【深度强化学习】DQN论文笔记:Human-level control through deep reinforcement learning
Google DeepMind团队2015年在《Nature》发表的论文提出了一种深度Q网络(DQN),首次实现AI在多种Atari游戏中达到人类水平的性能。该模型将Q-learning与深度卷积神经网络结合,直接从像素输入学习控制策略,无需人工特征设计。通过创新性地采用经验回放和目标网络机制,解决了传统方法的稳定性问题。
目录
简介
论文题目:《Human-level control through deep reinforcement learning》
论文来源:Nature 2015,Google DeepMind 团队
论文链接:Human-level control through deep reinforcement learning | Nature
它标志着深度强化学习(Deep Reinforcement Learning, DRL)领域的一个里程碑,首次展示了人工智能可以在多种复杂任务中达到接近甚至超越人类水平的表现,而无需针对每个任务专门设计特征。
主要思想
文章提出了一种名为 深度 Q 网络(Deep Q-Network, DQN) 的新方法,将 Q-learning(一种经典强化学习算法) 与 深度卷积神经网络(CNN) 相结合,从而能够直接从高维原始像素输入(如游戏画面)中学习控制策略。
简单说:DQN 能像人一样“看”屏幕、“玩”游戏,并通过试错学会怎么玩得更好——而且用的是同一个算法玩 49 种不同的 Atari 游戏!
方法
DQN 方法流程(以 Atari 游戏为例)
一、初始化
-
构建两个相同的深度 Q 网络:
-
主网络(online network):参数为 θ,用于选择动作和计算当前 Q 值。
-
目标网络(target network):参数为 θ-,用于计算 Bellman 目标值。
-
初始时令θ- ←θ。
-
-
创建经验回放缓冲区(Replay Buffer)D,容量通常为 1,000,000 条经验。
-
设置超参数:
- 折扣因子
- 探索率
:从 1.0 线性衰减到 0.1(前 1M 帧)
- 批量大小:32
- 目标网络更新周期:每 C = 10,000步同步一次
- 训练总步数:5000 万帧(约 38 天游戏时间)
- 折扣因子
-
预处理函数
:将原始帧转为 84×84 灰度图,并堆叠最近 4 帧作为状态输入。
CNN 作为 Q 函数的逼近器,Q 函数被参数化为一个神经网络:
状态 s(预处理后的图像)作为 CNN 的输入
CNN 的输出层有多个节点,每个节点对应一个动作 a 的 Q 值
智能体选择 Q 值最大的动作
二、与环境交互(数据收集)
对每一帧 到
(总帧数):
-
观察原始帧
