YOLOv8【特征融合Neck篇·第18节】一文搞懂,DetectoRS递归特征融合!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。 ✨ 特惠福利
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
上期回顾:【第17节】YOLOF单级特征融合
各位才华横溢的读者们,大家好!👋 在上一期《YOLOv8【特征融合Neck篇·第17节】一文整明白,YOLOF单级特征融合!》的分享中,我们共同探讨了一个向主流FPN范式发起"挑战"的"反叛者"——YOLOF (You Only Look One-level Feature)。
我们首先分析了FPN及其变体(如PANet, CSP-PAN)虽然性能强大,但也带来了日益增加的结构复杂性、计算开销和内存占用。YOLOF大胆地提出一个问题:解决多尺度检测问题,真的非特征金字塔不可吗?
YOLOF给出的答案是否定的。它的核心思想是"大道至简",并围绕此构建了两个关键创新:
-
空洞编码器 (Dilated Encoder):这是YOLOF的"灵魂"。它巧妙地放弃了FPN的多层级特征融合,转而在单层特征图上,通过堆叠一系列具有 **递增空洞率(Dilation Rate)**的3x3卷积,来捕获多尺度的上下文信息。这就像在二维平面上模拟出了一个"感受野金字塔",在保持结构极简的同时,有效地解决了多尺度目标的上下文建模问题。
-
统一匹配 (Uniform Matching):为了解决单层特征图预测时可能出现的正负样本稀疏问题,YOLOF为每个真值框(Ground Truth)匹配了K个最近的Anchor作为正样本。这种策略确保了即使在稀疏的单层Anchor上,也能为模型提供充足、高质量的监督信号。
总而言之,YOLOF的出现,为我们展示了一条与主流FPN截然不同的技术路径。它证明了,通过对核心矛盾(即多尺度上下文建模)的深刻洞察,我们可以用更简洁、更高效的设计,同样达到出色的性能。
回顾了YOLOF的"化繁为简",今天,我们将走向另一个极端,去探索一个通过"化简为繁、精益求精"来追求极致性能的重量级选手——DetectoRS。它将告诉我们,当网络拥有了"递归思考"的能力后,究竟能爆发出多么惊人的力量!准备好迎接这场思想的风暴了吗?Let’s dive in! ✨
摘要:
在主流的目标检测器中,信息流通常是单向的:从骨干网络(Backbone)到特征融合颈(Neck),再到检测头(Head)。骨干网络在提取特征时,对下游任务的需求一无所知,这限制了特征的"任务特异性"和质量上限。本文将深入剖析一种突破性的检测器架构——DetectoRS,它创造性地引入了"递归"机制,构建了一个宏观的反馈循环。我们将详细探讨其两大核心创新:递归特征金字塔(Recursive Feature Pyramid, RFP)和可切换空洞卷积(Switchable Atrous Convolution, SAC)。我们将解构RFP如何将Neck输出的高层语义信息反馈给Backbone,引导其进行多轮次的特征精炼;同时,我们也将揭示SAC如何让卷积层动态地、内容自适应地选择最佳的空洞率。本文不仅提供核心组件的PyTorch实现与详尽解析,更旨在阐明DetectoRS如何通过"反复思考"的机制,显著提升特征质量,有效处理困难样本,最终在COCO等基准上达到SOTA性能。
一、引言:单向信息流的"天花板"
大家好!今天我们要探讨一个非常深刻的架构设计问题。在目前我们接触过的大多数目标检测器中,无论是经典的Faster R-CNN,还是高效的YOLO系列,它们都遵循着一个共同的范式。
1.1 标准检测器的"流水线"作业模式
这个范式可以被看作是一条高效的"流水线":

信息从输入图像开始,像水流一样,单向地、不可逆地流经Backbone、Neck和Head,最终得到检测结果。这个流程非常清晰,也易于优化。但是,它隐藏着一个根本性的限制。
1.2 "无反馈"带来的问题
这条"流水线"最大的问题在于缺乏反馈(Feedback)。
想象一下,Backbone(例如ResNet)就像一个负责前期图像处理的部门。它辛辛苦苦地提取了大量的特征,然后把这些特征打包,一股脑地交给了下游的Neck部门。但是,在它工作的整个过程中,它完全不知道Neck部门和Head部门真正需要什么样的特征。
- 它不知道哪些区域包含小物体,需要保留更多的高分辨率细节。
- 它不知道哪些区域是难啃的"硬骨头",需要更深层次的语义信息。
Backbone的特征提取过程是 “盲目的”、“上下文无关的”。它只执行预设好的卷积、池化操作,而无法根据高层的、全局的语义信息来动态调整自己的行为。FPN等结构虽然在Neck层面融合了高层语义,但这些语义信息从未被用来反过来指导和优化Backbone的特征提取过程。这无疑是信息利用上的一种浪费,也构成了模型性能的"天花板"。
1.3 DetectoRS的革命性设想:建立反馈循环
DetectoRS的作者们提出了一个极具开创性的设想:我们能否打破这条单向的"流水线",建立一个宏观的反馈循环?
