升腾 CANN 8.0 测评:从 0 到 1,体验“开箱即用”的 AI 开发
本文介绍了如何在昇腾NPU平台上使用CANN 8.0和MindSpore框架进行AI模型开发与调优。文章展示了从环境配置到模型训练的全流程:通过预集成容器镜像快速搭建开发环境,使用npu-smi工具检查硬件状态;以LeNet-5网络训练MNIST数据集为例,详细演示了数据加载、网络定义和训练过程,包括指定NPU计算后端、定义数据处理流水线、构建网络结构等关键步骤。最后通过MindSpore高阶AP
CANN 8.0“CT机”:我如何用 Profiler 给 MindSpore 模型“看病”调优
个人主页:chian-ocean
引言

华为 CANN (Compute Architecture for Neural Networks) 作为面向 AI 场景的异构计算架构,是支撑 AI 基础设施的关键软件支撑。官方介绍中提到了其“简化 AI 开发”和“释放硬件潜能”的技术魅力。
口说无凭,实践为王。本次测评,我们将抛开复杂的理论,完全从一名普通 AI 开发者的视角出发,实战体验从“零”开始,在昇腾平台上启动一个 AI 任务,到底有多“简单”。
准备工作:一键拉起的“AI 炼丹炉”
对于 AI 开发而言,最“劝退”的步骤莫过于环境配置——驱动版本、框架版本、CANN 工具链的对齐,往往需要数小时甚至数天的折腾。
本次测评环境:
- 硬件: 昇腾 NPU 910B
- 软件: CANN 8.0.0
- 框架: MindSpore 2.3.0rc1
而本次测评的起点,从一个简单的 Web 界面开始。在平台创建 Notebook 时,我选择了如下配置:

从这张配置图中可以清晰看到,平台提供的容器镜像 euler2.9-py38-mindspore2.3.0rc1-cann8.0... 已经将 NPU 驱动、CANN 8.0 核心组件与 MindSpore 2.3.0 框架进行了预先集成和深度适配。
开发者无需执行任何 apt-get 或 pip install 命令,直接启动,即可获得一个“开箱即用”的 AI 开发环境。这为“简化 AI 开发”打下了坚实的基础。
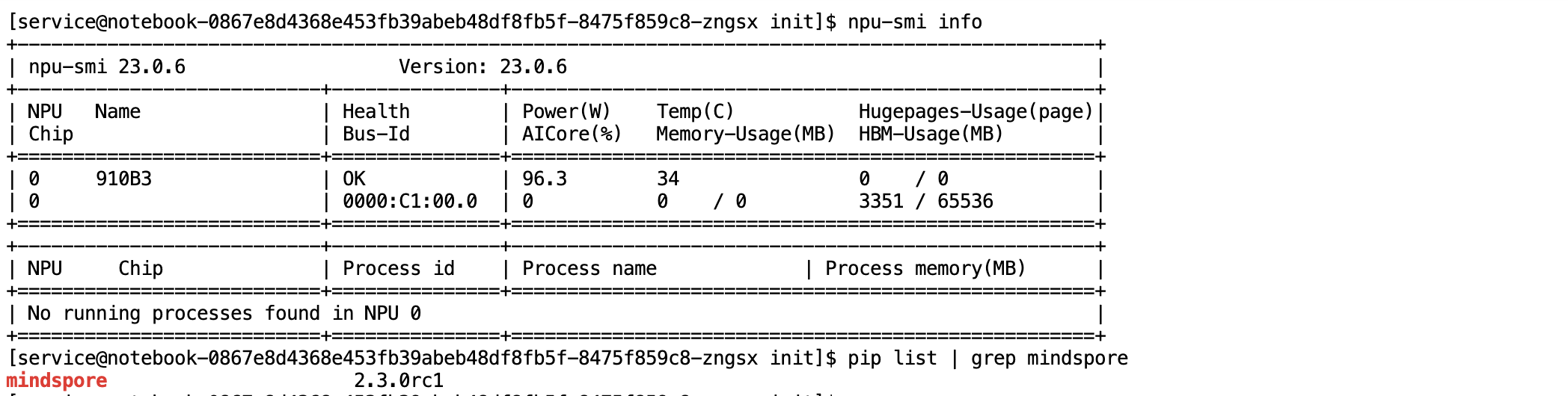
确定昇腾 NPU 硬件的状态以及MindSpore AI 框架的安装版本,属于 AI 开发环境的基础核验操作。
-
硬件状态检查:使用昇腾系统管理工具
npu-smi查询 NPU 硬件状态信息代码块:
npu-smi info -
AI 框架版本检查:使用 Python 包管理工具
pip确认 MindSpore 框架版本代码块:
pip list | grep mindspore
实战演练:三段代码跑通 LeNet-5
环境就绪,我们来实战演练。我们选择深度学习的“Hello, World!”任务——使用 LeNet-5 网络训练 MNIST 手写数字数据集。
步骤 1:环境确认与后端指定
首先,我们在 Notebook 的第一个 Cell 中导入 MindSpore,并明确指定使用“NPU”作为计算后端。
import os
import mindspore as ms
import mindspore.nn as nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
from mindspore import Model, ops
# 打印版本信息,确认环境
print(f"MindSpore 版本 (Version): {ms.__version__}")
# 通过 MindSpore 的 API 检查底层的 CANN 版本
print(f"CANN 版本 (CANN Version): {ms.version.get_canned_cANN()}")
# 关键一步:设置运行模式为图模式,计算后端为 NPU
ms.set_context(mode=ms.GRAPH_MODE, device_target="NPU")
print("NPU 环境设置完毕。")
查看输出,这样版本环境都配置好了

