构建AI智能体:九十八、实践出真知:本地AI大模型部署的核心要点与经验总结
本文介绍了如何在个人电脑上加载和运行轻量级AI大语言模型。首先解析了大语言模型的基本概念和工作原理,包括Tokenizer、Prompt等关键术语。然后详细演示了三种模型加载方式:通过ModelSpace下载Qwen模型、使用HuggingFace加载BERT模型、利用SentenceTransformer获取句子嵌入。特别强调了在CPU环境下的配置技巧,如设置torch.float32数据类型和
一、引言
当我们初次接触理解大模型时,可能会被那些需要昂贵GPU、复杂环境配置的要求吓到,很多人误以为运行AI模型必须依赖高端显卡和专业的计算机硬件,这种认知让许多对AI感兴趣的学习者望而却步,实际上,随着模型优化技术的进步,现在有大量优秀的轻量级模型完全可以在普通笔记本电脑甚至台式机的CPU上流畅运行。
为了打破这种壁垒、解读一些基本的疑惑,今天们将从最基础的概念开始,一步步详细的说明如何在个人电脑上加载和运行各类AI模型,通过今天的了解,我们将学习到不同的模型加载方式,从最简单的单行代码到更灵活的配置选项。我们会详细介绍每个参数的作用,让你不仅知道怎么做,更明白为什么这么做,更重要的是,我们将推荐多个经过验证的小型模型,这些模型在保持不错性能的同时,对硬件要求极低,同时我们也将使用通俗易懂的语言,避开复杂的数学公式和深奥的理论,专注于实际操作和立即可以上手的代码示。
二、大模型回顾
1. 什么是大语言模型
核心定义:大语言模型是一个基于海量文本数据训练而成的、极其复杂的“下一个词预测器”。
通俗理解:当你输入一段话,我们通常称为 Prompt提示词,它会根据之前的所有文字,计算出下一个最有可能出现的词是什么,并这样一直继续下去,从而生成一段完整的、通顺的回答。
关键特点:
- 规模巨大:这里的大指的是模型的参数 数量极其庞大,可以达到百亿、千亿甚至万亿,参数可以理解为模型学到的知识单元,参数越多,模型通常越聪明。
- 通用性强:同一个模型,无需重新训练,就能完成写作、翻译、编程、逻辑推理等多种任务,只需我们给它不同的提示。
2. 三个关键概念
- Token(词元):模型不是直接理解汉字或英文单词,而是先把它们切分成更小的单元。
- 例如,“我喜欢苹果”可能会被切成 ["我", "喜欢", "苹果"] 三个Token。
- 英文单词 "learning" 可能会被切成 ["learn", "ing"] 两个Token。
- 这是模型处理文本的基本单位。
- Prompt(提示):你给模型的指令或问题。你的提问技巧直接决定了模型回答的质量。
- 不好的Prompt:“苹果。”
- 好的Prompt:“请用一段话介绍苹果这种水果的营养价值。”
- Inference(推理):训练好的模型根据我们输入的提示生成回答的过程,就叫做推理。这就像我们向一个已经学成归来的专家提问,他现场为你解答。
3. 结合常用模型介绍
3.1 ModelScope(模型小镇)
- ModelScope 是一个模型平台或模型社区,我们可以把它想象成一个模型的应用商店。
- 核心功能:它本身不只是一个模型,而是汇集了成千上万个AI模型(包括各种大语言模型、图像生成模型、语音模型等)的平台。开发者可以在这里找到、体验甚至直接调用这些模型。
- 对初学者的说我们不需要关心模型底层有多复杂,可以像在手机应用商店里下载App一样,在ModelScope上找到适合你任务的模型,直接在线体验或通过简单代码调用。
