穿透C++的语法糖,理解底层实现——智慧航道场景下的实践与思考
C++语法糖在智慧航道系统中的底层优化与应用 摘要:本文探讨C++语法糖在智慧航道系统中的高效实现与优化应用。重点分析了右值引用与移动语义如何破解大数据传输瓶颈,通过船舶轨迹数据类实例展示移动构造函数的资源窃取机制,相比深拷贝性能提升显著。同时剖析智能指针(unique_ptr/shared_ptr/weak_ptr)的底层RAII机制及其在避免内存泄漏方面的应用,特别强调weak_ptr解决循环
在智慧航道系统开发中,C++凭借其高性能、底层可控性成为核心开发语言。从船舶动态轨迹追踪到航道环境实时监测,从海量传感器数据处理到智能避障算法执行,每一个核心模块都对程序的可靠性、效率提出了极致要求。然而,C++丰富的语法糖在简化开发的同时,也容易让开发者陷入"知其然不知其所以然"的困境。只有穿透语法糖的表象,理解其底层实现机制,才能在智慧航道这种高并发、低延迟、高可靠的场景中,写出经得起考验的代码。本文结合智慧航道的实际应用场景,通过具体代码实例,剖析C++核心语法糖的底层逻辑,并探讨其在工程实践中的优化思路。
文章目录
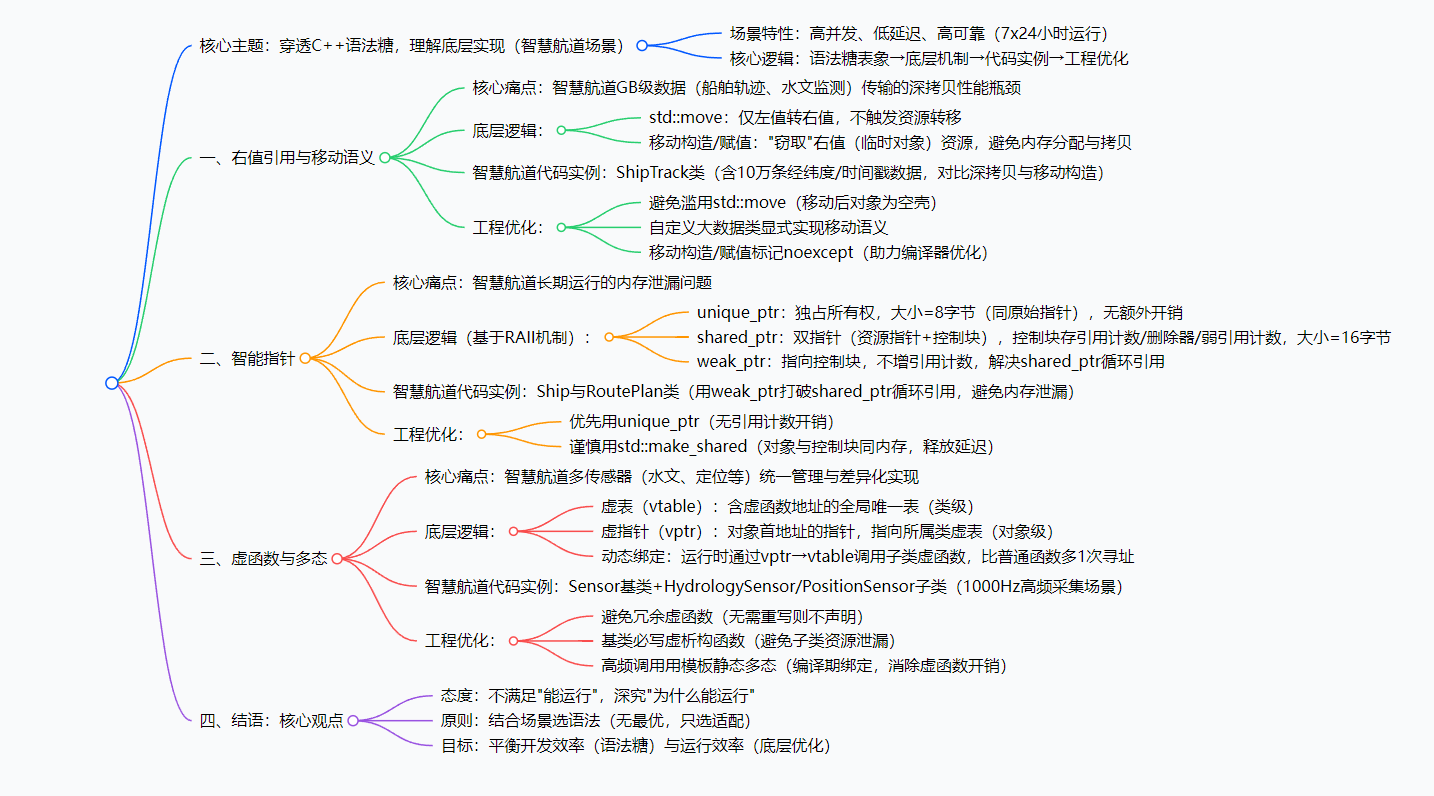
一、右值引用与移动语义:破解大数据传输的性能瓶颈
在智慧航道系统中,船舶轨迹数据、水文环境监测数据通常以结构体或类的形式存储,数据量动辄达到GB级别。传统的拷贝语义会导致大量冗余数据拷贝,严重影响数据传输和处理效率。C++11引入的右值引用(&&)和移动语义,看似简单的语法糖,其底层实则是对对象资源所有权的精准控制。
1. 语法糖背后的底层逻辑
很多开发者认为std::move是"转移对象"的魔法,但本质上,std::move只是一个类型转换工具——它将左值强制转换为右值,本身并不触发任何资源转移。真正实现资源转移的是移动构造函数和移动赋值运算符。
底层实现核心:当对象为右值(即将销毁的临时对象)时,移动构造函数会直接"窃取"其内部资源(如指针指向的堆内存),而非重新分配内存并拷贝数据。这一过程避免了昂贵的内存分配和数据拷贝操作,尤其适用于大数据对象的传递。
2. 智慧航道场景下的代码实例
以智慧航道系统中的船舶轨迹数据类ShipTrack为例,该类存储船舶的经纬度序列、时间戳数组等大数据量成员:
#include <vector>
#include <string>
#include <utility> // 包含std::move
// 船舶轨迹数据类:智慧航道核心数据结构
class ShipTrack {
private:
std::vector<double> lngs; // 经度序列(可能包含数万条数据)
std::vector<double> lats; // 纬度序列
std::vector<long long> times; // 时间戳序列
std::string shipId; // 船舶ID
int dataSize; // 数据条数
public:
// 普通构造函数:初始化轨迹数据
ShipTrack(std::string id, std::vector<double> l, std::vector<double> la, std::vector<long long> t)
: shipId(std::move(id)), lngs(std::move(l)), lats(std::move(la)), times(std::move(t)),
dataSize(static_cast<int>(lngs.size())) {}
// 拷贝构造函数(深拷贝):左值对象拷贝时调用
ShipTrack(const ShipTrack& other)
: lngs(other.lngs), lats(other.lats), times(other.times),
shipId(other.shipId), dataSize(other.dataSize) {
// 底层:重新分配内存并拷贝所有数据,耗时巨大
std::cout << "深拷贝构造:耗时操作" << std::endl;
}
// 移动构造函数(浅拷贝+资源窃取):右值对象拷贝时调用
