基于昇腾的大模型性能分析
性能采集工具MindStudio Insight界面介绍文档包括Timeline、Operator、Memory、Summary、Communication页签。
·
文章目录
背景
- 性能优化的是什么
本文章介绍Pytorch模型基于昇腾设备的性能优化;而性能优化的总体原则为减少Host算子下发时间和减少Device算子执行时间。
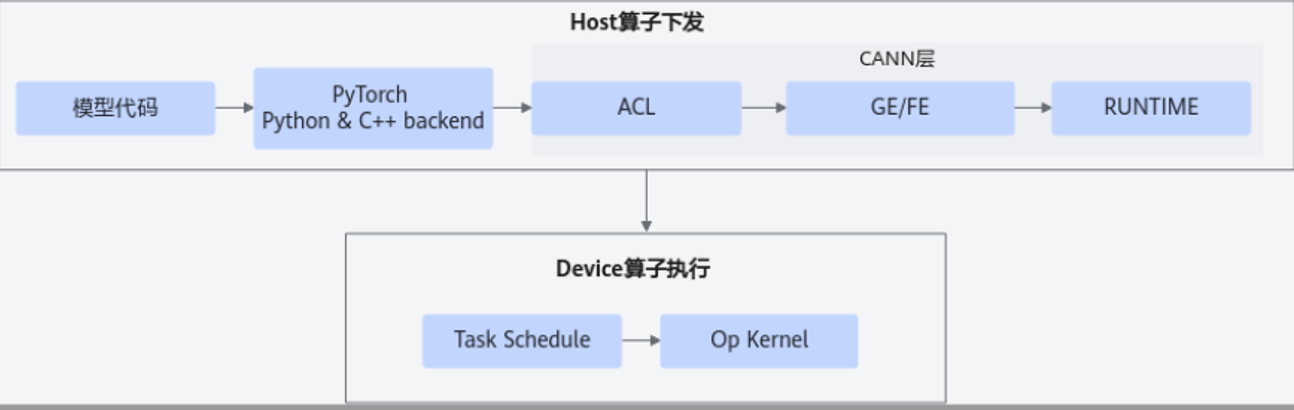
-
性能问题主要是分析什么
可以分为:下发、计算、通信三大类问题。 -
性能的调优流程是什么
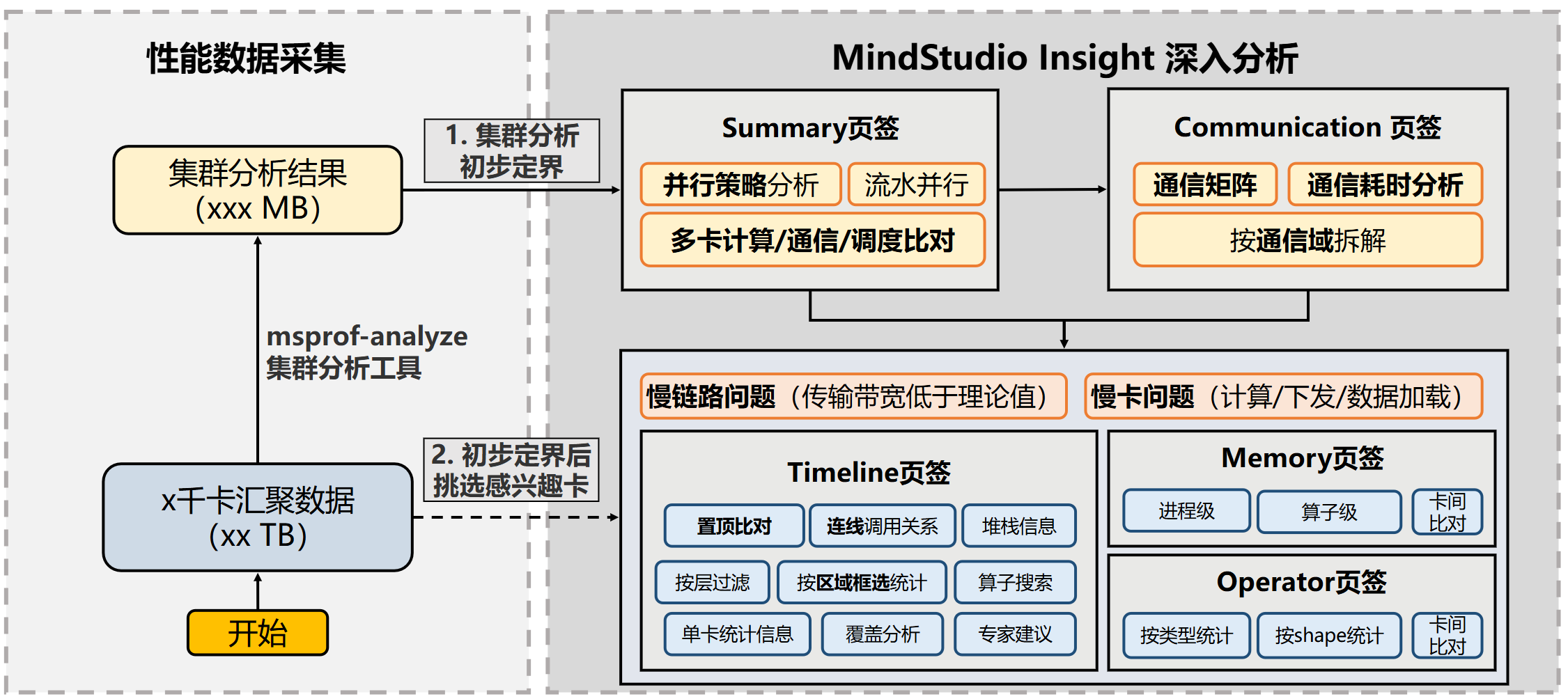
1.数据采集、解析
2.初步定界分析:msprof-analyze(专家建议、对比工具、集群分析)
3.深入分析:MindStudio Insight可视化分析
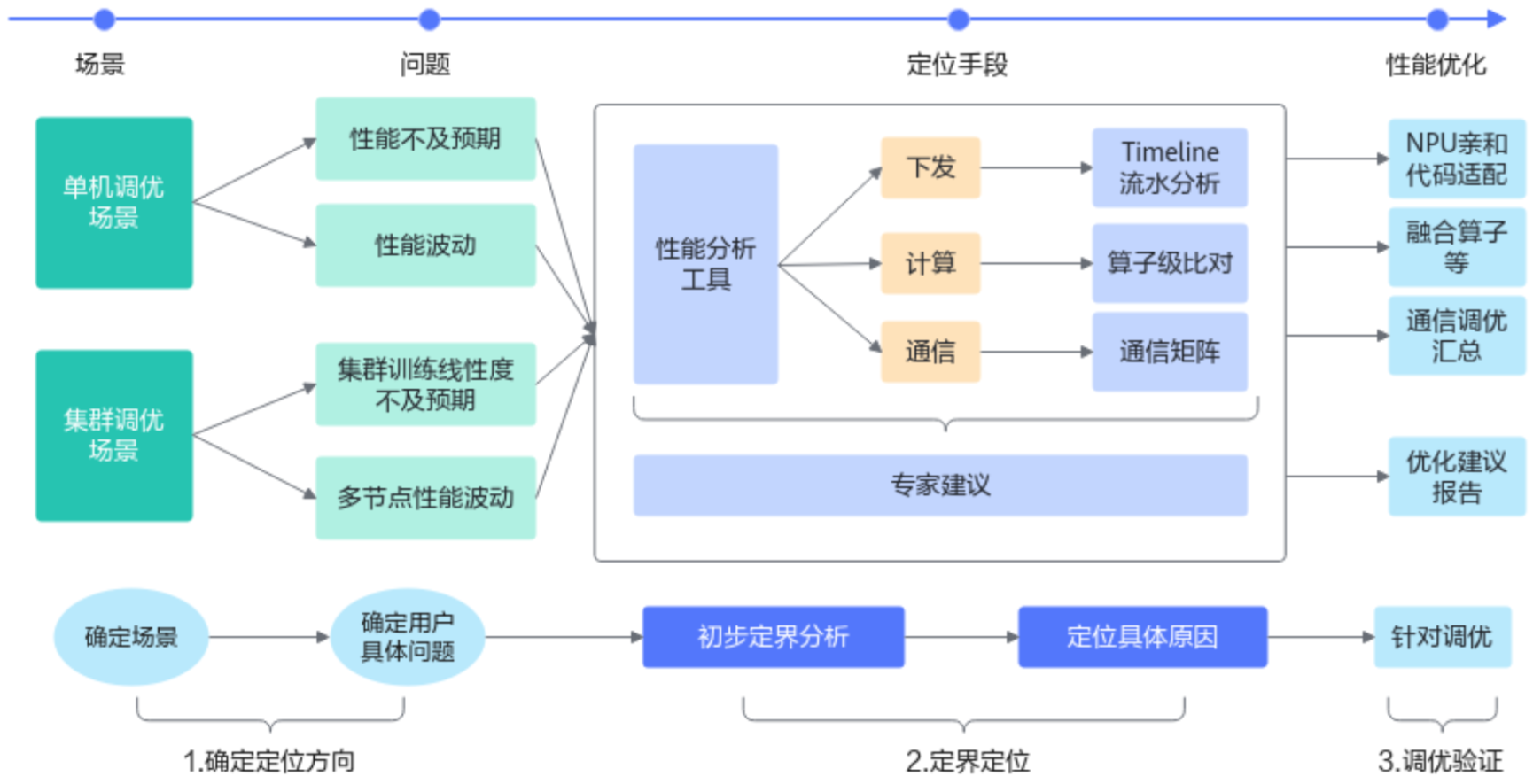
总流程图:
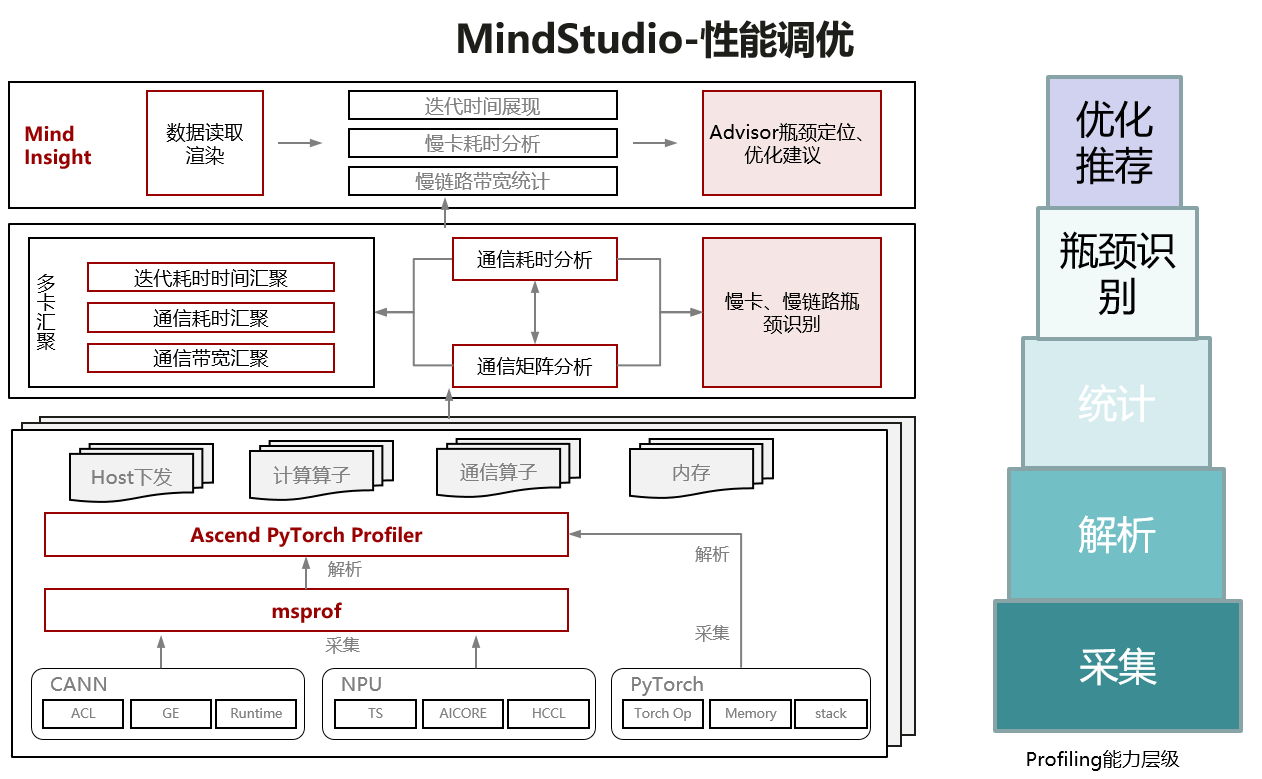
profiling数据采集
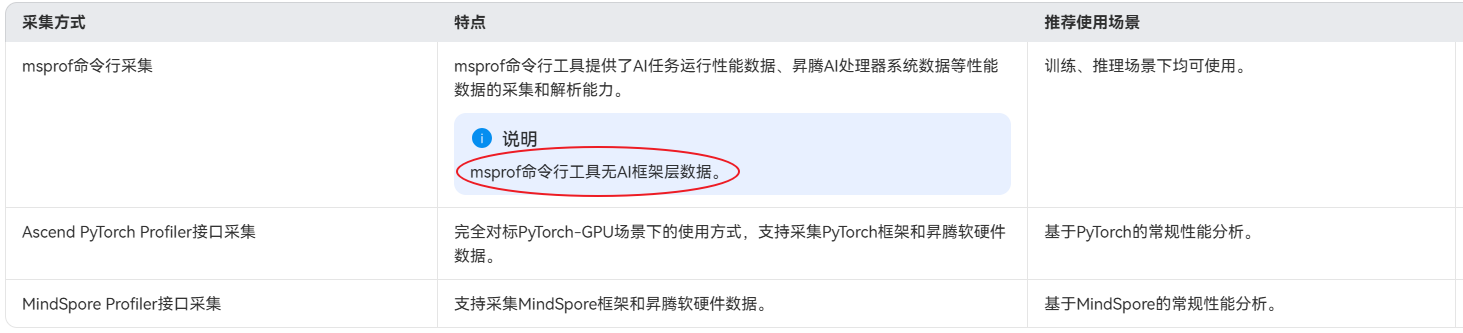
采集工具介绍
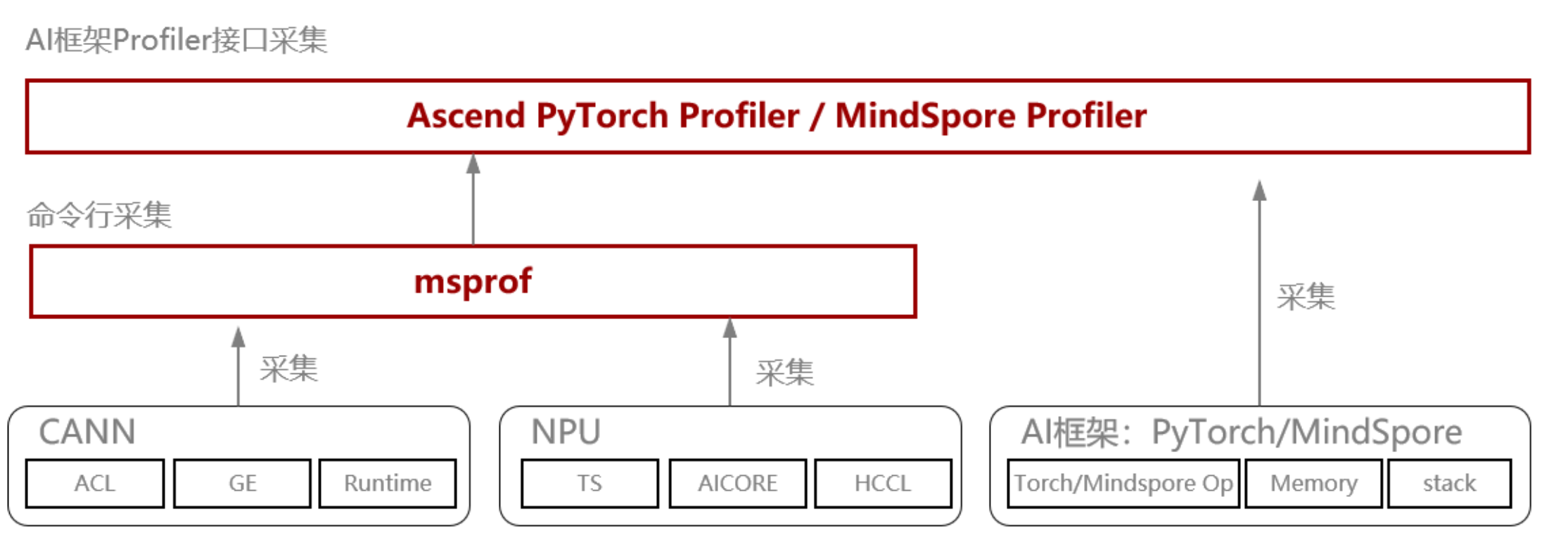
msprof、Ascend PyTorch Profiler/MindSpore Profiler之间的区别和关系:
MindIE纯模型profiling的采集
MindIE ATB-Models的性能采集方式:参考MindIE LLM README
