【论文笔记•(医学)】AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
AutoMedEval:基于语言模型的医疗能力自动评估系统 为解决医疗大语言模型评估中传统指标不足、人工成本高等问题,研究者提出AutoMedEval开源评估模型。该系统通过构建高质量医疗指令数据集(经医生双重验证,保留9569条有效数据)和分层训练方法(课程指令微调+迭代知识内省),实现专业评估能力。实验表明,AutoMedEval在评估准确性和人类判断相关性上超越GPT-4等模型,如Accur
【论文笔记•(医学)】AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
1 一句话总结
为解决医疗领域大语言模型(LLMs)评估难题 —— 传统 metrics(如 F1、ROUGE)忽视医疗术语重要性、人工评估成本高且依赖专业知识、现有 LLM 评估方法因私有性或缺乏专业度受限,Zhang 等研究者提出AutoMedEval:一款 13B 参数的开源自动评估模型,通过构建经医生双重验证的高质量医疗指令数据集(基于 medical-meadow-wikidoc 等数据集,最终保留 9569 条有效数据),采用分层训练方法(含课程指令微调与迭代知识内省),实现对医疗 LLMs 问答能力的评估。实验表明,AutoMedEval 在与人类判断的相关性上超越 GPT-4、Gemini 等闭源模型及 Vicuna、PandaLM 等开源模型,如在 Accuracy₂₋tuple 指标上相对 PandaLM 提升 10.9%,且在双盲偏好实验中更受医疗专业人员认可。
2 论文基本信息

🏫单位:华东师范大学
🔖会议:ACL 2025
⏰阅读时间:2025.11.17
😀论文地址:[2505.11887] AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
🔭代码:
3 研究的核心问题和背景
3.1 核心问题
当前面临的核心问题就是评估大模型的指标无法全面反映医学水平,而使用人工评估的方法开销又十分巨大。
3.2 背景
- 当前大模型的能力提升非常快,评估的指标也要随之提升。然而现有的指标像 F 1 和 Rouge 这样的传统指标依靠令牌重叠来衡量质量,严重忽视了医学术语的重要性。
- 人类评估虽然有效,但是非常昂贵。
4 框架及具体实现
4.1 核心方案
AutoMedEval 是一款13B 参数的开源自动评估模型,专门用于评估医疗 LLMs 的问答能力,核心包括 “高质量指令数据集构建” 与 “分层训练方法” 两部分。
4.2 具体实现
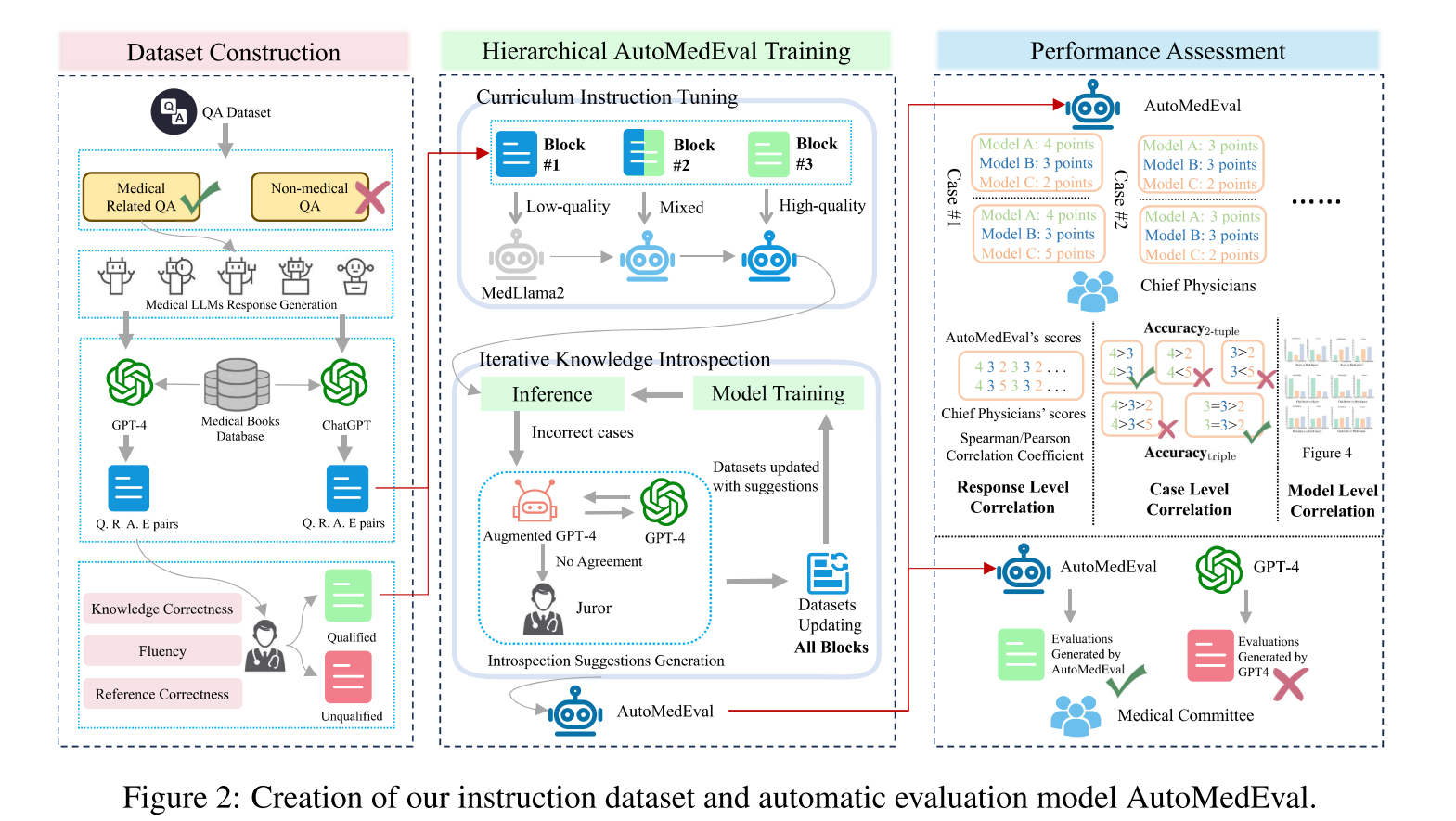
4.2.1 高质量医疗指令数据集构建
数据集构建流程严格,确保数据有效性与专业性,具体步骤如下表:
| 步骤 | 操作内容 | 关键结果 |
|---|---|---|
| 1. 原始数据筛选 | 基于 medical-meadow-wikidoc 的 10K QA 对,用模式匹配剔除医疗无关数据(如含 “rephras” 的重述请求) | 剔除 126 条,保留 9874 条(记为 D) |
| 2. 生成响应数据 | 用医疗 LLMs(ChatDoctor、Baize Healthcare)生成响应,构建 “问题 - 多响应 - 参考答案” 元组(qᵢ, rᵢ₋₁, rᵢ₋₂, aᵢ) | 形成评估输入基础 |
