学习:SimGNN:基于神经网络的快速图相似度计算方法
SimGNN提出了一种基于神经网络的图相似度计算方法,通过将传统组合优化问题转化为端到端学习任务。该方法采用双策略设计:(1)图级嵌入交互策略,利用GCN生成节点嵌入后通过注意力机制聚合为图嵌入,再使用神经张量网络计算全局相似度;(2)节点级成对比较策略,生成节点相似度矩阵并提取直方图特征补充局部信息。相比传统GED算法,SimGNN在AIDS等数据集上实现了数百倍的速度提升,同时保持较高精度,支
SimGNN:基于神经网络的快速图相似度计算方法
在图数据广泛应用的今天,图相似度计算是诸多领域的核心问题——从化学分子结构匹配到社交网络社区检索,都需要高效衡量两个图的相似程度。传统方法如Graph Edit Distance(GED)或Maximum Common Subgraph(MCS)虽精度可靠,但计算复杂度极高,难以应对大规模图数据。而SimGNN的出现,通过神经网络将图相似度计算转化为学习问题,在保证精度的同时实现了效率的质的飞跃。本文将重点拆解SimGNN的核心设计,即论文第三章提出的两大核心策略与完整模型架构。
一、SimGNN的核心目标
SimGNN的核心目标是学习一个"图相似度映射函数",输入任意两个图,输出0-1之间的相似度分数。这个函数需要满足三个关键特性:
- 表示不变性:同一个图可以用不同的邻接矩阵表示。计算出的相似度分数应对此类变化保持不变。
- 归纳性:相似度计算应能泛化到未见过的图,即计算训练图对之外的图的相似度分数。
- 可学习性:通过训练适配不同的相似度度量标准(如GED)。
为实现这些目标,SimGNN设计了"图级嵌入交互"与"节点级成对比较"两大策略,结合粗粒度全局信息与细粒度局部信息,实现精准且高效的相似度计算。
二、核心策略一:图级嵌入交互(Graph-Level Embedding Interaction)
该策略通过将每个图映射为一个固定维度的嵌入向量,再通过向量交互捕捉全局相似度,是SimGNN的基础核心。整个流程分为四个阶段: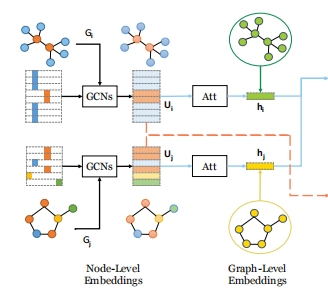
1. 节点级嵌入生成(Node Embedding)
使用 图卷积神经网络(GCN)对每个节点进行嵌入,捕捉节点自身特征与局部邻居结构。
(先了解图卷积神经网络(GCN)核心思想是:每个节点的特征更新,依赖于自身特征与邻居节点特征的加权聚合,通过逐层传递实现 “局部 - 全局” 特征融合。)
GCN的核心操作如下:
conv(un)=f1(∑m∈N(n)1dndmumW1(l)+b1(l))conv(u_n) = f_1\left(\sum_{m \in \mathcal{N}(n)} \frac{1}{\sqrt{d_n d_m}} u_m W_1^{(l)} + b_1^{(l)}\right)conv(un)=f1 m∈N(n)∑dndm1umW1(l)+b1(l)
其中:
- N(n)\mathcal{N}(n)N(n) 表示节点 nnn 的一阶邻居(含自身)
- dnd_ndn 是节点 nnn 的度数(含自环)
- W1(l)W_1^{(l)}W1(l) 和 b1(l)b_1^{(l)}b1(l) 分别为第 lll 层GCN的权重矩阵和偏置
- f1f_1f1 采用ReLU激活函数
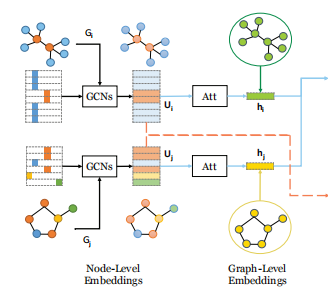
2. 图嵌入生成:全局上下文注意力(Global Context-Aware Attention)
