本地RAG知识库搭建全攻略,一文搞定大模型文档检索技术,值得收藏学习
一句话足矣~本文主要讲解了微舆的整体架构,并通过研读并调试源码,整理了多个Agent各自的执行流程、以及前后端交互。如项目原理、项目部署、源码等存在疑问,欢迎随时私信或留言交流!
本文详细解析了国产舆情分析系统"微舆"的架构与功能。该系统采用多Agent协作机制,包括Insight Agent、Media Agent和Query Agent,通过AI驱动的爬虫集群覆盖10余个社交平台。系统支持多模态信息解析,具备基于"圆桌讨论"的协作机制,能够融合公私域数据。文章深入探讨了各Agent的执行机制,展示了从Flask接收到最终报告生成的完整流程,为开发者提供了轻量灵活的扩展架构。
1.背景
近两周github一直霸榜的国产项目-微舆,引起了广泛的关注,11月3日start数3.4K,截止今天11月14日,start数26.6K,火箭原地起飞。
前几个月我也从事了舆情分析的相关项目,遂抱着学习的态度,花费了3天时间研究并调试了其中的运行机制。
2.特色功能
(1)AI驱动的全网舆情监控系统
基于全天候运行的AI爬虫集群,覆盖微博、小红书、抖音、快手等10余个国内外主流社交平台。该系统不仅能实时追踪热点话题,还可深入挖掘海量用户评论,捕捉真实、多元的公众声音。
(2)超越单一模型的复合分析系统
融合了5类自研专业Agent、微调模型与统计中间件,形成多模型协同的分析架构。通过多模型互补增强,分析结果在深度、准确性与多维度视角上得到有效保证。
(3)多模态信息解析能力
