【必学】构建时序AI代理:优化RAG系统中动态知识库的完整指南(建议收藏)
文章介绍构建时序AI代理系统,通过语义分块、原子事实提取、实体解析、时序失效、知识图谱构建和优化知识库六个步骤,将动态数据转化为可查询的结构化知识。利用LangGraph自动化流水线,构建多步检索代理,使AI系统能处理时间敏感信息,解决知识过时问题,提高回答准确性和时效性。
原子事实、验证、实体解析、知识图谱等
用于问答的检索增强生成(Retrieval-Augmented Generation, RAG)或代理架构依赖于一个随时间动态更新的知识库,例如财务报告或技术文档,以确保其推理和规划步骤保持逻辑性和准确性。
为了处理这类规模持续增长且可能增加幻觉风险的知识库,您的 AI 产品中需要一个独立的逻辑-时序(时间感知)代理流水线来管理这个不断演化的知识库。该流水线包括:
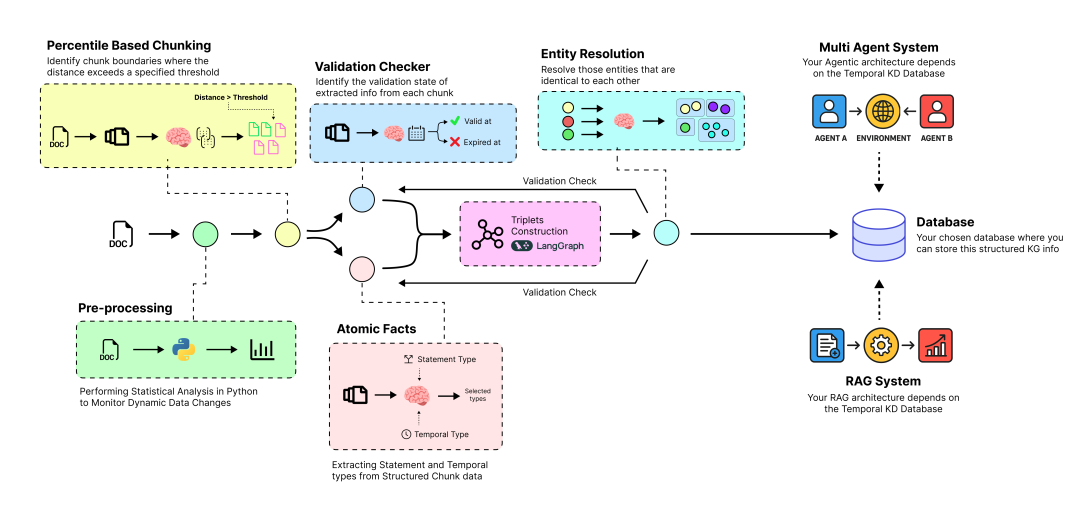
时序 AI 代理流水线 (由 Fareed Khan 创建)
-
- 语义分块 (Semantic Chunking): 将大型原始文档分解为小而具有上下文意义的文本块。
-
- 原子事实 (Atomic Facts): 使用大语言模型(LLM)读取每个文本块,并提取原子事实、其时间戳以及涉及的实体。
-
- 实体解析 (Entity Resolution): 通过自动查找和合并重复实体(例如,“AMD” 和 “Advanced Micro Devices”)来清理数据。
-
- 时序失效 (Temporal Invalidation): 当新信息出现时,通过将过时的事实标记为“已过期”,智能地识别和解决矛盾。
-
- 知识图谱构建 (Knowledge Graph Construction): 将最终的、干净的、带有时间戳的事实组装成一个互联的图结构,供我们的 AI 代理查询。
-
- 优化的知识库 (Optimized Knowledge Base): 将最终的动态知识图谱存储在可扩展的云数据库中,从而创建一个可靠、最新的“大脑”,并在此基础上构建最终的 RAG 或代理系统。
在本博客中,我们将创建……
一个端到端的时序代理流水线,它将原始数据转换为动态知识库,然后在此之上构建一个多代理系统来衡量其性能。
所有(理论 + Notebook)分步实现都可以在如下的 GitHub 仓库中找到:
GitHub - FareedKhan-dev/temporal-ai-agent-pipeline: Optimizing Dynamic Knowledge Base Using AI Agent
预处理和分析我们的动态数据
我们将处理随时间不断演化的数据集,并且……
公司的财务状况是最好的例子之一。
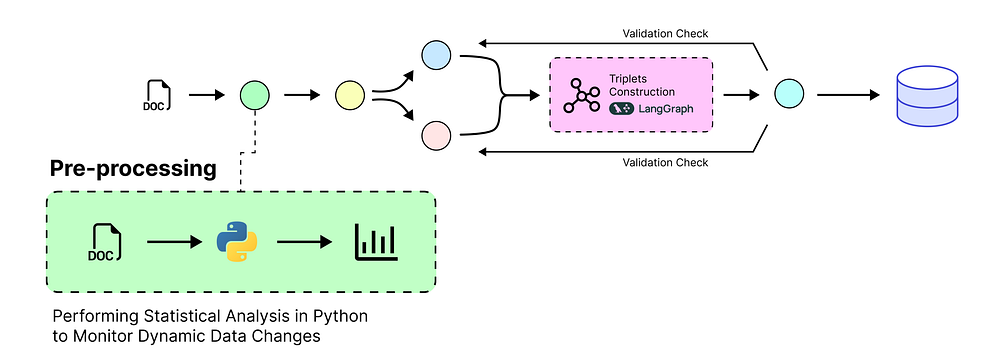
预处理步骤 (由 Fareed Khan 创建)
公司会定期分享其财务业绩的更新,例如股价变动、高管变动等重大进展,以及前瞻性预期,如季度收入预计同比增长 12% 等。
在医疗领域,ICD 编码是另一个不断演化数据的例子,从 ICD-9 到 ICD-10 的转变使诊断代码从约 14,000 个增加到 68,000 个。
为了模拟真实世界的场景,我们将使用来自 John Henning 的 earnings_call huggingface 数据集。它包含了不同公司在一段时间内的财务业绩信息。
让我们加载这个数据集并对其进行一些统计分析以熟悉它。
# Import loader for Hugging Face datasetsfrom langchain_community.document_loaders import HuggingFaceDatasetLoader# Dataset configurationhf_dataset_name = "jlh-ibm/earnings_call"# HF dataset namesubset_name = "transcripts" # Dataset subset to load# Create the loader (defaults to 'train' split)loader = HuggingFaceDatasetLoader( path=hf_dataset_name, name=subset_name, page_content_column="transcript"# Column containing the main text)# This is the key step. The loader processes the dataset and returns a list of LangChain Document objects.documents = loader.load()
我们关注的是该数据集的 transcript 子集,它包含了关于不同公司的原始文本信息。这是任何 RAG 或 AI 代理架构的基本结构和起点。
# Let's inspect the result to see the differenceprint(f"Loaded {len(documents)} documents.")#### 输出 ####Loaded 188 documents.
我们的数据中总共有 188 份财报电话会议记录(transcripts)。这些记录属于不同的公司,我们需要统计数据集中有多少家独立的公司。
# Count how many documents each company hascompany_counts = {}# Loop over all loaded documentsfor doc in documents: company = doc.metadata.get("company") # Extract company from metadata if company: company_counts[company] = company_counts.get(company, 0) + 1# Display the countsprint("Total company counts:")for company, count in company_counts.items(): print(f" - {company}: {count}")#### 输出 ####Total company counts: - AMD: 19 - AAPL: 19 - INTC: 19 - MU: 17 - GOOGL: 19 - ASML: 19 - CSCO: 19 - NVDA: 19 - AMZN: 19 - MSFT: 19
几乎所有公司的文档分布比例都相等。我们来看一个随机记录的元数据。
# Print metadata for two sample documents (index 0 and 33)print("Metadata for document[0]:")print(documents[0].metadata)print("\nMetadata for document[33]:")print(documents[33].metadata)#### 输出 ####{'company': 'AMD', 'date': datetime.date(2016, 7, 21)}{'company': 'AMZN', 'date': datetime.date(2019, 10, 24)}
company 字段指明了记录所属的公司,date 字段则表示该信息所依据的时间。
# Print the first 200 characters of the first document's contentfirst_doc = documents[0]print(first_doc.page_content[:200])#### 输出 ####Thomson Reuters StreetEvents Event TranscriptE D I T E D V E R S I O NQ2 2016 Advanced Micro Devices Inc Earnings CallJULY 21, 2016 / 9:00PM GMT=====================================...
通过打印文档样本,我们可以得到一个宏观的了解。例如,当前样本显示的是 AMD 的季度报告。
会议记录可能非常长,因为它们代表了特定时间段内的信息,并包含大量细节。我们需要检查这 188 份记录平均包含多少单词。
# Calculate the average number of words per documenttotal_words = sum(len(doc.page_content.split()) for doc in documents)average_words = total_words / len(documents) if documents else 0print(f"Average number of words in documents: {average_words:.2f}")#### 输出 ####Average number of words in documents: 8797.12
每份记录约 9000 个单词,这是相当大的篇幅,无疑包含了大量信息。但这正是我们所需要的,因为创建一个结构良好的知识库 AI 代理需要处理海量信息,而不仅仅是几个小文档。
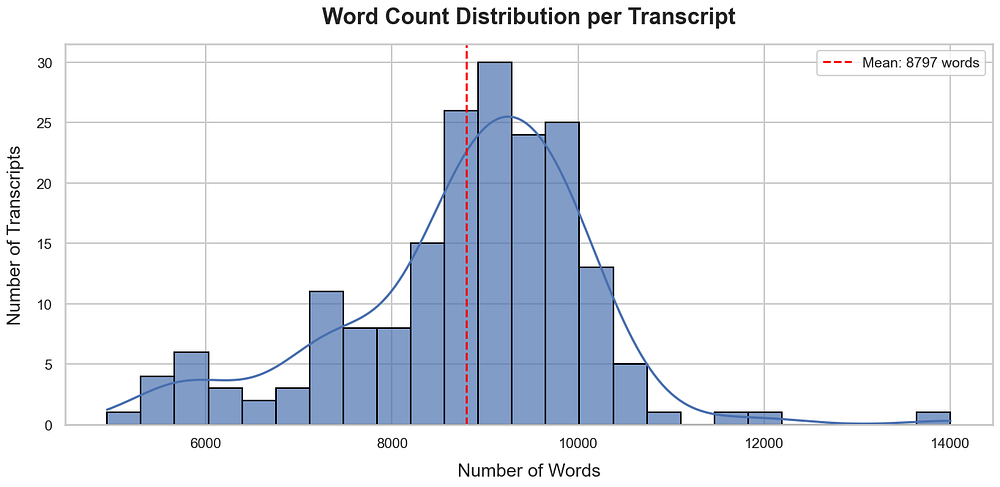
单词分布图 (由 Fareed Khan 创建)
通常,财务数据基于不同的时间段,每个时间段代表了该时期内发生的不同事件的信息。我们可以使用纯 Python 代码而不是 LLM 从记录中提取这些时间段,以节省成本。
import refrom datetime import datetime# Helper function to extract a quarter string (e.g., "Q1 2023") from textdeffind_quarter(text: str) -> str | None: """Return the first quarter-year match found in the text, or None if absent.""" # Match pattern: 'Q' followed by 1 digit, a space, and a 4-digit year match = re.findall(r"Q\d\s\d{4}", text) returnmatch[0] ifmatchelseNone# Test on the first documentquarter = find_quarter(documents[0].page_content)print(f"Extracted Quarter for the first document: {quarter}")#### 输出 ####Extracted Quarter for the first document: Q2 2016
更好的季度-日期提取方法是通过 LLM,因为它们能更深入地理解数据。然而,由于我们的数据在文本结构上已经相当规范,我们暂时可以不使用 LLM。
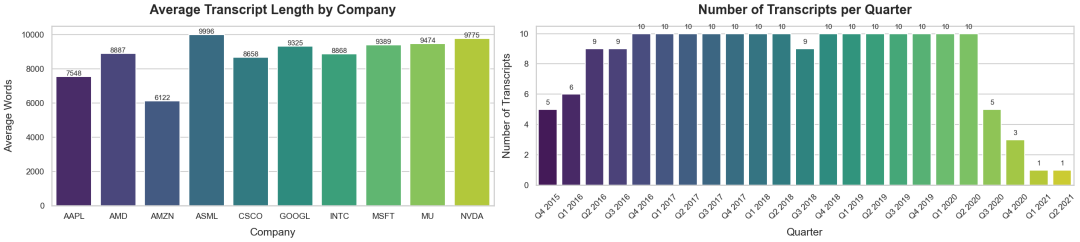
会议记录季度分析 (由 Fareed Khan 创建)
现在我们对动态数据有了初步了解,可以开始通过时序 AI 代理构建知识库了。
百分位语义分块
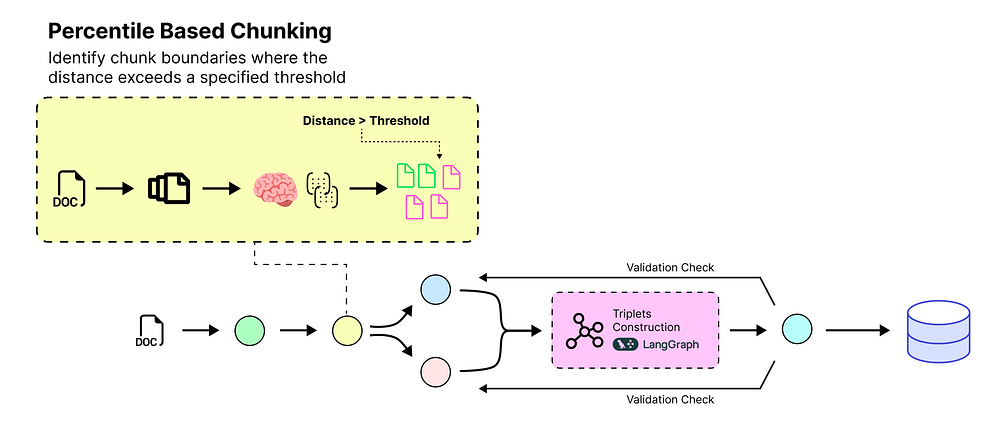
基于百分位的分块 (由 Fareed Khan 创建)
通常,我们基于随机分割或有意义的句子边界(如句号)对数据进行分块。然而,这种方法可能导致信息丢失。例如:
净利润增长了 12%,达到 210 万美元。这一增长是由较低的运营费用驱动的。
如果我们在句号处分割,就会失去“净利润增长是由于运营费用降低”这一紧密的联系。
我们将在这里使用基于百分位的分块(percentile-based chunking)。让我们先理解这种方法,然后实现它。
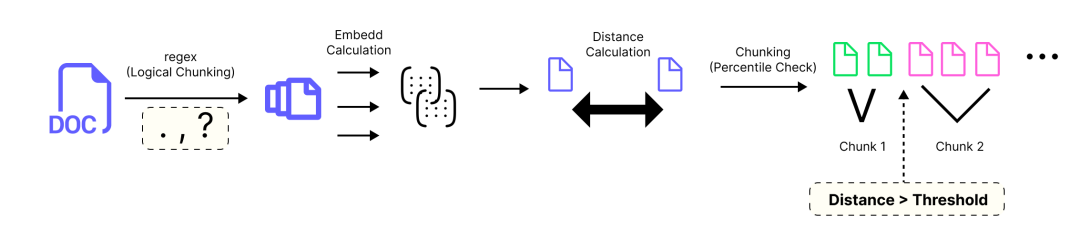
百分位分块 (由 Fareed Khan 创建)
-
- 文档使用正则表达式被分割成句子,通常在
.、?或!之后断开。
- 文档使用正则表达式被分割成句子,通常在
-
- 每个句子使用嵌入模型转换为高维向量。
-
- 计算连续句子向量之间的语义距离,较大的值表示主题变化较大。
-
- 收集所有距离,并确定所选的百分位数(例如 95%),以捕捉异常大的跳跃。
-
- 距离大于或等于此阈值的边界被标记为分块断点。
-
- 这些边界之间的句子被组合成块,应用
min_chunk_size以避免过小的块,并使用buffer_size来添加重叠(如果需要)。
- 这些边界之间的句子被组合成块,应用
from langchain_nebius import NebiusEmbeddings# Set Nebius API key (⚠️ Avoid hardcoding secrets in production code)os.environ["NEBIUS_API_KEY"] = "YOUR_API_KEY_HERE"# 1. Initialize Nebius embedding modelembeddings = NebiusEmbeddings(model="Qwen/Qwen3-Embedding-8B")
我们正在使用 Qwen3–8B 通过 LangChain 中的 Nebius AI 生成嵌入。当然,LangChain 模块下还支持许多其他嵌入服务提供商。
from langchain_experimental.text_splitter import SemanticChunker# Create a semantic chunker using percentile thresholdinglangchain_semantic_chunker = SemanticChunker( embeddings, breakpoint_threshold_type="percentile", # Use percentile-based splitting breakpoint_threshold_amount=95 # split at 95th percentile)
我们选择了 95% 的百分位值,这意味着如果连续句子之间的距离超过此值,它将被视为一个断点。使用一个循环,我们可以简单地开始对我们的记录进行分块处理。
