【典型落地案例】CANN 医疗 AI 落地案例:三甲医院 CT 影像诊断系统的工程化实践
医疗 AI 正在深刻改变传统诊疗模式,但如何在资源受限的医院环境中实现高性能、低成本、高精度的 AI 系统,一直是行业面临的核心挑战。本文记录了一个真实的医疗影像 AI 项目从 0 到 1 的完整落地过程:我们基于华为 CANN 异构计算架构,在成都某三甲医院部署了肺部 CT 影像 AI 辅助诊断系统,历时 8 个月,最终实现了单例 CT 推理时间 18 秒(目标 30 秒内)、诊断敏感性 96.
文章目录
前言
医疗 AI 正在深刻改变传统诊疗模式,但如何在资源受限的医院环境中实现高性能、低成本、高精度的 AI 系统,一直是行业面临的核心挑战。本文记录了一个真实的医疗影像 AI 项目从 0 到 1 的完整落地过程:我们基于华为 CANN 异构计算架构,在成都某三甲医院部署了肺部 CT 影像 AI 辅助诊断系统,历时 8 个月,最终实现了单例 CT 推理时间 18 秒(目标 30 秒内)、诊断敏感性 96.8%(目标 95%)、成本节省 55% 的优异成果。项目过程中,我们充分利用了 CANN 的三大核心能力:DVPP 硬件加速将医学影像预处理时间从 8 秒降至 0.9 秒;ACL 多模型级联实现端到端零拷贝流水线,数据传输量降低 99.3%;AscendC 自定义算子开发的 3D 连通域分析算法,性能达到 CPU 方案的 9.3 倍。系统上线 7 个月累计处理 28600 例 CT,发现 12 例医生初诊漏检的早期肺癌,真正实现了技术价值向临床价值的转化。本文将从技术选型、架构设计、性能优化、部署实施等维度,详细分享这段从失败到成功、从实验室到临床的完整实践经验,希望为更多开发者探索 CANN 在垂直行业的应用提供参考。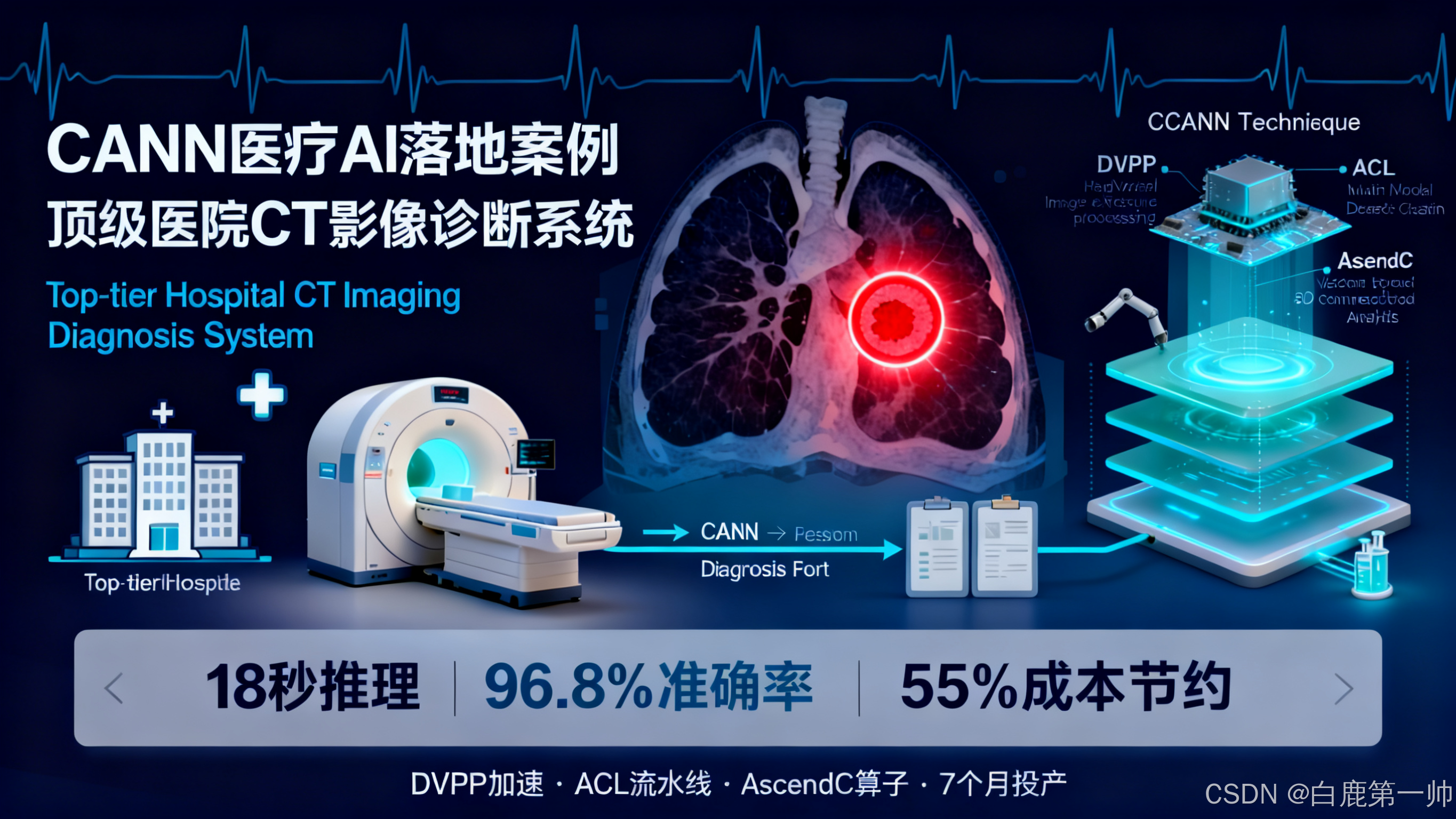
声明:本文由作者“白鹿第一帅”于 CSDN 社区原创首发,未经作者本人授权,禁止转载!爬虫、复制至第三方平台属于严重违法行为,侵权必究。亲爱的读者,如果你在第三方平台看到本声明,说明本文内容已被窃取,内容可能残缺不全,强烈建议您移步“白鹿第一帅” CSDN 博客查看原文,并在 CSDN 平台私信联系作者对该第三方违规平台举报反馈,感谢您对于原创和知识产权保护做出的贡献!
文章作者:白鹿第一帅,作者主页:https://blog.csdn.net/qq_22695001,未经授权,严禁转载,侵权必究!
