openGauss 7.0 数据库实战指南:从部署到应用,教你轻松上手无压力
openGauss 是一款全面友好开放的企业级开源关系型数据库,由华为深度参与并联合全球伙伴共同打造。凭借高性能、高可用、高安全、易运维的核心特性,它正受到越来越多开发者与企业的青睐。无论是还是开发AI驱动的新型应用,还是大数据分析、物联网数据这些场openGauss景都是一个不错的选择。
前言
openGauss 是一款全面友好开放的企业级开源关系型数据库,由华为深度参与并联合全球伙伴共同打造。凭借高性能、高可用、高安全、易运维的核心特性,它正受到越来越多开发者与企业的青睐。无论是还是开发AI驱动的新型应用,还是大数据分析、物联网数据这些场openGauss景都是一个不错的选择。
而对于初次接触 openGauss 的用户而言,部署便捷性与学习成本,往往是影响其数据库选型的关键因素之一。下面,我们就给大家带来 openGauss 7.0 数据库实战指南,助力大家从部署到应用全流程轻松上手,快速掌握这款由华为深度参与并联合全球伙伴共同打造开源数据库。
文章目录
一、openGauss 7.0 核心特性速览
1.1 ByPass 机制:按需简化,效率跃升
openGauss 作为企业级开源数据库,创新性地推出Bypass 机制,通过精准识别可优化场景、选择性简化非核心流程,在确保数据一致性的前提下实现了关键操作的效率跃升。Bypass 机制的核心思想是 “按需简化”—— 针对数据库中资源消耗大、流程冗余度高的特定操作,在不破坏 ACID 核心特性的前提下,跳过非必要的校验、日志或交互环节,为高频场景开辟优化路径。
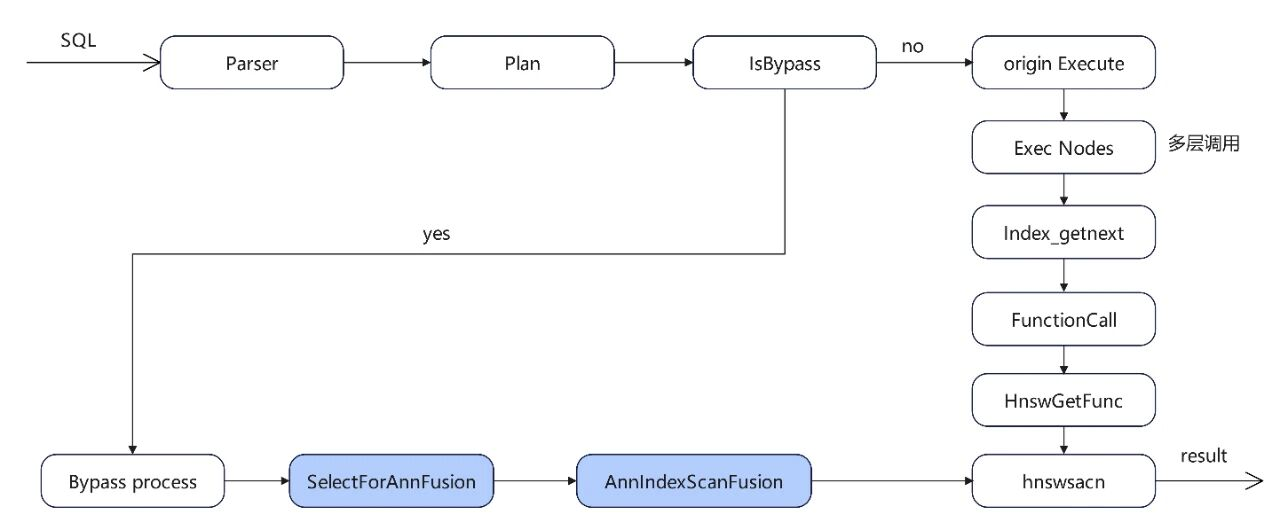
