LangSmith-智能应用可见性
本文介绍了如何使用LangSmith工具对大模型应用进行开发和监控。首先演示了一个基于PDF文档的RAG应用构建过程,包括文档加载、文本分割、向量存储和信息检索。随后详细说明了如何通过设置环境变量和封装模型,使用LangSmith跟踪大模型调用过程,包括输入输出记录和完整应用流程跟踪。文章还展示了LangSmith对LangChain原生支持的特性,通过简单的环境变量配置即可实现对智能体(agen
1.概述
LangSmith提供了用于开发、调试和部署大模型应用的工具,使用LangSmith,开发人员可以对智能应用运行进行跟踪,从而实现应用的可观察性;对输出结果进行评估,从而对智能应用质量进行评价;实施提示词工程,创建、管理和优化提示词。LangSmith提供的免费版和收费版,个人开发和测试使用免费版即可。本文基于一个简单的RAG应用,说明如何使用LangSmith跟踪智能应用的运行过程。
2.创建简单RAG
如下代码创建一个基础RAG,不需赘述:
from langchain_community.document_loaders import PyPDFLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitterfrom openai import OpenAI
#PDF加载器加载文档
loader = PyPDFLoader ("../data/beijing_annual_report_2024.pdf")
docs = loader.load()#使用RecursiveCharacterTextSplitter进行文档切分
character_splitter = RecursiveCharacterTextSplitter(
#separators=["\n\n", "\n", ". ", " ", ""],英文文档的分割符示例
separators=["\n\n", "\n", "。", ",", "、", ";", ""],
chunk_size=1000,
chunk_overlap=0)splits = character_splitter.split_documents(docs)
#把分块保存到向量库,向量库使用chromadb
embedding = HuggingFaceEmbeddings(
model_name='../models/text2vec-base-chinese' # 高效的语义模型
)
persist_directory = "../data/chroma"
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)#定义检索函数
