论文精读:《FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking》
本文详细解读 FairMOT 如何利用 Anchor-free 架构、DLA-34 特征融合以及低维 Re-ID 特征,成功打破这一瓶颈 。它不仅在 MOT17 等各大榜单霸榜,更在 RTX 2080Ti 上实现了 30 FPS 的实时推理 。从理论痛点到工程细节,带你彻底读懂这一 MOT 领域的里程碑工作。
文章目录
论文基本信息
- 论文标题:FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
- 中文标题:FairMOT:论多目标跟踪中检测与重识别的公平性
- 作者团队:
- 第一作者:Yifu Zhang (华中科技大学)
- 通讯/共同作者:Chunyu Wang (微软亚洲研究院 MSRA), Xinggang Wang (华中科技大学), Wenjun Zeng (MSRA), Wenyu Liu (华中科技大学)
- 发表/来源:该文档显示为 arXiv 版本(2021年10月 v6) 。
- 开源代码:GitHub - FairMOT
Abstract
- 背景与痛点 (The Conflict)
原文片段:
“Formulating MOT as multi-task learning… is appealing… However, we find that the two tasks tend to compete with each other… previous works usually treat re-ID as a secondary task… the network is biased to the primary detection task which is not fair to the re-ID task.”
-
核心矛盾:MOT 被建模为多任务学习(Multi-task Learning),即在一个网络中同时做检测(Detection)和重识别(Re-ID)。
-
深度解读:
- 检测任务希望忽略个体差异(只要是人,特征都要相似,以便归为“人”这一类)。
- Re-ID任务希望放大个体差异(即使都是人,A和B的特征必须截然不同)。
- 这就是特征层面的根本冲突。
-
“Unfairness” (不公平):这是论文题目的由来。以前的方法(如 JDE, TrackR-CNN)通常是 Anchor-based 的。它们必须先通过 Anchor 检出框(Detection is Primary),再从框里抠图做 Re-ID(Re-ID is Secondary)。
- 如果框不准,Re-ID 特征就废了。
- 训练时,网络会优先把 Detection 的 Loss 降下来,导致 Re-ID 分支学得不好。这就是所谓的“Bias(偏见)”和“Not Fair” 。
- 解决方案 (The Solution)
原文片段:
“To solve the problem, we present a simple yet effective approach termed as FairMOT based on the anchor-free object detection architecture CenterNet.”
- 破局点:Anchor-free。
- 核心架构:CenterNet。
- 为什么是 CenterNet?
- CenterNet 将目标视为一个点(Point),而不是一个框(Box)。
- 在 FairMOT 中,它在预测目标中心点热图(Heatmap)的同时,直接在中心点所在的像素提取 Re-ID 特征。
- 这样,检测和 Re-ID 就变成了并行的、地位平等的任务(Pixel-to-pixel alignment),消除了先后依赖关系,实现了“公平”。
- 强调与成果 (Nuance & Results)
原文片段:
“Note that it is not a naive combination of CenterNet and re-ID. Instead, we present a bunch of detailed designs… The approach outperforms the state-of-the-art methods by a large margin…”
- 声明:作者特意强调“这不是简单的 CenterNet + Re-ID 拼凑” 。
- 这意味着论文的贡献不仅是换了个架构,还在于工程细节(Detailed designs)。这些细节包括:DLA-34 骨干网的改进、多层特征融合、以及低维 Re-ID 特征(64/128维 vs 512维)的选择。
