【论文阅读18】-BearingFM:基于领域知识和对比学习的轴承故障诊断基础模型
题目:BearingFM: Towards a foundation model for bearing fault diagnosis by domain knowledge and contrastive learning期刊:International Journal of Production Economics检索情况:作者:单位:发表年份:DOI:设备预测性维护对保障精密制造(如半导体
😊文章背景
题目:BearingFM: Towards a foundation model for bearing fault diagnosis by domain knowledge and contrastive learning
期刊:International Journal of Production Economics
检索情况:
作者:
单位:
发表年份:
DOI:
网址:
❓ 研究问题
设备预测性维护对保障精密制造(如半导体)供应链至关重要。轴承作为核心部件,其故障诊断是重中之重,面临以下痛点:
-
泛化性差: “一机一模型”,为不同设备、不同工况训练专用模型,成本高昂,难以规模化部署。
-
依赖标注数据: 高质量故障数据标注极度依赖领域专家,费时费力,是实际应用的主要瓶颈。
📌 研究目标
提出BearingFM:设计一个充分利用海量无标签振动数据并能快速适配新设备、新任务轴承故障诊断基础模型。
🧠 所用方法
整体框架
基于云-边-端协同的通用轴承故障诊断框架
实现了知识共享(云)与个性化定制(边)的完美结合:
-
云端(大脑): 利用强大算力,聚合海量无标签数据,预训练通用基础模型。
-
边缘端(专家):接收基础模型,使用特定场景的少量标注数据进行高效领域微调,并根据终端设备工况进行个性化模型压缩。
-
终端(哨兵): 将轻量化的模型部署在车间现场的物联网设备上,实现低延迟、低成本的实时故障诊断。
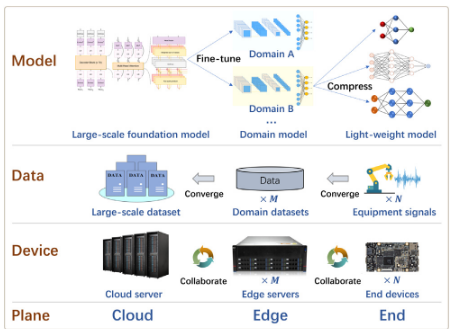
BearingFM的总体框架
第一阶段:信号采集和预处理
-
数据来源:从电机、泵、机器人等工业设备采集振动信号。
-
信号获取:通过传感器采集设备运行时的原始振动信号。
-
数据预处理:对原始信号进行三步处理,将其转化为标准、规整的样本,为后续训练做准备:
-
重采样:将不同转速下采集的信号统一到标准转速,消除转速变化带来的干扰。
- 滑动窗口:将连续的长信号截成一段段固定长度的短信号。
- 分段:形成最终模型可处理的、一个个标准化的振动信号样本。
第二阶段:基于故障机制的数据增强(流程图核心创新区)
-
分支:每一个预处理后的原始样本,都会同时进入两个平行的增强通道。
-
通道一:信号级增强:对样本进行通用变换,如加随机噪声、幅度缩放等。目的是提升模型对随机干扰的鲁棒性。生成信号视图 。
-
通道二:机理级增强(核心创新):对样本进行基于轴承故障物理知识的智能变换。它会根据轴承故障的特征频率,仅在非关键频段添加噪声,从而保留故障最核心的特征。生成机理视图。它们看起来不同,但代表同一个故障本质。
第三阶段:时间和知识层面的对比学习
-
模型输入:将上述生成的一对“孪生”视图(信号视图和机理视图)输入到模型的编码器中,负责将振动信号转换为高维的特征向量。
-
时序级对比学习:使用Transformer模型,让模型从信号增强视图的“过去”预测机理增强视图的“未来”,反之亦然,强化模型提取时间序列中本质特征的能力。