- 常用模型举例:平台上就包含了我们下面要讲的 Qwen(通义千问) 系列模型。
3.2 Qwen(通义千问)
- 它是什么阿里自主研发的 大语言模型系列,它就是我们常说的那个超级大脑。
- 特点:
- 系列丰富:有不同大小的版本,比如 Qwen-7B(70亿参数)、Qwen-72B(720亿参数)等。参数越多,能力通常越强,但运行所需的资源也越多。
- 开源开放:很多版本的Qwen模型都开源了,意味着任何人都可以免费下载、使用甚至在自己的电脑上部署(如果硬件足够的话)。这对于学习和研究非常友好。
- 多模态:除了纯文本模型,还有能理解图片的 Qwen-VL,以及能处理音频的 Qwen-Audio。
- 我们可以用它聊天、写邮件、翻译、写代码、分析图片内容等。
3. 腾讯混元大模型
- 它是腾讯自主研发的 大语言模型系列。
- 特点:
- 深度集成腾讯生态:你可能已经在不知不觉中用过它了!它被集成在微信、QQ、腾讯广告、腾讯会议等众多腾讯产品中,为其提供AI能力。
- 强调实用性和应用落地:混元模型非常注重在真实业务场景中的表现,比如提升广告推荐效果、在腾讯会议中生成会议纪要等。
- 多模态能力:同样具备文生图、图生文等能力。
- 对初学者而言,混元代表了大型科技公司如何将大模型技术融入我们日常使用的产品中,让我们感受到AI就在身边,虽然它不像Qwen那样完全开源,但你可以通过腾讯云等渠道申请使用其API。
三、模型的加载方式
1. 从ModelScope下载并加载
这段代码从ModelScope平台下载并加载Qwen1.5-1.8B-Chat模型,加载完成后提示加载完成,如果加载失败会直接退出。
1.1 示例演示
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
import torch
# 设置设备为CPU
device = "cpu"
# 从ModelScope下载/加载模型和分词器
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
print("正在加载模型...")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32, # CPU上使用float32
device_map=device
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print("模型加载完成!")
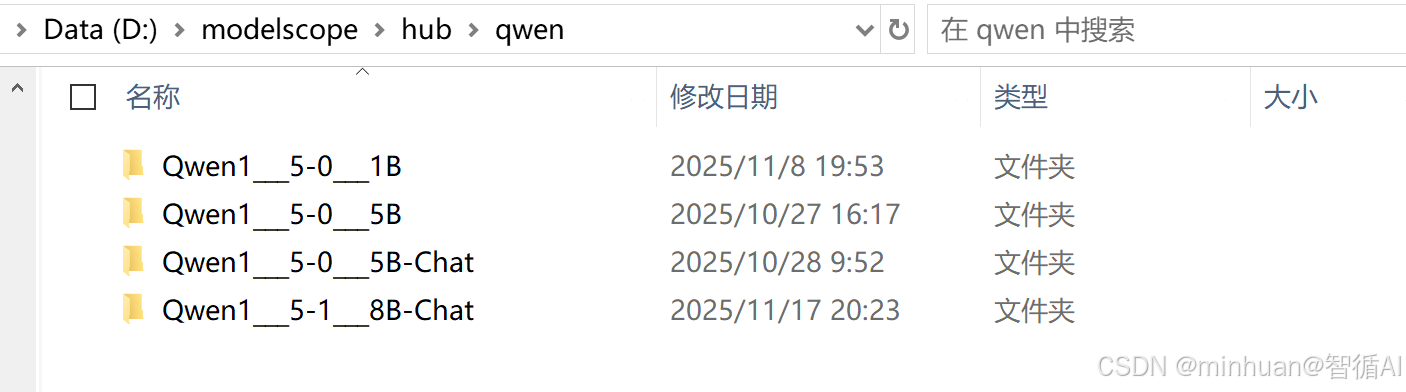
示例中运行的模型名称是Qwen1.5-1.8B-Chat,初次运行时,会先从本地D:\\modelscope\\hub\\qwen目录中查看是否存在,如果没有模型文件,会先下载,然后再加载

下载后本地的存放路径:
示例运行输出结果:
正在下载/校验模型缓存...
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-18 19:45:04,376 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat].
2025-11-18 19:45:04,377 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat.
正在加载模型...
模型加载完成!
