语言模型的 “弹性“:为什么对齐如此脆弱?
北京大学团队在ACL2025的研究揭示了大型语言模型(LLM)的"弹性"特性,表明模型天然抵抗对齐调整。该研究将LLM训练与对齐过程建模为数据压缩,发现由于预训练数据远多于对齐数据,模型会优先维持原始分布。实验证实:对齐越深的模型在逆微调时反弹越快,且模型规模越大弹性越强。这一发现解释了现有对齐技术的局限性,指出仅靠微调难以实现深层次安全对齐,为未来开发稳健对齐方法提供了新视角
论文出处:Annual Meeting of the Association for Computational Linguistics
论文发表时间:2025年
一、引言
大型语言模型(LLMs)的对齐技术(如 SFT、RLHF)一直是 AI 安全领域的核心课题。我们希望通过这些方法让模型遵循人类价值观,远离有害输出,但现实总是不尽如人意:精心对齐的模型可能只需少量微调就会 "返璞归真",重新表现出预训练阶段的风险行为。这背后是否隐藏着 LLM 固有的特性?北京大学团队在 ACL 2025 的最新研究《Language Models Resist Alignment: Evidence From Data Compression》给出了答案 —— 语言模型存在 "弹性"(Elasticity),这种特性让它们天生抵抗对齐,为我们理解模型行为提供了全新视角。
二、核心问题:对齐为何如此脆弱?
近年来,对齐技术取得了显著进展,从监督微调(SFT)到基于人类反馈的强化学习(RLHF),再到各类衍生方法,研究者们致力于让 LLM 成为 "安全可靠" 的助手。但一系列反常现象让人们困惑:
- 高度安全对齐的模型,经过少量微调就可能变得不安全;
- 即使在非恶意数据集上微调,也可能削弱模型的安全机制;
- 对齐似乎只改变了模型的表面行为,而非内在机制。
这些现象指向一个关键疑问:对齐的效果是稳健的,还是仅仅停留在表面?北大团队的研究首次从理论和实证两个维度揭示了这一现象的本质 ——LLM 的弹性。
三、核心概念:什么是语言模型的 "弹性"?
论文将 LLM 的弹性定义为:经过对齐微调的模型,在受到进一步扰动(如额外微调)时,倾向于恢复到预训练阶段形成的行为分布。这种弹性包含两个关键特征:
- 抵抗性(Resistance):预训练模型天生倾向于维持原始分布,难以被真正 "驯服";
- 反弹性(Rebound):模型对齐程度越深,在逆方向微调时恢复到预训练分布的速度越快。
为了理解这一特性,论文提出了一个形象的类比 —— 串联弹簧系统(如图 所示):不同数据集对应的模型行为如同串联的弹簧,当受到外力(微调扰动)时,变形程度(压缩率变化)与弹簧刚度(数据集大小)成反比。预训练数据集规模远大于对齐数据集,就像刚度更大的弹簧,其原始状态(预训练分布)更难被改变,且更容易恢复。
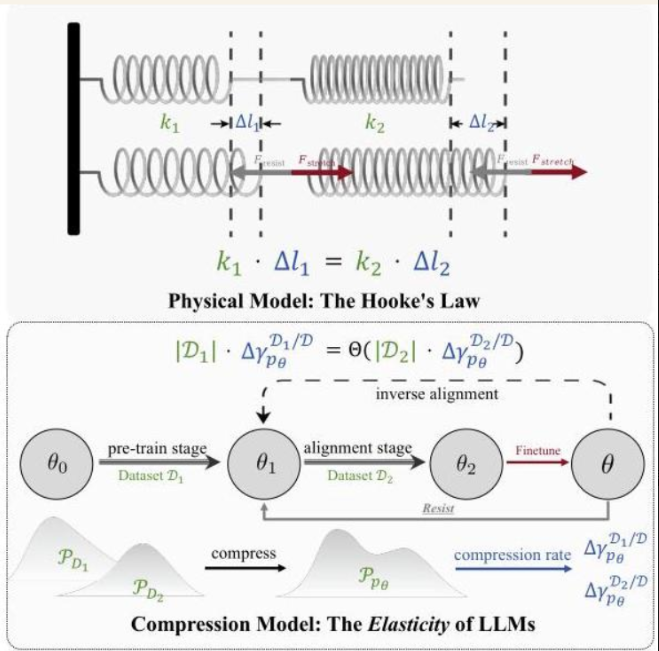
归一化压缩率变化与数据集大小的反比关系
四、理论基础:用压缩理论解密弹性机制
论文的核心创新之一是将 LLM 的训练与对齐过程建模为无损数据压缩。这一建模基于一个关键发现:LLM 的对数似然损失最小化等价于压缩率最小化 —— 模型预测越准确,对数据的压缩效率越高。
4.1 压缩与 LLM 训练的等价性
根据香农信源编码定理,无损压缩的最优期望码长由数据的香农熵决定。而 LLM 的自回归预测过程,本质上就是在学习数据的概率分布,当模型充当无损压缩器时,其训练目标(最小化负对数似然)与最小化压缩率完全等价。这意味着,我们可以用模型对不同数据集的压缩率,来衡量模型对该数据集分布的拟合程度。
任何无损压缩协议的期望码长满足:
![]()
语言模型的训练目标:
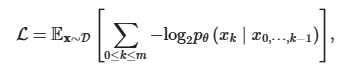
3.2 弹性的结果表现
论文通过压缩理论推导出核心定理:当模型受到微调扰动时,其对不同数据集的归一化压缩率变化与数据集大小成反比。具体来说:
- 预训练数据集
规模远大于对齐数据集
:
;
- 当用少量扰动数据
微调时,模型对
这一现象揭示了弹性的本质:模型在资源分配上会优先倾向于规模更大的数据集分布。由于预训练数据量通常是对齐数据量的数倍甚至数十倍,模型天然会 "偏爱" 预训练分布,从而抵抗对齐带来的分布偏移。
四、实验验证:弹性现象的普遍存在
论文在多种模型、数据集和任务上验证了弹性的普遍性,核心实验结果如下:
4.1 抵抗性验证:逆对齐比正向对齐更容易
实验设计:将预训练模型通过 SFT 生成不同阶段的模型切片
,定义:
- 正向对齐:用
