ICML AI4Math 最佳论文+NeurIPS 2025 Oral 满分!清华LeapLab:RLVR的巨额投入可能白砸了!
NeurIPS唯一满分论文(四审稿人全给6分)由清华大学LeapLab团队(黄高老师领衔)完成,其抛出的颠覆性结论引发行业震动。真正决定大模型推理上限的是基座模型本身而非强化学习,蒸馏比RLVR(可验证奖励的强化学习)更有望实现模型自我进化——这一观点给作为OpenAI-o1、DeepSeek-R1等主流模型核心驱动力、被视为模型自我进化终极路径的RLVR泼了冷水,也让当前围绕RLVR的巨额投入与
NeurIPS唯一满分论文(四审稿人全给6分)由清华大学LeapLab团队(黄高老师领衔)完成,其抛出的颠覆性结论引发行业震动。

真正决定大模型推理上限的是基座模型本身而非强化学习,蒸馏比RLVR(可验证奖励的强化学习)更有望实现模型自我进化——这一观点给作为OpenAI-o1、DeepSeek-R1等主流模型核心驱动力、被视为模型自我进化终极路径的RLVR泼了冷水,也让当前围绕RLVR的巨额投入与探索意义引发热议。

相关论文已开源,如有需要可自取!
1. 【导读】

论文标题:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
作者:Yang Yue、Zhiqi Chen、Rui Lu、Andrew Zhao、Zhaokai Wang、Yang Yue、Shiji Song、Gao Huang
作者机构:1. LeapLab, Tsinghua University(清华大学LeapLab);2. Shanghai Jiao Tong University(上海交通大学)
论文来源:NeurIPS 2025 Oral,ICML 2025 Workshop AI4Math Best Paper Award
论文链接:https://openreview.net/pdf?id=4OsgYD7em5
项目链接:https://limit-of-rlvr.github.io