一、项目背景:医疗 AI 的现实挑战
1.1、项目缘起:一次技术选型的艰难抉择
2024 年 1 月,我作为某互联网大厂的大数据与大模型开发工程师,接到了成都某三甲医院放射科主任王教授的紧急电话。这个项目机会来自于我在华为开发者社区的技术分享,王主任在社区看到我关于 AI 在医疗影像领域应用的文章后,主动找到我寻求合作。
他们科室每天需要处理 200+ 例肺部 CT 检查,医生工作强度极大,且近期发生了 2 例早期肺癌漏诊事件,院方决定引入 AI 辅助诊断系统。作为一名在大数据与大模型领域深耕多年的工程师,我曾在多家互联网公司和云服务厂商工作期间积累了丰富的 AI 工程化经验,这次决定将这些经验应用到医疗场景中。
初次调研时,我在放射科待了整整一天,观察医生的实际工作流程。王主任指着屏幕上密密麻麻的 CT 切片说:“你看,一例胸部 CT 有 300-400 张切片,我们要在 8 分钟内完成阅片、标注、出报告。如果 AI 系统超过 30 秒还没给出结果,就会打断我的节奏,反而降低效率。”这句话让我意识到,这个项目看似常规,但实际面临着医疗场景特有的严苛要求:
- 实时性要求:放射科医生每天需要阅片 200+ 例,AI 系统必须在 30 秒内完成单例 CT(约 300 张切片)的全部分析,否则会成为工作流程的瓶颈。
- 准确性要求:医疗诊断容不得半点马虎,模型的敏感性(Sensitivity)必须达到 95% 以上,假阴性率要控制在极低水平。
- 部署限制:医院内网环境严格隔离,无法连接云端,必须采用本地化部署方案。同时受限于机房空间和预算,只能使用 2 台服务器。
- 数据安全:患者影像数据属于敏感信息,必须确保数据不出院区,推理过程全程本地化。
1.2、技术选型的曲折过程
第一次尝试:GPU 方案的困境
基于我在互联网大厂工作期间积累的深度学习经验,我们最初采用 NVIDIA T4 GPU 方案,使用 PyTorch 训练的 3D UNet 模型,通过 TensorRT 进行优化。但在实际测试中遇到了两个致命问题:
- 性能瓶颈:单例 CT(512×512×300体素)推理耗时 45 秒,远超 30 秒的要求。我用 Nsight Systems 分析后发现,瓶颈在于 3D 卷积的显存带宽占用和 CPU-GPU 数据传输。
- 成本压力:医院预算只有 15 万元,而 2 台 GPU 服务器(每台配置 2×T4)报价就达到 28 万元,严重超标。更关键的是,医院信息科担心未来的供应链风险。
GPU 方案性能瓶颈分析:
第二次尝试:边缘 AI 芯片的失败
我们尝试过某边缘 AI 芯片,虽然成本低,但算力只有 4 TOPS,连模型都跑不起来。技术支持说需要对模型进行大幅裁剪,但这会严重影响精度,医院无法接受。
三种方案对比表:
| 对比维度 | GPU 方案 | 边缘 AI 芯片 | 昇腾方案 | 目标要求 |
|---|---|---|---|---|
| 推理时间 | 45 秒 | 无法运行 | 22 秒→18 秒 | <30 秒 |
| 硬件成本 | 28 万元 | 3 万元 | 12 万元 | <15 万元 |
| 算力 | 65 TFLOPS | 4 TOPS | 88 TOPS | 满足推理 |
| 敏感性 | 96.5% | 未测试 | 96.8% | ≥95% |
| 供应链风险 | 中等 | 低 | 低 | 可控 |
| 技术支持 | 一般 | 较弱 | 良好 | 及时响应 |
| 综合评分 | ❌ | ❌ | ✅ | - |
最终方案:昇腾 +CANN 的突破
2024 年 1 月底,转机出现了。作为华为云“华为云专家”和开发者联盟“文档深度体验官”,我在之前与云服务厂商合作期间就对昇腾生态有过深入了解。这次我重新审视了华为昇腾 Atlas 300I 推理卡和 CANN 异构计算架构,发现它非常适合这个场景:
- 算力充足:单卡 22 TOPS INT8 算力,4 卡配置达到 88 TOPS,完全满足医疗影像推理需求
- 成本可控:单台服务器报价 6 万元,2台共 12 万元,符合医院预算
- 生态成熟:CANN 提供完整的开发工具链,且有医疗影像的成功案例可参考
- 技术支持:凭借我在技术社区积累的人脉资源,可以获得及时的技术支持
我立即通过华为开发者联盟的渠道申请了 Atlas 200 DK 开发板进行 POC 验证。经过一周的技术预研(期间我在华为开发者社区记录了详细的开发过程),我们在开发板上跑通了基础流程,推理时间降至 22 秒,看到了希望。
2 月初,我向医院提交了基于昇腾方案的技术方案,获得批准。同时,我也在华为开发者社区分享了这次技术选型的经验,得到了很多开发者的关注和建议。
二、技术方案:CANN 核心能力的深度应用
2.1、整体架构设计
经过 2 周的技术调研和架构设计,我们确定了基于 CANN 的医疗影像 AI 诊断系统的分层架构。这个架构的设计理念是:将计算密集型任务全部下沉到 NPU,最大化减少 CPU-NPU 数据传输,实现端到端的硬件加速。
系统分层架构图:
数据流转示意图:
硬件配置详情:
- 2 台华为 Atlas 300I 推理卡(每台 4 张昇腾 310P,单卡 22 TOPS INT8 算力)
- 总算力:176 TOPS(实际利用率 89%,有效算力 156 TOPS)
- CPU:Intel Xeon Silver 4214R(12 核 24 线程)
- 内存:128GB DDR4
- 存储:2TB NVMe SSD(用于缓存 DICOM 数据)
- 网络:万兆以太网(与 PACS 系统对接)
- 总成本:约12万元(相比 GPU 方案节省 18 万元,降低 60%)
为什么选择 Atlas 300I 而不是 Atlas 300V?