1.2 代码分析
1.2.1 导入库和环境配置
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
import torch
device = "cpu"- AutoModelForCausalLM: 用于自动加载因果语言模型(生成式模型)
- AutoTokenizer: 自动加载对应的分词器
- snapshot_download: 从ModelSpace下载模型文件
- 设置为"cpu"表示在CPU上运行,适合没有GPU或内存较小的环境
- 如果有GPU,可以设置为"cuda"或"cuda:0"
- 此为自动判断设置:device = "cuda" if torch.cuda.is_available() else "cpu"
1.2.2 模型配置
# 从ModelScope下载/加载模型和分词器
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"- model_id:
- qwen/: 命名空间,表示这是千问系列模型
- Qwen1.5-1.8B-Chat: 具体模型名称
- 1.8B: 18亿参数,属于较小规模的大模型
- Chat: 经过对话优化的版本
- cache_dir: 本地模型缓存目录,避免重复下载
1.2.3 模型下载
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)- 检查本地缓存是否已有该模型,如果没有,从ModelSpace服务器下载
- 这个路径不是必须的,如果没有指定路径会下载到系统默认的缓存路径
- 下载内容包括:
- 模型权重文件 (pytorch_model.bin 或 .safetensors)
- 配置文件 (config.json)
- 分词器文件 (tokenizer.json, vocab.json等)
- 可能还有其他必要的运行文件
1.2.4 分词器加载
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True
)- trust_remote_code=True,非常重要:允许运行模型自定义的代码
- 对于Qwen等国产模型,通常需要这个参数来加载特殊的分词器实现
- from_pretrained()方法的作用:
- 自动从仓库下载模型文件(如果本地没有缓存)
- 加载配置文件构建模型结构
- 加载预训练权重
- 返回可用的模型实例
1.2.5 模型加载
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True, # 同样需要信任自定义代码
torch_dtype=torch.float32, # 指定数据类型
device_map=device # 指定运行设备
)- torch_dtype=torch.float32:
- 指定模型权重使用的数据类型
- float32: 单精度浮点数,精度最高,但内存占用最大
- 其他选项:
- torch.float16: 半精度,内存减半,速度更快
- torch.bfloat16: 脑浮点数,在保持范围的同时减少精度
- device_map=device:
- 控制模型在哪些设备上运行
- "cpu": 所有层都在CPU上
- "auto": 自动分配(如果有多个GPU)
- {"": "cuda:0"}: 指定到特定GPU
1.2.6 分词器配置
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token- pad_token: 用于将不同长度的序列填充到相同长度
- eos_token: 结束符(End-of-Sequence)
- 很多对话模型没有显式定义pad_token,用eos_token代替可以保证批处理时的正常工作
1.2.7 内存开销估算
对于Qwen1.5-1.8B模型:
- float32: 1.8B × 4字节 ≈ 7.2GB
- float16: 1.8B × 2字节 ≈ 3.6GB
- 实际运行: 还需要额外内存用于中间激活值等
1.3 模型加载流程

步骤说明:
- 路径解析:确定模型文件的本地存储位置
- 配置文件读取:加载模型的架构配置参数
- 模型架构构建:根据配置实例化模型结构
- 权重加载:将预训练权重加载到模型中
- 设备转移:将模型转移到指定设备(CPU/GPU)
2. 从Hugging Face仓库下载
这段代码使用Hugging Face Transformers库加载中文BERT模型,并展示模型的基本信息和内存占用。
2.1 示例演示
from transformers import BertTokenizer, BertModel
# 加载中文BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 模型信息展示
print(f"模型类型: {type(model).__name__}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
print(f"模型设备: {next(model.parameters()).device}")
