【AI大模型前沿】Qwen3-Omni:阿里巴巴通义千问团队引领全模态大模型新突破
Qwen3-Omni 是阿里巴巴 Qwen 团队最新开源的原生端到端多语言“全模态”大模型,一次性打通文本、图片、音频、视频的理解与生成,并且能做文字 + 自然语音的实时流式响应(自然轮流对话、低延迟首包)。它支持 119 种文本语言、19 种语音输入、10 种语音输出,既能“听懂世界”,也能流利地“说出来”,在加入音视能力后,并没有牺牲纯文本与图像基准的表现,同时在音频 / 音视频任务上拿到非常
系列篇章💥
目录
前言
在人工智能领域,多模态大模型的发展正不断刷新着我们对智能交互的认知。阿里巴巴通义千问团队推出的 Qwen3-Omni,作为业界首个原生端到端全模态 AI 模型,凭借其卓越的性能和广泛的应用前景,成为了当下备受瞩目的焦点。它不仅能够处理文本、图像、音频和视频等多种模态数据,还能以文本和自然语音的形式提供实时流式响应,为全球用户带来了全新的交互体验。
一、项目概述
Qwen3-Omni 是阿里巴巴 Qwen 团队最新开源的原生端到端多语言“全模态”大模型,一次性打通文本、图片、音频、视频的理解与生成,并且能做文字 + 自然语音的实时流式响应(自然轮流对话、低延迟首包)。它支持 119 种文本语言、19 种语音输入、10 种语音输出,既能“听懂世界”,也能流利地“说出来”,在加入音视能力后,并没有牺牲纯文本与图像基准的表现,同时在音频 / 音视频任务上拿到非常强的成绩。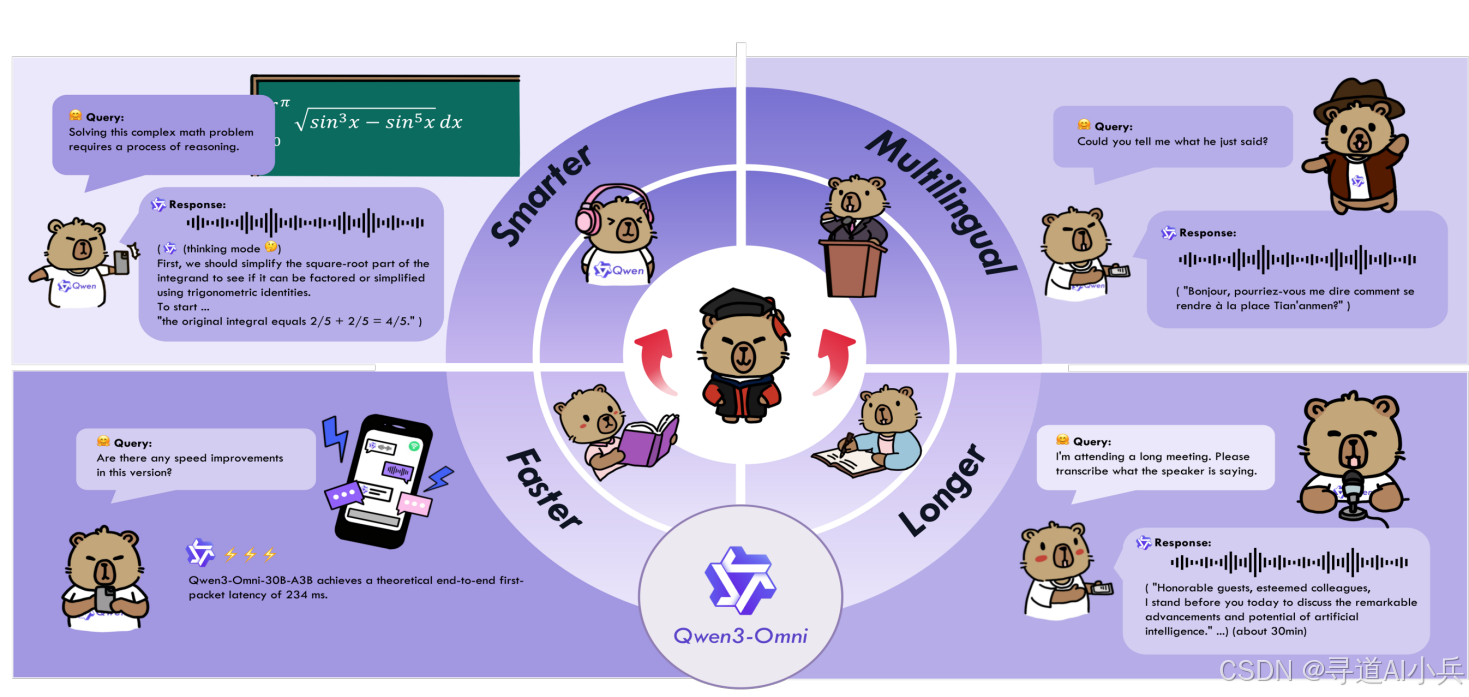
二、核心功能
(一)原生全模态
Qwen3-Omni 是原生全模态大模型,预训练全模态不降智,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。
(二)强大的性能
在 36 项音频及音视频基准测试中斩获 32 项开源 SOTA 与 22 项总体 SOTA,超越 Gemini - 2.5 - Pro、Seed - ASR、GPT - 4o - Transcribe 等闭源强模型,同时图像和文本性能在同尺寸模型中达到 SOTA 水平。
(三)多语言
Qwen3 - Omni 支持 119 种文本语言、19 种语音理解语言和 10 种语音生成语言。这种多语言能力使得模型能够在全球范围内为用户提供服务。例如,用户可以用中文上传一段音频,模型能够理解并以英文生成文本或语音回复。
(四)更快响应
Qwen3 - Omni 在响应速度上表现出色。纯模型端到端音频对话延迟低至 211 毫秒,视频对话延迟低至 507 毫秒。这种低延迟使得模型能够实时处理用户输入并提供即时反馈,极大地提升了用户体验。
(五)长音频
Qwen3 - Omni 支持长达 30 分钟的音频理解。这一功能使得模型能够处理长篇音频内容,如播客、会议录音等。例如,用户可以上传一段 30 分钟的会议录音,模型能够理解并生成详细的会议纪要或摘要。
(六)个性化
Qwen3 - Omni 支持系统提示词(system prompt)的自定义。用户可以根据自己的需求修改回复风格、人设等。例如,用户可以将系统提示词设置为“你是一位专业的法律顾问”,模型在回复时会以专业法律顾问的风格和语气进行回答。
(七)工具调用
Qwen3 - Omni 支持 function call,能够实现与外部工具和服务的高效集成。例如,用户可以通过模型调用天气查询 API,获取实时天气信息并生成相应的文本或语音回复。
(八)开源通用音频 Captioner
Qwen3 - Omni 开源了 Qwen3 - Omni - 30B - A3B - Captioner,这是一个低幻觉且非常详细的通用音频 caption 模型。该模型能够为任意音频输入生成详细的描述文本,填补了开源社区在这一领域的空白。例如,用户可以上传一段音乐音频,模型能够生成描述音乐风格、节奏和情感的详细文本。
三、技术揭秘
(一)Thinker - Talker 架构
- Thinker:主要负责文本生成任务,能处理文本输入、输出高层语义表征,为后续的语音生成提供基础信息。
- Talker:专注于流式语音 Token 的生成,直接用 Thinker 输出的语义表征,通过自回归方式预测多码本序列,实现低延迟的逐帧流式语音生成。
- MTP 模块:在解码过程中,MTP 模块负责输出当前帧的残差码本,通过 Code2Wav 模块将码本合成对应的音频波形,实现高效的流式音频生成。
(二)创新架构设计
- AuT 音频编码器:基于海量音频数据(2000 万小时)训练而成,具备强大的通用音频表征能力,为模型处理音频任务提供坚实基础。
