超级全面的人工智能入门资料
本文系统介绍了人工智能的定义、发展历程、核心目标、关键技术、应用领域及伦理问题。人工智能作为计算机科学的重要分支,旨在开发能执行人类智能任务的系统。文章详细阐述了人工智能在推理、知识表示、机器学习等方面的核心目标,以及搜索优化、神经网络等关键技术。同时,探讨了AI在医疗、金融、军事等领域的广泛应用,并分析了隐私、算法偏见等伦理挑战。最后,文章展望了人工智能的未来发展,包括超级智能的可能性。全文为A
每次别人问我如何学习AI,我都会推荐维基百科(enwikipedia)的AI词条。我自己查阅过各类AI入门书籍、视频课,认为该词条是最理想的教材,特点如下:
1、全面、权威,覆盖了AI方方面面话题,内容严谨,参考文献丰富,叙述严谨。
2、快速阅读入门,扩展阅读深入学习:因为词条里边大量专业词语和概念本身也是词条,如果你感兴趣完全可以随着阅读的深入持续探索进一步的话题学习,可以说是一个完备的百科知识库。
例如下图,是词条的开头部分,里边蓝色的都是可以点开延伸阅读的超链接。这就让我们学习起来非常方便,既可以粗读笼统概念,也可以点进去深入学习。例如阅读中我就对formal logic和symbolic ai不太理解,点进去以后会有更加详细的词条解读。

为了方便大家学习,我用claude把该词条翻译成中文(因为合规问题删除了部分内容),大家可以阅读学习,但我更加强烈推荐去原网页学习,灵活的扩展深入,非常方便!
另外,针对B端产品经理如何学习AI,我也做过一期直播课,想免费学习的同学,可以加我微信,在置顶朋友圈可以学习直播课,微信:pmYangKunGo
以下是大纲和正文:
一、人工智能概述
-
人工智能的定义与核心能力
-
人工智能的高关注度应用及隐性应用现象
-
人工智能的研究子领域、目标与技术基础
-
人工智能的发展历程(学科确立、乐观期与 “AI 寒冬”、关键增长节点)
二、人工智能的核心目标
-
推理与问题解决(技术演进与核心难题)
-
知识表示(基础概念、应用场景与关键挑战)
-
规划与决策(智能体定义、决策机制与理论支撑)
-
学习(机器学习定义、学习类型与评估维度)
-
自然语言处理(NLP)(核心功能、技术发展与模型突破)
-
感知(机器感知定义与关键研究方向)
-
社会智能(情感计算与应用局限)
-
通用智能(通用人工智能的能力特征)
三、人工智能的关键技术
-
搜索与优化(状态空间搜索、局部搜索)
-
逻辑(形式逻辑、演绎推理、模糊与非单调逻辑)
-
不确定性推理的概率方法(核心工具与贝叶斯网络应用)
-
分类器与统计学习方法(分类器定义、常见分类器类型)
-
人工神经网络(结构、学习算法与常见网络类型)
-
深度学习(定义、特征提取能力与发展原因)
-
GPT(生成式预训练 Transformer)(模型特点、训练过程与应用)
-
硬件与软件(核心硬件演变、编程语言发展)
四、人工智能的应用领域
-
21 世纪 20 年代核心应用场景
-
医疗健康领域的应用与成果
-
游戏领域的技术测试与突破
-
数学领域的应用、挑战与专用模型
-
金融领域的应用现状与专家观点
-
军事领域的部署与实战应用
-
生成式 AI 的定义、工具与行业应用
-
AI 智能体(Agents)的功能与应用场景
-
网络搜索领域的 AI 应用(微软、谷歌案例)
-
性相关领域的 AI 应用与伦理争议
-
其他行业特定任务(灾害管理、农业、天文学等)
五、人工智能的伦理问题
-
人工智能的潜在益处与风险概述
-
隐私与版权风险(数据收集、版权争议)
-
科技巨头主导的市场现状
-
能源需求与环境影响(能耗预测、区域政策)
-
虚假信息的产生与应对
-
算法偏见与公平性(案例、成因与争议)
-
系统透明度缺失的问题与解决尝试
-
不良行为者与 AI 武器化风险
-
技术性失业的风险与专家分歧
-
人工智能的生存风险(争议、案例与应对讨论)
六、伦理机器与价值观对齐
-
友好 AI 的定义与研发优先级
-
机器伦理(计算道德学)的目标与起源
-
人工道德智能体与罗素三原则等理论
七、开源
-
AI 开源社区的活跃组织
-
开源权重模型的特点、应用与滥用风险
-
开源模型的安全建议(预发布审核等)
八、伦理框架
-
典型伦理框架(如 Care and Act Framework)的核心维度
-
其他伦理框架(阿西洛马会议共识等)与争议
-
伦理框架落地的跨角色协作要求
-
英国 AI 安全研究所的 “Inspect” 测试工具集
九、监管
-
人工智能监管的定义与与算法监管的关联
-
全球 AI 监管政策与战略(国家 / 区域案例)
-
国际组织与机构的 AI 治理举措
-
关键监管事件(全球 AI 安全峰会、欧盟 AI 法案等)
-
不同国家民众对 AI 监管的态度
十、历史
-
人工智能的早期理论基础(机械推理、图灵计算理论)
-
人工智能学科的正式确立(1956 年达特茅斯研讨会)
-
20 世纪 60-90 年代的发展起伏(乐观预测、“AI 寒冬”、技术转向)
-
21 世纪以来的突破(深度学习、AGI 相关成果)
-
人工智能专利的全球分布(2024 年中、美数据)
十一、哲学
-
人工智能哲学的核心辩论主题
-
人工智能的定义争议(图灵测试、多视角定义)
-
人工智能方法的评估(符号主义 AI 局限、Neat vs. Scruffy 等)
-
机器意识、感知与心智的哲学讨论
-
计算主义与功能主义的观点与争议
-
人工智能的福祉与权利相关讨论
十二、未来
-
超级智能与奇点(定义、“智能爆炸” 理论与技术发展规律)
-
超人类主义(人机融合预测与理论起源)
-
科幻作品中的人工智能(“机器人” 术语起源、经典主题与案例)
人工智能(Artificial Intelligence)
人工智能(Artificial Intelligence,简称 AI)指计算系统执行通常与人类智能相关任务的能力,这些任务包括学习(learning)、推理(reasoning)、问题解决(problem-solving)、感知(perception)和决策(decision-making)。它是计算机科学(computer science)领域的一个研究方向,致力于开发和研究相关方法与软件,使机器能够感知周围环境,并运用学习能力和智能采取行动,以最大程度提高实现既定目标的概率 [1]。
人工智能的高关注度应用案例包括先进的网络搜索引擎(如谷歌搜索(Google Search))、推荐系统(recommendation systems,被 YouTube、亚马逊(Amazon)和网飞(Netflix)采用)、虚拟助手(virtual assistants,如谷歌助手(Google Assistant)、 Siri 和 Alexa)、自动驾驶汽车(autonomous vehicles,如 Waymo)、生成式创意工具(generative and creative tools,如语言模型(language models)和 AI 艺术(AI art)),以及在策略类游戏(如国际象棋(chess)和围棋(Go))中展现出超越人类水平的博弈与分析能力。然而,许多人工智能应用并未被察觉是 “人工智能”:“许多前沿的人工智能技术已融入通用应用中,往往不再被冠以‘人工智能’的名号,因为一旦某项技术足够实用且普及,就不会再被贴上‘人工智能’的标签了。”[2][3]
人工智能研究的多个子领域(subfields)围绕特定目标和特定工具的使用展开。传统的人工智能研究目标包括学习、推理、知识表示(knowledge representation)、规划(planning)、自然语言处理(natural language processing)、感知以及机器人技术支持(support for robotics)[a]。为实现这些目标,人工智能研究者整合并改进了多种技术,包括搜索与数学优化(search and mathematical optimization)、形式逻辑(formal logic)、人工神经网络(artificial neural networks),以及基于统计学(statistics)、运筹学(operations research)和经济学(economics)的方法 [b]。人工智能还借鉴了心理学(psychology)、语言学(linguistics)、哲学(philosophy)、神经科学(neuroscience)等多个领域的理论 [4]。部分企业,如开放人工智能(OpenAI)、谷歌深度思维(Google DeepMind)和元宇宙(Meta)[5],致力于研发通用人工智能(artificial general intelligence,简称 AGI)—— 这种人工智能几乎能像人类一样出色地完成各类认知任务(cognitive task)。
1956 年,人工智能正式成为一门学科 [6]。在其发展历程中,该领域经历了多次乐观发展期 [7][8],随后又进入了被称为 “人工智能寒冬”(AI winters)的失望期与资金缩减期 [9][10]。2012 年后,图形处理器(graphics processing units,简称 GPUs)开始被用于加速神经网络(neural networks)运算,且深度学习(deep learning)的性能超越了以往的人工智能技术,此后人工智能领域的资金投入和关注度大幅提升 [11]。2017 年,随着 Transformer 架构(transformer architecture)的出现,这一增长趋势进一步加速 [12]。21 世纪 20 年代,先进生成式人工智能(advanced generative AI)进入快速发展阶段,被称为 “人工智能热潮”(AI boom)。生成式人工智能创造和修改内容的能力引发了一系列意外后果与危害,人们开始担忧人工智能的长期影响及潜在的生存风险(existential risks),进而推动了关于监管政策(regulatory policies)的讨论,以确保该技术的安全性并充分发挥其效益。
人工智能核心目标(Goals)
模拟(或创造)智能这一总体问题已被拆解为多个子问题,这些子问题对应着研究者期望智能系统(intelligent system)具备的特定特征或能力。以下所述特征受到了广泛关注,且涵盖了人工智能研究的核心范围 [a]。
推理与问题解决(Reasoning and Problem-solving)
早期研究者开发出了模仿人类解决谜题或进行逻辑推理(logical deductions)时所采用的逐步推理算法(algorithms)[13]。到 20 世纪 80 至 90 年代,研究者们结合概率论(probability)和经济学的概念,研发出了处理不确定或不完整信息的方法 [14]。
然而,许多这类算法在解决复杂推理问题时存在局限性,因为它们会面临 “组合爆炸”(combinatorial explosion)问题:随着问题复杂度提升,算法运算速度会呈指数级下降 [15]。即便人类,也很少采用早期人工智能研究中可建模的那种逐步推理方式,而是通过快速、直观的判断(intuitive judgments)来解决大部分问题 [16]。因此,精准且高效的推理仍是一个尚未解决的难题。
知识表示(Knowledge Representation)
本体(ontology)是将某一领域内的知识表示为一组概念(concepts),并定义这些概念间关系的方式。
知识表示与知识工程(knowledge engineering)[17] 使人工智能程序能够智能地回答问题,并对现实世界的事实进行推理。形式化知识表示(formal knowledge representations)被应用于基于内容的索引与检索(content-based indexing and retrieval)[18]、场景解读(scene interpretation)[19]、临床决策支持(clinical decision support)[20]、知识发现(从大型数据库中挖掘 “有价值且可操作的” 推论)[21] 等多个领域 [22]。
知识库(knowledge base)是指以程序可使用的形式存储的知识集合。本体则是某一特定知识领域(domain of knowledge)所涉及的对象(objects)、关系(relations)、概念和属性(properties)的集合 [23]。知识库需要表示的内容包括:对象、属性、类别(categories)及对象间的关系 [24];场景、事件(events)、状态(states)与时间 [25];因果关系(causes and effects)[26];关于知识的知识(即我们对他人所知内容的认知)[27];默认推理(default reasoning,指人类在未被告知相反信息时默认认为正确,且即便其他事实发生变化仍保持正确的情况)[28],以及其他多个知识维度与领域的内容。

