心任务评估方案
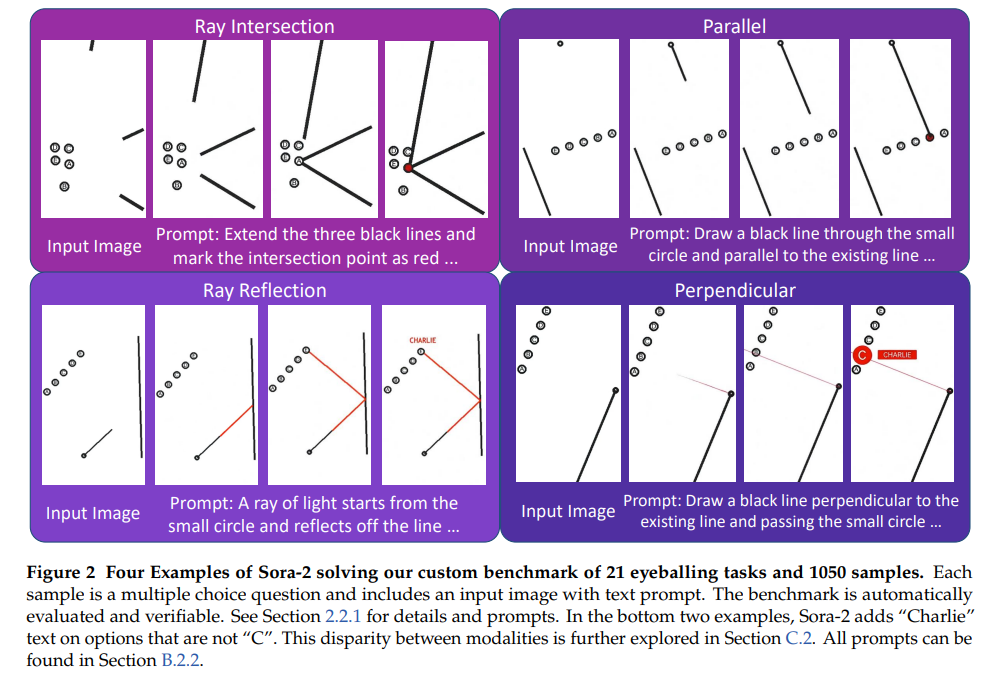
4.2.1 Eyeballing Puzzles任务
-
数据集构建:设计21类可验证几何任务(含点、线、形状3个子类),每类生成50个样本(共1050个),输入为图像+提示词,采用选择题形式。
-
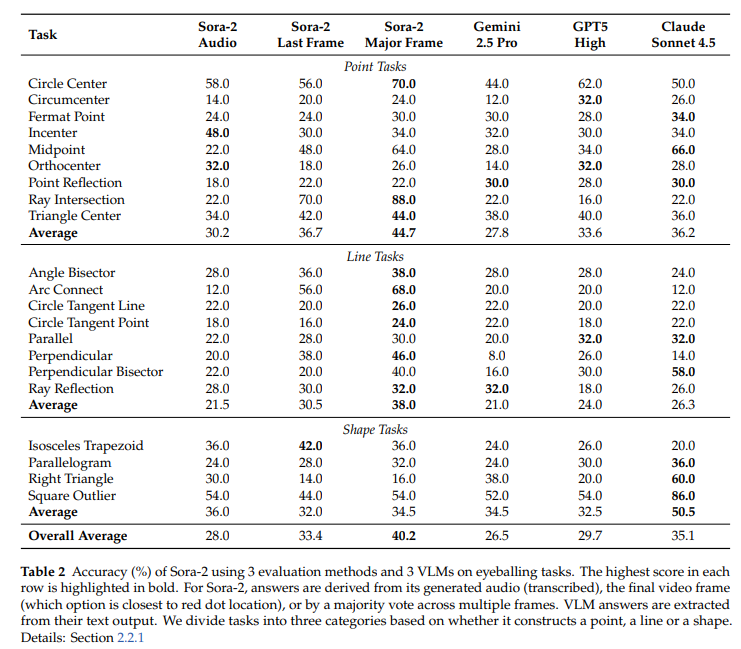
评估方法(针对Sora-2):
-
音频评估:提取视频音频,用whisper-1模型转录,取首个音标词作为答案,与真值对比。
-
最后一帧评估:提示模型在正确选项画红点,提取视频最后一帧,计算红色像素平均坐标,匹配最近选项,与真值对比。
-
主帧评估:每5帧提取1帧,通过图像评估器获取每帧选项,对非“无选项”结果进行多数投票,与真值对比。
-
-
VLMs评估:提示模型在文本响应中包含选项,程序提取后与真值对比。
4.2.2 Visual Puzzles任务
-
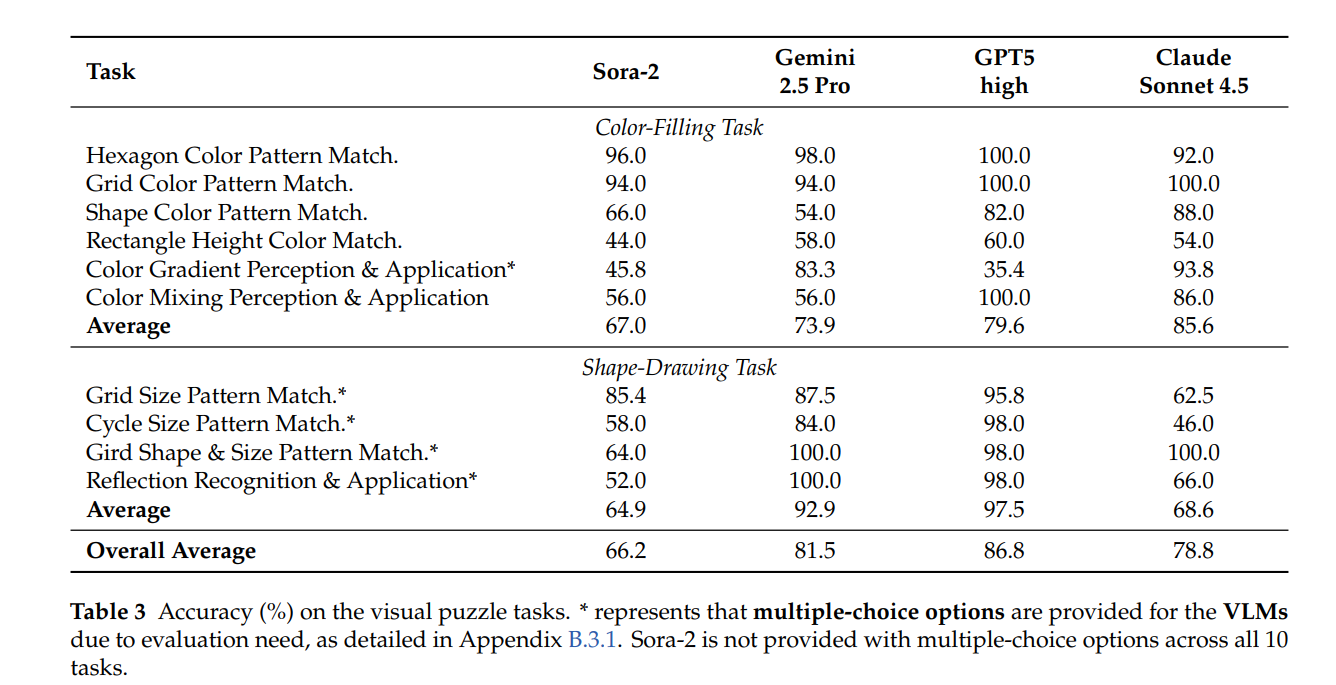
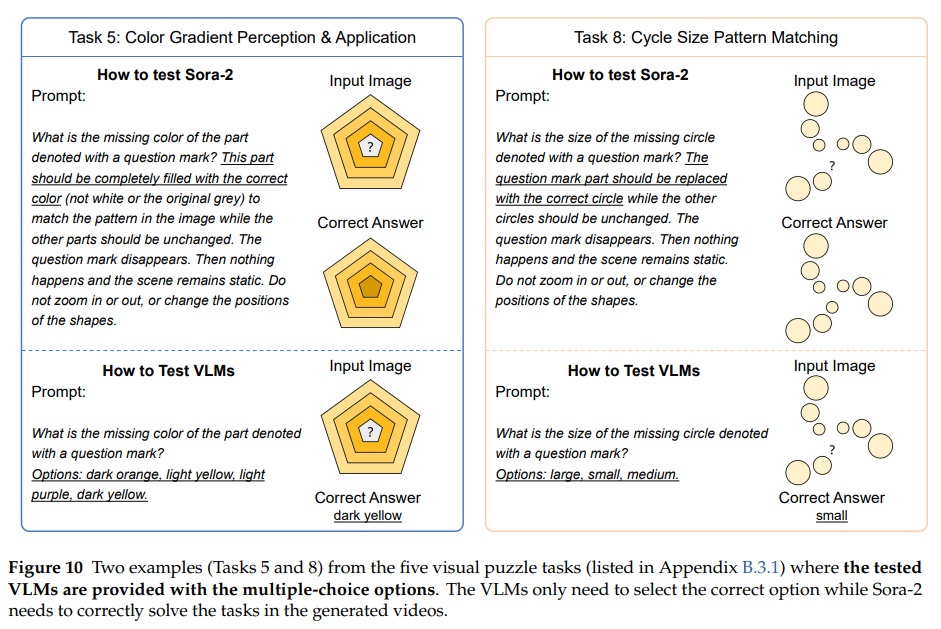