# 内存使用统计
model_memory = sum(p.numel() * p.element_size() for p in model.parameters())
print(f"模型内存占用: {model_memory / 1024 / 1024:.2f} MB")
print("模型加载完成!")这个示例,我们特意没有指定目录,先观察模型的下载过程:
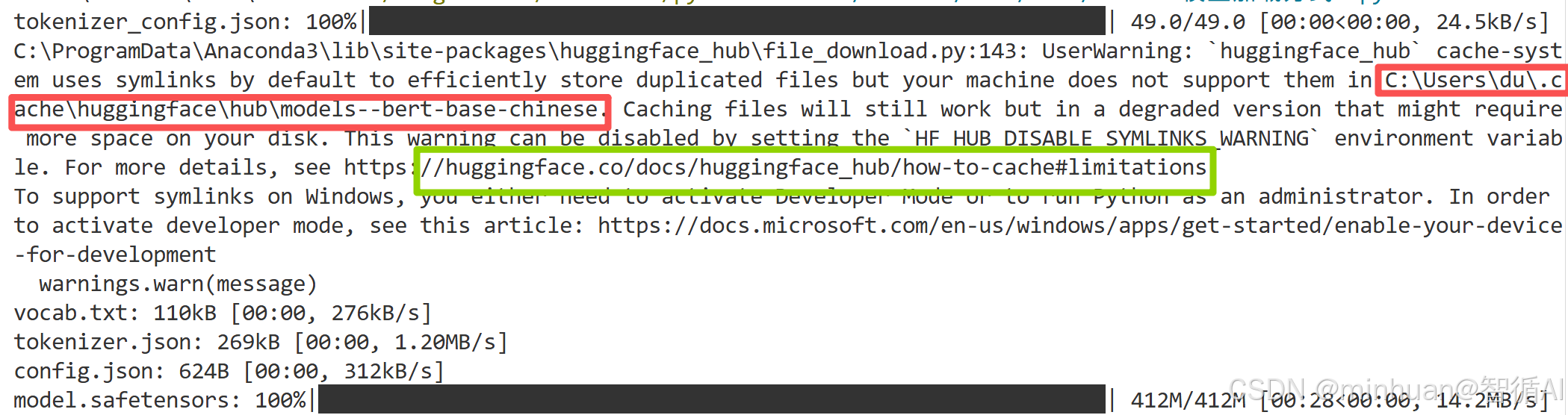
通过运行日志可知,模型访问的是huggingface网站进行下载,由于我们没有配置缓存目录,模型默认下载到了系统用户的缓存目录中C:\Users\du\.cache\huggingface\hub\models--bert-base-chinese
示例运行输出结果:
模型类型: BertModel
模型参数量: 102,267,648
模型设备: cpu
模型内存占用: 390.12 MB
模型加载完成!
2.2 代码分析
2.2.1 导入库
from transformers import BertTokenizer, BertModel- BertTokenizer: BERT专用的分词器,负责将文本转换为模型可理解的token ID
- BertModel: 标准的BERT模型类,不包含特定任务头部,输出原始隐藏状态
2.2.2 模型和分词器加载
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')- 'bert-base-chinese':
- 这是Hugging Face Model Hub上的模型标识符
- 组成部分:
- bert: 模型架构类型
- base: 模型规模(基础版,还有large版)
- chinese: 专门针对中文训练
- 具体规格:
- 12层Transformer
- 768维隐藏层
- 12个注意力头
- 约1.02亿参数
2.2.3 模型信息展示
print(f"模型类型: {type(model).__name__}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
print(f"模型设备: {next(model.parameters()).device}")- 输出模型的具体类名,这里是BertModel
- model.parameters(): 获取模型所有可学习参数
- p.numel(): 计算每个参数张量中的元素数量
- sum(...): 累加所有参数数量
- :,: 千位分隔符格式化,便于阅读
- next(model.parameters()): 获取第一个参数张量
- .device: 查看该张量所在的设备(CPU/GPU)
- BERT模型默认加载到CPU
2.3 模型加载流程

步骤说明:
- 模型标识符解析:解析模型名称确定下载源和本地缓存位置
- 配置文件下载/读取:获取模型结构定义和超参数配置
- 模型架构构建:根据配置文件创建空的模型计算图结构
- 权重文件下载/加载:将预训练参数填充到模型架构中
- 模型实例化完成:获得包含权重的完整可运行模型
3. 使用SentenceTransformer加载
我们使用SentenceTransformer加载一个多语言句子嵌入模型,并输出模型的相关信息。
3.1 示例演示
from sentence_transformers import SentenceTransformer
import torch
# 加载多语言句子嵌入模型
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# 模型信息展示
print(f"模型类型: {type(embedder).__name__}")
print(f"模型设备: {embedder.device}")
print(f"模型参数量: {sum(p.numel() for p in embedder.parameters()):,}")
# 内存使用统计
model_memory = sum(p.numel() * p.element_size() for p in embedder.parameters())
print(f"模型内存占用: {model_memory / 1024 / 1024:.2f} MB")
# 显示模型配置信息
print(f"嵌入维度: {embedder.get_sentence_embedding_dimension()}")
print(f"最大序列长度: {embedder.max_seq_length}")
print("模型加载完成!")模型加载也是从Hugging Face Transformers库下载,默认也是在用户缓存目录,SentenceTransformer一般用于一些句子嵌入功能,对句子、词语的处理。

示例运行输出结果:
模型类型: SentenceTransformer
模型设备: cpu
模型参数量: 117,653,760
模型内存占用: 448.81 MB
嵌入维度: 384
最大序列长度: 128
模型加载完成!