openGauss7.0.0-RC2版本在向量检索增加Bypass机制并非简单 “走捷径”,而是基于向量检索的特性设计的精准优化方案:通过识别可省略的非核心步骤,为高频查询开辟专属通道,同时严格保障向量计算的准确性与结果完整性。其核心价值不仅在于性能提升,更在于为向量数据库的工程化落地提供了灵活的效率调节手段 —— 既满足核心场景的极致性能需求,又通过安全机制守住准确性底线。
1.2 MMAP:突破向量数据库性能检索边界
openGauss7.0.0-RC2 版本针对向量数据库HNSW索引检索,引入MMAP技术,通过深度整合操作系统级内存管理机制,为向量索引检索的读密集场景带来颠覆性性能突破,重新定义高性能向量数据库的技术标准。MMAP打破传统I/O流程,将向量索引文件直接挂载到进程虚拟空间,实现“内存般的直接访问”。
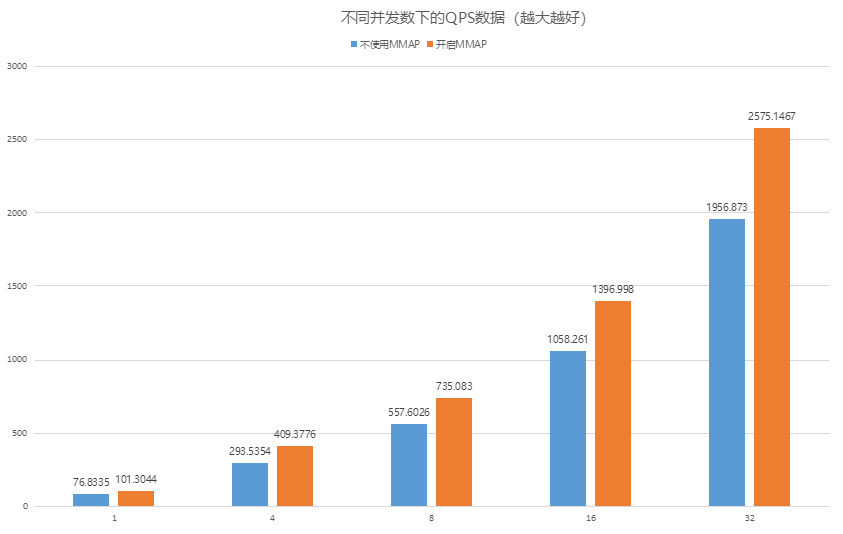
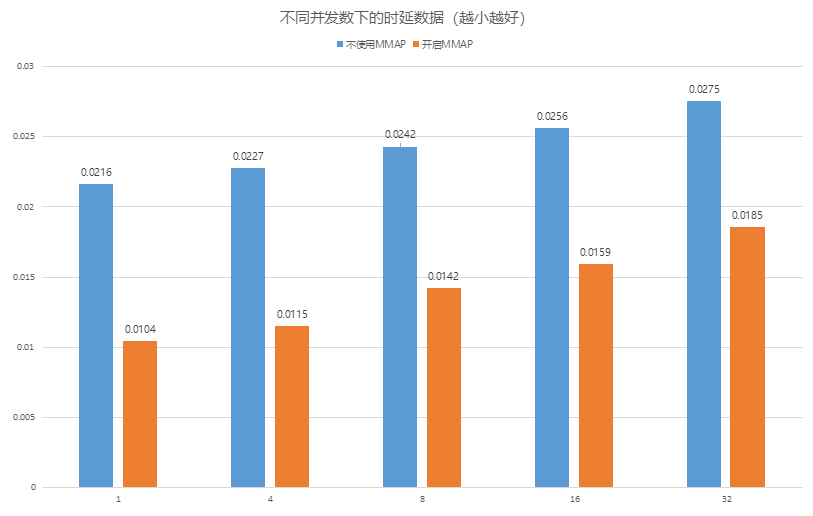
在亿级向量数据的近似查询中,借助MMAP对索引文件的直接映射,避免了传统 I/O 的多次拷贝,单并发查询QPS从80提升至110,提升了30%+。结合 openGauss数据库独有的 Bypass 算子复用技术,执行链路进一步精简,复杂检索场景下性能较行业平均水平提升30%+。
1.3 内核能力增强
openGauss 在 7.0 版本的内核能力上实现多维度增强:
- 行存压缩功能增强:对行存表(包括Ustore和Astore)的数据和索引页面,openGauss提供基于通用压缩算法的透明页压缩功能,降低磁盘空间占用的同时保持OLTP场景下的高性能;支持页式存储和段页式存储两种模式。
- SQL功能增强:支持CROSS/OUTER APPLY JOIN语法,用于返回左侧表达式的每一行和右侧表达式的匹配行。CUME_DIST、DENSE_RANK、PERCENT_RANK、RANK函数支持任意类型的任意多个入参,在函数内的入参数据类型和ORDER BY的数据类型不一致时也支持执行。支持JSON_EXISTS、 JSON_TEXTCONTAINS表达式。支持修改/删除视图引用的对象(如表、列、函数、视图等)后,将视图置为无效状态。