# Store the new, smaller chunk documentschunked_documents_lc = []# Printing total number of docs (188) We already know thatprint(f"Processing {len(documents)} documents using LangChain's SemanticChunker...")# Chunk each transcript documentfor doc in tqdm(documents, desc="Chunking Transcripts with LangChain"): # Extract quarter info and copy existing metadata quarter = find_quarter(doc.page_content) parent_metadata = doc.metadata.copy() parent_metadata["quarter"] = quarter # Perform semantic chunking (returns Document objects with metadata attached) chunks = langchain_semantic_chunker.create_documents( [doc.page_content], metadatas=[parent_metadata] ) # Collect all chunks chunked_documents_lc.extend(chunks)#### 输出 ####Processing 188 documents using LangChains SemanticChunker...Chunking Transcripts with LangChain: 100%|██████████| 188/188 [01:03:44<00:00, 224.91s/it]
这个过程会花费很长时间,因为我们之前看到,每份记录大约有 8000 个单词。为了加快速度,我们可以使用异步函数来减少运行时间。然而,为了便于理解,这个循环恰好完成了我们想要实现的目标。
# Analyze the results of the LangChain chunking processoriginal_doc_count = len(docs_to_process)chunked_doc_count = len(chunked_documents_lc)print(f"Original number of documents (transcripts): {original_doc_count}")print(f"Number of new documents (chunks): {chunked_doc_count}")print(f"Average chunks per transcript: {chunked_doc_count / original_doc_count:.2f}")#### 输出 ####Original number of documents (transcripts): 188Number of new documents (chunks): 3556Average chunks per transcript: 19.00
我们平均每份记录有 19 个文本块。让我们检查其中一份记录的一个随机块。
# Inspect the 11th chunk (index 10)sample_chunk = chunked_documents_lc[10]print("Sample Chunk Content (first 30 chars):")print(sample_chunk.page_content[:30] + "...")print("\nSample Chunk Metadata:")print(sample_chunk.metadata)# Calculate average word count per chunktotal_chunk_words = sum(len(doc.page_content.split()) for doc in chunked_documents_lc)average_chunk_words = total_chunk_words / chunked_doc_count if chunked_documents_lc else0print(f"\nAverage number of words per chunk: {average_chunk_words:.2f}")#### 输出 ####Sample Chunk Content (first 30 chars):No, that is a fair question, Matt. So we have been very focused ...Sample Chunk Metadata:{'company': 'AMD', 'date': datetime.date(2016, 7, 21), 'quarter': 'Q2 2016'}Average number of words per chunk: 445.42
我们的文本块元数据略有变化,包含了一些额外信息,比如该块所属的季度,以及一个 Python 友好的日期时间格式,便于检索。
使用陈述代理提取原子事实
既然我们的数据已经整齐地组织成小而有意义的块,我们就可以开始使用 LLM 来读取这些块并提取核心事实了。
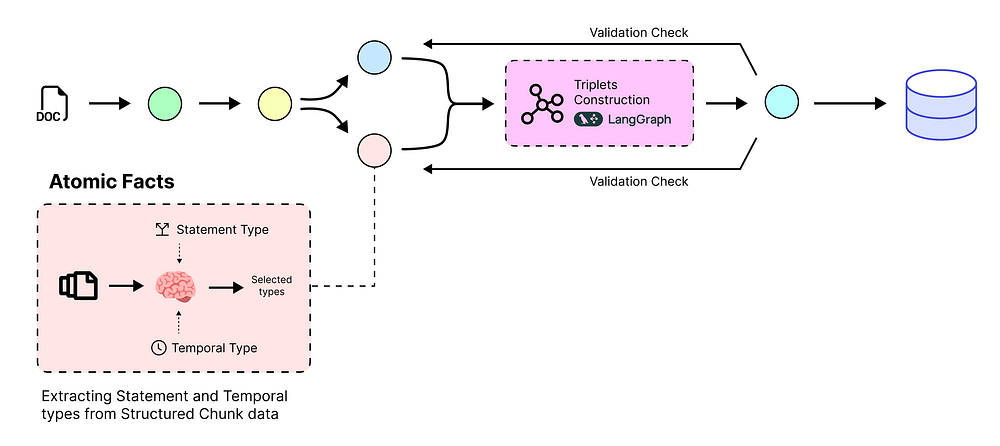
原子事实提取 (由 Fareed Khan 创建)
为什么首先提取陈述?
我们需要将文本分解为尽可能小的“原子”事实。例如,我们不想要一个复杂的句子,而是想要可以独立存在的单个声明。
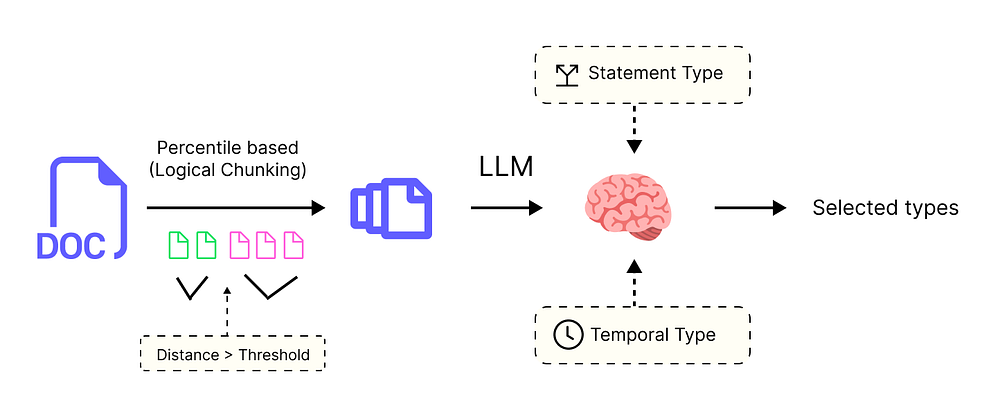
原子事实提取流程 (由 Fareed Khan 创建)
这个过程使得信息更容易被我们的 AI 系统在后续阶段理解、查询和推理。
为了确保我们的 LLM 给出干净、可预测的输出,我们需要给它一套严格的指令。在 Python 中,最好的方法是使用 Pydantic 模型。这些模型充当了 LLM 必须遵循的“模式”或“模板”。
首先,让我们使用枚举(Enums)来定义标签的允许类别。我们使用的是 (str, Enum)。
from enum import Enum# Enum for temporal labels describing time sensitivityclass TemporalType(str, Enum): ATEMPORAL = "ATEMPORAL" # Facts that are always true (e.g., "Earth is a planet") STATIC = "STATIC" # Facts about a single point in time (e.g., "Product X launched on Jan 1st") DYNAMIC = "DYNAMIC" # Facts describing an ongoing state (e.g., "Lisa Su is the CEO")
每个类别捕捉了一种不同类型的时间参考:
- • 非时序 (Atemporal): 普遍为真且不随时间变化的陈述(例如,“水在 100 摄氏度时沸腾。”)。
- • 静态 (Static): 在特定时间点变为真并此后保持不变的陈述(例如,“John 于 2020 年 6 月 1 日被聘为经理。”)。
- • 动态 (Dynamic): 可能随时间变化并且需要时间上下文才能准确解释的陈述(例如,“John 是团队的经理。”)。
# Enum for statement labels classifying statement natureclass StatementType(str, Enum): FACT = "FACT" # An objective, verifiable claim OPINION = "OPINION" # A subjective belief or judgment PREDICTION = "PREDICTION" # A statement about a future event
StatementType 枚举显示了每个陈述的类型。
- • 事实 (Fact): 在陈述时为真的陈述,但之后可能会改变(例如,“公司上个季度赚了 500 万美元。”)。
- • 观点 (Opinion): 个人信念或感觉,仅在陈述时为真(例如,“我认为这个产品会表现得很好。”)。
- • 预测 (Prediction): 对未来的猜测,从现在到预测时间结束前都为真(例如,“明年的销售额将会增长。”)。
通过定义这些固定的类别,我们确保了代理在分类其提取的信息时的一致性。
现在,让我们创建将使用这些枚举来定义输出结构的 Pydantic 模型。
from pydantic import BaseModel, field_validator# This model defines the structure for a single extracted statementclass RawStatement(BaseModel): statement: str statement_type: StatementType temporal_type: TemporalType# This model is a container for the list of statements from one chunkclass RawStatementList(BaseModel): statements: list[RawStatement]
这些模型是我们与 LLM 之间的“合同”。我们告诉它:“当你处理完一个文本块后,你的答案必须是一个 JSON 对象,其中包含一个名为‘statements’的列表,列表中的每个项目都必须有 statement、statement_type 和 temporal_type”。
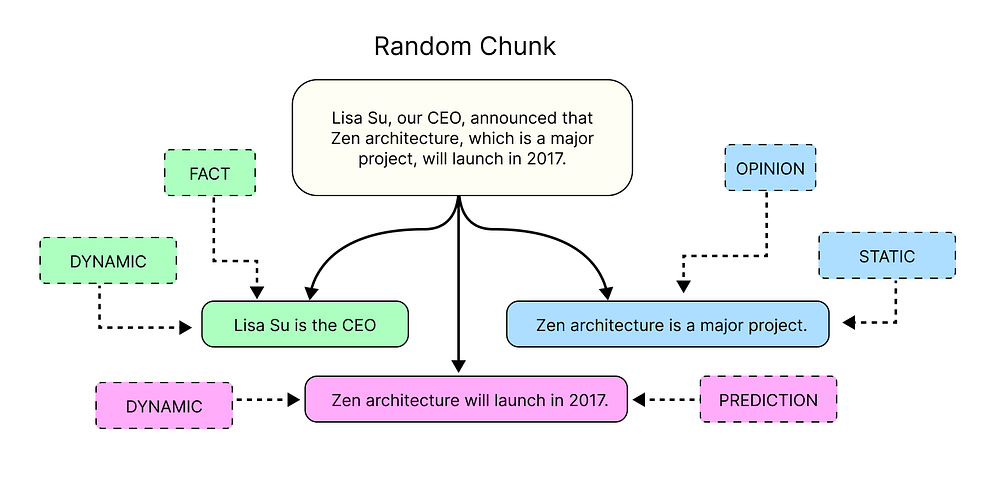
原子事实提取 (由 Fareed Khan 创建)
让我们为提供给 LLM 的标签创建上下文定义。这有助于它理解 FACT 和 OPINION,或 STATIC 和 DYNAMIC 陈述之间的区别。
# These definitions provide the necessary context for the LLM to understand the labels.LABEL_DEFINITIONS: dict[str, dict[str, dict[str, str]]] = { "episode_labelling": { "FACT": dict(definition="Statements that are objective and can be independently verified or falsified through evidence."), "OPINION": dict(definition="Statements that contain personal opinions, feelings, values, or judgments that are not independently verifiable."), "PREDICTION": dict(definition="Uncertain statements about the future on something that might happen, a hypothetical outcome, unverified claims."), }, "temporal_labelling": { "STATIC": dict(definition="Often past tense, think -ed verbs, describing single points-in-time."), "DYNAMIC": dict(definition="Often present tense, think -ing verbs, describing a period of time."), "ATEMPORAL": dict(definition="Statements that will always hold true regardless of time."), },}
这些定义只是每个标签的描述。它们通过解释为什么应该将特定标签分配给提取的信息,为 LLM 提供了更好的支持。现在,我们需要使用这些定义创建提示模板。
# Format label definitions into a clean string for prompt injectiondefinitions_text = ""for section_key, section_dict in LABEL_DEFINITIONS.items(): # Add a section header with underscores replaced by spaces and uppercased definitions_text += f"==== {section_key.replace('_', ' ').upper()} DEFINITIONS ====\n" # Add each category and its definition under the section for category, details in section_dict.items(): definitions_text += f"- {category}: {details.get('definition', '')}\n"
这个 definitions_text 字符串将是我们提示的关键部分,为 LLM 提供了准确执行任务所需的“教科书式”定义。
现在,我们将构建主提示模板。这个模板将所有内容整合在一起:输入、任务指令、标签定义,以及一个关键示例,向 LLM 展示一个好的输出应该是什么样子。
请注意我们如何使用 {{ 和 }} 来“转义”我们 JSON 示例中的花括号。这告诉 LangChain 这些是文本的一部分,而不是需要填充的变量。