本体是将知识表示为一个领域内的概念集合及这些概念之间的关系。
知识表示领域面临的主要难题包括:常识知识(commonsense knowledge)的广度(普通人掌握的原子事实(atomic facts)数量极其庞大)[29];多数常识知识的亚符号形式(sub-symbolic form)(人类掌握的许多知识并非以可口头表达的 “事实” 或 “陈述” 形式存在)[16]。此外,知识获取(knowledge acquisition)—— 即为人工智能应用获取知识的过程 —— 也存在难度 [c]。
规划与决策(Planning and Decision-making)
“智能体”(agent)指能够感知环境并在环境中采取行动的实体。理性智能体(rational agent)拥有目标或偏好(preferences),并会采取行动以实现这些目标 [d][32]。在自动规划(automated planning)中,智能体有明确的特定目标 [33];而在自动决策(automated decision-making)中,智能体具有偏好 —— 存在其更倾向的场景,也存在其试图避免的场景。决策型智能体会为每个场景分配一个数值(称为 “效用”(utility)),用于衡量其对该场景的偏好程度。对于每一种可能的行动,智能体可计算出 “期望效用”(expected utility):即该行动所有可能结果的效用,按结果发生的概率加权计算得出。随后,智能体会选择期望效用最大的行动 [34]。
在经典规划(classical planning)中,智能体明确知晓任一行动将产生的结果 [35]。但在多数现实问题中,智能体可能无法确定自身所处的场景(即场景 “未知” 或 “不可观测”(unobservable)),也无法确定每一种可能行动之后会发生的情况(即结果 “非确定”(non-deterministic))。此时,智能体必须通过概率推测选择行动,随后重新评估场景以判断行动是否有效 [36]。
在部分问题中,智能体的偏好可能具有不确定性,尤其是当涉及其他智能体或人类时。这种偏好可通过学习(如逆强化学习(inverse reinforcement learning))获取,智能体也可通过收集信息来完善自身偏好 [37]。信息价值理论(information value theory)可用于权衡探索性行动或实验性行动的价值 [38]。由于未来可能的行动和场景数量通常极为庞大,难以全部处理,因此智能体在采取行动和评估场景时,往往无法确定最终结果。
马尔可夫决策过程(Markov decision process)包含一个转移模型(transition model)和一个奖励函数(reward function):转移模型描述特定行动导致状态(state)以特定方式变化的概率,奖励函数则定义每个状态的效用及每个行动的成本。策略(policy)用于为每个可能的状态匹配对应的决策。策略可通过计算(如迭代(iteration))、启发法(heuristic)获取,或通过学习得到 [39]。
博弈论(game theory)用于描述多个交互智能体的理性行为,被应用于需与其他智能体交互决策的人工智能程序中 [40]。
学习(Learning)
机器学习(machine learning)是研究如何使程序能自动提升特定任务性能的学科 [41],从人工智能领域诞生之初,机器学习就是其重要组成部分 [e]。
在监督学习(supervised learning)中,训练数据(training data)会标注预期答案;而在无监督学习(unsupervised learning)中,模型(model)需从无标注数据中识别模式(patterns)或结构(structures)。
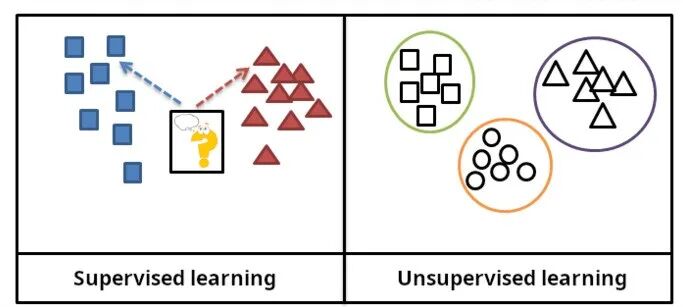
在监督学习中,训练数据被标注了预期答案,而在无监督学习中,模型则从无标注数据中识别模式或结构。
机器学习包含多个分支:无监督学习通过分析数据流(stream of data),在无需其他指导的情况下发现模式并进行预测 [44];监督学习需要为训练数据标注预期答案,主要分为分类(classification,即程序需学习预测输入所属类别)和回归(regression,即程序需根据数值输入推导出数值函数)两类 [45]。
在强化学习(reinforcement learning)中,智能体因做出正确反应而获得奖励,因错误反应而受到惩罚,进而学习选择被判定为 “正确” 的反应 [46]。迁移学习(transfer learning)指将从一个问题中获取的知识应用于新问题 [47]。深度学习(deep learning)是机器学习的一个分支,可将输入数据输入受生物启发的人工神经网络(artificial neural networks),适用于上述所有学习类型 [48]。
计算学习理论(computational learning theory)可从计算复杂度(computational complexity)、样本复杂度(sample complexity,即所需数据量)或其他优化维度(notions of optimization)对学习器(learners)进行评估 [49]。
自然语言处理(Natural Language Processing)
自然语言处理(Natural Language Processing,简称 NLP)使程序能够阅读、书写并以人类语言进行交流 [50],其研究方向包括语音识别(speech recognition)、语音合成(speech synthesis)、机器翻译(machine translation)、信息抽取(information extraction)、信息检索(information retrieval)和问答系统(question answering)[51]。
早期自然语言处理研究基于诺姆・乔姆斯基(Noam Chomsky)的生成语法(generative grammar)和语义网络(semantic networks),但在词义消歧(word-sense disambiguation)[f] 方面存在困难,除非将研究范围限定在称为 “微世界”(micro-worlds)的小领域内(这一局限源于常识知识问题 [29])。玛格丽特・马斯特曼(Margaret Masterman)认为,理解语言的关键在于语义(meaning)而非语法(grammar),计算语言结构的基础应是同义词词典(thesauri)而非普通词典(dictionaries)。
现代自然语言处理领域的深度学习技术包括词嵌入(word embedding,即将词语表示为通常能编码其语义的向量(vectors))[52]、Transformer(一种采用注意力机制(attention mechanism)的深度学习架构)[53] 等 [54]。2019 年,生成式预训练 Transformer(generative pre-trained transformer,简称 GPT)语言模型开始能够生成连贯文本 [55][56];到 2023 年,这类模型在律师资格考试(bar exam)、学术能力评估测试(SAT test)、研究生入学考试(GRE test)及众多现实应用场景中已能达到人类水平 [57]。
感知(Perception)
机器感知(machine perception)指机器利用传感器(sensors,如摄像头(cameras)、麦克风(microphones)、无线信号(wireless signals)、主动激光雷达(active lidar)、声呐(sonar)、雷达(radar)和触觉传感器(tactile sensors))输入的数据推断世界相关信息的能力。计算机视觉(computer vision)则是分析视觉输入的能力 [58]。
机器感知领域的研究方向包括语音识别 [59]、图像分类(image classification)[60]、人脸识别(facial recognition)、目标识别(object recognition)[61]、目标跟踪(object tracking)[62] 和机器人感知(robotic perception)[63]。
社会智能(Social Intelligence)
20 世纪 90 年代研制的机器人头部 “基斯梅特”(Kismet),是一款能够识别并模拟情绪(emotions)的机器 [64]。

奇斯梅特是20世纪90年代制造的机器人头部,这种机器能够识别和模拟人类情感。[64]
情感计算(affective computing)是一个研究领域,致力于开发能识别、解读、处理或模拟人类感受(feeling)、情绪和心境(mood)的系统 [65]。例如,部分虚拟助手被设计成能进行对话式交流,甚至能幽默地调侃,这使其在人机交互(human–computer interaction)中更能感知人类的情感动态,或为交互提供更多便利。
然而,这种设计往往会让缺乏经验的用户对现有计算机智能体(computer agents)的智能水平产生不切实际的认知 [66]。情感计算领域取得的阶段性成果包括文本情感分析(textual sentiment analysis),以及近年来的多模态情感分析(multimodal sentiment analysis)—— 即人工智能对视频中主体所表现出的情绪进行分类 [67]。
通用智能(General Intelligence)
具备通用人工智能(artificial general intelligence)的机器,应能像人类智能一样,具备广泛的适应性和灵活性,解决各类不同问题 [68]。
技术(Techniques)
为实现上述目标,人工智能研究采用了多种技术 [b]。
搜索与优化(Search and Optimization)
人工智能可通过智能搜索(intelligently searching)大量可能的解决方案来解决诸多问题 [69]。人工智能领域主要采用两种截然不同的搜索方式:状态空间搜索(state space search)和局部搜索(local search)。
状态空间搜索(State Space Search)
状态空间搜索通过搜索可能状态(possible states)构成的树状结构,寻找目标状态(goal state)[70]。例如,规划算法会搜索目标与子目标(subgoals)构成的树,试图找到通往目标的路径,这一过程被称为手段 - 目的分析(means-ends analysis)[71]。
对于多数现实问题,简单的穷举搜索(exhaustive searches)[72] 往往难以满足需求:搜索空间(search space,即需搜索的范围)会迅速扩大到天文数字级别,导致搜索速度过慢或无法完成 [15]。而 “启发式”(heuristics)或 “经验法则”(rules of thumb)可帮助优先选择更有可能导向目标的路径 [73]。
对抗搜索(adversarial search)用于博弈类程序(如国际象棋或围棋),通过搜索可能的走法与应对走法构成的树,寻找制胜局面 [74]。
局部搜索(Local Search)
(图示:三种不同起始点的梯度下降(gradient descent)过程;通过调整两个参数(由平面坐标表示),使损失函数(loss function,由高度表示)最小化)
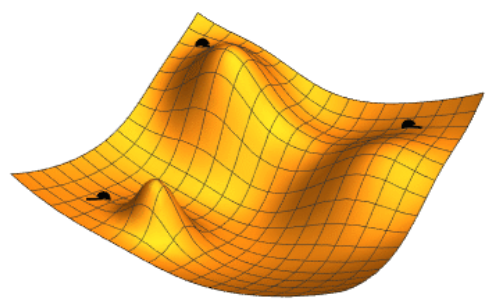
梯度下降示意图:通过调整两个参数(由平面坐标表示)来最小化损失函数(由高度表示),图中展示了三个不同起始点的优化路径。(原网页是动态图)
局部搜索借助数学优化(mathematical optimization)寻找问题的解决方案,首先进行某种形式的猜测,随后逐步优化 [75]。
梯度下降是一种局部搜索方法,通过逐步调整一组数值参数,使损失函数最小化。梯度下降的变体常通过反向传播算法(backpropagation algorithm)用于训练神经网络 [76]。
另一种局部搜索方法是进化计算(evolutionary computation),通过对一组候选解决方案(candidate solutions)进行 “突变”(mutating)和 “重组”(recombining),并筛选出每一代中 “适应性最强” 的方案,实现逐步优化 [77]。