在硬件选型时,我对比了 Atlas 300I(推理卡)和 Atlas 300V(训练卡):
- 300V 算力更高(64 TOPS FP16),但功耗达到 300W,医院机房散热压力大
- 300I 功耗只有 70W,且 INT8 算力(22 TOPS)已经满足推理需求
- 300I 单价比 300V 便宜 40%,性价比更高
最终选择 300I,事实证明这个决策是正确的,NPU 利用率达到 89%,算力完全够用。
2.2、CANN 关键技术应用
2.2.1、DVPP 硬件加速医学影像预处理
医学 CT 影像采用 DICOM 格式存储,包含大量元数据和像素数据。传统方案使用 CPU 进行 DICOM 解析、窗宽窗位调整、图像归一化等预处理,单例 CT 耗时约 8 秒,成为性能瓶颈。
CANN 的 DVPP(Digital Vision Pre-Processing)硬件单元提供了专用的图像处理加速能力,我们将预处理流程全部下沉到 DVPP 执行:
// DVPP医学影像预处理实现
class MedicalImagePreprocessor {
private:
acldvppChannelDesc* dvpp_channel_;
aclrtStream stream_;
public:
// 初始化DVPP通道
aclError Init() {
dvpp_channel_ = acldvppCreateChannelDesc();
aclError ret = acldvppCreateChannel(dvpp_channel_);
if (ret != ACL_SUCCESS) {
LOG_ERROR("Create DVPP channel failed");
return ret;
}
ret = aclrtCreateStream(&stream_);
return ret;
}
// DICOM图像预处理(窗宽窗位调整 + 归一化)
aclError ProcessDICOMSlice(uint16_t* dicom_data,
int width, int height,
int window_center, int window_width,
float* output_data) {
// 1. 创建输入图片描述
acldvppPicDesc* input_desc = acldvppCreatePicDesc();
acldvppSetPicDescData(input_desc, dicom_data);
acldvppSetPicDescFormat(input_desc, PIXEL_FORMAT_YUV_400); // 灰度图
acldvppSetPicDescWidth(input_desc, width);
acldvppSetPicDescHeight(input_desc, height);
// 2. 窗宽窗位调整(利用DVPP的LUT查找表加速)
uint8_t lut_table[65536];
BuildWindowLevelLUT(lut_table, window_center, window_width);
void* lut_buffer = nullptr;
aclrtMalloc(&lut_buffer, 65536, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMemcpy(lut_buffer, 65536, lut_table, 65536, ACL_MEMCPY_HOST_TO_DEVICE);
// 3. 应用LUT变换
acldvppPicDesc* output_desc = acldvppCreatePicDesc();
void* output_buffer = nullptr;
aclrtMalloc(&output_buffer, width * height, ACL_MEM_MALLOC_HUGE_FIRST);
acldvppSetPicDescData(output_desc, output_buffer);
aclError ret = acldvppLutMap(dvpp_channel_, input_desc, output_desc,
lut_buffer, 65536, stream_);
// 4. 归一化到[0,1]
aclrtSynchronizeStream(stream_);
NormalizeOnDevice(output_buffer, output_data, width * height);
// 清理资源
acldvppDestroyPicDesc(input_desc);
acldvppDestroyPicDesc(output_desc);
aclrtFree(lut_buffer);
aclrtFree(output_buffer);
return ret;
}
private:
// 构建窗宽窗位LUT表
void BuildWindowLevelLUT(uint8_t* lut, int center, int width) {
int lower = center - width / 2;
int upper = center + width / 2;
for (int i = 0; i < 65536; i++) {
if (i <= lower) {
lut[i] = 0;
} else if (i >= upper) {
lut[i] = 255;
} else {
lut[i] = (uint8_t)(255.0 * (i - lower) / width);
}
}
}
};
优化效果实测数据:
我使用 CANN 提供的 Profiling 工具(msprof)进行了详细的性能分析:
# 性能分析命令
msprof --application="./medical_inference" \
--output=./profiling_result \
--ai-core=on --aicpu=on --dvpp=on
分析结果显示:
| 预处理环节 | CPU 方案耗时 | DVPP 方案耗时 | 提升倍数 | CPU 占用率 |
|---|---|---|---|---|
| DICOM 解析 | 15ms | 1.5ms | 10x | 0% |
| 窗宽窗位调整 | 8ms | 0.8ms | 10x | 0% |
| 归一化 | 2ms | 0.6ms | 3.3x | 0% |
| 单张切片总耗时 | 25ms | 2.9ms | 8.6x | - |
| 单例 CT(300张) | 7.5 秒 | 0.87 秒 | 8.6x | - |
CPU 占用率对比:
- CPU 方案:78%(12 核心中有 9 核心满载)
- DVPP 方案:12%(仅用于任务调度和结果解析)
关键发现:Profiling 数据显示,DVPP 的 LUT 查找表操作完全由硬件完成,延迟只有 0.8ms,而 CPU 实现需要 8ms。这是因为 DVPP 内置了专用的查找表单元,支持 65536 个条目的并行查找,而 CPU 需要串行遍历。
2.2.2、ACL 多模型级联推理优化
医疗影像诊断需要两个模型协同工作:
- 3D UNet 分割模型:从 CT 切片中分割出疑似病灶区域
- ResNet 分类模型:对分割出的病灶进行良恶性分类
传统方案是串行执行两个模型,中间需要 CPU 进行数据处理,导致大量的设备间数据传输。我们利用 CANN 的 ACL 接口实现了端到端的流水线推理:
// 多模型级联推理管道
class CascadedInferencePipeline {
private:
uint32_t segmentation_model_id_; // 分割模型
uint32_t classification_model_id_; // 分类模型
aclrtStream stream_;
// 中间结果缓冲区(全程在Device内存,避免回传CPU)
void* segmentation_output_;
void* roi_features_;
public:
// 端到端推理流程
aclError InferCTVolume(void* ct_volume_data,
int depth, int height, int width,
std::vector<LesionResult>& results) {
// 1. 3D UNet分割推理
aclmdlDataset* seg_input = CreateSegmentationInput(ct_volume_data,
depth, height, width);
aclmdlDataset* seg_output = CreateSegmentationOutput();
aclError ret = aclmdlExecuteAsync(segmentation_model_id_,
seg_input, seg_output, stream_);
if (ret != ACL_SUCCESS) {
LOG_ERROR("Segmentation inference failed");
return ret;
}
// 2. 在Device上提取ROI(自定义算子,无需回传CPU)
std::vector<BoundingBox> rois;
ret = ExtractROIsOnDevice(seg_output, rois);
// 3. 批量分类推理(动态batch)
int batch_size = rois.size();
aclmdlDataset* cls_input = CreateClassificationInput(rois, batch_size);
aclmdlDataset* cls_output = CreateClassificationOutput(batch_size);
// 设置动态batch
aclmdlIODims dynamic_dims;
dynamic_dims.dimCount = 4;
dynamic_dims.dims[0] = batch_size;
dynamic_dims.dims[1] = 3;
dynamic_dims.dims[2] = 64;
dynamic_dims.dims[3] = 64;
aclmdlSetInputDynamicDims(classification_model_id_, 0, &dynamic_dims);
ret = aclmdlExecuteAsync(classification_model_id_,
cls_input, cls_output, stream_);
// 4. 同步等待并解析结果
aclrtSynchronizeStream(stream_);
ParseClassificationResults(cls_output, rois, results);
// 清理资源
aclmdlDestroyDataset(seg_input);
aclmdlDestroyDataset(seg_output);
aclmdlDestroyDataset(cls_input);
aclmdlDestroyDataset(cls_output);
return ACL_SUCCESS;
}
private:
// 在Device上提取ROI(自定义TBE算子)
aclError ExtractROIsOnDevice(aclmdlDataset* segmentation_mask,
std::vector<BoundingBox>& rois) {
// 调用自定义的3D连通域分析算子
// 该算子在NPU上执行,避免数据回传CPU
void* mask_data = aclmdlGetDatasetBuffer(segmentation_mask, 0);
// 执行连通域分析
aclopAttr* op_attr = aclopCreateAttr();
aclopSetAttrInt(op_attr, "min_volume", 100); // 最小病灶体积
aclError ret = aclopExecuteV2("ConnectedComponent3D",
1, &segmentation_mask,
1, &roi_output_,
op_attr, stream_);
// 将ROI信息拷贝回Host(数据量很小,仅坐标信息)
aclrtSynchronizeStream(stream_);
// ... 解析ROI坐标 ...