from langchain_core.prompts import ChatPromptTemplate# Define the prompt template for statement extraction and labelingstatement_extraction_prompt_template = """You are an expert extracting atomic statements from text.Inputs:- main_entity: {main_entity}- document_chunk: {document_chunk}Tasks:1. Extract clear, single-subject statements.2. Label each as FACT, OPINION, or PREDICTION.3. Label each temporally as STATIC, DYNAMIC, or ATEMPORAL.4. Resolve references to main_entity and include dates/quantities.Return ONLY a JSON object with the statements and labels."""# Create a ChatPromptTemplate from the string templateprompt = ChatPromptTemplate.from_template(statement_extraction_prompt_template)
最后,我们将所有部分连接起来。我们将创建一个 LangChain “链”,它将我们的提示链接到 LLM,并告诉 LLM 根据我们的 RawStatementList 模型来结构化其输出。
我们将通过 Nebius 使用 deepseek-ai/DeepSeek-V3 模型来完成此任务,因为它功能强大且擅长遵循复杂指令。
from langchain_nebius import ChatNebiusimport json# Initialize our LLMllm = ChatNebius(model="deepseek-ai/DeepSeek-V3")# Create the chain: prompt -> LLM -> structured output parserstatement_extraction_chain = prompt | llm.with_structured_output(RawStatementList)
让我们在一个数据块上测试我们的链,看看它的实际效果。
# Select the sample chunk we inspected earlier for testing extractionsample_chunk_for_extraction = chunked_documents_lc[10]print("--- Running statement extraction on a sample chunk ---")print(f"Chunk Content:\n{sample_chunk_for_extraction.page_content}")print("\nInvoking LLM for extraction...")# Call the extraction chain with necessary inputsextracted_statements_list = statement_extraction_chain.invoke({ "main_entity": sample_chunk_for_extraction.metadata["company"], "publication_date": sample_chunk_for_extraction.metadata["date"].isoformat(), "document_chunk": sample_chunk_for_extraction.page_content, "definitions": definitions_text})print("\n--- Extraction Result ---")# Pretty-print the output JSON from the model responseprint(extracted_statements_list.model_dump_json(indent=2))
运行上述代码,我们得到了以下针对文本块的结构化输出。
#### 输出 ####{"statements": [ { "statement": "AMD has been very focused on the server launch for the first half of 2017.", "statement_type": "FACT", "temporal_type": "DYNAMIC" }, { "statement": "AMD's Desktop product should launch before the server launch.", "statement_type": "PREDICTION", "temporal_type": "STATIC" }, { "statement": "AMD believes true volume availability will be in the first quarter of 2017.", "statement_type": "OPINION", "temporal_type": "STATIC" }, { "statement": "AMD may ship some limited volume towards the end of the fourth quarter.", "statement_type": "PREDICTION", "temporal_type": "STATIC" } ]}
到目前为止,我们已经完成了原子事实提取步骤,准确地提取了基于时间和陈述的事实,这些事实在需要时可以稍后更新。
使用验证检查代理精确定位时间
我们已经成功地从文本中提取了什么——原子陈述。现在,我们需要提取何时。每个陈述都需要一个精确的时间戳来告诉我们它何时有效。
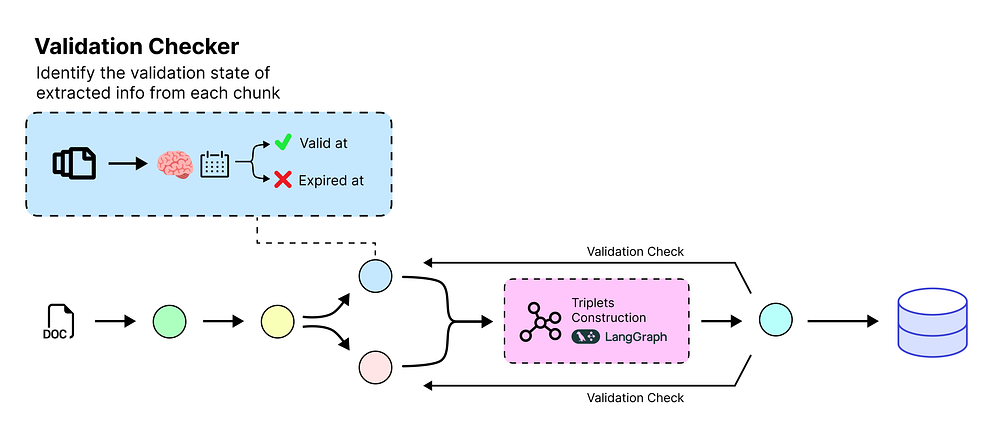
验证检查流程 (由 Fareed Khan 创建)
一个产品是上周还是去年发布的?或者一位 CEO 是在 2016 年还是 2018 年任职的?
这是使我们的知识库真正成为“时序”知识库最重要的一步。
为什么我们需要一个专门的日期代理?
从自然语言中提取日期是很棘手的。一个陈述可能会说下个季度、三个月前或在 2017 年。人类能理解这些,但计算机需要一个具体的日期,比如 2017-01-01。
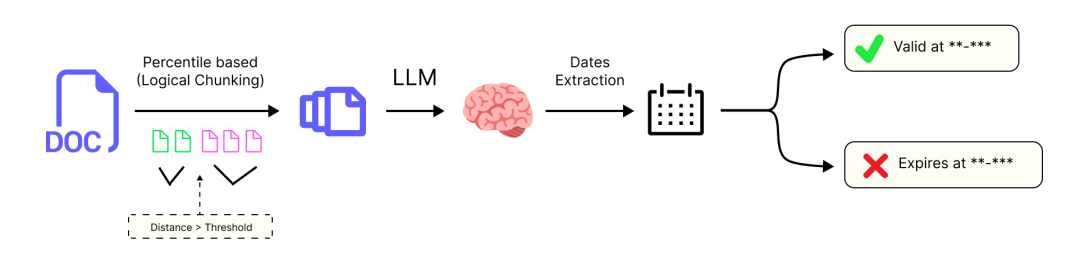
有效/无效事实检查流程 (由 Fareed Khan 创建)
我们的目标是创建一个专门的代理,它能读取一个陈述,并以原始文档的发布日期为参照,确定两个关键的时间戳:
- •
valid_at:事实变为真的日期。 - •
invalid_at:事实不再为真的日期(如果它不再有效)。
和之前一样,我们首先定义 Pydantic 模型,以确保我们的 LLM 给出干净、结构化的日期输出。
首先,我们需要一个健壮的辅助函数来解析 LLM 可能返回的各种日期格式。这个函数可以处理像 2017 或 2016–07–21 这样的字符串,并将它们转换为标准的 Python datetime 对象。
from datetime import datetime, timezonefrom dateutil.parser import parseimport redefparse_date_str(value: str | datetime | None) -> datetime | None: """ Parse a string or datetime into a timezone-aware datetime object (UTC). Returns None if parsing fails or input is None. """ ifnot value: returnNone # If already a datetime, ensure it has timezone info (UTC if missing) ifisinstance(value, datetime): return value if value.tzinfo else value.replace(tzinfo=timezone.utc) try: # Handle year-only strings like "2023" if re.fullmatch(r"\d{4}", value.strip()): year = int(value.strip()) return datetime(year, 1, 1, tzinfo=timezone.utc) # Parse more complex date strings with dateutil dt: datetime = parse(value) # Ensure timezone-aware, default to UTC if missing if dt.tzinfo isNone: dt = dt.replace(tzinfo=timezone.utc) return dt except Exception: return None
现在,我们定义两个 Pydantic 模型。RawTemporalRange 将捕获来自 LLM 的原始文本输出,而 TemporalValidityRange 将使用我们的辅助函数自动将该文本解析为干净的 datetime 对象。
from pydantic import BaseModel, Field, field_validatorfrom datetime import datetime# Model for raw temporal range with date strings as ISO 8601classRawTemporalRange(BaseModel): valid_at: str | None = Field(None, description="The start date/time in ISO 8601 format.") invalid_at: str | None = Field(None, description="The end date/time in ISO 8601 format.")# Model for validated temporal range with datetime objectsclassTemporalValidityRange(BaseModel): valid_at: datetime | None = None invalid_at: datetime | None = None # Validator to parse date strings into datetime objects before assignment @field_validator("valid_at", "invalid_at", mode="before") @classmethod def_parse_date_string(cls, value: str | datetime | None) -> datetime | None: return parse_date_str(value)
这种两步模型方法是一个很好的实践。它将原始的 LLM 输出与我们干净、经过验证的应用程序数据分开,使流水线更加健壮。
接下来,我们为此日期提取任务创建一个新的提示。我们将给 LLM 一个我们提取的陈述,并要求它根据上下文确定有效日期。
# Prompt guiding the LLM to extract temporal validity ranges from statementsdate_extraction_prompt_template = """You are a temporal information extraction specialist.INPUTS:- statement: "{statement}"- statement_type: "{statement_type}"- temporal_type: "{temporal_type}"- publication_date: "{publication_date}"- quarter: "{quarter}"TASK:- Analyze the statement and determine the temporal validity range (valid_at, invalid_at).- Use the publication date as the reference point for relative expressions (e.g., "currently").- If a relationship is ongoing or its end is not specified, `invalid_at` should be null.GUIDANCE:- For STATIC statements, `valid_at` is the date the event occurred, and `invalid_at` is null.- For DYNAMIC statements, `valid_at` is when the state began, and `invalid_at` is when it ended.- Return dates in ISO 8601 format (e.g., YYYY-MM-DDTHH:MM:SSZ).**Output format**Return ONLY a valid JSON object matching the schema for `RawTemporalRange`."""# Create a LangChain prompt template from the stringdate_extraction_prompt = ChatPromptTemplate.from_template(date_extraction_prompt_template)
这个提示高度专业化。它告诉 LLM 扮演“时序专家”的角色,并为其处理不同类型陈述提供了明确的规则。
现在我们构建此步骤的 LangChain 链,并在我们之前提取的一个陈述上进行测试。
# Reuse the existing LLM instance.# Create a chain by connecting the date extraction prompt# with the LLM configured to output structured RawTemporalRange objects.date_extraction_chain = date_extraction_prompt | llm.with_structured_output(RawTemporalRange)
让我们在以下陈述上测试它:
AMD has been very focused on the server launch for the first half of 2017.