def retrieve(query: str):
"""Retrieve information to help answer a query."""
retrieved_docs = vectordb.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs#创建大模型,使用千问
client = OpenAI(
api_key="sk-*",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)#定义RAG方法
def rag(question: str) -> str:
serialized, raw_docs = retrieve(question)
system_message = (
f"Answer the user's question using only the provided information below:{serialized}\n"
)resp = client.chat.completions.create(
model="qwen-max",
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
)
return resp.choices[0].message.content
3.增加可见性
设置LangSmith相关的环境变量,需要事先在LangSmith注册才能获取KEY和工作空间ID:
import os
os.environ['LANGSMITH_TRACING'] = 'true'
os.environ['LANGSMITH_API_KEY'] = 'lsv2_sk_*'
os.environ['LANGSMITH_WORKSPACE_ID'] = '*'
对大模型进行封装,修改相关代码:
from langsmith.wrappers import wrap_openai # traces openai calls
model = OpenAI(
api_key="sk-*",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
client = wrap_openai(model)
运行应用:
rag("北京市政府工作报告中关于改善民生有哪些举措?")
登录LangSmith平台,可以看到调用大模型时的输入、输出:
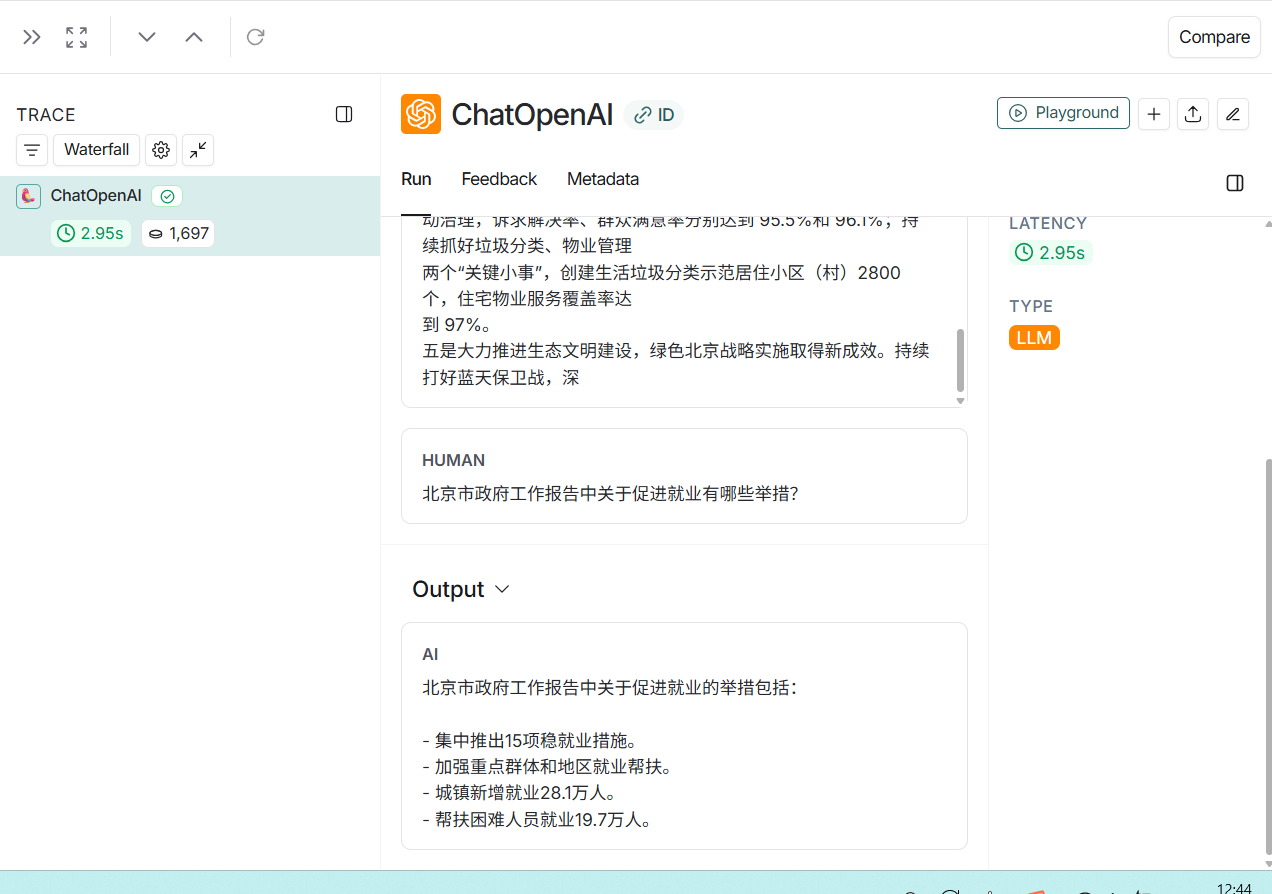
以上示例中仅跟踪大模型调用,还可以对整个应用进行跟踪,此时需要用@traceable对rag方法增加注解:
from langsmith import traceable
@traceable
def rag(question: str) -> str:
……
再次运行后,查看跟踪页面,效果如下:
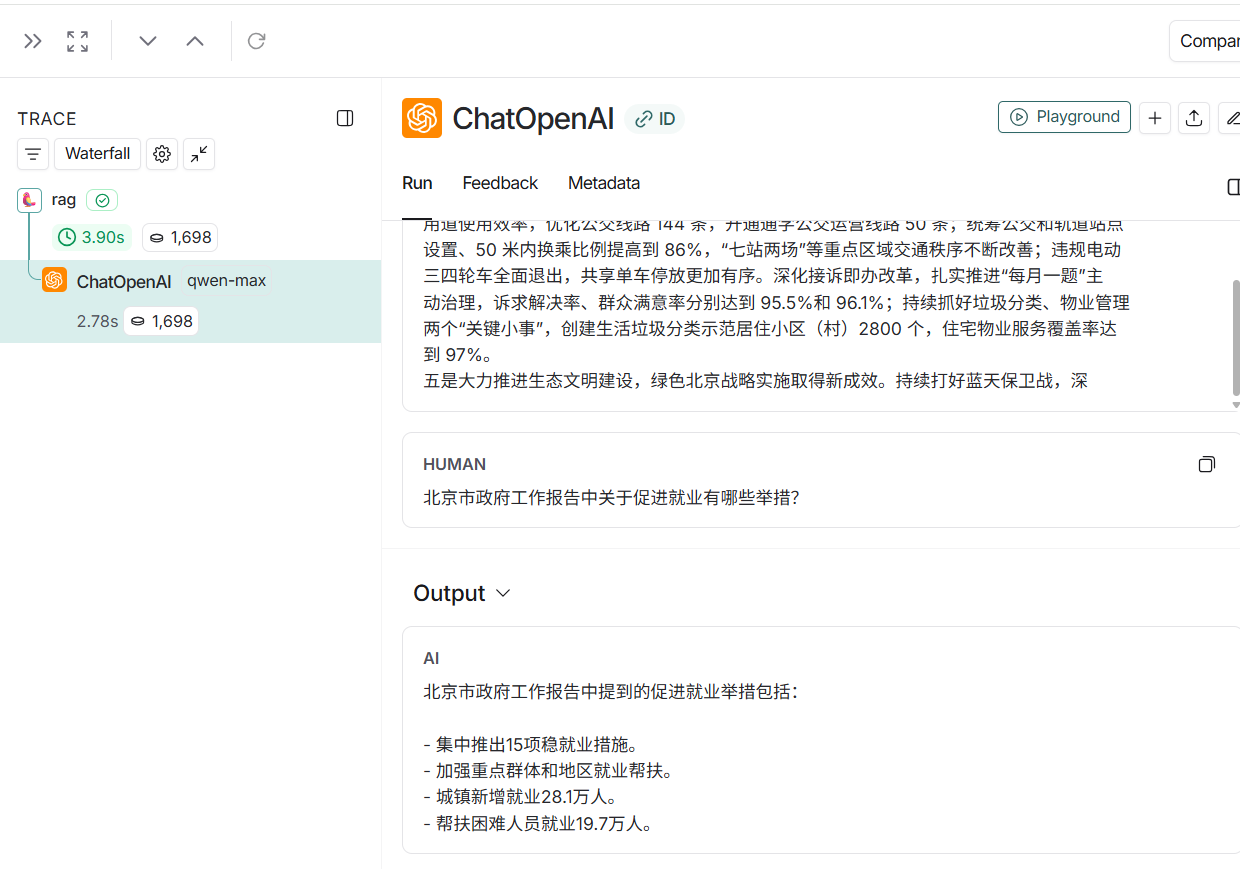 4.langchain agent
4.langchain agent
前面的应用使用的标准OpenAI接口创建大模型,LangSmith当然对于langchain(包括链、图和智能体)更是原生支持。对于你既有的应用,仅需要增加三个必须得环境变量即可,原有代码不需做任何修改就可以使用LangSmith进行跟踪。
以下是示例代码是用的langchain agent:
#增加三个环境变量
import os
os.environ['LANGSMITH_TRACING'] = 'true'
os.environ['LANGSMITH_API_KEY'] = 'lsv2_sk_*'
os.environ['LANGSMITH_WORKSPACE_ID'] = '*'
agent代码如下:
#创建大模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model = 'qwen-plus',
api_key = "sk-*",
base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1")#定义检索工具
@tool
def retrieve(query: str):
"""Retrieve information to help answer a query."""
retrieved_docs = vectordb.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs#创建智能体
from langchain.agents import create_agent
agent = create_agent(
model=llm,
tools=[retrieve,]
)#调用
result = agent.invoke({
"messages": [{"role": "user", "content": "北京市政府工作报告中关于促进就业有哪些举措?"}]
})
登录LangSmith,查看跟踪页面如下:
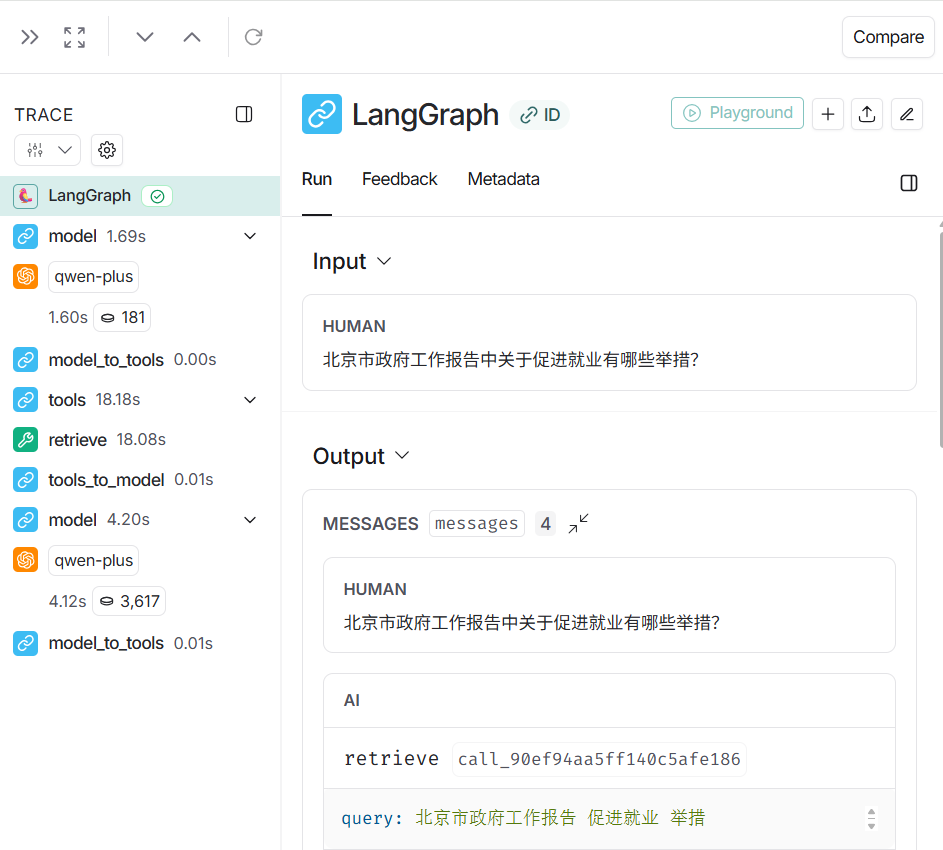

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)