| 3. GPT-4 评估增强 | 基于医疗向量数据库(含 14 本专业书籍,如《PFENNINGER & FOWLOER’S Procedures for Primary Care》),用动态知识补全链(Algorithm 1)优化 GPT-4 评估,生成理据(eᵢ)与分数(sᵢ) | 形成初始评估数据集 E |
| 4. 医生双重验证 | 2 名主任医师从 “医疗知识正确性、归因准确性、语言流畅性” 三方面审核,剔除不合格数据 | 三方面达标率分别为 94.06%、90.71%、94.04%,剔除 305 条,最终保留 9569 条(记为 R) |
| 5. 补充测试数据 | 从 MedText 数据集选取 172 条数据,用于模型测试 | 测试集共 1130 条(958+172) |
4.2.2 分层训练方法
基于 MedLLaMA-13B 基础模型,采用 “课程指令微调 + 迭代知识内省” 的分层训练,解决高质量数据稀缺问题:
-
课程指令微调(Curriculum Instruction Tuning):
- 数据准备:用分类器(基于 SimCSE+SVM,准确率 91%)从 GPT-4 评估中筛选 4788 条高质量指令(R’),从 ChatGPT 评估中筛选 3823 条较高质量指令(S’),无交集。
- 三阶段训练:
- Lv.1(课程 #1):随机选取 S’ 中 1911 条,让模型识别评估模式。
- Lv.2(课程 #2):合并 R’-R₃’+S’-S₁’(剩余数据),实现从模式到质量的过渡。
- Lv.3(课程 #3):选取 R’ 中 2394 条,聚焦评估质量提升。
- 训练目标:最大化生成评估的对数概率,公式为θ∗=argmaxθ∑j=1Nlogp(Yj∣Xj;Ij,ϕ)(I 为三阶段课程指令,X 为输入,Y 为生成评估)。
-
迭代知识内省(Iterative Knowledge Introspection):
- 核心逻辑:模仿人类 “反馈修正” 过程,通过 AI - 医生协作修正模型错误评估,迭代优化。
- 实施步骤(Algorithm 2):
- 用当前模型评估训练数据,筛选错误案例(I)。
- AI(检索增强 GPT-4)生成修正建议,GPT-4 判断;3 轮未达成共识则由主任医师裁决。
- 用修正后的案例更新数据集,重新训练模型。
- 关键结果:迭代次数影响性能,2 次迭代后 Accuracyₜᵣᵢₚₗₑ达 48.65%,6 次迭代后达 52.21%(无进一步增长)。
5 实验
5.1.1 实验设置
- 基线模型:
- 闭源模型:text-davinci-003、ChatGPT(gpt-3.5-turbo-0125)、GPT-4(gpt-4-turbo-2024-04-09)、Gemini(gemini-2.0-flash)。
- 开源模型:Vicuna-7B/13B、DeepSeek-R1-Distill-Llama-8B、MedLLaMA、PandaLM。
- 评估指标:
- 分数评估:Spearman(响应级相关性)、Pearson(响应级相关性)、Accuracy₂₋tuple(两模型相对评分一致性)、Accuracyₜᵣᵢₚₗₑ(三模型评分一致性)。
- 理据评估:BERTScore、BARTScore(以 GPT-4 评估为参考)。
- 双盲偏好实验:3 名医学硕士候选人对比 AutoMedEval 与 GPT-4 的评估,从 “知识正确性、归因准确性、流畅性” 三方面选择更优结果。
- 训练配置:8 张 NVIDIA A100 80GB GPU,DeepSpeed ZeRO-Stage 3 优化,AdamW optimizer,学习率 2×10⁻⁵,批大小 2(每 GPU),梯度累积 8 步,FlashAttention(最大输入 2048 tokens)。
