大模型Agent开发实战:2025“大运河杯”数据开发应用创新大赛——智慧应急
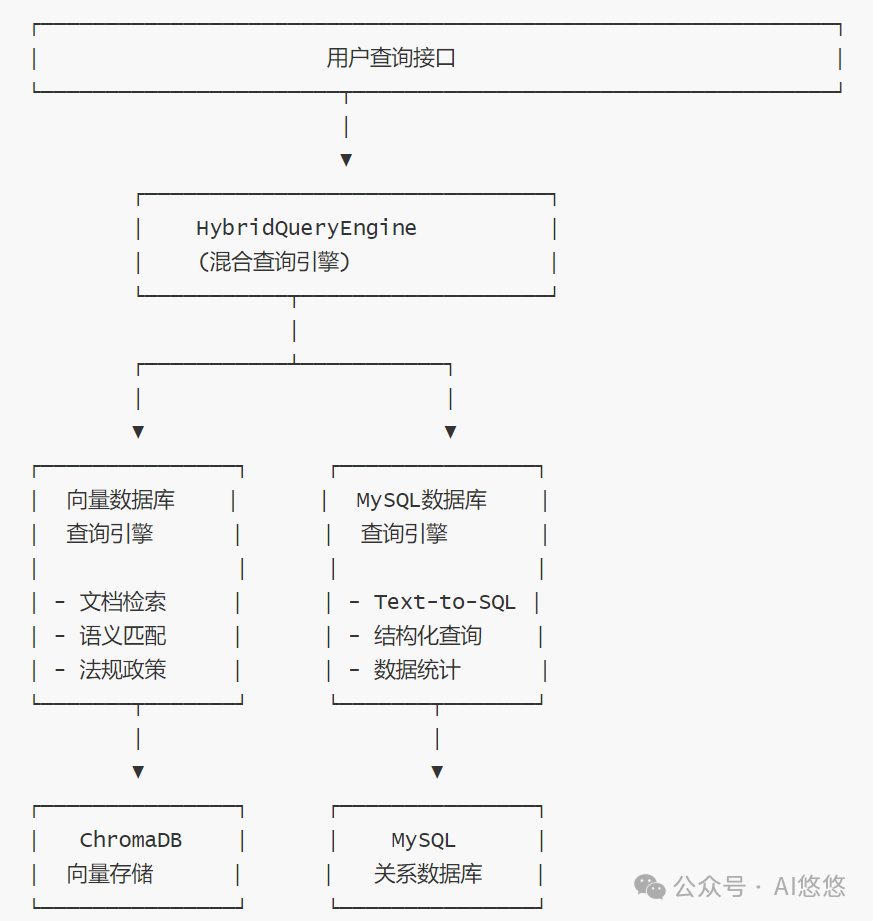
混合查询架构优先使用向量数据库检索 自动质量评估和回退机制必要时切换到 MySQL Text-to-SQL 查询智能回退策略基于相似度分数判断结果质量检测回答中的低质量关键词自动触发 MySQL 查询回退
《应急管理安全生产智能问答》大赛是一个较典型大模型Agent实战项目,首先看下比赛的具体内容,然后再进行具体的分析和实战!