- MoE 架构:Thinker 和 Talker 均采用 MoE(Mixture of Experts)架构,支持高并发处理和快速推理,显著提升模型在多任务处理时的效率和性能。
- 多码本技术:Talker 用多码本自回归方案,在每步生成过程中,能生成一个编解码帧,MTP 模块会同步输出剩余的残差码本,设计进一步优化语音生成的效率和质量。
(三)全模态不降智
在文本预训练阶段,模型将单模态数据与跨模态数据混合训练。混合训练方式保证了各模态的性能与纯单模态训练相当,显著增强模型的跨模态能力,使模型在处理多模态任务时更加得心应手。
(四)实时音频和音视频交互
整个流程(包括 AuT 音频编码、Thinker 文本处理、Talker 语音生成及 Code2wav 音频合成)均实现全流式处理,支持首帧 Token 直接流式解码为音频输出,确保实时音频和音视频交互的高效性和流畅性。
四、性能表现
Qwen3-Omni在全方位性能评估中,其单模态任务表现与类似大小的Qwen系列单模态模型持平,尤其在音频任务中展现显著优势。该模型在36项音视频基准测试中,36项测试中的32项取得开源领域最佳性能,22项达到SOTA水平,性能超越Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe等性能强大的闭源模型。
五、应用场景
(一)内容创作
Qwen3 - Omni 为内容创作者提供了强大的支持。无论是撰写文章、创作剧本,还是生成图像、音频和视频内容,Qwen3 - Omni 都能提供丰富的创意素材和高质量的生成结果。例如,创作者可以输入一段简单的文本描述,模型能够生成详细的文本内容、相关的图像或音频片段,甚至创作出完整的视频脚本。
(二)智能客服
在智能客服领域,Qwen3 - Omni 的多语言文本和语音交互能力使其能够快速准确地理解用户问题并提供解决方案。例如,用户可以通过语音或文本向客服系统提问,Qwen3 - Omni 能够实时理解问题并生成详细的回复。
(三)教育领域
Qwen3 - Omni 在教育领域的应用前景广阔。它能够生成个性化的学习材料和互动内容,满足不同学生的学习需求。例如,教师可以上传一段教学视频,模型能够生成相关的文字讲解、图像示例和音频讲解,帮助学生更好地理解和掌握知识。
(四)医疗辅助
在医疗领域,Qwen3 - Omni 的多模态处理能力使其能够辅助医生进行诊断和治疗方案制定。例如,医生可以上传患者的医学影像和语音记录,模型能够理解并生成详细的诊断报告和治疗建议。
(五)多媒体娱乐
Qwen3 - Omni 为多媒体娱乐行业带来了新的可能性。它能够创作音乐、视频等多媒体内容,为用户提供个性化娱乐体验。例如,用户可以根据自己的喜好输入一段文本描述,模型能够生成相应的音乐或视频内容。
(六)智能办公
在智能办公场景中,Qwen3 - Omni 能够显著提升工作效率。例如,用户可以上传会议录音,模型能够实时生成会议纪要和摘要,帮助用户快速回顾会议内容。此外,Qwen3 - Omni 还可以为办公文档生成详细的语音讲解,提升文档的可读性和理解度。这种多模态处理能力使得 Qwen3 - Omni 成为智能办公的得力助手,帮助用户更高效地完成工作任务。
六、快速使用
(一)安装依赖
安装相关依赖,准备了服务器环境:
# If you already have transformers installed, please uninstall it first, or create a new Python environment
# pip uninstall transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
# 安装工具包,需要提前准备 ffmpeg
pip install qwen-omni-utils -U
# 安装FlashAttention 2
pip install -U flash-attn --no-build-isolation
(二)模型下载
以下是以 Qwen3 - Omni - 30B - A3B - Instruct模型为例的代码示例:
# Download through ModelScope (recommended for users in Mainland China)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni-30B-A3B-Instruct
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Thinking --local_dir ./Qwen3-Omni-30B-A3B-Thinking