- 存储过程功能增强:支持自定义subtype语法;支持EXCEPTION FOR自定义异常;支持在函数或者过程中创建过程。
- 其他增强:支持多个会话并发插入interval分区时,如果多个会话都涉及分区自动扩展动作,不会发生卡死问题。新增用于词法语法分析的openGauss SQL审计工具libog_query,支持离线审计分析SQL语句在openGauss中的语法合法性。CM/OM/DATAKIT工具中用到的SSH SCP等相关通信工具支持用户自定义端口,避免部分环境无法使用默认22端口的问题。OM工具支持记录升级历史记录。
二、部署前环境准备
2.1 硬件环境要求
以下就是我们的openGauss 7.0对于硬件环境的要求了,本次给大家测试的是个人电脑所以我们可以看到个人开发者最低配置2核4G,推荐配置4核8G。目前,openGauss仅支持ARM服务器和基于X86_64通用PC服务器的CPU。这个大家一定要注意奥,不然运行时会显示CPU 架构与宿主机架构不匹配的错误。
| 项目 | 配置描述 |
|---|---|
| 内存 | 功能调试建议32GB以上。 性能测试和商业部署时,单实例部署建议128GB以上。 复杂的查询对内存的需求量比较高,在高并发场景下,可能出现内存不足。此时建议使用大内存的机器,或使用负载管理限制系统的并发。 |
| CPU | 功能调试最小1×8核 2.0GHz。 性能测试和商业部署时,建议1×16核 2.0GHz。 CPU超线程和非超线程两种模式都支持。 说明: 个人开发者最低配置2核4G,推荐配置4核8G。目前,openGauss仅支持ARM服务器和基于X86_64通用PC服务器的CPU。 |
