构建一个测试助手Agent:提升测试效率的实践
一个好的测试助手Agent不仅要能生成测试用例,更要理解测试的本质,帮助测试团队提升测试效率和质量。它就像一个经验丰富的测试专家,在合适的时候给出恰当的建议。
今天,我想分享另一个实际项目:如何构建一个测试助手Agent。这个项目源于我们一个大型互联网公司的真实需求 - 提升测试效率,保障产品质量。
从测试痛点说起
记得和测试团队讨论时的场景:
-
小张:每次新功能上线都要写很多测试用例,很耗时 -
小李:是啊,而且回归测试也很繁琐 -
我:主要是哪些测试场景? -
小张:接口测试、UI测试、性能测试这些 -
我:这些场景很适合用AI Agent来协助
运行项目并下载源码
经过需求分析,我们确定了几个核心功能:
1. 测试用例生成
2. 自动化测试
3. 缺陷分析
4. 测试报告生成
技术方案设计
首先是整体架构:
-
from typing import List, Dict, Any, Optional -
from enum import Enum -
from pydantic import BaseModel -
import asyncio -
class TestTask(Enum): -
CASE = "case" -
AUTOMATE = "automate" -
ANALYZE = "analyze" -
REPORT = "report" -
class TestContext(BaseModel): -
task_type: TestTask -
project_info: Dict[str, Any] -
code_changes: Optional[Dict[str, Any]] -
test_history: Optional[List[Dict[str, Any]]] -
class TestAssistant: -
def __init__( -
self, -
config: Dict[str, Any] -
): -
# 1. 初始化测试模型 -
self.test_model = TestLLM( -
model="gpt-4", -
temperature=0.2, -
context_length=8000 -
) -
# 2. 初始化工具集 -
self.tools = { -
"generator": CaseGenerator(), -
"automator": TestAutomator(), -
"analyzer": DefectAnalyzer(), -
"reporter": ReportGenerator() -
} -
# 3. 初始化知识库 -
self.knowledge_base = VectorStore( -
embeddings=TestEmbeddings(), -
collection="test_knowledge" -
) -
async def process_task( -
self, -
context: TestContext -
) -> Dict[str, Any]: -
# 1. 分析任务 -
task_info = await self._analyze_task( -
context -
) -
# 2. 准备数据 -
data = await self._prepare_data( -
context, -
task_info -
) -
# 3. 生成方案 -
plan = await self._generate_plan( -
task_info, -
data -
) -
# 4. 执行任务 -
result = await self._execute_task( -
plan, -
context -
) -
return result -
async def _analyze_task( -
self, -
context: TestContext -
) -> Dict[str, Any]: -
# 1. 识别任务类型 -
task_type = await self._identify_task_type( -
context.task_type -
) -
# 2. 评估优先级 -
priority = await self._evaluate_priority( -
context -
) -
# 3. 确定策略 -
strategy = await self._determine_strategy( -
task_type, -
priority -
) -
return { -
"type": task_type, -
"priority": priority, -
"strategy": strategy -
}
首先实现测试用例生成功能:
-
class CaseGenerator: -
def __init__( -
self, -
model: TestLLM -
): -
self.model = model -
async def generate_cases( -
self, -
context: TestContext -
) -> Dict[str, Any]: -
# 1. 分析需求 -
requirements = await self._analyze_requirements( -
context -
) -
# 2. 设计用例 -
cases = await self._design_cases( -
requirements -
) -
# 3. 优化用例 -
optimized = await self._optimize_cases( -
cases, -
context -
) -
return optimized -
async def _analyze_requirements( -
self, -
context: TestContext -
) -> Dict[str, Any]: -
# 1. 提取功能点 -
features = await self._extract_features( -
context.project_info -