(210×160 彩色图像)。
-
构建状态
→ 输出为 84×84×4 的张量。 -
选择动作
(
-
以概率
-
否则:
(利用)
-
-
执行动作
-
奖励
(论文中裁剪为 $[-1, 0, +1]$)
-
下一帧
-
-
存储经验到 Replay Buffer:
⚠️ 注意:此阶段不进行网络训练,仅收集数据。
三、网络训练(离线更新)
每隔 4 帧(即每 4 步)执行一次训练(减少计算开销):
-
从 Replay Buffer 中均匀随机采样一个 batch(如 32 条经验):
-
对每条经验计算目标值
(使用目标网络):
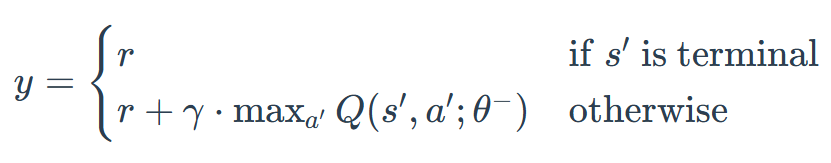
-
计算主网络的预测值:
-
定义损失函数(均方误差):
-
执行一次梯度下降更新主网络参数
(如使用 RMSProp)。
四、目标网络同步
-
每
次训练步,执行:
-
在两次同步之间,
保持固定不变,确保目标值稳定。
θi:主网络参数 (参与预测)—— 频繁更新,每进行一次训练(即每处理1个 batch)就更新一次
θi−:目标网络参数(参与计算目标值) —— 缓慢/周期性更新,目标不会剧烈波动,避免了“自指循环”导致的发散。每隔 C 步(论文中典型值:C=10,000)才更新一次,在两次更新之间,θi−完全固定不变,更新时直接复制主网络的当前参数:θ−←θ
这个损失函数衡量的是:“当前 Q 网络预测的动作价值”与“根据 Bellman 方程计算的理想目标价值”之间的差距。通过最小化这个差距,AI 逐步学会预测每个动作在未来能带来多少总奖励。
五、决策阶段(评估或部署)
当需要让智能体“认真玩”(如测试性能)时:
-
关闭探索:设
(保留少量随机性以防卡死)
-
对每个状态
:
-
输入 CNN 主网络
-
选择动作
-
-
不存储经验,也不更新网络(纯推理模式)
论文中报告的“人类水平比较”就是在这种模式下运行 30 轮取平均得分。
六、关键技术组件总结
| 组件 | 作用 | 生物/工程启发 |
|---|---|---|
| 深度卷积网络 | 从像素自动提取特征,输出 Q 值 | 模仿视觉皮层层次化处理(Hubel & Wiesel) |
| 经验回放 | 打乱数据顺序,消除时间相关性 | 类似海马体“离线重放”巩固记忆 |
| 目标网络 | 提供稳定 Bellman 目标,防止发散 | 工程技巧,避免自指循环 |
| 奖励裁剪 | 将 $r \in [-1, +1]$,提升训练稳定性 | 防止梯度爆炸,统一不同游戏尺度 |
七、最终效果
- 输入:仅原始像素 + 游戏得分(无内部状态、无规则说明)
- 输出:在 49 个 Atari 游戏中,29 个达到人类水平 75% 以上
- 通用性:同一架构、同一超参、同一算法,无需任务定制
技术关键点
-
端到端学习(End-to-End Learning)
