【大模型】理论基础(3):transformer,模型架构的基座

目录
1.概述
可以说当前绝大多数都是transformer的,所以说transformer是模型架构的基座,不为过。几乎可以说弄懂了transformer就弄懂了AI模型的架构以及工作过程和原理。
计算机要完整的理解一个句子,肯定要完整的知道每个词在句子中的位置和具体含义,很显然每个词在句子中的意思都是由上下文决定的,计算机要理解这句话就肯定要去理解每个词和上下文之间的联系,这就是transformer的核心所在。
2.分词
首先将输入分词,然后用词嵌入的方式做成词向量:
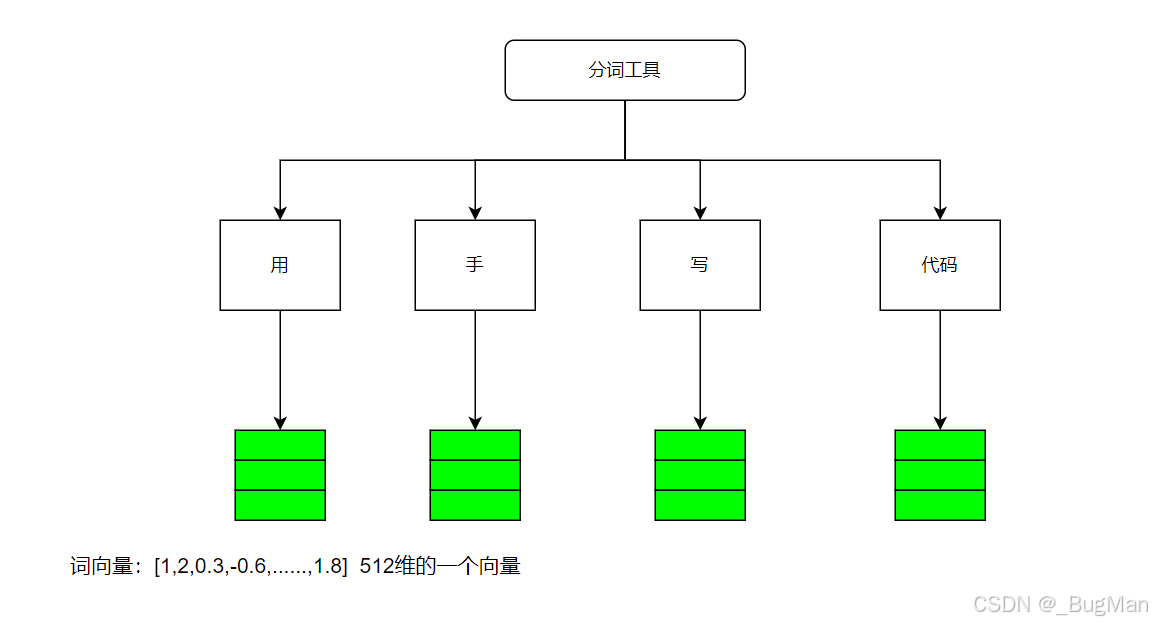
3.位置信息
分词之后,各个词并不知道自己在句子中的位置,所以要加入位置信息:
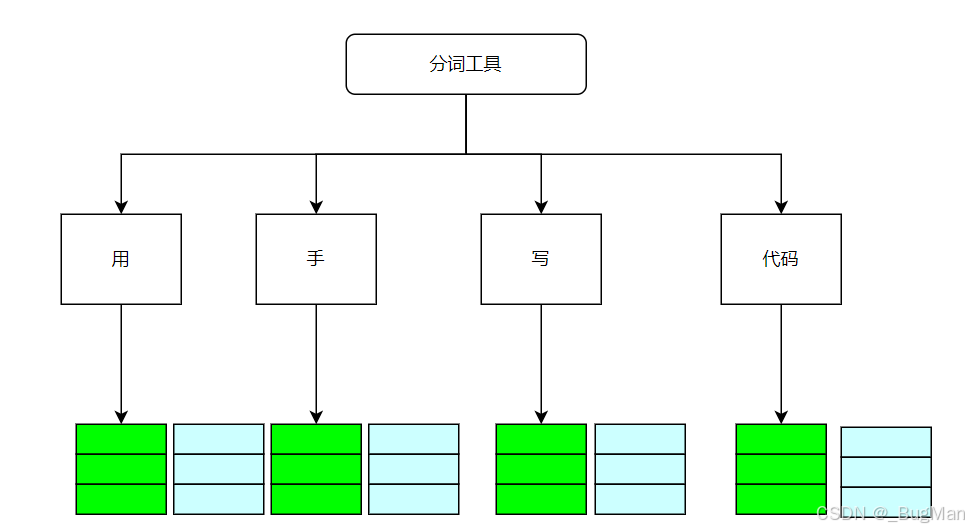
注意:不会改变形状,两个向量运算后的结果,每个词仍然是512维的向量。
4注意力机制
4.1.q、k、v矩阵
分词以及加上位置信息后的词向量,要和qkv矩阵继续做运算,从而实现注意力机制,所以要首先搞懂什么是qkv矩阵。
核心类比:图书馆查资料:
想象一下,你要去一个巨大的图书馆(这个图书馆就是输入文本的序列)里,为你的研究课题(比如“人工智能的风险”)查找相关资料。
-
查询: 就是你脑子里的问题:“人工智能有哪些风险?” 这就是你的 Query。
-
键: 图书馆里每本书的书名、目录和关键词标签。这些“键”帮助你快速判断一本书是否相关。这就是 Key。
-
值: 书里面具体的文字内容。当你通过“键”找到一本相关的书后,你真正需要阅读和吸收的是它的“值”。
自注意力机制的过程就是:
-
用你的Query去和图书馆里所有书的Key进行匹配,计算一个相关度分数。
-
根据这个分数,决定你从每本书的Value中汲取多少信息。
-
最后,你综合所有书的信息,形成了一个关于“人工智能风险”的丰富理解。
QKV是提前用海量数据训练好的一个权重矩阵,用输入矩阵方便乘以三个权重矩阵,就能投影到三个维度上去:
-
乘以 W*Q 后,我们得到了一个专门用于发起询问的向量(Query)。
-
乘以 W*K 后,我们得到了一个专门用于被检索的向量(Key)。
-
乘以 W*V 后,我们得到了一个专门用于提供信息的向量(Value)。
4.2.自注意力机制
每个词都与QKV矩阵相乘:
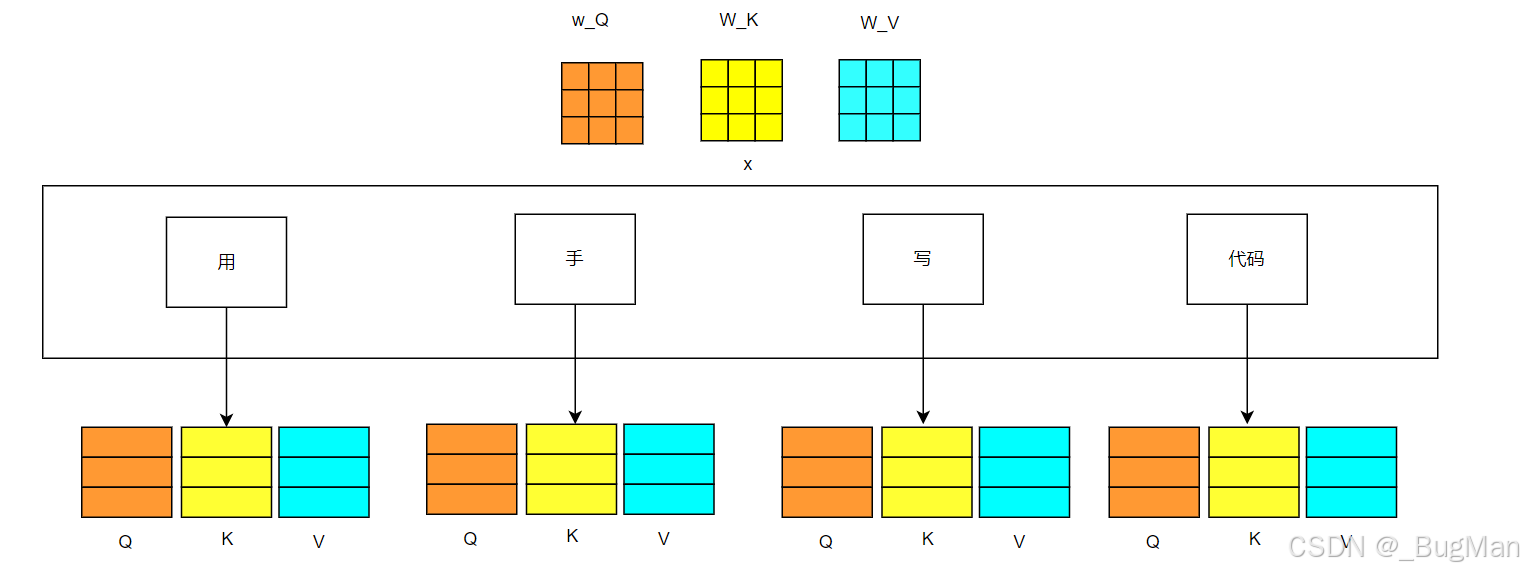
这样就能得到每个词:
-
当前词想要关注什么?