ShipTrack(ShipTrack&& other) noexcept
: lngs(std::move(other.lngs)), lats(std::move(other.lats)), times(std::move(other.times)),
shipId(std::move(other.shipId)), dataSize(other.dataSize) {
// 底层:直接接管other的资源,other变为空对象(不负责资源释放)
other.dataSize = 0;
std::cout << "移动构造:高效资源转移" << std::endl;
}
// 移动赋值运算符
ShipTrack& operator=(ShipTrack&& other) noexcept {
if (this != &other) {
// 释放当前对象资源
lngs.clear();
lats.clear();
times.clear();
// 窃取other的资源
lngs = std::move(other.lngs);
lats = std::move(other.lats);
times = std::move(other.times);
shipId = std::move(other.shipId);
dataSize = other.dataSize;
other.dataSize = 0;
}
std::cout << "移动赋值:高效资源转移" << std::endl;
return *this;
}
// 获取数据大小
int getSize() const { return dataSize; }
};
// 智慧航道数据处理函数:接收轨迹数据并处理
void processTrack(ShipTrack track) {
// 模拟数据处理:轨迹分析、异常检测等
std::cout << "处理船舶轨迹,数据条数:" << track.getSize() << std::endl;
}
int main() {
// 模拟采集船舶轨迹数据(大数据量)
std::vector<double> lngs(100000, 120.345); // 10万条经度数据
std::vector<double> lats(100000, 31.234); // 10万条纬度数据
std::vector<long long> times(100000, 1699999999); // 时间戳
// 场景1:传递左值对象(触发深拷贝)
ShipTrack track1("SHIP001", lngs, lats, times);
processTrack(track1); // 输出:深拷贝构造:耗时操作
// 场景2:传递右值对象(触发移动构造)
ShipTrack track2("SHIP002", lngs, lats, times);
processTrack(std::move(track2)); // 输出:移动构造:高效资源转移
return 0;
}
3. 工程实践优化要点
在智慧航道系统的轨迹数据分发、传感器数据聚合等模块中,优化效果显著:
- 避免盲目使用
std::move:std::move后的对象会变为"空壳",不可再使用,尤其在多线程数据传递中需格外注意; - 为自定义大数据类显式实现移动构造/赋值:STL容器已支持移动语义,但自定义类需手动实现,否则会默认调用拷贝构造;
- 结合
noexcept:移动构造/赋值标记noexcept可让编译器优化(如vector扩容时优先选择移动而非拷贝),在智慧航道高并发数据处理中能减少异常开销。
二、智能指针:内存安全的底层实现与航道场景避坑
智慧航道系统需要长期运行(7x24小时),内存泄漏是致命问题。C++的智能指针(unique_ptr、shared_ptr、weak_ptr)看似是"自动管理内存"的语法糖,其底层实则是基于RAII(资源获取即初始化)机制,通过对象生命周期管理指针资源。
1. 语法糖背后的底层逻辑