(AMD 一直非常关注 2017 年上半年的服务器发布。)
这是一个 DYNAMIC(动态)事实,所以我们期望有一个 valid_at 日期,但结束日期未指定。
# Take the first extracted statement for date extraction testingsample_statement = extracted_statements_list.statements[0]chunk_metadata = sample_chunk_for_extraction.metadataprint(f"--- Running date extraction for statement ---")print(f'Statement: "{sample_statement.statement}"')print(f"Reference Publication Date: {chunk_metadata['date'].isoformat()}")# Invoke the date extraction chain with relevant inputsraw_temporal_range = date_extraction_chain.invoke({ "statement": sample_statement.statement, "statement_type": sample_statement.statement_type.value, "temporal_type": sample_statement.temporal_type.value, "publication_date": chunk_metadata["date"].isoformat(), "quarter": chunk_metadata["quarter"]})# Parse and validate raw LLM output into a structured TemporalValidityRange modelfinal_temporal_range = TemporalValidityRange.model_validate(raw_temporal_range.model_dump())print("\n--- Parsed & Validated Result ---")print(f"Valid At: {final_temporal_range.valid_at}")print(f"Invalid At: {final_temporal_range.invalid_at}")
让我们看看提取的时间范围事实是什么样的:
##### 输出 #####--- Running date extraction for statement ---Statement: "AMD has been very focused on the server launch for the first half of 2017."Reference Publication Date: 2016-07-21--- Parsed & Validated Result ---Valid At: 2017-01-01 00:00:00+00:00Invalid At: 2017-06-30 00:00:00+00:00
LLM 正确地解释了“2017 年上半年”,并将其转换为一个精确的日期范围。它理解这个 DYNAMIC 陈述有一个明确的开始和结束。
我们现在已经成功地为我们的事实添加了时间维度。下一步是将陈述的文本进一步分解为知识图谱的基本结构——三元组 (Triplets)。
将事实结构化为三元组
我们已经成功地提取了事实是什么(陈述)以及它们何时为真(日期)。
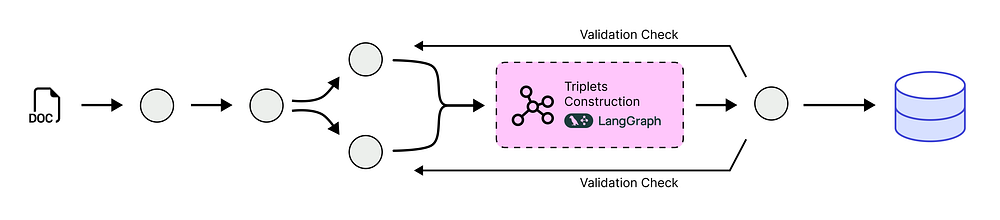
三元组提取 (由 Fareed Khan 创建)
现在,我们需要将这些自然语言句子转换为 AI 代理可以轻松理解和连接的格式。
三元组提取流程 (由 Fareed Khan 创建)
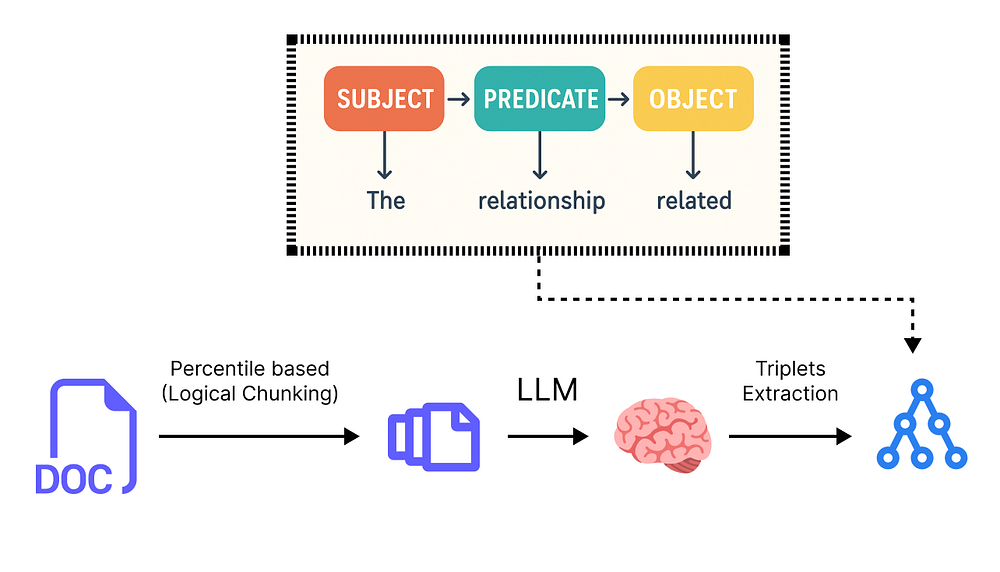
三元组将一个事实分解为三个核心组成部分:
-
- 主语 (Subject): 事实所关于的主要实体。
-
- 谓语 (Predicate): 关系或动作。
-
- 宾语 (Object): 与主语相关的实体或概念。
通过将我们所有的陈述转换为这种格式,我们可以构建一个相互连接的事实网络——我们的知识图谱。
和之前一样,我们首先定义将结构化 LLM 输出的 Pydantic 模型。这次提取是我们迄今为止最复杂的,因为 LLM 需要同时识别实体(名词)和关系(三元组)。
首先,让我们定义一个我们希望代理使用的固定 Predicate(谓语)关系列表。这确保了我们整个知识图谱的一致性。
from enum import Enum # Import the Enum base class to create enumerated constants# Enum representing a fixed set of relationship predicates for graph consistencyclassPredicate(str, Enum): # Each member of this Enum represents a specific type of relationship between entities IS_A = "IS_A" # Represents an "is a" relationship (e.g., a Dog IS_A Animal) HAS_A = "HAS_A" # Represents possession or composition (e.g., a Car HAS_A Engine) LOCATED_IN = "LOCATED_IN" # Represents location relationship (e.g., Store LOCATED_IN City) HOLDS_ROLE = "HOLDS_ROLE" # Represents role or position held (e.g., Person HOLDS_ROLE Manager) PRODUCES = "PRODUCES" # Represents production or creation relationship SELLS = "SELLS" # Represents selling relationship between entities LAUNCHED = "LAUNCHED" # Represents launch events (e.g., Product LAUNCHED by Company) DEVELOPED = "DEVELOPED" # Represents development relationship (e.g., Software DEVELOPED by Team) ADOPTED_BY = "ADOPTED_BY" # Represents adoption relationship (e.g., Policy ADOPTED_BY Organization) INVESTS_IN = "INVESTS_IN" # Represents investment relationships (e.g., Company INVESTS_IN Startup) COLLABORATES_WITH = "COLLABORATES_WITH"# Represents collaboration between entities SUPPLIES = "SUPPLIES" # Represents supplier relationship (e.g., Supplier SUPPLIES Parts) HAS_REVENUE = "HAS_REVENUE"# Represents revenue relationship for entities INCREASED = "INCREASED" # Represents an increase event or metric change DECREASED = "DECREASED" # Represents a decrease event or metric change RESULTED_IN = "RESULTED_IN"# Represents causal relationship (e.g., Event RESULTED_IN Outcome) TARGETS = "TARGETS" # Represents target or goal relationship PART_OF = "PART_OF" # Represents part-whole relationship (e.g., Wheel PART_OF Car) DISCONTINUED = "DISCONTINUED"# Represents discontinued status or event SECURED = "SECURED" # Represents secured or obtained relationship (e.g., Funding SECURED by Company)
现在,我们为原始实体和三元组定义模型,以及一个容器模型 RawExtraction 来容纳整个输出。
from pydantic import BaseModel, Fieldfrom typing importList, Optional# Model representing an entity extracted by the LLMclassRawEntity(BaseModel): entity_idx: int = Field(description="A temporary, 0-indexed ID for this entity.") name: str = Field(description="The name of the entity, e.g., 'AMD' or 'Lisa Su'.") type: str = Field("Unknown", description="The type of entity, e.g., 'Organization', 'Person'.") description: str = Field("", description="A brief description of the entity.")# Model representing a single subject-predicate-object tripletclassRawTriplet(BaseModel): subject_name: str subject_id: int = Field(description="The entity_idx of the subject.") predicate: Predicate object_name: str object_id: int = Field(description="The entity_idx of the object.") value: Optional[str] = Field(None, description="An optional value, e.g., '10%'.")# Container for all entities and triplets extracted from a single statementclassRawExtraction(BaseModel): entities: List[RawEntity] triplets: List[RawTriplet]
这个结构非常巧妙。它要求 LLM 首先列出它找到的所有实体,并为每个实体分配一个临时编号 (entity_idx)。
然后,它要求 LLM 使用这些编号构建三元组,从而在关系和所涉及的实体之间建立清晰的链接。
接下来,我们创建将指导 LLM 的提示和定义。这个提示非常具体,指示模型只关注关系,忽略任何我们已经提取过的时间信息。
# These definitions guide the LLM in choosing the correct predicate.PREDICATE_DEFINITIONS = { "IS_A": "Denotes a class-or-type relationship (e.g., 'Model Y IS_A electric-SUV').", "HAS_A": "Denotes a part-whole relationship (e.g., 'Model Y HAS_A electric-engine').", "LOCATED_IN": "Specifies geographic or organisational containment.", "HOLDS_ROLE": "Connects a person to a formal office or title.",}# Format the predicate instructions into a string for the prompt.predicate_instructions_text = "\n".join(f"- {pred}: {desc}" for pred, desc in PREDICATE_DEFINITIONS.items())
现在是主提示模板。再次强调,我们小心地用 {{ 和 }} 转义 JSON 示例,以便 LangChain 能正确解析它。
# Prompt for extracting entities and subject-predicate-object triplets from a statementtriplet_extraction_prompt_template = """You are an information-extraction assistant.Task: From the statement, identify all entities (people, organizations, products, concepts) and all triplets (subject, predicate, object) describing their relationships.Statement: "{statement}"Predicate list:{predicate_instructions}Guidelines:- List entities with unique `entity_idx`.- List triplets linking subjects and objects by `entity_idx`.- Exclude temporal expressions from entities and triplets.Example:Statement: "Google's revenue increased by 10% from January through March."Output: {{ "entities": [ {{"entity_idx": 0, "name": "Google", "type": "Organization", "description": "A multinational technology company."}}, {{"entity_idx": 1, "name": "Revenue", "type": "Financial Metric", "description": "Income from normal business."}} ], "triplets": [ {{"subject_name": "Google", "subject_id": 0, "predicate": "INCREASED", "object_name": "Revenue", "object_id": 1, "value": "10%"}} ]}}Return ONLY a valid JSON object matching `RawExtraction`."""# Initializing the prompt templatetriplet_extraction_prompt = ChatPromptTemplate.from_template(triplet_extraction_prompt_template)
最后,我们创建第三个链并用其中一个陈述来测试它。
# Create the chain for triplet and entity extraction.triplet_extraction_chain = triplet_extraction_prompt | llm.with_structured_output(RawExtraction)# Let's use the same statement we've been working with.sample_statement_for_triplets = extracted_statements_list.statements[0]print(f"--- Running triplet extraction for statement ---")print(f'Statement: "{sample_statement_for_triplets.statement}"')# Invoke the chain.raw_extraction_result = triplet_extraction_chain.invoke({ "statement": sample_statement_for_triplets.statement, "predicate_instructions": predicate_instructions_text})print("\n--- Triplet Extraction Result ---")print(raw_extraction_result.model_dump_json(indent=2))
这是我们链的输出。
--- Running triplet extraction for statement ---Statement: "AMD has been very focused on the server launch for the first half of 2017."--- Triplet Extraction Result ---{"entities": [ { "entity_idx": 0, "name": "AMD", "type": "Organization", "description": "" }, { "entity_idx": 1, "name": "server launch", "type": "Event", "description": "" } ],"triplets": [ { "subject_name": "AMD", "subject_id": 0, "predicate": "TARGETS", "object_name": "server launch", "object_id": 1, "value": null } ]}
LLM 正确地识别出“AMD”和“server launch”是关键实体,并用 TARGETS 谓语将它们连接起来,完美地捕捉了原句的含义。
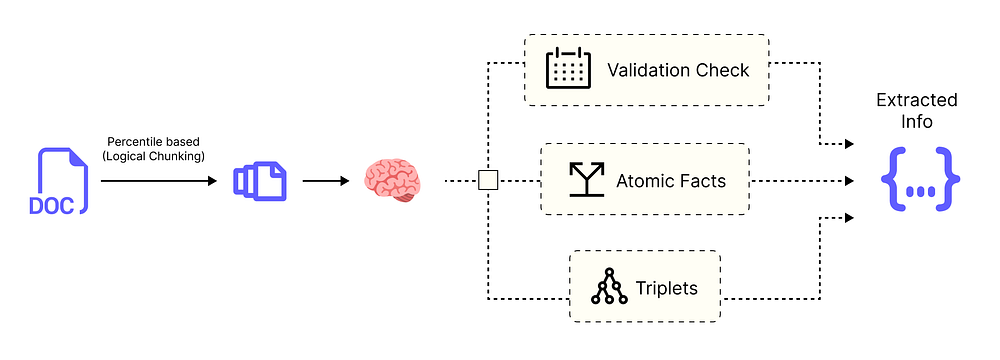
我们现在已经完成了所有独立的提取步骤。我们有一个系统,可以从一段文本中提取陈述、日期、实体和三元组。下一步是将所有这些信息组合成一个统一的对象,代表一个完整的**“时序事件 (Temporal Event)”**。
组装时序事件
我们现在已经完成了所有独立的提取步骤。我们有一个系统,可以从一段文本中提取:
-
- 陈述 (Statements):原子事实。
-
- 日期 (Dates):每个事实的“何时”。
-
- 实体和三元组 (Entities & Triplets):结构化格式的“谁”和“什么”。
我们提取过程的最后一步是将所有这些部分整合在一起。我们将创建一个名为 TemporalEvent 的主数据模型,它将关于单个陈述的所有信息整合到一个干净、统一的对象中。
时序事件 (由 Fareed Khan 创建)
这个 TemporalEvent 将是我们后续摄入流水线中处理的核心对象。它将包含所有内容:原始陈述、其类型、其时间范围,以及指向从中派生的所有三元组的链接。
我们还将定义 Triplet 和 Entity 模型的最终持久化版本。这些模型与 Raw 版本几乎相同,但它们将使用 uuid(通用唯一标识符)作为其主键。这是一种最佳实践,为它们在任何数据库中的存储做好了准备。
import uuidfrom pydantic import BaseModel, Field# Final persistent model for an entity in your knowledge graphclassEntity(BaseModel): id: uuid.UUID = Field(default_factory=uuid.uuid4, description="Unique UUID for the entity") name: str = Field(..., description="The name of the entity") type: str = Field(..., description="Entity type, e.g., 'Organization', 'Person'") description: str = Field("", description="Brief description of the entity") resolved_id: uuid.UUID | None = Field(None, description="UUID of resolved entity if merged")# Final persistent model for a triplet relationshipclassTriplet(BaseModel): id: uuid.UUID = Field(default_factory=uuid.uuid4, description="Unique UUID for the triplet") subject_name: str = Field(..., description="Name of the subject entity") subject_id: uuid.UUID = Field(..., description="UUID of the subject entity") predicate: Predicate = Field(..., description="Relationship predicate") object_name: str = Field(..., description="Name of the object entity") object_id: uuid.UUID = Field(..., description="UUID of the object entity") value: str | None = Field(None, description="Optional value associated with the triplet")
现在是主要的 TemporalEvent 模型。它包括我们迄今为止提取的所有信息,外加一些额外的字段用于嵌入和失效处理,我们将在后续步骤中使用它们。
class TemporalEvent(BaseModel): """ The central model that consolidates all extracted information. """ id: uuid.UUID = Field(default_factory=uuid.uuid4) chunk_id: uuid.UUID # To link back to the original text chunk statement: str embedding: list[float] = [] # For similarity checks later # Information from our previous extraction steps statement_type: StatementType temporal_type: TemporalType valid_at: datetime | None = None invalid_at: datetime | None = None # A list of the IDs of the triplets associated with this event triplets: list[uuid.UUID] # Extra metadata for tracking changes over time created_at: datetime = Field(default_factory=datetime.now) expired_at: datetime | None = None invalidated_by: uuid.UUID | None = None
让我们手动组装一个 TemporalEvent,看看所有部分是如何组合在一起的。我们将使用前面步骤中对示例陈述的处理结果:
AMD has been very focused on the server launch for the first half of 2017.
