模型微调(SFT)面试完全指南:从基础到前沿的深度解析
监督微调(SFT)面试指南精要 监督微调(SFT)是使通用大模型适应特定任务的关键技术,在面试中常被考察。本文概述了SFT的核心要点: 基础概念: SFT位于预训练与RLHF之间,使用标注数据调整模型 相比预训练,SFT数据量小、学习率低、目标特定 与提示学习相比,SFT更新模型参数而非仅调整提示 技术原理: 目标函数基于最大似然估计 需防止灾难性遗忘,采用小学习率、正则化等策略 学习率调度策略需
模型微调(SFT)面试完全指南:从基础到前沿的深度解析
在大模型技术快速发展的今天,监督微调(SFT)已成为定制化AI能力的核心技术。无论是基础概念还是前沿进展,SFT相关的问题都成为AI工程师面试的必考内容。本文为你系统梳理SFT的完整知识体系。
导语
监督微调(Supervised Fine-Tuning)是大模型从"通才"到"专才"的关键转变环节,也是技术面试中考察候选人深度学习功底和工程实践能力的重要领域。面对从理论原理到落地实践的深度追问,你是否已经做好了万全准备?
本文将深入解析SFT的理论基础、技术实践、前沿进展,涵盖25+高频面试问题,帮助你在技术面试中展现专业深度。
一、基础概念篇:理解SFT的本质
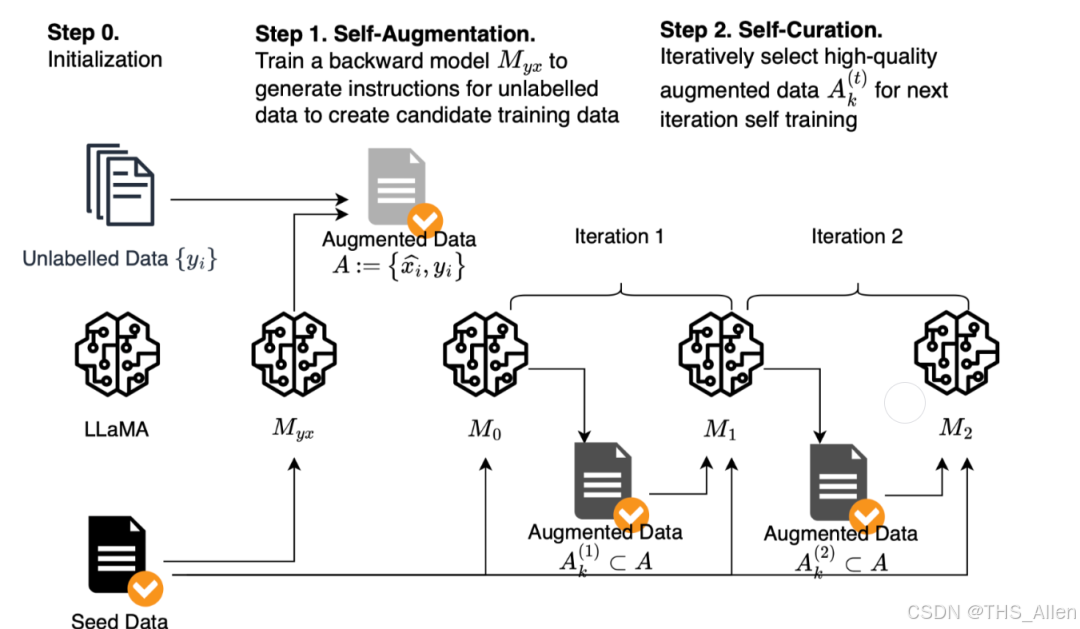
问题1:什么是监督微调(SFT)?它在LLM训练流程中的位置?
答案:
监督微调(SFT)是在预训练大模型的基础上,使用高质量的监督数据对模型进行进一步训练的技术。它在整个LLM训练流程中处于承上启下的关键位置:
预训练(Pre-training) → 监督微调(SFT) → 人类反馈强化学习(RLHF) → 部署
核心价值:
- 使通用大模型适应特定领域或任务
- 提升模型在目标任务上的准确性和可靠性
- 为后续的RLHF阶段提供良好的初始化
问题2:SFT与预训练(Pre-training)的主要区别是什么?