一、赛题描述
随着我国工业经济的迅猛发展,危化品企业与工业高危工艺规模持续扩张,安全生产风险防控压力剧增。传统依赖人工查询数据、解读政策的模式已难以满足应急管理的快速决策需求,“监管难”“响应慢” 成为制约安全生产治理能力提升的关键瓶颈。机器学习、大模型等AI技术的发展为应急管理数字化转型提供了全新路径,其强大的自然语言理解与知识整合能力,正推动智慧应急建设迈向智能化新阶段。
本赛题立足应急管理实际需求,将AI技术应用于安全生产智能问答场景。核心任务是构建一个面向应急安全生产的统一智能问答系统。该系统将助力应急管理人员快速获取关键数据、精准掌握政策要求,有效提升应急安全生产决策效率,为风险预警、隐患排查、应急处置提供科学支撑,筑牢安全生产数字化防线,为智慧应急体系建设与城市安全发展提供重要保障,推动应急管理能力实现质的飞跃。
二、赛题题目
应急管理安全生产智能问答
三、赛题任务
赛题同步接入本地危化企业/工业企业高危工艺的结构化表数据、应急领域地方政策文件、国家法律法规、行业标准规范等文本数据。系统能够精准理解用户提出的多样化问题(涉及数据查询、政策解读、合规性判断等),并基于对问题意图的深度解析自动判断需检索的数据,生成准确可靠的答案。参赛者可依托主流开源大模型或机器学习模型,通过大模型微调、检索增强生成(RAG)、智能体(Agent)等技术手段,实现最终目标。
【初赛-A榜】
选手根据提供的数据,线下进行AI模型开发与调试,构建应急管理安全生产智能问答系统。基于测试问题集,利用构建的问答系统自动化输出答案结果,严禁人为构造答案结果并提交。
四、数据描述
【初赛-A榜】
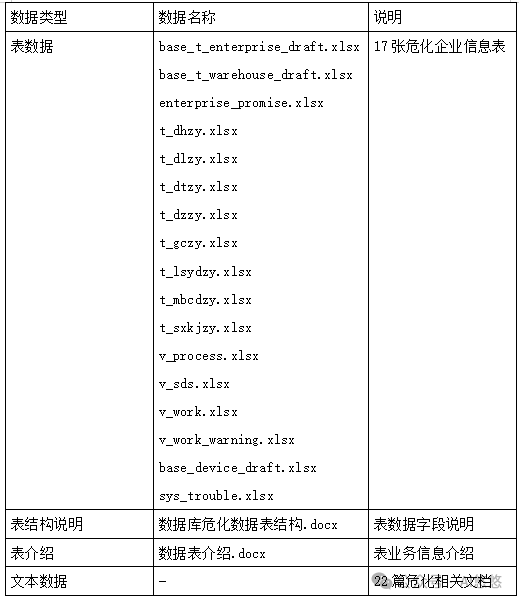
本赛题提供的数据集包含危化企业结构化表数据和危化品、危化企业相关的地方政策/法律法规/标准规范/管理办法等文本数据。数据集清单与说明:
选手需对给定的A榜测试数据进行推理预测,测试数据格式如下:

问答对涉及表数据的重要规则说明:
1.通用规则:
-
基础关联条件:在任何涉及企业编码(org_code)的查询中,都必须确保企业编码来源于企业基础表(base_t_enterprise_draft)中有效的企业数据,即删除状态为未删除(delete_status=0)且审核状态为已审核(check_status=2);
-
多表关联查询:对于主表(企业安全生产责任承诺表(enterprise_promise)除外),若其包含“删除状态”、“审核状态”字段,需确保企业数据为有效数据,即删除状态为“未删除”、审核状态为“已审核”;
2.涉及“特殊作业”相关问答对的时间范围:
(1)特殊作业的时间范围由两个阶段共同构成:计划阶段与实施阶段。其中,计划阶段的时间范围为作业计划开始时间(start_time)至作业计划结束时间(end_time);实施阶段的时间范围为作业实施开始时间(zysskssj)至作业实施结束时间(zyssjssj);
五、提交说明
【初赛-A榜】
选手需要根据给定的测试问题集,分别预测出测试集对应的答案,并以csv格式保存,文件名为result.csv。结果result.csv的样例如下:
注:选手需保证提交的result.csv中数据的字段顺序与给定的问答测试集顺序一致,提交的文件记录数也需保持一致。为避免评测过程中文件编码格式导致评测错误的影响,文件统一以utf-8编码。
六、评估指标

详情可以看网址:
https://www.marsbigdata.com/competition/details?id=3845468616549

以上为竞赛项目的实际情况,接下来进入分析阶段!