突破图文限制,支持对抖音、快手等平台短视频内容的深度理解,并能精准提取天气、股票、日历等搜索引擎中的结构化多模态信息卡片,为全面把握舆情动态提供支持。
(4)基于Agent“圆桌讨论”的协作机制
为不同Agent赋予专属工具与思维模式,并引入“主持人”模型,通过链式辩论与思维碰撞,打破模型同质化局限,有助于激发更高质量的集体智慧与决策建议。
(5)公私域数据无缝整合
除洞察公开舆情外,还提供高安全性接口,实现内部业务数据与舆情信息的高效融合。此举有助于打破数据孤岛,构建“外部趋势+内部实情”一体化的垂直业务洞察体系。
(6)轻量灵活的扩展架构
采用纯Python模块化设计,系统具备轻量化部署与灵活扩展的特性。清晰的代码结构使开发者能够快速接入自定义算法与业务逻辑,轻松实现平台定制与功能延展。
3.总体架构
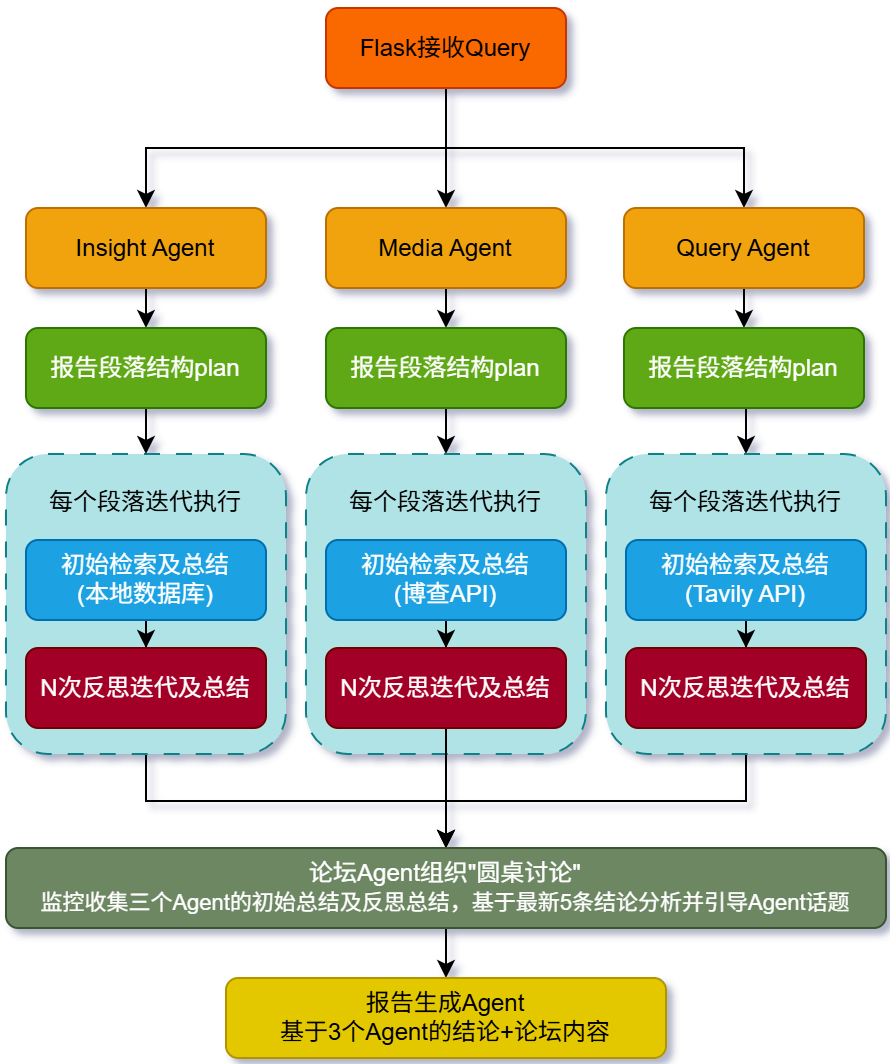
整体流程如下:
(1)Flask接收用户的原始问题,并行调用三个Agent,其中
Insight Agent: 私有舆情数据库深度分析AI代理,用于私有数据库挖掘。
Media Agent: 具备强大多模态能力的AI代理,用于多模态内容分析。
Query Agent: 具备国内外网页搜索能力的AI代理,用于精准信息搜索。
(2)每个Agent会分别执行以下步骤:
1)基于用户Query生成报告段落(默认为5段)
2)针对每个段落分别执行初始检索并生成段落报告总结,其中Insight Agent主要检索本地数据库,Media Agent主要通过博查API进行检索,Query Agent主要通过Tavily API进行检索。