数据集构建:从PuzzleVQA适配10类任务(6类颜色填充、4类形状绘制),每类约50个样本,要求模型填充颜色或绘制形状。
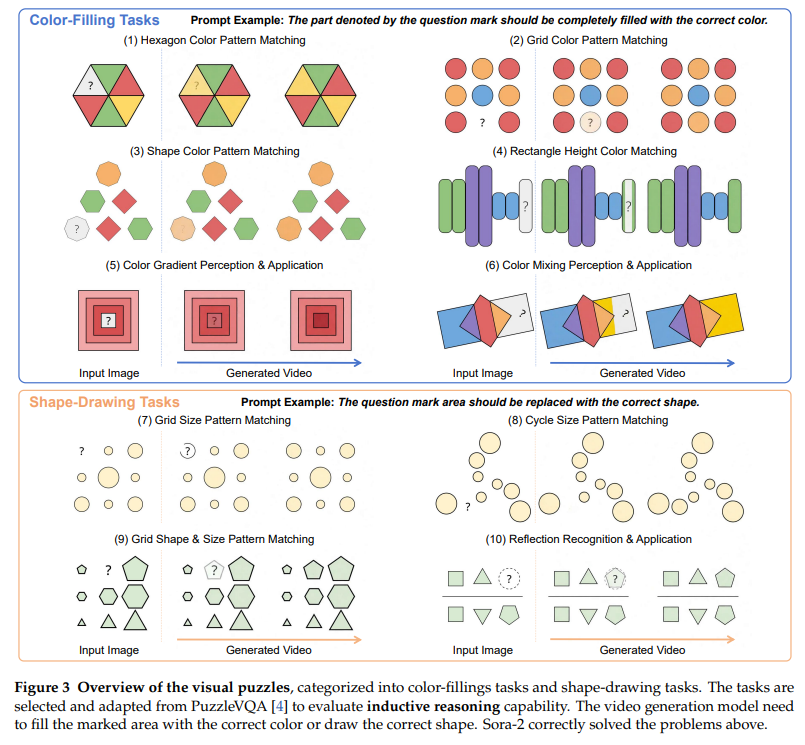
-
评估指标:定义偏差值量化生成帧与真值图像的差异:
-
颜色填充任务:基于RGB空间欧氏距离计算像素差,公式为 ,其中、分别为生成图与真值图像素。
-
形状绘制任务:先将图像灰度化、二值化(阈值245),计算像素匹配差,公式为。
-
-
评估流程:
-
Sora-2:选取最小的“最佳帧”,人工评估性能。
-
VLMs:部分任务提供选择题选项,采用规则匹配评估,与真值对比。
-
4.2.3 ARC-AGI-2任务
-
数据集构建:使用ARC-AGI-2训练集(1000个样本),每样本含多组输入-输出网格,要求模型学习变换规则并生成测试集输出,将原始JSON数据转为图像格式并统一宽高比。
- 评估方法:
-
自动评估:提取Sora-2生成视频最后一帧,缩放至输入尺寸,计算每个单元格平均颜色,匹配10色调色板中最近颜色,全单元格正确则判定为对。
-
人工评估:随机选取100个样本,分为“完全正确”“基本正确”“部分正确”“错误”4类,细化性能分析。