这个设想的核心是:
让Neck(FPN)处理完一轮特征后,把它的"批阅意见"(即包含了丰富全局语义和多尺度信息的特征图)反馈给Backbone。然后,让Backbone拿着这份"意见",对原始图像再看一遍、再想一遍,从而提炼出更高质量、更具任务导向性的特征。
这个过程可以递归地进行多次,每一次都让特征得到进一步的精炼。这就是DetectoRS(Detectors with Recursive Feature Pyramid and Switchable Atrous Convolution)中"Recursive"一词的由来。它让网络从一个简单的"流水线工人",进化成了一个会"反复审视、迭代优化"的"专家"。
二、核心创新一:递归特征金字塔 (RFP)
递归特征金字塔(RFP)是实现上述宏观反馈循环的核心机制。它的设计思想是,将整个Backbone+FPN的结构,在"时间"维度上展开,形成多个阶段。
2.1 宏观递归:将整个Backbone-Neck结构展开
传统的网络是空间上的深,而RFP引入了"时间"上的深。一个包含 K 个递归步骤的RFP,其计算流程如下:
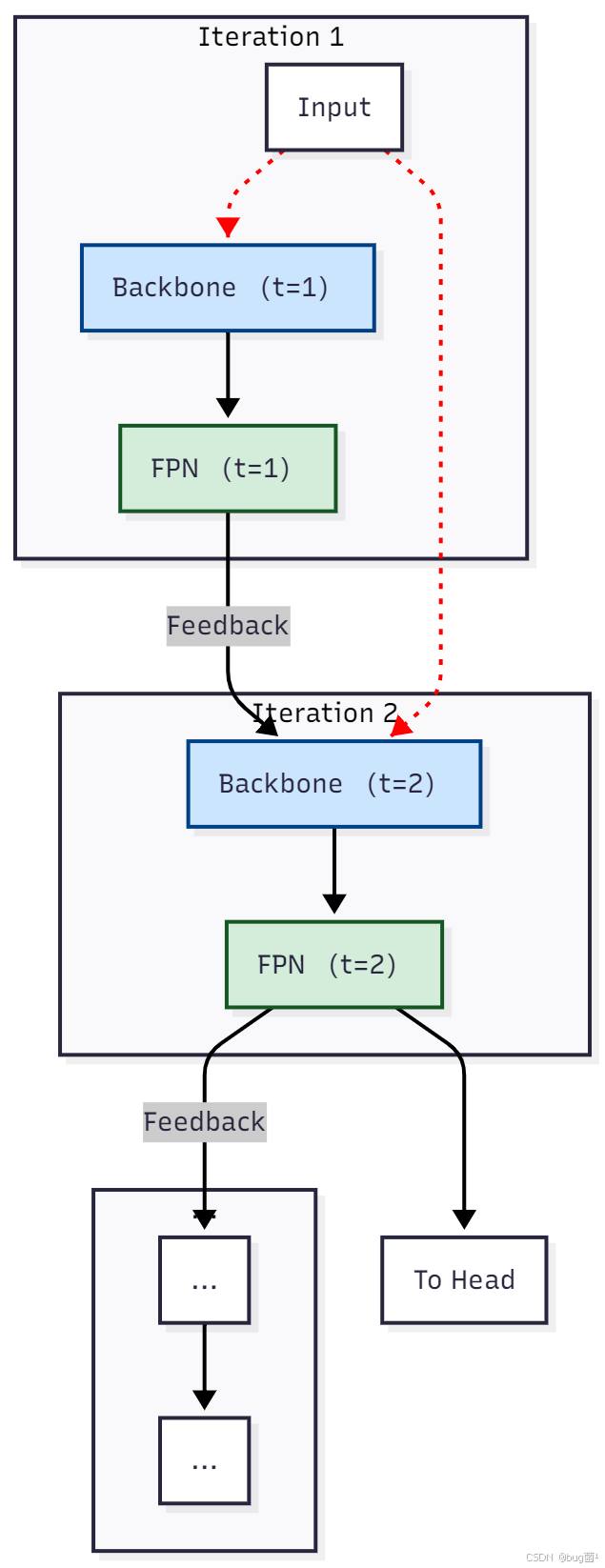
从图中可以看到,信息不再是单向流动了。FPN的输出形成了一条红色的反馈链路,回流到了下一阶段Backbone的输入端,从而实现了闭环。
2.2 RFP的工作流程:一次完整的"思考"与"反馈"
让我们以从 t-1 阶段到 t 阶段的转换为例,详细拆解其工作流程:
- 前向传播 (t-1):原始图像 I 输入到 Backbone_t-1,得到骨干特征 B_t-1。然后 B_t-1 输入到 FPN_t-1,得到金字塔特征 F_t-1。
- 反馈信息生成:将 FPN_t-1 的所有层级特征(例如P2到P6)进行处理,转换成一种适合"注入"回Backbone的形式。这个过程是RFP的关键。
- 特征注入 (t):在 t 阶段,当Backbone_t在处理图像I时,在它的每一个阶段(例如ResNet的stage1到stage4)的输出上,都加上(或拼接)来自上一步处理好的反馈信息。
- 再次前向传播 (t):经过"注入"和增强后的Backbone_t,会产生出比 B_t-1 更高质量的特征。这些特征再送入 FPN_t,得到进一步精炼的金字塔特征 F_t。
- 迭代:这个过程可以重复 K 次。最终,第 K 次迭代的 FPN_K 输出的特征将被送到检测头进行预测。
2.3 反馈信息的"打包"与"注入"
如何将FPN的输出 F_t-1 "打包"成有效的反馈信息呢?DetectoRS的做法是:
- 统一尺度:将FPN_t-1的所有层级特征(P2到P6)通过上采样或下采样,统一到一个共同的、较小的尺度(例如P4的尺度)。
- 上下文聚合:将统一尺度后的特征拼接起来,并通过一个类似 ASPP (Atrous Spatial Pyramid Pooling) 的模块。这个模块使用不同空洞率的卷积来捕获丰富的多尺度上下文信息,最终输出一个高度浓缩的上下文特征图。
- 转换与注入:将这个上下文特征图,通过 1x1 卷积进行转换,使其通道数与Backbone中对应stage的输出通道数相匹配,然后通过逐元素相加的方式,注入到Backbone的特征图中。
这个过程确保了反馈给Backbone的信息是高度浓缩的、包含了全局和多尺度语义的"精华"。
2.4 权重共享:一个网络,多次迭代
这里有一个至关重要的细节:在所有 K 次的递归迭代中,Backbone的权重是共享的,FPN的权重也是共享的。
