最佳实践|“手搓” GraphRAG 应用,社区开发者实战经验全公开
本文来自TuGraph社区开发者张哲源,分享了他改进GraphRAG并实践应用的经验。作者目前就职于中科数睿,拥有4年AI开发经验,同时也是多个数据库产品认证的数据库专家。
GraphRAG是一个创新的知识检索与问答增强框架,它巧妙地结合了图数据库技术与检索增强生成(RAG)方法。GraphRAG往往在处理复杂数据关系任务上取得比传统RAG更好的效果,是当下LLM领域热门的工程方向之一。
去年,TuGraph图数据库作为底层的图存储系统,联合AI工程框架DB-GPT、知识图谱系统OpenSPG,设计了一个通用的开源RAG框架,以兼容未来多样化的基础研究建设和工程化应用诉求。
本文来自TuGraph社区开发者张哲源,分享了他改进GraphRAG并实践应用的经验。作者目前就职于中科数睿,拥有4年AI开发经验,同时也是多个数据库产品认证的数据库专家。
一、行业与技术背景
随着人工智能、大数据与自然语言处理技术的快速发展,各行业中数据量呈爆炸式增长,不同来源(文档、数据库、API、知识图谱等)的信息呈现碎片化、多样化特征。传统的信息检索方法(关键词或向量检索)虽然能在一定程度上提升检索效率,但往往难以充分挖掘数据之间的“隐含”关联,难以支撑复杂推理和跨文档、多跳检索需求。
知识图谱作为一种以“实体—关系”形式刻画知识的结构化表示,能够直观表达多源异构数据中的语义关联,支持图算法进行路径查询和关系推理;而 Retrieval-Augmented Generation(RAG)技术则通过“检索 + 生成”模式,将外部知识注入预训练大模型,实现了对开放域问答、智能摘要、决策支持等场景下高质量答案的生成。将知识图谱与 RAG 融合,即 Graph RAG,便在此背景下应运而生。本文基于社区 GraphRAG 版本做了一定的改进。
二、方案验证的环境
Ubuntu 20.04.6 LTS
Python 3.12
TuGraph 4.5.1
三、算法逻辑
3.1 文档读取:
为了方便大家快捷验证。我提供了doc、docx、txt 的解析代码。
import os
import re
import struct
import sys
import olefile
from docx import Document as DocxDocument
from typing import List, Tuple, Dict, Any
ANSI_TO_UNICODE: Dict[int, int] = {
0x82: 0x201A, 0x83: 0x0192, 0x84: 0x201E, 0x85: 0x2026,
0x86: 0x2020, 0x87: 0x2021, 0x88: 0x02C6, 0x89: 0x2030,
0x8A: 0x0160, 0x8B: 0x2039, 0x8C: 0x0152, 0x91: 0x2018,
0x92: 0x2019, 0x93: 0x201C, 0x94: 0x201D, 0x95: 0x2022,
0x96: 0x2013, 0x97: 0x2014, 0x98: 0x02DC, 0x99: 0x2122,
0x9A: 0x0161, 0x9B: 0x203A, 0x9C: 0x0153, 0x9F: 0x0178,
}
_FIELD_RE = re.compile(r'\bPAGE\b|\bMERGEFORMAT\b', re.IGNORECASE)
_TABLE_FRAGMENT_RE = re.compile(r'^[\d\.\-\t ]+$') # 只含数字、点、连字符、制表符、空格
def _clean_text(text: str) -> str:
cleaned = ''.join(ch for ch in text if ch.isprintable() or ch in '\t\r\n ')
return re.sub(r'[ \t]+', ' ', cleaned).strip()
def parse_docx(path: str) -> List[Tuple[int, str]]:
doc = DocxDocument(path)
lines = []
for idx, para in enumerate(doc.paragraphs, start=1):
txt = para.text.strip()
if txt and not txt.startswith('附件'):
lines.append((idx, txt))
if txt.startswith('附件'):
break
return lines
def parse_txt(path: str) -> List[Tuple[int, str]]:
lines = []