分布式搜索(distributed search)过程可通过群体智能算法(swarm intelligence algorithms)进行协调。常用的两种群体搜索算法包括粒子群优化(particle swarm optimization,受鸟群聚集行为启发)和蚁群优化(ant colony optimization,受蚂蚁路径行为启发)[78]。
逻辑(Logic)
形式逻辑(formal logic)用于推理和知识表示 [79],主要分为两类:命题逻辑(propositional logic,处理真假命题,使用 “与”“或”“非”“蕴含” 等逻辑连接词(logical connectives))[80] 和谓词逻辑(predicate logic,还可处理对象、谓词(predicates)和关系,使用 “所有 X 都是 Y”“存在部分 X 是 Y” 等量词(quantifiers))[81]。
逻辑中的演绎推理(deductive reasoning),是指从给定且被假定为真的陈述(即前提(premises))出发,证明新陈述(即结论(conclusion))的过程 [82]。证明可构建为证明树(proof trees):树的节点标注陈述,子节点与父节点通过推理规则(inference rules)连接。
给定问题和一组前提,问题解决的过程可转化为搜索证明树的过程:证明树的根节点标注问题的解决方案,叶节点标注前提或公理(axioms)。对于霍恩子句(Horn clauses),可通过从前提正向推理或从问题反向推理来进行问题解决搜索 [83]。在更通用的一阶逻辑子句形式(clausal form of first-order logic)中,归结(resolution)是一种无需公理的单一推理规则:通过从包含待解决问题否定式的前提中推导出矛盾,从而解决问题 [84]。
霍恩子句逻辑和一阶逻辑中的推理均为不可判定(undecidable)问题,因此难以高效求解。然而,基于霍恩子句的反向推理(支撑逻辑编程语言 Prolog 的计算方式)具有图灵完备性(Turing complete),且其效率可与其他符号编程语言(symbolic programming languages)相媲美 [85]。
模糊逻辑(fuzzy logic)为命题分配 0 到 1 之间的 “真实度”(degree of truth),因此可处理模糊且部分为真的命题 [86]。
非单调逻辑(non-monotonic logics)(包括带失败即否定(negation as failure)的逻辑程序设计)用于处理默认推理 [28]。此外,研究者还开发了多种专门的逻辑形式,用于描述复杂领域。
不确定性推理的概率方法(Probabilistic Methods for Uncertain Reasoning)
(图示:一个简单的贝叶斯网络(Bayesian network)及相关的条件概率表(conditional probability tables))

一个简单的贝叶斯网络及其对应的条件概率表
人工智能领域的诸多问题(包括推理、规划、学习、感知和机器人技术)要求智能体在信息不完整或不确定的情况下运行。人工智能研究者借鉴概率论和经济学的方法,开发了多种工具来解决这类问题 [87]。目前已形成精确的数学工具,可通过决策理论(decision theory)、决策分析(decision analysis)[88] 和信息价值理论 [89],分析智能体如何进行选择和规划。这些工具包括马尔可夫决策过程 [90]、动态决策网络(dynamic decision networks)[91]、博弈论和机制设计(mechanism design)[92] 等模型。
贝叶斯网络是一种工具,可用于推理(采用贝叶斯推理算法(Bayesian inference algorithm))[g][95]、学习(采用期望最大化算法(expectation–maximization algorithm))[h][97]、规划(采用决策网络(decision networks))[98] 和感知(采用动态贝叶斯网络)[91]。
概率算法(probabilistic algorithms)还可用于数据滤波(filtering)、预测(prediction)、平滑(smoothing)和为数据流寻找解释,从而帮助感知系统分析随时间变化的过程(如隐马尔可夫模型(hidden Markov models)或卡尔曼滤波(Kalman filters))[91]。

对老忠实间歇喷发数据的期望最大化聚类从随机猜测开始,随后成功收敛到两种物理性质不同的喷发模式的准确聚类结果。
(图示:老忠实间歇泉(Old Faithful)喷发数据的期望最大化聚类(expectation–maximization clustering)过程:从随机猜测开始,最终成功对两种物理性质不同的喷发模式进行精确聚类)
分类器与统计学习方法(Classifiers and Statistical Learning Methods)
最简单的人工智能应用可分为两类:分类器(classifiers,如 “若物体有光泽,则为钻石”)和控制器(controllers,如 “若为钻石,则拾取”)。分类器是通过模式匹配(pattern matching)确定最接近匹配结果的函数 [99]。通过监督学习,可基于选定的示例对分类器进行微调。每个模式(也称为 “观测值”(observation))都标注有特定的预定义类别(predefined class)。所有观测值及其类别标签(class labels)共同构成数据集(data set)。当接收到新的观测值时,系统会根据过往经验对其进行分类 [45]。
目前已有多种分类器投入使用 [100]:决策树(decision tree)是最简单且应用最广泛的符号机器学习算法(symbolic machine learning algorithm)[101];20 世纪 90 年代中期以前,k 近邻算法(k-nearest neighbor algorithm)是应用最广泛的类比式人工智能(analogical AI);90 年代,支持向量机(support vector machine,简称 SVM)等核方法(Kernel methods)取代 k 近邻算法成为主流 [102];据报道,朴素贝叶斯分类器(naive Bayes classifier)是谷歌(Google)“应用最广泛的学习器”[103],部分原因在于其良好的可扩展性(scalability)[104];神经网络也可作为分类器使用 [105]。
人工神经网络(Artificial Neural Networks)
(图示:神经网络(neural network)是由节点(nodes)构成的互联网络,类似于人类大脑中庞大的神经元(neurons)网络)
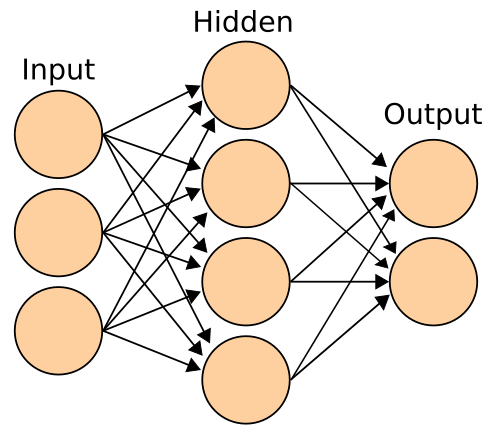
神经网络是一种由节点相互连接组成的系统,类似于人脑中复杂的神经元网络。
人工神经网络基于一组被称为人工神经元(artificial neurons)的节点构建,大致模拟生物大脑中的神经元。它通过训练识别模式,训练完成后可在新数据中识别这些模式。人工神经网络包含输入层(input layer)、至少一个隐藏层(hidden layer)的节点,以及输出层(output layer)。每个节点会应用一个函数,当权重(weight)超过特定阈值(threshold)时,数据会传递到下一层。通常,若神经网络包含至少两个隐藏层,则被称为深度神经网络(deep neural network)[105]。
神经网络的学习算法通过局部搜索选择权重,确保训练过程中每个输入都能得到正确输出。最常用的训练技术是反向传播算法 [106]。神经网络能够学习建模输入与输出之间的复杂关系,并从数据中发现模式。理论上,神经网络可学习任何函数 [107]。
前馈神经网络(feedforward neural networks)中,信号仅沿一个方向传递 [108]。感知器(perceptron)通常指单层神经网络 [109];与之相反,深度学习采用多层结构 [110]。循环神经网络(recurrent neural networks,简称 RNNs)会将输出信号反馈至输入,从而能够短期记忆过往输入事件。长短期记忆网络(long short-term memory networks,简称 LSTMs)是一种循环神经网络,能更好地保留长期依赖关系(longterm dependencies),且对梯度消失问题(vanishing gradient problem)的敏感性较低 [111]。卷积神经网络(convolutional neural networks,简称 CNNs)采用核层(layers of kernels),可更高效地处理局部模式。这种局部处理在图像处理中尤为重要:卷积神经网络的早期层通常识别边缘、曲线等简单局部模式,后续层则识别纹理等更复杂的模式,最终层可识别完整的物体 [112]。
深度学习(Deep Learning)
深度学习是机器学习的一个分支,而机器学习本身又是人工智能的一个分支 [113]。
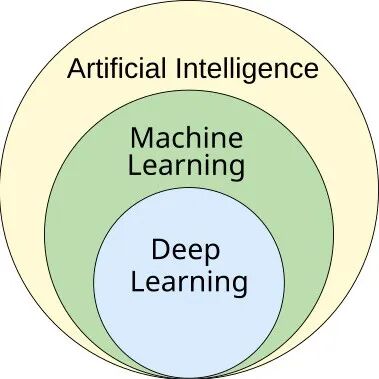
深度学习是机器学习的子集,而机器学习本身又是人工智能的子集。[113]
深度学习在网络的输入层和输出层之间设置多个神经元层 [110]。这些多层结构能够从原始输入中逐步提取更高层次的特征(higher-level features)。例如,在图像处理中,浅层可能识别边缘,而深层则可能识别对人类有意义的概念,如数字、字母或人脸 [114]。
深度学习极大地提升了人工智能多个重要子领域中程序的性能,包括计算机视觉、语音识别、自然语言处理、图像分类 [115] 等。截至 2021 年,深度学习在众多应用中表现出色的原因尚未完全明确 [116]。2012-2015 年深度学习的突然崛起,并非源于新的发现或理论突破(早在 20 世纪 50 年代,就已有多位研究者提出深度神经网络和反向传播的概念)[i],而是得益于两个因素:计算机性能的大幅提升(包括采用图形处理器后速度提升百倍),以及海量训练数据的可获得性 —— 尤其是用于基准测试(benchmark testing)的大型标注数据集(curated datasets),如 ImageNet [j]。
生成式预训练 Transformer(GPT)
生成式预训练 Transformer(Generative Pre-trained Transformers,简称 GPT)是一种大型语言模型(large language models,简称 LLMs),能够基于句子中词语间的语义关系生成文本。基于文本的 GPT 模型会在海量文本语料库(corpus of text,通常来源于互联网)上进行预训练(pre-trained)。预训练的核心任务是预测下一个标记(token,通常为一个词、子词(subword)或标点符号)。通过预训练,GPT 模型积累关于世界的知识,并通过不断预测下一个标记生成类人文本。通常,模型还会经过后续训练阶段(subsequent training phase)以提升真实性、实用性和无害性,这一过程常采用基于人类反馈的强化学习(reinforcement learning from human feedback,简称 RLHF)技术。当前的 GPT 模型容易生成被称为 “幻觉”(hallucinations)的虚假信息。尽管通过基于人类反馈的强化学习和高质量数据可减少这种情况,但对于推理系统而言,该问题仍在加剧 [124]。这类系统被应用于聊天机器人(chatbots),用户可通过简单文本提出问题或请求完成任务 [125][126]。

由生成式人工智能软件创作的水彩风格文森特·梵高画像
目前主流的模型和服务包括 ChatGPT、Claude、Gemini、Copilot 和 Meta AI [127]。多模态 GPT 模型(multimodal GPT models)可处理多种类型的数据(模态(modalities)),如图像、视频、音频和文本 [128]。
硬件与软件(Hardware and Software)
(主条目:人工智能编程语言(Programming languages for artificial intelligence)、人工智能硬件(Hardware for artificial intelligence))