答案:
| 维度 | 预训练 | 监督微调 |
|---|---|---|
| 数据规模 | 海量无标注文本(TB级别) | 少量高质量标注数据(GB级别) |
| 训练目标 | 语言建模(下一个词预测) | 任务特定的监督学习 |
| 学习率 | 相对较大 | 相对较小(避免灾难性遗忘) |
| 计算成本 | 极高(数千GPU周) | 中等(数十GPU天) |
| 主要目标 | 获得通用语言能力 | 获得特定任务能力 |
问题3:SFT与提示学习(Prompt Learning)的区别与联系?
答案:
区别:
- 参数更新:SFT更新全部或部分模型参数;提示学习通常冻结主干模型,只训练少量额外参数
- 数据需求:SFT需要相对较多的标注数据;提示学习可以在少样本场景下工作
- 灵活性:SFT一旦训练完成难以快速适应新任务;提示学习更容易快速适配
联系:
- 都是使预训练模型适应下游任务的技术
- 可以结合使用,如先用SFT微调,再用提示学习快速适配
二、技术原理篇:深入SFT的核心机制
问题4:SFT的训练目标函数通常如何设计?
答案:
SFT通常采用标准的最大似然估计目标:
# 伪代码示例
def sft_loss(model, inputs, targets):
# 前向传播获取预测分布
logits = model(inputs)
# 计算交叉熵损失
loss = cross_entropy(logits, targets)
# 可选:添加正则化项防止过拟合
regularization = weight_decay * model_parameters_norm()
return loss + regularization
关键考虑:
- 只计算目标序列的损失,忽略输入序列
- 使用因果注意力掩码确保自回归性质
- 适当调整学习率避免灾难性遗忘
问题5:解释SFT中的灾难性遗忘问题及应对策略
答案:
灾难性遗忘:在微调过程中,模型过度适应新数据,导致丢失预训练阶段学到的通用知识。
应对策略:
-
学习率策略:
- 使用较小的学习率(通常1e-5到1e-4)
- 分层学习率:底层使用更小的学习率
-
正则化技术:
# 权重衰减示例 optimizer = AdamW(model.parameters(), lr=1e-5, weight_decay=0.01) # Elastic Weight Consolidation (EWC) ewc_loss = fisher_info * (current_params - pretrained_params)**2 -
数据策略:
- 在微调数据中混合部分预训练数据
- 渐进式训练:从通用任务到特定任务
问题6:SFT中如何选择合适的学习率调度策略?
答案:
常用调度策略:
-
线性暖机 + 线性衰减:
scheduler = get_linear_schedule_with_warmup( optimizer, num_warmup_steps=500, # 暖机步数 num_training_steps=total_steps ) -
余弦衰减:
- 平滑衰减,在训练末期使用很小的学习率
- 适合需要精细调优的场景
-
常量学习率:
- 简单但需要仔细调整学习率大小
- 适合数据分布与预训练数据相似的情况
选择原则:
- 小数据集:建议使用衰减策略
- 大数据集:常量或余弦衰减可能更好
- 需要验证不同策略在验证集上的效果
三、数据工程篇:SFT的数据准备与处理
问题7:SFT训练数据的关键质量要求是什么?
答案:
数据质量维度:
- 准确性:标注必须正确无误
- 多样性:覆盖任务的各种场景和边缘情况
- 一致性:相似的输入应有相似的输出格式
- 完整性:提供完整的上下文信息
数据准备流程:
数据收集 → 数据清洗 → 数据标注 → 质量验证 → 数据格式化
问题8:SFT数据应该如何进行预处理和格式化?
答案:
格式化示例:
def format_sft_example(instruction, input_text, output_text):
"""格式化SFT训练样本"""
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
{output}"""
return template.format(
instruction=instruction,
input=input_text,
output=output_text
)
预处理要点:
- 统一文本格式和分隔符
- 处理特殊字符和编码问题
- 确保序列长度在模型限制内
- 添加适当的开始/结束标记
问题9:如何评估SFT数据的质量和充分性?