设置如下:
# 注意atb-models已经在run_pa.py集成了Ascend PyTorch Profiler接口,可以直接通过环境变量开启采集
export ATB_PROFILING_ENABLE=1
export PROFILING_LEVEL=Level1
export WITH_STACK_ENABLE=1
# exprot PROFILING_FILEPATH=./profiling
profiling数据文件说明
profiling
└── 319b6248b57e_117843_20251119012620334_ascend_pt // 性能数据结果目录,命名格式:{worker_name}_{timestamp}_ascend_{framework},默认情况下{worker_name}为{hostname}_{pid},{timestamp}为时间戳,{framework}是MindSpore和PyTorch两个框架的简写(ms和pt)
├── profiler_info_{Rank_ID}.json // 用于记录Profiler相关的元数据,PyTorch单卡场景时文件名不显示{Rank_ID}
├── profiler_metadata.json // 用来保存用户通过add_metadata接口添加的信息和其他Profiler相关的元数据
├── ASCEND_PROFILER_OUTPUT // MindSpore Profiler或Ascend PyTorch Profiler接口采集并解析的性能数据目录
│ ├── api_statistic.csv // profiler_level配置为Level0(仅MindSpore)、Level1或Level2级别时生成
│ ├── communication.json // 多卡或集群等存在通信的场景,为性能分析提供可视化数据基础,profiler_level配置为Level1或Level2级别时生成
│ ├── communication_matrix.json // 多卡或集群等存在通信的场景,为性能分析提供可视化数据基础,通信小算子基本信息文件,profiler_level配置为Level1或Level2级别时生成
│ ├── kernel_details.csv // activities配置为NPU类型时生成
│ ├── memory_record.csv // profile_memory配置True开启时生成
│ ├── nic.csv // sys_io配置True开启时生成
│ ├── npu_module_mem.csv // profile_memory配置True开启时生成
│ ├── operator_details.csv // MindSpore场景配置activities为CPU类型且record_shapes配置True开启时生成;PyTorch场景默认自动生成
│ ├── operator_memory.csv // profile_memory配置True开启时生成
│ ├── op_statistic.csv // AI Core和AI CPU算子调用次数及耗时数据
│ ├── step_trace_time.csv // 迭代中计算和通信的时间统计