- SOTA:在多个数据集上大幅超越(Large margin)当时的 SOTA。
1 Introduction
- 背景:两阶段方法的困境 (The Two-Step Dilemma)
多目标跟踪(MOT)的核心目标是估计视频中感兴趣目标的轨迹。传统的、也是最主流的方法通常采用 “Tracking-by-Detection”(检测加跟踪) 的两阶段模式:
- 检测模型(Detection Model):首先在每一帧中画出目标的边界框(Bounding Box)。
- 关联模型(Association Model):然后从这些边界框对应的图像区域中提取重识别(Re-ID)特征,根据特征的相似度将当前帧的检测结果链接到已有的轨迹上。
存在的问题:
虽然随着目标检测(如 Faster R-CNN, YOLO)和 Re-ID 技术的进步,这种方法的精度很高,但它面临严重的可扩展性问题(Scalability issues)。
- 速度瓶颈:两个模型不共享特征,Re-ID 模型需要对视频中的每一个边界框独立运行。
- 无法实时:当环境中目标数量庞大时,推理速度会显著下降,无法满足实时应用的需求。
- 尝试:早期的单阶段(One-Shot)探索
为了解决速度问题,学术界开始引入多任务学习(Multi-task Learning),即 One-Shot Trackers。这类方法尝试在一个网络中同时完成“目标检测”和“Re-ID 特征提取”。
- 典型代表:JDE, Track R-CNN。
- 优势:通过共享 Backbone 特征,大幅减少了推理时间。
- 新问题:虽然速度上去了,但性能却显著下降,尤其是 ID 切换(ID Switches)的数量大幅增加。
关键发现:作者观察到一个有趣的现象——在这些早期的 One-Shot 方法中,检测精度通常保持得不错,但跟踪性能却崩了。这说明简单地将两个任务结合并非易事,两者之间存在深层的冲突。
- 核心洞察:三大“不公平”因素 (The 3 Unfairness Issues)
作者剖析了导致 One-Shot 方法失败的三个根本原因,并将其总结为任务之间的“竞争”与“不公平”:
(1) Anchor 导致的不公平 (Unfairness caused by Anchors)
目前的 One-Shot 方法大多基于 Anchor-based 的检测器(如 Faster R-CNN),这带来了两个致命问题:
- 地位不平等:这类框架是“检测优先,Re-ID 次之”。必须先通过 Anchor 预测出框,再基于框提取特征。如果框不准,Re-ID 特征就是废的。训练时网络会偏向于优化检测任务,导致 Re-ID 任务被忽视。
- 特征歧义(Ambiguity):
- 一对多:一个 Anchor 可能覆盖了多个目标(拥挤场景)或包含大量背景,导致提取的特征不纯。
- 多对一:为了提高召回率,通常会有多个相邻的 Anchor 负责预测同一个目标,这导致不同的图像 Patch 被强行要求映射到同一个 ID,给训练带来干扰。
(2) 特征冲突 (Feature Conflict)
检测和 Re-ID 是两个本质完全不同的任务:
- 检测:需要高层语义特征,要求同一类物体(都是人)的特征尽可能相似。
- Re-ID:需要低层外观特征,要求同一类物体(不同的人)的特征必须可区分。
在 One-Shot 框架中强行共享特征,会导致特征冲突,进而损害两个任务的性能。
(3) 特征维度的不匹配 (Feature Dimension)
- 传统的 Re-ID 特征维度很高(512 或 1024 维)。
- 作者发现,在 One-Shot 框架中,过高的 Re-ID 维度会伤害检测精度。
- 新发现:在 MOT 任务中,学习低维特征不仅能提升推理速度,反而能获得更好的跟踪精度。这是之前被该领域忽视的一个重要差异。
- FairMOT (The Solution)
针对上述问题,作者提出了 FairMOT。这不是 CenterNet 和 Re-ID 的简单拼凑,而是经过深思熟虑的设计:
- 架构基础:基于 Anchor-free 的 CenterNet 架构。
- 公平性设计:
- 完全消除 Anchor,检测分支预测物体中心热图,Re-ID 分支直接预测中心像素点的特征。
- 两个分支是**完全同质(Homogeneous)**且并行的,没有级联依赖关系,消除了“检测优先”的偏见。
- 像素级特征:Re-ID 特征直接从像素点提取,避免了 Anchor 带来的区域歧义。
2 Related Work
- 两阶段方法:精度虽高,速度难以为继
