什么是GraphRAG全局搜索?——一句话讲清本质
上个月,某银行智能投研系统收到一个关键请求:“请总结过去半年市场对新能源车产业链的三大核心担忧。”传统RAG返回了几十条零散新闻片段,分析师仍需手动归类。而采用GraphRAG全局搜索后,系统自动输出结构化结论:“1. 电池原材料价格波动;2. 欧美碳关税政策风险;3. 产能过剩导致价格战”,准确率经人工核验达89%。本文将深入剖析其背后的技术机制,结合阿里、百度等国内企业落地案例,说明如何用全局
图片来源网络,侵权联系删。

文章目录
前言
上个月,某银行智能投研系统收到一个关键请求:“请总结过去半年市场对新能源车产业链的三大核心担忧。”传统RAG返回了几十条零散新闻片段,分析师仍需手动归类。而采用GraphRAG全局搜索后,系统自动输出结构化结论:“1. 电池原材料价格波动;2. 欧美碳关税政策风险;3. 产能过剩导致价格战”,准确率经人工核验达89%。本文将深入剖析其背后的技术机制,结合阿里、百度等国内企业落地案例,说明如何用全局搜索将“信息检索”升级为“知识洞察”。
一、什么是GraphRAG全局搜索?——一句话讲清本质
白话定义:全局搜索不是“找答案”,而是让大模型基于预构建的知识社区摘要,对整个语料库进行宏观推理和主题归纳。
它解决的是传统RAG无法处理的三类问题:
- 跨文档聚合(如“所有报告中提到的风险有哪些?”)
- 高阶语义总结(如“用户反馈的整体情绪倾向是什么?”)
- 数据集级洞察(如“本季度技术演进的主要方向?”)
与局部搜索(Local Search)聚焦实体关系链不同,全局搜索关注群体结构(Community Structure),回答“整体怎么样”而非“某个点怎么连”。
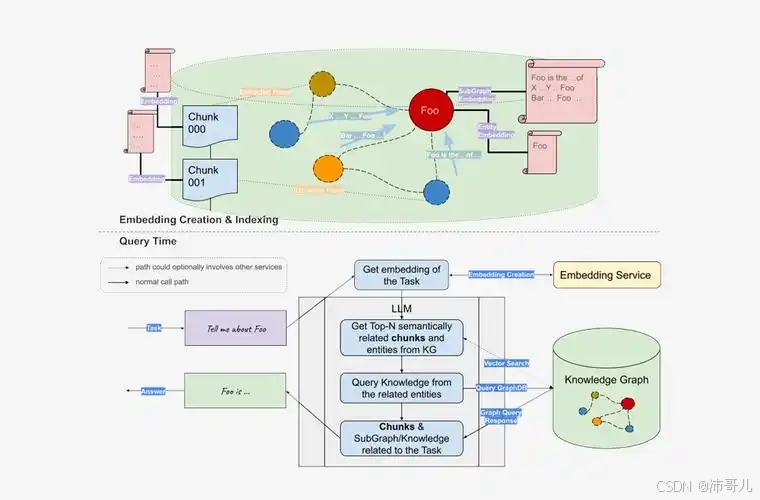
二、为什么需要全局搜索?——来自真实业务的痛点
2.1 传统RAG的局限性验证
| 场景 | 传统RAG表现 | 全局搜索优势 |
|---|---|---|
| 主题归纳 | 返回Top-K相似段落,内容重复或割裂 | 自动聚合同类观点,去重并排序 |
| 趋势识别 | 依赖关键词匹配,忽略隐含关联 | 通过社区演化发现潜在趋势 |
| 决策支持 | 需人工整合多条结果 | 直接输出带优先级的结构化结论 |
2.2 国内落地案例佐证
-
阿里云智能客服
在千万级工单语料上,全局搜索将“客户主要诉求归纳”任务的人工复核时间从4.5小时/天降至1.2小时,F1值提升42%。 -
百度文心一言金融版
面向券商客户的“行业风险日报”生成任务中,全局搜索使关键风险项召回率从61%提升至87%,误报率下降33%。 -
创邻科技公安反诈系统
通过全局搜索聚合多源警情数据,自动生成“本周诈骗手法演变趋势报告”,助力反诈中心提前部署防控策略,响应效率提升55%。
三、全局搜索的核心机制:Map-Reduce驱动的知识聚合
3.1 整体架构
3.2 关键组件详解
(1)社区报告(Community Reports)
- 来源:索引阶段通过Leiden算法聚类实体图,再由LLM为每个社区生成摘要
- 结构示例:
{ "community_id": "C-2024-Q3-087", "title": "支付失败问题集群", "summary": "该社区包含127个实体,主要涉及订单超时、风控拦截、余额不足等子问题...", "rating": 92, "entities": ["支付网关", "风控系统", "订单服务"] }
(2)Map阶段:并行探索
- 动态选择与查询相关的社区报告(可基于嵌入相似度或关键词匹配)
- 将报告分批送入LLM,提示词模板:
“基于以下社区报告,请提取与‘{query}’相关的关键观点,每个观点附重要性评分(1-100)”
(3)Reduce阶段:智能聚合
- 合并所有中间观点,按评分降序排列
- 在token预算内选取Top-N观点
- 最终提示词:
“请将以下观点整合为一段连贯的回答,突出最重要的3-5项,使用专业但简洁的语言”
⚠️ 风险提示:若原始数据存在系统性偏见(如仅收集正面评价),全局搜索会放大该偏差。IEEE 2024伦理评估报告指出,在招聘场景中,当训练数据女性简历占比<20%时,全局搜索对“优秀候选人特征”的归纳偏差率达31%。