│ └── trace_view.json // 记录整个AI任务的时间信息
├── FRAMEWORK // 框架侧的原始性能数据,无需关注
├── logs // 解析过程日志
└── PROF_000001_20251119092620336_GAOJGPIODODEQQRA // CANN层的性能数据,命名格式:PROF_{数字}_{时间戳}_{字符串},data_simplification配置True开启时,仅保留此目录下的原始性能数据,删除其他数据
├── analyze // 多卡或集群等存在通信的场景下,profiler_level配置为Level1或Level2级别时生成
├── device_{Rank_ID} // CANN Profiling采集的device侧的原始性能数据
├── host // CANN Profiling采集的host侧的原始性能数据
├── mindstudio_profiler_log // CANN Profiling解析的日志文件
└── mindstudio_profiler_output // CANN Profiling解析的性能数据
基于MindStudio Insight分析
MindStudio Insight的下载安装
MindStudio Insight的界面介绍
包括Timeline、Operator、Memory、Summary、Communication页签。
Timeline(时间线)界面
- 界面概览
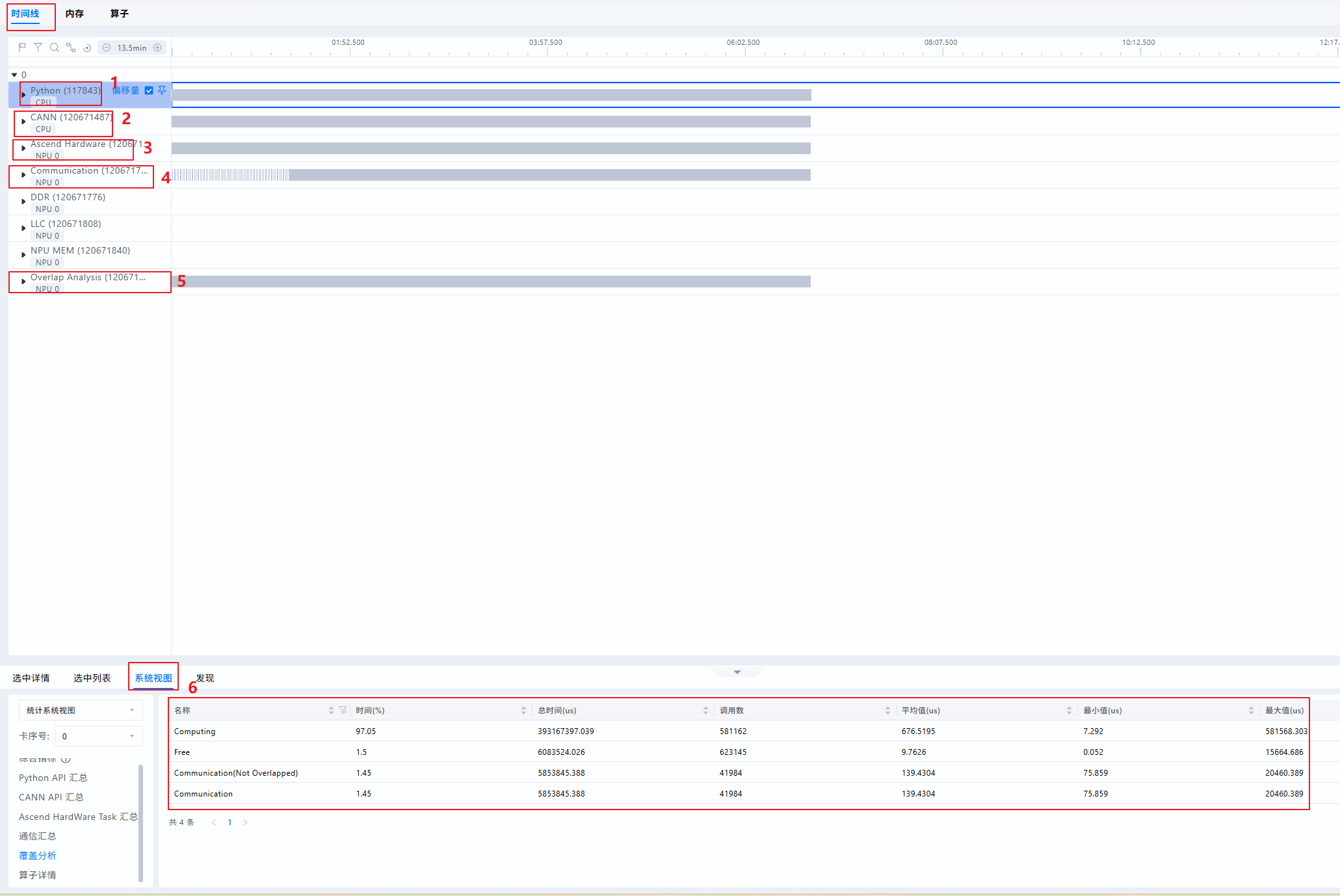
| 序号 | 名称 | 说明 |