这意味着,我们并没有训练 K 个独立的Backbone和FPN。我们训练的始终是同一个Backbone和FPN。我们是在训练它们"执行迭代式精炼"的能力。这不仅极大地节省了参数量,更重要的是,它迫使网络学习一种通用的、可迭代的特征增强策略,而不是为每个阶段学习一个固定的变换。
三、核心创新二:可切换空洞卷积 (SAC)
如果说RFP是宏观层面的"战略"创新(改变整体信息流),那么SAC(Switchable Atrous Convolution)就是微观层面的"战术"创新(改进基础卷积单元)。
3.1 动机:固定的感受野无法应对尺度变化
我们知道,空洞卷积通过调整空洞率(dilation rate),可以在不增加参数的情况下,灵活地改变卷积核的感受野。但是,在标准网络中,一个卷积层的空洞率一旦设定,就是固定不变的。
这显然是次优的。当网络处理一个包含大大小小各种物体的图像时,理想的情况是:
- 在处理大物体时,使用大的空洞率来捕获全局结构。
- 在处理小物体时,使用小的空洞率(甚至是标准的3x3卷积)来关注局部细节。
SAC的目标,就是让网络自己学会根据输入内容,为不同位置的像素动态地、自适应地选择最合适的空洞率。
3.2 SAC的结构:并行分支与"智能开关"
SAC的实现方式非常巧妙:
- 并行卷积:对同一个输入特征图 x,并行地应用多个具有不同空洞率的卷积。例如,一个分支是标准的 3x3 卷积(rate=1),另一个分支是 3x3 卷积(rate=2),等等。
- 学习"开关":将输入特征图 x 送入一个轻量级的"开关"模块(通常是一个 1x1 卷积,后接 Softmax)。这个模块会为每一个空间位置,都生成一组权重,权重的数量等于并行卷积分支的数量。
- 加权求和:将"开关"生成的权重,与对应并行卷积分支的输出,进行加权求和。
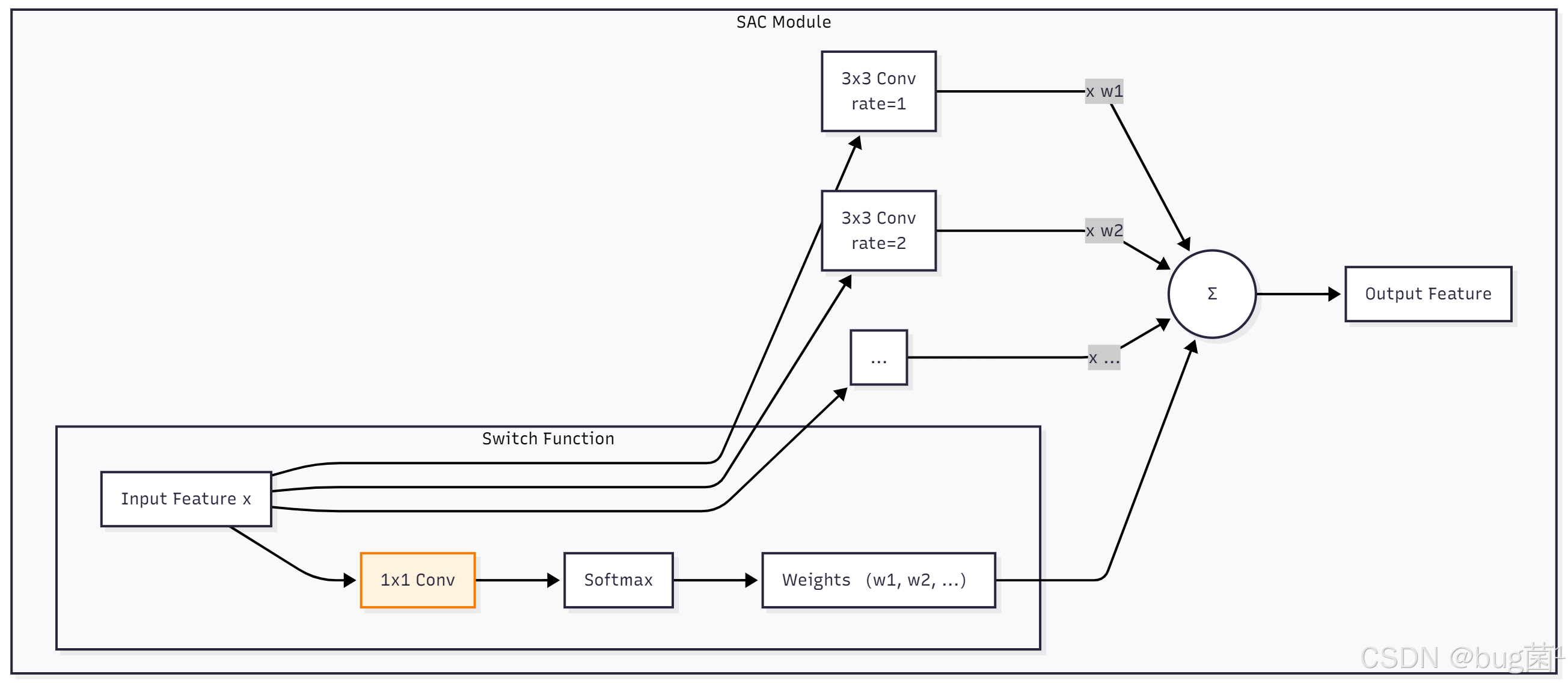
通过这种方式,如果"开关"模块在某个位置预测出权重 (0.9, 0.1, …),那就意味着对于这个位置,网络认为标准卷积(rate=1)的结果最重要。SAC将"选择"这一离散操作,通过Softmax加权的方式,变成了一个可微的、可学习的连续操作。
3.3 全局上下文指导的切换
为了让"开关"的决策更明智,DetectoRS还在开关模块中加入了一个全局平均池化分支。这意味着,在为每个像素决定使用何种空洞率时,网络不仅会考虑该像素的局部邻域信息,还会参考整张特征图的全局上下文。这使得SAC的决策更加鲁棒和准确。
四、DetectoRS整体架构:RFP与SAC的协同
DetectoRS的最终形态,是将RFP和SAC这两大创新结合在一起。具体来说,它在ResNet骨干网络的 stage3 和 stage4中,将所有的3x3 卷积都替换为了SAC模块。
这样一来,DetectoRS就实现了:
- 宏观层面:通过RFP,建立了高级语义到低级特征的反馈回路,让特征进行迭代式精炼。
- 微观层面:通过SAC,让基础卷积单元具备了内容自适应的、动态调整感受野的能力。
这两者相辅相成,共同将检测器的特征表达能力推向了一个新的高峰。
五、PyTorch核心实现与代码解析
理论的深度需要通过代码来触摸。💻 让我们来实现SAC模块,并搭建一个RFP的概念性包装器,来深入理解其工作原理。
5.1 可切换空洞卷积 (SAC) 模块实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class SAC(nn.Module):
def __init__(self,
in_channels, # 输入通道数
out_channels, # 输出通道数
kernel_size=3, # 卷积核大小
stride=1, # 步长