-
知识级对比学习:在一个批次中,将同一样本的两个增强视图(信号视图和机理视图)作为正样本对,与其他样本的视图作为负样本对,通过计算对比损失,引导模型学习故障的不变特征。
- “找相同”:让模型知道,同一个样本产生的信号视图和机理视图是“双胞胎”(正样本对),它们在特征空间中的距离应该很近。
- “辨不同”:让模型知道,这个样本的视图与批次中其他样本的视图是“陌生人”(负样本对),它们在特征空间中的距离应该很远
4.最终输出:通过这种大量的对比训练,模型最终学会忽略无关的干扰(信号增强引入的),并牢牢抓住故障最本质、不变的特征(机理增强所保护的),从而得到一个非常强大和智能的轴承故障诊断基础模型。
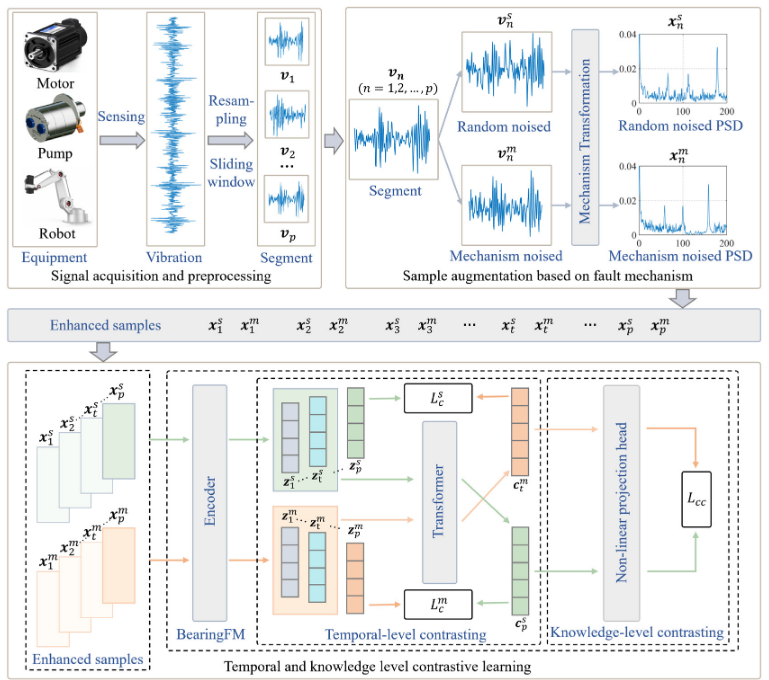
🧪 实验设计与结果
一、实验设计
-
数据集: 使用多个公开权威数据集(如CWRU, PU等)进行验证,确保结果可信。
-
基线模型: 与多种主流故障诊断模型进行对比。
-
评估指标: 准确率(Accuracy)、F1分数(F1-Score)等。
二、实验结果
实验结果一(半监督实验):
在仅使用1.2%的标签数据进行微调的情况下,BearingFM在多个数据集上的故障分类准确率均达到约98%,显著优于所有基线模型。
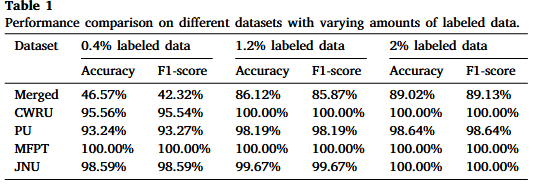
实验结果二(零样本实验):
在“零样本”实验(训练集完全不含目标工况数据)中,模型仍能取得高精度,证明了其强大的跨工况泛化能力。
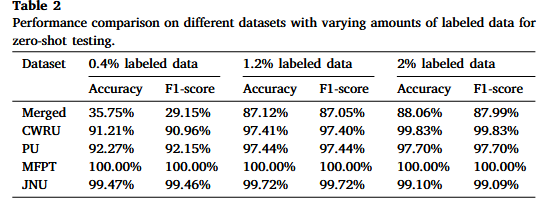
实验结果三:
使用预训练权重初始化模型可以显著加速收敛。
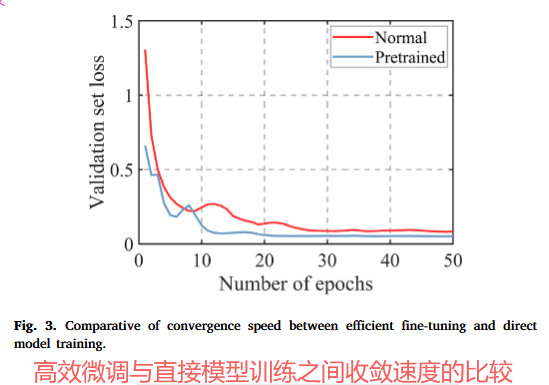
实验结果四(消融实验):
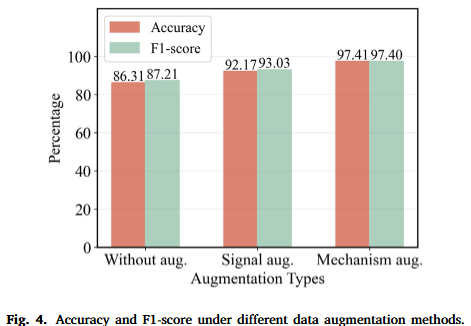
消融实验证明,移除机理级增强后,模型性能显著下降,直接验证了该创新点的关键作用。
✅ 研究结论
-
本研究成功提出了BearingFM,一种创新的轴承故障诊断基础模型。
-
它通过云边协同框架和领域知识赋能的对比学习,有效解决了工业场景中标注数据稀缺和模型泛化性差两大核心挑战。
-
实验证明,该模型能以极少的标注成本实现高性能、高泛化能力的诊断。
📈 研究意义
这项研究不仅提出了一个创新的技术框架,更探索了一条将前沿AI理念(基础模型、对比学习)与工业领域知识深度融合的路径,为破解工业智能运维的规模化应用难题提供了极具价值的解决方案。
🔮 未来研究方向
-
扩展数据源: 纳入更多特定行业(如半导体制造)的专有数据,使基础模型更强大。
-
迈向开放集诊断: 未来研究将致力于让模型不仅能识别已知故障,还能检测出未知的、新的故障类型,更贴近实际需求。
-
模型轻量化: 进一步优化模型,以适应资源更受限的终端设备。
思考与启发

- 模态对齐可以通过对比学习的方法实现;
- 对比学习需要数据增强。
📕专业名词
1. 核心模型与方法论
-
BearingFM: 本文提出的轴承故障诊断基础模型的名称。您可以把它想象成一个经过“海量阅读”(无标签数据训练)的“轴承故障专家”,掌握了轴承故障的普遍规律,只需稍加“点拨”(少量数据微调)就能快速适应新的具体任务。
-
Foundation Model (基础模型): 指在广泛数据上大规模预训练的模型(如GPT-4)。本文目标是构建一个轴承诊断领域的专用基础模型,使其具备强大的泛化能力。