|---|---|---|
| 1 | Python泳道(一级流水) | 查看Python层代码,采集时开启with stack开关可查看代码调用栈 |
| 2 | CANN泳道(二级流水) | 收集ACL接口执行、GE融合、Runtime等数据。Python侧算子从一级流水下发至此二级流水,任务从二级流水出队后被下发至NPU层 |
| 3 | Ascend Hardware(NPU层) | 也称Device侧,记录发生在NPU上计算、通信等任务的执行时序。 |
| 4 | Communication | 记录NPU层通信事件,与Ascend Hardware的通信子泳道一一对应,此处由HCCL等组件上报。定位通信细节时,可查看此泳道 |
| 5 | Overlap Analysis(覆盖分析) | 将Ascend Hardware(NPU层)的计算、通信任务垂直投影至此,得到计算、通信、空闲时间的拆分。常用于快速比对不同卡间计算、通信、空闲差异来源 |
| 6 | 统计视图 | 单卡维度统计汇总信息,可通过左侧“卡序号”下拉框切换不同卡 |
-
泳道之间的关系
- 算子从Python(一级流水)处下发至CANN层(二级流水),可通过查看async_task_queue连线,如下图:
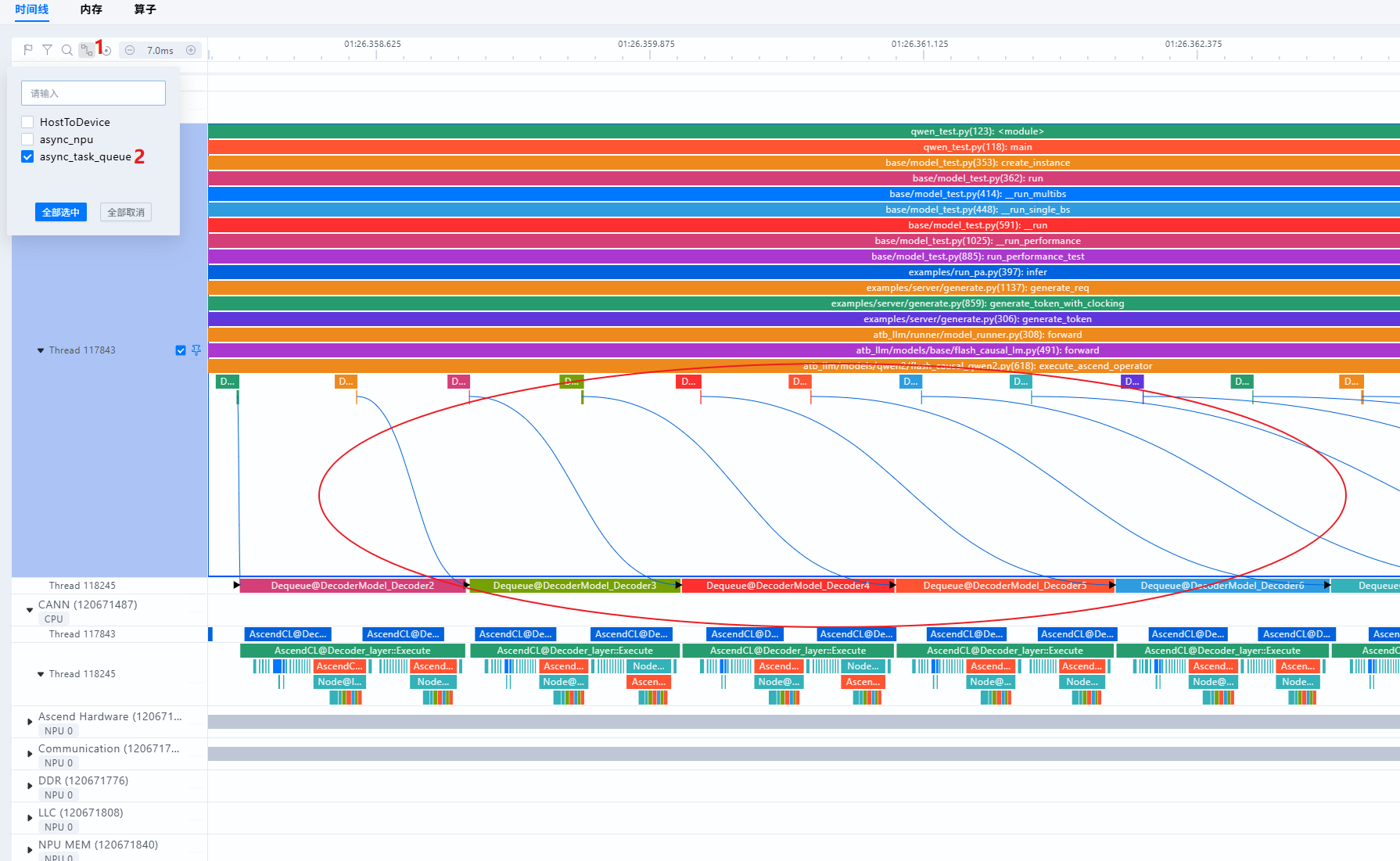
- 算子从CANN层(二级流水)下发至NPU层,即Ascend Hardware泳道,可通过查看HostToDevice连线,如下图:
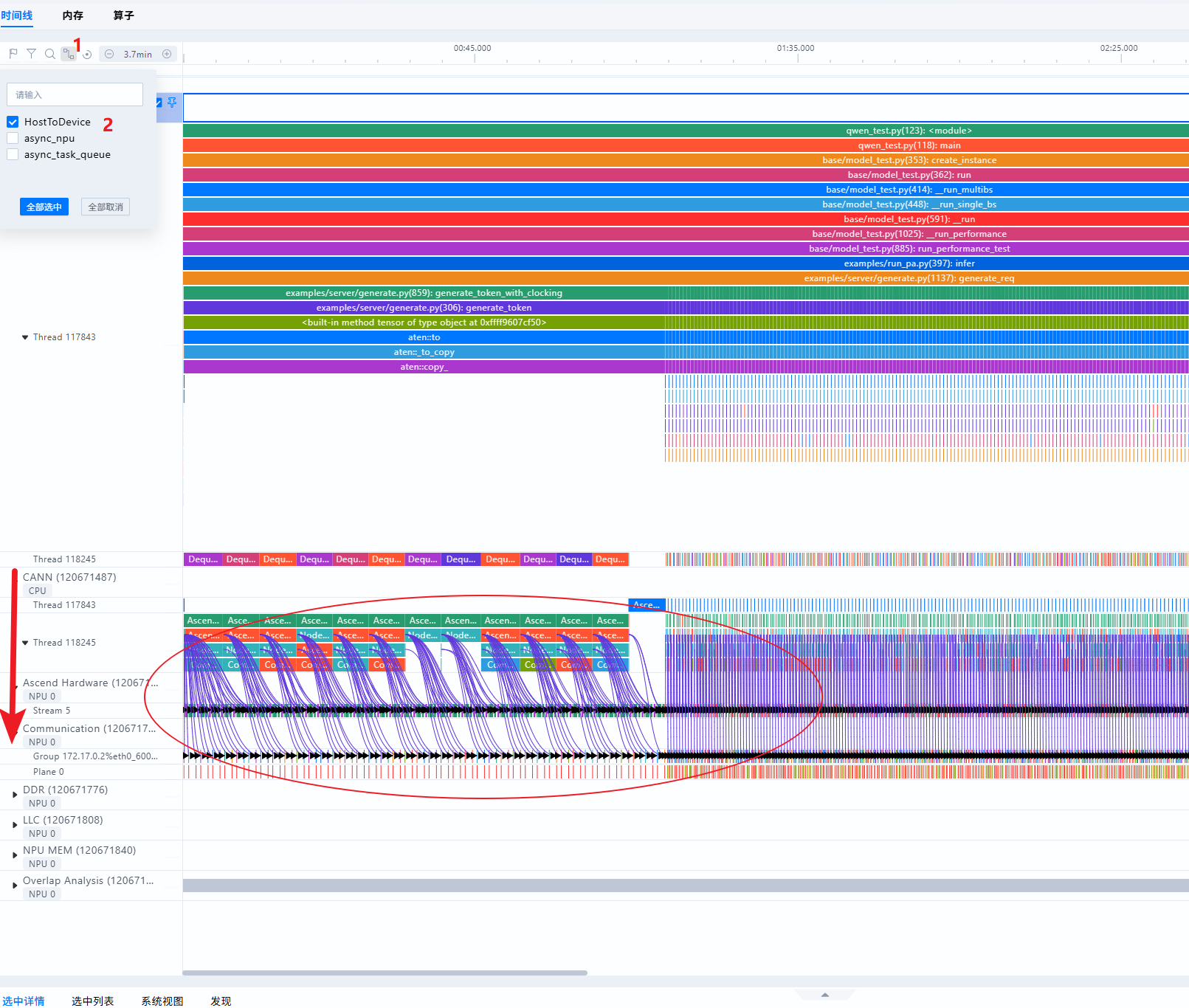