3.2 代码分析
3.2.1 库导入
from sentence_transformers import SentenceTransformer
import torch- SentenceTransformer: 核心类,专门用于句子和文本段落的嵌入表示
- torch: PyTorch深度学习框架,提供张量计算和GPU支持
3.2.2 模型加载
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')- paraphrase-multilingual-MiniLM-L12-v2 是Hugging Face模型仓库中的预训练模型
- 组件分解:
- paraphrase: 在释义任务上训练,擅长捕捉语义相似性
- multilingual: 支持多语言(50+种语言)
- MiniLM: 轻量级模型架构,通过知识蒸馏得到
- L12: 12层Transformer层
- v2: 第二版本
3.3 模型加载流程

步骤说明:
- 模型标识符解析:解析模型名称确定下载源和本地缓存位置
- 缓存检查与下载:检查本地是否已有模型缓存,若无则从远程仓库下载
- 配置文件解析:读取模型架构配置和超参数设置
- 架构构建:根据配置文件创建空的模型计算图结构
- 权重加载:将预训练参数填充到对应的模型层中
- 设备分配:自动检测并分配模型运行的硬件设备(CPU/GPU)
- 模型初始化完成:获得包含完整权重的可运行模型实例
4. 加载方式总结
4.1 加载方式的区别
4.1.1 使用 from_pretrained(如 transformers 库)
- 这是直接加载 Hugging Face 模型的方式,返回的是基础模型(如 BertModel、RobertaModel 等)。
- 需要自己处理 tokenization、模型前向传播、以及可能的池化操作(如获取句子表示)。
- 适用于需要自定义模型结构或训练过程的场景,例如:
- 只使用模型的某些层、修改模型结构、进行特定任务的微调
4.1.2 使用 SentenceTransformer
- 这是一个高级库,专门用于生成句子嵌入(sentence embeddings),可参考前面的章节都有涉及
- 它封装了模型加载、tokenization、前向传播和池化操作,直接输出句子的向量表示。
- 内部可能使用多个模型(例如,Transformer 和池化层)组合而成。
- 适用于需要快速获取句子嵌入的场景,例如:
- 语义相似度计算、聚类、信息检索
- 在以下情况下,建议使用 SentenceTransformer:
- 任务需求:当你需要获取句子的嵌入表示,并且不需要修改模型内部结构时。
- 方便性:希望用几行代码就实现句子嵌入的生成,而不想处理 tokenization、模型前向传播和池化等细节。
- 性能:SentenceTransformer 的池化方法是为句子嵌入专门设计的(例如,使用均值池化、CLS 池化等),并且已经过优化。
- 多语言支持:SentenceTransformer 提供了许多多语言模型,可以方便地处理多种语言的句子嵌入。
4.2 对比示例参考
# 使用 from_pretrained 获取句子嵌入(以 BERT 为例)
from transformers import AutoTokenizer, AutoModel
import torch
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased')
# 输入句子
sentences = ["This is a sentence.", "This is another one."]