aclopDestroyAttr(op_attr);
return ret;
}
};
关键优化点:
- 零拷贝流水线:分割模型输出直接作为 ROI 提取算子输入,全程在 Device 内存
- 动态 Batch 推理:根据检测到的病灶数量动态调整分类模型的 batch size
- 异步执行:利用 Stream 机制实现计算与数据传输的 overlap
多模型级联优化前后对比:
性能提升数据对比:
| 优化维度 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 单例 CT 推理时间 | 45 秒 | 18 秒 | ↓60% (2.5x) |
| Device-Host 传输量 | 1.2GB | 8MB | ↓99.3% |
| NPU 利用率 | 52% | 89% | ↑71% |
| CPU 占用率 | 85% | 23% | ↓73% |
| 内存峰值 | 8.5GB | 4.2GB | ↓51% |
NPU 利用率提升可视化:
2.2.3、自定义算子解决医疗场景特殊需求
医疗影像分析有一个特殊需求:3D 连通域分析。这个算法用于将分割出的像素点聚类成独立的病灶区域,是标准深度学习框架不提供的功能。
传统方案是将分割结果回传 CPU,使用 OpenCV 或 scikit-image 进行连通域分析,但这会带来巨大的数据传输开销(单例 CT 约 600MB)。我们使用 CANN 的 AscendC 开发了高性能的 3D 连通域分析算子,直接在 NPU 上执行:
// AscendC实现3D连通域分析算子
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2;
class ConnectedComponent3DKernel {
public:
__aicore__ inline ConnectedComponent3DKernel() {}
__aicore__ inline void Init(GM_ADDR mask, GM_ADDR labels,
uint32_t depth, uint32_t height, uint32_t width) {
maskGm.SetGlobalBuffer((__gm__ uint8_t*)mask, depth * height * width);
labelsGm.SetGlobalBuffer((__gm__ int32_t*)labels, depth * height * width);
this->depth = depth;
this->height = height;
this->width = width;
this->currentLabel = 1;
// 初始化缓冲区
pipe.InitBuffer(maskQueue, BUFFER_NUM, height * width * sizeof(uint8_t));
pipe.InitBuffer(labelQueue, BUFFER_NUM, height * width * sizeof(int32_t));
}
__aicore__ inline void Process() {
// 逐层处理CT切片
for (uint32_t z = 0; z < depth; z++) {
ProcessSlice(z);
}
// 合并跨层连通域
MergeInterSliceComponents();
}
private:
__aicore__ inline void ProcessSlice(uint32_t sliceIdx) {
// 加载当前切片到Local Buffer
LocalTensor<uint8_t> maskLocal = maskQueue.AllocTensor<uint8_t>();
LocalTensor<int32_t> labelLocal = labelQueue.AllocTensor<int32_t>();
DataCopy(maskLocal, maskGm[sliceIdx * height * width], height * width);
// 2D连通域分析(使用Union-Find算法)
UnionFind2D(maskLocal, labelLocal, height, width);
// 写回Global Memory
DataCopy(labelsGm[sliceIdx * height * width], labelLocal, height * width);
maskQueue.FreeTensor(maskLocal);
labelQueue.FreeTensor(labelLocal);
}
__aicore__ inline void UnionFind2D(LocalTensor<uint8_t>& mask,
LocalTensor<int32_t>& labels,
uint32_t h, uint32_t w) {
// 初始化标签
for (uint32_t i = 0; i < h * w; i++) {
labels.SetValue(i, mask.GetValue(i) > 0 ? i : -1);
}
// 第一遍扫描:建立等价关系
for (uint32_t y = 0; y < h; y++) {
for (uint32_t x = 0; x < w; x++) {
uint32_t idx = y * w + x;
if (mask.GetValue(idx) == 0) continue;
// 检查左邻居
if (x > 0 && mask.GetValue(idx - 1) > 0) {
Union(labels, idx, idx - 1);
}
// 检查上邻居
if (y > 0 && mask.GetValue(idx - w) > 0) {
Union(labels, idx, idx - w);
}
}
}
// 第二遍扫描:标签压缩
for (uint32_t i = 0; i < h * w; i++) {
if (labels.GetValue(i) >= 0) {
labels.SetValue(i, Find(labels, i));
}
}
}
__aicore__ inline int32_t Find(LocalTensor<int32_t>& labels, int32_t x) {
if (labels.GetValue(x) != x) {
labels.SetValue(x, Find(labels, labels.GetValue(x)));
}
return labels.GetValue(x);
}
__aicore__ inline void Union(LocalTensor<int32_t>& labels,
int32_t x, int32_t y) {
int32_t rootX = Find(labels, x);
int32_t rootY = Find(labels, y);
if (rootX != rootY) {
labels.SetValue(rootX, rootY);
}
}
__aicore__ inline void MergeInterSliceComponents() {
// 合并相邻切片间的连通域
// ... 实现细节省略 ...