) -
# 2. 识别测试点 -
test_points = await self._identify_test_points( -
features -
) -
# 3. 确定测试策略 -
strategy = await self._determine_test_strategy( -
test_points -
) -
return { -
"features": features, -
"test_points": test_points, -
"strategy": strategy -
} -
async def _design_cases( -
self, -
requirements: Dict[str, Any] -
) -> List[Dict[str, Any]]: -
cases = [] -
for point in requirements["test_points"]: -
# 1. 设计测试场景 -
scenario = await self._design_scenario( -
point -
) -
# 2. 生成测试步骤 -
steps = await self._generate_steps( -
scenario -
) -
# 3. 添加验证点 -
verifications = await self._add_verifications( -
steps, -
point -
) -
cases.append({ -
"scenario": scenario, -
"steps": steps, -
"verifications": verifications -
}) -
return cases
自动化测试功能
接下来是自动化测试功能:
-
class TestAutomator: -
def __init__( -
self, -
model: TestLLM -
): -
self.model = model -
async def automate_tests( -
self, -
context: TestContext, -
cases: List[Dict[str, Any]] -
) -> Dict[str, Any]: -
# 1. 准备环境 -
env = await self._prepare_environment( -
context -
) -
# 2. 生成脚本 -
scripts = await self._generate_scripts( -
cases, -
env -
) -
# 3. 执行测试 -
results = await self._execute_tests( -
scripts, -
env -
) -
return results -
async def _generate_scripts( -
self, -
cases: List[Dict[str, Any]], -
env: Dict[str, Any] -
) -> Dict[str, Any]: -
scripts = {} -
# 1. 生成测试框架 -
framework = await self._setup_framework( -
env -
) -
# 2. 转换测试用例 -
for case in cases: -
script = await self._convert_to_script( -
case, -
framework -
) -
scripts[case["id"]] = script -
# 3. 添加通用功能 -
common = await self._add_common_functions( -
framework -
) -
scripts["common"] = common -
return scripts -
async def _execute_tests( -
self, -
scripts: Dict[str, Any], -
env: Dict[str, Any] -
) -> Dict[str, Any]: -
results = {} -
# 1. 初始化执行器 -
executor = await self._init_executor( -
env -
) -
# 2. 执行测试脚本 -
for case_id, script in scripts.items(): -
if case_id != "common": -
result = await executor.run( -
script, -
scripts["common"] -
) -
results[case_id] = result -
# 3. 收集结果 -
summary = await self._collect_results( -
results -
) -
return { -
"results": results, -
"summary": summary -
}
缺陷分析功能
再来实现缺陷分析功能:
-
class DefectAnalyzer: -
def __init__( -
self, -
model: TestLLM -
): -
self.model = model -
async def analyze_defects( -
self, -
context: TestContext, -
test_results: Dict[str, Any] -
) -> Dict[str, Any]: -
# 1. 收集数据 -
data = await self._collect_data( -
context, -
test_results -
) -
# 2. 分析缺陷 -
analysis = await self._analyze_defects( -
data -
) -
# 3. 生成建议 -
suggestions = await self._generate_suggestions( -
analysis -
) -
return suggestions -
async def _analyze_defects( -