| 硬盘 | 用于安装openGauss的硬盘需最少满足如下要求: - 至少1GB用于安装openGauss的应用程序。 - 每个主机需大约300MB用于元数据存储。 - 预留70%以上的磁盘剩余空间用于数据存储。 建议系统盘配置为Raid1,数据盘配置为Raid5,且规划4组Raid5数据盘用于安装openGauss。有关Raid的配置方法在本手册中不做介绍。请参考硬件厂家的手册或互联网上的方法进行配置,其中Disk Cache Policy一项需要设置为Disabled,否则机器异常掉电后有数据丢失的风险。 openGauss支持使用SSD盘作为数据库的主存储设备,支持SAS接口和NVME协议的SSD盘,以RAID的方式部署使用。 |
| 网络要求 | 300兆以上以太网。 建议网卡设置为双网卡冗余bond。有关网卡冗余bond的配置方法在本手册中不做介绍。请参考硬件厂商的手册或互联网上的方法进行配置。 |
2.2 系统环境要求
在系统选择上 openGauss支持openEuler系统和CentOs等系统,本次我们部署实战我们就选择使用(CentOS7.6操作系统)来给大家部署测试。
表格 还在加载中,请等待加载完成后再尝试复制
2.3 软件依赖要求
表格 还在加载中,请等待加载完成后再尝试复制
对于以上所需的软件我们可以使用以下命令一键下载
yum install libaio-devel readline-devel libedit-devel libxml2-devel lz4-devel numactl-devel unixODBC-devel java-1.8.0-openjdk-devel
三、部署 openGauss数据库(CentOS7.6操作系统)
3.1 安装部署docker环境
- 首先安装 yum-utils(提供 yum-config-manager 工具),用于管理 YUM 仓库:
sudo yum install -y yum-utils
- 添加国内Docker镜像仓库(这里我们使用的是阿里云),让下载速度更快:
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo

- 下载安装docker
yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
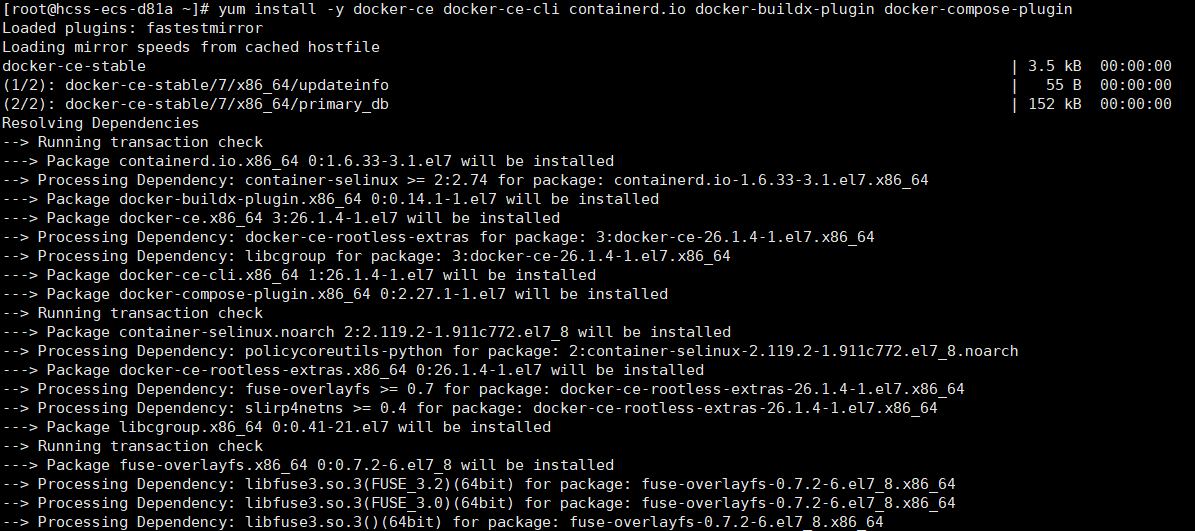
- 验证Docker是否安装成功(出现以下提示咱们docker就算安装成功了)
docker --version

国内网络拉取 Docker Hub 镜像可能较慢,所以我们这里配置下阿里云加速器
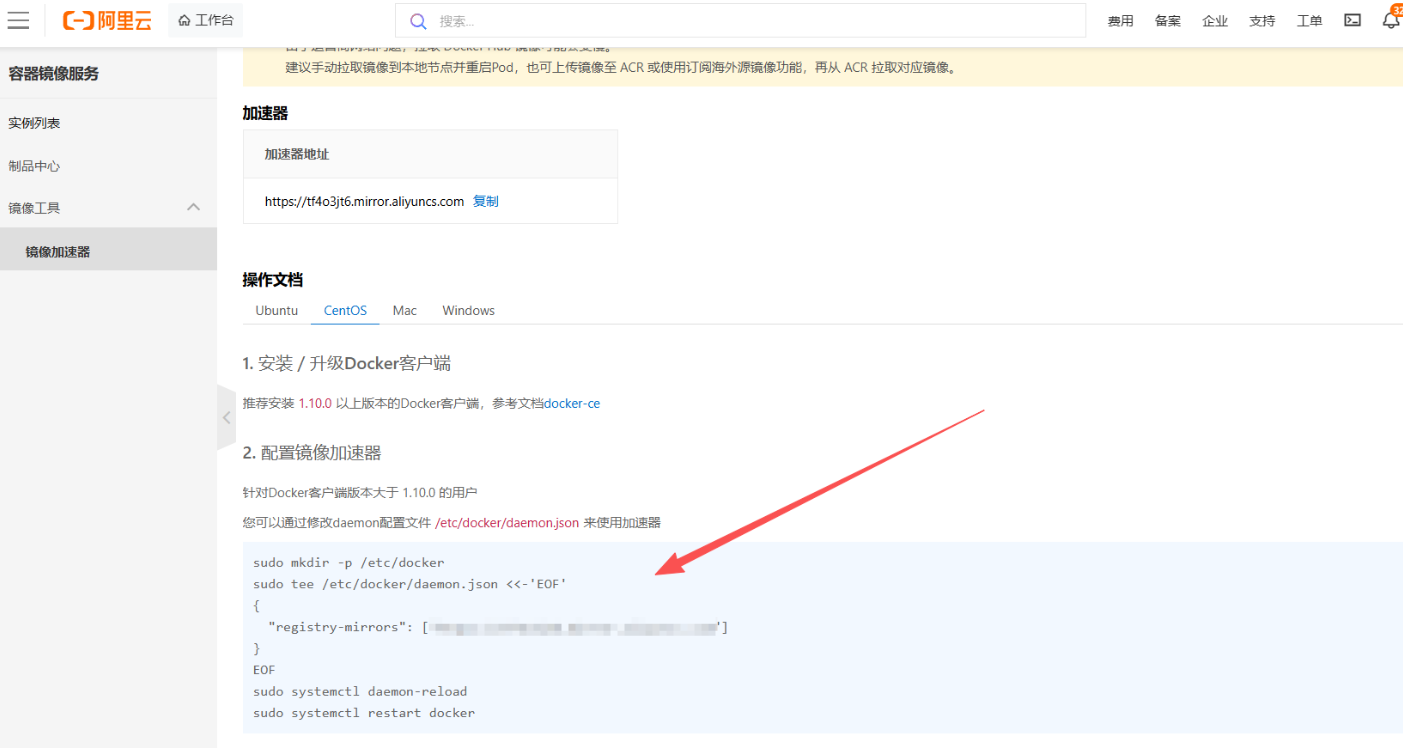
# 创建Docker配置目录
mkdir -p /etc/docker
# 编辑配置文件(替换为你的阿里云加速器地址)
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xxxxxx.mirror.aliyuncs.com"]
}
EOF
# 重启Docker使配置生效
systemctl daemon-reload
systemctl restart docker
3.1 部署 openGauss数据库
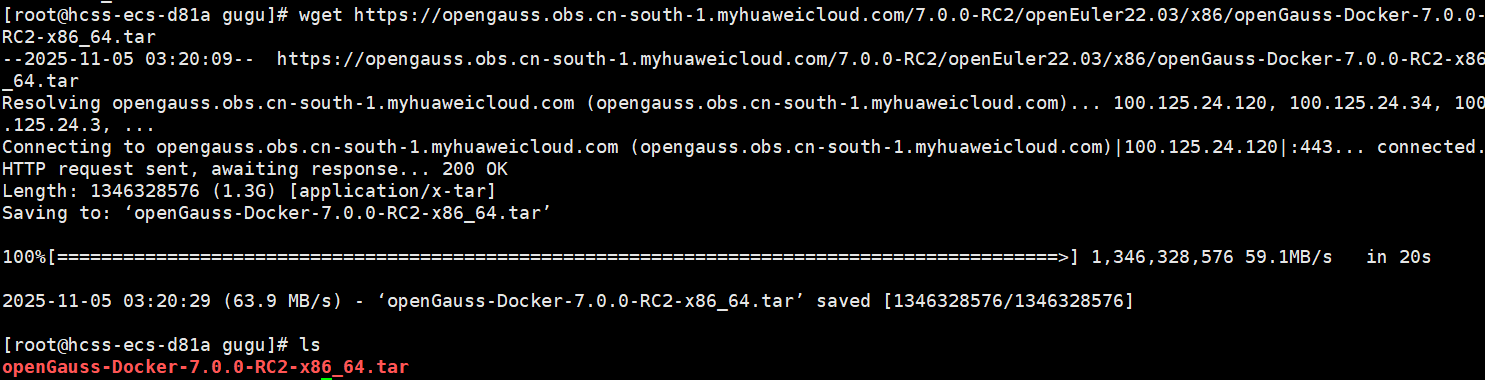
由于国内镜像源访问原因,直接拉取下载的话特别容易出现拉取失败等提示,所以我们选择通过 wget 命令下载 openGauss 的 Docker 镜像包,并加载到docker启动。

- 下载镜像包(我们本次用的是Centos 7.6版本的所以在下载的时候要注意一点要选择CentOS7-x86_64架构下的安装包 )
wget https://openGauss.obs.cn-south-1.myhuaweicloud.com/7.0.0-RC2/openEuler22.03/x86/openGauss-Docker-7.0.0-RC2-x86_64.tar