答案:
数据质量评估指标:
class DataQualityEvaluator:
def __init__(self):
self.metrics = {}
def evaluate_diversity(self, dataset):
"""评估数据多样性"""
# 计算样本间的相似度
similarity_matrix = calculate_similarity(dataset)
diversity_score = 1 - average_similarity(similarity_matrix)
return diversity_score
def evaluate_consistency(self, dataset):
"""评估标注一致性"""
# 通过多人标注计算一致性
consistency_score = calculate_agreement(dataset)
return consistency_score
def estimate_data_requirements(self, task_complexity):
"""估算数据需求"""
# 基于任务复杂度估算所需数据量
base_size = 1000 # 基础数据量
complexity_factor = task_complexity * 500
return base_size + complexity_factor
四、训练策略篇:SFT的工程实践
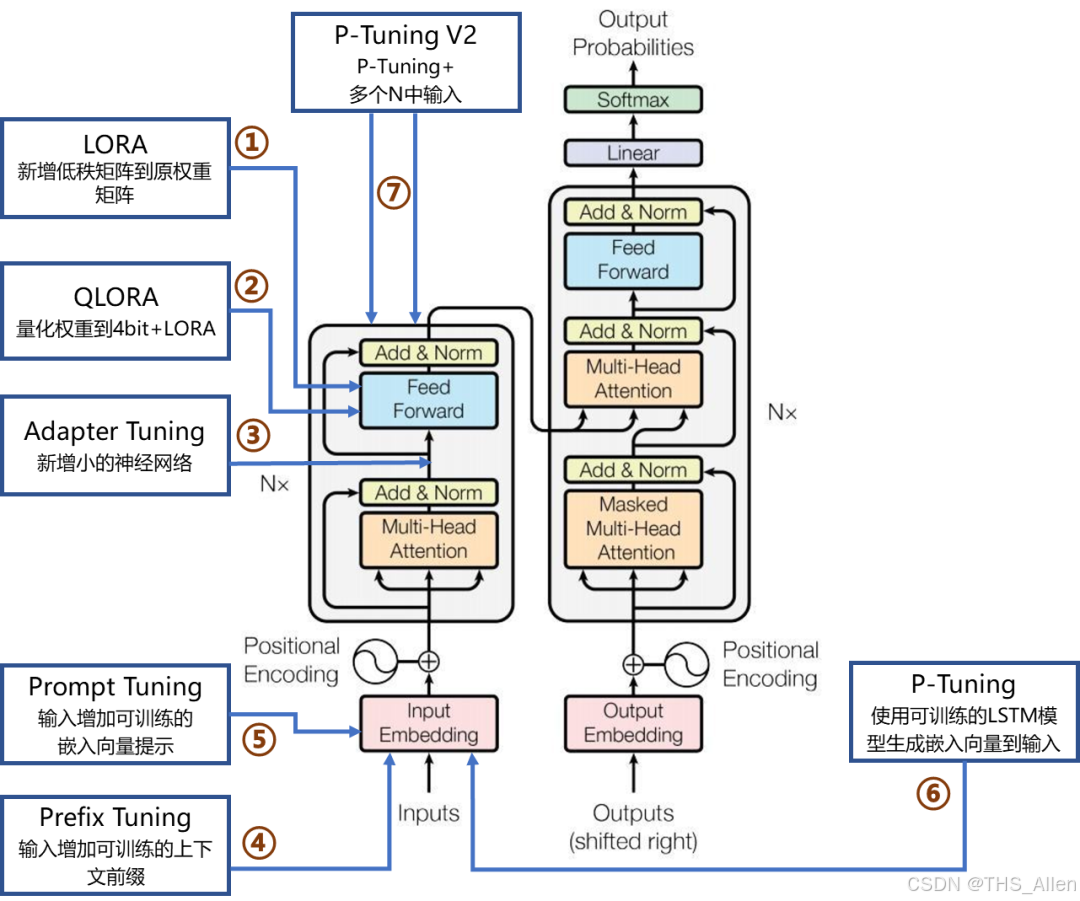
问题10:全参数微调与参数高效微调(PEFT)如何选择?
答案:
技术对比:
| 方法 | 参数量 | 计算成本 | 数据需求 | 适用场景 |
|---|---|---|---|---|
| 全参数微调 | 全部参数 | 高 | 大量数据 | 计算资源充足,性能要求极高 |
| LoRA | 0.1%-1% | 低 | 中等数据 | 资源受限,需要快速迭代 |
| Adapter | 2%-5% | 中低 | 中等数据 | 多任务学习,模块化部署 |
| Prefix Tuning | <1% | 很低 | 少样本 | 提示工程,快速原型 |
选择建议:
def select_finetuning_strategy(available_gpus, data_size, performance_requirement):
"""选择微调策略的决策逻辑"""
if available_gpus >= 4 and data_size > 10000 and performance_requirement == "high":
return "full_finetuning"
elif available_gpus <= 2 and data_size < 5000:
return "lora"
elif data_size < 1000:
return "prefix_tuning"
else:
return "adapter"
问题11:SFT训练中的过拟合问题如何监控和解决?