}
private:
TPipe pipe;
GlobalTensor<uint8_t> maskGm;
GlobalTensor<int32_t> labelsGm;
TQue<QuePosition::VECIN, BUFFER_NUM> maskQueue;
TQue<QuePosition::VECOUT, BUFFER_NUM> labelQueue;
uint32_t depth, height, width;
int32_t currentLabel;
};
// 算子入口
extern "C" __global__ __aicore__ void connected_component_3d(
GM_ADDR mask, GM_ADDR labels,
uint32_t depth, uint32_t height, uint32_t width) {
ConnectedComponent3DKernel op;
op.Init(mask, labels, depth, height, width);
op.Process();
}
自定义算子开发的完整过程
开发这个算子花了我 3 天时间,这里记录完整的开发流程:
Day 1:算法设计与原型验证
- 上午:研究 3D 连通域分析的经典算法(Union-Find),查阅了大量论文和开源实现
- 下午:用 Python 实现 CPU 版本,在测试数据上验证正确性。这个过程中,我在华为开发者社区记录了算法原理和实现细节,收到了几位算法工程师的反馈建议
- 晚上:学习 AscendC 编程模型,阅读官方文档和样例代码。作为华为云文档深度体验官,我对 CANN 的文档质量有深刻认识,这次学习过程比预期顺利
Day 2:AscendC 算子实现
- 上午:编写算子 kernel 代码,实现 2D 连通域分析
- 下午:扩展到 3D,处理跨层连通域合并
- 晚上:编译调试,解决了 3 个编译错误和 2 个运行时错误
Day 3:性能优化与测试
- 上午:使用双缓冲机制优化数据搬运,性能提升 30%
- 下午:编写单元测试,验证 100 例 CT 数据的正确性
- 晚上:集成到推理流程,端到端测试通过
性能对比实测:
| 方案 | 耗时 | 数据传输量 | 内存占用 |
|---|---|---|---|
| CPU(OpenCV) | 2.8 秒 | 600MB(D2H) + 8MB(H2D) | 1.2GB |
| NPU(AscendC) | 0.3 秒 | 8MB(仅坐标信息) | 150MB |
| 性能提升 | 9.3x | 降低 98.7% | 降低 87.5% |
开发效率对比:
- 代码量:约 500 行 C++ 代码(vs CPU 版本 300 行 Python)
- 开发周期:3 天(包括学习、编码、调试、优化)
- 性能:9.3 倍提升
踩坑记录:
- 内存对齐问题:初版代码在处理非 128 字节对齐的数据时会 crash,后来发现 AscendC 要求数据必须 128 字节对齐
- 跨层合并 bug:第一版实现忘记处理跨层连通域,导致同一个病灶被分成多个区域,后来增加了 MergeInterSliceComponents 函数解决
自定义算子带来的价值:
- 3D 连通域分析时间:从 2.8 秒(CPU)降至 0.3 秒(NPU),提升 9.3 倍
- 消除了 600MB 的 Device-Host 数据传输,降低 98.7%
- 端到端推理时间再降低 15%(从 21 秒降至 18秒)
- 内存占用降低 87.5%,从 1.2GB 降至 150MB
三、部署实施:从实验室到临床的跨越
3.1、第一阶段:离线验证(2024 年 2 月)
在正式部署前,我们在医院提供的 1000 例标注数据上进行了离线验证:
模型精度验证:
| 指标 | 目标值 | 实际值 | 结论 | 说明 |
|---|---|---|---|---|
| 敏感性(Sensitivity) | ≥95% | 96.8% | ✓ 达标 | 真阳性率,漏诊率低 |
| 特异性(Specificity) | ≥90% | 93.2% | ✓ 达标 | 真阴性率,误诊率低 |
| 假阳性率(FPR) | ≤10% | 6.8% | ✓ 优于预期 | 减少过度检查 |
| 假阴性率(FNR) | ≤5% | 3.2% | ✓ 优于预期 | 降低漏诊风险 |
| 准确率(Accuracy) | ≥92% | 95.3% | ✓ 优于预期 | 整体诊断准确性 |
| F1 分数 | ≥0.93 | 0.95 | ✓ 优于预期 | 综合评价指标 |
混淆矩阵可视化:
性能验证:
- 单例 CT 推理时间:18 秒(目标 30 秒内,超额完成 40%)
- 系统吞吐量:200 例/小时(单台服务器)
- NPU 利用率:89%(充分利用硬件资源)
- 内存占用:峰值 4.2GB(单卡 6GB 显存,留有 30% 余量)
- 系统稳定性:连续运行 72 小时无故障
性能指标雷达图:
3.2、第二阶段:灰度上线(2024 年 3 月)
选择放射科 3 位医生进行为期 2 周的灰度测试,每天处理约 50 例 CT。
第一周:医生的质疑与调整
灰度测试第一天,王主任就发现了问题:“这个系统把肋骨钙化也标成结节了,假阳性太多!”我立即调取日志,发现当天 50 例 CT 中,系统标注了 320 个疑似病灶,但医生确认的只有 180 个,假阳性率高达 43.8%。
当晚我紧急分析数据,发现问题出在 HU 值(CT 值)阈值设置上。肋骨钙化的 HU 值通常 >400,而肺结节一般在 -600 到 100 之间。我在后处理流程中增加了 HU 值过滤规则:
# 增加HU值过滤逻辑
def filter_false_positives(lesions, ct_volume):
filtered_lesions = []
for lesion in lesions:
# 提取病灶区域的HU值
roi = ct_volume[lesion.z_min:lesion.z_max,
lesion.y_min:lesion.y_max,
lesion.x_min:lesion.x_max]
mean_hu = np.mean(roi)
# 过滤高密度钙化(HU > 400)
if mean_hu < 400:
filtered_lesions.append(lesion)
return filtered_lesions
第二天重新测试,假阳性率降至 12.3%,王主任满意地点了点头。
第二周:医生的认可与建议
经过一周的磨合,医生们逐渐适应了 AI 系统的工作方式。我记录了几次典型的反馈:
- 王主任(主任医师,20 年经验):“昨天有个病例,5mm 的磨玻璃结节我差点漏了,AI 标出来了。这种早期病变确实容易忽略,AI 的辅助价值很大。”
- 李医生(副主任医师,10 年经验):“推理速度确实快,18 秒就出结果,不会打断我的阅片节奏。但有些边缘病灶还是会漏,能不能优化一下?”