with open(path, encoding='utf-8', errors='ignore') as f:
for idx, line in enumerate(f, start=1):
txt = line.strip()
if not txt:
continue
if txt.startswith('附件'):
break
lines.append((idx, txt))
return lines
def _read_fib(stream) -> Dict[str, Any]:
stream.seek(0)
# Skip header
stream.read(64)
fib_rg_lw = stream.read(88)
ccpText = struct.unpack("<I", fib_rg_lw[12:16])[0]
cb = struct.unpack("<H", stream.read(2))[0]
blob = stream.read(cb * 8)
csw_new = struct.unpack("<H", stream.read(2))[0]
if csw_new:
stream.read(csw_new * 2)
return {
'ccpText': ccpText,
'fcClx': struct.unpack("<I", blob[0x108:0x10C])[0],
'lcbClx': struct.unpack("<I", blob[0x10C:0x110])[0],
'fcPlcfBtePapx': struct.unpack("<I", blob[0x68:0x6C])[0],
'lcbPlcfBtePapx': struct.unpack("<I", blob[0x6C:0x70])[0],
}
def _read_clx(table_stream, fc_clx: int, lcb_clx: int) -> bytes:
table_stream.seek(fc_clx)
data = table_stream.read(lcb_clx)
return data if data and data[0] == 0x02 else b''
def _parse_plc_pcd(pcdt_data: bytes) -> List[Dict[str, Any]]:
lcb = struct.unpack("<I", pcdt_data[1:5])[0]
plc = pcdt_data[5:5 + lcb]
n = (lcb - 4) // 12
aCP = [struct.unpack("<I", plc[i*4:(i+1)*4])[0] for i in range(n+1)]
pieces = []
base = (n+1)*4
for i in range(n):
part = plc[base + i*8: base + (i+1)*8]
raw_fc = int.from_bytes(part[2:6], 'little')
pieces.append({
'fc': raw_fc & ~1,
'start_cp': aCP[i],
'end_cp': aCP[i+1],
'compressed': bool((raw_fc >> 1) & 1)
})
return pieces
def extract_paragraphs_from_doc(path: str) -> List[str]:
ole = olefile.OleFileIO(path)
wd = ole.openstream('WordDocument')
ts = '0Table' if ole.exists('0Table') else '1Table'
tb = ole.openstream(ts)
fib = _read_fib(wd)
clx = _read_clx(tb, fib['fcClx'], fib['lcbClx'])
pieces = _parse_plc_pcd(clx) if clx else []
paragraphs = []
for piece in pieces:
raw_chars = []
for cp in range(piece['start_cp'], piece['end_cp']):
offset = piece['fc'] + (cp - piece['start_cp']) * (1 if piece['compressed'] else 2)
wd.seek(offset)
if piece['compressed']:
code = wd.read(1)[0]
raw_chars.append(chr(ANSI_TO_UNICODE.get(code, code)))
else:
raw_chars.append(wd.read(2).decode('utf-16-le', errors='ignore'))