2. 【论文速读】
本文聚焦大模型推理能力进化路径,颠覆性指出真正决定推理上限的是基座模型本身,而非正炙手可热的RLVR(可验证奖励的强化学习);研究通过系统实验对比,表明蒸馏方法更有望实现大模型自我进化,这一结论对当前围绕RLVR的巨额投入与探索提出关键质疑,为大模型推理能力进化研究提供了全新视角。

3.【RLVR的“王座”,突然晃了?】
3.1 推理进化的“RLVR狂热”
大模型推理范式开启后,RLVR(可验证奖励的强化学习)因无需人工标注、可自动优化模型,成为OpenAI-o1、DeepSeek-R1等主流模型的核心驱动力,被视作实现模型自我进化、逼近更高推理能力的“终极路径”,行业围绕其展开巨额投入与探索。
3.2 清华上交的“逆声”挑战
来自清华大学LeapLab与上海交通大学的团队,针对“RLVR是否真能突破基座模型上限”这一核心问题,开展了系统性研究,试图从根本上验证RLVR在大模型推理进化中的实际价值。
3.3 结论的“地震级”冲击
研究最终得出颠覆性结论:真正决定推理上限的是基座模型本身而非强化学习,蒸馏方法更有望实现大模型自我进化,这一发现给RLVR的“王座”泼下冷水,也让行业对现有技术路径的意义产生深刻反思。
4.【推理进化的“技术基石”,先盘明白!】
4.1 基座模型(Base Model)
设基座模型为 M b M_b Mb,其通过大规模无监督预训练学习通用知识与基础推理能力,是大模型推理能力的“底层根基”,记其推理能力上限为 C b C_b Cb。
4.2 强化学习(RL)与RLVR
- 强化学习框架中,模型 M M M通过与环境交互获取奖励信号 r r r,以策略 π \pi π优化目标函数 J ( π ) = E s ∼ S , a ∼ π [ r ( s , a ) ] J(\pi)=\mathbb{E}_{s\sim\mathcal{S}, a\sim\pi}[r(s,a)] J(π)=Es∼S,a∼π[r(s,a)]。
