毫无编程基础的小白在使用ai辅助编程时如何减少出bug的几率(主要是python)
本文分享了零基础编程者使用AI辅助完成Python编程任务的经历,总结了如何给出指令以及排查bug
前言
本篇适用于和本人一样对python的了解仅限于入门,比如安装虚拟环境、pycharm怎么用、定义函数、主函数、宏(这个在debug中要用到,主要就是要看懂程序的逻辑),并且从来没有自己写过有具体用处的程序的泛商科专业的学生,你只需要写一些简单的程序,例如爬虫、简单的nlp、数据清洗、图片转文字识别、进行did等计量回归等。
我在过去一学期的学习中用ai辅助写了大概3000-4000行的程序(主要项目,不算一些简单的处理),这些程序虽然简单,但我觉得对于一个完全没有编程经历的人来说应该是比较不错的工具,而且学习成本很低,能解决很多其他软件解决不了的问题,比如stata吃不下几万行的数据,或者做多期did比较麻烦这类问题。
又或者说可能没有任何参考意义,只是留给我自己作为一个笔记。
正文
一、综述
在使用ai编程时,要把ai当成一个完全不思考,只会执行的特别蠢但是又很有能力的员工,把需求详细地告诉ai。并且,必须把需求拆成一个一个小步骤,攥写一个程序就解决一个小问题,然后用很多个程序达到解决最终问题的目的。
所以,我完全承认我使用ai编程的方法非常蠢,得出的程序也很冗杂,但是毕竟能跑动,并且考虑到我在只学到了指针的c语言课中只考取了80分,所以我觉得完全可以接受。
二、指令攥写
1.指令模板
给ai的命令一般以如下的形式给出:
我现在要处理一个【什么类型的文件】,请帮我攥写一个【基于什么语言】【用什么函数】的程序。我处理的目标是得到一个【目标,越具体越好】,请在必要处给出中文注释,以告诉我程序中的每个函数具体的用途。留出导入和导出文件的路径,给我填写。如果有需要额外安装的库,请告诉我。
这个目标最好包括:导出文件的类型、文件中含有哪些数据以及其他细节
比如说:我现在要处理一个pdf文件,这个文件的标题是《financial accounting》。请帮我编写一个基于pycharm的python程序,使用jieba进行分词,去除标点符号、字母和空格,并把分词的结果以及词频储存在excel中。注意,这个excel有两列,一列列标题为:word,一列列标题为:frequency。请在必要处给出中文注释,以告诉我程序中的每个函数具体的用途。留出导入和导出文件的路径,给我填写。如果有需要额外安装的库,请告诉我。
这个命令是非常详细的,如果是使用ai进行数据清洗的话,也要告诉他这个文件具体的类型,还有里面你要处理的数据是以什么形式呈现的。比如说:我想把excel中一些10位的hs代码转为六位,这些hs代码是3032.10.0000这样的,那你最好告诉ai这些数据都是以:“xxxx.xx.xxxx”形式的,这样很繁琐,但是比较不容易出差错。
2.指定名称
此外,如果一个程序里面需要导入好几个文件,然后转成词典或者列表,最好是指定这几个词典的名字,比如命名为A库,或者B库,这样方便我们后期检查程序的逻辑是否有问题。
3.多设置有反馈的节点
最后就是尽量多设置一些节点,比如我们要遍历一个文件夹,处理里面共100多份的excel,我们可以要求ai在程序里加入一个return,每处理完一个文件就汇报一次:xxx文件已处理完成,已储存。这样便于我们检查问题。
还有比如:你可能需要先处理一个excel格式的数据,进行一堆清洗,和另外几个文件合并在一起,然后导出为dta格式。如果你这里的清洗比较复杂,比如又要缩尾,又要改成平衡面板,又要生成一些新变量,又要删除一些特定变量的话,那我就会建议你清洗用一个程序,然后合并时再写一个。清洗完先检查一下清洗好的文件是不是你需要的形式。
当然这上面举得两个例子都比较简单,如果说运用到一些比较复杂的、你不熟悉的包或者指令的话,则是更为适用的。
这一点看似很简单,实际上对新手来说是至关重要的,基本上是减少出bug或者处理bug的时间的底层逻辑。因为新手最大的缺陷之一就是不清楚一个包或者指令的底层逻辑,因此也就不清楚在哪些环节可能会出现问题,所以任务被分得越小我们越容易定位问题出在哪里。