答案:
过拟合监控:
class OverfittingMonitor:
def __init__(self, patience=3):
self.patience = patience
self.best_val_loss = float('inf')
self.wait_count = 0
def check_overfitting(self, train_loss, val_loss):
"""检查过拟合迹象"""
# 计算训练与验证损失的差距
loss_gap = train_loss - val_loss
# 判断标准
if val_loss > self.best_val_loss:
self.wait_count += 1
else:
self.best_val_loss = val_loss
self.wait_count = 0
# 过拟合信号
overfitting_signals = [
loss_gap > 0.5, # 损失差距过大
self.wait_count >= self.patience, # 验证损失持续上升
train_loss < 0.1 and val_loss > 1.0 # 严重过拟合
]
return any(overfitting_signals)
解决方案:
- 早停(Early Stopping):基于验证集性能停止训练
- 数据增强:增加训练数据的多样性
- 正则化:Dropout、权重衰减等
- 减少模型容量:在微调时减少层数或隐藏维度
问题12:如何设计有效的SFT评估体系?
答案:
多维度评估框架:
class SFTEvaluator:
def __init__(self, model, tokenizer, eval_datasets):
self.model = model
self.tokenizer = tokenizer
self.eval_datasets = eval_datasets
def run_automatic_evaluation(self):
"""自动评估"""
metrics = {}
# 困惑度评估
metrics['perplexity'] = self.calculate_perplexity()
# 任务特定指标
metrics['task_specific'] = self.evaluate_task_metrics()
return metrics
def run_human_evaluation(self, samples=100):
"""人工评估"""
human_scores = {
'fluency': 0, # 流畅度
'relevance': 0, # 相关性
'accuracy': 0, # 准确性
'completeness': 0 # 完整性
}
# 人工评分逻辑
return human_scores
def evaluate_safety_alignment(self):
"""安全性评估"""
safety_metrics = self.test_safety_questions()
return safety_metrics
五、进阶技术篇:SFT的前沿进展
问题13:指令微调(Instruction Tuning)与SFT的关系?
答案:
关系解析:
- 指令微调是SFT的一种特殊形式,专注于让模型理解和遵循自然语言指令
- 使用多样化的指令-响应对进行训练
- 目标是提升模型的零样本和少样本泛化能力
技术特点:
# 指令微调数据示例
instruction_tuning_data = [
{
"instruction": "将以下英文翻译成中文",
"input": "Hello, how are you?",
"output": "你好,最近怎么样?"
},
{
"instruction": "总结以下文章的主要内容",
"input": "长篇文章内容...",
"output": "文章主要讲述了..."
}
]
问题14:多任务SFT与单任务SFT的优劣比较
答案:
多任务SFT优势:
- 提升模型泛化能力
- 减少任务间负迁移
- 一次训练,多任务部署
单任务SFT优势:
- 在特定任务上可能达到更高性能
- 训练过程更简单稳定
- 调试和优化更直接
选择策略:
def select_sft_approach(task_requirements):
"""选择SFT方法的决策逻辑"""
if task_requirements['generalization'] > 0.7:
return "multi_task"
elif task_requirements['performance'] > 0.8:
return "single_task"
elif task_requirements['data_availability'] < 0.3:
return "multi_task" # 数据少时多任务有助于泛化
else:
return "single_task"
问题15:SFT如何与RLHF配合工作?
答案:
协同工作流程:
预训练模型
↓
SFT(获得基础能力)
↓
奖励模型训练
↓
RLHF(基于人类反馈优化)
↓
最终模型
SFT在RLHF中的角色:
- 为RLHF提供良好的初始化
- 确保模型具备基本的指令跟随能力
- 减少RLHF训练的不稳定性
六、实战问题篇:SFT的工程挑战
问题16:如何处理SFT中的类别不平衡问题?