一、系统分析
-
根据比赛内容,涉及到问答、知识库、RAG、Agent等,我们基本可以可以断定是一个涉及Agent+RAG的项目。
-
有大量的Excel数据,数据量比较大,则需要将数据导入到关系型数据库里作为结构化数据,再使用NL2SQL/Text2SQL。
-
非结构化文档pdf/words等格式,包含扫描件等,需要清洗数据。
-
需要对非结构化数据(pdf/words等)和结构数据(Excel)数据分别处理,检索时需要整合这两种数据源。
二、技术选型
1、Agent(RAG+Text2SQL)的问答功能,可选技术框架一般有:
(1)LangChain;
(2)LlamaIndex;
本文选择LlamaIndex,该框架入门简单,内置了丰富的功能,特别适合RAG类型的Agent开发,也内置Text2SQL组件!
2、关系型数据库选择Mysql;
3、向量数据库选择ChromaDB;
三、数据整理
1、非结构化文档使用MinerU(OCR)统一转化为MarkDown格式的文件;
2、将所有Excel数据导入到Mysql数据库里,特别说明:表名的备注说明、表字段的说明一定要全部导入。
四、建立索引
非结构化数据已全部转为MarkDown,所以Llamaindex内置的文本切分器MarkdownNodeParser批量将所有MarkDown文件全部向量化,存储到ChromaDB里。
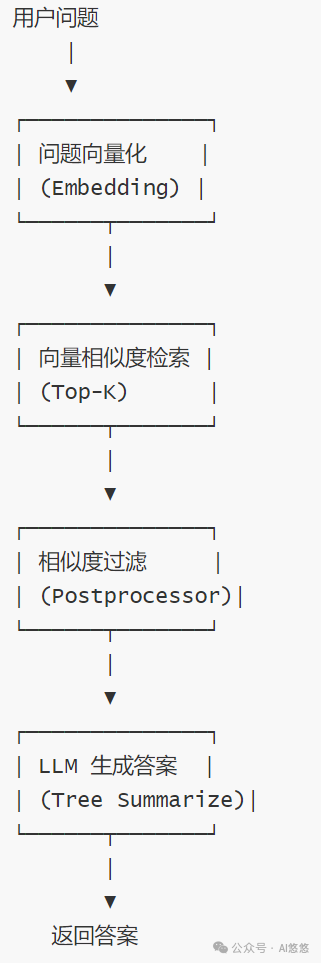
五、对非结构化数据的检索查询
先完成非结构化数据的检索查询,再整合Text2SQL。 非结构化数据的检索查询就是我们最常见的RAG知识库检索增强。流程如下:
核心代码如下:
query_engine = index.as_query_engine(
similarity_top_k=similarity_top_k,
response_mode="tree_summarize",
node_postprocessors=node_postprocessors if node_postprocessors else None
)六、结构化数据Text2SQL查询检索
使用LlamaIndex内置的SQL查询引擎SQLTableRetrieverQueryEngine,分2步骤查询,第1是查询涉及到的表,第2步是从这几个表中写SQL进行查询。流程如下:
用户问题
│
▼
┌──────────────┐
│ 表结构检索 │
│ (SQLTable │
│ Retriever) │
└──────┬───────┘
│
▼
┌──────────────┐
│ 业务规则注入 │
│ (SQL Rules) │
└──────┬───────┘
│
▼
┌──────────────┐
│ LLM 生成 SQL │
│ (Text-to-SQL) │
└──────┬───────┘
│
▼
┌──────────────┐
│ SQL 执行 │
└──────┬───────┘
│
▼
┌──────────────┐
│ 结果检测 │
│ (空结果?) │
└──────┬───────┘
│
┌──┴──┐
│ │
否 是
│ │
▼ ▼
返回结果 模糊查询回退
│ │
└──┬──┘
│
返回结果实战过程中发现一些问题:
-
检索到的表不正确;
-
拼接的SQL中出现非该表的字段;
-
表字段混乱使用;
-
业务理解错误;
-
Value值拆分不正确,不需要拆分的却被拆分了;
解决方案:
-
写业务规则,告诉大模型什么场景下使用什么表。
-
限定某些表的使用范围;
-
限定某些表字段使用范围,禁止显示的场景;
-
使用模糊查询:先精确查询,若未查询到结果,则再使用模糊查询再次查询。
七、整合两个查询
两个查询,一般需要先查询非结构化数据,若查询到的结果得分较低,则使用Text2SQL查询数据。
八、拆分子句