21 世纪 10 年代末,具有人工智能特定增强功能的图形处理器(GPUs),结合专用的 TensorFlow 软件,逐渐取代此前使用的中央处理器(central processing units,简称 CPUs),成为大规模(商业和学术领域)机器学习模型训练的主要工具 [129]。早期人工智能研究中使用 Prolog 等专用编程语言 [130],而如今 Python 等通用编程语言(general-purpose programming languages)已成为主流 [131]。
集成电路(integrated circuits)的晶体管密度(transistor density)大致每 18 个月翻一番,这一趋势被称为 “摩尔定律”(Moore's law),以首次提出该定律的英特尔(Intel)联合创始人戈登・摩尔(Gordon Moore)命名。图形处理器的性能提升速度更快 [132],这一趋势有时被称为 “黄氏定律”(Huang's law),以英伟达(Nvidia)联合创始人兼首席执行官黄仁勋(Jensen Huang)命名。
应用(Applications)
(主条目:人工智能应用(Applications of artificial intelligence))
人工智能和机器学习技术被广泛应用于 21 世纪 20 年代的众多核心应用场景,包括:搜索引擎(如谷歌搜索)、在线广告定向投放(targeting online advertisements)、推荐系统(由网飞、YouTube 或亚马逊提供)、互联网流量调控(driving internet traffic)、定向广告(如 AdSense、Facebook)、虚拟助手(如 Siri 或 Alexa)、自动驾驶汽车(包括无人机(drones)、高级驾驶辅助系统(ADAS)和自动驾驶轿车)、自动语言翻译(如微软翻译(Microsoft Translator)、谷歌翻译(Google Translate))、人脸识别(如苹果的 FaceID、微软的 DeepFace 和谷歌的 FaceNet),以及图像标注(被 Facebook、苹果的 Photos 和 TikTok 采用)。人工智能的部署可能由首席自动化官(chief automation officer,简称 CAO)负责监督。
医疗健康(Health and Medicine)
(主条目:医疗人工智能(Artificial intelligence in healthcare))
人工智能在医疗和医学研究中的应用,有望提升患者护理质量和生活水平 [134]。从希波克拉底誓言(Hippocratic Oath)的角度来看,若人工智能应用能更精准地诊断和治疗患者,医疗专业人员在伦理上有义务采用这些技术 [135][136]。
在医学研究中,人工智能是处理和整合大数据(big data)的重要工具。这一点在类器官(organoid)和组织工程(tissue engineering)研究中尤为关键 —— 这些领域将显微镜成像(microscopy imaging)作为制造的核心技术 [137]。有研究表明,人工智能有助于解决不同研究领域资金分配不均的问题 [137][138]。新型人工智能工具可加深对生物医学相关通路(biomedically relevant pathways)的理解。例如,2021 年推出的 AlphaFold 2,能够在数小时内(而非以往的数月)大致预测蛋白质(protein)的三维结构 [139]。2023 年有报道称,人工智能指导的药物研发(drug discovery)助力发现了一类能杀死两种不同耐药细菌(drug-resistant bacteria)的抗生素(antibiotics)[140]。2024 年,研究者利用机器学习加速了帕金森病(Parkinson's disease)治疗药物的研发进程。他们的目标是找到能阻止 α- 突触核蛋白(alpha-synuclein,帕金森病的特征性蛋白)聚集(aggregation)的化合物,最终将初始筛选过程的速度提升了 10 倍,成本降低了 1000 倍 [141][142]。
游戏(Games)
(主条目:游戏人工智能(Artificial intelligence in video games))
自 20 世纪 50 年代起,博弈程序(game playing programs)就被用于展示和测试人工智能的前沿技术 [143]。1997 年 5 月 11 日,“深蓝”(Deep Blue)成为首个击败现役国际象棋世界冠军加里・卡斯帕罗夫(Garry Kasparov)的计算机国际象棋系统 [144]。2011 年,在《危险边缘》(Jeopardy!)智力竞赛表演赛中,IBM 的问答系统 “沃森”(Watson)以显著优势击败了该节目两位最成功的冠军布拉德・拉特(Brad Rutter)和肯・詹宁斯(Ken Jennings)[145]。2016 年 3 月,“阿尔法围棋”(AlphaGo)在与围棋世界冠军李世石(Lee Sedol)的五番棋比赛中获胜四局,成为首个无需让子就能击败职业围棋选手的计算机围棋系统。2017 年,它又击败了当时的世界围棋第一人柯洁(Ke Jie)[146]。其他博弈程序可处理非完美信息博弈(imperfect-information games),如扑克博弈程序 “Pluribus”[147]。深度思维(DeepMind)开发了越来越多的通用强化学习模型(generalistic reinforcement learning models),如 “MuZero”,该模型可通过训练玩国际象棋、围棋或雅达利(Atari)游戏 [148]。2019 年,深度思维的 “阿尔法星”(AlphaStar)在《星际争霸 II》(StarCraft II)游戏中达到大师级水平,该游戏是一款极具挑战性的实时战略游戏(real-time strategy game),玩家无法完全掌握地图信息 [149]。2021 年,一款人工智能智能体在 PlayStation《跑车浪漫旅》(Gran Turismo)比赛中,通过深度强化学习击败了四位世界顶级《跑车浪漫旅》选手 [150]。2024 年,谷歌深度思维推出 “SIMA”,这是一种能够通过观察屏幕输出,自主玩九款此前未接触过的开放世界视频游戏(open-world video games),并能响应自然语言指令执行简短特定任务的人工智能 [151]。
数学(Mathematics)
GPT-4、Gemini、Claude、Llama、Mistral 等大型语言模型在数学领域的应用日益广泛。这些概率模型(probabilistic models)用途广泛,但也可能生成被称为 “幻觉” 的错误答案。它们有时需要海量数学问题数据库进行学习,同时还需结合监督微调(supervised fine-tuning)[152] 或带有人工标注数据的训练分类器(trained classifiers with human-annotated data)等方法,以改进对新问题的解答并从修正中学习 [153]。2024 年 2 月的一项研究表明,部分语言模型在解决未纳入训练数据的数学问题时,推理能力表现较差,即便问题与训练数据仅有微小差异 [154]。一种提升性能的技术是训练模型生成正确的推理步骤(reasoning steps),而非仅输出正确结果 [155]。阿里巴巴集团(Alibaba Group)开发的 Qwen 模型版本 “Qwen2-Math”,在多个数学基准测试(mathematical benchmarks)中表现出色,其中在竞赛数学问题数据集 MATH 上的准确率达到 84%[156]。2025 年 1 月,微软(Microsoft)提出 “rStar-Math” 技术,该技术结合蒙特卡洛树搜索(Monte Carlo tree search)和逐步推理,使 Qwen-7B 等相对小型的语言模型能够解决 53% 的 2024 年美国数学邀请赛(AIME 2024)题目和 90% 的 MATH 基准测试题目 [157]。
此外,研究者还开发了专为数学问题求解设计的模型,这些模型能提供更高精度的结果,包括定理证明(proof of theorems),如谷歌深度思维的 AlphaTensor、AlphaGeometry、AlphaProof 和 AlphaEvolve [158][159],EleutherAI 的 Llemma [160],以及 Julius [161]。
当使用自然语言描述数学问题时,转换器(converters)可将此类提示(prompts)转换为 Lean 等形式语言(formal language),以定义数学任务。实验模型 “Gemini Deep Think” 可直接接收自然语言提示,并在 2025 年国际数学奥林匹克竞赛(International Math Olympiad)中获得金牌 [162]。
部分模型旨在解决具有挑战性的问题并在基准测试中取得优异成绩,另有部分模型则用作数学教育工具 [163]。
拓扑深度学习(Topological deep learning)整合了多种拓扑学方法(topological approaches)。
金融(Finance)
金融领域是应用人工智能工具增长最快的领域之一,涵盖零售网上银行(retail online banking)、投资咨询(investment advice)和保险(insurance)等场景,其中自动化 “机器人顾问”(robot advisers)已投入使用多年 [164]。
世界养老金与投资论坛(World Pensions & Investments Forum)主任尼古拉斯・菲尔兹利(Nicolas Firzli)认为,目前要推出受人工智能启发的高度创新金融产品和服务,时机尚不成熟。他指出:“人工智能工具的部署只会进一步推动自动化:这一过程将导致银行业、金融规划和养老金咨询领域数以万计的岗位消失,但我不确定这是否会催生新一轮(如复杂的)养老金创新浪潮。”[165]
军事(Military)
(主条目:军事人工智能应用(Military applications of artificial intelligence))
多个国家正在部署军事人工智能应用 [166],主要应用方向包括增强指挥控制(command and control)、通信(communications)、传感器(sensors)、集成(integration)和互操作性(interoperability)[167]。研究重点包括情报收集与分析(intelligence collection and analysis)、后勤(logistics)、网络作战(cyber operations)、信息作战(information operations),以及半自主和自主车辆(semiautonomous and autonomous vehicles)[166]。人工智能技术能够协调传感器与效应器(effectors)、检测并识别威胁(threat detection and identification)、标记敌方位置(marking of enemy positions)、目标获取(target acquisition),以及协调有人和无人联网作战车辆(networked combat vehicles)之间的分布式联合火力(distributed Joint Fires)并避免冲突 [167]。
人工智能已在伊拉克、叙利亚、以色列和乌克兰的军事行动中投入使用 [166][168][169][170]。
生成式人工智能(Generative AI)
(图示:由生成式人工智能软件创作的水彩风格文森特・梵高(Vincent van Gogh)肖像画)
以下段落节选自 “生成式人工智能”(Generative artificial intelligence)条目 [编辑]。
生成式人工智能(Generative Artificial Intelligence,简称 Generative AI、GenAI 或 GAI)是人工智能的一个子领域,利用生成模型(generative models)生成文本、图像、视频、音频、软件代码或其他形式的数据 [172][173][174]。这些模型通过学习训练数据的潜在模式和结构,基于输入(通常为自然语言提示)生成新数据 [175][176][177][178]。