- 算子从Python(一级流水)处下发至NPU层,即Ascend Hardware泳道,可通过查看async_npu连线,如下图:
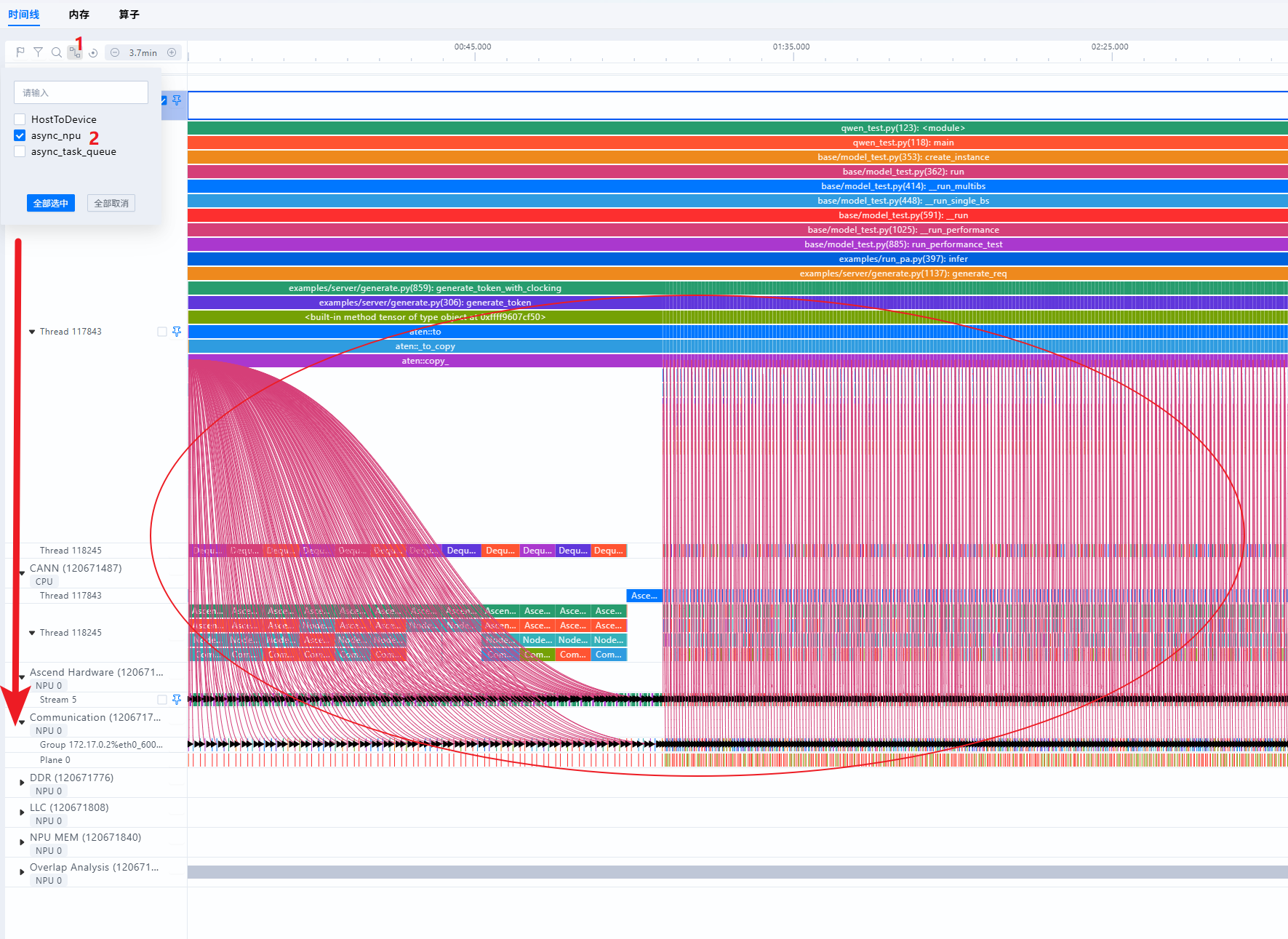
- 算子从Python(一级流水)处下发至CANN层(二级流水),可通过查看async_task_queue连线,如下图:
-
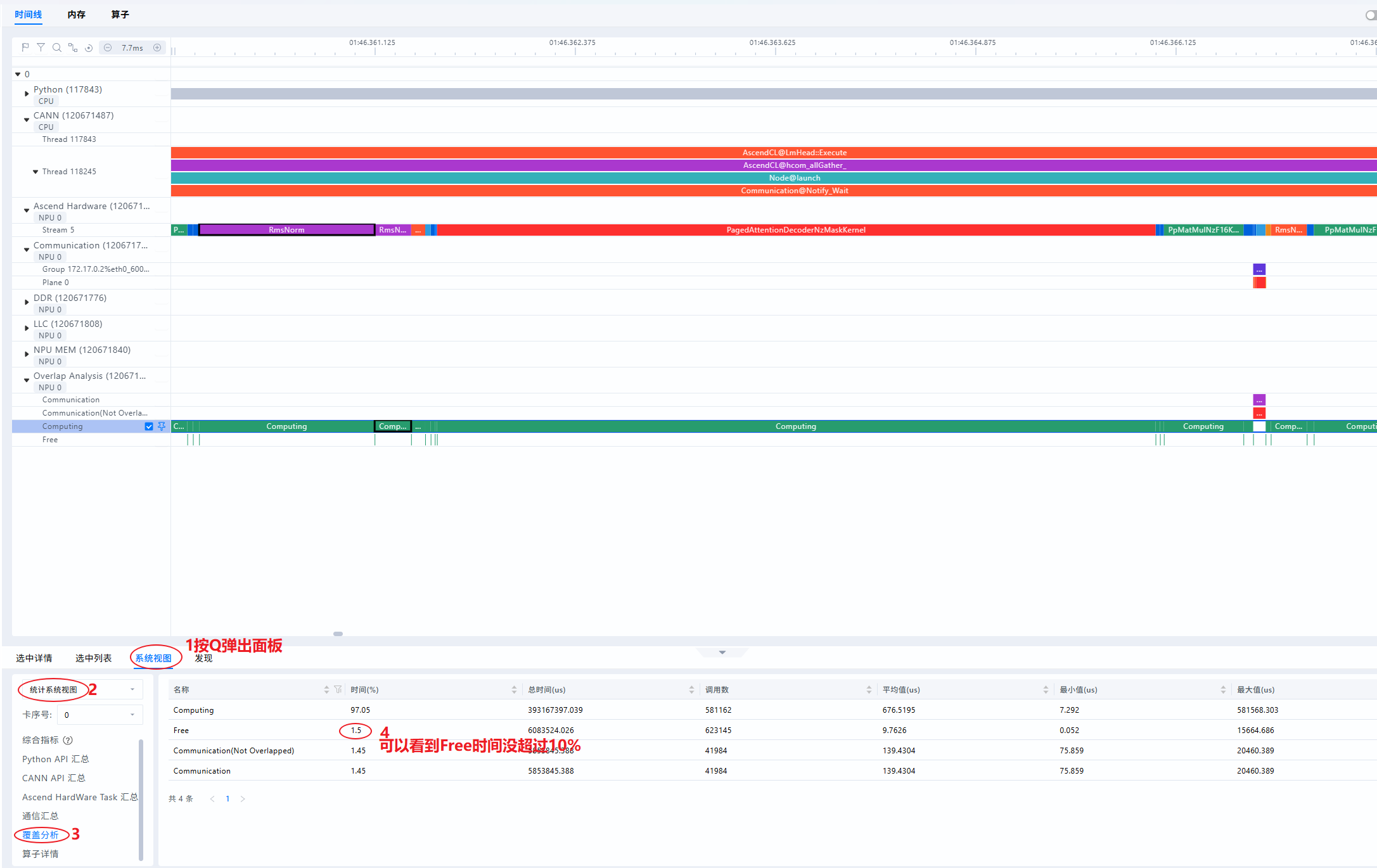
什么是Overlap Analysis(覆盖分析)
- NPU层(即Ascend Hardware层)的事件大致可以分为两种类型,计算事件与通信事件,Overlap Analysis即对NPU层垂直投影后的分类统计;其中Computing为计算算子垂直投影,Communication为通信算子垂直投影;如下图所示:
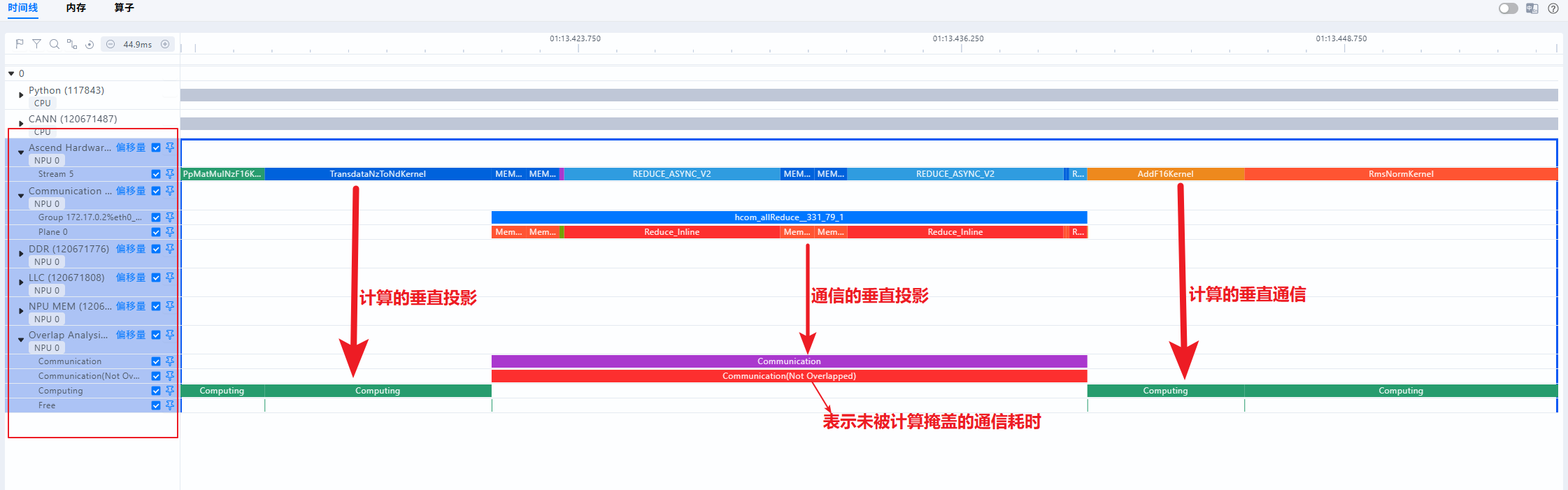
- Communication Not Overlapped即为未被计算覆盖的通信时间。当此类时间占比过高时,可考虑增加计算通信的并行程度

- Free代表NPU即不在计算也不在通信的时间,即为空闲时间。理想情况下,NPU侧的流水线应尽量避免空闲,减少出现NPU等Host侧的场景。若Free Time占比较高(例如超过10%),说明出现Host下发瓶颈,NPU在等待Host侧下发任务,需针对Host侧进行着重优化,例如流水优化、绑核优化、开启CPU高性能模式等

- NPU层(即Ascend Hardware层)的事件大致可以分为两种类型,计算事件与通信事件,Overlap Analysis即对NPU层垂直投影后的分类统计;其中Computing为计算算子垂直投影,Communication为通信算子垂直投影;如下图所示:
MindStudio Insight常用的快捷键
Timeline(时间线)界面
- 放大时间轴:W
- 缩小时间轴:S
- 左移时间轴:A
- 右移时间轴:D
- 页面向上滚动:↑
- 页面向下滚动:↓
- 撤销一次缩放或平移:Backspace
- 重置时间轴:Ctrl(Windows)/ Cmd(Mac)+ 0,时间轴会恢复为默认视图
- 收起/展开底部面板:Q
- 将已框选的区域放大至屏幕:Shift + Z
- 框选一段区域并放大至屏幕:Alt(Windows)/ Option(Mac)+ 拖动,按住 Alt键并拖动鼠标,可以放大框选区域,功能同shift + Z
- 根据当前选中的算子设置或取消框选区域:M
MindStudio Insight的分析流程
按照三个层次:下发->计算->通信来分别展开分析
下发问题分析
理想情况下,NPU侧的计算流水不停运转,不会出现NPU等CPU的场景,一旦出现下发慢的情况,会导致流水线无法运转,aicore算力利用率降低,此时则认为存在下发问题。
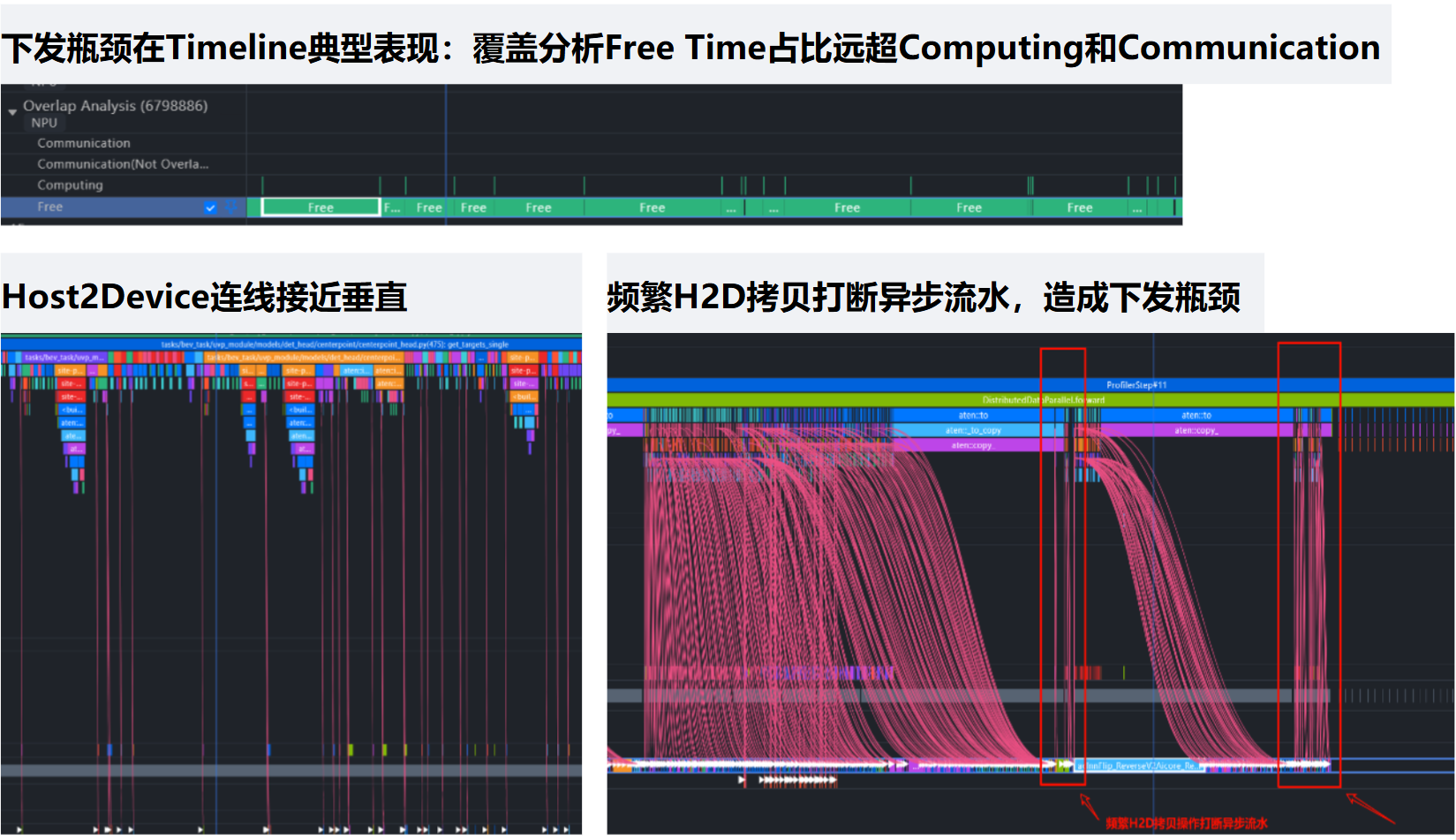
典型表现有以下方面:
- Free Time占比超过10%;2.Host2Device连线接近垂直;3.H2D异步流水频繁被打断
具体操作如下:
- 查看Free Time占比
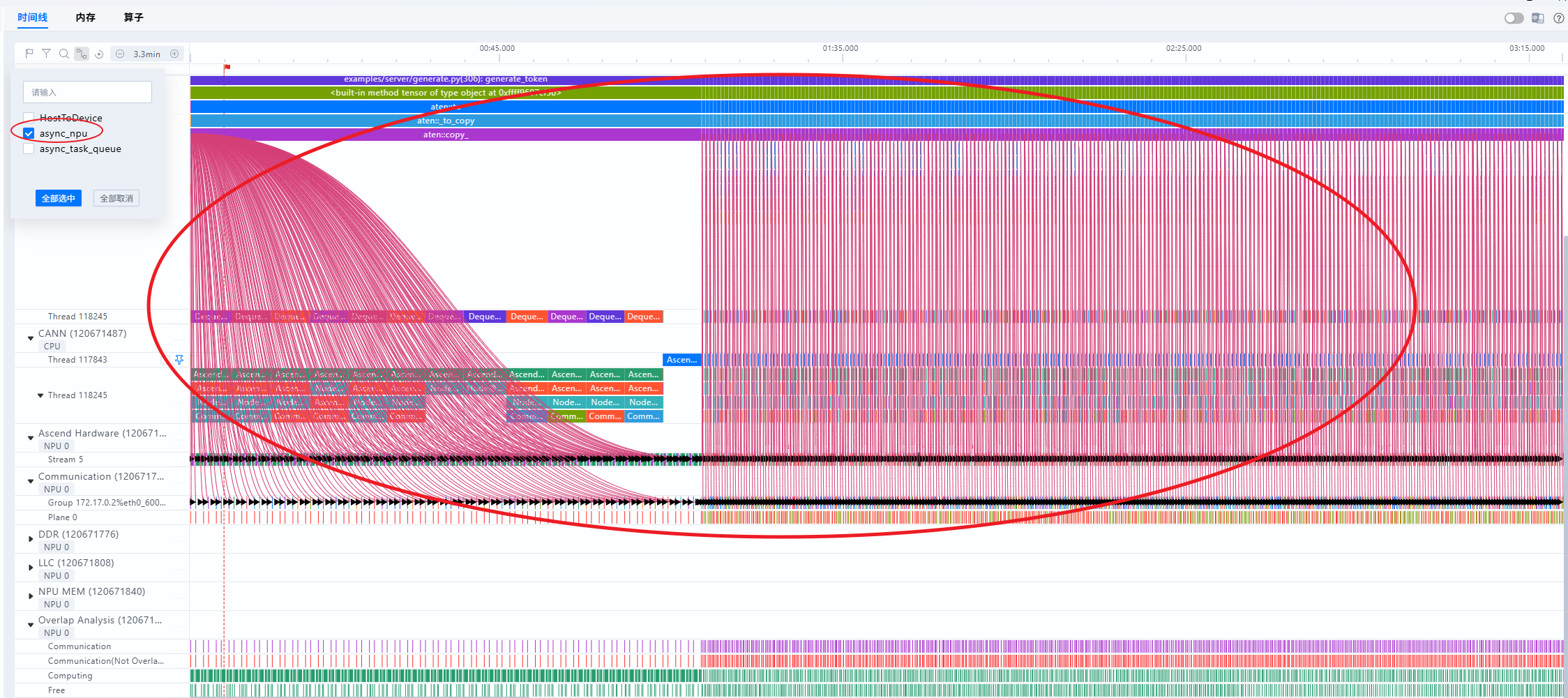
- 查看Host2Device的连线