为了从节点嵌入聚合出图的全局特征,SimGNN提出了一种自适应相似度度量的注意力机制,而非简单的平均池化。具体步骤如下:
-
计算全局图上下文 ccc:对所有节点嵌入取平均后进行非线性变换
c=tanh((1N∑n=1Nun)W2)c = tanh\left(\left(\frac{1}{N} \sum_{n=1}^N u_n\right) W_2\right)c=tanh((N1n=1∑Nun)W2)
其中,NNN 是图的节点数,W2W_2W2 是可学习的权重矩阵。
-
计算节点注意力权重:通过节点嵌入与全局上下文的内积,再经sigmoid函数归一化到(0,1)区间,为每个节点计算一个注意力权重,与全局上下文相似的节点应获得更高的注意力权重。
-
生成图嵌入 hhh:节点嵌入的加权和,权重为注意力分数
h=∑n=1Nσ(unTc)unh = \sum_{n=1}^N \sigma(u_n^T c) u_nh=n=1∑Nσ(unTc)un
这种设计让模型自动关注对当前相似度度量更重要的节点(如高degree节点、稀有标签节点),提升全局嵌入的代表性。
整体模型图: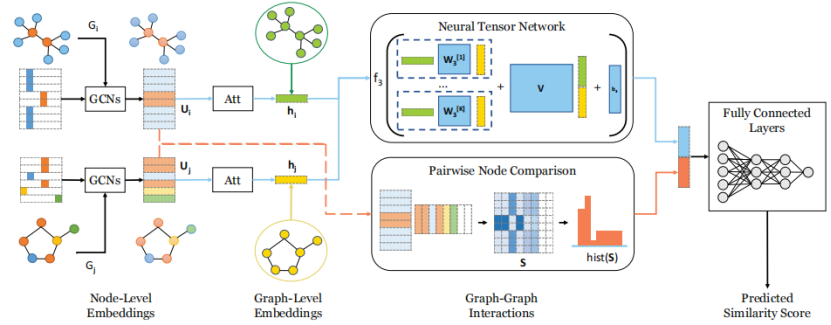
NTN部分: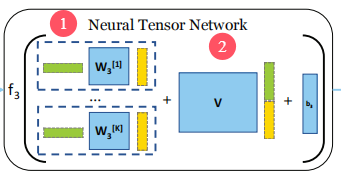
3. 图-图交互:神经张量网络(Neural Tensor Network, NTN)
为了捕捉两个图级嵌入之间的复杂关系,SimGNN使用神经张量网络替代简单的内积运算。NTN的计算公式如下:
g(hi,hj)=f3(hiTW3[1:K]hj+V[hihj]+b3)g(h_i, h_j) = f_3\left(h_i^T W_3^{[1:K]} h_j + V\left[ \begin{array}{l} h_i \\ h_j \end{array} \right] + b_3\right)g(hi,hj)=f3(hiTW3[1:K]hj+V[hihj]+b3)
其中:
- hih_ihi 和 hjh_jhj 分别是两个图的嵌入向量
- W3[1:K]W_3^{[1:K]}W3[1:K] 是三维权重张量(维度 D×D×KD \times D \times KD×D×K)
- VVV 是线性权重矩阵
- KKK 是交互分数的维度(实验中设为16)
- f3f_3f3 为ReLU激活函数
该操作能生成 KKK 个交互特征,全面刻画两图的全局相似性。(简单来说:得到最有价值的K维特征)
4. 相似度分数初步计算
将NTN输出的 KKK 维交互特征,通过4层全连接网络逐步降维(32→16→8→4→1),得到初步的全局相似度分数。训练过程中,采用均方误差(MSE)损失优化预测分数与真实相似度的差距:
L=1∣D∣∑(i,j)∈D(s^ij−s(Gi,Gj))2\mathcal{L} = \frac{1}{|\mathcal{D}|} \sum_{(i,j) \in \mathcal{D}} \left(\hat{s}_{ij} - s(\mathcal{G}_i, \mathcal{G}_j)\right)^2L=∣D∣1(i,j)∈D∑(s^ij−s(Gi,Gj))2
其中:
- D\mathcal{D}D 是训练图对集合
- s^ij\hat{s}_{ij}s^ij 是预测相似度
- s(Gi,Gj)s(\mathcal{G}_i, \mathcal{G}_j)s(Gi,Gj) 是真实相似度(由GED转换得到)