- RLVR(可验证奖励的强化学习)是针对大模型推理的强化学习范式,通过自动构建可验证的奖励函数,试图让模型 M r l M_{rl} Mrl在推理任务上超越基座模型,即期望 C r l > C b C_{rl} > C_b Crl>Cb。
4.3 蒸馏(Distillation)
蒸馏是将复杂模型(如教师模型 M t M_t Mt)的知识迁移到简单模型(如学生模型 M s M_s Ms)的方法,目标是最小化蒸馏损失 L d i s t i l l ( M s , M t ) \mathcal{L}_{distill}(M_s, M_t) Ldistill(Ms,Mt),使 M s M_s Ms在推理能力上逼近甚至超越 M t M_t Mt,本文聚焦其在大模型自我进化中的作用,记蒸馏后模型推理能力为 C d C_d Cd。
5.【RLVR“神化”破局:推理边界竟在收缩?】
5.1 实验核心设计:多维度覆盖+公平评估
- 模型与任务:涵盖Qwen2.5(7B/14B/32B)、LLaMA-3.1-8B等模型家族,聚焦数学推理(GSM8K、AIME24等)、代码生成(LiveCodeBench等)、视觉推理(MathVistaTestMini等)三大任务域。
- 评估标准:采用pass@k metric(k为采样次数),通过多轮采样规避“单次尝试低估模型潜力”问题,以平均pass@k反映模型可解问题比例,更精准衡量推理边界。
- 实验控制:base模型与RLVR模型使用相同零样本提示,排除上下文示例干扰;采样温度设为0.6、最大生成长度16384 tokens,确保对比公平性。
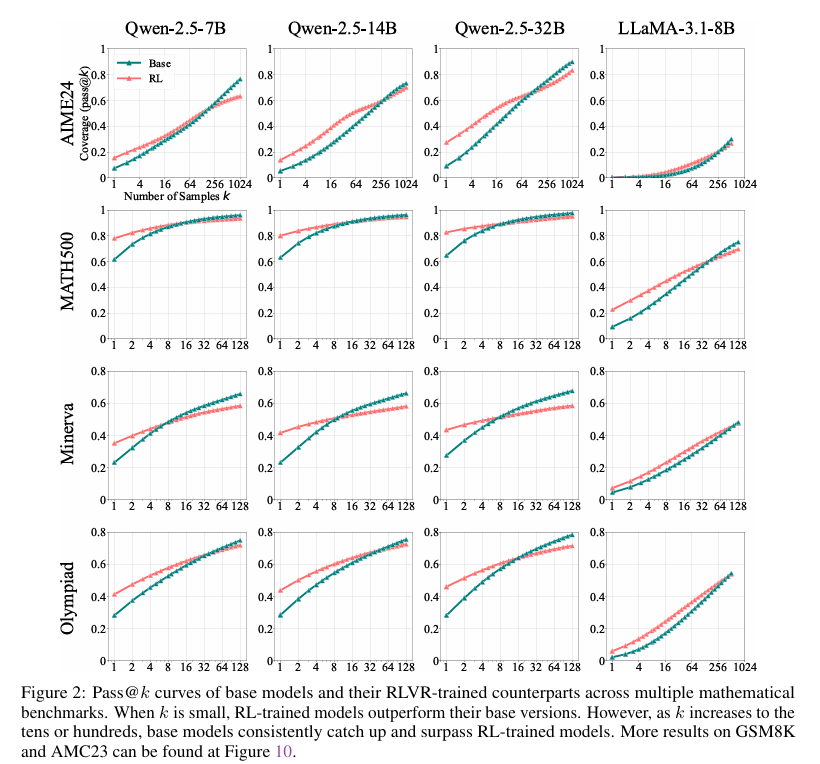
5.2 数学推理:小k领先,大k被base反超
-
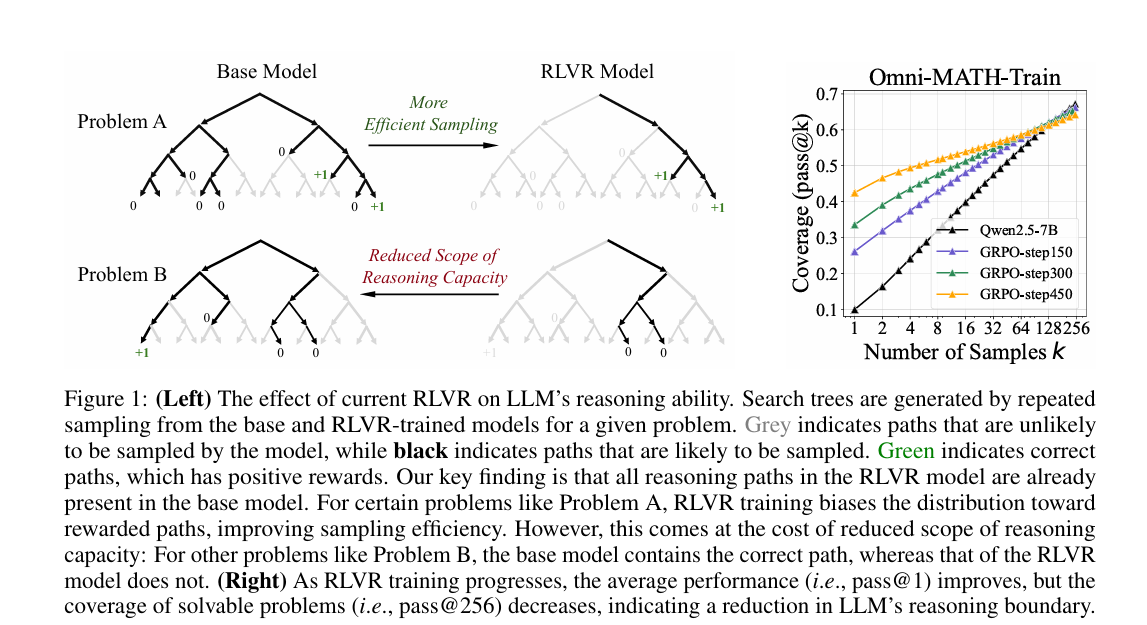
短期优势:RLVR模型在k较小时(如k=1)表现优于base模型,因RL优化提升了正确路径的采样效率。
-
长期局限:随k增大(如k=128/256),base模型pass@k持续上升并反超RLVR模型,例如Minerva基准下32B模型,base比RLVR高约9%,表明RLVR未拓展可解问题范围,反而缩小推理覆盖。