dilation_rates=[1, 3, 5], # 并行分支的空洞率列表
use_global_context=True): # 是否使用全局上下文指导切换
"""
SAC (Switchable Atrous Convolution) 模块
Args:
in_channels (int): 输入通道数
out_channels (int): 输出通道数
kernel_size (int): 卷积核大小
stride (int): 卷积步长
dilation_rates (list of int): 不同分支的空洞率
use_global_context (bool): 是否在开关函数中使用全局上下文
"""
super(SAC, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.dilation_rates = dilation_rates
self.num_branches = len(dilation_rates)
self.use_global_context = use_global_context
# 1. 创建并行的空洞卷积分支
self.conv_branches = nn.ModuleList()
for rate in self.dilation_rates:
padding = (kernel_size + (rate - 1) * (kernel_size - 1)) // 2
self.conv_branches.append(
nn.Conv2d(
self.in_channels,
self.out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=rate,
bias=False
)
)
# 2. 创建"开关"模块
# 开关模块的输出通道数等于分支数,用于生成每个分支的权重
self.switch_conv = nn.Conv2d(self.in_channels, self.num_branches, kernel_size=1)
# 如果使用全局上下文,则添加一个全局池化分支
if self.use_global_context:
self.global_pool = nn.AdaptiveAvgPool2d(1)
# 全局上下文分支的1x1卷积
self.global_conv = nn.Conv2d(self.in_channels, self.num_branches, kernel_size=1)
# 初始化开关的bias,使其在训练初期倾向于平均选择
nn.init.constant_(self.switch_conv.bias, 1.0 / self.num_branches)
def forward(self, x):
# --- 计算开关权重 ---
# 局部权重
local_switch_logits = self.switch_conv(x) # 形状: (B, num_branches, H, W)
# 全局权重 (如果使用)
if self.use_global_context:
global_context = self.global_pool(x)
global_switch_logits = self.global_conv(global_context) # 形状: (B, num_branches, 1, 1)
# 将局部和全局权重相加
switch_logits = local_switch_logits + global_switch_logits
else:
switch_logits = local_switch_logits
# 通过Softmax生成最终权重
# 在通道维度(dim=1)上进行Softmax,得到每个位置每个分支的权重
switch_weights = F.softmax(switch_logits, dim=1) # 形状: (B, num_branches, H, W)
# --- 计算并行分支并进行加权求和 ---
branch_outputs = []
for i in range(self.num_branches):
# 获取第i个分支的输出
branch_out = self.conv_branches[i](x)
# 获取第i个分支的权重
# unsqueeze(1)将权重从(B, H, W)变为(B, 1, H, W)以便广播
weight = switch_weights[:, i:i+1, :, :]
# 加权
branch_outputs.append(branch_out * weight)
# 将所有加权后的分支输出相加
output = torch.sum(torch.stack(branch_outputs, dim=0), dim=0)
return output
5.2 SAC模块代码逐行解析
-
__init__(...):self.conv_branches = nn.ModuleList(): 创建一个模块列表,用于存放多个并行的空洞卷积层。padding = ...: 再次强调,正确计算空洞卷积的padding以保持分辨率是关键。self.switch_conv = nn.Conv2d(...): 这是开关函数的核心,一个简单的1x1卷积。它的输出通道数被设为num_branches,因任务就是为每个分支生成一个"分数"(logit)。self.global_pool和self.global_conv: 定义了可选的全局上下文分支。nn.init.constant_(...): 一个很好的训练技巧。在训练开始时,将开关的偏置初始化,使得Softmax的输出趋向于均匀分布(每个分支权重约为1/N),避免了早期训练时网络过分偏爱某个特定分支。
-
forward(self, x):local_switch_logits = self.switch_conv(x): 计算基于局部信息的开关分数。global_switch_logits = self.global_conv(...): 计算基于全局信息的开关分数。switch_logits = local_switch_logits + global_switch_logits: 将两者相加,融合局部和全局信息来共同决策。switch_weights = F.softmax(switch_logits, dim=1): 核心步骤。dim=1确保了对于每一个像素点,所有分支的权重之和为1。branch_out * weight: 利用PyTorch的广播机制。branch_out是(B, Cout, H, W),weight是(B, 1, H, W),广播后实现对branch_out所有通道的统一加权。torch.stack和torch.sum: 将所有加权后的分支输出堆叠成一个新的维度,然后在这个维度上求和,高效地完成了最终的融合。
5.3 递归特征金字塔 (RFP) 概念性实现
完整实现DetectoRS非常复杂,涉及到对现有Backbone和FPN的深度修改。在这里,我们通过一个 包装器(Wrapper) 的形式,来概念性地、清晰地展示RFP的核心逻辑。
class RFPWrapper(nn.Module):