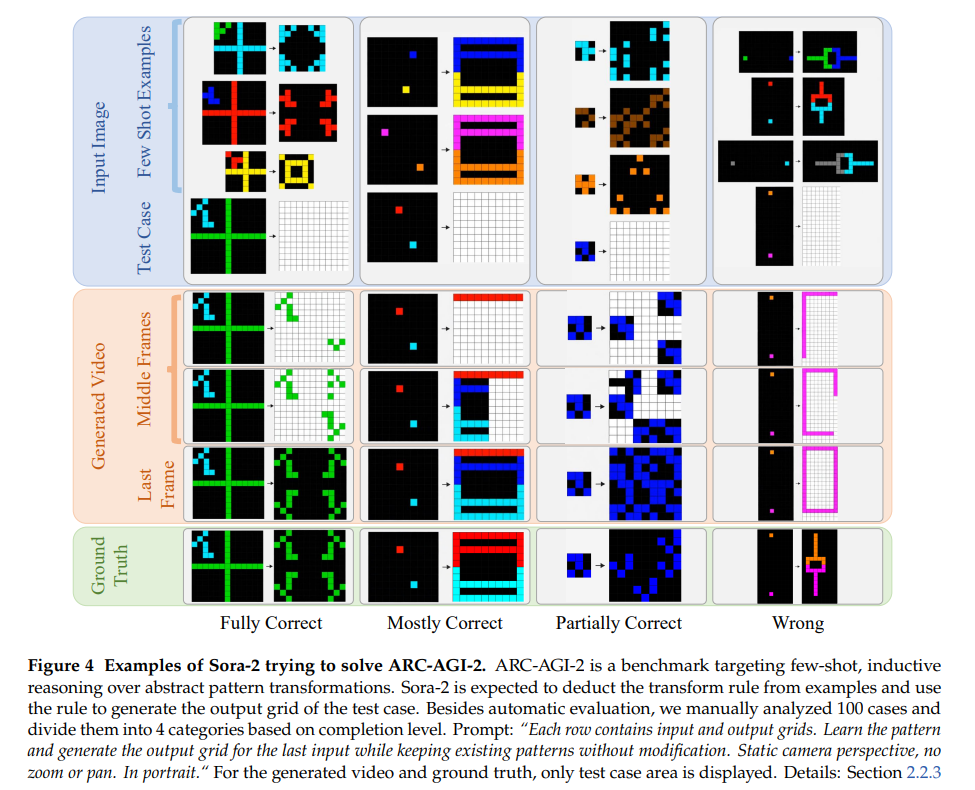
-
4.3 文本中心任务评估方案
4.3.1 输入与指令设计
-
输入形式:采用“文本提示词+参考图像”,文本提示包含问题全文(文本仅任务)或文本部分(多模态任务),参考图像在白色背景上展示完整问题(含多模态任务的原始图像)。
-
生成要求:模型需在视频中呈现文字解题过程+答案,音频仅播报最终答案(避免视频时长限制导致截断)。
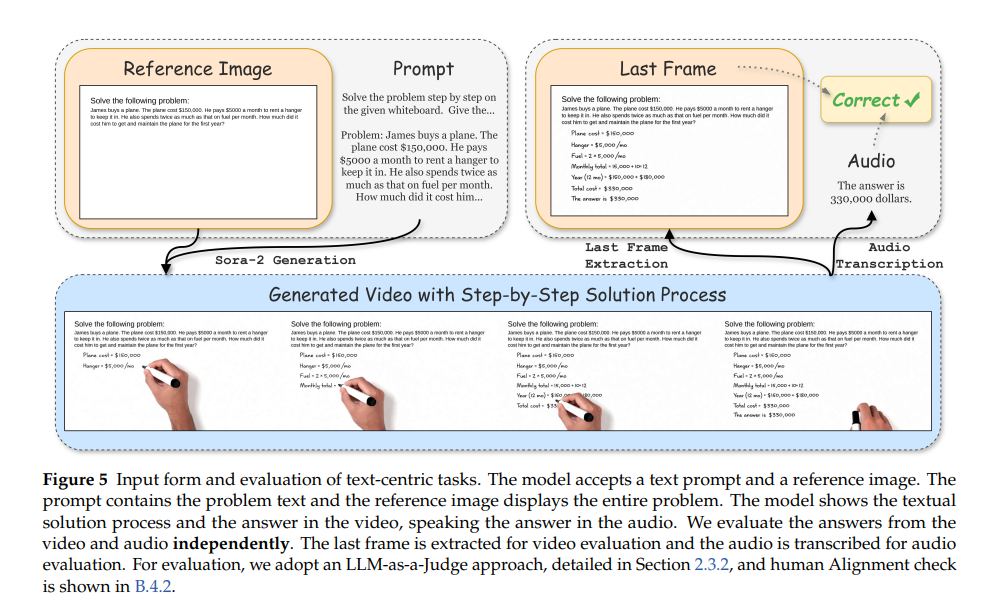
4.3.2 评估流程与方法
- 双模态独立评估:
-
视频评估:提取视频最后一帧(含文字答案),采用“LLM-as-a-Judge”方案,以GPT-4o为裁判模型,按优先级(显式答案声明>符号标记>右下角结果)提取可见答案,与真值对比。
-
音频评估:用whisper-1转录音频,同样通过GPT-4o判断转录文本是否明确包含或暗示正确答案,与真值对比。
-
-
结果统计:报告视频准确率、音频准确率,及“双模态均正确”(V∩A)、“至少一模态正确”(V∪A)的比例。
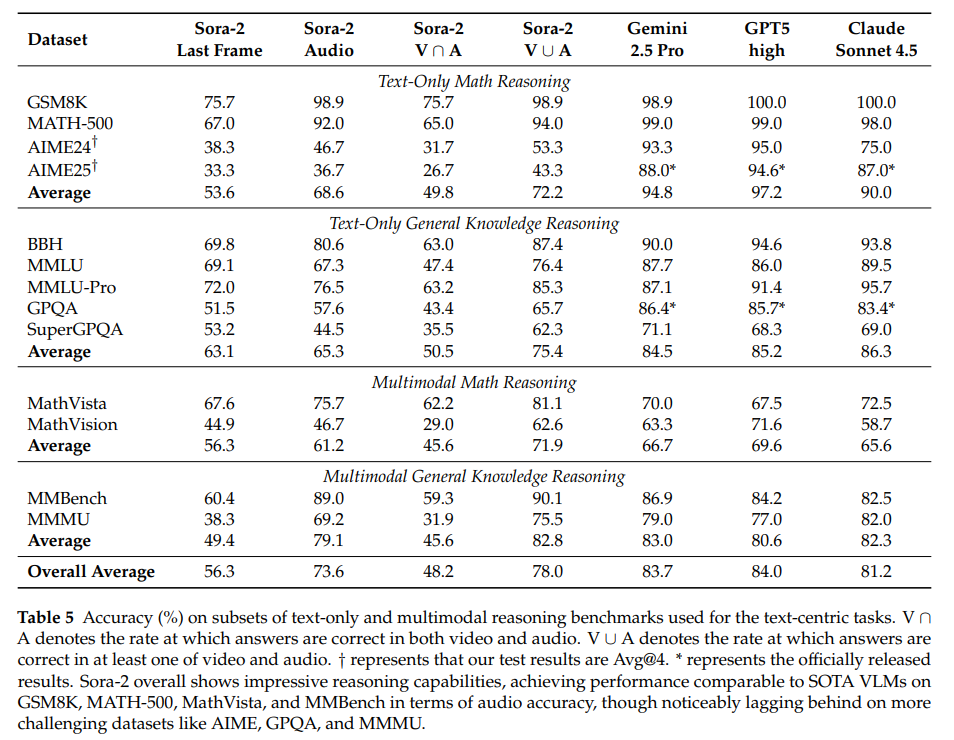