-
能为其他词提供什么?(类似于标签和索引)
-
当前词实际包含的内容
得到每个词的QKV矩阵后,再与句子中其他词的QKV进行点积,然后加权求和,这样每个词都能得到一个新的词向量,这个新的词向量中包含了上下文的所有信息。这就是transformer的自注意力机制。
但是一套QKV的注意力可能比较片面,所以可以用训练出来的,多个维度的不同套的QKV来对句子进行多次自注意力机制,然后再加权得到多头自注意力机制的最新词向量。
注意:所有运算后不会改变形状,每个词仍然是512维的向量。
5.编码器
梯度消失问题:
模型还没有训练到最优状态,但是梯度等于0或者趋近于0了,这就叫梯度消失。梯度消失的原因是神经网络中有些层级带入计算导数的时候导数算出来为0或者趋近于0,这就会导致求导求导改层后,梯度就消失了,明明后面的层级还没有训练好。这时候加一个残差网络,去处理一下梯度消失即可。
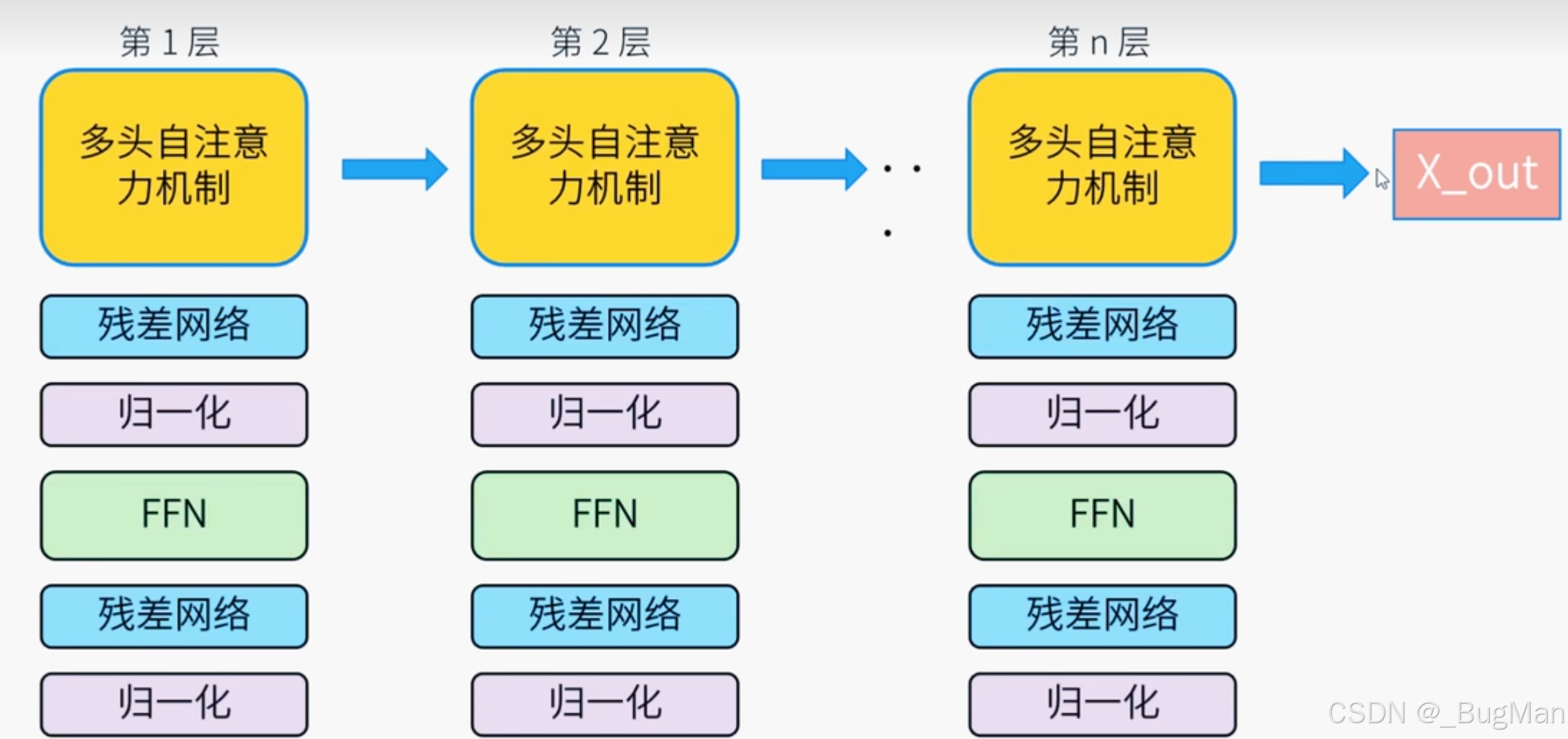