(Detection and Tracking by Separate Models)
这是 MOT 领域最传统、也是长期以来的主流范式。它的核心思想是分而治之:先用一个模型把所有目标检出来(Detection),再用另一个模型把它们连起来(Association)。
-
检测部分 (Detection Methods):
- 通常直接使用现成的强力检测器,如 Faster R-CNN 或 Cascade R-CNN。
- 为了公平比较,MOT 榜单(如 MOT17)通常提供统一的公共检测结果(Public Detections),但也有许多方法(Private Detections)通过在大规模私有数据集上训练检测器来刷榜。
-
跟踪部分 (Tracking Methods):根据关联线索的不同,又细分为两类:
- 基于位置和运动线索 (Location and Motion Cues):
- 代表作:SORT (卡尔曼滤波 + 匈牙利算法) 和 IOU-Tracker。
- 特点:速度极快(甚至可达 100K FPS),但这仅限于检测时间不计入的情况。
- 局限:在拥挤场景或快速运动下容易失效,且无法处理长时间遮挡(无法重找回)。
- 基于外观线索 (Appearance Cues):
- 代表作:DeepSORT。
- 做法:从检测框中抠图(Crop),送入一个独立的 Re-ID 网络提取特征,再计算相似度。
- 优势:抗遮挡能力强,能找回丢失的目标。
- 改进:后续工作引入了更复杂的特征(如人体姿态)或关联策略(如 RNN, Group Models)。
- 基于位置和运动线索 (Location and Motion Cues):
-
离线方法 (Offline Methods):
- 利用整个视频序列的信息进行全局优化(如图模型、最小费用流),精度通常比在线方法更高,但不适用于实时流媒体应用。
-
总结:两阶段方法的最大优势是各司其职,检测和 Re-ID 都可以做到最优,且可以通过 Resize 抠图解决尺度变化问题,因此长期霸榜。最大劣势是慢,两个模型串行计算且无法共享特征,难以达到视频实时帧率。
- 单阶段方法:追求速度,但遭遇瓶颈
(Detection and Tracking by a Single Model)
为了解决速度问题,研究者开始探索 One-Shot(单阶段) 框架,即用一个网络同时搞定检测和跟踪。随着多任务学习的成熟,这一方向逐渐火热。
作者将现有的单阶段方法分为两类:
-
联合检测与 Re-ID (Joint Detection and Re-ID):
- 代表作:Track R-CNN (Mask R-CNN + Re-ID head), JDE (YOLOv3 + Re-ID)。
- 思路:在检测网络的 Head 部分加一个分支输出 Re-ID 特征。
- 现状:速度快了(接近实时),但精度崩了。相比两阶段方法,ID Switches 激增。这正是 FairMOT 要解决的核心痛点。
-
联合检测与运动预测 (Joint Detection and Motion Prediction):
- 代表作:Tracktor, CenterTrack, Chained-Tracker。
- 思路:输入两帧图像,网络直接输出目标的**位移(Displacement)**或关联框。
- 局限:这类方法虽然不需要 Re-ID 特征,但通常只能关联相邻两帧。一旦目标被遮挡或丢失,由于缺乏身份特征(Appearance Features),很难再找回来。
-
FairMOT 的定位:
- 属于第一类(联合检测与 Re-ID)。
- 相比 CenterTrack:FairMOT 能提取长时 Re-ID 特征,具备找回丢失目标的能力。
- 相比 CSTrack(同期工作):CSTrack 试图通过 Cross-correlation 模块缓解特征冲突,而 FairMOT 则是从架构设计(Anchor-free)和特征维度入手,更系统地解决了不公平问题。
- 视频目标检测:相关但不同
(Video Object Detection, VOD)
这一小节简要提及了 VOD 领域。虽然 VOD 的目标是提高检测框的质量(利用时序信息增强单帧检测),而不是生成轨迹,但其中的一些思想(如 Tubelets, Seq-NMS)对 MOT 也有启发。不过,这些方法通常极其缓慢,难以直接用于实时 MOT。
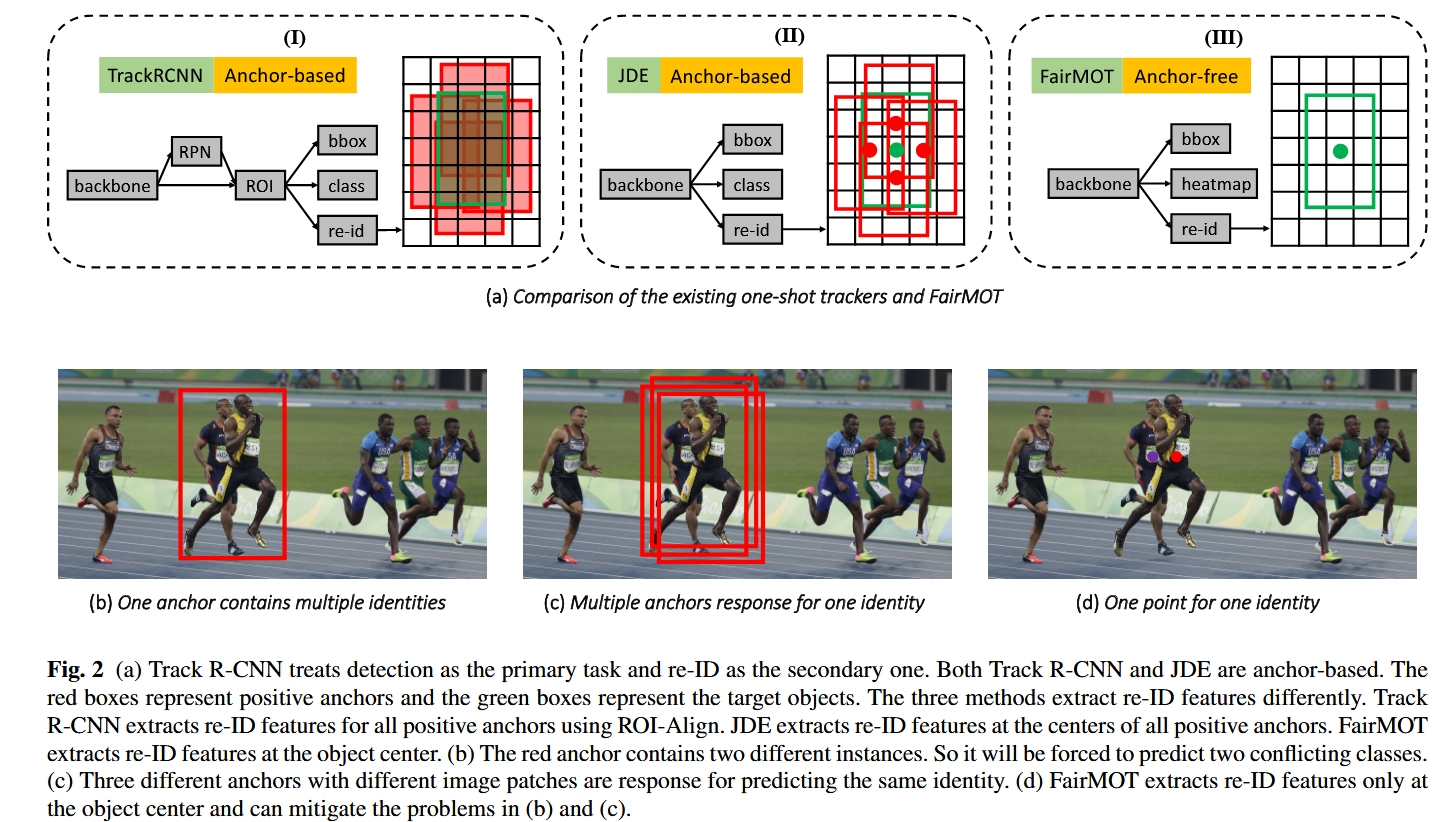
3 Unfairness Issues in One-shot Trackers
3.1 锚框导致的不公平 (Unfairness Caused by Anchors)