-
CoT验证:手动检查AIME24等难题的推理链(CoT),发现base模型能生成有效推理路径,RLVR模型的正确路径均来自base模型已有分布。
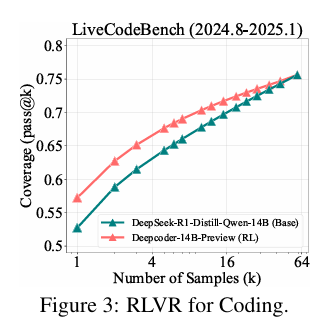
5.3 代码生成:与数学推理趋势高度一致
- 验证可靠性:代码任务依赖编译器与单元测试验证,pass@k无“猜测正确”干扰,结果更可靠。
- 核心发现:RLVR模型(如CodeR1-Zero-Qwen2.5-7B、DeepCoder-14B)在LiveCodeBench等基准中,仍呈现“小k优于base、大k被base超越”的规律,进一步证明RLVR对推理边界的收缩效应。
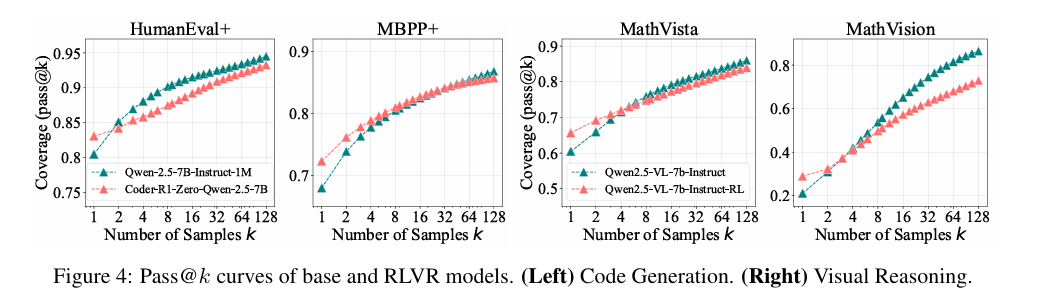
5.4 视觉推理:跨模态任务结论不变
- 任务设定:以视觉语境下的数学推理为目标,基于Qwen2.5-VL-7B模型,在MathVistaTestMini、MathVision-TestMini基准评估。
- 实验结果:RLVR模型虽在低k时提升采样效率,但随k增大,base模型的推理覆盖优势仍会显现,说明RLVR的局限不局限于单模态,在跨模态推理中同样存在。
6.【深挖RLVR“短板”:推理路径藏在哪?】
6.1 推理路径:全来自基座模型,无新增
-
准确性分布分析:RLVR训练会提升模型高准确率(接近1.0)路径的出现频率,同时增加准确率为0的路径占比,说明其仅优化已有可解问题的采样效率,未解决新问题,反而让部分问题从“可解”变“不可解”。
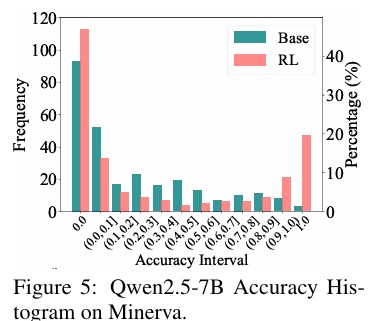
-
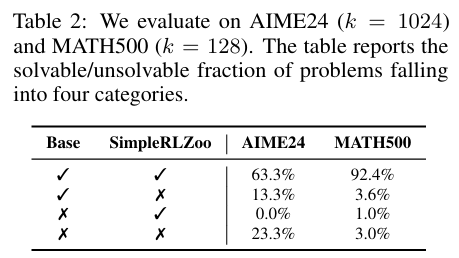
可解问题覆盖对比:在AIME24、MATH500等基准中,RLVR模型能解决的问题几乎是基座模型可解问题的子集,极少存在RLVR可解而基座模型不可解的情况(如MATH500中仅1%),且这些极少数问题在基座模型大k采样(如k=1024)时也能解决。