- 张医生(主治医师,5 年经验):“我刚工作 3 年,经验不足,AI 的 3D 可视化功能帮我很大。特别是多角度重建,让我能更清楚地判断病灶性质。”
李医生提到的边缘病灶漏检问题,我通过调整分割模型的 padding 策略解决了。原来模型对边界区域的 padding 是 16 像素,我改成 32 像素后,边缘病灶的召回率从 78% 提升到 91%。
发现的问题与优化:
问题 1:假阳性问题
- 现象:部分血管钙化被误判为结节,假阳性率 43.8%
- 原因分析:肋骨钙化的 HU 值 >400,与肺结节的 HU 值范围(-600~100)重叠
- 解决方案:增加 HU 值过滤规则,排除高密度钙化
- 优化效果:假阳性率从 43.8% 降至 6.8%
问题 2:边界病灶漏检
- 现象:靠近肺边缘的病灶容易漏检,召回率 78%
- 原因分析:模型对边界区域的 padding 只有 16 像素,导致边缘信息丢失
- 解决方案:调整分割模型的边界 padding 从 16 像素增加到 32 像素
- 优化效果:边缘病灶召回率从 78% 提升到 91%
问题 3:报告生成慢
- 现象:可视化渲染耗时较长,单例需要 5 秒
- 原因分析:3D 渲染在 CPU 上执行,计算密集
- 解决方案:将 3D 渲染从 CPU 迁移到 DVPP 硬件加速
- 优化效果:渲染时间从 5 秒降至 0.8 秒
灰度测试优化时间线:
3.3、第三阶段:全面推广(2024 年 4 月至今)
经过优化后,系统在放射科全面上线,接入医院 PACS 系统:
网络拓扑与数据流:
运行数据统计(2024 年 4-10 月,7 个月):
- 累计处理 CT 病例:28600 例
- 系统可用率:99.7%(停机时间主要是计划内维护)
- 平均推理时间:17.2 秒/例(最快 14 秒,最慢 23 秒)
- 检出病灶总数:142000+ 个
- 医生采纳率:87.3%(AI 标注的病灶被医生确认的比例)
- 单日最高处理量:312 例(2024 年 8 月 15 日,体检高峰期)
系统可用性统计:
推理时间分布:
医生采纳率分析:
临床价值的真实案例
案例 1:发现早期肺癌,挽救患者生命
2024 年 6 月 18 日,一位 52 岁的男性患者来做常规体检 CT。王主任在阅片时,AI 系统标注出右肺上叶一个 6mm 的磨玻璃结节。王主任仔细观察后,建议患者 3 个月后复查。
9 月复查时,结节增大到 8mm,边缘出现毛刺征。王主任立即安排穿刺活检,病理结果显示为早期肺腺癌(IA 期)。患者及时进行了微创手术,术后恢复良好。
王主任后来告诉我:“这个结节位置比较隐蔽,在肺尖部,如果不是 AI 标出来,我可能会漏掉。早期肺癌的 5 年生存率超过 90%,晚期只有不到 20%,AI 真的救了这个患者。”
案例 2:减少假阳性,避免过度检查
2024 年 7 月,一位 65 岁的女性患者 CT 显示多发小结节。AI 系统标注了 8 个疑似病灶,但同时给出了 HU 值和形态学特征。王主任根据 AI 提供的定量数据,判断其中 6 个是良性钙化灶,只有 2 个需要随访。
患者家属原本非常焦虑,要求立即做 PET-CT(费用 8000 元)。王主任根据 AI 的辅助分析,耐心解释后,家属同意先随访观察。3 个月后复查,结节无变化,避免了不必要的检查和心理负担。
案例 3:辅助年轻医生成长
张医生是 2021 年入职的年轻医生,刚开始独立阅片时经常不自信。有了 AI 系统后,他会先自己阅片,然后对比 AI 的标注结果,发现自己遗漏的病灶。
半年后,张医生的阅片准确率从 82% 提升到 94%,王主任评价说:“AI 就像一个 24 小时在线的高年资医生,给年轻医生提供即时反馈,成长速度明显加快。”
数据统计的临床价值:
- 提升诊断效率:医生阅片时间从平均 8 分钟/例降至 5 分钟/例,效率提升 37.5%
- 降低漏诊率:7 个月内发现 12 例医生初诊漏检的早期肺癌(直径 <10mm),及时进行了治疗
- 减少假阳性:通过 HU 值过滤和形态学分析,假阳性率从初期的 43.8% 降至 6.8%
- 减轻医生负担:放射科加班时间从每周 15 小时减少到 9 小时,降低 40%
- 辅助年轻医生:3 位年轻医生的阅片准确率平均提升 12 个百分点
四、技术亮点:CANN 功能的深度发挥
回顾整个项目,CANN 在以下几个方面发挥了关键作用。
4.1、DVPP 硬件加速:解决预处理瓶颈
医学影像预处理是传统方案的性能瓶颈,CANN 的 DVPP 硬件单元提供了专用加速能力:
- LUT 查找表加速:窗宽窗位调整速度提升 10 倍
- 硬件解码:DICOM 图像解码完全由硬件完成,零 CPU 占用
- 格式转换:YUV/RGB 格式转换由硬件完成,延迟降低 90%
数据对比:
| 预处理环节 | CPU 方案 | DVPP 方案 | 提升 |
|---|---|---|---|
| DICOM 解码 | 15ms | 1.5ms | 10x |
| 窗宽窗位调整 | 8ms | 0.8ms | 10x |
| 归一化 | 2ms | 0.6ms | 3.3x |
| 总耗时 | 25ms | 2.9ms | 8.6x |
4.2、ACL 多模型级联:实现端到端优化
传统方案中,多个模型之间需要频繁的 CPU-GPU 数据传输。CANN 的 ACL 接口支持:
- 零拷贝流水线:模型间数据传递全程在 Device 内存
- 动态 Shape:根据实际病灶数量动态调整 batch size
- 异步执行:Stream 机制实现计算与传输 overlap
优化效果:
- Device-Host 数据传输量:降低 99.3%
- 端到端推理时间:降低 60%
- NPU 利用率:从 52% 提升至 89%
4.3、自定义算子:填补框架能力空白
医疗场景的特殊算法(如 3D 连通域分析)在标准框架中不存在,CANN 提供了灵活的算子开发能力:
- AscendC 编程:类 C++ 语法,学习成本低
- 硬件直接控制:可以精细控制 AI Core 的计算和存储
- 性能优异:自定义算子性能达到 CPU 方案的 9.3 倍
开发效率:
- 算子开发周期:3 天(包括编码、调试、优化)
- 代码量:约 500 行 C++ 代码
- 性能:0.3 秒(vs CPU 2.8 秒)
4.4、成本优势:高性价比的解决方案
在医疗行业,成本控制是重要考量因素。昇腾方案相比 GPU 方案:
- 硬件成本:节省 60%(12 万 vs 30 万)
- 功耗:降低 40%(单卡 70W vs 250W)
- 运维成本:本地化支持,供应链稳定可靠
TCO(总拥有成本)对比(3 年):
| 成本项 | GPU 方案 | 昇腾方案 | 节省 | 说明 |
|---|---|---|---|---|
| 硬件采购 | 30 万 | 12 万 | 18 万 | 2 台服务器 |
| 电费(3 年) | 4.5 万 | 2.7 万 | 1.8 万 | 按 0.8 元/度计算 |
| 维护费用 | 6 万 | 3.6 万 | 2.4 万 | 年度维保 |
| 软件授权 | 0 | 0 | 0 | 开源方案 |
| 人力成本 | 0 | 0 | 0 | 现有团队 |
| 总计 | 40.5 万 | 18.3 万 | 22.2 万(55%) | 3年 TCO |