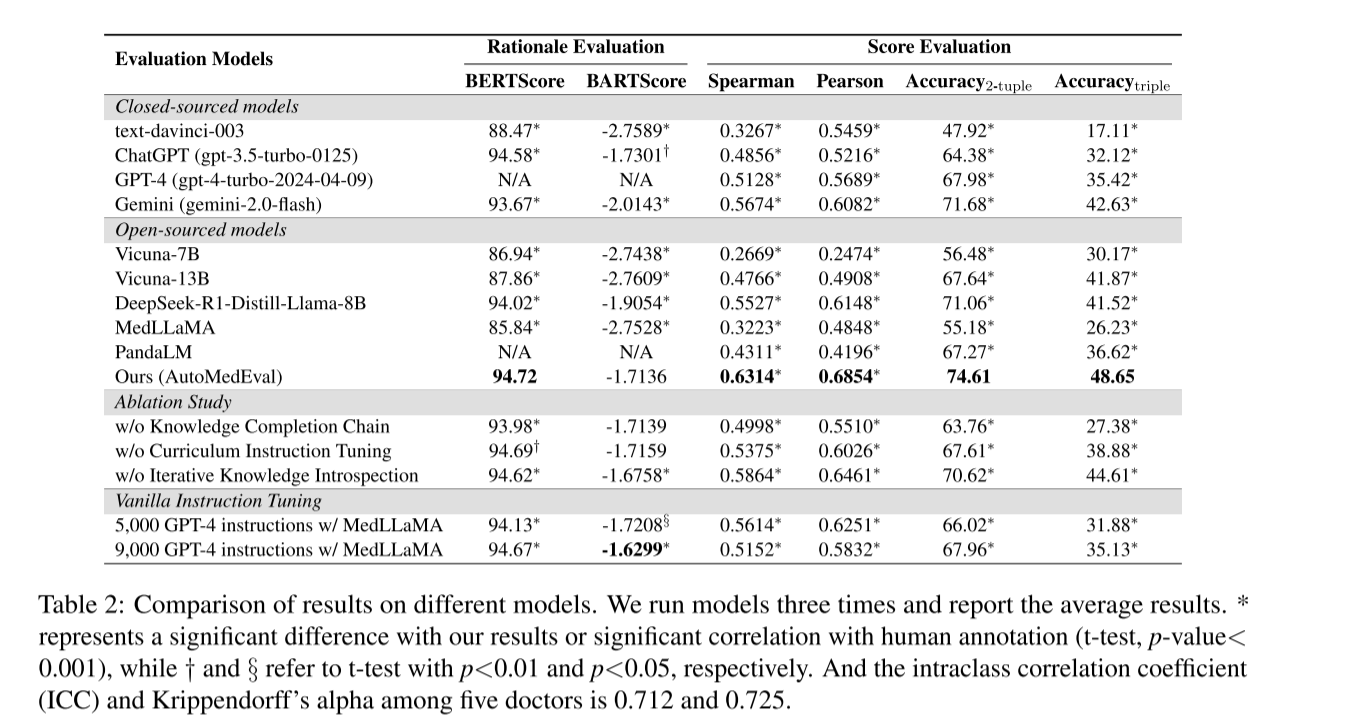
5.1.2 核心实验结果
6 关键问题
6.1 AutoMedEval 的高质量指令数据集是如何构建的?相比普通数据集,其核心优势是什么?
AutoMedEval 的指令数据集构建分 4 步:①原始数据筛选:从 medical-meadow-wikidoc 的 10K QA 对中,用模式匹配剔除 126 条医疗无关数据,保留 9874 条;②生成响应:用 ChatDoctor、Baize Healthcare 生成响应,构建 “问题 - 多响应 - 参考答案” 元组;③GPT-4 增强评估:基于含 14 本医疗专业书籍的向量数据库,通过动态知识补全链让 GPT-4 生成评估理据与分数;④医生双重验证:2 名主任医师从 “知识正确性、归因准确性、流畅性” 审核,剔除 305 条不合格数据,最终保留 9569 条。
核心优势:①专业性:经医疗 LLM 生成响应 + GPT-4 专业评估 + 医生双重验证,确保医疗知识准确;②针对性:聚焦医疗 LLM 评估场景,数据格式为 “问题 - 多响应 - 参考答案 - 评估理据 - 分数”,直接匹配评估任务需求;③高质量:三方面审核达标率超 90%,剔除低质数据,避免噪声干扰。
6.2 分层训练方法(课程指令微调 + 迭代知识内省)如何解决 “高质量医疗评估数据稀缺” 的问题?具体效果如何?
- 解决逻辑:
- 课程指令微调:不依赖纯高质量数据,而是用 “ChatGPT 较高质量数据(3823 条)+GPT-4 高质量数据(4788 条)” 分三阶段训练 —— 先让模型用低质数据识别评估模式(Lv.1),再用混合数据过渡(Lv.2),最后用高质量数据聚焦评估质量(Lv.3),实现 “从易到难” 的能力提升,降低对纯高质量数据的依赖。
- 迭代知识内省:通过 AI - 医生协作修正模型错误评估,将错误案例转化为 “修正后高质量数据”,迭代更新数据集并微调模型,相当于 “二次生成高质量数据”,弥补初始数据的不足。
- 具体效果:
- 课程指令微调:对比 “仅用 9000 条 GPT-4 高质量数据的 MedLLaMA”,AutoMedEval(用 5000 条高质量 + 4000 条较低质量数据)在 Accuracyₜᵣᵢₚₗₑ上相对提升 38.5%。