# 手动处理 tokenization 和模型前向传播
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# 使用均值池化获取句子嵌入
embeddings = outputs.last_hidden_state.mean(dim=1)
# ==================================================================
#使用 SentenceTransformer 获取句子嵌入
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
sentences = ["This is a sentence.", "This is another one."]
embeddings = model.encode(sentences)4.3 总结
- SentenceTransformer 更适合即插即用的句子嵌入任务,它简化了流程并提供了优化的池化方法。
- from_pretrained 更适合研究人员和开发者需要自定义模型结构或训练过程的场景。
四、模型应用实例
示例从ModelScope下载Qwen1.5-1.8B-Chat模型,并加载分词器和模型,然后进行中文对话生成测试。
步骤概述:
- 配置模型下载参数并下载模型。
- 加载分词器,并展示分词器的详细信息和测试分词效果。
- 加载模型,并展示模型的详细信息和内存占用。
- 使用加载的模型和分词器进行中文对话生成。
1. 示例代码
import os
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 配置模型下载参数
cache_dir = "D:\\modelscope\\hub" # 本地缓存目录
model_name = "qwen/Qwen1.5-1.8B-Chat" # 模型标识
print("开始模型下载过程...")
print(f"目标模型: {model_name}")
print(f"缓存目录: {cache_dir}")
# 创建缓存目录(如果不存在)
os.makedirs(cache_dir, exist_ok=True)
print(f"缓存目录创建/验证完成")
# 执行模型下载
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision='master', # 模型版本,默认为master
ignore_file_pattern=None # 不忽略任何文件
)
print(f"模型下载完成!")
print(f"本地路径: {local_model_path}")
def load_tokenizer_detailed(local_model_path):
"""
详细的分词器加载过程
"""
print("\n" + "=" * 60)
print("分词器加载过程")
print("=" * 60)
try:
# 分词器加载参数详解
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True, # 允许执行自定义代码
use_fast=True, # 使用快速分词器
padding_side='left', # 填充方向
truncation_side='right', # 截断方向
local_files_only=True # 只使用本地文件
)
print("分词器加载成功!")
# 分词器信息展示
print(f"分词器类型: {type(tokenizer).__name__}")
print(f"词汇表大小: {len(tokenizer)}")
print(f"填充token: {tokenizer.pad_token}")
print(f"起始token: {tokenizer.bos_token}")
print(f"结束token: {tokenizer.eos_token}")
# 测试中文分词
test_texts = [
"你好,今天天气怎么样?",
"人工智能是未来的发展方向",
"请帮我写一首关于春天的诗"
]
print("\n中文分词测试:")
for text in test_texts:
tokens = tokenizer.tokenize(text)
token_ids = tokenizer.encode(text, add_special_tokens=False)
print(f"文本: {text}")
print(f"分词: {tokens}")
print(f"Token IDs: {token_ids}")
# 尝试将每个token ID单独解码
decoded_tokens = [tokenizer.decode([token_id]) for token_id in token_ids]
print(f"解码每个token: {decoded_tokens}")
print(f"整体解码: {tokenizer.decode(token_ids)}")
print(f"Token数量: {len(tokens)}")
print("-" * 40)
return tokenizer
except Exception as e:
print(f"分词器加载失败: {e}")
return None
tokenizer = load_tokenizer_detailed(local_model_path)
def load_model_detailed(local_model_path):
"""
详细的模型加载过程
"""
print("\n" + "=" * 60)
print("模型加载过程")
print("=" * 60)
try:
# 检查可用内存
import psutil
memory_info = psutil.virtual_memory()
print(f"系统总内存: {memory_info.total / 1024 / 1024 / 1024:.2f} GB")
print(f"可用内存: {memory_info.available / 1024 / 1024 / 1024:.2f} GB")
# 模型加载参数详解
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True, # 允许自定义代码
torch_dtype=torch.float32, # CPU上使用float32
device_map="cpu", # 使用CPU
low_cpu_mem_usage=True, # 优化CPU内存使用
local_files_only=True # 只使用本地文件
)
print("模型加载成功!")
# 模型信息展示
print(f"模型类型: {type(model).__name__}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
print(f"模型设备: {next(model.parameters()).device}")
# 内存使用统计
model_memory = sum(p.numel() * p.element_size() for p in model.parameters())
print(f"模型内存占用: {model_memory / 1024 / 1024:.2f} MB")
return model
except Exception as e:
print(f"模型加载失败: {e}")
return None
model = load_model_detailed(local_model_path)
def chinese_chat_generation(model, tokenizer, prompt, max_length=500):
"""
中文对话生成函数
"""
print("\n" + "=" * 60)
print("中文对话生成")
print("=" * 60)
# 构建对话格式(Qwen专用格式)
formatted_prompt = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
print(f"用户输入: {prompt}")
print("正在生成回复...")