raw_text = ''.join(raw_chars)
for sub in re.split(r'[\r\n]+', raw_text):
text = _clean_text(sub)
if not text or _FIELD_RE.search(text) or _TABLE_FRAGMENT_RE.fullmatch(text):
continue
if text.startswith('附件'):
ole.close()
return paragraphs
paragraphs.append(text)
ole.close()
return paragraphs
def parse_document(path: str) -> List[Tuple[int, str]]:
ext = os.path.splitext(path)[1].lower()
if ext == '.docx':
return parse_docx(path)
if ext == '.txt':
return parse_txt(path)
if ext == '.doc':
return [(i+1, p) for i, p in enumerate(extract_paragraphs_from_doc(path))]
raise ValueError(f"Unsupported format: {ext}")
3.2 构建知识抽取并通过正则提取到 TuGraph 中:
注意:要根据自己的垂于修改提示词。为了方便大家验证,提供抽取三元组的代码。导入 TuGraph 由于涉及到了数据不做提供。
import asyncio
import re
import json
import tomllib
import pandas as pd
from tqdm.asyncio import tqdm_asyncio
from openai import AsyncOpenAI
from document_parse import parse_document
with open("config.toml", "rb") as f:
cfg = tomllib.load(f)["openai"]
client = AsyncOpenAI(
api_key=cfg["api_key"],
base_url=cfg.get("base_url", "https://api.openai.com/v1"),
)
PROMPT = """你是一个结构化信息提取助手,请从给定的中文文本中抽取所有实体及它们之间的关系。
将结果以严格的 JSON 数组格式输出,数组中的每个元素都是一个对象,包含 "subject"、"predicate"、"object" 三个字段。
不要输出任何多余说明或文本,只要合法的 JSON。
示例输入:
“Acme公司注册资本为500万元,法定代表人为张三。Acme公司的子公司为Beta公司。”
示例输出:
[
{ "subject": "Acme公司", "predicate": "注册资本", "object": "500万元" },
{ "subject": "张三", "predicate": "法定代表人", "object": "Acme公司" },
{ "subject": "Acme公司", "predicate": "子公司", "object": "Beta公司" }
]
文本:
「{chunk}」
"""
async def _extract(chunks, model, concurrency=5):
sem = asyncio.Semaphore(concurrency)
triples = []
async def job(i, txt):
async with sem:
resp = await client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": PROMPT.format(chunk=txt[:8000])}],
temperature=0,
)
content = resp.choices[0].message.content.strip()
try:
data = json.loads(content)
for obj in data:
h = obj.get("subject", "").strip()
r = obj.get("predicate", "").strip()
t = obj.get("object", "").strip()
if h and r and t:
triples.append((h, r, t, i))
except json.JSONDecodeError:
for line in content.splitlines():