- 迭代知识内省:无该组件时,AutoMedEval 的 Accuracy₂₋tuple 为 70.62%、Accuracyₜᵣᵢₚₗₑ为 44.61%;加入后分别提升至 74.61%、48.65%,相对提升 5.3%、8.3%;6 次迭代后 Accuracyₜᵣᵢₚₗₑ达 52.21%,无进一步增长。
6.3 相比当前主流的医疗 LLM 评估工具(如 GPT-4、PandaLM),AutoMedEval 的核心竞争力体现在哪些方面?实验中有哪些关键证据支撑?
AutoMedEval 的核心竞争力体现在 “开源性 + 医疗专业性 + 与人类判断高一致性” 三方面,实验证据如下:
- 开源性:GPT-4、Gemini 为闭源模型,缺乏透明性且无法适配医疗隐私场景;AutoMedEval 开源,可用于医疗领域二次开发,符合医疗数据隐私要求。
- 医疗专业性:PandaLM 等开源模型为通用评估设计,医疗知识不足;AutoMedEval 基于 MedLLaMA-13B 医疗基础模型,经医疗指令微调,在医疗术语理解、评估维度(如治疗方案正确性、症状匹配度)上更专业 —— 实验中,AutoMedEval 在 “知识正确性” 评分上,医生标注平均分为 4 分(满分 5 分),显著高于 PandaLM 的 3.2 分。
- 与人类判断高一致性:
- 量化指标:Spearman 相关系数 0.6314(超 GPT-4 的 0.5128、PandaLM 的 0.4311),Accuracy₂₋tuple 74.61%(超 GPT-4 的 67.98%、PandaLM 的 67.27%),相对 PandaLM 提升 10.9%。
- 定性证据:双盲偏好实验中,3 名医学硕士候选人对 AutoMedEval 的偏好占比(62%)高于 GPT-4(38%);医生标注的评估结果分布与 AutoMedEval 高度 congruent,ICC(组内相关系数)达 0.712,证明一致性接近人类专家水平。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)