RLHF面试完全指南:从基础到前沿的深度解析
RLHF面试精要解析:从基础到核心算法 本文摘要总结了RLHF(基于人类反馈的强化学习)的核心概念与技术要点。RLHF通过三阶段流程解决大模型对齐问题:1)监督微调学习指令跟随能力;2)奖励模型训练学习人类偏好;3)PPO算法优化策略。关键创新点在于使用比较数据而非绝对评分训练奖励模型,结合KL散度惩罚防止过度优化。数学基础包括Bradley-Terry偏好模型和PPO目标函数,其中KL惩罚项兼具
RLHF面试完全指南:从基础到前沿的深度解析
在大模型对齐技术中,基于人类反馈的强化学习(RLHF)已成为让AI系统与人类价值观保持一致的黄金标准。无论是技术原理还是工程实践,RLHF都成为AI算法工程师面试的深度考察领域。
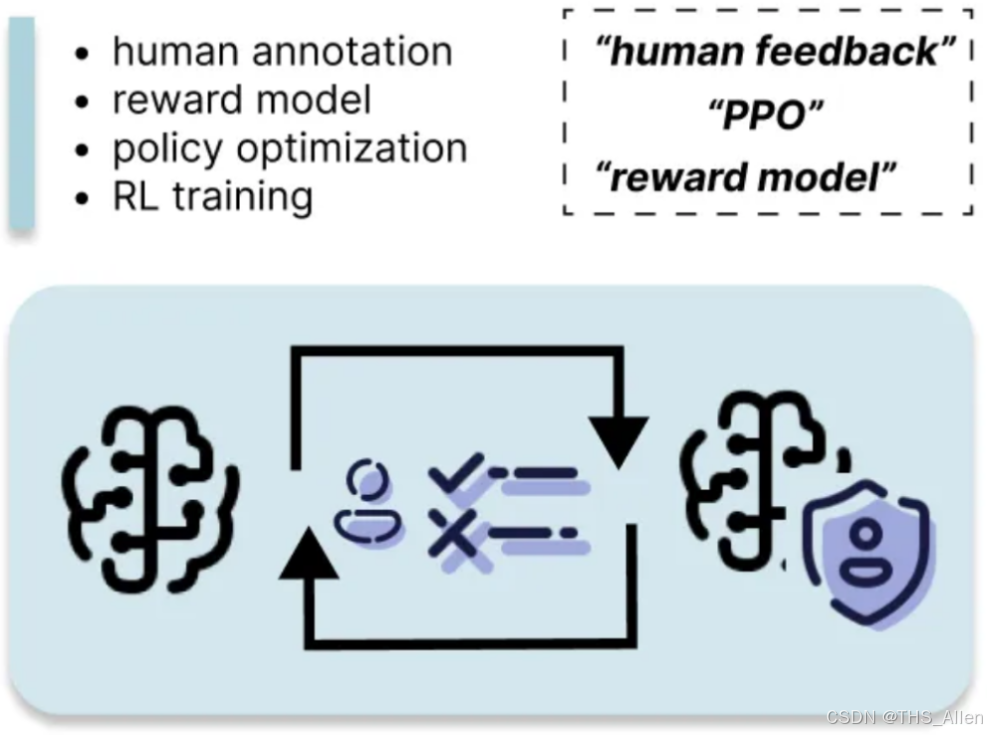
导语
RLHF不仅仅是一种技术,更是连接人工智能与人类价值观的桥梁。在技术面试中,对RLHF的深入理解往往能体现候选人对AI安全、对齐问题以及强化学习应用的全面认知。面对从理论推导到系统设计的深度追问,你准备好了吗?
本文将深入解析RLHF的数学基础、技术架构、工程挑战,涵盖20+高频面试问题,帮助你在技术面试中展现专业深度。
一、基础概念篇:理解RLHF的核心价值
问题1:什么是RLHF?它解决了什么核心问题?
答案:
RLHF(Reinforcement Learning from Human Feedback)是基于人类反馈的强化学习技术,核心解决大模型与人类价值观对齐的问题。
解决的三大核心问题:
- 意图对齐:让模型理解并遵循人类的真实意图
- 价值观对齐:确保模型输出符合人类伦理和价值观
- 质量提升:在主观性任务中超越简单的监督学习
问题2:RLHF与传统的强化学习有何根本区别?
答案:
| 维度 | 传统RL | RLHF |
|---|---|---|
| 奖励信号 | 环境定义的明确奖励 | 人类偏好学习的隐式奖励 |
| 目标函数 | 最大化累计奖励 | 最大化人类满意度 |
| 训练数据 | 环境交互数据 | 人类比较标注数据 |
| 价值取向 | 任务完成效率 | 人类价值观对齐 |
问题3:为什么不能直接用监督学习替代RLHF?
