【代码实战】基于 LangChain 与 GLM-4 构建 RAG 应用:技术原理与实现指南
本文介绍了如何利用RAG(检索增强生成)技术解决大模型"幻觉"和知识库过时问题。通过LangChain框架、智谱AI(GLM-4)和Chroma数据库搭建私有知识问答助手,实现类似"开卷考试"的智能问答。主要步骤包括:1)准备API密钥;2)构建项目目录结构;3)配置环境参数;4)加载和向量化数据;5)封装RAG服务核心逻辑;6)实现用户交互界面。该系统能有
在大模型(LLM)时代,我们经常遇到一个痛点:“一本正经地胡说八道”(幻觉)以及“知识库过时”。
比如,你问ChatGPT:“我公司今天的午餐补贴政策是什么?”它肯定答不上来,因为这些数据不在它的训练集里。
解决这个问题的最佳方案就是 RAG(Retrieval-Augmented Generation,检索增强生成)。
本文后附代码,使用 LangChain 框架 + 智谱AI (GLM-4) + 轻量级数据库 Chroma,搭建一个私有知识问答助手。
那么,什么是 RAG?
想象你在参加一场闭卷考试(传统大模型),你只能靠脑子里的记忆(训练数据)回答问题。如果题目超纲,你可能就会乱编。
而 RAG 就是让你带一本参考书(你的私有数据)进考场。
-
检索 (Retrieval):看到题目,先翻书找到相关段落。
-
增强 (Augmented):把题目和找到的段落一起交给大脑。
-
生成 (Generation):大脑根据书上的内容,组织语言回答问题。
准备
zhipuai:智谱AI的官方SDK。
你需要去 智谱AI开放平台 申请一个 API Key。

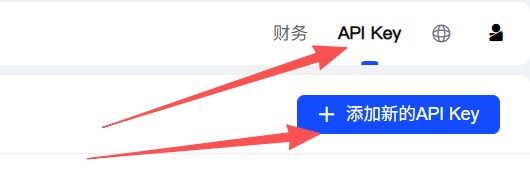
代码实战
请在你的工作区创建文件夹 rag_project,并在其中创建以下文件:
rag_project/
├── .env # 存放敏感配置(API Key)
├── config.py # 配置加载模块
├── data_ingestion.py # 数据清洗与向量化脚本
├── rag_service.py # RAG 核心检索与生成逻辑
├── main.py # 主程序入口
└── requirements.txt # 依赖清单
1. requirements.txt
langchain>=0.3.0
langchain-community
langchain-chroma
zhipuai
python-dotenv
chromadb
2. .env 点不要忽略
ZHIPUAI_API_KEY=你的_ZHIPUAI_API_KEY_粘贴在这里
3. 配置模块 (config.py)
用于统一管理配置项,便于后续切换模型或路径。
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
# 加载 .env 文件
load_dotenv()
# 项目根目录定位
BASE_DIR = Path(__file__).resolve().parent
DATA_DIR = BASE_DIR / "data"
DB_DIR = BASE_DIR / "chroma_db"
# 确保目录存在
DATA_DIR.mkdir(exist_ok=True)
DB_DIR.mkdir(exist_ok=True)
# API 配置
ZHIPUAI_API_KEY = os.getenv("ZHIPUAI_API_KEY")
if not ZHIPUAI_API_KEY:
print("错误:未在 .env 文件中找到 ZHIPUAI_API_KEY")
sys.exit(1)
# 模型参数配置
EMBEDDING_MODEL = "embedding-2"
LLM_MODEL = "glm-4"
4. 数据入库脚本 (data_ingestion.py)
加载原始数据,切分文本,计算向量,并持久化存储到磁盘。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_community.embeddings import ZhipuAIEmbeddings
from config import ZHIPUAI_API_KEY, DB_DIR, DATA_DIR, EMBEDDING_MODEL
def create_dummy_data():
"""生成模拟的业务数据文件"""
file_path = DATA_DIR / "policy.txt"
content = """
【差旅报销制度】
1. 住宿费:一线城市(北上广深)上限 600元/天,其他城市 400元/天。
2. 交通费:市内交通实报实销,严禁使用专车服务,仅限网约车或出租车。
3. 审批流:总金额超过 2000 元需部门总监审批。
"""
# 使用 utf-8 写入,防止乱码
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
print(f"已生成模拟数据: {file_path}")
return str(file_path)
def ingest_documents(file_path: str):
"""核心入库逻辑:加载 -> 切分 -> 向量化 -> 存储"""
print("开始构建向量数据库...")