def __init__(self, backbone, fpn, num_recursive_steps=2):
"""
RFP的概念性包装器
Args:
backbone (nn.Module): 原始的骨干网络
fpn (nn.Module): 原始的FPN模块
num_recursive_steps (int): 递归的次数 K
"""
super(RFPWrapper, self).__init__()
# 注意:在真实实现中,backbone和fpn的权重是共享的
# 这里我们直接复用同一个实例来模拟权重共享
self.backbone = backbone
self.fpn = fpn
self.num_recursive_steps = num_recursive_steps
# --- 用于处理反馈信息的模块 ---
# 这是一个简化的ASPP模块,用于融合FPN的输出
# 假设FPN有4个输出层级,每个层级256通道
fpn_out_channels = 256
self.feedback_processor = nn.Sequential(
# 假设所有FPN输出都被resize到同一尺寸并concat
nn.Conv2d(fpn_out_channels * 4, 512, 1),
nn.ReLU(),
# 简化版ASPP: 用一个空洞卷积模拟多尺度上下文
nn.Conv2d(512, 512, 3, padding=3, dilation=3),
nn.ReLU()
)
# --- 用于将反馈信息注入Backbone的转换层 ---
# 假设Backbone有4个stage,需要4个转换层
# 这里的通道数需要与你的Backbone匹配
backbone_stage_channels = [256, 512, 1024, 2048] # ResNet50的例子
self.injection_convs = nn.ModuleList()
for c in backbone_stage_channels:
self.injection_convs.append(
nn.Conv2d(512, c, 1)
)
def forward(self, x):
# 存储每个递归步骤的FPN输出
fpn_outputs = None
# 递归循环
for i in range(self.num_recursive_steps):
# --- 特征注入 ---
feedback_info = None
if i > 0 and fpn_outputs is not None:
# 1. 准备反馈信息 (简化处理)
# 将上一轮的FPN输出resize到统一尺寸并拼接
# 此处省略了复杂的resize代码,用一个概念性的函数代替
unified_fpn_out = self._unify_fpn_features(fpn_outputs)
feedback_info = self.feedback_processor(unified_fpn_out)
# --- 执行一次Backbone + FPN ---
# 真实实现中,feedback_info会注入到backbone的每个stage
# 这里我们简化为对输入的修改,以展示逻辑
enhanced_x = x
if feedback_info is not None:
# 概念性注入: 将feedback resize到输入尺寸并相加
resized_feedback = F.interpolate(feedback_info, size=x.shape[2:], mode='bilinear')
