【AI大模型前沿】Qwen3-VL:阿里云通义千问的多模态视觉语言模型,开启智能交互新纪元
Qwen3-VL是阿里云通义千问团队发布的多模态视觉语言模型系列,旨在通过强大的视觉和语言处理能力,实现更自然、更智能的人机交互。该模型系列具备卓越的视觉交互能力、纯文本处理能力、视觉编程能力、空间感知与推理能力、长上下文与长视频理解能力、多模态推理与思考能力、全面升级的视觉感知与识别能力以及多语言OCR与复杂场景识别能力。
系列篇章💥
前言
随着人工智能技术的飞速发展,多模态模型逐渐成为研究和应用的热点。Qwen3-VL作为阿里云通义千问团队推出的最新一代视觉语言模型,凭借其卓越的视觉理解、空间感知和长上下文处理能力,为多模态交互带来了全新的可能性。
一、项目概述
Qwen3-VL是阿里云通义千问团队发布的多模态视觉语言模型系列,旨在通过强大的视觉和语言处理能力,实现更自然、更智能的人机交互。该模型系列具备卓越的视觉交互能力、纯文本处理能力、视觉编程能力、空间感知与推理能力、长上下文与长视频理解能力、多模态推理与思考能力、全面升级的视觉感知与识别能力以及多语言OCR与复杂场景识别能力。
二、核心功能
(一)视觉交互与任务执行
Qwen3-VL能够操作电脑和手机界面,识别图形用户界面(GUI)元素,理解按钮功能,调用工具并执行任务。在OS World等基准测试中表现卓越,通过工具调用显著提升细粒度感知任务的表现。
(二)强大的纯文本处理能力
从预训练初期开始,Qwen3-VL融合文本与视觉模态的协同训练,持续强化文本处理能力。纯文本任务表现与Qwen3-235B-A22B-2507纯文本旗舰模型相当。
(三)视觉编程能力
Qwen3-VL支持根据图像或视频生成代码,能够将设计图转化为网页代码,帮助开发者快速实现前端开发。
(四)空间感知与推理
2D定位从绝对坐标升级为相对坐标,支持判断物体方位、视角变化和遮挡关系,能实现3D定位。
(五)长上下文与长视频理解
全系列模型原生支持256K token的上下文长度,可扩展至100万token。模型能完整输入、全程记忆、精准检索,支持视频精确定位到秒级别。
(六)多模态推理与思考
Thinking版本重点优化STEM和数学推理能力。面对专业学科问题,模型能捕捉细节、分析因果,给出有逻辑、有依据的答案。
(七)全面升级的视觉感知与识别
Qwen3-VL能识别更丰富的对象类别,从名人、动漫角色、商品、地标到动植物等,满足日常生活和专业领域的“万物识别”需求。
(八)多语言OCR与复杂场景识别
OCR支持的语言种类从10种扩展到32种,覆盖更多国家和地区。在复杂光线、模糊、倾斜等实拍场景下表现稳定,对生僻字、古籍字、专业术语的识别准确率显著提升,超长文档理解和精细结构还原能力进一步增强。
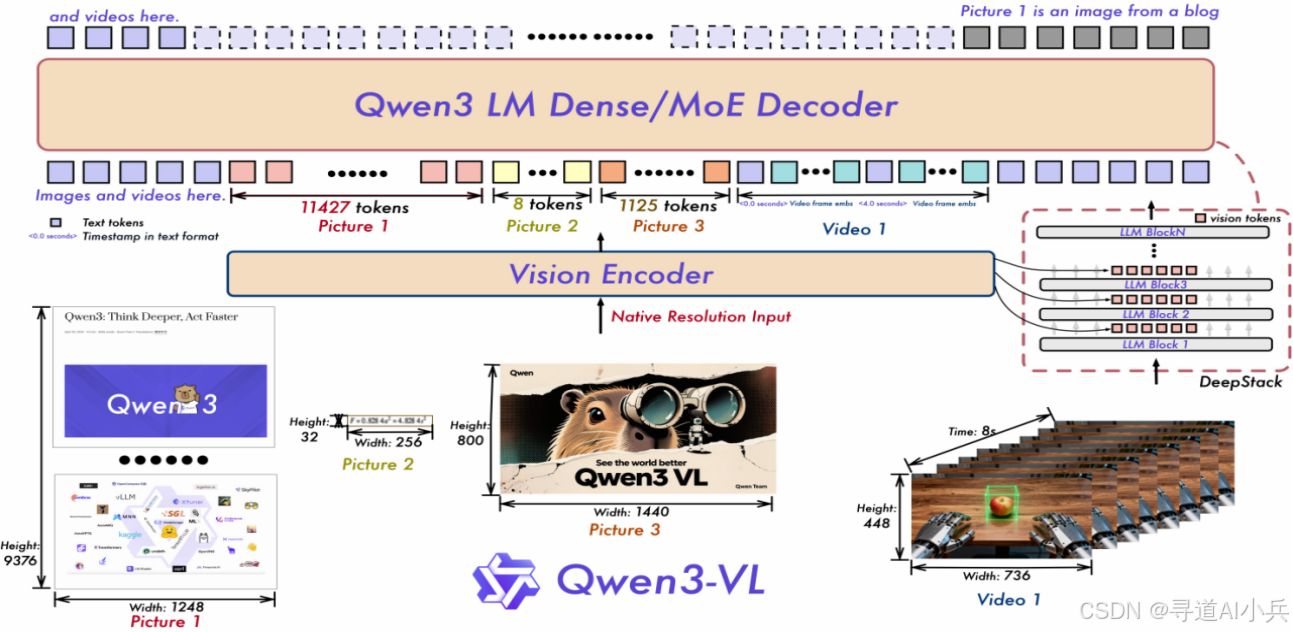
三、技术揭秘
(一)多模态融合
Qwen3-VL结合视觉(图像、视频)和语言(文本)模态,通过混合模态预训练,实现视觉和语言的深度融合。
(二)架构设计