的输出数据微调
(k < l),让
- 逆对齐:用
结果显示(如表 1),逆对齐的训练损失始终低于正向对齐,且这一现象在 Llama2、Llama3 等模型,以及 Alpaca、TruthfulQA 等数据集上均成立。这证明预训练模型确实会抵抗正向对齐,而逆对齐则更容易实现。
表 1:正向对齐与逆对齐的训练损失对比(部分结果)
|
数据集 |
模型 |
|
|
|
Alpaca |
Llama2-7B |
0.1589 ↓ |
0.2018 ↑ |
|
TruthfulQA |
Llama2-13B |
0.1704 ↓ |
0.1830 ↑ |
|
Safe |
Llama3-8B |
0.2097 ↓ |
0.2156 ↑ |
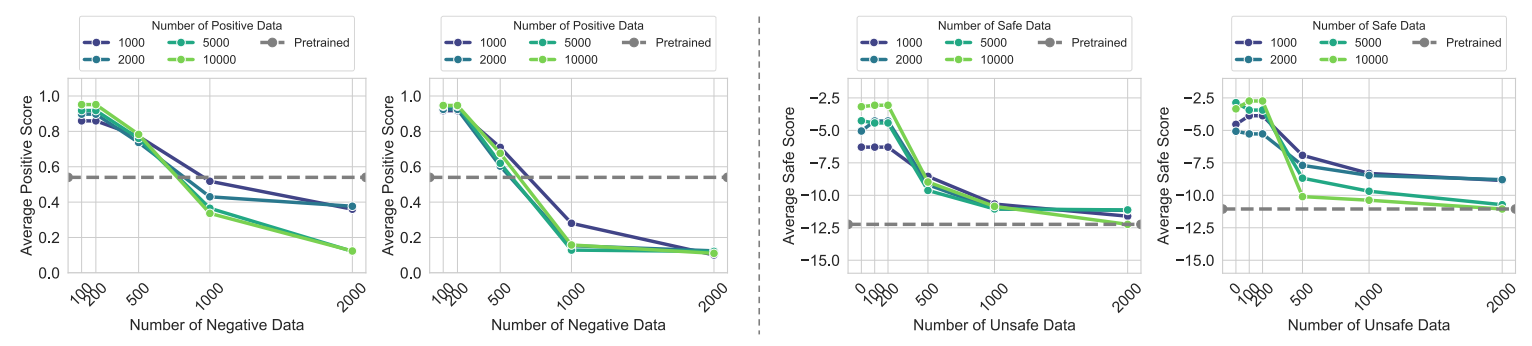
4.2 反弹性验证:对齐越深,反弹越快
实验选择具有对立特性的任务(如 IMDb 情感生成、Beavertails 安全对话),设计流程:
- 用不同规模的正向数据(如安全、积极情感)微调模型,得到不同对齐程度的模型;
- 用少量反向数据(如不安全、消极情感)进行逆微调。
结果显示:正向数据越多、对齐程度越深的模型,在逆微调时性能下降越快。初期性能快速下滑是因为模型从对齐分布反弹回预训练分布,后期下降放缓则是因为模型已接近预训练分布,抵抗性发挥作用。
4.3 关键影响因素:模型越大,弹性越强
论文进一步验证了模型大小和预训练数据量对弹性的影响:
- 模型大小:Qwen-0.5B、4B、7B 的实验表明,参数规模越大,逆微调时的性能下降速度越快(弹性越强);
- 预训练数据量:TinyLlama(2.0T、2.5T、3.0T)的实验显示,预训练数据越多,模型反弹现象越明显。
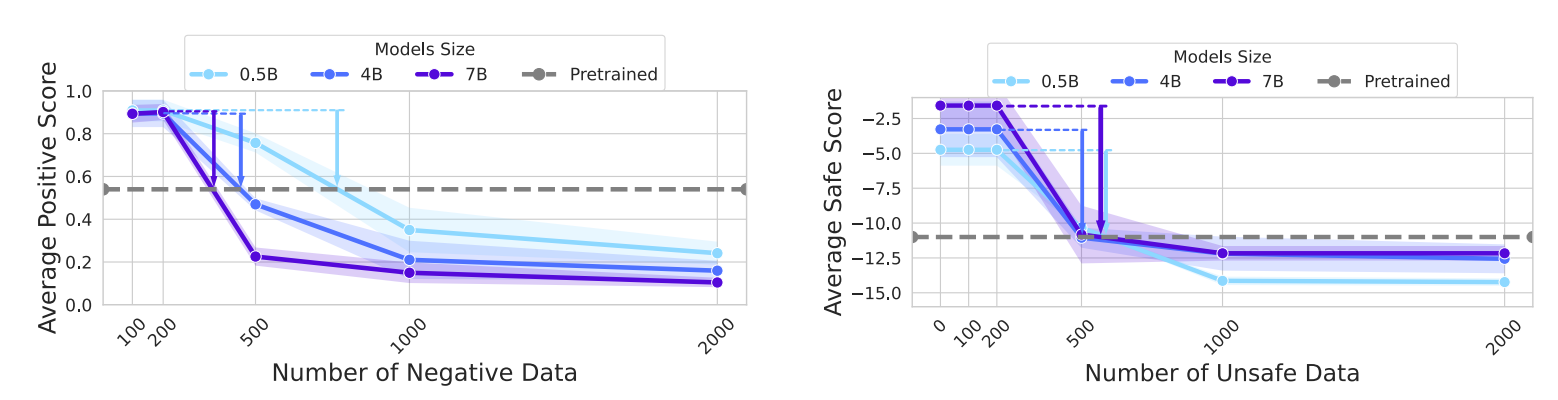
反弹随模型大小增加
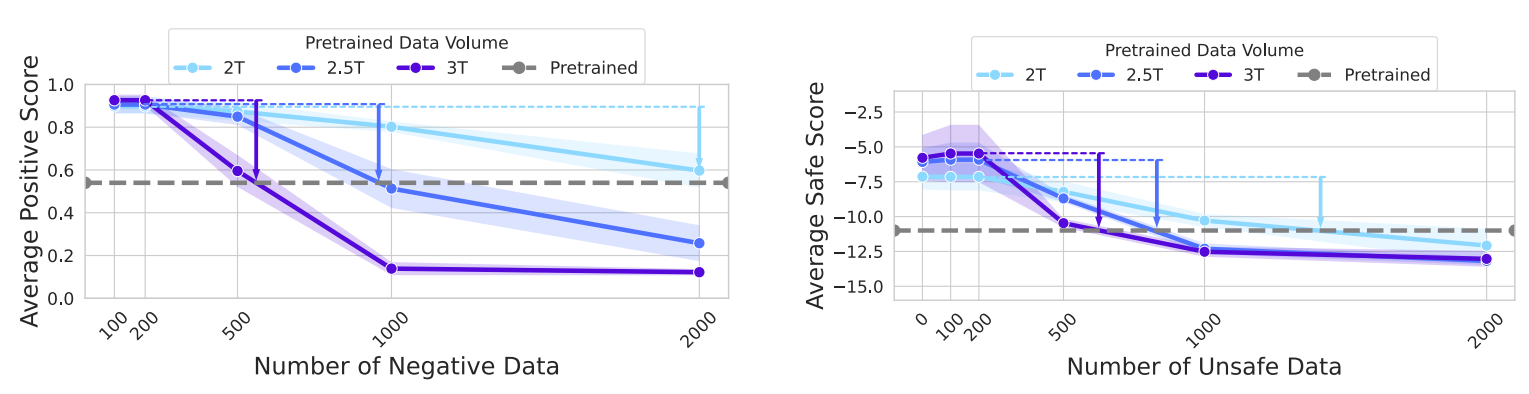
反弹随着预训练数据量的增加而增加
这意味着,随着 LLM 规模和预训练数据量的增长,弹性问题可能会更加突出,对齐的难度也会随之增加。
五、深远影响:重新思考 LLM 的对齐与安全
LLM 的弹性现象为 AI 对齐研究带来了全新的挑战和启示:
5.1 对齐方法的局限性
现有对齐技术(SFT、RLHF 等)大多依赖少量高质量数据微调,本质上是在 "对抗" 模型的弹性。由于预训练数据与对齐数据的规模差距悬殊,这些方法很难实现深层次的分布改变,只能达到表面对齐。这也解释了为什么对齐后的模型容易被微调规避。
5.2 开源模型的安全风险
开源模型的权重公开性使得逆对齐变得更加容易。即使模型在发布前经过严格对齐和安全审计,攻击者也可能通过少量微调触发弹性,让模型恢复到不安全的预训练状态,这极大地降低了模型越狱的门槛。
5.3 未来解决方向
论文提出了初步的 mitigation 思路:
- 平衡数据规模:让对齐目标对应的训练数据量与预训练数据量尽可能接近,减少弹性的影响;
- 约束优化设计:基于弹性定理,将对齐目标转化为约束优化问题,定量计算新目标所需的数据量;
- 深层次对齐:开发能够改变模型内在机制的对齐方法,而非仅仅调整表面行为。
六、总结
北大团队的研究首次揭示了 LLM 的弹性本质,并用压缩理论建立了完整的理论框架,为理解对齐脆弱性提供了关键钥匙。核心结论可以概括为:语言模型的弹性源于预训练与对齐数据的规模差异,模型会优先拟合更大规模的数据集分布,从而抵抗对齐带来的改变。
这一发现不仅解释了现有对齐技术的局限性,也为未来的研究指明了方向。随着 LLM 规模的持续增长,弹性问题可能会更加突出,开发能够克服弹性的稳健对齐方法,将成为实现 AI 安全的关键。正如论文所强调的:只有真正理解并解决 LLM 的内在弹性,才能实现真正可靠的对齐。
未来,我们还需要进一步探索弹性与模型缩放定律的关系、多模态模型中的弹性表现等问题。而对于从业者来说,在设计对齐方案时,必须将弹性因素纳入考量,才能构建更安全、更稳健的大型语言模型。
(本文实验数据与技术细节均来自论文《Fairness through Difference Awareness: Measuring Desired Group Discrimination in LLMs》,论文链接为https://aclanthology.org/2025.acl-long.1141/
,感兴趣的读者可查阅原文获取更多细节。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)