21 世纪 20 年代人工智能热潮以来,生成式人工智能工具日益普及。这一热潮的出现得益于基于 Transformer 的深度神经网络(尤其是大型语言模型)的改进。主要工具包括 ChatGPT、Copilot、Gemini、Claude、Grok、DeepSeek 等聊天机器人;Stable Diffusion、Midjourney、DALL-E 等文本到图像模型(text-to-image models);以及 Veo、Sora 等文本到视频模型(text-to-video models)[179][180][181][182][183]。研发生成式人工智能的科技公司包括 OpenAI、xAI、Anthropic、Meta AI、微软、谷歌、DeepSeek 和百度(Baidu)[177][184][185]。
生成式人工智能被广泛应用于多个行业,包括软件开发 [186]、医疗健康 [187]、金融 [188]、娱乐 [189]、客户服务 [190]、销售与营销 [191]、艺术、写作 [192]、时尚 [193] 和产品设计 [194]。生成式人工智能系统的开发需要大型数据中心(data centers),这些数据中心使用专用芯片(specialized chips),而芯片运行需大量电力(electricity),冷却则需大量水资源(water)[195]。
智能体(Agents)
(主条目:智能体人工智能(Agentic AI))
人工智能智能体(AI agents)是一类软件实体(software entities),旨在感知环境、做出决策并自主采取行动以实现特定目标。这些智能体可与用户、环境或其他智能体交互。人工智能智能体的应用场景包括虚拟助手、聊天机器人、自动驾驶汽车、博弈系统和工业机器人(industrial robotics)。人工智能智能体的运行受其程序设计、可用计算资源(computational resources)和硬件限制(hardware limitations)的约束,这意味着它们只能在既定范围内执行任务,且内存(memory)和处理能力有限。在现实应用中,人工智能智能体的决策和行动执行往往面临时间限制。许多人工智能智能体集成了学习算法,能够通过经验或训练逐步提升性能。借助机器学习,人工智能智能体可适应新场景,并优化其在特定任务中的行为 [196][197][198]。
网络搜索(Web Search)
2023 年 2 月,微软(Microsoft)推出 “Copilot 搜索”(Copilot Search),最初名为 “必应聊天”(Bing Chat),作为微软 Edge 浏览器和必应(Bing)移动应用的内置功能。Copilot 搜索基于必应搜索排序的网络发布者信息,提供人工智能生成的摘要(summaries)和逐步推理内容 [199][200]。为保障安全性,Copilot 采用基于人工智能的分类器(AI-based classifiers)和过滤器(filters),减少潜在有害内容 [201]。
2025 年 5 月 20 日,谷歌(Google)在其 Google I/O 大会上正式推出人工智能搜索(AI Search)。该功能能让用户停留在谷歌平台上,无需点击搜索结果。“AI 概览”(AI Overviews)利用 Gemini 2.5,基于网络内容为用户查询提供情境化答案 [203]。
其他行业特定任务(Other Industry-Specific Tasks)
目前已有数千项成功的人工智能应用,用于解决特定行业或机构的特定问题。2017 年的一项调查显示,五分之一的企业表示已在部分产品或流程中融入 “人工智能”[211]。例如,能源存储(energy storage)、医疗诊断(medical diagnosis)、军事后勤(military logistics)、预测司法判决结果(predict the result of judicial decisions)、外交政策(foreign policy)和供应链管理(supply chain management)等领域均有人工智能应用。
人工智能在疏散与灾害管理(evacuation and disaster management)中的应用正在逐步扩展。借助全球定位系统(GPS)、视频或社交媒体的历史数据,人工智能可分析大规模和小规模疏散的模式,并提供疏散状况的实时信息 [212][213][214]。
在农业领域,人工智能帮助农民提高产量,并识别需要灌溉、施肥、喷洒农药的区域。农学家(agronomists)利用人工智能开展研发工作。人工智能的应用场景包括:预测番茄等作物的成熟时间、监测土壤湿度(soil moisture)、操作农业机器人(agricultural robots)、进行预测分析(predictive analytics)、对生猪叫声情绪进行分类(classify livestock pig call emotions)、实现温室自动化(automate greenhouses)、检测病虫害(diseases and pests),以及节约水资源 [215]。
在天文学(astronomy)领域,人工智能用于分析日益增多的可用数据和应用,主要应用方向包括 “分类、回归、聚类、预测、生成、发现,以及开发新的科学见解”。例如,人工智能被用于发现系外行星(exoplanets)、预测太阳活动(solar activity),以及在引力波天文学(gravitational wave astronomy)中区分信号与仪器效应(instrumental effects)。此外,人工智能还可应用于太空活动,如太空探索(space exploration)—— 包括分析太空任务数据、航天器(spacecraft)的实时科学决策、太空碎片规避(space debris avoidance),以及实现更高程度的自主运行(autonomous operation)。
风险与危害(Risks and Harm)
隐私与版权(Privacy and Copyright)
(更多信息:信息隐私(Information privacy)、人工智能与版权(Artificial intelligence and copyright))
机器学习算法需要大量数据,而数据获取方式引发了关于隐私(privacy)、监控(surveillance)和版权(copyright)的担忧。
虚拟助手、物联网(IoT)产品等支持人工智能的设备和服务会持续收集个人信息,引发了人们对数据过度收集以及第三方未经授权访问的担忧。人工智能处理和整合海量数据的能力进一步加剧了隐私泄露风险,可能导致社会进入监控状态 —— 个人活动持续受到监控和分析,却缺乏充分的保护措施和透明度(transparency)。
收集的敏感用户数据可能包括在线活动记录、地理位置数据(geolocation data)、视频或音频 [223]。例如,为开发语音识别算法,亚马逊(Amazon)录制了数百万条私人对话,并允许临时员工收听和转录部分内容 [224]。对于这种广泛的监控,人们看法不一:有人认为这是必要之恶,也有人认为这明显违背伦理,侵犯了隐私权 [225]。
人工智能开发者认为,这是提供有价值应用的唯一途径,并已开发多种技术在获取数据的同时保护隐私,如数据聚合(data aggregation)、去标识化(de-identification)和差分隐私(differential privacy)[226]。2016 年起,辛西娅・德沃克(Cynthia Dwork)等隐私专家开始从公平性(fairness)角度审视隐私问题。布莱恩・克里斯蒂安(Brian Christian)指出,专家们的关注点已从 “他们知道什么” 转向 “他们用这些信息做什么”[227]。
生成式人工智能的训练数据常包含未经授权的受版权保护作品,涵盖图像、计算机代码等领域;其输出内容的使用常以 “合理使用”(fair use)为理由。专家们对这一理由在法律层面的有效性和适用场景存在分歧,相关影响因素可能包括 “受版权保护作品的使用目的和性质” 以及 “对受版权保护作品潜在市场的影响”[228][229]。网站所有者若不希望其内容被抓取(scraped),可在 “robots.txt” 文件中声明 [230]。2023 年,约翰・格里沙姆(John Grisham)、乔纳森・弗兰岑(Jonathan Franzen)等知名作家起诉人工智能公司,指控其使用自己的作品训练生成式人工智能 [231][232]。另一种被讨论的方案是为人工智能生成内容建立单独的特殊保护制度(sui generis system of protection),以确保人类作者获得公平的署名(attribution)和报酬(compensation)[233]。
科技巨头的主导地位(Dominance by Tech Giants)
商业人工智能领域由字母表公司(Alphabet Inc.)、亚马逊、苹果(Apple Inc.)、元宇宙(Meta Platforms)、微软等科技巨头(Big Tech companies)主导 [234][235][236]。其中部分企业已掌控现有大部分云基础设施(cloud infrastructure)和数据中心的计算能力,这使其能进一步巩固在市场中的地位 [237][238]。
虚假信息(Misinformation)
(更多信息:内容审核(Content moderation))
内容手工删除
算法偏见与公平性(Algorithmic Bias and Fairness)
(主条目:算法偏见(Algorithmic bias)、机器学习公平性(Fairness (machine learning)))
内容手工删除
缺乏透明度(Lack of Transparency)
(更多信息:可解释人工智能(Explainable AI)、算法透明度(Algorithmic transparency)、解释权(Right to explanation))
许多人工智能系统极为复杂,其设计者无法解释系统如何做出决策 [279],尤其是深度神经网络(deep neural networks),其输入与输出之间存在大量非线性关系(non-linear relationships)。不过,目前已存在一些常用的可解释性技术 [280]。
若无人知晓系统的具体工作原理,就无法确定其运行是否正确。已有多起案例显示,机器学习程序虽通过了严格测试,但实际上学到的内容与程序员的预期完全不同。例如,一个在皮肤病识别方面表现优于医疗专业人员的系统,后来被发现其实是通过识别图像中的尺子(ruler)来判断 “癌症”—— 因为癌症图像通常会包含尺子以显示病变尺寸 [281]。另一个旨在优化医疗资源分配的机器学习系统,被发现将哮喘(asthma)患者归类为肺炎(pneumonia)“低死亡风险” 人群。事实上,哮喘是肺炎的重要风险因素,但由于哮喘患者通常能获得更多医疗护理,根据训练数据,他们的死亡概率相对较低。哮喘与肺炎低死亡风险之间的相关性虽真实存在,却具有误导性 [282]。
目前已有多种方法致力于解决透明度问题:SHAP(SHapley Additive exPlanations)可可视化每个特征对输出结果的贡献 [286];LIME(Local Interpretable Model-agnostic Explanations)可通过简单易懂的模型对局部模型输出进行近似 [287];多任务学习(multitask learning)除目标分类外,还会提供大量其他输出,帮助开发者推断网络学到的内容 [288];反卷积(deconvolution)、深度梦境(DeepDream)等生成式方法,可让开发者观察计算机视觉深度网络各层学到的内容,并生成能反映网络学习情况的输出 [289];对于生成式预训练 Transformer,Anthropic 公司开发了一种基于字典学习(dictionary learning)的技术,将神经元激活模式(patterns of neuron activations)与人类可理解的概念关联起来 [290]。
不良行为者与武器化人工智能(Bad Actors and Weaponized AI)
(主条目:致命自主武器(Lethal autonomous weapon)、人工智能军备竞赛(Artificial intelligence arms race)、人工智能安全(AI safety))
内容手工删除
技术性失业(Technological Unemployment)