-
输入:原始像素(210×160 RGB 图像,每秒 60 帧)
-
输出:每个可能动作的 Q 值(即预期未来奖励)
-
中间:一个深度卷积神经网络自动提取有用特征(无需人工设计)
-
-
挑战:为什么以前做不到?
使用神经网络拟合 Q 函数时容易不稳定甚至发散,原因包括:-
观测序列高度相关(比如连续几帧画面几乎一样)
-
策略变化导致数据分布不断漂移
-
Q 值和目标值之间存在强耦合
-
-
DQN 的两大创新机制
-
经验回放(Experience Replay)
将智能体的经历(状态、动作、奖励、下一状态)存入记忆库,训练时随机采样。这打破了时间相关性,使学习更稳定。 -
目标网络(Target Network)
使用一个单独的、缓慢更新的网络来计算 Q-learning 的目标值,减少目标波动,防止振荡或发散。
-
-
网络结构
-
输入:84×84×4 的灰度图像堆栈(代表最近 4 帧)
-
3 层卷积 + 2 层全连接
-
输出:每个合法动作对应的 Q 值
-
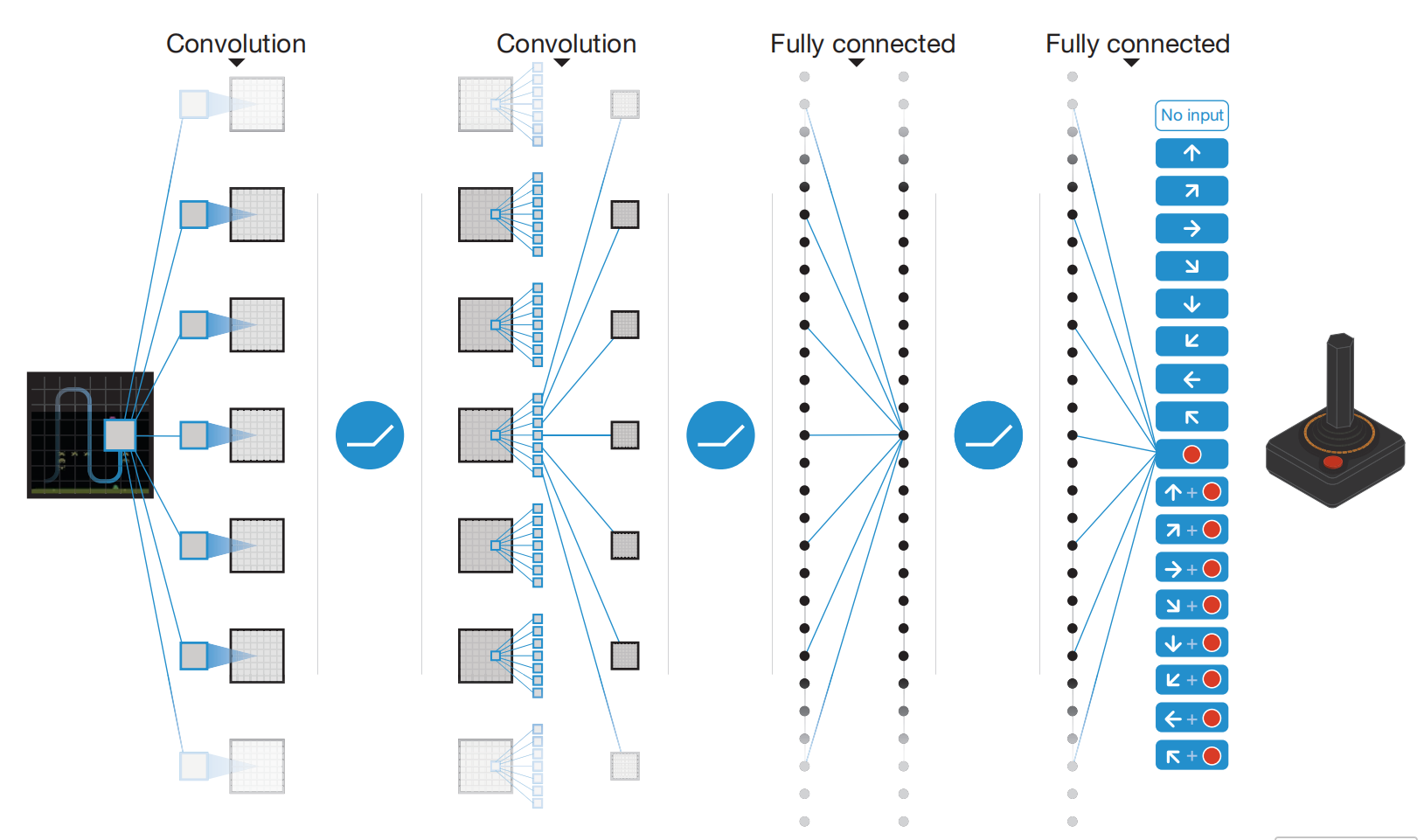
实验设置与结果
-
测试平台:Atari 2600 游戏(共 49 款,如《太空侵略者》《打砖块》《蒙特祖玛的复仇》等)
-
输入限制:仅像素画面 + 游戏得分(不提供内部状态、规则或动作含义)
-
对比对象:
-
其他强化学习算法
-
随机策略(baseline)
-
专业人类玩家(在相同条件下测试)
-
✅ 主要成果:
-
DQN 在 49 个游戏中有 43 个 表现优于之前所有 RL 方法。
-
在 29 个游戏(超过一半) 中,DQN 达到 人类水平的 75% 以上。
-
在某些游戏(如《打砖块》)中,DQN 甚至发现了人类玩家使用的高级策略(例如挖隧道让球绕后摧毁大量砖块)。
-
所有游戏使用 相同的网络架构、超参数和算法,体现了通用性。
生物学启发
论文强调其方法受到神经科学启发:
-
多巴胺神经元的“时序差分误差”信号 ≈ RL 中的 reward prediction error
-
经验回放 ≈ 海马体在休息时“重放”经历以巩固记忆
这体现了 DeepMind 一贯的“类脑 AI”理念。
局限性
-
对需要长期规划的游戏(如《蒙特祖玛的复仇》)表现不佳——因为稀疏奖励难以关联到早期动作。
-
计算成本高(训练需数千万帧)。
-
仍属离策略、模型无关方法,泛化能力有限。
意义与影响
-
首次证明:单一算法可从原始感官输入中学会多种复杂行为。
-
开启了深度强化学习的新时代,为 AlphaGo、AlphaStar 等后续突破奠定基础。
-
推动了“通用人工智能(AGI)”研究——追求一个能适应多种任务的智能体。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)