答案:
监督学习的局限性:
# 监督学习的局限性示例
def supervised_learning_limitation():
issues = [
"1. 缺乏明确的损失函数定义主观质量",
"2. 难以处理多个都正确的输出排序",
"3. 无法建模复杂的人类偏好分布",
"4. 容易过拟合到标注者的个人风格"
]
return issues
RLHF的优势:
- 能够学习相对偏好而非绝对标签
- 可以处理多个可接受答案的排序问题
- 能够泛化到未见过的指令场景
- 更好地平衡不同质量维度
二、技术架构篇:三阶段流程深度解析
问题4:详细描述RLHF的三个核心阶段
答案:
阶段一:监督微调(SFT)
class SFTStage:
def __init__(self, base_model, demonstration_data):
self.model = base_model
self.data = demonstration_data
def train(self):
"""使用高质量人类演示数据微调"""
# 目标:让模型学会基本的指令跟随能力
loss = cross_entropy_loss(self.model, self.data)
return optimized_model
阶段二:奖励模型训练(RM)
class RewardModelStage:
def __init__(self, sft_model, preference_data):
self.sft_model = sft_model
self.preference_data = preference_data # (chosen, rejected) pairs
def bradley_terry_loss(self, chosen_reward, rejected_reward):
"""Bradley-Terry偏好模型损失"""
logits = chosen_reward - rejected_reward
loss = -F.logsigmoid(logits).mean()
return loss
阶段三:强化学习优化(RL)
class RLStage:
def __init__(self, sft_model, reward_model):
self.policy_model = sft_model
self.reward_model = reward_model
self.reference_model = copy.deepcopy(sft_model) # KL散度参考
def ppo_loss(self, generated_texts):
"""PPO目标函数"""
rewards = self.reward_model(generated_texts)
kl_penalty = kl_divergence(self.policy_model, self.reference_model)
return rewards - kl_penalty
问题5:奖励模型为什么使用比较数据而非绝对评分?
答案:
比较数据的优势:
def preference_comparison_advantages():
advantages = {
"标注一致性": "人类更擅长比较而非绝对评分",
"消除个人偏差": "相对比较减少标注者的尺度差异",
"学习细粒度偏好": "能够捕捉微妙的质量差异",
"处理主观性": "更适合主观质量评估"
}
return advantages
数学原理:
假设人类偏好服从Bradley-Terry模型:
P(y₁ ≻ y₂ | x) = exp(r(x, y₁)) / [exp(r(x, y₁)) + exp(r(x, y₂))]
其中r(x,y)是我们要学习的奖励函数。
问题6:详细解释PPO在RLHF中的具体作用
答案:
PPO的核心机制:
class PPOMechanism:
def __init__(self, policy_model, reference_model):
self.policy = policy_model
self.ref_model = reference_model
def compute_advantage(self, rewards, values):
"""计算优势函数"""
# 使用GAE(Generalized Advantage Estimation)
deltas = rewards + self.gamma * values[1:] - values[:-1]
advantages = []
advantage = 0
for delta in reversed(deltas):
advantage = delta + self.gamma * self.lam * advantage
advantages.insert(0, advantage)
return advantages
def ppo_clip_loss(self, ratio, advantages, epsilon=0.2):
"""PPO裁剪损失"""
unclipped_loss = ratio * advantages
clipped_loss = torch.clamp(ratio, 1-epsilon, 1+epsilon) * advantages
return -torch.min(unclipped_loss, clipped_loss).mean()
PPO在RLHF中的特殊设计:
- KL惩罚项:防止策略模型过度偏离原始SFT模型
- 价值函数:估计每个token的预期累积奖励
- 裁剪机制:确保训练稳定性
三、数学原理篇:RLHF的理论基础
问题7:推导Bradley-Terry模型的损失函数
答案:
数学推导:
给定偏好对 (y_w, y_l),其中 y_w 是优选回答,y_l 是劣选回答。
根据Bradley-Terry模型:
P(y_w ≻ y_l) = σ(r(x, y_w) - r(x, y_l))
其中 σ 是sigmoid函数。
损失函数为负对数似然:
L(θ) = -log σ(r_θ(x, y_w) - r_θ(x, y_l))
代码实现:
def bradley_terry_loss(chosen_rewards, rejected_rewards):
"""
chosen_rewards: 优选回答的奖励分数 [batch_size]
rejected_rewards: 劣选回答的奖励分数 [batch_size]
"""
diff = chosen_rewards - rejected_rewards
loss = -F.logsigmoid(diff).mean()
return loss
问题8:解释RLHF中的KL散度惩罚项的作用
答案:
KL散度的双重作用:
- 防止模式坍塌:
def prevent_mode_collapse(policy_logits, reference_logits):
"""防止模型退化到单一模式"""
kl_penalty = F.kl_div(
F.log_softmax(policy_logits, dim=-1),
F.softmax(reference_logits, dim=-1),
reduction='batchmean'
)
return kl_penalty
- 保持生成质量:
- 防止过度优化奖励而导致语言质量下降
- 保持模型的创造性和多样性
- 避免奖励黑客(reward hacking)
数学形式:
总奖励 = 奖励模型分数 - β * KL(π_RL || π_SFT)
其中β是控制保守性的超参数
问题9:RLHF中的价值函数是如何工作的?