-
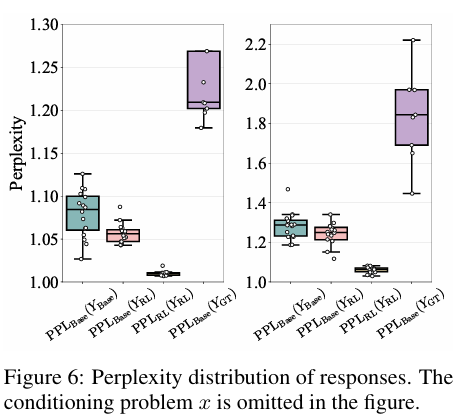
困惑度验证:通过计算基座模型对RLVR模型生成路径的困惑度( P P L m ( Y ∣ x ) = e x p ( − 1 T ∑ t = 1 T l o g P ( y t ∣ x , y 1 , . . . , y t − 1 ) ) PPL_{m}(Y | x)=exp \left(-\frac{1}{T} \sum_{t=1}^{T} log P\left(y_{t} | x, y_{1}, ..., y_{t-1}\right)\right) PPLm(Y∣x)=exp(−T1∑t=1TlogP(yt∣x,y1,...,yt−1))),发现RLVR路径的困惑度分布与基座模型高频生成路径高度重合,且随RL训练推进,困惑度逐渐降低,证明RLVR仅“强化”基座模型已有路径,未拓展新路径。
6.2 蒸馏vs RLVR:前者才是“破界”关键
- 核心差异:RLVR受限于基座模型能力边界,而蒸馏可将更强教师模型的推理模式迁移到学生模型。
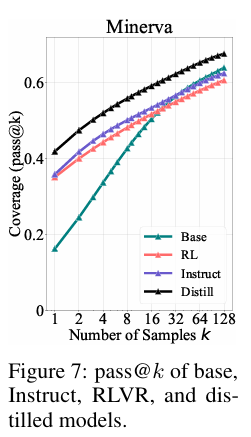
- 实验佐证:以DeepSeek-R1-Distill-Qwen-7B为例,其pass@k曲线在Minerva基准中持续高于基座模型及RLVR模型(如Qwen2.5-Math-7B-Oat-Zero),说明蒸馏能让模型突破基座模型上限,真正拓展推理边界。
6.3 不同RL算法:表现相近,均远非最优
- 采样效率差距定义:提出 Δ S E \Delta_{SE} ΔSE(RL模型pass@1与基座模型pass@256的差值)衡量算法接近最优的程度, Δ S E \Delta_{SE} ΔSE越小越优。
- 实验结果:PPO、GRPO、Reinforce++等6种主流RL算法, Δ S E \Delta_{SE} ΔSE在不同基准中仅小幅波动(如GRPO为43.9,RLOO最优为42.6),且均保持在40以上,说明现有RL算法虽提升采样效率,但距离充分利用基座模型潜力的“最优状态”仍有巨大差距。