(AMD 一直非常关注 2017 年上半年的服务器发布。)
首先,我们将 RawEntity 和 RawTriplet 对象转换为它们最终的、持久化的 Entity 和 Triplet 形式,并附带唯一的 UUID。
# Assume these are already defined from previous steps:# sample_statement, final_temporal_range, raw_extraction_resultprint("--- Assembling the final TemporalEvent ---")# 1. Convert raw entities to persistent Entity objects with UUIDsidx_to_entity_map: dict[int, Entity] = {}final_entities: list[Entity] = []for raw_entity in raw_extraction_result.entities: entity = Entity( name=raw_entity.name, type=raw_entity.type, description=raw_entity.description ) idx_to_entity_map[raw_entity.entity_idx] = entity final_entities.append(entity)print(f"Created {len(final_entities)} persistent Entity objects.")# 2. Convert raw triplets to persistent Triplet objects, linking entities via UUIDsfinal_triplets: list[Triplet] = []for raw_triplet in raw_extraction_result.triplets: subject_entity = idx_to_entity_map[raw_triplet.subject_id] object_entity = idx_to_entity_map[raw_triplet.object_id] triplet = Triplet( subject_name=subject_entity.name, subject_id=subject_entity.id, predicate=raw_triplet.predicate, object_name=object_entity.name, object_id=object_entity.id, value=raw_triplet.value ) final_triplets.append(triplet)print(f"Created {len(final_triplets)} persistent Triplet objects.")
准备好最终的 Entity 和 Triplet 对象后,我们现在可以构建主 TemporalEvent 记录了。
# 3. Create the final TemporalEvent object# We'll generate a dummy chunk_id for this example.temporal_event = TemporalEvent( chunk_id=uuid.uuid4(), # Placeholder ID statement=sample_statement.statement, statement_type=sample_statement.statement_type, temporal_type=sample_statement.temporal_type, valid_at=final_temporal_range.valid_at, invalid_at=final_temporal_range.invalid_at, triplets=[t.idfor t in final_triplets])print("\n--- Final Assembled TemporalEvent ---")print(temporal_event.model_dump_json(indent=2))print("\n--- Associated Entities ---")for entity in final_entities: print(entity.model_dump_json(indent=2))print("\n--- Associated Triplets ---")for triplet in final_triplets: print(triplet.model_dump_json(indent=2))
让我们看一下流水线的结果。
--- Final Assembled TemporalEvent ---{"id": "d6640945-8404-476f-bcf2-1ad5889f5321","chunk_id": "3543e983-8ddf-4e7e-9833-9476dc747f6d","statement": "AMD has been very focused on the server launch for the first half of 2017.","embedding": [],"statement_type": "FACT","temporal_type": "DYNAMIC","valid_at": "2017-01-01T00:00:00+00:00","invalid_at": "2017-06-30T00:00:00+00:00","triplets": [ "af3a84b0-4430-424c-858f-650ad3d211e0" ],"created_at": "2024-08-10T19:17:40.509077","expired_at": null,"invalidated_by": null}--- Associated Entities ---{"id": "a7e56f1c-caba-4a07-b582-7feb9cf1a48c","name": "AMD","type": "Organization","description": "","resolved_id": null}{"id": "582c4edd-7310-4570-bc4f-281db179c673","name": "server launch","type": "Event","description": "","resolved_id": null}--- Associated Triplets ---{"id": "af3a84b0-4430-424c-858f-650ad3d211e0","subject_name": "AMD","subject_id": "a7e56f1c-caba-4a07-b582-7feb9cf1a48c","predicate": "TARGETS","object_name": "server launch","object_id": "582c4edd-7310-4570-bc4f-281db179c673","value": null}
我们已经成功地将一条信息从原始段落追溯到完全结构化、带有时间戳的 TemporalEvent。
但手动为每个陈述执行此操作是不可能的。下一步是使用 LangGraph 自动化整个装配线,一次性处理我们所有的文本块。
使用 LangGraph 自动化流水线
到目前为止,我们已经构建了三个强大的、专门的“代理”(或链):一个用于提取陈述,一个用于日期,一个用于三元组。我们也看到了如何手动将它们的输出组合成最终的 TemporalEvent。
但是,为我们数千个文本块中的每个陈述手动执行此操作是不可能的。我们需要自动化这条装配线。这就是 LangGraph 发挥作用的地方。
什么是 LangGraph 以及为何使用它?
LangGraph 是 LangChain 的一个库,用于构建复杂的、有状态的 AI 应用程序。与简单的 提示 -> LLM 链不同,我们可以构建一个图,其中每个步骤都是一个“节点”。信息,或称“状态”,从一个节点流向下一个节点。
这非常适合我们的用例。我们可以创建一个图,其中:
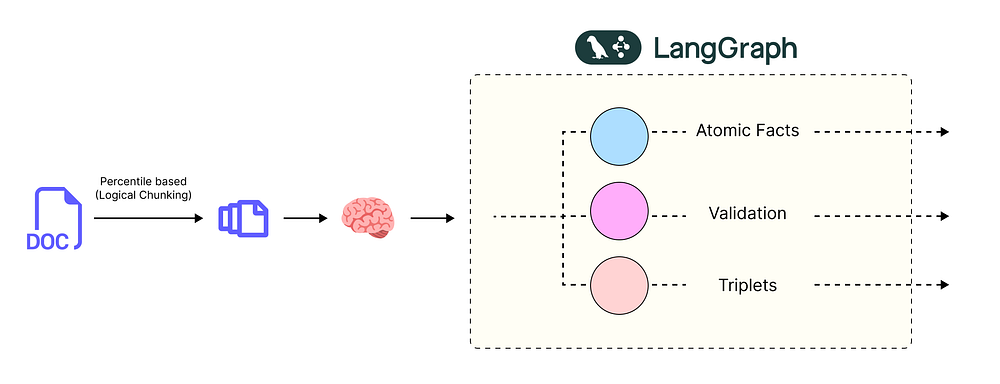
LangGraph 时序事件 (由 Fareed Khan 创建)
-
- 第一个节点从所有文本块中提取陈述。
-
- 第二个节点为所有这些陈述提取日期。
-
- 第三个节点提取三元组。
-
- 依此类推……
这创建了一个健壮、可重复且易于调试的数据处理流水线。
构建 LangGraph 的第一步是定义其“状态”。状态是图的记忆,是每个节点之间传递的数据。我们将定义一个状态,它可以容纳我们的文本块列表以及在此过程中创建的所有新对象。
from typing import List, TypedDictfrom langchain_core.documents import Documentclass GraphState(TypedDict): """ TypedDict representing the overall state of the knowledge graph ingestion. Attributes: chunks: List of Document chunks being processed. temporal_events: List of TemporalEvent objects extracted from chunks. entities: List of Entity objects in the graph. triplets: List of Triplet objects representing relationships. """ chunks: List[Document] temporal_events: List[TemporalEvent] entities: List[Entity] triplets: List[Triplet]
这个简单的字典结构将充当我们工厂装配线的“传送带”,将我们的数据从一个工位传送到下一个工位。
现在,我们将我们之前的所有逻辑组合成一个强大的函数。这个函数将成为我们图中的主要“节点”。它从状态中获取文本块列表,并以三个并行的步骤协调整个提取过程。
这里的一个关键优化是使用 .batch() 方法。与在一个缓慢的循环中逐个处理陈述不同,.batch() 一次性将它们全部发送给 LLM,这更快、更高效。
def extract_events_from_chunks(state: GraphState) -> GraphState: chunks = state["chunks"] # Extract raw statements from each chunk raw_stmts = statement_extraction_chain.batch([{ "main_entity": c.metadata["company"], "publication_date": c.metadata["date"].isoformat(), "document_chunk": c.page_content, "definitions": definitions_text } for c in chunks]) # Flatten statements, attach metadata and unique chunk IDs stmts = [{"raw": s, "meta": chunks[i].metadata, "cid": uuid.uuid4()} for i, rs inenumerate(raw_stmts) for s in rs.statements] # Prepare inputs and batch extract temporal data dates = date_extraction_chain.batch([{ "statement": s["raw"].statement, "statement_type": s["raw"].statement_type.value, "temporal_type": s["raw"].temporal_type.value, "publication_date": s["meta"]["date"].isoformat(), "quarter": s["meta"]["quarter"] } for s in stmts]) # Prepare inputs and batch extract triplets trips = triplet_extraction_chain.batch([{ "statement": s["raw"].statement, "predicate_instructions": predicate_instructions_text } for s in stmts]) events, entities, triplets = [], [], [] for i, s inenumerate(stmts): # Validate temporal range data tr = TemporalValidityRange.model_validate(dates[i].model_dump()) ext = trips[i] # Map entities by index and collect them idx_map = {e.entity_idx: Entity(e.name, e.type, e.description) for e in ext.entities} entities.extend(idx_map.values()) # Build triplets only if subject and object entities exist tpls = [Triplet( idx_map[t.subject_id].name, idx_map[t.subject_id].id, t.predicate, idx_map[t.object_id].name, idx_map[t.object_id].id, t.value) for t in ext.triplets if t.subject_id in idx_map and t.object_id in idx_map] triplets.extend(tpls) # Create TemporalEvent with linked triplet IDs events.append(TemporalEvent( chunk_id=s["cid"], statement=s["raw"].statement, statement_type=s["raw"].statement_type, temporal_type=s["raw"].temporal_type, valid_at=tr.valid_at, invalid_at=tr.invalid_at, triplets=[t.idfor t in tpls] )) return {"chunks": chunks, "temporal_events": events, "entities": entities, "triplets": triplets}
这个函数是我们之前手动步骤的完整自动化版本。它封装了整个提取逻辑。
现在,我们可以定义我们的工作流。目前,它将是一个只有一个步骤的简单图:extract_events。稍后我们将添加更多用于清理数据的步骤。
from langgraph.graph import StateGraph, END# Define a new graph using our stateworkflow = StateGraph(GraphState)# Add our function as a node named "extract_events"workflow.add_node("extract_events", extract_events_from_chunks)# Define the starting point of the graphworkflow.set_entry_point("extract_events")# Define the end point of the graphworkflow.add_edge("extract_events", END)# Compile the graph into a runnable applicationapp = workflow.compile()
让我们在我们单个示例文档创建的所有文本块上运行我们新的自动化流水线。
# The input is a dictionary matching our GraphState, providing the initial chunksgraph_input = {"chunks": chunked_documents_lc}# Invoke the graph. This will run our entire extraction pipeline in one call.final_state = app.invoke(graph_input)#### 输出 ####--- Entering Node: extract_events_from_chunks ---Processing 19 chunks...Extracted a total of 95 statements fromall chunks.Completed batch extraction for dates and triplets.Assembled 95 TemporalEvents, 213 Entities, and121 Triplets.--- Graph execution complete ---
通过一次 .invoke() 调用,我们的 LangGraph 应用处理了我们文档中的所有 19 个文本块,并行运行了数百次 LLM 调用,并将所有结果组装成一个干净的最终状态。
让我们检查输出来看看我们取得了多大的成就。
# Check the number of objects created in the final statenum_events = len(final_state['temporal_events'])num_entities = len(final_state['entities'])num_triplets = len(final_state['triplets'])print(f"Total TemporalEvents created: {num_events}")print(f"Total Entities created: {num_entities}")print(f"Total Triplets created: {num_triplets}")print("\n--- Sample TemporalEvent from the final state ---")# Print a sample event to see the fully assembled objectprint(final_state['temporal_events'][5].model_dump_json(indent=2))
这是我们示例处理数据的输出。