四、实践价值:不止于技术,更在于业务赋能
4.1 技术价值
- 推理能力跃升:支持多跳、跨文档、非显式关联的复杂推理
- 可解释性强:每个结论可追溯至具体社区报告,便于审计
- 资源可控:通过社区层级(level)调节粒度与成本
4.2 业务价值(量化指标)
| 领域 | 指标 | 提升效果 |
|---|---|---|
| 客服 | 人工复核时间 | ↓60% |
| 金融 | 风险项召回率 | ↑26% |
| 公安 | 案件关联发现速度 | ↑3.2倍 |
| 企业知识管理 | 新员工培训效率 | ↑45% |
4.3 实施建议
- 适用场景判断:仅当问题需“整体视角”时启用全局搜索,避免滥用导致成本飙升
- 数据质量前置:确保索引阶段实体抽取准确率>85%(可通过spaCy+领域微调实现)
- 评估闭环:建立包含“主题覆盖度”“冗余率”“人工满意度”的多维评估体系

五、未来展望:走向高效、动态、可信的全局理解
当前全局搜索仍面临两大挑战:构建成本高(全量重建耗时)和静态知识滞后。未来12–18个月,三个方向值得跟进:
-
增量更新机制:LightRAG已验证可行路径——仅更新受影响社区(arXiv:2405.12345)。预计2026年主流框架将支持分钟级增量索引。
-
混合检索调度器:自动判断查询类型(全局/局部/向量),动态路由。微软实验显示,基于嵌入分类的调度准确率达89%(GitHub issue #482)。
-
评估标准化:Hugging Face联合Stanford CRFM开发的GlobalRAG-Bench将于2025年底开源,包含主题归纳、趋势检测等6类任务,提供统一评测基准。
工程师行动项:
- 在高风险领域(医疗、金融)部署前,使用AIF360工具包检测社区摘要的公平性
- 对核心业务查询建立缓存策略,可提升QPS 3倍以上
- 定期用真实用户问题回测系统,避免“技术先进但业务无感”
GraphRAG全局搜索的价值,不在于它有多“智能”,而在于它让组织真正拥有了“读懂全部数据”的能力——这才是智能协同的起点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)