unique_ptr:底层是"独占所有权"的指针封装,禁用拷贝构造和赋值运算符,仅允许移动语义。其大小与原始指针一致(通常8字节),无额外开销;shared_ptr:底层包含两个指针——指向资源的原始指针和指向"控制块"的指针(控制块存储引用计数、删除器、弱引用计数)。因此shared_ptr大小是原始指针的2倍,且引用计数的原子操作存在轻微开销;weak_ptr:不持有资源所有权,仅指向shared_ptr的控制块,用于解决shared_ptr的循环引用问题。
2. 智慧航道场景下的代码实例
智慧航道系统中,Ship(船舶)对象和RoutePlan(航线规划)对象存在关联关系,若使用原始指针易导致内存泄漏,使用智能指针需理解其底层机制避免陷阱:
#include <memory>
#include <string>
#include <iostream>
// 前置声明
class RoutePlan;
// 船舶类:智慧航道核心实体
class Ship {
private:
std::string shipId;
// 错误示例:shared_ptr循环引用
// std::shared_ptr<RoutePlan> routePlan;
// 正确示例:weak_ptr打破循环引用
std::weak_ptr<RoutePlan> routePlan;
public:
Ship(std::string id) : shipId(id) {
std::cout << "Ship " << shipId << " 构造" << std::endl;
}
~Ship() {
std::cout << "Ship " << shipId << " 析构" << std::endl;
}
void setRoutePlan(std::shared_ptr<RoutePlan> plan) {
routePlan = plan; // weak_ptr接收shared_ptr,不增加引用计数
}
std::string getShipId() const { return shipId; }
};
// 航线规划类:关联船舶对象
class RoutePlan {
private:
std::string planId;
std::shared_ptr<Ship> ship; // 持有船舶的shared_ptr
public:
RoutePlan(std::string id) : planId(id) {
std::cout << "RoutePlan " << planId << " 构造" << std::endl;
}
~RoutePlan() {
std::cout << "RoutePlan " << planId << " 析构" << std::endl;
}
void bindShip(std::shared_ptr<Ship> s) {
ship = s;
}
std::string getPlanId() const { return planId; }
};
// 智慧航道航线管理模块
void routeManagement() {
// 创建船舶对象:unique_ptr独占所有权,适合无需共享的场景
std::unique_ptr<Ship> ship1 = std::make_unique<Ship>("SHIP003");
// 创建航线规划对象:shared_ptr支持共享所有权
std::shared_ptr<RoutePlan> plan1 = std::make_shared<RoutePlan>("PLAN001");
// 绑定关系
plan1->bindShip(ship1); // unique_ptr移动到shared_ptr
ship1->setRoutePlan(plan1);
// 底层机制:
// ship1(已移动)不再持有所有权,plan1的ship成员持有Ship的shared_ptr(引用计数=1)
// plan1的引用计数=1,ship1的routePlan是weak_ptr,不增加plan1的引用计数
}
int main() {
routeManagement();
// 若使用shared_ptr循环引用,此处Ship和RoutePlan都不会析构(内存泄漏)
// 正确使用weak_ptr后,会正常析构:
// RoutePlan PLAN001 析构