Total TemporalEvents created: 95Total Entities created: 213Total Triplets created: 121--- Sample TemporalEvent from the final state ---{"id": "f7428490-a92a-4f0a-90f0-073b7d4f170a","chunk_id": "37830de8-d442-45ae-84e4-0ae31ed1689f","statement": "Jaguar Bajwa is an Analyst at Arete Research.","embedding": [],"statement_type": "FACT","temporal_type": "STATIC","valid_at": "2016-07-21T00:00:00+00:00","invalid_at": null,"triplets": [ "87b60b81-fc4c-4958-a001-63f8b2886ea0" ],"created_at": "2025-08-10T19:52:48.580874","expired_at": null,"invalidated_by": null}
我们已经成功地自动化了我们的提取流水线。然而,数据仍然是“原始的”。例如,LLM 可能将“AMD”和“Advanced Micro Devices”提取为两个独立的实体。下一步是在我们的装配线上增加一个质检站:实体解析 (Entity Resolution)。
通过实体解析清理我们的数据
我们的自动化流水线现在正在提取大量信息。然而,如果你仔细观察这些实体,你可能会注意到一个问题。
LLM 可能会从文本的不同部分提取出“AMD”、“Advanced Micro Devices”和“Advanced Micro Devices, Inc”。
对人类来说,这些显然是同一家公司,但对计算机来说,它们只是不同的字符串。
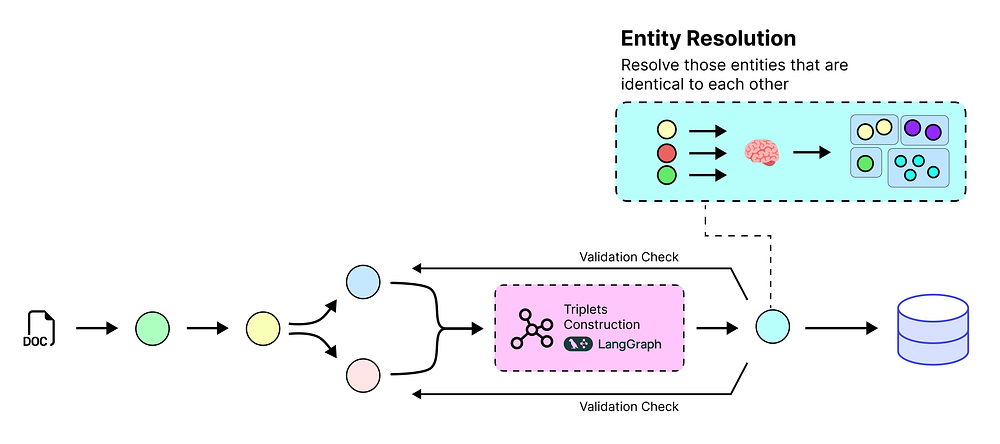
实体解析 (由 Fareed Khan 创建)
这是一个关键问题。如果我们不解决它,我们的知识图谱将变得混乱和不可靠。关于“AMD”的查询会漏掉与“Advanced Micro Devices”相关的事实。
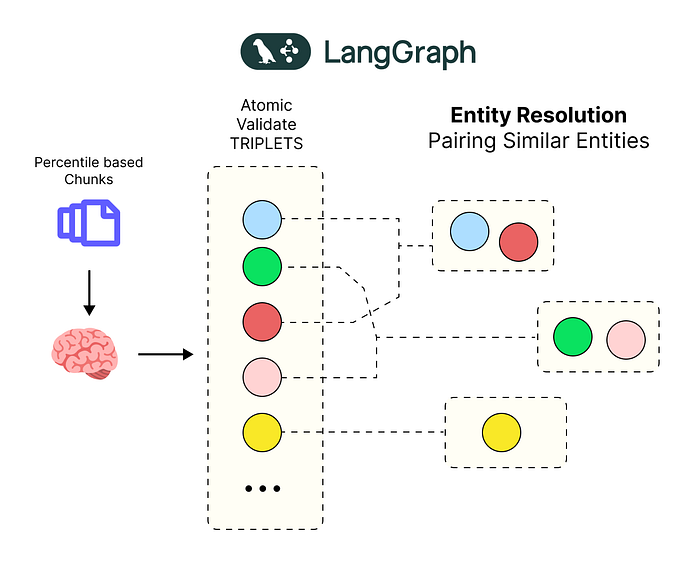
实体解析 (由 Fareed Khan 创建)
这被称为实体解析 (Entity Resolution)。目标是识别所有指向同一现实世界实体的不同名称(或“提及”),并将它们合并到一个权威的、“规范的”ID下。
为了解决这个问题,我们将在我们的 LangGraph 装配线上增加一个新的质检站。这个节点将:
-
- 使用模糊字符串匹配对名称相似的实体进行聚类。
-
- 为集群中的所有实体分配一个单一的、规范的 ID。
-
- 更新我们的三元组以使用这些新的、干净的 ID。
为了跟踪我们的规范实体,我们需要一个地方来存储它们。在本教程中,我们将使用 Python 内置的 sqlite3 库创建一个简单的内存数据库。在实际应用中,这应该是一个持久化的、生产级的数据库。
让我们创建我们的内存数据库和我们需要的表。
import sqlite3defsetup_in_memory_db(): """ Sets up an in-memory SQLite database and creates the 'entities' table. The 'entities' table schema: - id: TEXT, Primary Key - name: TEXT, name of the entity - type: TEXT, type/category of the entity - description: TEXT, description of the entity - is_canonical: INTEGER, flag to indicate if entity is canonical (default 1) Returns: sqlite3.Connection: A connection object to the in-memory database. """ # Establish connection to an in-memory SQLite database conn = sqlite3.connect(":memory:") # Create a cursor object to execute SQL commands cursor = conn.cursor() # Create the 'entities' table if it doesn't already exist cursor.execute(""" CREATE TABLE IF NOT EXISTS entities ( id TEXT PRIMARY KEY, name TEXT, type TEXT, description TEXT, is_canonical INTEGER DEFAULT 1 ) """) # Commit changes to save the table schema conn.commit() # Return the connection object for further use return conn# Create the database connection and set up the entities tabledb_conn = setup_in_memory_db()
这个简单的数据库将作为我们代理识别出的所有干净、权威实体的中央注册表。
现在我们将为我们的新 LangGraph 节点创建函数。这个函数将包含查找和合并重复实体的逻辑。对于模糊字符串匹配,我们将使用一个名为 rapidfuzz 的便利库。你可以通过 pip install rapidfuzz 简单地安装它。
我们必须编写 resolve_entities_in_state 函数,它将实现聚类和合并逻辑。
import stringfrom rapidfuzz import fuzzfrom collections import defaultdictdefresolve_entities_in_state(state: GraphState) -> GraphState: """ A LangGraph node to perform entity resolution on the extracted entities. """ print("\n--- Entering Node: resolve_entities_in_state ---") entities = state["entities"] triplets = state["triplets"] cursor = db_conn.cursor() cursor.execute("SELECT id, name FROM entities WHERE is_canonical = 1") global_canonicals = {row[1]: uuid.UUID(row[0]) for row in cursor.fetchall()} print(f"Starting resolution with {len(entities)} entities. Found {len(global_canonicals)} canonicals in DB.") # Group entities by type (e.g., 'Person', 'Organization') for more accurate matching type_groups = defaultdict(list) for entity in entities: type_groups[entity.type].append(entity) resolved_id_map = {} # Maps an old entity ID to its new canonical ID newly_created_canonicals = {} for entity_type, group in type_groups.items(): ifnot group: continue # Cluster entities in the group by fuzzy name matching clusters = [] used_indices = set() for i inrange(len(group)): if i in used_indices: continue current_cluster = [group[i]] used_indices.add(i) for j inrange(i + 1, len(group)): if j in used_indices: continue # Use partial_ratio for flexible matching (e.g., "AMD" vs "Advanced Micro Devices, Inc.") score = fuzz.partial_ratio(group[i].name.lower(), group[j].name.lower()) if score >= 80.0: # A similarity threshold of 80% current_cluster.append(group[j]) used_indices.add(j) clusters.append(current_cluster) # For each cluster, find the best canonical representation (the "medoid") for cluster in clusters: scores = {e.name: sum(fuzz.ratio(e.name.lower(), other.name.lower()) for other in cluster) for e in cluster} medoid_entity = max(cluster, key=lambda e: scores[e.name]) canonical_name = medoid_entity.name # Check if this canonical name already exists or was just created in this run if canonical_name in global_canonicals: canonical_id = global_canonicals[canonical_name] elif canonical_name in newly_created_canonicals: canonical_id = newly_created_canonicals[canonical_name].id else: # Create a new canonical entity canonical_id = medoid_entity.id newly_created_canonicals[canonical_name] = medoid_entity # Map all entities in this cluster to the single canonical ID for entity in cluster: entity.resolved_id = canonical_id resolved_id_map[entity.id] = canonical_id # Update the triplets in our state to use the new canonical IDs for triplet in triplets: if triplet.subject_id in resolved_id_map: triplet.subject_id = resolved_id_map[triplet.subject_id] if triplet.object_id in resolved_id_map: triplet.object_id = resolved_id_map[triplet.object_id] # Add any newly created canonical entities to our database if newly_created_canonicals: print(f"Adding {len(newly_created_canonicals)} new canonical entities to the DB.") new_data = [(str(e.id), e.name, e.type, e.description, 1) for e in newly_created_canonicals.values()] cursor.executemany("INSERT INTO entities (id, name, type, description, is_canonical) VALUES (?, ?, ?, ?, ?)", new_data) db_conn.commit() print("Entity resolution complete.") return state
现在,让我们将这个新的 resolve_entities 节点添加到我们的 LangGraph 工作流中。新的、改进后的流程将是:开始 -> 提取 -> 解析 -> 结束。
# Re-define the graph to include the new nodeworkflow = StateGraph(GraphState)# Add our two nodes to the graphworkflow.add_node("extract_events", extract_events_from_chunks)workflow.add_node("resolve_entities", resolve_entities_in_state)# Define the new sequence of stepsworkflow.set_entry_point("extract_events")workflow.add_edge("extract_events", "resolve_entities")workflow.add_edge("resolve_entities", END)# Compile the updated workflowapp_with_resolution = workflow.compile()
让我们在同一组文本块上运行我们新的两步流水线,并查看结果。
# Use the same input as beforegraph_input = {"chunks": chunked_documents_lc}# Invoke the new graphfinal_state_with_resolution = app_with_resolution.invoke(graph_input)#### 输出 ####--- Entering Node: extract_events_from_chunks ---Processing 19 chunks...Extracted a total of 95 statements fromall chunks.Completed batch extraction for dates and triplets.Assembled 95 TemporalEvents, 213 Entities, and121 Triplets.--- Entering Node: resolve_entities_in_state ---Starting resolution with213 entities. Found 0 canonicals in DB.Adding 110 new canonical entities to the DB.Entity resolution complete.--- Graph execution with resolution complete ---
图成功运行了!它首先提取了所有内容,然后新的 resolve_entities 节点启动,找到了重复的实体,并将新的规范版本添加到了我们的数据库中。
让我们检查输出来看差异。我们可以检查一个实体,看它的 resolved_id 是否被设置,并检查一个三元组,确认它正在使用新的、干净的 ID。
# Find a sample entity that has been resolved (i.e., has a resolved_id)sample_resolved_entity = next((e for e in final_state_with_resolution['entities'] if e.resolved_id is not None and e.id != e.resolved_id), None)if sample_resolved_entity: print("\n--- Sample of a Resolved Entity ---") print(sample_resolved_entity.model_dump_json(indent=2))else: print("\nNo sample resolved entity found (all entities were unique in this small run).") # Check a triplet to see its updated canonical IDssample_resolved_triplet = final_state_with_resolution['triplets'][0]print("\n--- Sample Triplet with Resolved IDs ---")print(sample_resolved_triplet.model_dump_json(indent=2))
这是解析后的实体输出:
# --- Sample of a Resolved Entity ---{"id": "1a2b3c4d-5e6f-4a7b-8c9d-0e1f2a3b4c5d","name": "Advanced Micro Devices","type": "Organization","description": "A semiconductor company.","resolved_id": "b1c2d3e4-f5g6-4h7i-8j9k-0l1m2n3o4p5q"}# --- Sample Triplet with Resolved IDs ---{"id": "c1d2e3f4-a5b6-4c7d-8e9f-0g1h2i3j4k5l","subject_name": "AMD","subject_id": "b1c2d3e4-f5g6-4h7i-8j9k-0l1m2n3o4p5q","predicate": "TARGETS","object_name": "server launch","object_id": "d1e2f3a4-b5c6-4d7e-8f9g-0h1i2j3k4l5m","value": null}
这非常完美。你可以看到一个名为“Advanced Micro Devices”的实体现在有一个 resolved_id,指向规范实体(很可能是名为 “AMD” 的实体)的 ID。我们所有的三元组现在都使用这些干净的、规范的 ID。
我们的数据现在不仅是结构化的、带有时间戳的,而且是干净和一致的。下一步是我们代理最智能的部分:使用失效代理 (Invalidation Agent) 处理矛盾。
使用失效代理使我们的知识动态化
我们的数据现在已经分块、提取、结构化和清理完毕。但我们仍未解决时序数据的核心挑战:事实会随时间变化。
想象一下,我们的知识库包含这样一个事实:(John Smith) --[HOLDS_ROLE]--> (CFO)。这是一个 DYNAMIC(动态)事实,意味着它在一段时间内是正确的。当我们的代理读到一个新文档说,“Jane Doe 于 2024 年 1 月 1 日被任命为 CFO”时,会发生什么?