目前的 One-Shot 跟踪器大多继承自 YOLO 或 Mask R-CNN,它们都是 Anchor-based(基于锚框) 的。作者指出,Anchor 机制天生就不适合学习 Re-ID 特征,主要有三个罪状:
(1) 被忽视的 Re-ID 任务 (Overlooked re-ID task)
- 机制问题:像 Track R-CNN 这种级联架构,必须先预测出框(Proposal),再从框里通过 ROI-Pooling 提取 Re-ID 特征。
- 恶性循环:Re-ID 特征的质量完全依赖于框的准确性。如果框不准,抠出来的特征就是废的。
- 训练偏差:在训练阶段,网络会优先“照顾”检测任务(先把框弄准),导致 Re-ID 分支被边缘化。这种“检测是主子,Re-ID 是仆人”的设计,使得 Re-ID 无法得到公平的训练。
(2) 一个 Anchor 对应多个 ID (One anchor corresponds to multiple identities)
- 采样污染:Anchor-based 方法通常使用
ROI-Align提取特征。但在拥挤场景下,一个 Anchor 的感受野往往很大,可能同时框住了目标人物、背景甚至干扰物(其他人)。 - 后果:提取出的特征变得“不纯”,无法精确代表目标,导致特征鉴别力下降。
- 解决方案预告:作者发现,直接提取**目标中心点(Single Point)**的特征,比提取整个区域的特征要好得多。
(3) 多个 Anchor 对应一个 ID (Multiple anchors correspond to one identity)
- 歧义性 (Ambiguity):在训练中,为了保证召回率,只要 IOU 够大,会有多个相邻的 Anchor(对应图像上略有不同的 Patch)被强行指派去预测同一个 ID。
- 矛盾:这意味着网络看到不同的输入(不同的图像区域),却被要求输出相同的 ID 标签。这给训练引入了严重的混乱。
- 对齐问题:此外,Anchor 检测器通常经过 8倍、16倍甚至 32倍的下采样。对于 Re-ID 这种需要精细特征的任务来说,这种粒度太粗糙了,特征中心很难与物体中心对齐。
3.2 特征冲突导致的不公平 (Unfairness Caused by Features)
One-Shot 跟踪器最大的卖点是“共享特征”,但这恰恰也是痛点:
- 检测任务 (Detection):需要深层、抽象的语义特征。它希望忽略个体差异(不管是穿红衣还是蓝衣,只要是人,特征都要相似)。
- Re-ID 任务 (Re-ID):需要浅层、具体的外观特征。它必须放大个体差异(区分不同的人)。
在多任务优化中,这两个目标由于梯度方向不一致,会产生严重的冲突。如果不加设计地强行共享,通常会导致两个任务相互拖累。
3.3 特征维度导致的不公平 (Unfairness Caused by Feature Dimension)
这部分提出了一个反直觉的观点:Re-ID 特征维度不是越高越好。
传统 Re-ID 任务(如行人重识别比赛)通常使用 512 或 1024 维的特征,但作者发现 低维特征(如 64 或 128 维) 对 One-Shot MOT 更好,原因有三:
- 竞争资源:高维 Re-ID 特征意味着 Re-ID 分支参数量巨大,这会抢占检测任务的学习资源,导致检测精度下降,进而拖累跟踪效果。
- 任务本质不同:
- 标准 Re-ID:是全局检索任务(在巨大的 Gallery 里找人),需要极高容量的特征。
- MOT:是局部匹配任务(只在相邻帧的几十个人里做匹配)。这是一个“小规模”的分类问题,不需要那么高维的特征。
- 推理速度:低维特征计算更快,这对实时跟踪至关重要。
4 FairMOT
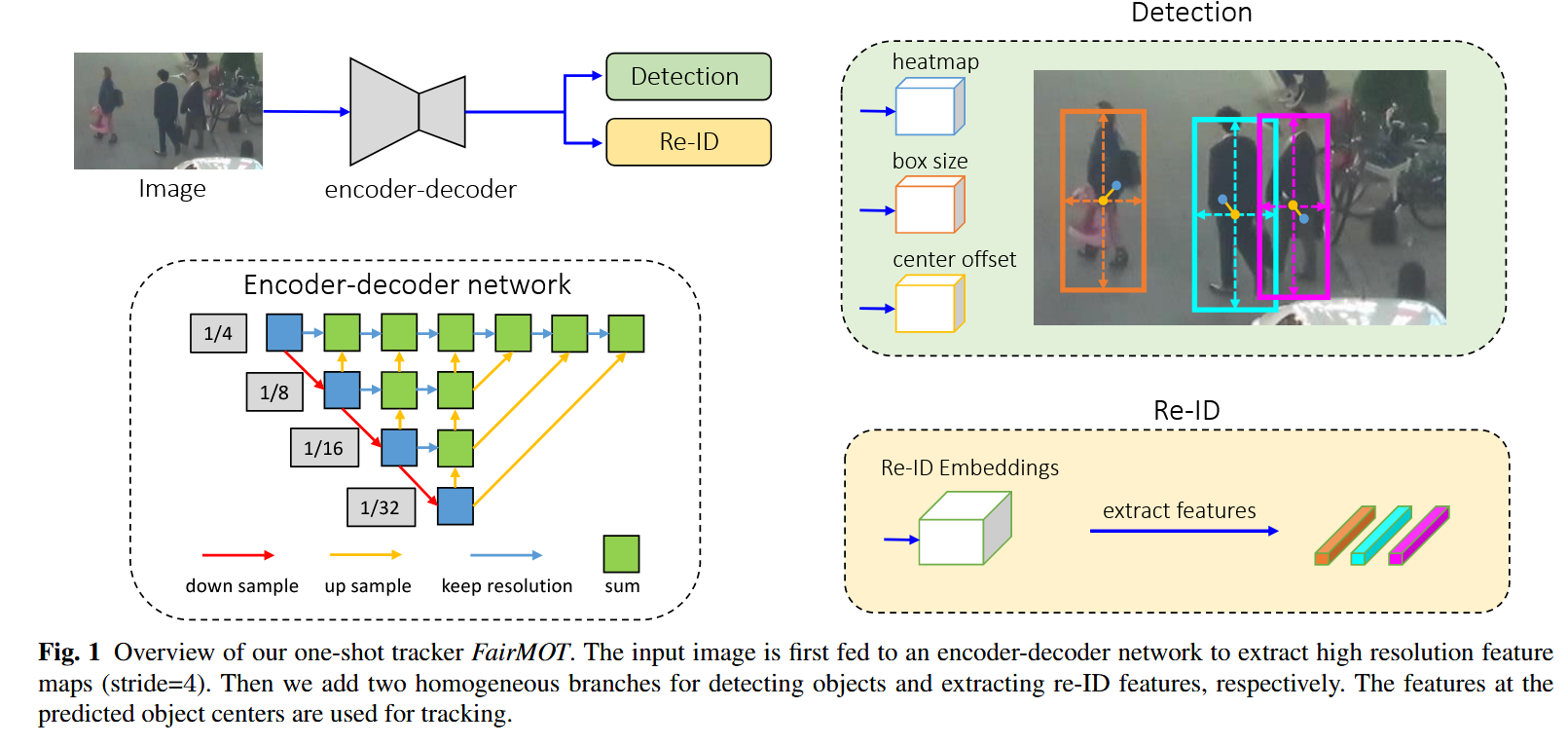
4.1 骨干网络 (Backbone Network)
选择理由:
作者选择了 ResNet-34 作为基础,并使用了 Deep Layer Aggregation (DLA) 进行增强,以此平衡速度(34层不算深)和精度(通过 DLA 增强特征)。
核心改进点 (Modified DLA-34):
- 多层特征融合:这与 FPN (Feature Pyramid Network) 类似,在低层特征(细节丰富)和高层特征(语义丰富)之间增加了更多的 Skip Connections(跳跃连接)。这对 Re-ID 任务至关重要,因为 Re-ID 需要低层纹理信息。
- 可变形卷积 (Deformable Convolution):将所有上采样模块中的普通卷积替换为可变形卷积。
- 作用:普通的卷积核是矩形的,而行人姿态各异。可变形卷积能根据目标的形状动态调整感受野,解决“特征对齐”问题(即特征点能更准确地落在物体中心)。