text = line.strip("()() ")
if not text:
continue
parts = re.split(r"[,,]", text, maxsplit=2)
if len(parts) == 3:
triples.append((*map(str.strip, parts), i))
await tqdm_asyncio.gather(*[job(i, t) for i, t in enumerate(chunks)])
return triples
async def run_pipeline(file_path: str,
out_csv: str | None = None,
model: str | None = None):
texts = [t for _, t in parse_document(file_path)]
triples = await _extract(texts, model or cfg["model"])
for head, rel, tail, idx in triples:
print(f"({head}, {rel}, {tail}) [chunk #{idx+1}]")
if out_csv:
pd.DataFrame(triples, columns=["subject", "predicate", "object", "chunk"]) \
.to_csv(out_csv, index=False, encoding="utf-8-sig")
四、完成构建
然后让大模型把维度数据(对实体的描述、对关系的描述这类非常长的纯文本)存入 RAG 库,指标数据(实体的数值属性比如人的年龄)存入 MySQL。即可完成构建。
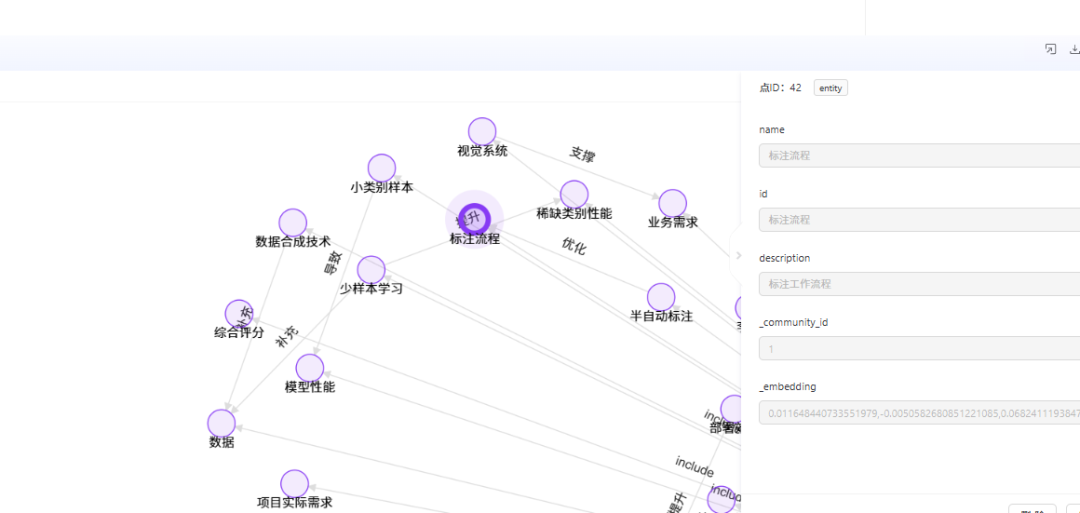
此外,TuGraph 双击就可以显示这个实体涉及到的实体关系非常棒
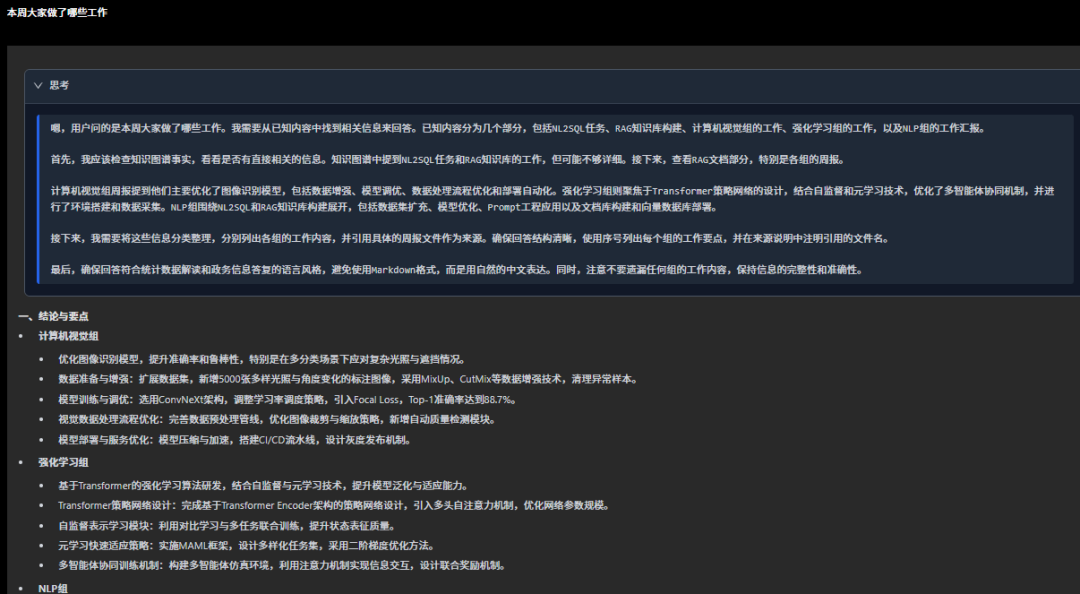
五、效果展示
让我们看看问答效果吧。我们录入了脱敏的工作周报,首先我询问整体的情况。这个比较适合领导看,因为所有组的周报大模型都会回答而且模型会筛选出重点数据。由于是全局不标注来源,因为来源可能很多。细节问题会标注,这个完了会测试细节问题。
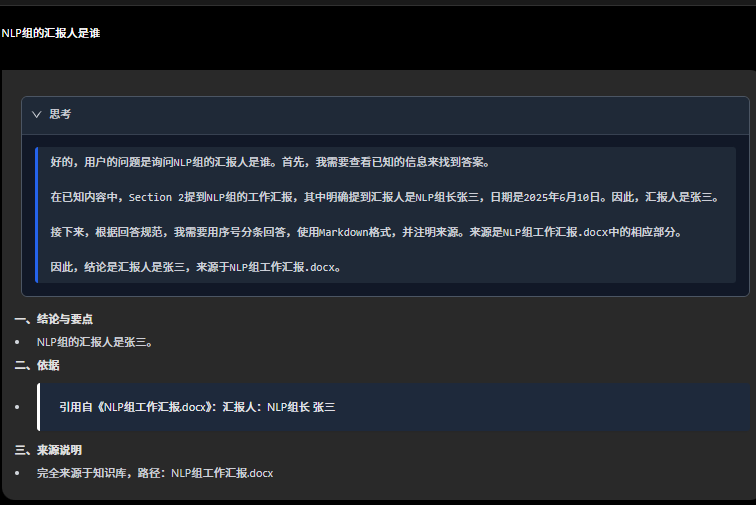
在询问局部的情况,可以定位到来源那个文件,方便用户快速核验。毕竟AI有幻觉问题。
优化后的优势:
1.统筹图社区的知识点,更适合领导进行规划。
2.询问局部的情况,可定位到来源文件,方便用户快速核验。
3.回答可统一关系型数据库、图数据库和文档的内容。
六、总结
最后总结下构建 GraphRAG 的核心流程:
- 文本分块 & 第一轮抽取:固定大小的文本块送入大模型,输出三等长数组,组成 ⟨实体 1, 关系, 实体 2⟩ 三元组。
- 不完整句检测:若发现句子未完或出现代词,取最近 k 个三元组作为上下文,拼接后续文本。
- 第二轮解析——补充上下文:模型在新上下文中完成指代消解,再次抽取并与第一次结果去重、合并。
- 分层存储——不用再担心维度数据难以修改的问题:实体节点、关系与维度属性写入 TuGraph;数值指标落到 MySQL。
- 流式循环:写库后立即清空数组、复位下标,进入下一文本块,保持解析流水线。
- 动态检索——抑制模型幻觉:用户提问时,LLM 先评估问题复杂度,在TuGraph中查询是否存在相应实体,再决定是否调用向量检索、图查询或外部 API。
- 占位符输出——抑制模型幻觉:推理中遇到外部调用,模型用 §GRAPH§、§MYSQL§ 等占位符输出草稿答案。
- 回填呈现:前端并行执行实际查询,将结果回填占位符,生成完整、可解释的最终回答。
优势与局限性
- 优势:适合对准确率和速度要求较高的领域(金融、政务、供应链)
- 减少模型幻觉 —— 模型只能回答知识图谱中存在的实体问题+占位符回填
- 检索并行加速 —— 生成与外部调用同步执行
- 维度和指标数据准确率几乎为100% —— 占位符回填。
- 支持多跳推理与复杂查询 —— TuGraph 子图遍历
- 任一组件可独立迭代 —— 检索或指标 API 随时替换
- 局限性:不适合趋势分析、创意写作、军事等领域
- 无法处理回答类似发展趋势之类的问题——模型生成过程中采用的是占位符。
- 内存溢出风险 —— 人物传记等长指代场景
- 前期微调与建库成本高 —— Token 与时间耗费大
- 系统运维复杂度高 —— LLM、Mysql、TuGraph 都需要维护
- 隐私与权限治理更困难 —— 占位符回填需要精细脱敏
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献424条内容
已为社区贡献424条内容

所有评论(0)