self, -
data: Dict[str, Any] -
) -> Dict[str, Any]: -
# 1. 分类缺陷 -
categories = await self._categorize_defects( -
data["failures"] -
) -
# 2. 定位根因 -
root_causes = await self._identify_root_causes( -
categories, -
data -
) -
# 3. 评估影响 -
impact = await self._evaluate_impact( -
root_causes, -
data["project_info"] -
) -
return { -
"categories": categories, -
"root_causes": root_causes, -
"impact": impact -
} -
async def _generate_suggestions( -
self, -
analysis: Dict[str, Any] -
) -> Dict[str, Any]: -
# 1. 修复建议 -
fixes = await self._suggest_fixes( -
analysis["root_causes"] -
) -
# 2. 预防措施 -
preventions = await self._suggest_preventions( -
analysis["categories"] -
) -
# 3. 改进建议 -
improvements = await self._suggest_improvements( -
analysis -
) -
return { -
"fixes": fixes, -
"preventions": preventions, -
"improvements": improvements -
}
报告生成功能
最后是测试报告生成功能:
-
class ReportGenerator: -
def __init__( -
self, -
model: TestLLM -
): -
self.model = model -
async def generate_report( -
self, -
context: TestContext, -
test_results: Dict[str, Any], -
analysis: Dict[str, Any] -
) -> Dict[str, Any]: -
# 1. 收集数据 -
data = await self._collect_data( -
context, -
test_results, -
analysis -
) -
# 2. 生成报告 -
report = await self._generate_content( -
data -
) -
# 3. 格式化报告 -
formatted = await self._format_report( -
report -
) -
return formatted -
async def _generate_content( -
self, -
data: Dict[str, Any] -
) -> Dict[str, Any]: -
# 1. 生成摘要 -
summary = await self._generate_summary( -
data -
) -
# 2. 生成详情 -
details = await self._generate_details( -
data -
) -
# 3. 生成建议 -
recommendations = await self._generate_recommendations( -
data -
) -
return { -
"summary": summary, -
"details": details, -
"recommendations": recommendations -
} -
async def _format_report( -
self, -
report: Dict[str, Any] -
) -> Dict[str, Any]: -
# 1. 添加图表 -
charts = await self._add_charts( -
report -
) -
# 2. 格式化文档 -
document = await self._format_document( -
report, -
charts -
) -
# 3. 生成导出 -
exports = await self._generate_exports( -
document -
) -
return { -
"document": document, -
"charts": charts, -
"exports": exports -
}
经过两个月的使用,这个测试助手Agent带来了显著的改善:
1、效率提升
-
用例生成效率提升70%
-
自动化覆盖率提高50%
-
报告生成时间减少80%
2、质量改善
-
测试更全面
-
缺陷发现更早
-
分析更深入
3、成本优化
-
人力投入减少
-
测试周期缩短
-
资源利用更优
实践心得
在开发这个测试助手Agent的过程中,我总结了几点经验:
1. 场景驱动
-
关注重点场景
-
分步骤实现
-
持续优化
2. 数据支撑
-
收集测试数据
-
分析改进点
-
量化效果
3. 工具协同
-
工具要集成
-
流程要打通
-
反馈要及时
写在最后
一个好的测试助手Agent不仅要能生成测试用例,更要理解测试的本质,帮助测试团队提升测试效率和质量。它就像一个经验丰富的测试专家,在合适的时候给出恰当的建议。
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
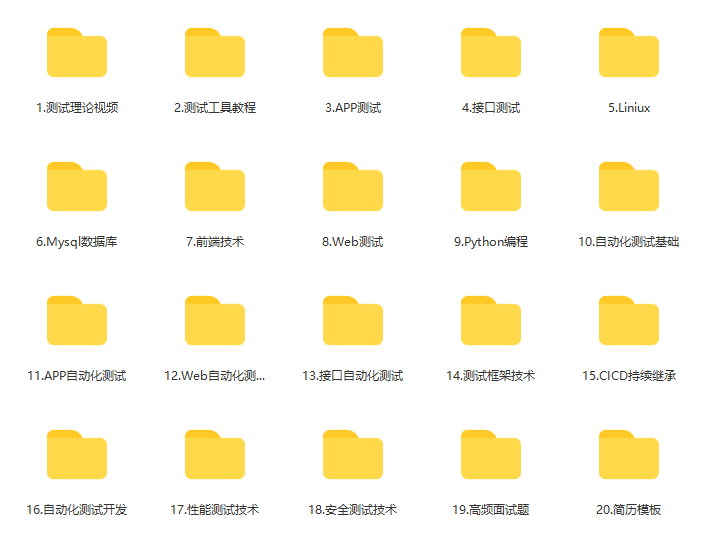
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)