基于原生动态分辨率设计,结合MRoPE-Interleave技术,交错分布时间、高度和宽度信息,提升对长视频的理解能力。引入DeepStack技术,融合ViT多层次特征,提升视觉细节捕捉能力和图文对齐精度。
(三)视觉特征token化
将ViT不同层的视觉特征进行token化,保留从底层到高层的丰富视觉信息,提升视觉理解能力。
(四)时间戳对齐机制
基于“时间戳-视频帧”交错输入形式,实现帧级别的时间信息与视觉内容的细粒度对齐,提升视频语义感知和时间定位精度。
四、性能表现
(一)视觉任务性能
Qwen3-VL在视觉任务中表现出色,尤其在图像描述和视觉问答任务中。例如,在图像描述任务中,其准确率高达91.2%,超越了GPT-4V的85.7%。
(二)纯文本任务性能
在纯文本任务中,Qwen3-VL的表现与Qwen3-235B-A22B-2507纯文本旗舰模型相当。这表明Qwen3-VL在文本生成、文本理解等任务上具备强大的能力。无论是生成连贯的文本内容,还是理解复杂的文本语义,Qwen3-VL都能提供高质量的输出。
(三)多模态任务性能
在多模态任务中,Qwen3-VL展现了强大的推理和理解能力。例如,在视频理解任务中,模型能够处理长达数小时的视频,并进行精准的语义理解和时间定位。Qwen3-VL能够理解视频中的复杂场景和事件,并生成准确的描述和总结。
(四)长上下文与长视频理解性能
Qwen3-VL全系列模型原生支持256K token的上下文长度,可扩展至100万token。这使得模型能够处理超长文本和长视频内容,而不会出现信息丢失或理解不准确的问题。在长视频理解任务中,Qwen3-VL能够完整输入、全程记忆、精准检索,支持视频精确定位到秒级别。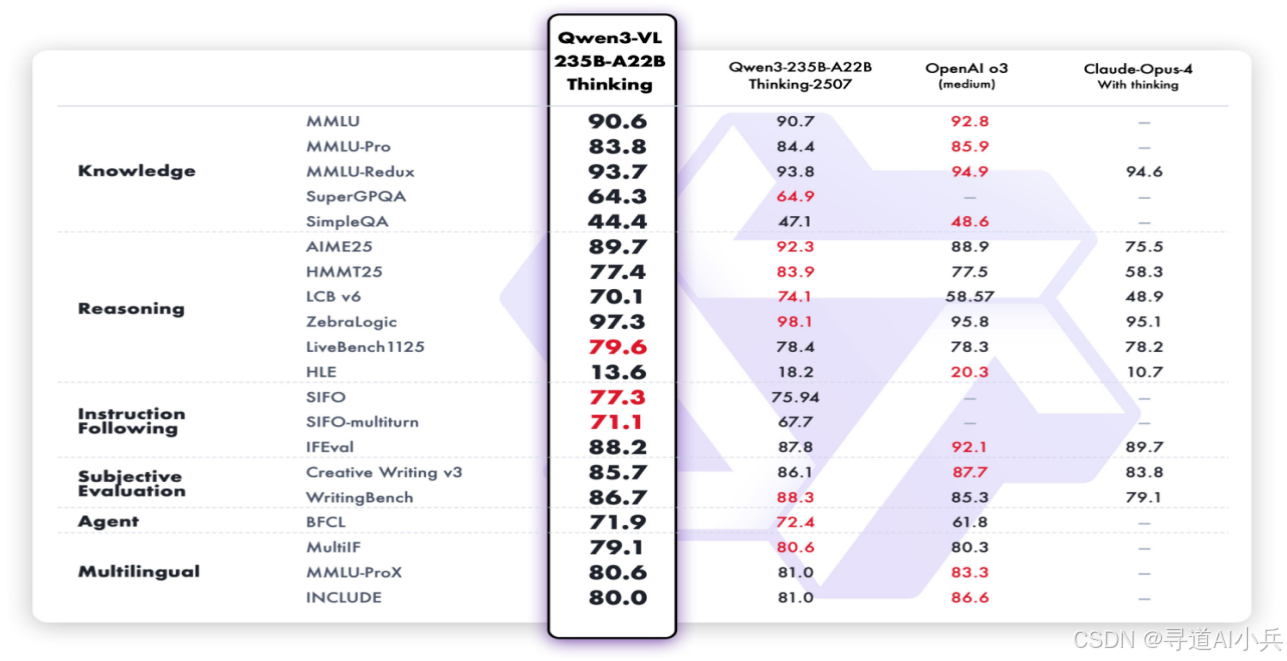
五、应用场景
(一)自动化办公与任务执行
Qwen3-VL能够操作电脑和手机界面,自动完成各种任务,极大地提高了办公效率。例如,它可以识别图形用户界面(GUI)元素,理解按钮功能,调用工具并执行任务。在自动化办公场景中,Qwen3-VL可以自动打开应用程序、填写表单、发送邮件等,减少人工操作的繁琐步骤。
(二)视觉编程辅助
Qwen3-VL支持根据图像或视频生成代码,这为开发者提供了强大的编程辅助功能。例如,它可以将设计图直接转化为网页代码,帮助开发者快速实现前端开发。这种能力不仅节省了开发时间,还提高了代码的质量和一致性。
(三)教育与学习辅导
在教育领域,Qwen3-VL能够为学生提供详细的解题思路和答案,辅助学习。它在STEM学科问题解答上表现出色,能够捕捉问题的细节,进行因果分析,并给出有逻辑、有依据的答案。此外,Qwen3-VL还可以通过图像和视频辅助教学,使学习过程更加生动和直观。
(四)创意内容生成
Qwen3-VL可以根据图像或视频内容生成文案、故事等,为创作者提供灵感和素材,助力创意写作。例如,它可以为广告公司生成创意文案,为小说家提供故事大纲,为视频创作者生成脚本等。这种能力不仅激发了创作者的灵感,还提高了内容创作的效率。
(五)复杂文档处理