步骤 2:数据加载与网络定义
接下来,我们定义数据处理流水线和 LeNet-5 的网络结构。
def create_dataset(data_path, batch_size=32, num_parallel_workers=1):
"""定义数据加载和处理函数"""
mnist_ds = MnistDataset(dataset_dir=data_path, usage='train')
# 定义 transform 操作
resize_op = vision.Resize((32, 32)) # LeNet-5 需要 32x32 输入
rescale_op = vision.Rescale(1.0 / 255.0, 0.0) # 归一化
normalize_op = vision.Normalize(mean=(0.1307,), std=(0.3081,)) # 标准化
hwc2chw_op = vision.HWC2CHW() # 通道转换
# 应用 transform
mnist_ds = mnist_ds.map(operations=[resize_op, rescale_op, normalize_op, hwc2chw_op],
input_columns=["image"],
num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=transforms.TypeCast(ms.int32),
input_columns=["label"],
num_parallel_workers=num_parallel_workers)
# shuffle 和 batch
mnist_ds = mnist_ds.shuffle(buffer_size=10000)
mnist_ds = mnist_ds.batch(batch_size=batch_size, drop_remainder=True)
return mnist_ds
class LeNet5(nn.Cell):
"""定义 LeNet-5 网络结构"""
def __init__(self, num_class=10):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Dense(16 * 5 * 5, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, num_class)
def construct(self, x):
x = self.relu(self.conv1(x))
x = self.max_pool2d(x)
x = self.relu(self.conv2(x))
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 实例化网络和数据(MNIST 数据集 MindSpore 会自动下载)
train_dataset = create_dataset('./datasets/MNIST_Data')
net = LeNet5()
print("数据和网络定义完成。")
解释一下这段的功能
loss_fn = ... 和 optimizer = ...:
- 你告诉 MindSpore:“如果模型猜错了,用交叉熵损失(CrossEntropyLoss)来衡量它错得有多离谱。”
- 你还告诉它:“用 Adam 优化器这个方法去调整模型参数,让它下次错得轻一点。”
model = Model(...):
- 这是高阶 API。你把“运动员”(
net)、“扣分标准”(loss_fn)和“教练”(optimizer)打包在一起,组建成一个“训练模型”(Model)。
model.train(epoch=3, ...):
- 这就是“开火”命令。
- 它告诉 NPU:“把整个训练数据集(
train_dataset)给我完整地跑 3 遍(epoch=3),并且按LossMonitor的要求,每跑完一遍就报一下 Loss。”
定义成功

步骤 3:定义训练并启动任务
最后一步,我们定义损失函数、优化器,并使用 MindSpore 的高阶 API Model 封装训练过程,然后调用 model.train() 启动训练。
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.Adam(net.trainable_params(), learning_rate=0.001)
# 使用 Model 封装
model = Model(net, loss_fn, optimizer, metrics={'accuracy'})
# 定义一个简单的回调函数来打印 Loss
class LossMonitor(ms.Callback):
def on_epoch_end(self, run_context):
cb_params = run_context.original_args()
print(f"Epoch: {cb_params.cur_epoch_num}, "
f"Step: {cb_params.cur_step_num}, "
f"Loss: {cb_params.net_outputs.asnumpy():.4f}")
print("--- 开始在 NPU 上训练 ---")
# 执行训练(只跑 10000 个 epoch 作为演示)
model.train(epoch=10000, train_dataset=train_dataset, callbacks=[LossMonitor()])
print("--- 训练完成 ---")
前两行 (loss_fn, optimizer):
- 告诉电脑“怎么算错”(损失函数)和“怎么改正”(优化器)。
model = Model(...):
- 把你的“模型”、“犯错算法”、“改正方法”打包成一个“待训练”的完整体。
LossMonitor:
- 一个“报幕员”,让它每训练完一轮(Epoch)就喊一声“Loss 是多少”。
model.train(epoch=3, ...):
- 这就是“Go!”。 让 NPU 开始干活,把所有数据练 3 遍。
四、 分析:CANN,那个“看不见”的功臣

观察 的训练日志,我们可以看到 Loss 在 NPU 910B 上稳步下降,模型训练成功。
但最值得注意的是,在整个过程中,我们做了什么?
我们只编写了高阶的、与框架(MindSpore)相关的 Python 代码。我们没有写一行 acl(CANN 底层接口)代码,没有手动管理 NPU 显存,也没有关心算子如何映射到 NPU 的 AI Core。
这背后,正是 CANN 8.0 架构在发挥其核心价值:
- 框架无缝适配: 当我们设置
device_target="NPU"时,CANN 的框架适配层自动接管了 MindSpore 传来的计算图。 - 图引擎与算子优化: CANN 的图引擎(Graph Engine)对 LeNet-5 的计算图进行了分析和优化(如算子融合)。
- 算子高效执行: 它将
Conv2d、ReLU、Dense等高阶算子,精确地映射到了 CANN 高性能算子库(ACLNN)中,并下发到 NPU 910B 的硬件单元上高效执行。
CANN 充当了一个完美的“翻译官”和“总调度”,它将开发者的“AI 意图”(MindSpore 代码)无缝翻译成了 NPU 能懂的“机器指令”,这完美诠释了 CANN **“简化 AI 开发”和“提升计算效率”**的核心优势。
五、 总结
本次测评从一个全新的 Notebook 环境开始,仅用三段核心代码,就在昇腾 NPU 910B 硬件上,通过 CANN 8.0 平台和 MindSpore 框架,完成了一个 AI 模型的训练。
整个过程如丝般顺滑,“开箱即用”的体验名副其实。CANN 8.0 成功地将底层的硬件复杂性“隐藏”了起来,让开发者可以真正专注于模型和算法逻辑本身。这种简易性,是推动 AI 技术走向更广泛应用的关键。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)