结构特点: 这是一种树状的聚合结构。绿色方块是聚合节点,它们负责将不同层级的特征融合在一起 。
-
增强的跳跃连接 (Enhanced Skip Connections): 文中提到,不同于原始的 DLA,FairMOT 增加了更多低层与高层特征之间的跳跃连接,这类似于 FPN (Feature Pyramid Network) 。
-
看图理解:你可以看到底部的 1/32 蓝色块,通过黄色箭头(Up sample)一路向上连接,最终汇聚到最顶层的 1/4 绿色块。
-
目的:这样做可以让最终输出的特征图(最右上角的绿色块)既包含 1/32 的深层语义信息(利于判断“是不是人”),又包含 1/4 的浅层纹理信息(利于判断“是哪个人”)。这种多层融合直接缓解了检测和 Re-ID 的特征冲突 。
输入输出:
- 输入:图像 H i m a g e × W i m a g e H_{image} \times W_{image} Himage×Wimage
- 输出:特征图 C × H × W C \times H \times W C×H×W,其中 H = H i m a g e / 4 H = H_{image}/4 H=Himage/4, W = W i m a g e / 4 W = W_{image}/4 W=Wimage/4。
- Stride = 4:下采样倍率为 4,意味着特征图分辨率较高,有利于小目标检测。
4.2 检测分支 (Detection Branch)
FairMOT 的检测头基于 CenterNet,它是 Anchor-free 的。检测部分包含三个并行的 Head(每个 Head 都是 3 × 3 3 \times 3 3×3 卷积 + 1 × 1 1 \times 1 1×1 卷积):
4.2.1 热图分支 (Heatmap Head)
功能:预测物体中心点的位置。
输出维度: 1 × H × W 1 \times H \times W 1×H×W(因为只有“人”这一类,所以通道数为 1)。如果是多类别检测,通道数就是类别数 C。
公式解析:真实热图生成 (Ground Truth Generation)
M x y = ∑ i = 1 N exp − ( x − c ~ x i ) 2 + ( y − c ~ y i ) 2 2 σ c 2 M_{xy} = \sum_{i=1}^{N} \exp^{-\frac{(x-\tilde{c}_{x}^{i})^2+(y-\tilde{c}_{y}^{i})^2}{2\sigma_{c}^{2}}} Mxy=i=1∑Nexp−2σc2(x−c~xi)2+(y−c~yi)2
- M x y M_{xy} Mxy:坐标 ( x , y ) (x, y) (x,y) 处的热图响应值(范围 0~1)。
- ( c ~ x i , c ~ y i ) (\tilde{c}_{x}^{i}, \tilde{c}_{y}^{i}) (c~xi,c~yi):第 i i i 个物体在特征图上的真实中心坐标。计算方式是先求原图中心,再除以 4 并取整: ( ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ ) (\lfloor \frac{c_x^i}{4} \rfloor, \lfloor \frac{c_y^i}{4} \rfloor) (⌊4cxi⌋,⌊4cyi⌋)。
- σ c \sigma_c σc:标准差,控制高斯圆的大小,与目标框的大小自适应相关。
- 含义:我们在特征图上,以每个物体的中心为圆心,生成一个高斯圆。中心点值为 1,越往外值越小。这就是我们要让网络学习的目标。
公式解析:热图损失函数 (Focal Loss)
L h e a t = − 1 N ∑ x y { ( 1 − M ^ x y ) α log ( M ^ x y ) , if M x y = 1 ( 1 − M x y ) β ( M ^ x y ) α log ( 1 − M ^ x y ) , otherwise ( 1 ) L_{heat} = -\frac{1}{N} \sum_{xy} \begin{cases} (1 - \hat{M}_{xy})^\alpha \log(\hat{M}_{xy}), & \text{if } M_{xy}=1 \\ (1 - M_{xy})^\beta (\hat{M}_{xy})^\alpha \log(1 - \hat{M}_{xy}), & \text{otherwise} \end{cases} \quad (1) Lheat=−N1xy∑{(1−M^xy)αlog(M^xy),(1−Mxy)β(M^xy)αlog(1−M^xy),if Mxy=1otherwise(1)