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Captioner --local_dir ./Qwen3-Omni-30B-A3B-Captioner
# Download through Hugging Face
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Instruct --local-dir ./Qwen3-Omni-30B-A3B-Instruct
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Thinking --local-dir ./Qwen3-Omni-30B-A3B-Thinking
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Captioner --local-dir ./Qwen3-Omni-30B-A3B-Captioner
(三)推理示例
下面代码示例,展示如何使用 Qwen3-Omni 与 transformers 和 qwen_omni_utils :
import soundfile as sf
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Thinking"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"},
{"type": "audio", "audio": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"},
{"type": "text", "text": "What can you see and hear? Answer in one short sentence."}
],
},
]
# Set whether to use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs,
speaker="Ethan",
thinker_return_dict_in_generate=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids.sequences[:, inputs["input_ids"].shape[1] :],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
print(text)
if audio is not None:
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
(四)性能优化
为了优化性能,可以使用以下技巧:
- 使用 GPU 加速:确保模型在 GPU 上运行以提高推理速度。
- 启用 FlashAttention:在使用 Hugging Face Transformers 时,启用 FlashAttention 2 可以显著降低 GPU 内存占用。
- 调整模型大小:根据实际需求选择合适的模型版本,较小的模型版本在推理速度上可能更快。
七、结语
Qwen3 - Omni 作为阿里巴巴通义千问团队推出的原生端到端全模态大模型,凭借其卓越的性能和广泛的应用场景,为多模态人工智能的发展注入了新的活力。它不仅在音频、图像和文本等多种模态任务上表现出色,还通过实时流式响应能力为用户带来了全新的交互体验。随着技术的不断进步和应用场景的不断拓展,Qwen3 - Omni 必将为人工智能领域带来更多的惊喜和突破。
八、项目地址
- 项目官网:https://qwen.ai/blog?id=65f766fc2dcba7905c1cb69cc4cab90e94126bf4&from=research.latest-advancements-list
- GitHub 仓库:https://github.com/QwenLM/Qwen3-Omni
- HuggingFace 模型库:https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
- 技术论文:https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)