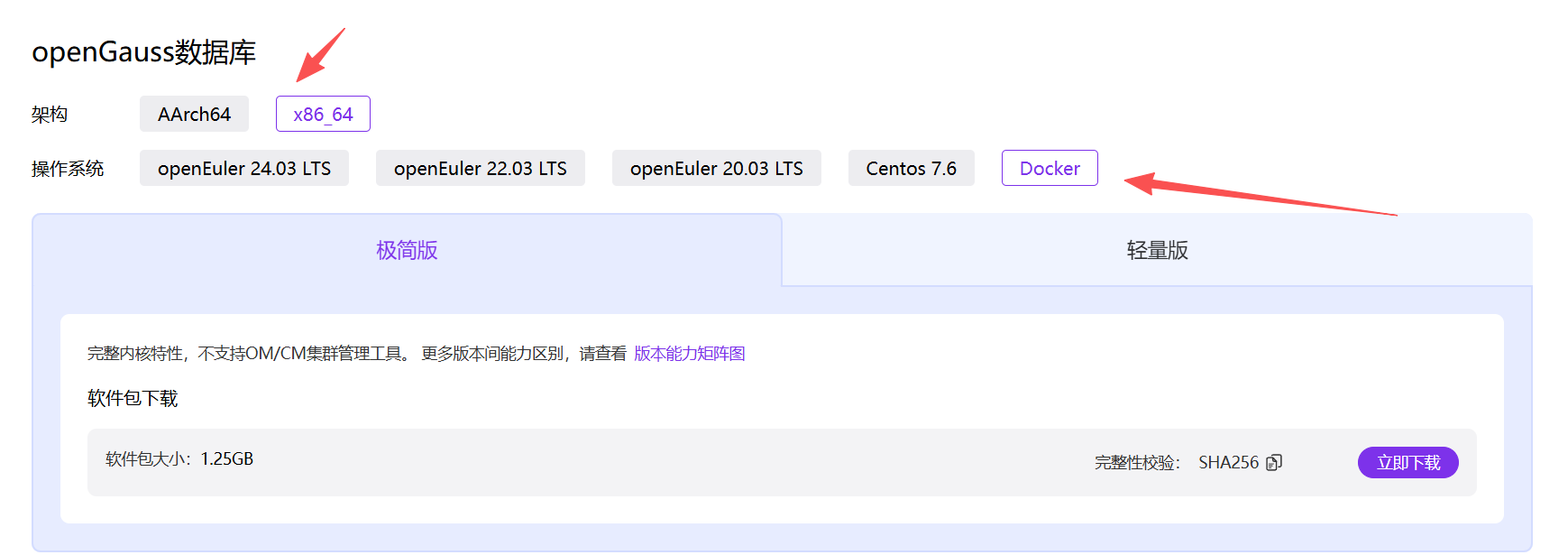
对于不同架构和系统的安装包在这里: https://openGauss.org/zh/download/archive/?version=7.0.0-RC2
大家一定要注意选择对奥
- 加载镜像
docker load -i openGauss-Docker-6.0.2-x86_64.tar
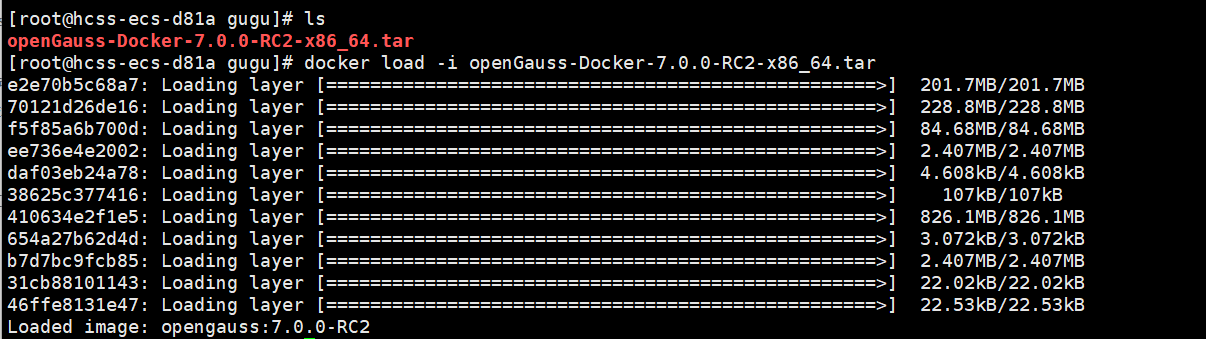
- 验证镜像状态
docker images

- 启动容器,从上面可以看到我们的仓库名是 openGauss,标签是 7.0.0-RC2。然后直接用本地镜像启动就OK了
[root@hcss-ecs-d81a gugu]# docker run --name openGauss --privileged=true -d -e GS_PASSWORD=Gugu@123 -p 5432:5432 openGauss:7.0.0-RC2

- 参看容器状态
docker ps | grep openGauss

3.2 使用gsql 连接数据库
openGauss数据库 部署完成之后就可以进入容器内部,来使用gsql 连接数据库了。gsql是openGauss提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护, 除了支持交互式地键入并执行SQL语句,也可以执行一个文件中指定的SQL语句,还提供了若干高级特性,便于用户使用。
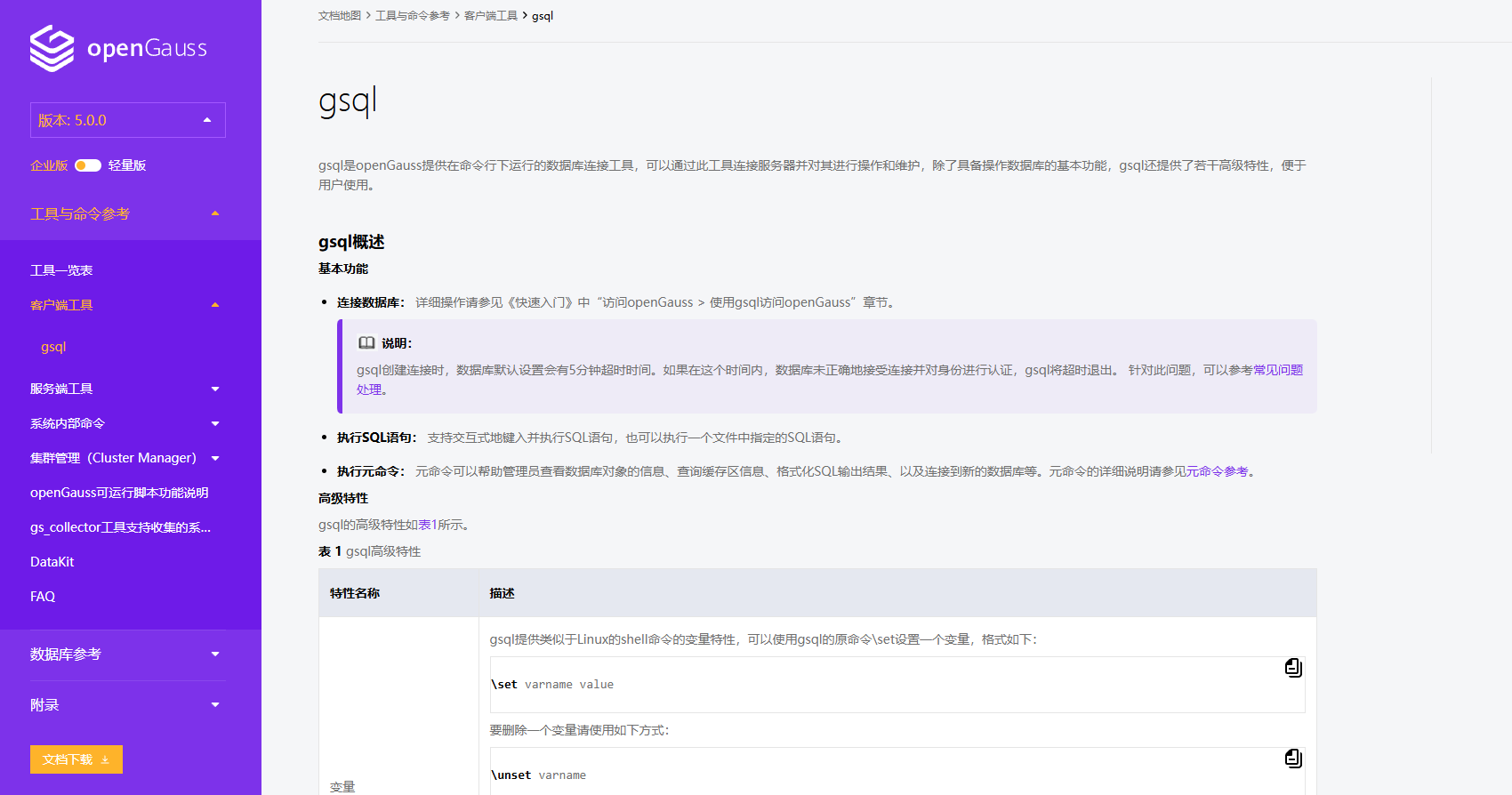
- 在容器内部进行连接数据库,进入 openGauss 容器的 bash 终端
docker exec -it openGauss bash
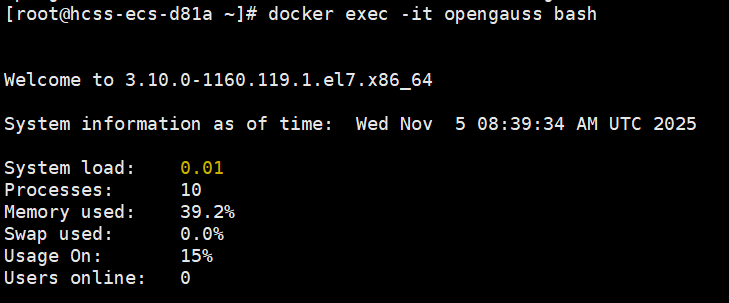