- 这是修改版的 Focal Loss,用于解决正负样本极度不平衡的问题(一张图上中心点很少,背景点很多)。
- M ^ x y \hat{M}_{xy} M^xy:网络预测的热图值。
- M x y = 1 M_{xy}=1 Mxy=1 (正样本/中心点):对应第一行公式。如果预测 M ^ \hat{M} M^ 接近 1,Loss 就很小;如果预测接近 0,Loss 很大。 ( 1 − M ^ ) α (1 - \hat{M})^\alpha (1−M^)α 是权重项,预测越准权重越小。
- Otherwise (负样本/背景点):对应第二行公式。
- ( 1 − M x y ) β (1-M_{xy})^\beta (1−Mxy)β:这是 CenterNet 特有的改进。对于靠近中心点的那些“负样本”(高斯圆边缘的点),它们其实离中心很近,我们希望惩罚得轻一点。 M x y M_{xy} Mxy 越大(越靠近中心),这一项越小,Loss 权重越低。
- ( M ^ x y ) α (\hat{M}_{xy})^\alpha (M^xy)α:标准的 Focal Loss 权重,压制简单负样本。
4.2.2 框偏移与尺寸分支 (Box Offset and Size Heads)
由于特征图下采样了 4 倍,直接映射回原图会有最大 4 像素的量化误差。
公式解析:Box Loss ( L 1 L_1 L1 Loss)
L b o x = ∑ i = 1 N ∥ o i − o ^ i ∥ 1 + λ s ∥ s i − s ^ i ∥ 1 ( 2 ) L_{box} = \sum_{i=1}^{N} \|o^i - \hat{o}^i\|_1 + \lambda_s \|s^i - \hat{s}^i\|_1 \quad (2) Lbox=i=1∑N∥oi−o^i∥1+λs∥si−s^i∥1(2)
- 这一项包含了两个任务的 Loss,使用 L 1 L_1 L1 距离(绝对值误差)。
- Offset Loss ( ∥ o i − o ^ i ∥ 1 \|o^i - \hat{o}^i\|_1 ∥oi−o^i∥1):
- o i = ( c x 4 , c y 4 ) − ( ⌊ c x 4 ⌋ , ⌊ c y 4 ⌋ ) o^i = (\frac{c_x}{4}, \frac{c_y}{4}) - (\lfloor \frac{c_x}{4} \rfloor, \lfloor \frac{c_y}{4} \rfloor) oi=(4cx,4cy)−(⌊4cx⌋,⌊4cy⌋)。即“精确坐标”减去“整数坐标”,算的是小数点后的偏差。
- o ^ i \hat{o}^i o^i:网络预测的偏移量。
- Size Loss ( ∥ s i − s ^ i ∥ 1 \|s^i - \hat{s}^i\|_1 ∥si−s^i∥1):
- s i s^i si:真实框的宽和高 (Width, Height)。
- s ^ i \hat{s}^i s^i:网络预测的宽和高。
- λ s \lambda_s λs:权重系数,设为 0.1。
4.3 Re-ID 分支 (Re-ID Branch)
这是 FairMOT 的核心创新点:将 Re-ID 视为一个并行的分支,而不是检测后的步骤。
- 结构:通过一层卷积(128个卷积核)提取特征图 E ∈ R 128 × H × W E \in \mathbb{R}^{128 \times H \times W} E∈R128×H×W。
- 提取方式:对于每个目标,直接提取其中心坐标 ( c ~ x , c ~ y ) (\tilde{c}_x, \tilde{c}_y) (c~x,c~y) 处的 128 维特征向量。
公式解析:Re-ID 损失函数 (Softmax Classification Loss)
L i d e n t i t y = − ∑ i = 1 N ∑ k = 1 K L i ( k ) log ( p ( k ) ) ( 3 ) L_{identity} = - \sum_{i=1}^{N} \sum_{k=1}^{K} L^i(k) \log(p(k)) \quad (3) Lidentity=−i=1∑Nk=1∑KLi(k)log(p(k))(3)
- 这是一个标准的分类交叉熵损失 (Cross Entropy Loss)。
- K K K:训练集中所有行人的总 ID 数量(比如 MOT17 可能有几千个不同的 ID)。