-
Semi-supervised Learning (半监督学习): 一种机器学习方法,模型同时使用大量没有标签的数据和少量有标签的数据进行训练。这模仿了人类的学习方式:通过观察大量现象(无标签)来形成概念,再通过少量明确指导(有标签)来精确化。
-
Contrastive Learning (对比学习): 一种自监督学习技术。核心思想是“物以类聚,人以群分”——让模型学习到同类样本(如同一故障的不同数据视图)在高维空间中的表示彼此接近,而不同类样本的表示彼此远离。
-
Fine-tuning / Efficient Fine-tuning (微调/高效微调): 迁移学习的关键步骤。指在一个已经预训练好的通用模型(基础模型)基础上,使用特定领域的少量数据对其进行“二次训练”,使其专门化于新任务。这比从零训练一个新模型要快得多,成本也低得多。
2. 系统架构与部署
-
Cloud-Edge-End Collaboration (云-边-端协同): 一种分层计算架构。
-
Cloud (云): 指远程的强大服务器集群,负责海量数据存储和基础模型训练。
-
Edge (边): 指靠近工厂车间的服务器(如车间服务器),负责接收云端的基础模型,并根据本地数据进行快速微调和优化。
-
End (端): 指直接安装在机器设备上的物联网设备,负责运行最终优化后的轻量级模型,实现实时故障诊断。
-
这种架构结合了云端的强大算力和终端的实时性优势。
-
-
IoT (Internet of Things) Devices (物联网设备): 指那些嵌入在物理对象(如轴承)中,能够连接互联网并收集、交换数据的微型计算设备。在本文中,即指安装在设备上用于采集振动信号的传感器和微型计算机。
3. 故障类型与信号处理
-
Fault Diagnosis (故障诊断): 本文的核心任务,即通过分析设备运行数据(如振动信号)来判断设备是否发生故障,并确定故障的类型和位置。
-
Vibration Signal (振动信号): 本文主要处理的数据类型,由加速度传感器采集。轴承发生故障时会产生独特的振动模式,就像人生病时会有特定的症状一样。
-
Inner Race Fault (IR, 内圈故障): 轴承内圈滚道上的损伤。
-
Outer Race Fault (OR, 外圈故障): 轴承外圈滚道上的损伤。
-
Ball Fault (BF, 滚动体故障): 轴承滚动体(滚珠或滚子)表面的损伤。
-
Normal Condition (NC, 正常状态): 轴承健康无故障的运行状态。
-
Data Augmentation (数据增强): 一种通过对现有数据进行各种变换(如加噪声、拉伸)来人工扩充数据量的技术,旨在提高模型的泛化能力和鲁棒性。本文特别提出了基于故障机理的增强方法。
4. 实验与评估
-
Zero-shot Generalization (零样本泛化): 指模型能够处理在训练过程中从未见过的新类别或新场景的能力。在本文实验中,特意将某些工况的数据完全排除在训练集之外来测试模型的这种能力。
-
Accuracy (准确率): 模型正确预测的样本数占总样本数的比例。
-
F1-score (F1分数): 综合考量了模型精确率(预测出的故障中有多少是真正的故障)和召回率(真正的故障中有多少被预测出来了)的评估指标,比单一准确率更能全面反映模型性能,尤其在数据类别不均衡时。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)