- 在容器内连接数据库(默认用户omm,数据库postgres,端口5432)
su omm
gsql -d postgres -p 5432
- 然后通过
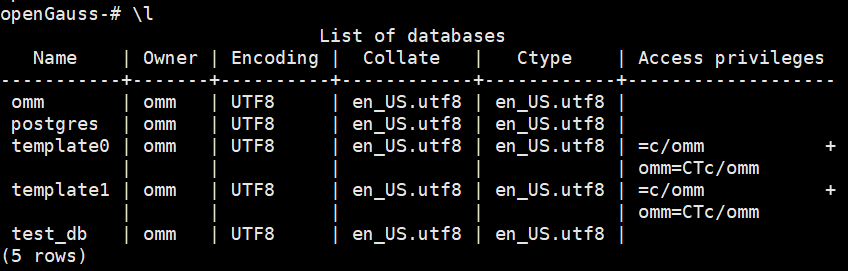
\l就可以命令查询到的数据库列表了
四、数据库基本操作测试
4.1 数据库操作
以上openGauss数据库就部署完成了,下面赶紧试试基本的数据库操作体验体验吧!我们先创建一个测试数据库来进行体验测试一下。
-- 1. 创建新数据库
CREATE DATABASE test_db WITH ENCODING 'UTF8' LC_COLLATE 'en_US.utf8' LC_CTYPE 'en_US.utf8';
-- 2. 切换到目标数据库
\c test_db
4.2 表与字段操作
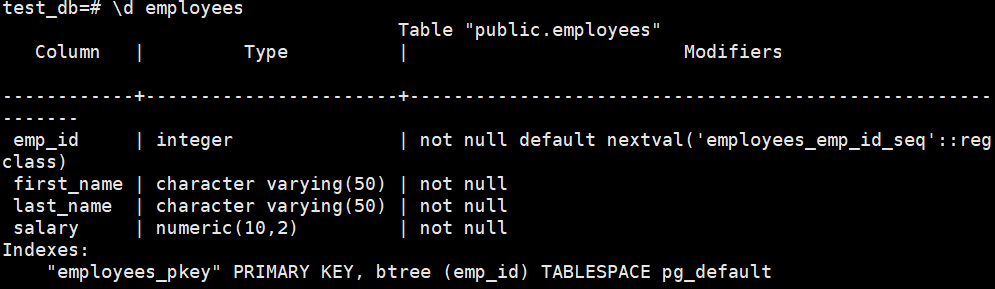
- 创建测试表,然后查看表结构
-- 1. 创建测试表
CREATE TABLE employees (
emp_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
gender CHAR(1) CHECK (gender IN ('M', 'F', 'O')),
salary NUMERIC(10, 2) NOT NULL,
hire_date DATE DEFAULT CURRENT_DATE);
-- 2. 查看表结构
\d employees
2.为employees表添加 <font style="background-color:rgb(187,191,196);">gender</font> 字段

ALTER TABLE employees
ADD COLUMN gender CHAR(1) CHECK (gender IN ('M', 'F', 'O'));
4.3 数据库插入数据测试