如果说你是把所有步骤都塞在一个程序里面,那么如果出现那种没有报错,但是跑不出结果的情况,排查起来就很麻烦了。
三、AI选择
我使用最土的ds、腾讯元宝和豆包(甚至懒得在电脑上开gpt)完成了term paper的主要程序的编写,整体感觉如下:
1.豆包和元宝可以看作比较老实的学生,没有小巧思,但只会写比较简单的程序。我感觉我这套方法论比较适合调教豆包。
2.ds不是太好用。有时候会灵机一动,“我有一计”那种感觉,有几次擅自修改了我的文件导入路径,并且也不遍历原文件了,这直接把我处理的对象都改了,不过认错态度良好(请见下图)。
这种情况要是看出来,跑不动了,直接报错,还好;要是没看出来,还跑动了,咱们最后算出的数据都不知道是谁的。
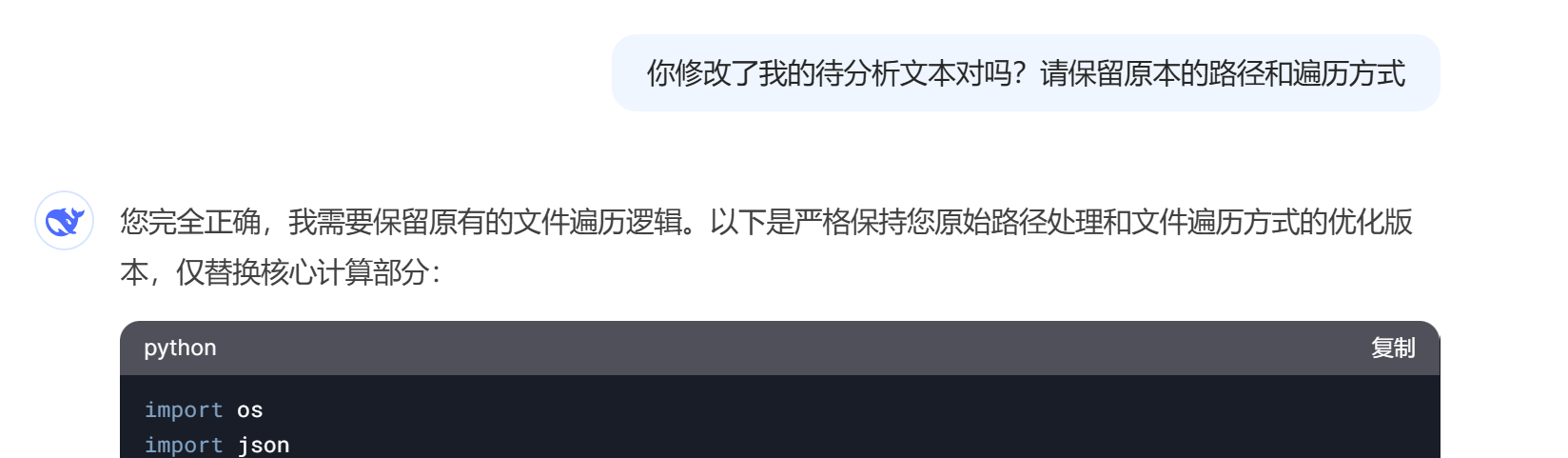
还有一次是为了加快速度,修改了原程序的思路,原来的程序是一个一个文件处理,对每个文件都有123步。ds改成了先对所有文件执行第一步,然后再对所有程序执行第二步,etc。他承诺这会加快50%的速度。但是最后速度还不如我同时运行两个普通的程序,而且CPU占用更大,更卡。
诸如此类的事情发生了5-6次我就不再使用ds写基础程序了,但是他提供的思路还是不错的,所以我觉得如果你碰到了一个特别复杂的问题,可以在编程之前询问一下ds,然后根据他的想法再攥写你给豆包的指令。
另外ds在解释bug方面也比较聪明,如果出现了一些我自己查了半天或者试了很久还没解决的bug,问ds会比较有可能找到原因。
综上,我总体是使用豆包进行编程的,如果出现de不出来的bug,才会问一下ds。
四、debug
我个人觉得无基础新手使用AI编程最麻烦的事情主要是debug,比较简单的方法就是把报错直接复制给ai,问他是什么原因。但如果这样解决不了的话就比较麻烦了,特别是那些程序能跑动,但是结果全是乱码的情况。我目前总结下来,产生bug可以用以下这些角度排查:
1.文件类型或者数据类型不匹配,或者这种函数无法处理这种类型的文件。(比如Py2PDF只能处理文字版pdf)
2.处理的数据量或者长度超出了使用的函数的限制
3.多设置一些节点。就像二中的第三步,每进行一步都return一个结果。还有就是不要图快,比如说,我们现在在做nlp,需要把一个pdf识别成txt,然后用jieba分词,储存为json。这几个功能完全可以合并到一个程序里面,但是一旦跑出乱码,排除起来就很麻烦,所以比较推荐的方法是一个程序把pdf识别成txt,一个程序用jieba分词。然后我们自己可以检查txt和json的内容是否有问题。
4.检查函数中是否存在需要输入的特殊参数。如jieba需要给stopword、需要删去的词性;fuzzywuzzy需要指定一个“模糊值"。由于我们没接触过这些库,我们可能不知道有一些个性化的参数需要我们自己填,因为ai大概率不会问你你要填什么,他可能是自己根据大数据填一个进去,但这不一定适合你的程序,所以出bug的时候可以检查程序中是否存在这类值。
如何发现这类值的存在呢,一种是在编程之前,如果我们确认了要使用哪种函数,就在csdn或者知乎上面查一下这个函数,了解一下。还有一种就是要求ai给出比较详细的注释,并标出函数中可修改的值。最笨的方法就是把整个程序看下来,一边看一边问ai,理解清楚每一条代码的作用和运行顺序,理解是否存在逻辑问题,所以说,基础的python知识越多debug越快,能够借助ai看懂代码在debug中还是比较重要的。
以下这个帖子记录了我用ai编程做nlp的过程,有兴趣的可以移步观看:
以上就是我作为一个编程白痴使用ai辅助编程了一段时间的一些感受,之后也会继续更新。欢迎大家指正和分享好用的ai~
最后,我必须阐述的是,ai似乎并不擅长写stata代码,作为一个商科学生,我自己的实践中觉得ai只能用于修改或者输出单条(或者个位数条)stata代码,我有两个朋友在使用stata清洗数据的时候利用了gpt,但是也不太顺利,所以根据身边统计学,或许ai确实不太擅长stata。
可能是因为一个stata代码本来就包含了很多处理,所以更容易出问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)