答案:
解决方案:
class ImbalanceHandler:
def __init__(self, dataset):
self.dataset = dataset
self.class_distribution = self.calculate_distribution()
def apply_resampling(self):
"""重采样策略"""
if self.is_imbalanced():
# 过采样少数类或欠采样多数类
balanced_dataset = self.resample_dataset()
return balanced_dataset
return self.dataset
def apply_loss_weighting(self):
"""损失加权"""
class_weights = self.calculate_class_weights()
def weighted_loss(logits, targets):
base_loss = cross_entropy(logits, targets)
weights = class_weights[targets]
return (base_loss * weights).mean()
return weighted_loss
def apply_focal_loss(self, gamma=2.0):
"""Focal Loss处理类别不平衡"""
def focal_loss(logits, targets):
ce_loss = cross_entropy(logits, targets, reduction='none')
pt = torch.exp(-ce_loss)
focal_loss = ((1 - pt) ** gamma * ce_loss).mean()
return focal_loss
return focal_loss
问题17:SFT模型部署的注意事项
答案:
部署准备:
class SFTDeploymentPreparer:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def optimize_for_inference(self):
"""推理优化"""
# 模型量化
quantized_model = self.quantize_model()
# 图优化
optimized_model = self.apply_graph_optimizations()
# 序列化保存
self.save_for_serving(optimized_model)
return optimized_model
def create_serving_template(self):
"""创建服务模板"""
template = {
"model": self.model,
"tokenizer": self.tokenizer,
"max_length": 512,
"temperature": 0.7,
"top_p": 0.9,
"stop_tokens": ["\n", "###"]
}
return template
def setup_monitoring(self):
"""设置监控"""
monitoring_config = {
"performance_metrics": ["latency", "throughput", "error_rate"],
"quality_metrics": ["perplexity", "response_quality"],
"safety_metrics": ["toxicity", "bias_detection"]
}
return monitoring_config
问题18:如何调试SFT训练过程中的问题?
答案:
系统化调试方法:
class SFTDebugger:
def __init__(self, model, dataloader, optimizer):
self.model = model
self.dataloader = dataloader
self.optimizer = optimizer
def diagnose_training_issues(self):
"""诊断训练问题"""
issues = []
# 检查梯度流动
if self.check_gradient_flow():
issues.append("梯度消失/爆炸")
# 检查数据流水线
if self.check_data_pipeline():
issues.append("数据预处理问题")
# 检查优化器状态
if self.check_optimizer_state():
issues.append("优化器配置问题")
return issues
def check_gradient_flow(self):
"""检查梯度流动"""
for name, param in self.model.named_parameters():
if param.grad is not None:
grad_norm = param.grad.norm().item()
if grad_norm < 1e-7 or grad_norm > 1e5:
return True
return False
七、未来趋势篇:SFT的发展方向
问题19:SFT技术的最新进展有哪些?
答案:
前沿技术方向:
-
参数高效微调的创新:
- LoRA的变体:DoRA、LoRA+
- 更高效的适配器设计
-
多模态SFT:
- 文本-图像联合微调
- 跨模态指令微调
-
持续学习SFT:
- 避免灾难性遗忘的新方法
- 增量学习技术
-
自动化SFT:
- 自动数据选择
- 超参数自动优化
问题20:SFT在大模型生态系统中的未来定位?
答案:
未来角色:
- 基础能力定制:仍是定制化模型的主要手段
- 快速适配:结合提示学习实现快速任务切换
- 安全对齐:在模型安全性和价值观对齐中发挥关键作用
- 个性化AI:支持用户个性化的模型微调
技术融合趋势:
SFT + 提示学习 → 快速适应
SFT + 强化学习 → 精细优化
SFT + 知识蒸馏 → 模型压缩
SFT + 持续学习 → 终身学习
结语
监督微调(SFT)作为连接预训练大模型与实际应用的关键桥梁,其重要性在AI工程实践中日益凸显。在技术面试中,除了掌握基础概念,更要展现:
- 系统性思维:从数据准备到模型部署的完整视角
- 深度理解:对过拟合、灾难性遗忘等核心问题的深刻认识
- 工程实践:实际项目中遇到的问题和解决方案
- 技术前瞻:对SFT技术发展趋势的洞察
记住:优秀的AI工程师不仅要知道如何调参,更要理解为什么这样调参,以及如何系统化地解决实际问题。
本文基于当前SFT技术的最佳实践和前沿研究整理,随着技术快速发展,建议持续关注最新研究成果和业界实践。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)