第一个事实现在已经过时了。一个简单的知识库不会知道这一点,但一个时序知识库必须知道。这就是失效代理 (Invalidation Agent) 的工作:充当裁判,发现这些矛盾,并更新旧事实,将其标记为已过期。
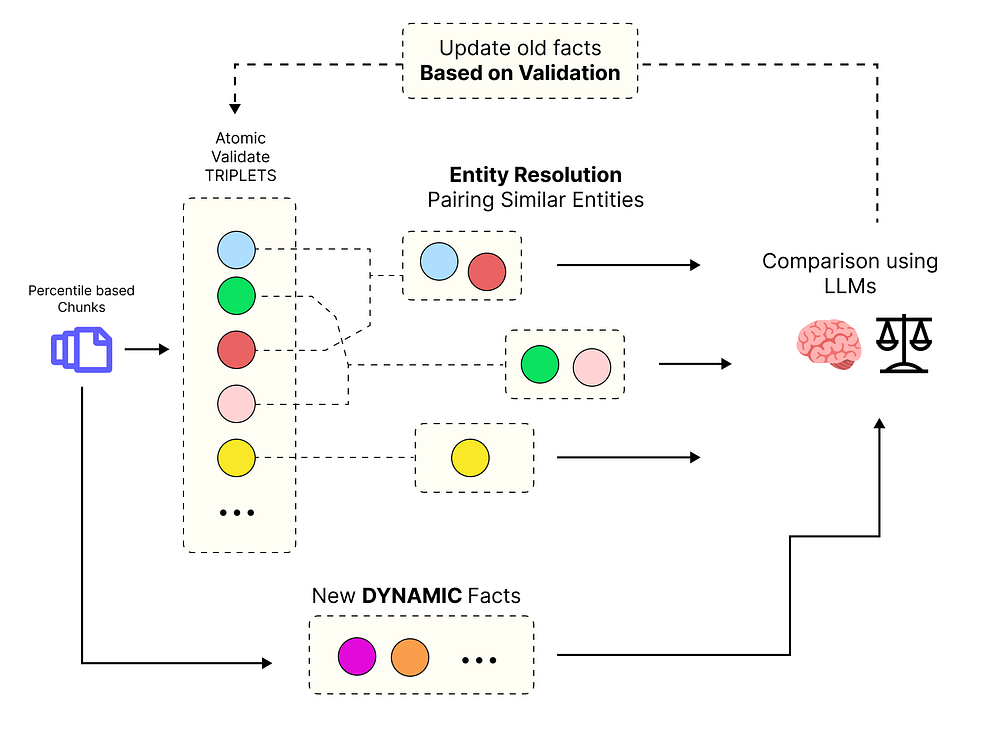
动态知识库 (由 Fareed Khan 创建)
为此,我们将在 LangGraph 流水线中添加最后一个节点。该节点将:
-
- 为我们所有的新陈述生成嵌入,以理解它们的语义含义。
-
- 将新的
DYNAMIC事实与数据库中已有的事实进行比较。
- 将新的
-
- 使用 LLM 对新事实是否使旧事实失效做出最终判断。
-
- 如果一个事实被判定失效,它将更新其
invalid_at时间戳。
- 如果一个事实被判定失效,它将更新其
首先,我们需要为失效逻辑准备环境。这包括将 events 和 triplets 表添加到我们的内存数据库中。这模拟了一个代理可以核对的真实的、持久化的知识库。
# Obtain a cursor from the existing database connectioncursor = db_conn.cursor()# Create the 'events' table to store event-related datacursor.execute("""CREATE TABLE IF NOT EXISTS events ( id TEXT PRIMARY KEY, -- Unique identifier for each event chunk_id TEXT, -- Identifier for the chunk this event belongs to statement TEXT, -- Textual representation of the event statement_type TEXT, -- Type/category of the statement (e.g., assertion, question) temporal_type TEXT, -- Temporal classification (e.g., past, present, future) valid_at TEXT, -- Timestamp when the event becomes valid invalid_at TEXT, -- Timestamp when the event becomes invalid embedding BLOB -- Optional embedding data stored as binary (e.g., vector))""")# Create the 'triplets' table to store relations between entities for eventscursor.execute("""CREATE TABLE IF NOT EXISTS triplets ( id TEXT PRIMARY KEY, -- Unique identifier for each triplet event_id TEXT, -- Foreign key referencing 'events.id' subject_id TEXT, -- Subject entity ID in the triplet predicate TEXT -- Predicate describing relation or action)""")# Commit all changes to the in-memory databasedb_conn.commit()
接下来,我们将创建一个新的提示和链。这个链非常简单:它会向 LLM 展示两个可能冲突的事件,并要求对一个事件是否使另一个事件失效做出简单的“True”或“False”的决定。
# This prompt asks the LLM to act as a referee between two events.event_invalidation_prompt_template = """Task: Analyze the primary event against the secondary event and determine if the primary event is invalidated by the secondary event.Return "True" if the primary event is invalidated, otherwise return "False".Invalidation Guidelines:1. An event can only be invalidated if it is DYNAMIC and its `invalid_at` is currently null.2. A STATIC event (e.g., "X was hired on date Y") can invalidate a DYNAMIC event (e.g., "Z is the current employee").3. Invalidation must be a direct contradiction. For example, "Lisa Su is CEO" is contradicted by "Someone else is CEO".4. The invalidating event (secondary) must occur at or after the start of the primary event.---Primary Event (the one that might be invalidated):- Statement: {primary_statement}- Type: {primary_temporal_type}- Valid From: {primary_valid_at}- Valid To: {primary_invalid_at}Secondary Event (the new fact that might cause invalidation):- Statement: {secondary_statement}- Type: {secondary_temporal_type}- Valid From: {secondary_valid_at}---Is the primary event invalidated by the secondary event? Answer with only "True" or "False"."""invalidation_prompt = ChatPromptTemplate.from_template(event_invalidation_prompt_template)# This chain will output a simple string: "True" or "False".invalidation_chain = invalidation_prompt | llm
现在我们将为我们的新 LangGraph 节点编写函数。这是我们流水线中最复杂的函数,但它遵循一个清晰的逻辑:使用嵌入找到可能相关的事实,然后请求 LLM 做出最终裁决。
from scipy.spatial.distance import cosinedefinvalidate_events_in_state(state: GraphState) -> GraphState: """Mark dynamic events invalidated by later similar facts.""" events = state["temporal_events"] # Embed all event statements embeds = embeddings.embed_documents([e.statement for e in events]) for e, emb inzip(events, embeds): e.embedding = emb updates = {} for i, e1 inenumerate(events): # Skip non-dynamic or already invalidated events if e1.temporal_type != TemporalType.DYNAMIC or e1.invalid_at: continue # Find candidate events: facts starting at or after e1 with high similarity cands = [ e2 for j, e2 inenumerate(events) if j != i and e2.statement_type == StatementType.FACT and e2.valid_at and e1.valid_at and e2.valid_at >= e1.valid_at and1 - cosine(e1.embedding, e2.embedding) > 0.5 ] ifnot cands: continue # Prepare inputs for LLM invalidation check inputs = [{ "primary_statement": e1.statement, "primary_temporal_type": e1.temporal_type.value, "primary_valid_at": e1.valid_at.isoformat(), "primary_invalid_at": "None", "secondary_statement": c.statement, "secondary_temporal_type": c.temporal_type.value, "secondary_valid_at": c.valid_at.isoformat() } for c in cands] # Ask LLM which candidates invalidate the event results = invalidation_chain.batch(inputs) # Record earliest invalidation info for c, r inzip(cands, results): if r.content.strip().lower() == "true"and (e1.idnotin updates or c.valid_at < updates[e1.id]["invalid_at"]): updates[e1.id] = {"invalid_at": c.valid_at, "invalidated_by": c.id} # Apply invalidations to events for e in events: if e.idin updates: e.invalid_at = updates[e.id]["invalid_at"] e.invalidated_by = updates[e.id]["invalidated_by"] return state
现在,让我们将最后的 invalidate_events 节点添加到 LangGraph 工作流中。完整的摄入流水线将是:提取 -> 解析 -> 失效。
# Re-define the graph to include all three nodesworkflow = StateGraph(GraphState)workflow.add_node("extract_events", extract_events_from_chunks)workflow.add_node("resolve_entities", resolve_entities_in_state)workflow.add_node("invalidate_events", invalidate_events_in_state)# Define the complete pipeline flowworkflow.set_entry_point("extract_events")workflow.add_edge("extract_events", "resolve_entities")workflow.add_edge("resolve_entities", "invalidate_events")workflow.add_edge("invalidate_events", END)# Compile the final ingestion workflowingestion_app = workflow.compile()
现在,让我们在示例文档的文本块上运行完整的三步流水线。
# Use the same input as beforegraph_input = {"chunks": chunked_documents_lc}# Invoke the final graphfinal_ingested_state = ingestion_app.invoke(graph_input)print("\n--- Full graph execution with invalidation complete ---")#### 输出 ####--- Entering Node: extract_events_from_chunks ---Processing 19 chunks...Extracted a total of 95 statements fromall chunks....--- Entering Node: resolve_entities_in_state ---Starting resolution with213 entities. Found 0 canonicals in DB....--- Entering Node: invalidate_events_in_state ---Generated embeddings for95 events....Checking for invalidations: 100%|██████████| 95/95 [00:08<00:00, 11.23it/s]Found 1 invalidations to apply.--- Full graph execution with invalidation complete ---
流水线成功运行,甚至找到了一个可以应用的失效判定!让我们找到那个特定的事件,看看发生了什么。
# Find and print an invalidated event from the final stateinvalidated_event = next((e for e in final_ingested_state['temporal_events'] if e.invalidated_by isnotNone), None)if invalidated_event: print("\n--- Sample of an Invalidated Event ---") print(invalidated_event.model_dump_json(indent=2)) # Find the event that caused the invalidation invalidating_event = next((e for e in final_ingested_state['temporal_events'] if e.id == invalidated_event.invalidated_by), None) if invalidating_event: print("\n--- Was Invalidated By this Event ---") print(invalidating_event.model_dump_json(indent=2))else: print("\nNo invalidated events were found in this run.")
这是我们文本块中发生的失效事件。
# --- Sample of an Invalidated Event ---{"id": "e5094890-7679-4d38-8d3b-905c11b0ed08","statement": "All participants are in a listen-only mode...","statement_type": "FACT","temporal_type": "DYNAMIC","valid_at": "2016-07-21T00:00:00+00:00","invalid_at": "2016-07-21T00:00:00+00:00","invalidated_by": "971ffb90-b973-4f41-a718-737d6d2e0e38"}# --- Was Invalidated By this Event ---{"id": "971ffb90-b973-4f41-a718-737d6d2e0e38","statement": "The Q&A session will begin now.","statement_type": "FACT","temporal_type": "STATIC","valid_at": "2016-07-21T00:00:00+00:00","invalid_at": null,"invalidated_by": null}
代理正确地识别出 DYNAMIC(动态)状态“所有参与者都处于只听模式”被后来的 STATIC(静态)事件 “问答环节现在开始” 所失效。它更新了第一个事件,设置了其 invalid_at 时间戳。
这完成了整个摄入流水线。我们已经构建了一个可以从原始文本中自动创建一个干净、结构化且具有时序感知的知识库的系统。接下来也是最后一步,是利用这些丰富的数据来构建我们的知识图谱。
组装时序知识图谱
到目前为止,我们已经成功地将原始、混乱的会议记录转化为一个干净、结构化且具有时序感知的知识集合。
我们已成功自动化:
-
- 提取 (Extraction):提取陈述、日期和三元组。
-
- 解析 (Resolution):清理重复的实体。
-
- 失效 (Invalidation):更新不再为真的事实。
现在,是时候利用这些最终的高质量数据来构建我们的知识图谱了。这个图谱将成为我们的检索代理查询以回答用户问题的“大脑”。
组装时序知识图谱 (由 Fareed Khan 创建)
图谱是这类数据的完美结构,因为它完全关乎连接。
- • 实体 (Entities)(如“AMD”或“Lisa Su”)成为节点 (nodes)(点)。
- • 三元组 (Triplets)(关系)成为边 (edges)(连接点的线)。
这种结构使我们能够轻松地从一个事实遍历到另一个事实,这正是一个智能检索代理所需要做的。
我们将使用一个流行的 Python 库 NetworkX 来构建我们的图谱。它轻量级、易于使用,非常适合在我们的 notebook 中直接处理图结构。
我们将编写一个函数,它接收我们 LangGraph 流水线的最终状态 (final_ingested_state) 并构建一个 NetworkX 图对象。
这个函数将为每个唯一的、规范的实体创建一个节点,并为每个三元组创建一条边,将我们所有丰富的时序数据作为该边的属性添加进去。
import networkx as nximport uuiddefbuild_graph_from_state(state: GraphState) -> nx.MultiDiGraph: """ Builds a NetworkX graph from the final state of our ingestion pipeline. """ print("--- Building Knowledge Graph from final state ---") entities = state["entities"] triplets = state["triplets"] temporal_events = state["temporal_events"] # Create a quick-lookup map from an entity's ID to the entity object itself entity_map = {entity.id: entity for entity in entities} graph = nx.MultiDiGraph() # A directed graph that allows multiple edges # 1. Add a node for each unique, canonical entity canonical_ids = {e.resolved_id if e.resolved_id else e.idfor e in entities} for canonical_id in canonical_ids: # Find the entity object that represents this canonical ID canonical_entity_obj = entity_map.get(canonical_id) if canonical_entity_obj: graph.add_node( str(canonical_id), # Node names in NetworkX are typically strings name=canonical_entity_obj.name, type=canonical_entity_obj.type, description=canonical_entity_obj.description ) print(f"Added {graph.number_of_nodes()} canonical entity nodes to the graph.") # 2. Add an edge for each triplet, decorated with temporal info edges_added = 0 event_map = {event.id: event for event in temporal_events} for triplet in triplets: # Find the parent event that this triplet belongs to parent_event = next((ev for ev in temporal_events if triplet.idin ev.triplets), None) ifnot parent_event: continue # Get the canonical IDs for the subject and object subject_canonical_id = str(triplet.subject_id) object_canonical_id = str(triplet.object_id) # Add the edge to the graph if graph.has_node(subject_canonical_id) and graph.has_node(object_canonical_id): edge_attrs = { "predicate": triplet.predicate.value, "value": triplet.value, "statement": parent_event.statement, "valid_at": parent_event.valid_at, "invalid_at": parent_event.invalid_at, "statement_type": parent_event.statement_type.value } graph.add_edge( subject_canonical_id, object_canonical_id, key=triplet.predicate.value, **edge_attrs ) edges_added += 1 print(f"Added {edges_added} edges (relationships) to the graph.") return graph# Let's build the graph from the state we got from our LangGraph appknowledge_graph = build_graph_from_state(final_ingested_state)
让我们获取图谱的输出。
# --- Building Knowledge Graph from final state ---Added 340 canonical entity nodes to the graph.Added 434 edges (relationships) to the graph.
所以,在我们的第一个文本块数据上,我们总共有 340 个实体和 434 条边。我们的函数已成功将流水线中的对象列表转换为正式的图结构。
现在我们有了 knowledge_graph 对象,让我们来探索一下我们构建了什么。我们可以检查一个特定的节点,比如“AMD”,看看它的属性和关系。
print(f"Graph has {knowledge_graph.number_of_nodes()} nodes and {knowledge_graph.number_of_edges()} edges.")# Let's find the node for "AMD" by searching its 'name' attributeamd_node_id = Nonefor node, data in knowledge_graph.nodes(data=True): if data.get('name', '').lower() == 'amd': amd_node_id = node breakif amd_node_id: print("\n--- Inspecting the 'AMD' node ---") print(f"Attributes: {knowledge_graph.nodes[amd_node_id]}") print("\n--- Sample Outgoing Edges from 'AMD' ---") for i, (u, v, data) inenumerate(knowledge_graph.out_edges(amd_node_id, data=True)): if i >= 3: break# Show the first 3 for brevity object_name = knowledge_graph.nodes[v]['name'] print(f"Edge {i+1}: AMD --[{data['predicate']}]--> {object_name} (Valid From: {data['valid_at'].date()})")else: print("Could not find a node for 'AMD'.")