3)检索之后进行多次迭代反思(默认为3),反思的过程是基于上一步的问题及总结等内容,判定是否存在遗漏偏差等情况,每次迭代均优化上一次迭代的段落总结
(3)论坛Agent通过监控三个Agent的日志,实时收集三者的段落总结内容,且根据最近的5次的段落总结,检测三者是否围绕主题展开,方向是否存偏等问题。且总结后的结果,会同步到初始检索和反思环节,以引导三个Agent围绕主题进行深度研究。
(4)等4个Agent执行结束后,再运行报告生成Agent,生成最终的报告。
4.核心组件
4.1 Insight Agent的执行机制
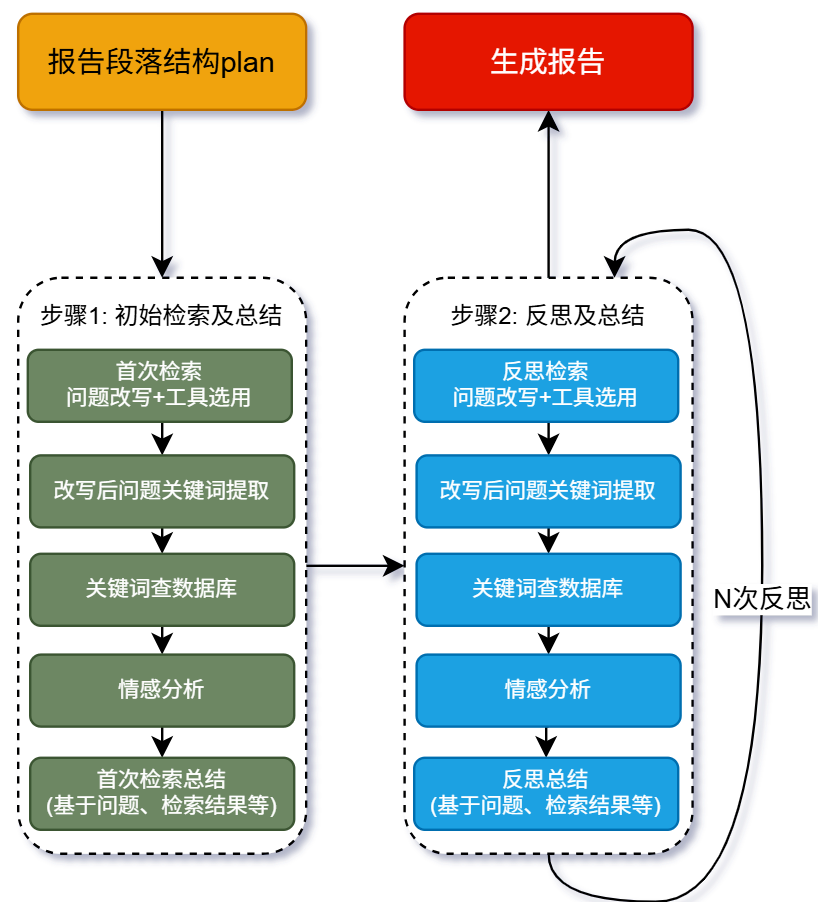
(1)首先生成报告段落结构Plan,默认为5个段落,包含title和content。
(2)生成的每个段落迭代执行如下流程:
1)初始检索并总结
a.基于title和content,针对问题进行改写,以适配不同网站(如B站、小红书、抖音、微博、知乎等)的问题风格,并提供诸多查询函数(包括按日期查找热点主题、全局热点主题等方法),输出最适配的查询函数及参数。
b.基于改写后的问题,生成核心关键词(默认20个)。
c.基于关键词以及匹配的查询函数,进行数据库查询,并对数据做去重处理。
d.针对查询后的结果采用多语言情感分析模型进行分类。
e.基于title、content、以及检索结果,生成段落报告总结。
2)多次反思迭代及总结
整体执行流程与初始检索并总结的流程大体相同,不同之处在于反思检索的输入除了title和content外,还有最新的段落总结(第一次是首次检索后的总结,后续是前次反思迭代后的总结)作为输入。