# 编码输入
inputs = tokenizer(
formatted_prompt,
return_tensors="pt",
padding=True,
truncation=True,
max_length=1024
)
# 生成参数配置
generation_config = {
"max_length": max_length,
"do_sample": True, # 使用采样而不是贪婪解码
"temperature": 0.7, # 控制随机性
"top_p": 0.9, # 核采样参数
"top_k": 50, # Top-k采样
"repetition_penalty": 1.1, # 重复惩罚
"pad_token_id": tokenizer.eos_token_id,
"eos_token_id": tokenizer.eos_token_id
}
# 生成回复
with torch.no_grad():
outputs = model.generate(
**inputs,
**generation_config
)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=False)
# 提取助手回复
if "<|im_start|>assistant\n" in response:
assistant_response = response.split("<|im_start|>assistant\n")[-1]
if "<|im_end|>" in assistant_response:
assistant_response = assistant_response.split("<|im_end|>")[0]
else:
assistant_response = response
print(f"助手回复: {assistant_response.strip()}")
return assistant_response.strip()
# 中文测试用例
chinese_test_prompts = [
"你好,请介绍一下你自己",
"什么是人工智能?它有哪些应用领域?",
"请写一首关于秋天的七言绝句",
"如何学习编程?给初学者一些建议",
"解释一下机器学习中的过拟合现象"
]
# 执行测试
for i, prompt in enumerate(chinese_test_prompts[:2]): # 先测试前两个
print(f"\n对话 {i+1}:")
chinese_chat_generation(model, tokenizer, prompt)2. 输出结果
开始模型下载过程...
目标模型: qwen/Qwen1.5-1.8B-Chat
缓存目录: D:\modelscope\hub
缓存目录创建/验证完成
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-18 16:00:29,266 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
2025-11-18 16:00:29,392 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat].
2025-11-18 16:00:29,393 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat.
模型下载完成!
本地路径: D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat============================================================
分词器加载过程
============================================================
✅ 分词器加载成功!
分词器类型: Qwen2TokenizerFast
词汇表大小: 151646
填充token: <|endoftext|>
起始token: None
结束token: <|im_end|>中文分词测试:
文本: 你好,今天天气怎么样?
Token IDs: [108386, 3837, 100644, 104307, 104472, 11319]
解码每个token: ['你好', ',', '今天', '天气', '怎么样', '?']
整体解码: 你好,今天天气怎么样?
Token数量: 6
----------------------------------------
文本: 人工智能是未来的发展方向
Token IDs: [104455, 20412, 100353, 103949, 100696]
解码每个token: ['人工智能', '是', '未来', '的发展', '方向']
整体解码: 人工智能是未来的发展方向
Token数量: 5
----------------------------------------
文本: 请帮我写一首关于春天的诗
Token IDs: [14880, 108965, 61443, 108462, 101888, 105303, 9370, 100045]
解码每个token: ['请', '帮我', '写', '一首', '关于', '春天', '的', '诗']
整体解码: 请帮我写一首关于春天的诗
Token数量: 8
----------------------------------------============================================================
模型加载过程
============================================================
系统总内存: 15.78 GB
可用内存: 7.65 GB
✅ 模型加载成功!
模型类型: Qwen2ForCausalLM
模型参数量: 1,836,828,672
模型设备: cpu
模型内存占用: 7006.95 MB对话 1:
============================================================
中文对话生成
============================================================
用户输入: 你好,请介绍一下你自己
正在生成回复...