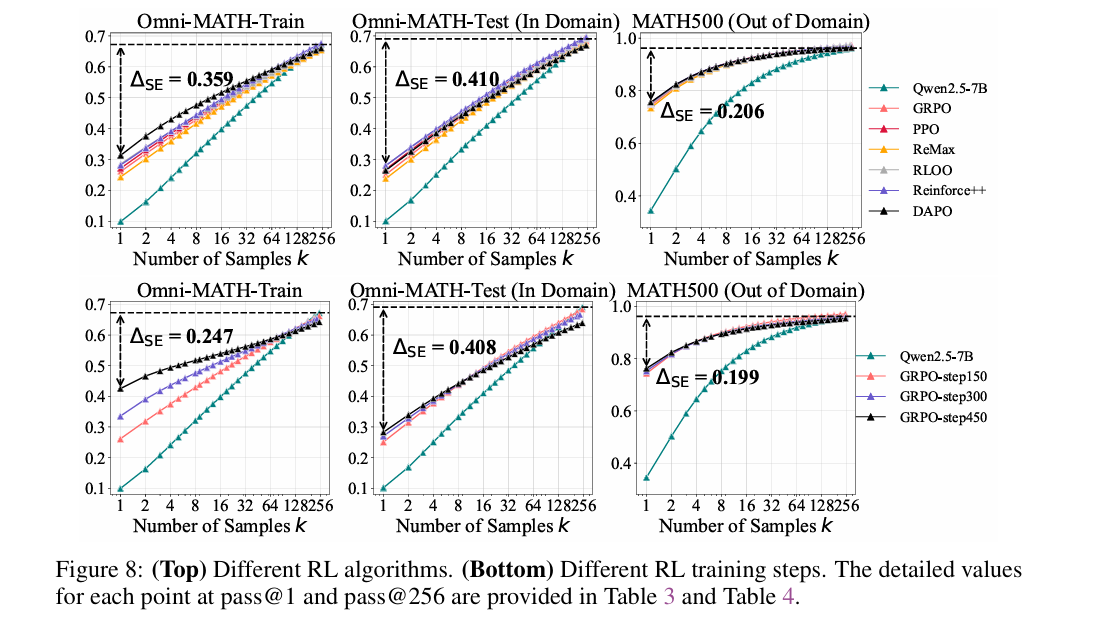
6.4 RL训练:步数越多,推理边界越窄
- 训练步数影响:随RL训练步数增加(如GRPO从150步到450步),模型pass@1(平均性能)持续提升(从26.1到42.5),但pass@256(可解问题覆盖)逐渐下降(如Omni-MATH-Test基准中从68.3降至63.9),证明训练会让模型“聚焦”已有正确路径,牺牲推理多样性。
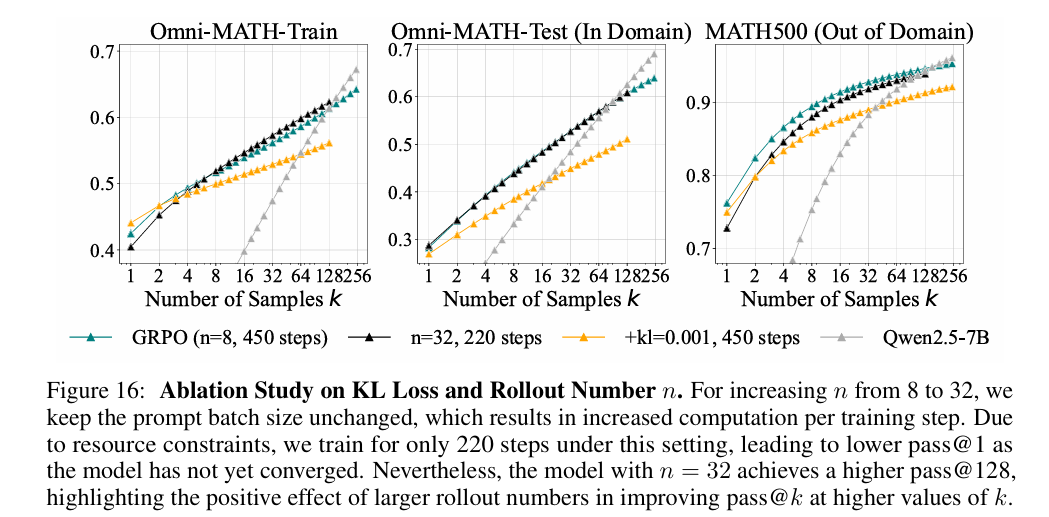
- 其他参数影响:增大每提示采样数(n从8到32)或添加KL损失约束,虽能小幅改善RL模型高k性能,但仍无法超越基座模型;提升RL模型生成温度以匹配基座模型熵值,也仅能轻微提升pass@k,无法改变“推理边界窄于基座模型”的核心结论。
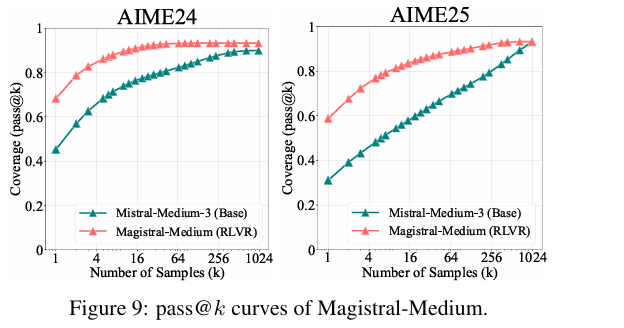
6.5 模型规模:大模型也逃不过RLVR局限
- 实验对象:选取Magistral-Medium(基于Mistral-Medium-3训练的纯RL模型,性能接近DeepSeek-R1)进行测试。
- 结果规律:该模型仍呈现“低k优于基座模型、高k被反超”的趋势,如AIME24中k=1时RL模型多解7题,但k增大后差距持续缩小,说明RLVR的局限不随模型规模扩大而消失。
7.【RLVR“祛魅”与进化新方向】
本文通过多模型、多任务、多算法的系统实验,颠覆了“RLVR是大模型推理自我进化终极路径”的认知:当前RLVR仅能提升基座模型已有正确路径的采样效率,无法生成新推理模式,且会缩小模型推理边界,其能力始终受限于基座模型;而蒸馏可通过迁移教师模型知识真正拓展推理边界。未来需探索更优RL范式,如持续规模扩展、多轮智能体-环境交互等,以突破现有局限,释放RL在大模型推理进化中的潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)