看下图的连线是明显有下发瓶颈的,右侧连线接近垂直
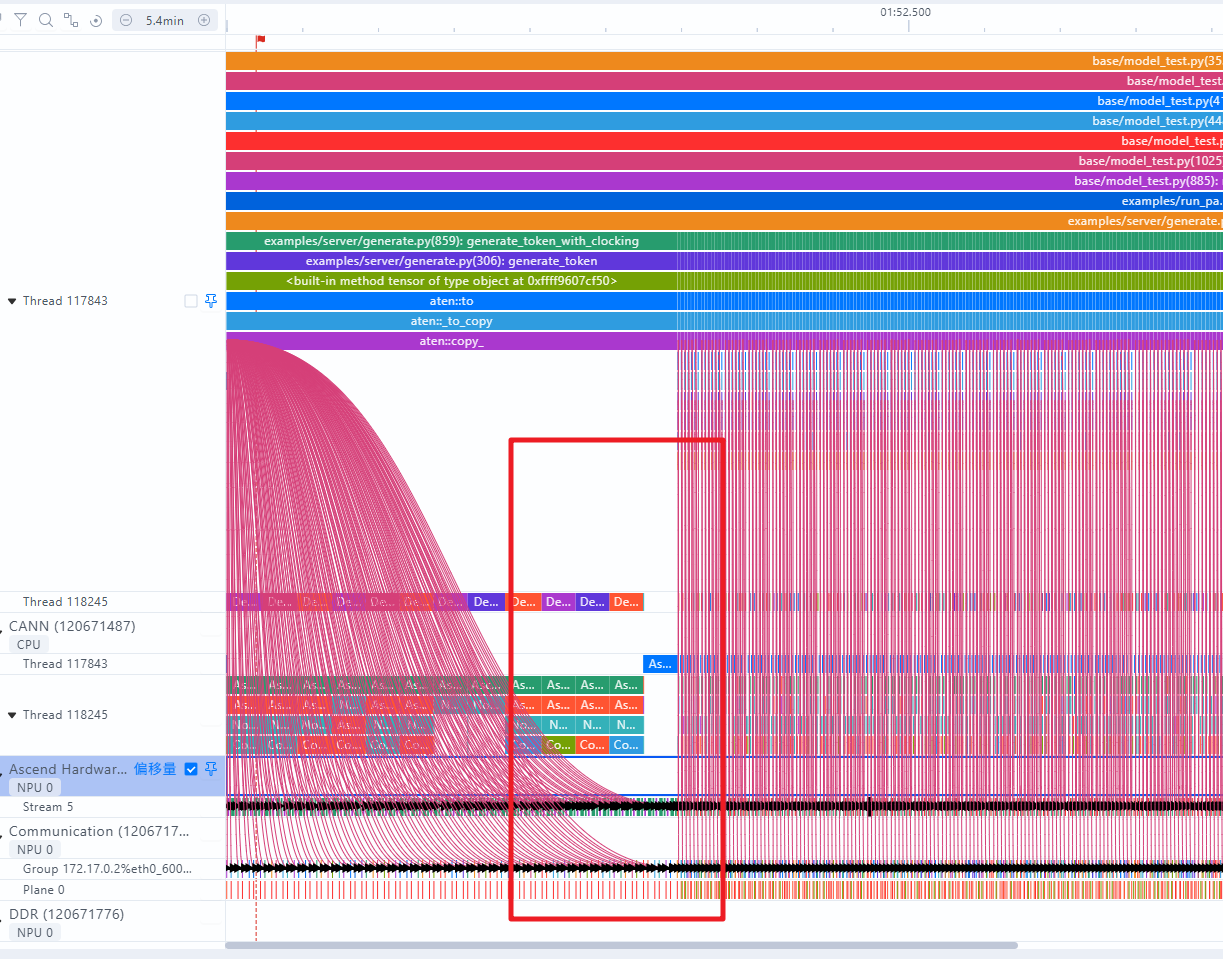
- 查看H2D是否有流水被打断现象
出现通信、拷贝的高耗时打断流水
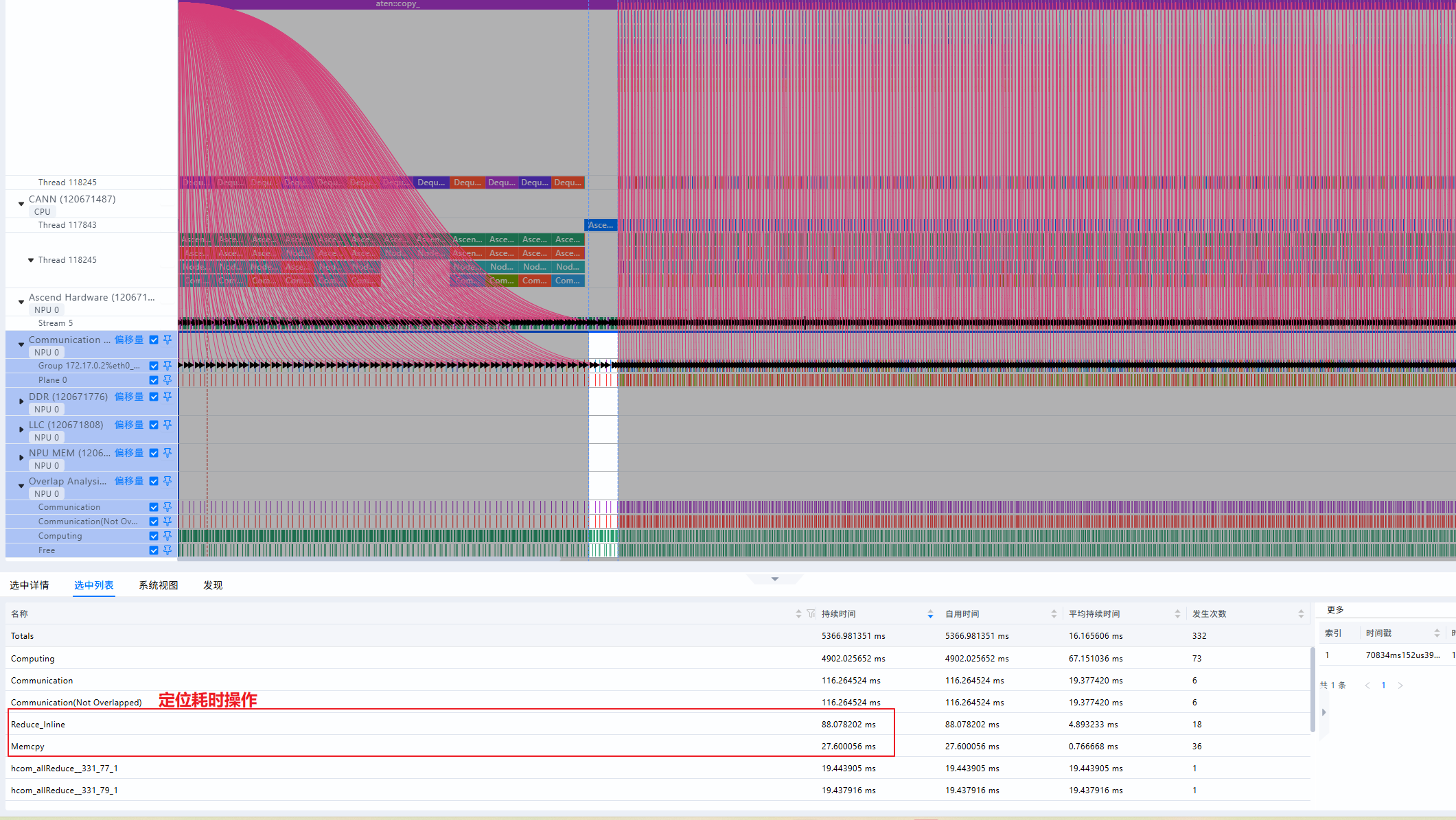
优化方法:
- 开启Host异步调度
如MindIE的异步调度开启:参考链接
# 设置如下环境变量
export MINDIE_ASYNC_SCHEDULING_ENABLE=1
- 流水优化
参考链接
# 设置二级流水
export TASK_QUEUE_ENABLE=2

- 绑核优化
参考链接
# 粗粒度绑核
export CPU_AFFINITY_CONF=1
# 细粒度绑核
export CPU_AFFINITY_CONF=2
计算问题分析
- 查看系统视图
发现计算占比很高,基本时间都耗在计算了
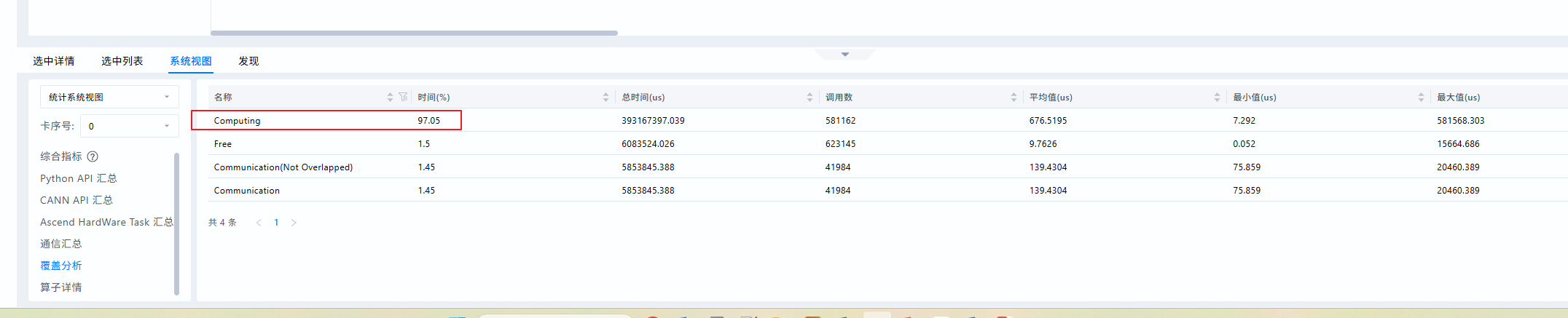
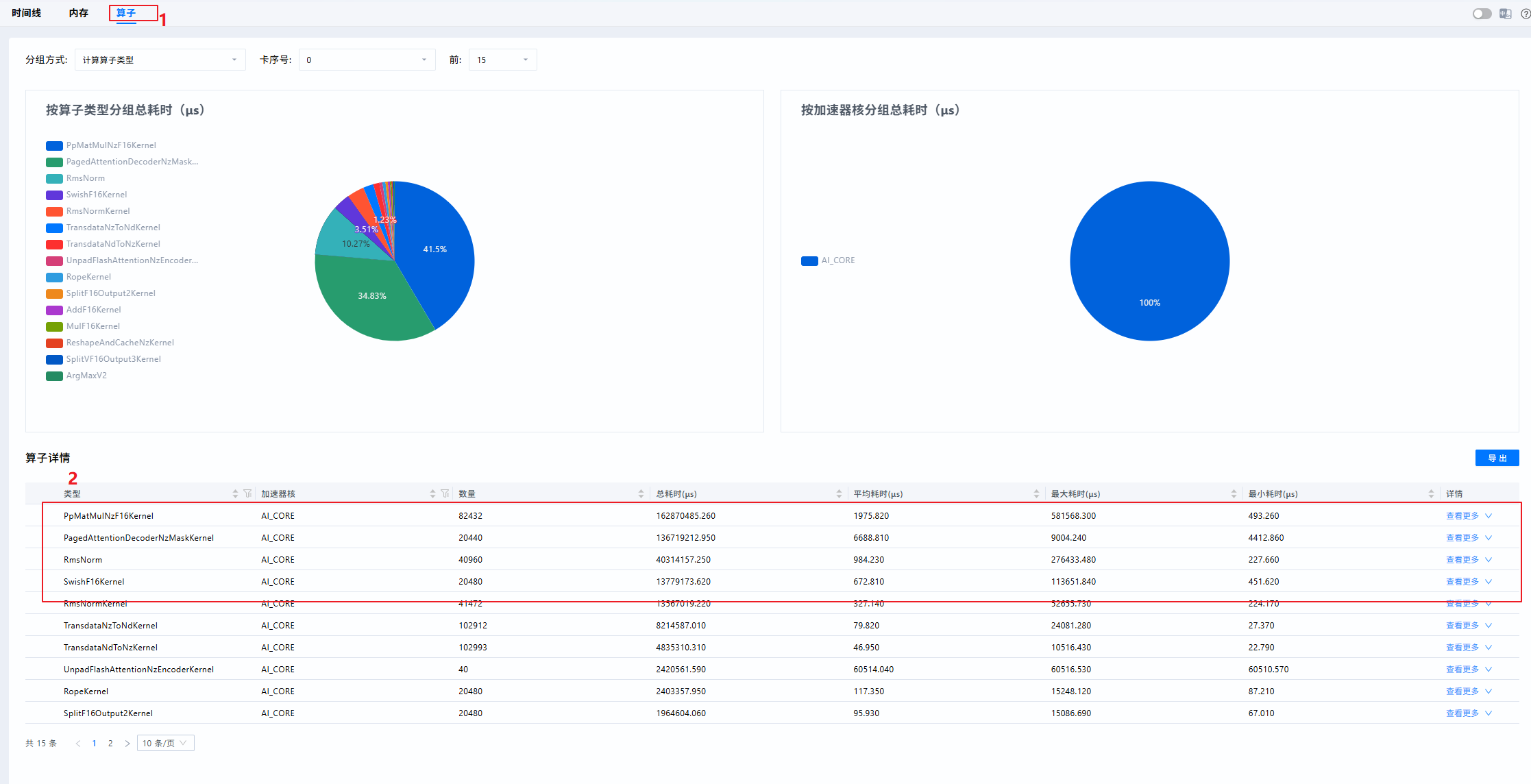
- 找出Top耗时算子,查看Operator页签
通信问题分析
通信优化参考链接
- 通信问题表现1:通信时长远大于计算
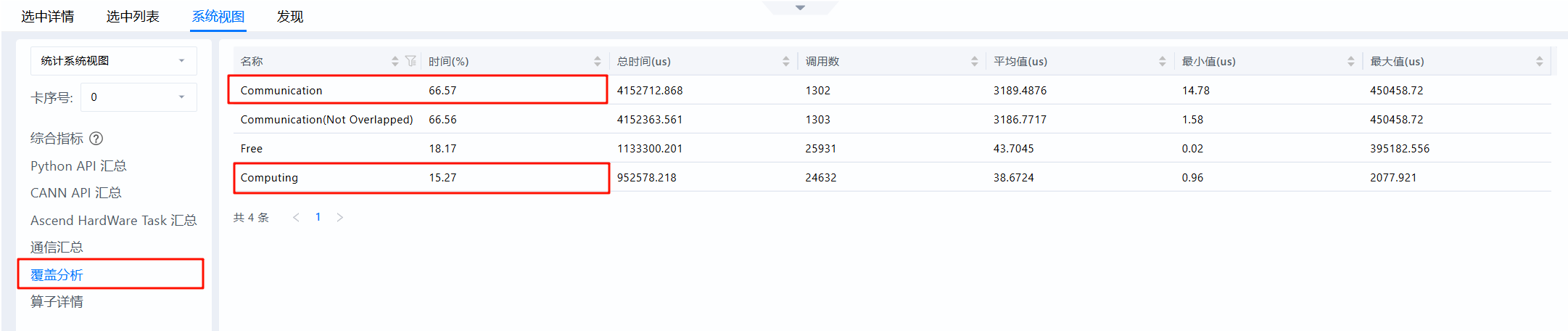
- 通信问题表现2:存在明显超长时间的通信算子
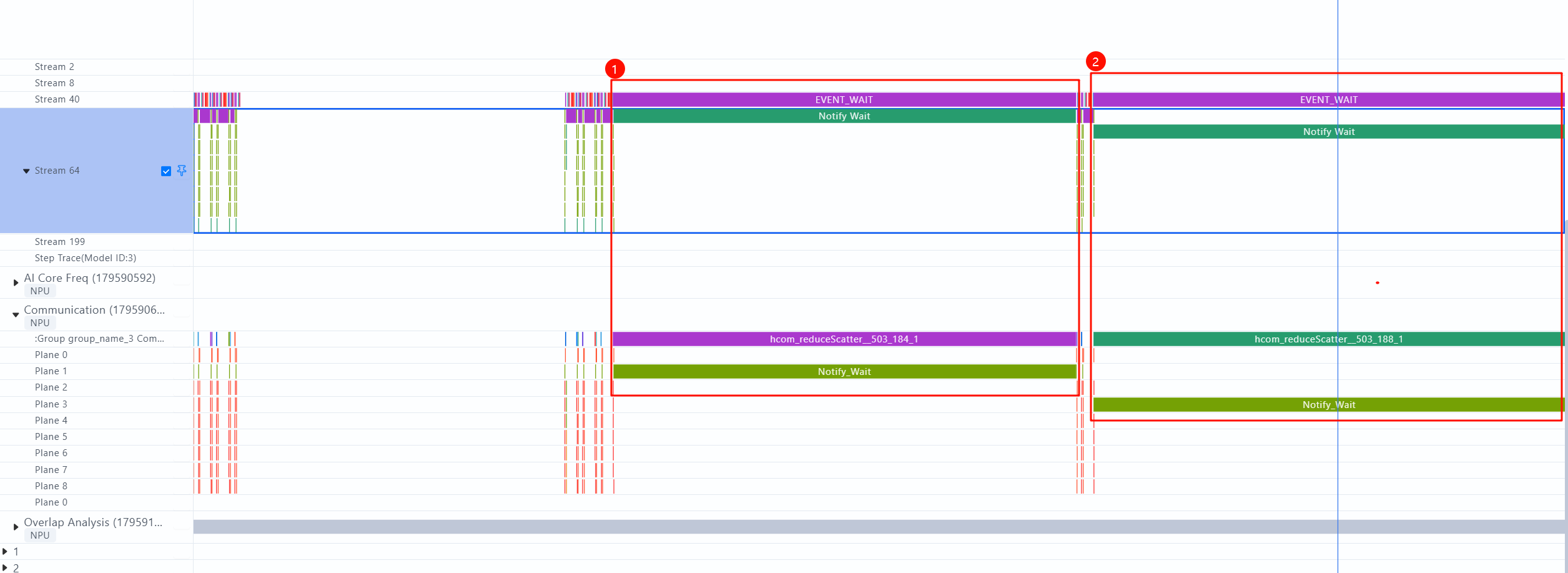
PTA提供的通信优化方法:链接
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)