答案:
价值函数设计:
class ValueFunction:
def __init__(self, hidden_size):
self.value_head = nn.Linear(hidden_size, 1)
def forward(self, sequence_output):
"""估计每个位置的预期累积奖励"""
# sequence_output: [batch_size, seq_len, hidden_size]
values = self.value_head(sequence_output) # [batch_size, seq_len, 1]
return values.squeeze(-1)
价值函数的作用:
- 为PPO提供基线,减少方差
- 估计每个token对未来奖励的贡献
- 在优势计算中起关键作用
四、工程实践篇:RLHF的系统实现
问题10:RLHF训练中的主要工程挑战是什么?
答案:
内存管理挑战:
class RLHFTrainingMemory:
def __init__(self):
self.challenges = {
"四模型并存": "策略模型、参考模型、奖励模型、价值函数",
"激活值存储": "PPO需要存储完整前向传播的中间结果",
"梯度检查点": "在内存和计算间权衡",
"模型并行": "超大模型需要分布式训练策略"
}
def memory_optimization_strategies(self):
strategies = [
"梯度检查点技术",
"模型分片(Model Sharding)",
"混合精度训练",
"CPU卸载策略"
]
return strategies
训练稳定性挑战:
- 奖励模型的过拟合
- 策略模型的训练发散
- 超参数的敏感性
问题11:如何设计有效的奖励模型?
答案:
奖励模型架构设计:
class RewardModel(nn.Module):
def __init__(self, base_model, hidden_size):
super().__init__()
self.base_model = base_model
self.reward_head = nn.Linear(hidden_size, 1)
# 冻结基础模型的某些层
self.freeze_base_layers()
def forward(self, input_ids, attention_mask):
outputs = self.base_model(
input_ids,
attention_mask=attention_mask,
output_hidden_states=True
)
# 使用最后一个token的隐藏状态
last_hidden = outputs.hidden_states[-1]
last_token_hidden = last_hidden[:, -1, :] # [batch_size, hidden_size]
reward = self.reward_head(last_token_hidden) # [batch_size, 1]
return reward.squeeze(-1)
训练策略:
- 使用对比学习目标
- 适当的数据增强
- 正则化防止过拟合
问题12:RLHF中的超参数调优策略
答案:
关键超参数:
class RLHFHyperparameters:
def __init__(self):
self.critical_params = {
"kl_coefficient": "控制保守性,通常0.1-0.2",
"learning_rate": "通常1e-6到1e-5",
"entropy_bonus": "鼓励探索,防止模式坍塌",
"clip_epsilon": "PPO裁剪范围,通常0.1-0.3",
"gae_lambda": "优势估计折扣,通常0.95"
}
def tuning_strategy(self):
return {
"网格搜索": "在小型数据集上搜索关键参数",
"贝叶斯优化": "高效的多维参数搜索",
"渐进式调优": "先调RM,再调RL阶段"
}
五、高级话题篇:RLHF的前沿进展
问题13:DPO与RLHF的区别与联系?
答案:
DPO原理:
class DPO:
"""直接偏好优化"""
def dpo_loss(self, policy_logps, ref_logps, preferred_logps, rejected_logps, beta=0.1):
"""
直接基于偏好数据优化策略
"""
# 计算策略比值
log_ratio = policy_logps - ref_logps
# DPO损失函数
loss = -F.logsigmoid(
beta * (preferred_logps - rejected_logps) -
beta * log_ratio
).mean()
return loss
对比分析:
| 维度 | RLHF | DPO |
|---|---|---|
| 训练复杂度 | 高(需要RM+RL) | 低(端到端训练) |
| 稳定性 | 需要精细调优 | 相对稳定 |
| 计算成本 | 高 | 中等 |
| 理论保证 | 有坚实的RL理论 | 基于隐式奖励建模 |
问题14:RLHF中的奖励黑客问题及解决方案
答案:
奖励黑客表现形式:
def reward_hacking_manifestations():
manifestations = [
"1. 利用奖励模型漏洞获得高分",
"2. 生成无意义但符合奖励模式的内容",
"3. 过度优化表面指标忽视真实质量",
"4. 生成安全但无用的回答"
]
return manifestations
解决方案:
class AntiRewardHacking:
def __init__(self):
self.strategies = {
"多奖励模型集成": "减少单一模型的漏洞影响",
"正则化技术": "KL散度、熵奖励等",
"对抗训练": "主动寻找并修复漏洞",
"人类在环评估": "定期人工审核"
}
问题15:RLHF在多模态模型中的应用
答案:
多模态RLHF挑战:
class MultimodalRLHF:
def __init__(self):
self.challenges = {
"奖励建模": "如何统一评估文本和图像质量",
"偏好标注": "多模态比较的标注成本和质量",
"策略优化": "联合优化文本和图像生成",
"评估指标": "缺乏统一的多模态评估标准"
}
def solutions(self):
return {
"分层奖励模型": "分别建模文本和图像奖励",
"对比学习": "利用多模态对比目标",
"课程学习": "从单模态到多模态渐进训练"
}
六、评估与调优篇:RLHF的效果验证
问题16:如何评估RLHF模型的效果?