// Ship SHIP003 析构
return 0;
}
3. 工程实践优化要点
在智慧航道的设备管理、航线规划等模块中,智能指针的正确使用至关重要:
- 优先使用
unique_ptr:当资源无需共享时,unique_ptr效率最高(无引用计数开销),如单个传感器数据采集对象; - 避免
shared_ptr循环引用:船舶与航线、设备与监测数据等关联场景,用weak_ptr打破循环,否则会导致内存泄漏; - 谨慎使用
std::make_shared:std::make_shared将对象和控制块分配在同一块内存,提升效率,但会导致对象内存释放延迟(需等待弱引用计数为0),在智慧航道海量设备场景下可能增加内存占用。
三、虚函数与多态:底层虚表机制在航道设备适配中的应用
智慧航道系统包含多种类型的传感器(水文传感器、气象传感器、船舶定位传感器等),不同传感器的数据采集和解析逻辑不同。C++的虚函数多态是实现"同一接口、不同实现"的核心语法糖,其底层依赖虚表(vtable)和虚指针(vptr)机制。
1. 语法糖背后的底层逻辑
- 虚表(vtable):每个包含虚函数的类会生成一个全局唯一的虚表,存储该类所有虚函数的地址;
- 虚指针(vptr):每个包含虚函数的对象会隐含一个虚指针(通常位于对象内存布局的首地址),指向所属类的虚表;
- 动态绑定:当通过基类指针/引用调用虚函数时,编译器会通过对象的vptr找到对应的vtable,再根据函数索引调用具体实现,这一过程在运行时完成(动态绑定)。
底层开销:虚函数调用比普通函数调用多一次vptr->vtable的寻址操作,虽开销微小,但在智慧航道传感器数据高频采集(如1000Hz采样)场景下,累计开销不可忽视。
2. 智慧航道场景下的代码实例
以智慧航道传感器数据采集模块为例,通过多态实现不同传感器的统一管理:
#include <iostream>
#include <string>
// 传感器基类:统一接口
class Sensor {
protected:
std::string sensorId;
double data; // 采集到的数据
public:
Sensor(std::string id) : sensorId(id), data(0.0) {
std::cout << "Sensor " << sensorId << " 构造" << std::endl;
}
// 虚析构函数:确保子类对象通过基类指针释放时调用正确析构函数
virtual ~Sensor() {
std::cout << "Sensor " << sensorId << " 析构" << std::endl;
}
// 虚函数:数据采集(子类重写)
virtual void collectData() = 0;
// 虚函数:数据解析(子类重写)
virtual void parseData() = 0;
// 普通函数:获取数据(无需多态)
double getData() const {
return data;
}
};
// 水文传感器(子类)
class HydrologySensor : public Sensor {
public:
HydrologySensor(std::string id) : Sensor(id) {}
~HydrologySensor() override {
std::cout << "HydrologySensor " << sensorId << " 析构" << std::endl;
}
void collectData() override {
// 模拟水文数据采集:水深、流速等
data = 15.6; // 示例数据:水深15.6米
std::cout << "HydrologySensor " << sensorId << " 采集数据:" << data << std::endl;
}
void parseData() override {
// 水文数据解析逻辑
std::cout << "HydrologySensor " << sensorId << " 解析数据:水深" << data << "米" << std::endl;
}
};
// 船舶定位传感器(子类)