- p ( k ) p(k) p(k):网络预测当前物体属于第 k k k 个 ID 的概率(通过全连接层 + Softmax 得到)。
- L i ( k ) L^i(k) Li(k):One-hot 标签。如果第 i i i 个物体是 ID k k k,则为 1,否则为 0。
- 核心思想:训练时,把 Re-ID 当作一个分类问题。只有位于物体中心位置的特征向量参与训练,其他位置的特征向量被忽略。这避免了 Anchor 带来的模糊性。
4.4 联合训练 (Training FairMOT)
将检测和 Re-ID 的 Loss 加在一起进行端到端训练。为了避免手动调参的麻烦,作者使用了不确定性加权 (Uncertainty Weighting) 的策略。
公式解析:自动加权 Loss
L d e t e c t i o n = L h e a t + L b o x ( 4 ) L_{detection} = L_{heat} + L_{box} \quad (4) Ldetection=Lheat+Lbox(4)
L t o t a l = 1 2 ( 1 e w 1 L d e t e c t i o n + 1 e w 2 L i d e n t i t y + w 1 + w 2 ) ( 5 ) L_{total} = \frac{1}{2} (\frac{1}{e^{w_1}} L_{detection} + \frac{1}{e^{w_2}} L_{identity} + w_1 + w_2) \quad (5) Ltotal=21(ew11Ldetection+ew21Lidentity+w1+w2)(5)
- 原理:这是 Kendall 等人在 CVPR 2018 提出的多任务学习策略。
- w 1 , w 2 w_1, w_2 w1,w2:是可学习的参数(Learnable Parameters),不需要人工设定。
- 解释:
- e w e^{w} ew 相当于任务的方差(不确定性)。
- 如果某个任务很难(Loss 很大,不确定性高),网络会自动增大 w w w(即增大分母 e w e^w ew),从而降低该任务 Loss 的权重,防止它主导梯度。
- 后面的 + w 1 + w 2 +w_1 +w_2 +w1+w2 是正则项,防止网络为了降低 Loss 直接把 w w w 设成无穷大。
4.5 在线推理 (Online Inference)
4.5.1 网络推理
- 输入图像 1088 × 608 1088 \times 608 1088×608。
- 通过 Heatmap Head 得到热图,进行 3 × 3 3 \times 3 3×3 Max Pooling(相当于 NMS)提取峰值点作为检测到的物体中心。
- 根据 Size 和 Offset Head 恢复出边界框。
- 直接读取这些中心点坐标在 Re-ID 特征图上的 128 维向量,作为该目标的身份特征。
4.5.2 在线关联 (Online Association)
采用类似 DeepSORT 的级联匹配策略:
-
第一级匹配 (Kalman + Re-ID):
- 使用卡尔曼滤波预测上一帧轨迹在当前帧的位置。
- 计算融合距离 D D D:
D = λ D r + ( 1 − λ ) D m D = \lambda D_r + (1 - \lambda) D_m D=λDr+(1−λ)Dm- D r D_r Dr:Re-ID 特征的余弦距离(Cosine Distance)。
- D m D_m Dm:位置的马氏距离(Mahalanobis Distance)。
- λ = 0.98 \lambda = 0.98 λ=0.98:说明主要依赖 Re-ID 特征,位置只是辅助。这体现了 FairMOT Re-ID 特征的强大。
- 使用匈牙利算法进行匹配(阈值 τ 1 = 0.4 \tau_1 = 0.4 τ1=0.4)。
-
第二级匹配 (IoU):
- 对于第一级没匹配上的,仅使用 IoU(交并比) 进行补救匹配(阈值 τ 2 = 0.5 \tau_2 = 0.5 τ2=0.5)。处理那些特征模糊但位置重叠度高的目标。
-
轨迹管理:
- 更新匹配成功的轨迹特征(平滑更新)。
- 未匹配的检测初始化为新轨迹。
- 丢失的轨迹保留 30 帧,如果还没找回来就删除。
好的,我们现在进入实验部分。FairMOT 的实验设计非常扎实,它不仅证明了方法在 SOTA 榜单上的有效性,更通过详尽的消融实验(Ablation Studies) 验证了前文提到的“三个不公平”假设。
为了方便你在博客中呈现,我将实验部分精炼为三个核心验证维度,对应之前的理论分析。
5 Experiments
- 验证核心假设:为什么 Anchor-free 更好?