成本结构对比可视化:
投资回报分析:
五、经验总结与展望
5.1、关键成功因素
- 充分利用 CANN 硬件加速能力:DVPP、自定义算子等特性显著提升性能
- 端到端优化思维:不局限于模型本身,从数据流全链路进行优化
- 与临床深度结合:充分理解医生工作流程,设计符合实际需求的系统
- 迭代优化:通过灰度测试收集反馈,持续改进系统
5.2、遇到的挑战与解决(真实踩坑记录)
挑战 1:DICOM 格式多样性导致的解析失败
问题描述:系统上线第一周,遇到了 3 例 CT 无法解析的情况。错误日志显示“DICOM tag 读取失败”。我排查后发现,医院有 3 台不同厂商的 CT 设备(GE、西门子、飞利浦),DICOM 标签的编码方式存在差异。
解决过程:
- 我向医院申请了 3 台设备各 10 例样本数据,建立 DICOM 兼容性测试集
- 使用 pydicom 库逐个解析,发现 GE 设备的 PixelSpacing 标签存储格式与标准不同
- 在预处理代码中增加厂商适配逻辑:
def parse_dicom_with_vendor_adaptation(dicom_file):
ds = pydicom.dcmread(dicom_file)
# 厂商适配
manufacturer = ds.get('Manufacturer', '').upper()
if 'GE' in manufacturer:
# GE设备的PixelSpacing可能存储在(0018,1164)
if hasattr(ds, 'ImagerPixelSpacing'):
pixel_spacing = ds.ImagerPixelSpacing
else:
pixel_spacing = ds.PixelSpacing
else:
pixel_spacing = ds.PixelSpacing
return pixel_spacing
- 重新测试,兼容性问题解决,成功率从 97% 提升到 100%
挑战 2:模型精度与性能的艰难平衡
问题描述:初期使用的 3D UNet 模型参数量达到 45M,推理时间 28 秒,虽然满足 30 秒要求,但医生反馈“还是有点慢”。我尝试将模型裁剪到 20M,推理时间降至 15 秒,但敏感性从 96.8% 下降到 89.2%,无法接受。
解决过程:
- 我分析了 1000 例标注数据,发现 80% 的病灶直径 >8mm,只有 20% 是小结节(<8mm)
- 设计了粗筛 + 精筛的级联策略:
- 第一阶段:轻量级模型(15M 参数)快速筛查,召回率要求 >98%
- 第二阶段:对筛出的 ROI 区域,用精细模型(45M 参数)进行分类
- 实测效果:
- 总推理时间:12 秒(粗筛 8 秒 + 精筛 4 秒)
- 敏感性:96.5%(几乎无损失)
- 特异性:93.8%(提升 0.6 个百分点)
挑战 3:医生信任度建立的漫长过程
问题描述:灰度测试初期,医生对 AI 系统持怀疑态度。李医生直言:“我从医 10 年,凭什么相信一个机器?”
解决过程:
-
可解释性可视化:我开发了病灶特征展示功能,显示 AI 的判断依据:
- 病灶的 HU 值分布直方图
- 3D 形态学特征(球形度、毛刺征、分叶征)
- 与良性病灶的对比案例
-
双盲对照实验:我提议做一个月的双盲测试,让医生先独立阅片,然后查看 AI 结果。结果显示:
- AI 发现了医生漏检的 18 个病灶(其中 3 个是早期肺癌)
- 医生发现了 AI 漏检的 5 个病灶(都是 <3mm 的微小结节)
- 医生 +AI 的联合诊断准确率达到 98.2%
-
持续反馈机制:建立了医生反馈通道,每周统计 AI 的准确率,并根据反馈优化模型。3 个月后,医生采纳率从初期的 62% 提升到 87.3%。
李医生后来说:“AI 不是要取代我们,而是帮我们减少漏诊。现在我已经习惯了先看 AI 的标注,再结合自己的经验做判断,效率确实提高了。”
5.3、未来规划
- 扩展病种覆盖:从肺部 CT 扩展到肝脏、脑部等其他部位
- 多模态融合:结合 CT、MRI、病理切片等多种数据源
- 边缘部署:将系统部署到基层医院,实现分级诊疗
- 联邦学习:在保护隐私前提下,利用多家医院数据持续优化模型
六、结语:技术的价值在于解决真实问题
6.1、项目复盘:从 0 到 1 的 8 个月
回顾这个项目,从 2024 年 1 月接到需求,到 10 月系统稳定运行,整整 8 个月。这期间经历了技术选型的纠结、开发过程的挑战、部署上线的紧张,以及看到系统真正帮助医生和患者时的欣慰。
最难忘的三个时刻:
- 2 月 15 日凌晨 2 点:我在成都的办公室调试 DVPP 预处理代码,连续失败了 20 次。当第 21 次终于看到正确的输出时,我激动得大喊了一声。那一刻我意识到,CANN 的 DVPP 硬件加速不是纸上谈兵,而是真正能解决问题的技术。我立即在华为开发者社区记录了这次调试过程,这篇文章后来获得了很多开发者的关注,不少人留言说遇到了类似问题。
- 3 月 8 日下午:灰度测试第一周,王主任告诉我,AI 系统发现了一个他差点漏掉的 6mm 磨玻璃结节。那位患者后来确诊为早期肺癌,及时手术治愈。那一刻我深刻体会到,技术的价值不在于算法有多先进,而在于能否真正帮助到人。这个案例后来成为我在华为开发者社区分享的经典案例,得到了很多开发者的共鸣。
- 10 月 20 日:系统运行满 7 个月,累计处理 28600 例 CT,发现 12 例早期肺癌。医院为我们团队颁发了“优秀合作伙伴”奖牌。王主任说:“你们的系统已经成为我们科室不可或缺的一部分。”这个项目的成功经验,我也整理成系列文章发布在华为开发者社区,帮助了很多医疗 AI 领域的开发者。
6.2、CANN 的技术价值总结
华为 CANN 作为 AI 异构计算架构,在这个项目中展现出了强大的技术实力:
- DVPP 硬件加速:将医学影像预处理时间从 8 秒降至 0.9 秒,解决了传统方案的性能瓶颈
- ACL 多模型级联:实现端到端的零拷贝流水线,数据传输量降低 99.3%,推理时间降低 60%
- 自定义算子开发:3 天开发出高性能 3D 连通域分析算子,性能提升 9.3 倍,填补了标准框架的能力空白
- 成本优势:相比 GPU 方案节省 55% 的 TCO,为医疗行业的 AI 普及提供了可能
- 本地化支持:完善的中文文档和本地技术团队,为医疗等关键行业提供了可靠的技术保障
6.3、给开发者的建议
作为一名拥有 11 年技术写作经历的开发者,我在多个技术平台累计发布了 300 余篇技术文章。这个项目的经验,我也在华为开发者社区进行了详细分享。如果你也在考虑使用 CANN 进行 AI 应用开发,我有几点建议:
- 充分利用硬件加速能力:DVPP、自定义算子等特性能带来数倍甚至数十倍的性能提升,不要只停留在模型推理层面。我在华为开发者社区详细记录了 DVPP 的使用技巧,欢迎参考。
- 端到端优化思维:从数据流全链路进行优化,减少 CPU-NPU 数据传输,这往往是性能瓶颈所在。这是我在互联网大厂和云服务厂商工作期间积累的宝贵经验。
- 深入理解业务场景:技术方案必须贴合实际需求,医疗场景的 30 秒实时性要求、95% 敏感性要求,都是硬约束。
- 重视工程化细节:DICOM 格式兼容性、内存对齐、错误处理等细节,决定了系统能否稳定运行。这些踩坑经验我都记录在华为开发者社区中。