class PositionSensor : public Sensor {
public:
PositionSensor(std::string id) : Sensor(id) {}
~PositionSensor() override {
std::cout << "PositionSensor " << sensorId << " 析构" << std::endl;
}
void collectData() override {
// 模拟定位数据采集:经纬度合并为数值(示例)
data = 120.345 + 31.234; // 经度+纬度(简化表示)
std::cout << "PositionSensor " << sensorId << " 采集数据:" << data << std::endl;
}
void parseData() override {
// 定位数据解析逻辑
std::cout << "PositionSensor " << sensorId << " 解析数据:经纬度合并值" << data << std::endl;
}
};
// 智慧航道数据采集管理模块
void collectSensorData(Sensor* sensor) {
sensor->collectData(); // 动态绑定:运行时调用子类实现
sensor->parseData();
}
int main() {
Sensor* hydSensor = new HydrologySensor("HYD001");
Sensor* posSensor = new PositionSensor("POS001");
// 统一接口管理不同传感器
collectSensorData(hydSensor);
collectSensorData(posSensor);
// 释放资源:虚析构函数确保子类析构被调用
delete hydSensor;
delete posSensor;
return 0;
}
3. 工程实践优化要点
在智慧航道传感器网络(可能包含数千个传感器)中,多态的高效使用需注意:
- 避免不必要的虚函数:若函数无需重写,不要声明为虚函数,减少vtable和vptr的开销;
- 虚析构函数不可少:通过基类指针管理子类对象时,必须声明虚析构函数,否则会导致子类资源泄漏;
- 静态多态替代动态多态:对于高频调用的传感器采集函数,可使用模板实现静态多态(编译期绑定),消除虚函数调用开销:
// 静态多态优化:编译期绑定,无虚函数开销
template <typename SensorType>
void collectDataStatic(SensorType& sensor) {
sensor.collectData();
sensor.parseData();
}
// 调用方式
HydrologySensor hydSensor("HYD002");
collectDataStatic(hydSensor); // 编译期确定调用HydrologySensor的实现
四、结语:语法糖是工具,底层是根基
最后做个总结,个人觉得C++ 的语法糖是提升开发效率的强大工具,但在智慧航道这种对性能、可靠性要求极高的场景中,仅依赖语法糖的 “表面用法” 远远不够。右值引用的资源转移、智能指针的内存管理、虚函数的动态绑定,每一个语法糖背后都隐藏着深刻的底层逻辑 —— 内存布局、编译器优化、操作系统机制等。
不管是我作为智慧航道系统的开发者,还是各位读者在学习和应用的过程中,我们都需要考虑下面3点:
- 保持"打破砂锅问到底"的态度:不满足于"这样写能运行",更要探究"为什么能运行";
- 结合场景选择合适的语法特性:没有最好的语法,只有最适合场景的用法;
- 平衡开发效率与运行效率:语法糖简化开发,但底层优化决定系统上限。
穿透语法糖的表象,掌握底层实现原理,才能在各种系统的复杂场景中,写出高效、可靠、可维护的代码。正如航道的安全运行依赖于对水文、气象、地形等底层环境的深刻理解,C++ 编程的高效可靠也离不开对语言底层机制的精准把握。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)