(Section 5.3.1: Anchors)
这是最直接回应 Section 3.1 中“Anchor 导致不公平”的实验。作者对比了三种提取 Re-ID 特征的方式:
- ROI-Align (Track R-CNN 方式):先出框,再在框内做 ROI-Align 采样特征。
- POS-Anchor (JDE 方式):在正样本 Anchor 的中心提取特征。
- Center (FairMOT 方式):在目标中心点提取特征。
实验结果 (Table 1):
- Center (FairMOT) 取得了最高的 IDF1 (72.8%) 和 TPR (94.4%)。
- 核心结论:Center 方式显著优于 ROI-Align 和 POS-Anchor。这证明了 Center 提取的特征更纯净,因为它避开了 Anchor 带来的背景噪声和多义性问题。IDF1 指标的大幅提升直接说明了 Re-ID 质量的改善。
- 验证特征冲突:多层特征融合与低维特征
(Section 5.3.3 & 5.3.4)
这部分回应了 Section 3.2 和 3.3 关于特征冲突和维度的讨论。
(1) 骨干网络与特征融合 (Backbone & Feature Fusion)
作者对比了 ResNet-34, ResNet-50, HRNet 以及 DLA-34 等骨干网络。
实验结果 (Table 3):
- 大不一定好:直接把 ResNet-34 换成更强的 ResNet-50,MOTA 几乎没涨,ID Switches 甚至还变多了。这说明单纯加深网络并不能解决特征冲突。
- 融合才是关键:DLA-34 (带有深浅层特征融合) 效果最好。这验证了 Multi-layer Feature Fusion 对于缓解检测(深层)和 Re-ID(浅层)的冲突至关重要。
- 可变形卷积:如果不加可变形卷积,DLA-34 的性能会暴跌。这再次证明了对于 Center-based 方法,特征对齐是多么重要。
(2) 特征维度 (Feature Dimension)
作者对比了 512 维和 64 维特征。
实验结果 (Table 6):
- 低维更好:对于 FairMOT,降低维度(从 512 到 64)虽然 TPR 略微下降,但 MOTA 提升了,且 AP (检测精度) 也提升了。
- 核心结论:低维特征减少了 Re-ID 分支对检测分支的资源抢占(缓解了冲突),同时也加快了推理速度。在 MOT 这种小规模匹配任务中,低维特征完全够用。
- 验证训练策略:数据与Loss平衡
(Section 5.3.2 & 5.4)
(1) Loss 平衡 (Balancing Losses)
作者对比了固定权重、GradNorm、MGDA-UB 和 Uncertainty Loss。
实验结果 (Table 2):
- Uncertainty Loss 取得了最好的综合效果。
- 固定权重 虽然检测(AP)最高,但 ID Switches 很多,说明模型偏向检测,忽视了 Re-ID(不公平)。
- 这证明了使用自动加权 Loss 可以有效地动态平衡两个竞争任务。
(2) 单图训练 (Single Image Training)
这是一个非常实用的发现。MOT 数据集通常很小,标注很贵。作者提出利用 CrowdHuman 这种只有框、没有 ID 标注的检测数据集来进行自监督预训练。
做法:把一张静态图片看作一个视频帧,把里面的每个框看作一个独立的类别(ID)。
实验结果 (Table 8):
- 即使只用单图预训练(没有真实视频序列),效果也能达到 64.1 MOTA。
- 如果加上 CrowdHuman 预训练再微调,效果直接起飞。这证明了 FairMOT 的数据利用效率极高。
- 与 SOTA 的终极对决
(Section 5.5)
作者在 MOT15, MOT16, MOT17, MOT20 四大榜单上与当时所有的 SOTA 方法进行了对比。
实验结果 (Table 9 & 10):
- 全榜第一:FairMOT 在所有数据集上均排名第一,且大幅领先。
- 速度与激情:不仅精度最高,而且在 RTX 2080Ti 上达到了 30 FPS(加上检测和关联的全流程时间)。
- 碾压 JDE:相比于之前的 One-Shot 代表作 JDE,FairMOT 的 ID Switches 从 218 降到了 80,体验上有质的飞跃。
6 Summary and Future Work
- 问题溯源:Anchor 是“万恶之源”
(The Root Cause)
论文的出发点非常明确:为什么之前的 One-Shot 方法(如 JDE)打不过两阶段方法?
作者再次强调,经过深入研究,发现 Anchor(锚框)机制 是导致性能下降的罪魁祸首。
- 核心矛盾:在 Anchor-based 的逻辑里,可能会有多个相邻的 Anchor(对应物体不同部位)被强制要求预测同一个 ID。这在训练中引入了巨大的歧义(Ambiguity),导致 Re-ID 特征学不清楚。
- 连带问题:除了 Anchor,还有**特征冲突(Feature Unfairness)和特征维度(Feature Dimension)**的不匹配问题。
- 解决方案:FairMOT 的胜利
(The Solution & Result)
针对上述问题,作者提出了 FairMOT,一个基于 Anchor-free 架构的单阶段网络。
- 设计哲学:通过消除 Anchor、融合深浅层特征、降低 Re-ID 维度,FairMOT 实现了检测与 Re-ID 任务的公平(Fairness)。
- 最终战绩:在多个基准数据集上,不仅**跟踪精度(Accuracy)大幅超越了当时的 SOTA,而且推理速度(Inference Speed)**也遥遥领先。这证明了“简单 + 公平”的设计思路是正确的。
- 实际价值:数据效率与单图训练
(Practical Value)
这一部分提到了一个对工业界非常有吸引力的点:数据效率(Data Efficiency)。
- 痛点:MOT 数据集(带 ID 标注的视频)非常难制作,标注成本极高。
- 创新:FairMOT 提出了一种**单图训练(Single Image Training)**策略。它允许模型在只有检测框标注(没有 ID 关联信息)的静态图片数据集(如 CrowdHuman)上进行训练。
- 意义:这意味着在实际应用中,我们可以利用海量的现成检测数据来训练跟踪器,极大地降低了落地门槛,让 FairMOT 在现实世界(Real Applications)中更具吸引力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)