根据给到的100个问题,发现有些问题,是2句话,其中一句话要从非结构化数据里查询,另一句话要从结构化数据里查询,那么我们在混合查询之前,需要拆分句子。我们使用大模型来帮我们拆分句子,核心代码如下:
import logging
from typing import List
from loguru import logger
# 导入LlamaIndex相关模块
from llama_index.core import Settings, PromptTemplate
from llama_index.core.llms import ChatMessage
# 语句拆分的提示模板
SENTENCE_SPLIT_PROMPT = """
你是一个专业的语句拆分助手。请将用户输入的文本按照自然语言的句子边界拆分成多个独立的句子。
要求:
1. 每个句子必须是完整的,表达一个完整的意思
2. 保留原始文本的标点符号
3. 确保拆分后的句子语法正确
4. 只返回拆分后的句子列表,不要添加任何额外的解释或说明
输入文本:{input_text}
请以JSON格式返回拆分后的句子列表,格式如下:
{"sentences": ["句子1", "句子2", "句子3"]}
"""
def split_sentences(input_text: str) -> List[str]:
"""
使用大模型将输入文本拆分成多个句子
Args:
input_text: 用户输入的文本,可以包含多句话
llm: 已初始化的语言模型,如果为None则自动初始化
Returns:
List[str]: 拆分后的句子列表
"""
if not input_text or not input_text.strip():
logger.warning("输入文本为空")
return []
try:
#logger.info(f"开始拆分句子,输入文本长度: {len(input_text)} 字符")
# 创建提示模板
prompt_template = PromptTemplate(SENTENCE_SPLIT_PROMPT)
# 格式化提示
formatted_prompt = prompt_template.format(input_text=input_text)
# 创建聊天消息
messages = [
ChatMessage(role="system", content="你是一个专业的语句拆分助手。"),
ChatMessage(role="user", content=formatted_prompt)
]
# 调用模型
response = Settings.llm.chat(messages)
# 提取响应内容
response_content = response.message.content.strip()
# logger.info(f"模型返回响应: {response_content}")
# 解析JSON响应
import json
try:
# 提取JSON部分(处理模型可能返回的额外文本)
if "{" in response_content:
json_start = response_content.find("{")
json_end = response_content.rfind("}") + 1
json_str = response_content[json_start:json_end]
result = json.loads(json_str)
sentences = result.get("sentences", [])
#logger.info(f"成功拆分出 {len(sentences)} 个句子")
return sentences
else:
logger.error("模型响应中未找到JSON格式数据")
# 备用方案:尝试基本的正则拆分
import re
sentences = re.split(r'[。!?.!?]\s*', input_text)