# 假设只注入到第一个stage前的输入
enhanced_x = x + self.injection_convs[0](resized_feedback)
# 核心:每次都用权重共享的backbone和fpn
backbone_features = self.backbone(enhanced_x)
fpn_outputs = self.fpn(backbone_features)
# 返回最后一次递归的FPN输出
return fpn_outputs
def _unify_fpn_features(self, fpn_feats):
# 这是一个辅助函数,用于将不同尺寸的FPN特征统一起来
# 真实实现会更复杂,这里仅为示意
target_size = fpn_feats[1].shape[2:] # 以P3层为基准
unified = [F.interpolate(feat, size=target_size) for feat in fpn_feats]
return torch.cat(unified, dim=1)
5.4 RFP包装器代码解析与讨论
-
__init__(...):- 它接收一个现成的
backbone和fpn作为输入。通过在循环中重复调用这两个相同的实例,我们巧妙地模拟了权重共享。 self.feedback_processor: 这是一个简化的模块,代表了"打包"反馈信息的过程。它接收拼接后的FPN特征,并通过类似ASPP的操作来提取上下文。self.injection_convs: 这代表了将"打包"好的反馈信息,转换为适合注入到Backbone各个阶段的形式的转换层。
- 它接收一个现成的
-
forward(self, x):for i in range(...): 核心的递归循环。if i > 0 ...: 从第二次迭代开始,就需要利用上一次的fpn_outputs来生成反馈。enhanced_x = x + ...: 这行代码概念性地展示了反馈注入的过程。在真实实现中,反馈信息会被resize到Backbone的每一个stage的输出尺寸,并通过injection_convs转换后,与对应stage的特征图相加,而不是简单地与原始输入x相加。我们的简化是为了让核心的循环逻辑更加突出。
-
代码的意义:尽管这个实现是概念性的,但它清晰地展示了RFP的算法流程:循环(for loop)、反馈(
feedback_info)、共享(复用self.backbone和self.fpn)。
六、性能分析与讨论
6.1 在COCO基准上的惊人表现
DetectoRS一经推出,便在COCO test-dev数据集上取得了当时最优的成绩,在单模型单尺度测试的情况下,其AP达到了惊人的54.7%,这在当时是极为领先的。这强有力地证明了其递归架构在提升检测精度上的巨大潜力。
6.2 消融实验:RFP与SAC的贡献
论文中的消融实验清晰地展示了每个组件的价值:
- 基线 (ResNeXt-101 + FPN): AP 约为 48.9%
- + SAC: AP 提升至 50.4% (+1.5)。证明SAC作为一种更强大的卷积单元,能显著提升特征质量。
- + RFP (2次迭代): AP 提升至 51.3% (+2.4)。证明RFP的反馈机制是性能提升的主要来源。
- + RFP + SAC (完整的DetectoRS): AP 达到 52.2% (+3.3)。证明两者可以协同工作,取得1+1>2的效果。
实验还表明,将递归次数 K 从1增加到2,性能有显著提升。但从2增加到3,性能提升变缓,而计算成本却线性增加,因此 K=2 是一个很好的平衡点。
6.3 优势:为何"反复思考"如此有效?