为了保证推理的准确性,神经网络中每一层都会计算一次多头注意力机制,但是会存在梯度消失的问题,所以每层加了一个残差网络进行,FFN是激活函数,归一化是用来做归一化的处理。这些所有的附加层合在一起有一个统一的名称叫编码器。
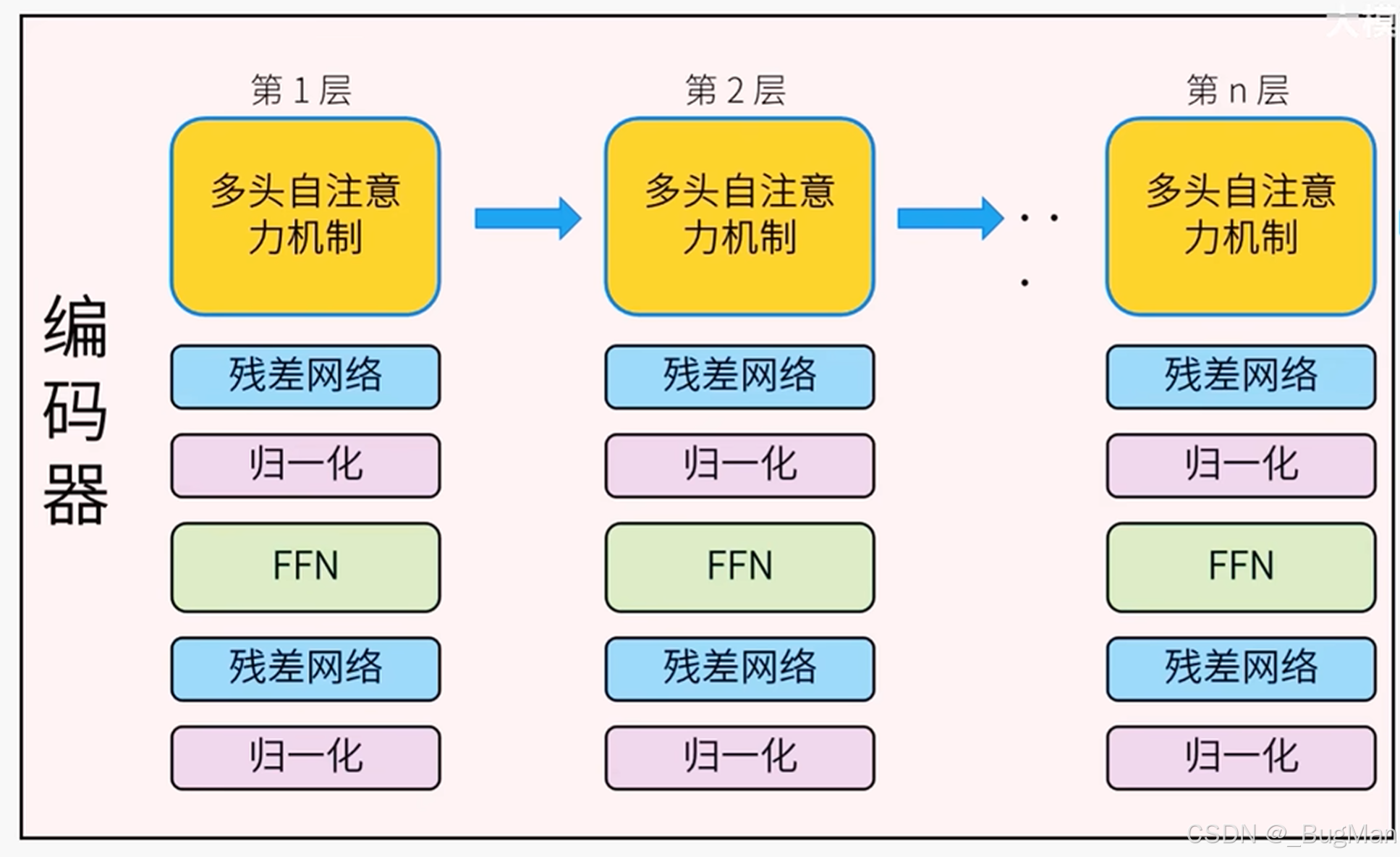
编码器的核心功能就是:去理解输入的语言。
注意:所有运算,不会改变形状,每个词仍然是512维的向量。
6.解码器
解码器主要负责产生、处理输出。里面的残差网络、归一化、FFN和编码器作用都是一样的,不同点在:掩码多头自注意力机制、交叉注意力机制。这两个注意力机制就是分别和上下文进行交叉,去注意到上下文的语义,从而生成和上下文语义想复合的输出。
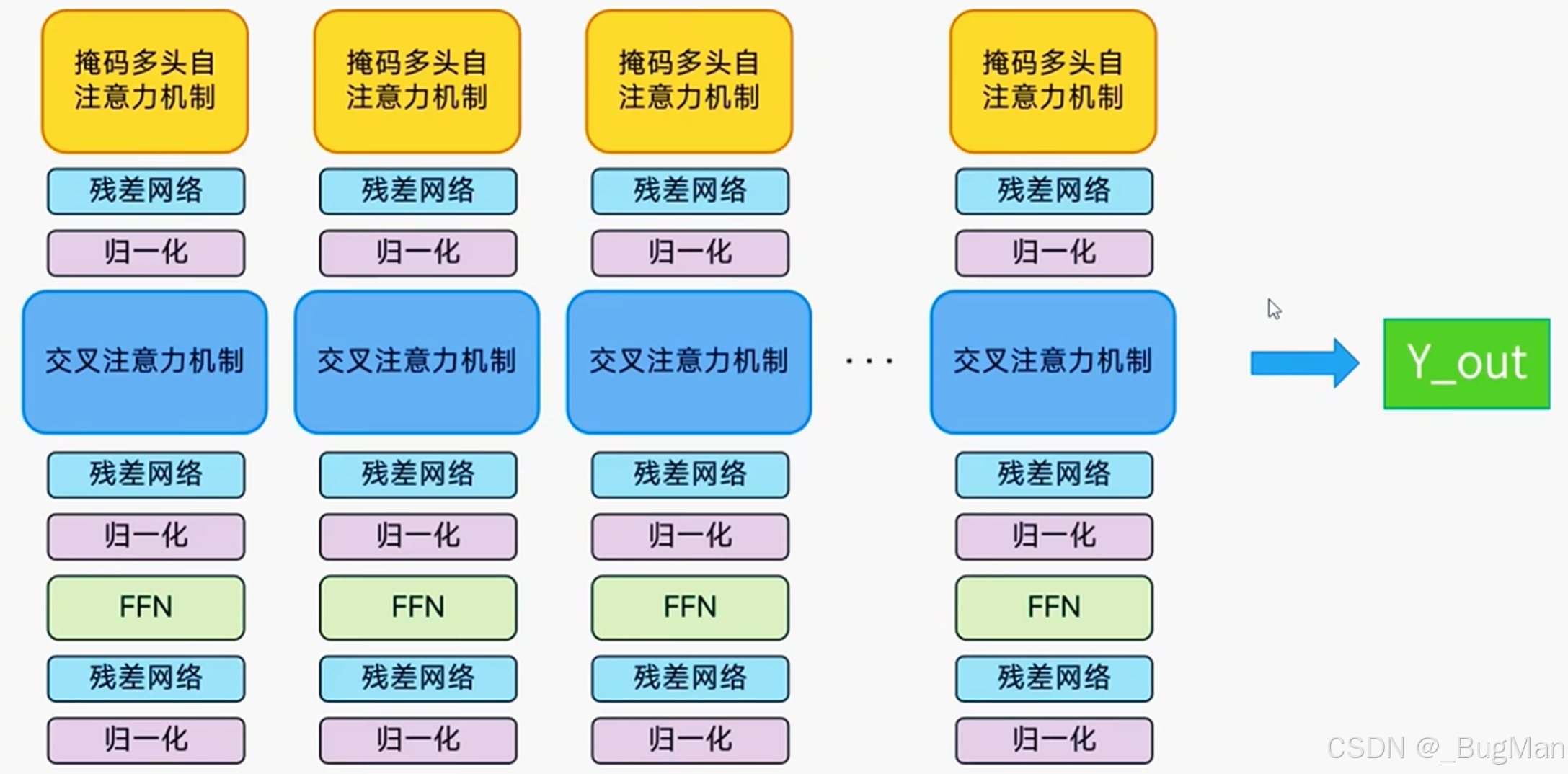
注意:所有运算,不会改变形状,每个词仍然是512维的向量。
7.输出映射到单词
一个transformer上下文推理的完整过程:
词汇表:
首先模型在训练阶段会根据输入的数据集生成一个巨大的词汇表,这个词汇表里面就只是单纯的包含所有词,假设这个词汇表的长度是5000,整个词汇表就是个长度为5000的向量。
1.通过自注意力机制去携带上下文信息
假设我们的输入序列是:“今天的天气很” -> 被分词为 ["今", "天", "的", "天", "气", "很"](6个tokens)。
-
每个token首先通过嵌入层(Embedding Layer) 被转换成一个低维的、密集的向量(比如一个长度为768的向量)。现在我们得到一个形状为
[6, 768]的矩阵。 -
这个矩阵经过Transformer块(包含自注意力层和前馈网络层)的多层复杂计算后,输出的仍然是一个
[6, 768]的矩阵。 -
这个输出矩阵的每一行(即每个向量),都已经不再是孤立的“今”、“天”等字的表示,而是融合了整个句子所有token信息的“上下文向量”。 例如,最后一个token
"很"对应的向量,已经包含了“今天的天气很”这整个片段的语义信息。
2.关键的最后一步:输出层(投影到词汇空间)
现在,我们有了这个富含信息的上下文矩阵 [6, 768]。模型的目标是预测下一个词。因此,我们只关心序列中最后一个位置的输出向量(即对应 "很" 的那个向量),因为它包含了之前所有词的全部上下文信息。
-
我们取出这个最后一个位置的向量,假设它的形状是
[1, 768]。 -
现在,我们需要将这个向量“翻译”成模型接下来要说什么词。如何翻译?通过一个叫做输出层(Output Layer) 或语言模型头(LM Head) 的线性层(Linear Layer / Fully Connected Layer)。
-
这个输出层本质上是一个权重矩阵,其形状为
[768, 50000](假设隐藏维度是768,词汇表大小是50000)。 -
数学操作: 我们将这个
[1, 768]的向量与[768, 50000]的权重矩阵相乘。 -
计算结果: 相乘后会得到一个
[1, 50000]的向量 -
然后去取出概率最大的一个词来即可。
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)