return [s.strip() for s in sentences if s.strip()]
except json.JSONDecodeError:
logger.error("无法解析JSON响应")
# 备用方案:尝试基本的正则拆分
import re
sentences = re.split(r'[。!?.!?]\s*', input_text)
return [s.strip() for s in sentences if s.strip()]
except Exception as e:
logger.error(f"语句拆分过程中出错: {str(e)}")
# 错误处理:使用简单的正则表达式作为备用方案
try:
import re
sentences = re.split(r'[。!?.!?]\s*', input_text)
return [s.strip() for s in sentences if s.strip()]
except Exception:
return [input_text] # 最后返回原始文本
# 添加一个简单的测试函数
def test_split():
"""测试语句拆分功能"""
test_cases = [
#"你好,很高兴认识你。今天天气真好,我们去公园玩吧!",
# "Python是一种广泛使用的解释型、高级的通用编程语言。它由荷兰人吉多·范罗苏姆于1989年圣诞节期间,为了打发圣诞节的无趣,而开发的。",
# "This is a test. Can you split these sentences correctly? I hope so!",
# "这是一个非常长的句子,中间没有任何标点符号,测试模型是否能正确处理这种情况虽然有些难度但我们可以看看效果如何如果真的处理不了的话至少能返回原始文本。"
#"给出全市风险等级为一般风险的企业数量,并说明如何划分安全风险评估的区域。",
"查询全市涉及烷基化工艺的企业名单。并说明烷基化工艺的重点监控工艺参数。"
]
for i, test_case in enumerate(test_cases, 1):
print(f"\n测试用例 {i}: {test_case}")
sentences = split_sentences(test_case, llm)
print(f"拆分结果 ({len(sentences)}个句子):")
for j, sentence in enumerate(sentences, 1):
print(f" {j}. {sentence}")
if __name__ == "__main__":
# 默认运行主函数
#main()
# 如果想要运行测试,可以取消下面一行的注释
test_split()拆分子句,轮询的结果可以直接拼接,也可以再使用大模型来整合语言。
九、Agent工作流
开发完这些功能后,发现该流程节点比较长的,节点和流转比较固定,适合使用WorkFlow来优化整体的代码结构。
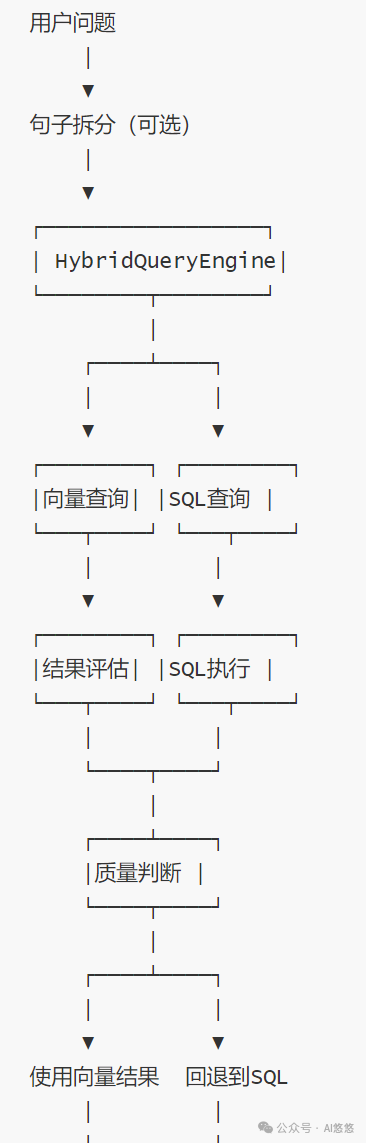

本系统的核心思想
-
混合查询架构
-
优先使用向量数据库检索
-
自动质量评估和回退机制
-
必要时切换到 MySQL Text-to-SQL 查询
-
-
智能回退策略
-
基于相似度分数判断结果质量
-
检测回答中的低质量关键词
-
自动触发 MySQL 查询回退
-
-
多数据源支持
-
Markdown /PDF/Word文档
-
Excel 表格(数据表结构说明)
-
MySQL 数据库(结构化业务数据)
-
-
句子拆分处理
-
支持复杂多句查询
-
自动拆分并分别处理每个子问题
-
合并多个子问题的答案
-
本项目代码实战的得分如下,分数不算高,但是整体思路是没有问题的,可在细节再打磨一下,还能提升不少分数。比如后处理重排序,BM25检索等多重检索,大模型的选择。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)