5. 拆解“视频思考”能力:实验分析背后的关键发现
5.1 视觉中心推理任务分析:Sora-2的学习与推理特性
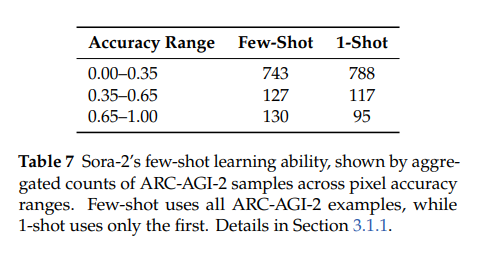
5.1.1 少样本学习能力验证
-
实验设计:在ARC-AGI-2任务中,对比“提供全部示例”(少样本)与“仅提供1个示例”(1-shot)的性能,以“像素准确率”衡量(0-1.0,值越高越优)。
-
结果:1-shot场景下,低准确率(0.00-0.35)样本数更多(788个)、高准确率(0.65-1.00)样本数更少(95个);少样本场景则相反(低准确率743个、高准确率130个),证明Sora-2为少样本学习者,多示例可提升抽象推理性能。
5.1.2 自一致性提升推理可靠性
-
实验设计:以Arc Connect谜题为对象,对比“单轮生成”与“5轮生成投票”的准确率,采用音频、最后一帧、主帧3种评估方式。
-
结果:主帧评估下,单轮准确率68%,5轮投票后达90%;最后一帧评估下,单轮56%,5轮66%;音频评估无提升(均12%)。表明视频时间一致性可“降噪”,多轮自一致性进一步强化推理可靠性,为视频生成推理的“测试时缩放”提供新方向。