# 1. 加载
loader = TextLoader(file_path, encoding="utf-8")
docs = loader.load()
# 2. 切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20
)
splits = text_splitter.split_documents(docs)
# 3. 向量化与存储
# persist_directory 指定了数据存放在硬盘的位置,重启后依然可用
embedding = ZhipuAIEmbeddings(
model=EMBEDDING_MODEL,
api_key=ZHIPUAI_API_KEY
)
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=str(DB_DIR)
)
print(f"数据入库成功!共存储 {len(splits)} 个片段。")
print(f"数据库路径: {DB_DIR}")
if __name__ == "__main__":
# 独立运行时执行数据构建
txt_path = create_dummy_data()
ingest_documents(txt_path)
5. RAG 业务服务 (rag_service.py)
将 RAG 逻辑封装为一个类 RAGBot。这种写法方便后续集成。
from typing import List
from langchain_chroma import Chroma
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from config import ZHIPUAI_API_KEY, DB_DIR, LLM_MODEL, EMBEDDING_MODEL
class RAGBot:
def __init__(self):
"""初始化资源:连接向量库,加载大模型"""
self.embedding = ZhipuAIEmbeddings(
model=EMBEDDING_MODEL,
api_key=ZHIPUAI_API_KEY
)
# 加载已持久化的向量数据库
self.vectorstore = Chroma(
persist_directory=str(DB_DIR),
embedding_function=self.embedding
)
self.retriever = self.vectorstore.as_retriever(
search_kwargs={"k": 2} # 检索 Top 2 相关片段
)
self.llm = ChatZhipuAI(
model=LLM_MODEL,
temperature=0.01,
api_key=ZHIPUAI_API_KEY
)
# 构建处理链
self.chain = self._build_chain()
def _build_chain(self):
template = """基于以下【参考资料】回答问题。严禁编造。
【参考资料】:
{context}
问题: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
return (
{"context": self.retriever | self._format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
@staticmethod
def _format_docs(docs: List) -> str:
return "\n\n".join(doc.page_content for doc in docs)
def chat(self, query: str) -> str:
"""对外暴露的问答接口"""
if not query:
return "请输入有效问题。"
return self.chain.invoke(query)
6. 主程序入口 (main.py)
这是用户交互的入口,负责串联各个模块。
import sys
from pathlib import Path
from config import DB_DIR
from data_ingestion import create_dummy_data, ingest_documents
from rag_service import RAGBot
def main():
# 1. 检查数据库是否存在,不存在则初始化
# Chroma 会在目录下生成 .sqlite3 文件,以此判断
if not any(DB_DIR.iterdir()):
print("检测到首次运行,正在初始化知识库...")
txt_path = create_dummy_data()
ingest_documents(txt_path)
else:
print("检测到现有知识库,直接加载。")
# 2. 实例化机器人
try:
bot = RAGBot()
except Exception as e:
print(f"初始化失败: {e}")
return
# 3. 进入交互循环
print("\n RAG 助手已就绪 (输入 'quit' 退出)")
print("-" * 30)
while True:
query = input("\n用户: ").strip()
if query.lower() in ["quit", "exit"]:
break
if not query:
continue
print("RAG正在思考...", end="", flush=True)
response = bot.chat(query)
print(f"\r助手: {response}")
if __name__ == "__main__":
main()
如何运行
-
安装依赖:
pip install -r requirements.txt -
配置 Key: 在
.env文件中填入你的 Key。 -
运行程序:
python main.py
总结
恭喜你!你刚刚完成了一个最小可行性的 RAG 系统。
这个 Demo 虽然简单,但它就是现在许多企业级 AI 知识库的底层逻辑。你可以尝试把 txt 换成更复杂的 PDF,或者调整 Prompt,打造更适合你的专属助手!
创作不易,点个赞或关注支持一下博主吧!!!谢谢~
我还在github上写了一个稍微复杂,但更为完整的RAG流程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)