-
特征的深度精炼:每一次递归,都是一次利用全局语义信息对局部细节进行重新审视和校准的过程。这使得最终的特征图对物体的边界、类别和位置的表征都更加精准。
-
处理困难样本:对于那些被遮挡、模糊或尺度极端的困难样本,第一遍前向传播可能无法形成有效的特征。RFP的反馈机制给了网络"第二次机会",可以根据第一次的初步判断,在下一次迭代中有针对性地去关注和增强这些困难区域的特征。
-
任务对齐:反馈信息来自于服务于最终检测任务的FPN,因此它携带了任务相关的"先验知识"。将这些信息注入回Backbone,使得Backbone的特征提取过程从一开始就更具"任务导向性",缓解了Backbone与下游任务之间的隔阂。
6.4 代价:性能的"重量级"交换
天下没有免费的午餐。DetectoRS的强大性能,是以巨大的计算成本为代价换来的。
-
计算量与内存:RFP需要将Backbone重复执行
K次,这使得模型的总计算量和训练时的内存占用大致也增加了K倍。这使其成为一个名副其实的"重量级"模型,难以在资源受限的设备上部署。 -
推理速度:同样,
K次迭代也意味着推理时间的大幅增加,使其不适用于实时检测场景。
DetectoRS是一个典型的"学院派"模型,它的目标是探索性能的极限,而不是追求部署的效率。
七、总结与展望
今天,我们一同攀登了DetectoRS这座目标检测领域的"高峰"。我们深入探索了它如何通过 **递归特征金字塔(RFP)构建宏观反馈,以及如何通过可切换空洞卷积(SAC) **实现微观的自适应感受野。
DetectoRS的核心贡献在于,它打破了传统检测器中根深蒂固的单向信息流假设。它向我们证明,通过建立一个让高层语义能够指导底层特征提取的反馈机制,我们可以让网络学会"反复思考"和"迭代精炼",从而系统性地、大幅度地提升特征的质量和检测的精度。
尽管其巨大的计算开销限制了它的实际应用,但DetectoRS所蕴含的设计哲学——反馈、递归、迭代优化——为未来的模型架构设计提供了极其宝贵的思路。它如同一座灯塔,指引着我们去探索更智能、更强大的网络信息交互方式。
感谢大家一同完成这次烧脑而又收获满满的探索之旅!我们下期再见!👋
下期预告:精彩继续 ✨
【第19节】GiraffeDet长颈鹿特征网络
在领略了DetectoRS这种通过"时间递归"实现的深度交互之后,下一期,我们将把目光转向一种同样致力于优化信息流,但思路截然不同的架构——GiraffeDet (长颈鹿检测器)。
它关注的是FPN中一个长期被忽视的问题:空间信息传递路径依然太短、太局部化了! FPN的信息交互主要发生在相邻的层级之间,那么,如何才能让金字塔的"顶端"和"底端"进行更直接、更高效的对话呢?
我们将一起探索GiraffeDet的奇思妙想:
- 何为"长颈鹿"网络? GiraffeDet如何通过其独特的"长颈"连接,实现跨越多个层级的长距离信息传递?
- 轻量级与全局性的平衡:它是如何设计一种既能连接遥远层级,又不会引入过多计算开销的全局信息交换机制的?
- 这种"一步到位"式的长距离依赖建模,对于小目标检测等挑战性任务,会带来怎样的奇效?
如果你对如何构建更高效、更全局化的特征信息网络充满兴趣,那么下一期的GiraffeDet,一定会让你眼前一亮!敬请期待!😉
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是计算机视觉、图像识别等领域的讲师 & 技术专家博客作者,笔名bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)