全局图: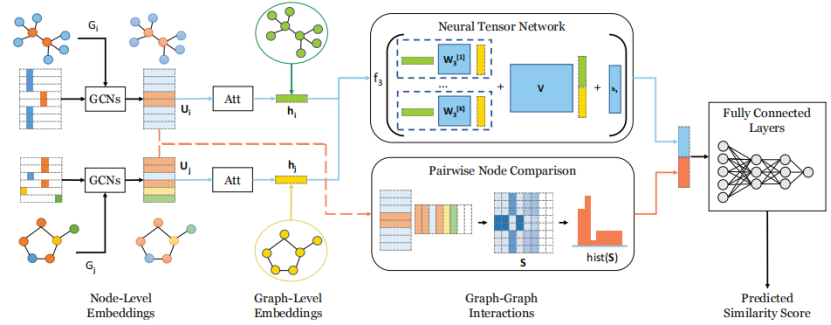
节点级成对比较: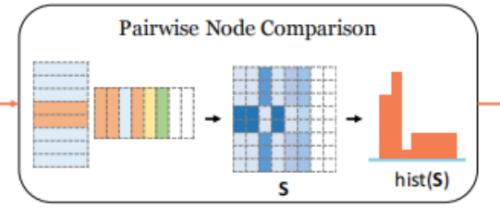
三、核心策略二:节点级成对比较(Pairwise Node Comparison)

仅靠图级嵌入无法捕捉细粒度的节点分布差异(如局部子结构不同),因此SimGNN补充了节点级成对比较策略,流程如下:
1. 先做fake padding:因为两图节点数可能不一样
2. 成对节点相似度矩阵计算
设两个图 Gi\mathcal{G}_iGi 和 Gj\mathcal{G}_jGj 的节点嵌入矩阵分别为 Ui∈RNi×DU_i \in \mathbb{R}^{N_i \times D}Ui∈RNi×D 和 Uj∈RNj×DU_j \in \mathbb{R}^{N_j \times D}Uj∈RNj×D,计算所有节点对的相似度:
S=σ(UiUjT)S = \sigma(U_i U_j^T)S=σ(UiUjT)
其中,σ\sigmaσ 是sigmoid函数,确保相似度分数在(0,1)区间。若两图节点数不同,对较小图填充零向量嵌入,使矩阵维度统一为 N×NN \times NN×N(N=max(Ni,Nj)N = max(N_i, N_j)N=max(Ni,Nj))。
3. 直方图特征提取
由于节点无固定顺序,直接将相似度矩阵展平会破坏表示不变性。因此SimGNN将矩阵转换为直方图特征 hist(S)∈RBhist(S) \in \mathbb{R}^Bhist(S)∈RB(BBB 为分箱数,实验中设为16),既保留节点分布信息,又确保顺序无关。
4. 特征融合
将直方图特征与策略一得到的 KKK 维交互特征拼接,输入全连接网络得到最终相似度分数。需要注意的是,直方图特征不可微,策略一的损失仍为模型参数更新的主要驱动,策略二仅提供补充信息。
四、SimGNN完整架构与时间复杂度
1. 整体流程
- 对输入的两个图,分别通过GCN生成节点嵌入;
- 基于注意力机制聚合节点嵌入,得到两个图的全局嵌入;
- 用NTN计算图嵌入的交互特征,同时计算节点成对相似度矩阵并提取直方图特征;
- 拼接两类特征,通过全连接网络输出最终相似度分数。
2. 时间复杂度分析
- 节点嵌入与图嵌入生成:O(E)O(E)O(E)(EEE 为图的边数),可预计算存储;
- 图-图交互(策略一):O(D2K)O(D^2 K)O(D2K)(DDD 为图嵌入维度);
- 节点成对比较(策略二):O(DN2)O(D N^2)O(DN2)(NNN 为最大节点数)。
最坏情况下,SimGNN的时间复杂度为 O(N2)O(N^2)O(N2),远低于传统近似算法的多项式/指数复杂度,且支持GPU加速。
五、核心优势总结
- 高效性:预计算图嵌入后,相似度查询可实时响应,比传统GED算法快数百倍;
- 精准性:结合全局嵌入与局部节点分布,在AIDS、LINUX、IMDB等数据集上的MSE误差显著低于基线;
- 泛化性:GCN与注意力机制的设计确保模型能适配不同类型的图(带标签/无标签、小分子/社交网络),且能泛化到 unseen 图。
SimGNN的创新之处在于将图相似度计算从"组合优化问题"转化为"端到端学习问题",为大规模图相似度检索提供了新范式。无论是化学分子筛选、程序依赖图匹配还是社交网络分析,SimGNN都能在保证精度的同时满足实时性需求,成为图数据挖掘领域的经典方法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)