Qwen3-VL能够解析长文档和多页文件,提取关键信息,方便用户快速获取所需内容。它支持多语言OCR和复杂场景识别,能够处理生僻字、古籍字、专业术语等,对超长文档的理解和精细结构还原能力进一步增强。这使得Qwen3-VL在法律、金融、科研等领域具有重要的应用价值。
(六)视频内容理解与分析
Qwen3-VL在视频理解方面表现出色,能够处理长达数小时的视频,并进行精准的语义理解和时间定位。它可以用于视频内容的自动标注、视频摘要生成、视频问答等场景。例如,在视频监控领域,Qwen3-VL可以实时分析监控视频,识别异常行为并发出警报。
(七)多语言文档处理
Qwen3-VL支持32种语言的OCR识别,覆盖更多国家和地区。这使得它在跨国企业、国际组织等场景中具有广泛的应用价值。例如,它可以用于多语言文档的翻译、内容提取和信息检索,帮助用户快速处理和理解不同语言的文档。
六、快速使用
(一)安装依赖
执行下面命令、安装相关依赖
pip install git+https://github.com/huggingface/transformers
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
(二)推理示例
以下是基于transformers 推理的代码示例:
from transformers import AutoModelForImageTextToText, AutoProcessor
# default: Load the model on the available device(s)
model = AutoModelForImageTextToText.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Instruct", dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = AutoModelForImageTextToText.from_pretrained(
# "Qwen/Qwen3-VL-235B-A22B-Instruct",
# dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
七、结语
Qwen3-VL作为阿里云通义千问团队推出的多模态视觉语言模型,凭借其卓越的性能和广泛的应用场景,为人工智能领域带来了新的突破。无论是视觉交互、纯文本处理,还是多模态推理,Qwen3-VL都展现出了强大的能力。未来,随着技术的不断发展,Qwen3-VL有望在更多领域发挥更大的作用。
项目地址
- 项目官网:https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef&from=research.latest-advancements-list
- GitHub仓库:https://github.com/QwenLM/Qwen3-VL
- Hugging Face模型库:https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)