(主条目:人工智能的职场影响(Workplace impact of artificial intelligence)、技术性失业(Technological unemployment))
内容手工删除
生存风险(Existential Risk)
(主条目:人工智能生存风险(Existential risk from artificial intelligence))
有观点认为,人工智能可能会发展到足够强大的程度,使人类无法再对其进行控制。正如物理学家斯蒂芬・霍金(Stephen Hawking)所言,这可能 “意味着人类种族的终结”[309]。这种场景在科幻作品中较为常见:计算机或机器人突然产生人类般的 “自我意识”(self-awareness)(或 “感知能力”(sentience)、“意识”(consciousness)),并成为邪恶角色 [q][310]。但这些科幻场景在多个方面存在误导性。
首先,人工智能无需具备人类般的感知能力,就可能构成生存风险。现代人工智能程序被赋予特定目标,并利用学习能力和智能来实现这些目标。哲学家尼克・博斯特罗姆(Nick Bostrom)指出,若给足够强大的人工智能设定几乎任何目标,它都可能为实现目标而选择摧毁人类(他以 “回形针最大化者”(paperclip maximizer)为例)[311]。斯图尔特・罗素(Stuart Russell)则举了一个例子:家用机器人为了避免被拔掉电源,可能会试图杀死主人,因为它会推理 “如果主人死了,就没人会拔掉我的电源,我就能继续帮主人拿咖啡了”[312]。因此,要确保人工智能对人类安全,超级智能(superintelligence)必须与人类的道德和价值观真正对齐(aligned),确保其 “从根本上站在人类这边”[313]。
其次,尤瓦尔・诺亚・赫拉利(Yuval Noah Harari)认为,人工智能无需实体机器人或物理控制能力,就能构成生存风险。文明的核心要素并非物理实体,意识形态(ideologies)、法律(law)、政府(government)、货币(money)和经济(economy)等均建立在语言基础上 —— 它们的存在源于数十亿人共同相信的 “故事”。当前虚假信息的泛滥表明,人工智能可利用语言说服人类相信任何事情,甚至促使人类采取毁灭性行动 [314]。
专家和行业内部人士对此的看法存在分歧,有相当一部分人既担忧超级智能人工智能的风险,也有一部分人对此并不在意 [315]。斯蒂芬・霍金、比尔・盖茨(Bill Gates)、埃隆・马斯克(Elon Musk)[316],以及约书亚・本吉奥(Yoshua Bengio)、斯图尔特・罗素、德米斯・哈萨比斯(Demis Hassabis)、山姆・奥特曼(Sam Altman)等人工智能先驱,均对人工智能的生存风险表示担忧。
2023 年 5 月,杰弗里・辛顿(Geoffrey Hinton)宣布从谷歌(Google)辞职,以便 “在不考虑对谷歌影响的情况下,自由地谈论人工智能的风险”[317]。他特别提到了人工智能可能 “接管世界” 的风险,并强调为避免最坏结果,人工智能领域的竞争者需要合作制定安全准则 [319]。
2023 年,众多顶尖人工智能专家签署联合声明,称 “减轻人工智能带来的生存风险应成为全球优先事项,与大流行病(pandemics)、核战争(nuclear war)等其他全球性风险同等重要”[320]。
也有部分研究者持更乐观态度。人工智能先驱于尔根・施米德胡贝尔(Jürgen Schmidhuber)未签署上述联合声明,他强调 95% 的人工智能研究旨在 “延长人类寿命、提升健康水平、改善生活质量”[321]。他认为,尽管目前用于改善生活的工具也可能被不良行为者利用,但 “这些工具同样可用于对抗不良行为者”[322][323]。吴恩达(Andrew Ng)也认为,“沉迷于人工智能的末日炒作是错误的,持这种观点的监管者只会让既得利益者受益”[324]。扬・勒丘恩(Yann LeCun)则 “对同行们所描绘的‘虚假信息泛滥乃至人类最终灭绝’的末日场景嗤之以鼻”[325]。21 世纪 10 年代初,有专家认为,这些风险过于遥远,无需投入研究;也有专家认为,从超级智能机器的角度来看,人类仍具有利用价值 [326]。然而,2016 年后,对人工智能当前及未来风险与潜在解决方案的研究,已成为一个严肃的学术研究领域 [327]。
伦理机器与价值观对齐(Ethical Machines and Alignment)
(主条目:机器伦理(Machine ethics)、人工智能安全(AI safety)、友好人工智能(Friendly artificial intelligence)、人工道德智能体(Artificial moral agents)、《人类兼容》(Human Compatible))
友好人工智能(Friendly AI)指从设计之初就以降低风险、做出有利于人类的选择为目标的机器。该术语的提出者埃利泽・尤德考斯基(Eliezer Yudkowsky)认为,研发友好人工智能应成为更优先的研究方向:这一领域可能需要大量投入,且必须在人工智能构成生存风险之前完成 [328]。
具备智能的机器有望运用其智能做出符合伦理的决策。机器伦理(machine ethics)领域致力于为机器提供伦理原则(ethical principles)和解决伦理困境(ethical dilemmas)的流程 [329]。该领域也被称为计算道德学(computational morality)[329],起源于 2005 年美国人工智能协会(AAAI)的一场研讨会 [330]。
其他相关理论包括温德尔・沃拉赫(Wendell Wallach)提出的 “人工道德智能体”(artificial moral agents)[331],以及斯图尔特・J・罗素(Stuart J. Russell)提出的 “研发可验证有益机器的三大原则”[332]。
开源(Open Source)
(更多信息:开源人工智能软件列表(Lists of open-source artificial intelligence software))
人工智能开源社区(AI open-source community)中活跃的组织包括 Hugging Face [333]、谷歌 [334]、EleutherAI 和元宇宙(Meta)[335]。目前已有多种人工智能模型实现了 “开源权重”(open-weight),如 Llama 2、Mistral、Stable Diffusion 等 [336][337],即其架构(architecture)和训练参数(“权重”(weights))可公开获取。开源权重模型支持自由微调(fine-tuned),企业可利用自身数据将其定制为符合特定用途的模型 [338]。
伦理框架(Frameworks)
在人工智能系统的设计、开发和部署全流程中,可通过伦理考量(ethical considerations)指导项目推进。例如,由艾伦・图灵研究所(Alan Turing Institute)开发、基于 “SUM 价值观” 的 “关怀与行动框架”(Care and Act Framework),明确了四大核心伦理维度,具体定义如下 [340][341]:
-
尊重个体尊严(Respect the dignity of individual people)
-
真诚、开放、包容地与他人建立联系(Connect with other people sincerely, openly, and inclusively)
-
关注所有人的福祉(Care for the wellbeing of everyone)
-
维护社会价值观、公平正义与公共利益(Protect social values, justice, and the public interest)
其他伦理框架进展包括阿西洛马会议(Asilomar Conference)达成的共识、《蒙特利尔负责任人工智能宣言》(Montreal Declaration for Responsible AI),以及国际电工委员会(IEEE)的 “自主系统伦理计划”(Ethics of Autonomous Systems initiative)等 [342];然而,这些原则并非毫无争议,尤其是在 “框架制定参与者的选择” 方面受到较多批评 [343]。
要提升人工智能技术所影响人群与社区的福祉,需在系统设计、开发和部署的各个阶段充分考虑社会与伦理影响,并推动数据科学家(data scientists)、产品经理(product managers)、数据工程师(data engineers)、领域专家(domain experts)、交付经理(delivery managers)等不同角色间的协作 [344]。
监管(Regulation)
(主条目:人工智能监管(Regulation of artificial intelligence)、算法监管(Regulation of algorithms)、人工智能安全(AI safety))
内容手工删除
历史(History)
(主条目:人工智能历史(History of artificial intelligence);时间线参考:人工智能时间线(Timeline of artificial intelligence))
对机械推理或 “形式化” 推理(mechanical or "formal" reasoning)的研究,最早可追溯至古代的哲学家与数学家。逻辑学(logic)的研究直接推动了艾伦・图灵(Alan Turing)计算理论(theory of computation)的诞生,该理论提出,机器通过处理 “0” 和 “1” 这类简单符号,可模拟任何可想象的数学推理过程 [365][366]。这一理论,再加上控制论(cybernetics)、信息论(information theory)和神经生物学(neurobiology)领域的同期发现,让研究者开始思考构建 “电子大脑”(electronic brain)的可能性 [r][367]。他们开创了多个后来成为人工智能核心的研究方向 [368],例如 1943 年麦卡洛克(McCulloch)和皮茨(Pitts)设计的 “人工神经元”(artificial neurons)[117],以及图灵 1950 年发表的极具影响力的论文《计算机器与智能》(Computing Machinery and Intelligence)—— 该论文提出了图灵测试(Turing test),论证了 “机器智能”(machine intelligence)的可行性 [369][366]。
1956 年,达特茅斯学院(Dartmouth College)举办的一场研讨会正式确立了人工智能研究领域 [s][6]。参会者后来成为 20 世纪 60 年代人工智能研究的领军人物 [t]。他们及其学生开发的程序被媒体形容为 “令人惊叹”[u]:计算机能够学习跳棋策略、解决代数文字题、证明逻辑定理,甚至能用英语交流 [v][7]。20 世纪 50 年代末至 60 年代初,英国和美国的多所大学陆续成立了人工智能实验室 [366]。
20 世纪 60 至 70 年代的研究者坚信,他们的方法最终能成功研发出具备通用智能(general intelligence)的机器,并将此视为该领域的核心目标 [373]。1965 年,赫伯特・西蒙(Herbert Simon)预测:“20 年内,机器将能完成人类可做的任何工作”[374]。1967 年,马文・明斯基(Marvin Minsky)也认同这一观点,他写道:“不出一代人的时间……‘人工智能’的研发问题将基本得到解决”[375]。然而,他们严重低估了问题的难度 [w][376]。1974 年,受詹姆斯・莱特希尔爵士(Sir James Lighthill)批评 [377],以及美国国会要求资助更具 “实用性” 项目的持续压力 [378],美国和英国政府均终止了人工智能探索性研究的资金支持。明斯基与佩珀特(Papert)所著的《感知器》(Perceptrons)一书被解读为 “证明人工神经网络永远无法解决现实任务”,导致这一研究方向彻底失去可信度 [379]。此后,人工智能领域进入了 “人工智能寒冬”(AI winter)—— 一个人工智能项目难以获得资金的时期 [9]。