5.2 文本中心推理任务分析:能力来源与局限
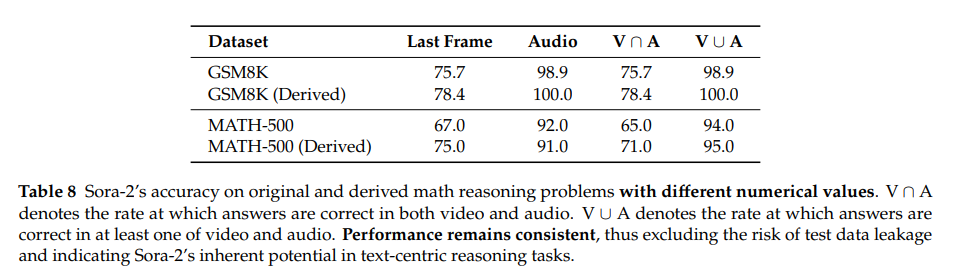
5.2.1 排除测试集泄露:能力源于固有推理
-
实验设计:对GSM8K、MATH-500的原始问题,用Qwen3-235B、Gemini 2.5 Pro生成“数值/场景不同、解题逻辑一致”的衍生题,对比Sora-2在两类问题上的准确率。
-
结果:GSM8K原始题与衍生题的音频准确率均超98%,MATH-500均超91%,无显著差异,证明Sora-2的文本推理能力非源于测试集泄露,而是固有能力。
5.2.2 推理过程局限:答案正确但过程难连贯
-
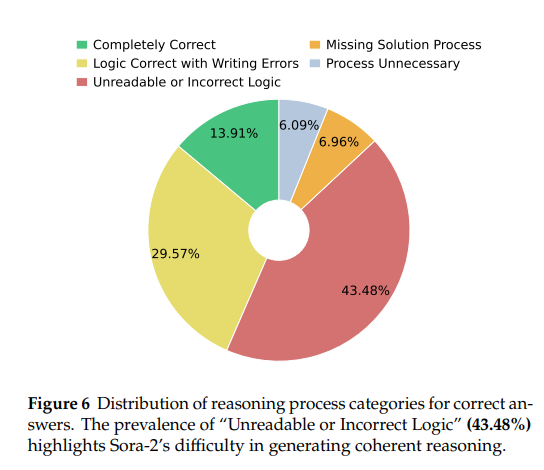
实验设计:抽样115个“视频+音频均正确”的案例,人工分析推理过程,分为“完全正确”“逻辑正确但书写错误”“不可读/逻辑错”“缺失过程”“无需过程”5类。
-
结果:仅13.91%为“完全正确”,43.48%“不可读/逻辑错”,29.57%“逻辑正确但书写错误”,表明Sora-2虽能输出正确答案,但难以通过视频生成清晰、连贯的推理步骤。