这是输出结果。
Graph has 340 nodes and 434 edges.# --- Inspecting the 'AMD' node ---Attributes: {'name': 'AMD', 'type': 'Organization', 'description': ''}# --- Sample Outgoing Edges from 'AMD' ---Edge 1: AMD --[HOLDS_ROLE]--> President and CEO (Valid From: 2016-07-21)Edge 2: AMD --[HAS_A]--> SVP, CFO, and Treasurer (Valid From: 2016-07-21)Edge 3: AMD --[HAS_A]--> Chief Human Resources Officer and SVP of Corporate Communications and IR (Valid From: 2016-07-21)
我们可以看到 AMD 的节点以及与其相连的一些关系,还有这些关系生效的日期。
为了更好地直观感受我们的图谱,让我们绘制一个包含最重要、连接度最高的实体的小型子图。
import matplotlib.pyplot as plt# Find the 15 most connected nodes to visualizedegrees = dict(knowledge_graph.degree())top_nodes = sorted(degrees, key=degrees.get, reverse=True)[:15]# Create a smaller graph containing only these top nodessubgraph = knowledge_graph.subgraph(top_nodes)# Draw the graphplt.figure(figsize=(12, 12))pos = nx.spring_layout(subgraph, k=0.8, iterations=50)labels = {node: data['name'] for node, data in subgraph.nodes(data=True)}nx.draw(subgraph, pos, labels=labels, with_labels=True, node_color='skyblue', node_size=2500, edge_color='#666666', font_size=10)plt.title("Subgraph of Top 15 Most Connected Entities", size=16)plt.show()
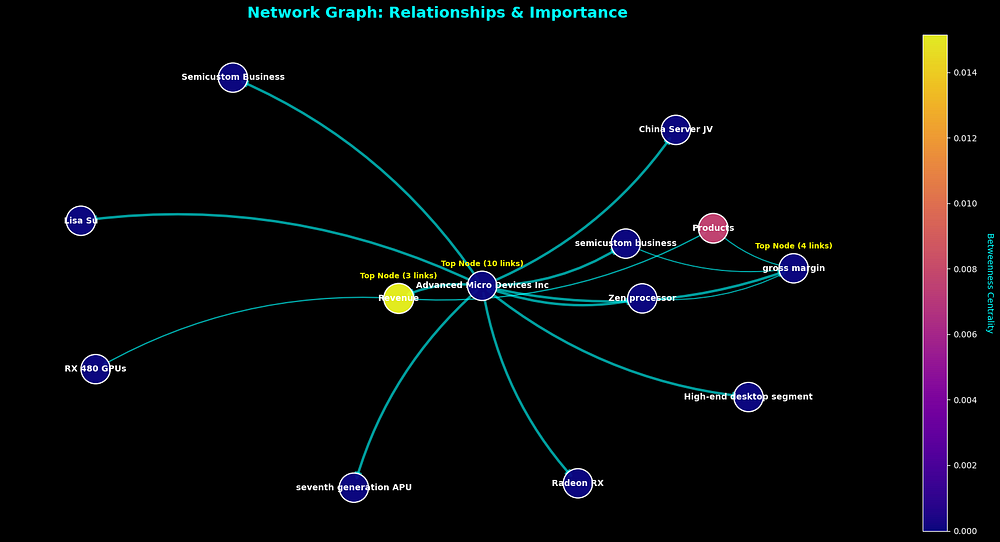
示例知识图谱 (由 Fareed Khan 创建)
这个可视化让我们对我们提取的核心实体和关系有了一个鸟瞰图。我们已经成功创建了我们的时序知识图谱。
现在我们可以构建一个能与这个先进的时序知识图谱数据库对话的智能代理,以回答复杂的、时间敏感的问题。
构建和测试多步检索代理
我们已经成功地构建了我们的“智能数据库”——一个丰富、干净且具有时序感知的知识图谱。现在是收获成果的时候了,构建一个能够与这个图谱进行对话以回答复杂问题的智能代理。
为什么单步 RAG 不够用
一个简单的 RAG 系统可能会找到一个相关事实并用它来回答问题。但如果答案需要连接多条信息呢?
思考一个问题,比如……
AMD 在 2016 年到 2017 年间对数据中心的关注是如何演变的?
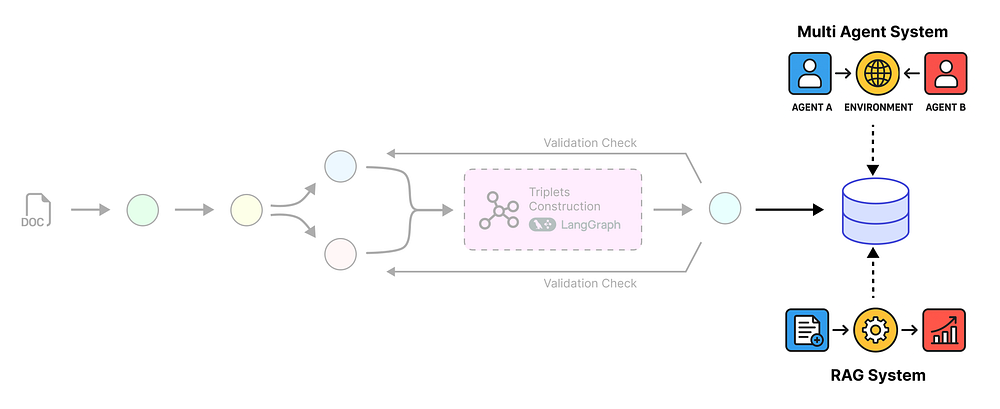
多代理系统 (由 Fareed Khan 创建)
一个简单的检索系统无法回答这个问题。它需要一个多步过程:
-
- 找到 2016 年关于 AMD 和数据中心的事实。
-
- 找到 2017 年关于 AMD 和数据中心的事实。
-
- 比较两年的结果。
-
- 综合出一个最终的总结。
这就是我们的多步检索代理将要做的事情。我们将使用 LangGraph 构建它,它将有三个关键组成部分:一个规划器 (Planner)、一套工具 (Tools) 和一个协调器 (Orchestrator)。
在我们主代理开始工作之前,我们希望它先思考并创建一个高层计划。这使得代理更可靠、更专注。规划器是一个简单的 LLM 链,其唯一的工作就是将用户的问题分解为一系列可操作的步骤。
让我们为我们的规划器创建提示。我们将给它一个“专家级金融研究助理”的“人设”,以指导其语调和它创建的计划质量。
# System prompt describes the "persona" for the LLMinitial_planner_system_prompt = ( "You are an expert financial research assistant. " "Your task is to create a step-by-step plan for answering a user's question " "by querying a temporal knowledge graph of earnings call transcripts. " "The available tool is `factual_qa`, which can retrieve facts about an entity " "for a specific topic (predicate) within a given date range. " "Your plan should consist of a series of calls to this tool.")# Template for the user prompt — receives `user_question` dynamicallyinitial_planner_user_prompt_template = """User Question: "{user_question}"Based on this question, create a concise, step-by-step plan. Each step should be a clear action for querying the knowledge graph.Return only the plan under a heading 'Research tasks'."""# Create a ChatPromptTemplate that combines the system persona and the user prompt.# `from_messages` takes a list of (role, content) pairs to form the conversation context.planner_prompt = ChatPromptTemplate.from_messages([ ("system", initial_planner_system_prompt), # LLM's role and behavior ("user", initial_planner_user_prompt_template), # Instructions for this specific run])# Create a "chain" that pipes the prompt into the LLM.# The `|` operator here is the LangChain "Runnable" syntax for composing components.planner_chain = planner_prompt | llm
现在,让我们用我们的示例问题测试规划器,看看它会制定出什么样的策略。
# Our sample user question for the retrieval agentuser_question = "How did AMD's focus on data centers evolve between 2016 and 2017?"print(f"--- Generating plan for question: '{user_question}' ---")plan_result = planner_chain.invoke({"user_question": user_question})initial_plan = plan_result.contentprint("\n--- Generated Plan ---")print(initial_plan)#### 输出 ####--- Generating plan for question: 'How did AMD's focus on data centers evolve between 2016 and 2017?' ------ Generated Plan ---Research tasks:1. Query the `factual_qa` tool for the entity "AMD" with predicates related to data centers (e.g., "LAUNCHED", "DEVELOPED", "TARGETS") for the date range 2016-01-01 to 2016-12-31.2. Query the `factual_qa` tool for the entity "AMD" with the same predicates for the date range 2017-01-01 to 2017-12-31.3. Synthesize the results from both queries to describe the evolution of AMD's focus on data centers.
根据生成的计划输出,我们可以看到它为我们的主代理提供了一个清晰的路线图。它确切地知道需要找到哪些信息来回答用户的问题。
from langchain_core.tools import toolfrom datetime import dateimport datetime as dt # Use an alias to avoid confusion# Helper function to parse dates robustly, even if the LLM provides different formatsdef_as_datetime(ts) -> dt.datetime | None: ifnot ts: returnNone ifisinstance(ts, dt.datetime): return ts ifisinstance(ts, dt.date): return dt.datetime.combine(ts, dt.datetime.min.time()) try: return dt.datetime.strptime(ts, "%Y-%m-%d") except (ValueError, TypeError): returnNone@tooldeffactual_qa(entity: str, start_date: date, end_date: date, predicate: str) -> str: """ Queries the knowledge graph for facts about a specific entity, topic (predicate), and time range. Returns a formatted string of matching relationships. """ print(f"\n--- TOOL CALL: factual_qa ---") print(f" - Entity: {entity}, Predicate: {predicate}, Range: {start_date} to {end_date}") start_dt = _as_datetime(start_date).replace(tzinfo=timezone.utc) end_dt = _as_datetime(end_date).replace(tzinfo=timezone.utc) # 1. Find the entity node in the graph using a case-insensitive search target_node_id = next((nid for nid, data in knowledge_graph.nodes(data=True) if entity.lower() in data.get('name', '').lower()), None) ifnot target_node_id: returnf"Error: Entity '{entity}' not found." # 2. Search all edges connected to that node for matches matching_edges = [] for u, v, data in knowledge_graph.edges(target_node_id, data=True): if predicate.upper() in data.get('predicate', '').upper(): valid_at = data.get('valid_at') if valid_at and start_dt <= valid_at <= end_dt: subject = knowledge_graph.nodes[u]['name'] obj = knowledge_graph.nodes[v]['name'] matching_edges.append(f"Fact: {subject} --[{data['predicate']}]--> {obj}") ifnot matching_edges: returnf"No facts found for '{entity}' with predicate '{predicate}' in that date range." return"\n".join(matching_edges)
这个 factual_qa 函数是代理的大脑(LLM)和它的记忆(知识图谱)之间的桥梁。
现在我们来构建最终的代理。这个代理将扮演**“协调器 (orchestrator)”**的角色。它将查看用户的问题和计划,然后智能地决定在一个循环中调用哪些工具,直到它有足够的信息来提供最终答案。
我们将使用 LangGraph 构建这个协调器,它非常适合管理这种循环的、**“决策-行动”**的逻辑。
from langgraph.prebuilt import ToolNodefrom langgraph.graph import StateGraph, ENDfrom langchain_core.messages import BaseMessage, HumanMessagefrom typing import TypedDict, List# Define the state for our retrieval agent's memoryclassAgentState(TypedDict): messages: List[BaseMessage]# This is the "brain" of our agent. It decides what to do next.defcall_model(state: AgentState): print("\n--- AGENT: Calling model to decide next step... ---") response = llm_with_tools.invoke(state['messages']) return {"messages": [response]}# This is a conditional edge. It checks if the LLM decided to call a tool or to finish.defshould_continue(state: AgentState) -> str: ifhasattr(state['messages'][-1], 'tool_calls') and state['messages'][-1].tool_calls: return"continue_with_tool" return"finish"# Bind our factual_qa tool to the LLM and force it to use a tool if possible# This is required by our specific modeltools = [factual_qa]llm_with_tools = llm.bind_tools(tools, tool_choice="any")# Now, wire up the graphworkflow = StateGraph(AgentState)workflow.add_node("agent", call_model)workflow.add_node("action", ToolNode(tools)) # ToolNode is a pre-built node that runs our toolsworkflow.set_entry_point("agent")workflow.add_conditional_edges( "agent", should_continue, {"continue_with_tool": "action", "finish": END})workflow.add_edge("action", "agent")retrieval_agent = workflow.compile()
我们的检索代理现在已经完全构建好了!它有一个大脑 (call_model),有手 (ToolNode),还有一个循环机制,让它能够多次思考和行动。
让我们运行完整的流程并提出我们的问题。我们将给代理用户问题和我们之前生成的计划,以便给它最好的起点。
# Create the initial message for the agentinitial_message = HumanMessage( content=f"Here is my question: '{user_question}'\n\n" f"Here is the plan to follow:\n{initial_plan}")# The input to the agent is always a list of messagesagent_input = {"messages": [initial_message]}print("--- Running the full retrieval agent ---")# Stream the agent's execution to see its thought process in real-timeasyncfor output in retrieval_agent.astream(agent_input): for key, value in output.items(): if key == "agent": agent_message = value['messages'][-1] if agent_message.tool_calls: print(f"LLM wants to call a tool: {agent_message.tool_calls[0]['name']}") else: print("\n--- AGENT: Final Answer ---") print(agent_message.content) elif key == "action": print("--- AGENT: Tool response received. ---")
现在,当我们使用异步方法运行完整的检索代理时,响应如下所示。
# --- Running the full retrieval agent ---# --- AGENT: Calling model to decide next step... ---LLM wants to call a tool: factual_qa# --- TOOL CALL: factual_qa --- - Entity: AMD, Predicate: LAUNCHED, Range: 2016-01-01 to 2016-12-31--- AGENT: Tool response received. ---# --- AGENT: Calling model to decide next step... ---LLM wants to call a tool: factual_qa# --- TOOL CALL: factual_qa --- - Entity: AMD, Predicate: LAUNCHED, Range: 2017-01-01 to 2017-12-31--- AGENT: Tool response received. ---# --- AGENT: Calling model to decide next step... ---# --- AGENT: Final Answer ---Based on the information from the knowledge graph, here is how AMDs focus on data centers evolved regarding product launches between 2016and2017:* **2016:** There were no facts found related to AMD launching products for data centers in this year.* **2017:** A key development occurred. The knowledge graph contains a fact stating that "AMD is on track to deliver its next-generation Zen architecture in 2017."This indicates a significant shift. While 2016 showed no specific launch activity in this area, 2017 marked a clear focus on bringing the new "Zen" architecture to market, which was crucial for their data center strategy.
代理成功地遵循了计划,用不同的日期范围调用了两次工具,然后将结果综合成一个完美的、比较性的答案。这展示了将时序知识图谱与多步代理相结合的强大能力。
我们接下来能做什么?
我们已经构建了一个强大的原型,展示了如何创建一个不仅仅是静态库,而是一个能够理解事实如何随时间演变的动态系统。
既然我们的代理可以工作了,下一个关键问题是:“它工作得多好?”回答这个问题需要一个正式的评估过程。主要有三种方法:
- • 黄金答案 (Golden Answers)(黄金标准): 你创建一个测试问题集,并请人类专家写出完美的答案。然后你将你的代理的输出与这些“黄金”答案进行比较。这是最准确的方法,但速度慢且成本高。
- • 以大模型为评判者 (LLM-as-Judge)(可扩展的方法): 你使用一个强大的 LLM(如 GPT-4)充当“评判者”。它为你的代理的答案在正确性和相关性方面打分。这种方法快速且成本低,非常适合快速测试和迭代。
- • 人类反馈 (Human Feedback)(真实世界的测试): 一旦你的代理部署,你可以添加简单的反馈按钮(如点赞/点踩),让用户对答案进行评价。这会告诉你你的代理在真实任务中的有用性。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献277条内容
已为社区贡献277条内容

所有评论(0)