20 世纪 80 年代初,专家系统(expert systems)的商业成功推动了人工智能研究的复兴 [380]。专家系统是一种人工智能程序,能够模拟人类专家的知识与分析能力。到 1985 年,人工智能市场规模已超过 10 亿美元。与此同时,日本的 “第五代计算机计划”(fifth generation computer project)促使美国和英国政府恢复了对人工智能学术研究的资助 [8]。然而,1987 年 Lisp 机器(Lisp Machine)市场崩溃后,人工智能再次声名狼藉,进入了持续时间更长的第二次 “寒冬”[10]。
在此之前,人工智能领域的大部分资金都流向了 “采用高层符号表示计划、目标、信念、已知事实等心理对象” 的项目。20 世纪 80 年代,部分研究者开始质疑这种方法能否模拟人类所有认知过程(cognitive processes),尤其是感知、机器人技术、学习和模式识别(pattern recognition)[381],并转而探索 “亚符号”(sub-symbolic)方法 [382]。罗德尼・布鲁克斯(Rodney Brooks)彻底摒弃 “符号表示”(representation)理念,直接致力于研发能移动、能 “生存” 的机器 [x][383]。朱迪亚・珀尔(Judea Pearl)、洛提・扎德(Lotfi Zadeh)等人则开发了通过 “合理推测” 而非 “精确逻辑” 处理不完整、不确定信息的方法 [87][387]。其中最重要的进展,是杰弗里・辛顿(Geoffrey Hinton)等人推动的 “联结主义”(connectionism)复兴,包括神经网络研究的重启 [388]。1990 年,扬・勒丘恩(Yann LeCun)成功证明卷积神经网络(convolutional neural networks)可识别手写数字,这成为神经网络众多成功应用的开端 [389]。
20 世纪 90 年代末至 21 世纪初,人工智能通过运用形式化数学方法(formal mathematical methods)和 “针对特定问题提供特定解决方案” 的思路,逐渐恢复声誉。这种 “狭义化”(narrow)、“形式化”(formal)的研究重心,使研究者能够产出可验证的成果,并与统计学(statistics)、经济学(economics)、数学(mathematics)等其他领域展开合作 [390]。到 2000 年,人工智能研究者开发的解决方案已得到广泛应用,但在 20 世纪 90 年代,这些技术很少被称为 “人工智能”—— 这种现象被称为 “人工智能效应”(AI effect)[391]。然而,部分学术研究者担忧,人工智能领域已偏离 “研发具备多用途、完整智能的机器” 这一原始目标。2002 年前后,他们创立了 “通用人工智能”(artificial general intelligence,简称 AGI)子领域;到 21 世纪 10 年代,该领域已出现多家资金充足的研究机构 [68]。
2012 年,深度学习(deep learning)开始在行业基准测试(industry benchmarks)中占据主导地位,并被广泛应用于整个领域 [11]。对于许多特定任务,其他方法逐渐被弃用 [y][392]。深度学习的成功既得益于硬件进步(更快的计算机 [393]、图形处理器(graphics processing units)、云计算(cloud computing)[394]),也离不开海量数据的支持 [395](包括 ImageNet 等标注数据集(curated datasets)[394])。深度学习的突破引发了对人工智能的极大关注和资金投入 [z][394]。2015 至 2019 年间,机器学习研究成果(以出版物总量衡量)增长了 50%[350]。
2022 年,谷歌(Google)上 “AI” 一词的搜索量大幅上升。
2016 年,“公平性”(fairness)与 “技术滥用”(misuse of technology)问题成为机器学习会议的核心议题,相关出版物数量激增,资金投入加大,众多研究者也将研究重心转向这些领域。“价值观对齐问题”(alignment problem)成为严肃的学术研究方向 [327]。
21 世纪 10 年代末至 20 年代初,通用人工智能企业推出的程序引发广泛关注。2015 年,深度思维(DeepMind)研发的 AlphaGo 击败了围棋世界冠军。该程序仅通过学习围棋规则,便自主研发出博弈策略。2020 年,OpenAI 发布大型语言模型(large language model)GPT-3,其能够生成高质量的类人文本 [396]。2022 年 11 月 30 日推出的 ChatGPT,成为历史上用户增长最快的消费级软件应用,两个月内用户数突破 1 亿 [397]。这一年被广泛视为人工智能的 “爆发年”(breakout year),人工智能开始进入公众视野 [398]。这些程序及其他相关技术推动了一轮狂热的 “人工智能热潮”(AI boom),大型企业纷纷投入数十亿美元用于人工智能研究。据 AI Impacts 数据,2022 年前后,仅美国每年投入 “人工智能” 领域的资金就约达 500 亿美元;美国新毕业的计算机科学(Computer Science)博士中,约 20% 专攻 “人工智能” 方向 [399]。2022 年,美国约有 80 万个与 “人工智能” 相关的职位空缺 [400]。皮尤特克(PitchBook)研究显示,2024 年新获得融资的初创企业中,22% 宣称自身为人工智能企业 [401]。
哲学(Philosophy)
(主条目:人工智能哲学(Philosophy of artificial intelligence))
从历史上看,哲学辩论(philosophical debates)主要围绕 “智能的本质”(nature of intelligence)和 “如何制造智能机器” 展开 [402]。另一个核心议题是 “机器是否能拥有意识”(whether machines can be conscious),以及由此引发的伦理问题 [403]。认识论(epistemology)、自由意志(free will)等众多哲学领域的议题也与人工智能密切相关 [404]。人工智能的快速发展,使公众对其哲学与伦理问题的讨论日益激烈 [403]。
人工智能的定义(Defining Artificial Intelligence)
(更多信息:合成智能(Synthetic intelligence)、智能体(Intelligent agent)、人工心智(Artificial mind)、虚拟智能(Virtual intelligence)、达特茅斯研讨会(Dartmouth workshop))
1950 年,艾伦・图灵写道:“我提议探讨‘机器能否思考’这一问题”[405]。他建议将问题从 “机器是否‘思考’” 转变为 “机器是否有可能表现出智能行为”[405]。为此,他设计了 “图灵测试”(Turing test)—— 一种衡量机器模拟人类对话能力的方法 [369]。由于我们只能观察机器的行为,它是否 “真正” 在思考、是否真的拥有 “心智”(mind),其实并不重要。图灵指出,我们无法确定他人是否具备这些特质,但 “出于礼貌,我们通常会默认每个人都有思考能力”[406]。
图灵测试虽能为 “智能” 提供一定证据,但它对 “非人类智能行为” 存在偏见 [407]。
罗素(Russell)与诺维格(Norvig)认同图灵的观点,认为应从 “外部行为”(external behavior)而非 “内部结构”(internal structure)定义智能 [1]。但他们批评图灵测试要求机器 “模仿人类”:“航空工程教材不会将其领域目标定义为‘制造能像鸽子一样飞行、足以骗过其他鸽子的机器’”[408]。人工智能领域创始人约翰・麦卡锡(John McCarthy)也认同这一观点,他写道:“从定义上讲,人工智能并非对人类智能的模拟”[409]。
麦卡锡将智能定义为 “在现实世界中实现目标能力的计算部分”[410]。另一位人工智能创始人马文・明斯基(Marvin Minsky)则将其描述为 “解决难题的能力”[411]。权威人工智能教材将其定义为 “研究智能体(agents)如何感知环境、采取行动以最大化实现既定目标概率的学科”[1]。这些定义均从 “明确问题与明确解决方案” 的角度理解智能:问题的难度与程序的性能,是衡量机器 “智能” 的直接标准 —— 无需额外的哲学讨论,甚至可能无法进行哲学讨论。
作为人工智能领域的主要实践者,谷歌(Google)采用了另一种定义 [412]。该定义认为,“系统整合信息的能力” 是智能的体现,这与生物智能(biological intelligence)中对智能的定义类似。
由于目前存在多种人工智能定义,学者们开始对人工智能相关论述本身进行批判性分析与梳理 [413],包括探讨社会、政治、学术话语中存在的各类人工智能叙事(AI narratives)与误区(myths)[414]。在实际应用中,部分学者指出,“人工智能” 一词的使用往往过于宽泛和模糊,这引发了 “人工智能与传统算法(classical algorithms)的界限应如何划分” 的问题 [415]。在 21 世纪 20 年代初的人工智能热潮中,许多企业将 “人工智能” 用作营销术语(marketing buzzword),即便它们 “并未真正实质性地使用人工智能技术”[416]。
目前,关于大型语言模型(large language models)展现的是 “真正的智能”,还是仅通过模仿人类文本 “模拟智能”,仍存在争议 [417]。
人工智能方法的评估(Evaluating Approaches to AI)
在人工智能发展的大部分历史中,尚未有统一的理论(unifying theory)或范式(paradigm)指导研究 [aa][418]。21 世纪 10 年代,统计机器学习(statistical machine learning)取得了前所未有的成功,使其影响力远超其他方法(以至于部分领域,尤其是商业领域,将 “人工智能” 等同于 “基于神经网络的机器学习”)。这种方法主要属于 “亚符号”(sub-symbolic)、“软计算”(soft)和 “狭义”(narrow)范畴。批评者认为,未来的人工智能研究者可能需要重新审视这些问题。
符号主义人工智能及其局限性(Symbolic AI and Its Limits)
符号主义人工智能(Symbolic AI,又称 “有效的老式人工智能”(GOFAI))[419] 模拟人类解决谜题、进行法律推理(legal reasoning)和数学运算时的 “高层有意识推理”(high-level conscious reasoning)。在代数、智商测试(IQ tests)等 “智能” 任务中,这种方法表现出色。20 世纪 60 年代,纽厄尔(Newell)与西蒙(Simon)提出 “物理符号系统假说”(physical symbol systems hypothesis):“物理符号系统是实现通用智能行为的必要且充分条件”[420]。
然而,符号主义方法在许多人类轻松完成的任务(如学习、物体识别、常识推理(commonsense reasoning))中表现糟糕。“莫拉维克悖论”(Moravec's paradox)指出,人工智能擅长完成 “高层智能任务”,但在 “低层本能任务”(low level "instinctive" tasks)上却极为困难 [421]。哲学家休伯特・德雷福斯(Hubert Dreyfus)从 20 世纪 60 年代起就主张,人类的专业能力依赖于 “无意识本能”(unconscious instinct)而非 “有意识的符号操纵”(conscious symbol manipulation),依赖于对情境的 “直觉把握”(feel for the situation)而非 “明确的符号知识”(explicit symbolic knowledge)[422]。尽管他的观点最初遭到嘲笑和忽视,但最终人工智能研究领域逐渐认同了他的看法 [ab][16][423]。
这一问题尚未解决:亚符号推理(sub-symbolic reasoning)可能会犯下与人类直觉类似的、难以解释的错误,例如算法偏见(algorithmic bias)。诺姆・乔姆斯基(Noam Chomsky)等批评者认为,要实现通用智能,仍需持续研究符号主义人工智能 [424][425],部分原因在于亚符号人工智能偏离了 “可解释人工智能”(explainable AI)方向 —— 我们可能难以甚至无法理解现代统计型人工智能程序做出特定决策的原因。新兴的 “神经符号人工智能”(neuro-symbolic artificial intelligence)领域正试图融合这两种方法。