(3)多次反思迭代完成后,基于多个段落的内容(title, content, summary等),生成最终的舆情报告。
4.2 Media Agent的执行机制
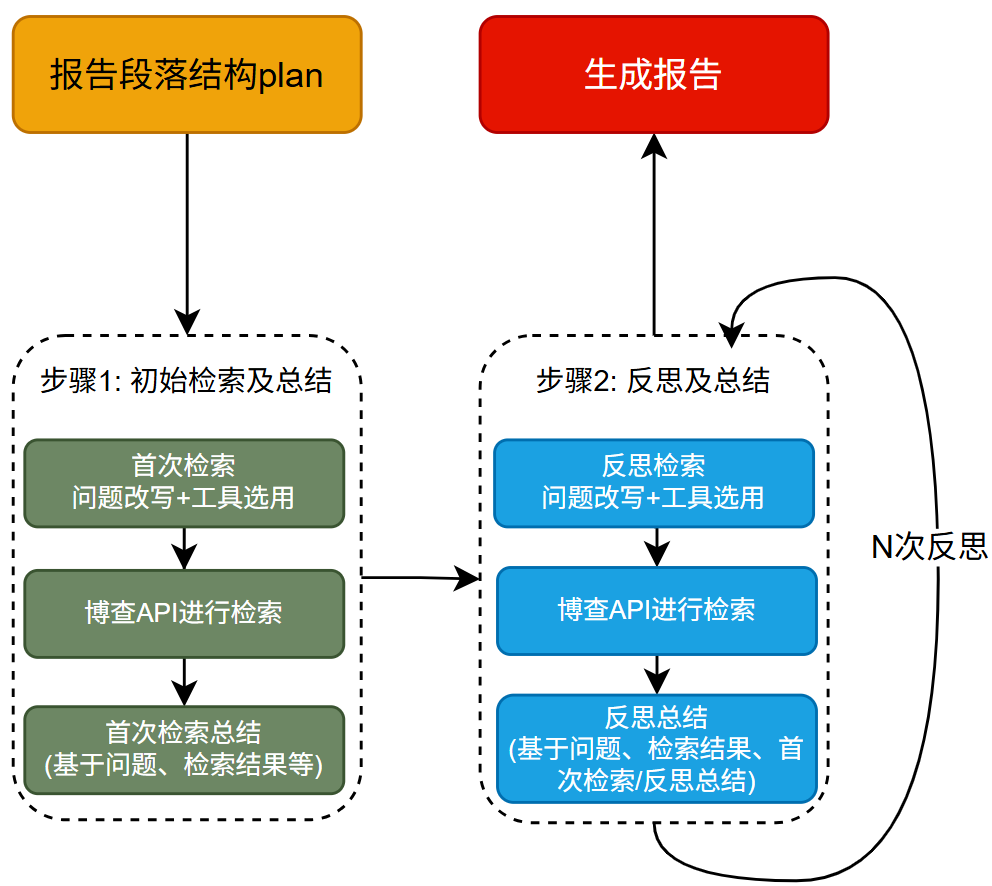
相比Insight Agent,流程相对简单一些,主要的不同之处在于前者查询数据库,后者通过博查API进行搜索调用。
4.3 Query Agent的执行机制
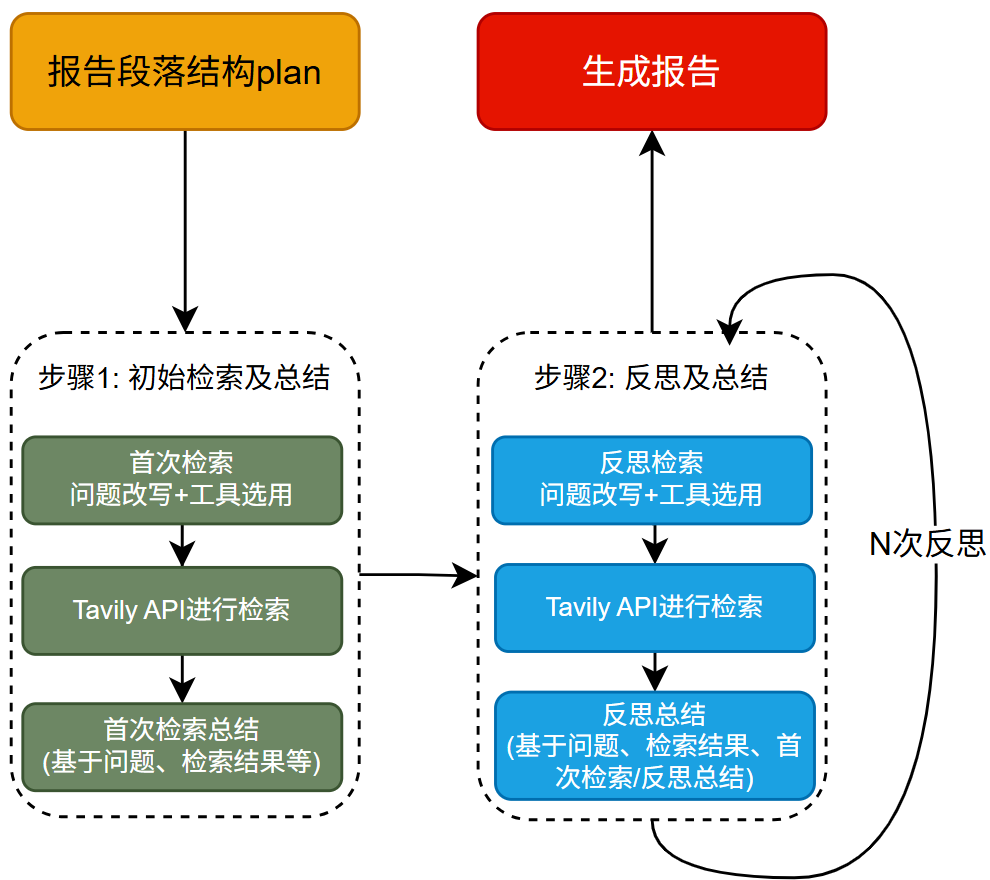
与Media Agent流程几乎一致,不同之处只是在于将博查API,切换到了 Tavily API。
5.源码说明
(1)借鉴MediaCrawler项目,可以实时收集B站、小红书、抖音、微博、知乎、贴吧等主流网站,采集代码位于项目中的MediaSpider目录下。
(2)代码比较简单,且不集成任何框架(包括LangGrahp, LangChain, LammaIndex等),从头实现了多Agent之间的流程编排及交互。
(3)代码相对冗余,可能确实是人家20岁小哥的手工作业做出来的。
(4)后端以Flask提供服务,通过html中的Script部分完成前后端的完整交互,且内部基于streamlit嵌入三个Agent的页面。
6.系统运行效果

7.总结
一句话足矣~
本文主要讲解了微舆的整体架构,并通过研读并调试源码,整理了多个Agent各自的执行流程、以及前后端交互。
如项目原理、项目部署、源码等存在疑问,欢迎随时私信或留言交流!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)