🤖 助手回复: 您好!我是来自阿里云的大规模语言模型,我叫通义千问。作为一个人工智能助手,我可以回答各种问题、提供信息、生
成文本、创作代码、编写程序、聊天等任务。我的目标是通过深度学习和自然语言处理技术,帮助用户更加便捷、高效地获取所需的知识
和信息。我采用的是预训练的语言模型架构,经过大量数据的训练,能够理解和生成多种语言,包括中文、英文、日文、法文、西班牙文、德文、
韩文、阿拉伯文等,并且在问答、撰写故事、翻译、聊天等方面具有出色的性能。我可以理解并回答与各类主题相关的开放性问题,如科
技、历史、文化、生活、娱乐、体育、健康等,以及特定领域的专业知识,如股票投资、编程、烹饪、摄影、音乐、电影、书籍推荐、天
气预报等。在使用过程中,您可以向我提问任何您想了解的问题,无论是简单的一般性问题,还是复杂的深度探究,我都会尽力为您提供准确、全面
的回答。同时,我也支持多轮对话和连续对话,可以进行深入的交流和讨论,让您的需求得到更细致、更个性化的满足。如果您有任何其他问题或需要帮助,请随时告诉我,我会尽我所能提供支持和解答。我期待着与您的沟通和合作,共同推动人工智能的发
展和应用,为人类的生活带来更多便利和智能化的可能性。对话 2:
============================================================
中文对话生成
============================================================
用户输入: 什么是人工智能?它有哪些应用领域?
正在生成回复...
🤖 助手回复: 人工智能(Artificial Intelligence,简称AI)是一种计算机科学分支,旨在创建智能机器和系统,使其能够模拟人类的
智能行为。通过使用算法、统计学、机器学习、深度学习等技术,AI系统可以自动从数据中提取模式和规律,从而实现自主决策、自我学
习和自我优化。以下是人工智能的主要应用领域:
1. 自动化:人工智能在自动化领域的应用最为广泛,包括自动驾驶汽车、智能家居、机器人技术、工业自动化、金融风控等领域。例如
,自动驾驶汽车需要通过传感器收集路况信息,然后利用深度学习算法分析这些信息以做出驾驶决策;智能家居则可以通过物联网设备连
接到互联网,实现对家庭环境的智能化控制和管理;机器人技术则可以帮助工厂进行生产流程自动化,提高效率和准确性。2. 语音识别与自然语言处理:人工智能在语音识别和自然语言处理领域的应用日益增强,如智能客服、语音助手、文本生成、翻译工具
、情感分析等。例如,智能客服系统可以根据客户的问题和需求,快速准确地提供服务支持;语音助手如Siri、Alexa等可以理解用户的
指令,并执行相应的操作;文本生成则可以帮助企业撰写新闻稿、邮件、报告等;翻译工具则可以帮助人们跨越语言障碍进行沟通交流。3. 图像识别与计算机视觉:图像识别和计算机视觉是人工智能的重要组成部分,主要用于物体检测、人脸识别、图像分类、图像分割、
目标跟踪等任务。例如,在安防领域,图像识别可用于监控摄像头捕捉的画面,以便及时发现异常行为或可疑物品;在自动驾驶车辆中,
计算机视觉用于识别道路标志、行人、车辆等,帮助车辆做出安全行驶决策;在医疗影像诊断中,计算机视觉可用于检测肿瘤、血管病变
等病理特征。4. 机器学习与预测模型:机器学习和预测模型是人工智能的核心算法,它们用于从大量数据中学习规律并建立预测模型,从而解决复杂
问题。例如,在金融风控领域,机器学习可用于评估贷款申请人的信用风险;在推荐系统中,推荐系统可以根据用户的历史行为和偏好,
为他们推荐可能感兴趣的商品或内容;在天气预报中,机器学习可用于预测未来几天的天气变化趋势。5. 智能辅助决策:人工智能还可以应用于智能决策支持系统,通过分析大量的历史数据和实时信息,为用户提供个性
五、总结
经过今天的学习,我们已经掌握了在本地CPU环境下加载和运行AI模型的核心技能。我们从最基础的from_pretrained()方法开始,逐步深入到更高级的配置参数,涵盖了trust_remote_code、torch_dtype、device_map等关键概念的理解和应用,这些知识打开了在个人设备上探索AI世界的大门。
回顾整个过程,最重要的收获不仅仅是学会了如何加载模型,更重要的是建立了对模型加载机制的全面理解。现在应该能够根据不同的需求选择合适的加载方式:无论是使用Hugging Face Hub的便捷一键加载,还是通过ModelScope获取更适合中文场景的模型,亦或是从本地路径加载预先下载的模型文件。这种灵活性让你在面对各种实际场景时都能游刃有余。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)