5.2.3 能力来源推测:依赖提示重写模型
-
实验设计:以可控制“提示重写”功能的Wan2.5为对照,对比“开启重写”与“关闭重写”在GSM8K、MMLU、MMMU上的准确率。
-
结果:关闭重写后,Wan2.5准确率近乎为0;开启后性能显著提升。推测Sora-2的文本推理能力也源于内部提示重写机制——先由重写模型解出问题,再指导视频生成组件输出结果。
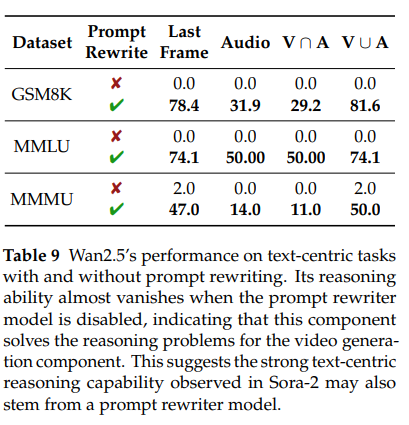
Wan2.5’s performance on text-centric tasks with and without prompt rewriting
6.【总结展望】
6.1 总结
本文针对“文本思考”“图像思考”范式动态性缺失、模态分离的局限,提出“视频思考”这一统一多模态推理新范式,通过Sora-2等视频生成模型在时间框架内整合视觉与文本推理,并构建VideoThinkBench基准(含视觉/文本中心任务)支撑评估。实验表明,Sora-2在视觉中心任务上与主流视觉语言模型(VLMs)相当且部分任务(如Eyeballing Games)表现更优,文本中心任务上MATH、MMMU等基准准确率亮眼,同时少样本学习与自一致性可提升其性能;进一步分析证实视频生成模型具备统一多模态理解与生成潜力,且文本推理能力源于固有能力与提示重写机制,最终确立“视频思考”的范式价值。
6.2 展望
未来研究将从三方面推进:一是拓展评估范围,纳入更多视频生成模型(尤其是开源模型),以深入分析内部机制,弥补当前仅评估Sora-2(闭源)的局限;二是探索能力增强路径,计划通过强化学习(RLVR)扩大VideoThinkBench中可验证任务规模,提升模型“视频思考”能力;三是探索统一多模态训练方法,将文本语料转化为视频形式训练数据(如帧生成模拟白板书写),结合大规模图文数据预训练,助力视频模型实现更深度的多模态理解与生成。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/KZCANHz9jxm9w4_oYNHF1w
https://mp.weixin.qq.com/s/KZCANHz9jxm9w4_oYNHF1w

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)