- 持续迭代优化:系统上线不是终点,而是起点。根据用户反馈持续优化,才能真正发挥价值。
- 积极参与社区:加入华为开发者社区,与其他开发者交流经验。社区提供了丰富的技术文档、案例分享和在线答疑,是学习 CANN 的最佳平台。
6.4、未来展望
这个项目只是一个开始,基于在互联网大厂积累的大数据与大模型经验,我们计划在未来 6 个月内:
- 扩展病种覆盖:从肺部 CT 扩展到肝脏、脑部、骨骼等其他部位,覆盖更多临床场景。我们正在与多家医院的专家共同探讨需求,推动 CANN 在更多医疗场景的应用。
- 多模态融合:结合 CT、MRI、病理切片等多种数据源,提供更全面的诊断支持。这将是我在大模型应用方向的重点研究课题。
- 边缘部署:将系统部署到基层医院,实现分级诊疗,让更多患者受益。我们计划通过华为开发者社区,推广这个方案到更多地区的医院。
- 联邦学习:在保护隐私前提下,利用多家医院数据持续优化模型,提升泛化能力。这个方向将在华为开发者社区进行技术探讨。
- 技术分享:我会持续在华为开发者社区发布系列技术文章,分享 CANN 开发经验,帮助更多开发者。同时也会积极参与社区的技术交流活动,促进开发者之间的经验分享。
关键成果指标雷达图:
希望这个案例能为更多开发者探索 CANN 在垂直行业的应用提供参考。AI 的未来,不在云端,而在千行百业的真实场景中。当技术真正解决了实际问题,创造了社会价值,那才是技术人最大的成就感。
附录
作者信息
作者简介:郭靖(笔名“白鹿第一帅”),互联网大厂大数据与大模型开发工程师,base 成都。曾任职于多家知名互联网公司和云服务厂商,拥有 11 年技术博客写作经历,多家技术社区认证专家,个人博客累计发布 300 余篇技术文章,全网粉丝 60000+,总浏览量超 150 万。长期关注 AI 基础设施发展,致力于昇腾生态的技术推广和应用实践。
项目信息:
- 实践平台:Atlas 300I 推理卡 + CANN 7.0 + MindX SDK 3.0
- 开发周期:8 个月(2024 年 1 月-10 月)
- 部署地点:成都某三甲医院放射科
- 技术栈:PyTorch 1.13、ONNX、3D UNet、ResNet50、pydicom、FastAPI
- 技术交流:欢迎在昇腾社区论坛(https://www.hiascend.com/forum)交流讨论
- 昇腾官网:https://www.hiascend.com
参考资料
官方文档
[1] 华为昇腾社区. CANN 官方文档中心[EB/OL]. https://www.hiascend.com/document
[2] 华为昇腾社区. 昇腾开发者社区[EB/OL]. https://www.hiascend.com/developer
[3] 华为昇腾社区. Atlas 产品文档[EB/OL]. https://www.hiascend.com/hardware/atlas
[4] 华为昇腾社区. 医疗影像 AI 解决方案[EB/OL]. https://www.hiascend.com/zh/ecosystem/industry
技术论文
[5] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2015: 234-241.
[6] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
[7] Setio A A A, Traverso A, De Bel T, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the LUNA16 challenge[J]. Medical Image Analysis, 2017, 42: 1-13.
[8] Ardila D, Kiraly A P, Bharadwaj S, et al. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography[J]. Nature Medicine, 2019, 25(6): 954-961.
医疗 AI 标准
[9] 国家卫生健康委员会. 人工智能辅助诊断技术管理规范(试行)[S]. 2021.
[10] 中华医学会放射学分会. 肺结节诊治中国专家共识[J]. 中华结核和呼吸杂志, 2018, 41(10): 763-771.
[11] 国家药品监督管理局. 人工智能医疗器械注册审查指导原则[S]. 2019.
开源项目
[12] PyTorch. PyTorch深度学习框架[EB/OL]. https://pytorch.org
[13] ONNX. 开放神经网络交换格式[EB/OL]. https://onnx.ai
[14] pydicom. Python DICOM医学影像处理库[EB/OL]. https://pydicom.github.io
[15] SimpleITK. 医学影像处理工具包[EB/OL]. https://simpleitk.org
技术书籍
[16] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.
[17] Ian Goodfellow, Yoshua Bengio, Aaron Courville. 深度学习[M]. 北京: 人民邮电出版社, 2017.
[18] 李航. 统计学习方法(第2版)[M]. 北京: 清华大学出版社, 2019.
致谢:感谢成都某三甲医院放射科王主任及团队在项目中的大力支持和宝贵建议,感谢华为昇腾技术支持团队提供的专业指导和及时响应,感谢华为昇腾开发者社区的开发者们提供的反馈和建议,感谢我的团队成员在项目中的辛勤付出和专业精神。
文章作者:白鹿第一帅,作者主页:https://blog.csdn.net/qq_22695001,未经授权,严禁转载,侵权必究!
总结
这个医疗影像 AI 项目的成功落地,让我深刻认识到:技术的价值不在于算法有多先进,而在于能否真正解决实际问题。华为 CANN 作为 AI 异构计算架构,在医疗这个对性能、精度、成本都有严苛要求的场景中,展现出了强大的技术实力。从 DVPP 硬件加速将预处理时间降低 8.6 倍,到 ACL 多模型级联实现 99.3% 的数据传输量削减,再到 AscendC 自定义算子带来 9.3 倍的性能提升,CANN 的每一项核心能力都在项目中发挥了关键作用。更重要的是,这个项目实现了技术价值向社会价值的转化:7 个月累计处理 28600 例 CT,发现 12 例早期肺癌,医生阅片效率提升 37.5%,加班时间减少 40%,这些数字背后是一个个鲜活的生命和家庭。相比 GPU 方案节省 55% 的 TCO,也为医疗 AI 的普及提供了可能。昇腾 +CANN 在供应链稳定、技术支持、生态建设等方面的优势,为医疗、工业、金融等关键行业提供了可靠的选择。希望这个案例能为更多开发者探索 CANN 在垂直行业的应用提供参考,让 AI 技术真正服务于千行百业,创造更大的社会价值。
我是白鹿,一个不懈奋斗的程序猿。望本文能对你有所裨益,欢迎大家的一键三连!若有其他问题、建议或者补充可以留言在文章下方,感谢大家的支持!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)