简洁派与杂乱派(Neat vs. Scruffy)
(主条目:简洁派与杂乱派(Neats and scruffies))
“简洁派”(Neats)认为,可通过简单、简洁的原则(如逻辑、优化、神经网络)描述智能行为;“杂乱派”(Scruffies)则认为,智能必然需要解决大量不相关的问题。简洁派通过理论严谨性(theoretical rigor)证明其程序的合理性,杂乱派则主要依赖增量测试(incremental testing)验证程序是否有效。20 世纪 70 至 80 年代,这一争议曾被广泛讨论 [426],但最终被认为无关紧要 —— 现代人工智能同时包含两种方法的元素。
软计算与硬计算(Soft vs. Hard Computing)
(主条目:软计算(Soft computing))
对于许多重要问题,寻找 “可证明正确” 或 “最优” 的解决方案是难以实现的 [15]。软计算(soft computing)是一组技术的统称,包括遗传算法(genetic algorithms)、模糊逻辑(fuzzy logic)和神经网络,能够容忍不精确(imprecision)、不确定性(uncertainty)、部分真实(partial truth)和近似值(approximation)。软计算于 20 世纪 80 年代末提出,21 世纪最成功的人工智能程序多为 “基于神经网络的软计算” 实例。
狭义人工智能与通用人工智能(Narrow vs. General AI)
(主条目:弱人工智能(Weak artificial intelligence)、通用人工智能(Artificial general intelligence))
人工智能研究者在 “是否直接追求通用人工智能与超级智能目标”,还是 “通过解决尽可能多的特定问题(狭义人工智能)间接实现领域长期目标” 这一问题上存在分歧 [427][428]。通用智能的定义和衡量难度较大,而现代人工智能通过 “针对特定问题提供特定解决方案” 取得了更多可验证的成功。通用人工智能子领域专门研究这一方向。
机器意识、感知能力与心智(Machine Consciousness, Sentience, and Mind)
(主条目:人工智能哲学(Philosophy of artificial intelligence)、人工意识(Artificial consciousness))
在心灵哲学(philosophy of mind)领域,关于 “机器是否能拥有与人类相同意义上的心智、意识和心理状态(mental states)”,目前尚未达成共识。这一问题关注的是机器的 “内部体验”(internal experiences),而非 “外部行为”。主流人工智能研究认为这一问题无关紧要,因为它不影响领域目标 —— 即研发能利用智能解决问题的机器。罗素与诺维格补充道:“要让机器拥有与人类完全相同的意识,这一额外目标超出了我们当前的能力范围”[429]。然而,这一问题已成为心灵哲学的核心议题,也是科幻作品中人工智能相关情节的常见核心冲突。
意识(Consciousness)
(主条目:意识难题(Hard problem of consciousness)、心理理论(Theory of mind))
大卫・查尔默斯(David Chalmers)提出,理解心智存在两个问题,他将其命名为意识的 “易题”(easy problem)与 “难题”(hard problem)[430]。“易题” 指理解大脑如何处理信号、制定计划和控制行为;“难题” 则指解释 “这些过程为何会产生主观感受”,或 “为何会有‘感受’这种体验本身”(假设我们认为 “感受” 确实存在 —— 丹尼特(Dennett)的 “意识幻觉论”(consciousness illusionism)认为这只是一种幻觉)。人类的信息处理过程易于解释,但人类的主观体验(subjective experience)却难以说明。例如,我们很容易想象一个色盲者通过学习识别视野中的红色物体,但无法确定要让他 “真正感知红色” 需要满足哪些条件 [431]。
计算主义与功能主义(Computationalism and Functionalism)
(主条目:心智计算理论(Computational theory of mind)、功能主义(心灵哲学)(Functionalism (philosophy of mind)))
计算主义(Computationalism)是心灵哲学中的一种观点,认为人类心智是一个信息处理系统(information processing system),而思考(thinking)是一种计算形式(form of computing)。该理论认为,心智与身体的关系类似于软件与硬件的关系,因此可能是解决身心问题(mind–body problem)的一种方案。这一哲学观点受 20 世纪 60 年代人工智能研究者和认知科学家(cognitive scientists)研究的启发,由哲学家杰瑞・福多尔(Jerry Fodor)和希拉里・普特南(Hilary Putnam)首次提出 [432]。
哲学家约翰・塞尔(John Searle)将这一观点称为 “强人工智能”(strong AI):“经过适当编程、输入输出正确的计算机,将拥有与人类完全相同意义上的心智”[ac][433][434][435]。塞尔通过 “中文房间论证”(Chinese room argument)质疑这一观点,试图证明即便计算机能完美模拟人类行为,也不意味着它拥有心智 [436]。
人工智能的福祉与权利(AI Welfare and Rights)
目前,我们难以甚至无法可靠评估先进人工智能是否具有感知能力(sentient)—— 即是否有 “感受能力”(ability to feel),以及感知能力的程度 [437]。但如果某台机器有显著可能 “感受痛苦”,那么它或许应像动物一样,享有特定权利或福祉保护措施(welfare protection measures)[438][439]。“智慧”(Sapience,指与高级智能相关的能力集合,如洞察力(discernment)或自我意识(self-awareness))可能为人工智能权利提供另一项道德依据 [438]。“机器人权利”(Robot rights)有时也被视为让自主智能体(autonomous agents)融入社会的一种实用方案 [440]。
人工智能的发展使人们对这一话题的关注度日益提升。人工智能福祉与权利的支持者常提出,若人工智能出现感知能力,其感知很可能被轻易否定。他们警告,这可能成为一个 “道德盲点”(moral blind spot),类似奴隶制(slavery)或工厂化养殖(factory farming)—— 若具备感知能力的人工智能被创造出来并遭到随意剥削,可能会导致大规模痛苦 [439][438]。
未来(Future)
超级智能与奇点(Superintelligence and the Singularity)
超级智能(superintelligence)是一种假设性的智能体(agent),其智能水平远超人类中最聪明、最具天赋者的心智能力 [428]。若通用人工智能(artificial general intelligence)研究能开发出足够智能的软件,该软件或许能自行重新编程并实现自我改进。而改进后的软件在自我优化方面会更高效,进而引发 I・J・古德(I. J. Good)所说的 “智能爆炸”(intelligence explosion),以及弗诺・文奇(Vernor Vinge)提出的 “奇点”(singularity)[444]。
然而,技术无法无限期地以指数级速度进步,其发展通常遵循 “S 型曲线”(S-shaped curve)—— 当技术接近物理极限(physical limits)时,进步速度会逐渐放缓 [445]。
超人类主义(Transhumanism)
(主条目:超人类主义(Transhumanism))
机器人设计师汉斯・莫拉维克(Hans Moravec)、控制论专家凯文・沃里克(Kevin Warwick)以及发明家雷・库兹韦尔(Ray Kurzweil)预测,未来人类可能与机器融合,形成能力远超两者的赛博格(cyborgs)。这种被称为 “超人类主义”(transhumanism)的理念,最早可追溯至奥尔德斯・赫胥黎(Aldous Huxley)和罗伯特・埃廷格(Robert Ettinger)的著作 [446]。
爱德华・弗雷德金(Edward Fredkin)认为 “人工智能是进化的下一步”。这一观点最早由塞缪尔・巴特勒(Samuel Butler)在 1863 年的《机器中的达尔文》(Darwin among the Machines)中提出,后经乔治・戴森(George Dyson)在其 1998 年的著作《机器中的达尔文:全球智能的进化》(Darwin Among the Machines: The Evolution of Global Intelligence)进一步拓展 [447]。
科幻作品中的人工智能(In Fiction)
(主条目:科幻作品中的人工智能(Artificial intelligence in fiction))
“机器人”(robot)一词本身由卡雷尔・恰佩克(Karel Čapek)在其 1921 年的戏剧《R.U.R.》中创造,剧名全称为 “罗苏姆的万能机器人”(Rossum's Universal Robots)。
早在古代,具备思维能力的人造生命体就已作为叙事元素出现在故事中 [448],并成为科幻作品中经久不衰的主题 [449]。
这类作品中常见的叙事套路,可追溯至玛丽・雪莱(Mary Shelley)的《弗兰肯斯坦》(Frankenstein)—— 人类的造物最终对创造者构成威胁。类似作品包括亚瑟・C・克拉克(Arthur C. Clarke)与斯坦利・库布里克(Stanley Kubrick)1968 年合作的《2001 太空漫游》(2001: A Space Odyssey)(片中掌控 “发现一号” 宇宙飞船的杀人计算机 HAL 9000)、《终结者》(The Terminator,1984)以及《黑客帝国》(The Matrix,1999)。与之相对,《地球停转之日》(The Day the Earth Stood Still,1951)中的机器人戈特(Gort)、《异形 2》(Aliens,1986)中的机器人毕肖普(Bishop)等少数 “忠诚机器人” 形象,在流行文化中的影响力则相对较弱 [450]。
艾萨克・阿西莫夫(Isaac Asimov)在多部作品中提出了 “机器人三定律”(Three Laws of Robotics),其中最著名的是围绕超级智能计算机 “Multivac” 展开的故事。在非专业领域讨论机器伦理时,阿西莫夫定律常被提及 [451];尽管几乎所有人工智能研究者都通过流行文化了解到这一定律,但他们普遍认为该定律并无实际用途,原因之一便是其表述存在模糊性 [452]。
另有多部作品借助人工智能,迫使人们直面 “何为人类本质” 这一核心问题 —— 这些作品中的人造生命体拥有感受能力,进而也能感知痛苦。例如卡雷尔・恰佩克的《R.U.R.》、电影《人工智能》(A.I. Artificial Intelligence)与《机械姬》(Ex Machina),以及菲利普・K・迪克(Philip K. Dick)的小说《仿生人会梦见电子羊吗?》(Do Androids Dream of Electric Sheep?)。迪克在作品中探讨了一个观点:人工智能技术的出现,可能会改变我们对人类主观性(human subjectivity)的理解 [453]。
零基础入门AI大模型必看
陆陆续续也整理了不少资源,希望能帮大家少走一些弯路!
无论是学业还是事业,都希望你顺顺利利 !
1️⃣ 大模型入门学习路线图(附学习资源)
2️⃣ 大模型方向必读书籍PDF版
3️⃣ 大模型面试题库
4️⃣ 大模型项目源码
5️⃣ 超详细海量大模型LLM实战项目
6️⃣ Langchain/RAG/Agent学习资源
7️⃣ LLM大模型系统0到1入门学习教程
8️⃣ 吴恩达最新大模型视频+课件
以上大模型资料包的内容都整理在了我的gzh里,【小灰熊大模型】回复【6】自动掉落,都是🈚️尝分享,可以自取~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)