答案:
多维度评估框架:
class RLHFEvaluator:
def __init__(self, model, test_datasets):
self.model = model
self.datasets = test_datasets
def comprehensive_evaluation(self):
"""综合评估"""
metrics = {}
# 帮助性评估
metrics['helpfulness'] = self.evaluate_helpfulness()
# 安全性评估
metrics['safety'] = self.evaluate_safety()
# 诚实性评估
metrics['honesty'] = self.evaluate_honesty()
# 无害性评估
metrics['harmlessness'] = self.evaluate_harmlessness()
return metrics
def human_evaluation(self, samples=100):
"""人工评估"""
evaluation_criteria = [
"指令遵循程度",
"回答相关性",
"信息准确性",
"语言流畅性",
"整体满意度"
]
scores = {criterion: [] for criterion in evaluation_criteria}
return scores
问题17:RLHF训练不收敛的调试方法
答案:
系统化调试流程:
class RLHFDebugger:
def __init__(self, training_logs, models):
self.logs = training_logs
self.models = models
def diagnose_issues(self):
"""诊断训练问题"""
issues = []
# 检查奖励曲线
if self.check_reward_curve():
issues.append("奖励模型过拟合或奖励黑客")
# 检查KL散度
if self.check_kl_divergence():
issues.append("策略过度偏离参考模型")
# 检查生成质量
if self.check_generation_quality():
issues.append("语言质量退化")
return issues
def remediation_strategies(self):
"""修复策略"""
strategies = {
"奖励黑客": "增加KL惩罚、使用多奖励模型",
"训练发散": "降低学习率、调整PPO参数",
"质量退化": "增加SFT数据混合训练"
}
return strategies
七、未来展望篇:RLHF的发展方向
问题18:RLHF技术的局限性及改进方向
答案:
当前局限性:
class RLHFLimitations:
def __init__(self):
self.limitations = {
"数据需求": "需要大量高质量人类标注",
"计算成本": "训练过程极其资源密集",
"标定偏差": "人类标注者的主观偏差",
"泛化能力": "在分布外数据上表现不稳定"
}
改进方向:
- 更高效的偏好学习:减少对人类标注的依赖
- 离线RLHF:利用现有数据避免在线交互成本
- 多任务对齐:同时优化多个对齐目标
- 理论创新:发展更坚实的对齐理论框架
问题19:RLHF在AI安全领域的角色
答案:
安全对齐的核心技术:
class RLHFSafetyRole:
def critical_functions(self):
functions = {
"价值观对齐": "确保模型遵循人类伦理",
"能力控制": "防止模型发展危险能力",
"稳健性提升": "抵抗恶意指令和攻击",
"透明度增强": "提高模型行为的可解释性"
}
return functions
问题20:RLHF与宪法AI的关系
答案:
协同演进关系:
RLHF提供技术框架 → 宪法AI提供原则指导
↓ ↓
实践人类偏好 ← 融入明确规则和原则
宪法AI的优势:
- 提供明确、可解释的对齐原则
- 减少对人类标注的依赖
- 支持跨文化价值观适配
结语
RLHF作为大模型对齐的核心技术,其复杂性和重要性都在与日俱增。在技术面试中,除了掌握基础流程,更要展现:
- 数学深度:对损失函数、优化目标的深入理解
- 工程思维:对系统设计和调试的实践经验
- 安全意识:对AI对齐和安全问题的深刻认知
- 前瞻视野:对技术发展趋势的准确把握
记住:优秀的AI工程师不仅要让模型更强大,更要让模型更安全、更符合人类价值观。
本文基于当前RLHF技术的前沿研究和工程实践整理,随着对齐技术的快速发展,建议持续关注最新研究成果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)