这里我们简单对数据做一下插入数据的测试,由于咱们openGauss 是支持PL/pgSQL 的,所以这里就简单多了直接 PL/pgSQL 循环来高效生成随机数据。
DO $$
DECLARE
i INT := 1;
first_names TEXT[] := ARRAY['张', '李', '王', '赵', '刘', '陈', '杨', '黄', '周', '吴', '徐', '孙', '胡', '朱', '高', '林', '何', '郭', '马', '罗'];
last_names TEXT[] := ARRAY['伟', '芳', '娜', '秀英', '敏', '静', '强', '磊', '军', '洋', '勇', '艳', '杰', '涛', '明', '华', '玉', '秀', '文', '强'];
genders CHAR[] := ARRAY['M', 'F', 'O'];
BEGIN
WHILE i <= 10000 LOOP
INSERT INTO employees (first_name, last_name, gender, salary)
VALUES (
first_names[floor(random() * array_length(first_names, 1)) + 1],
last_names[floor(random() * array_length(last_names, 1)) + 1],
genders[floor(random() * array_length(genders, 1)) + 1],
5000 + (random() * 45000)::NUMERIC(10, 2)
);
i := i + 1;
END LOOP;
END $$;
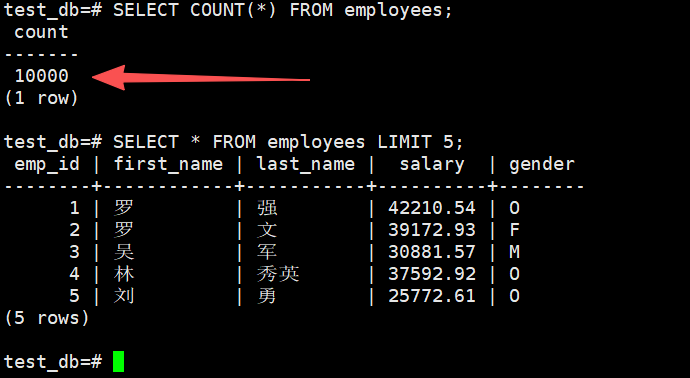
- 这里我们实际体验下来1万条数据几乎是一瞬间就完成非常快,这插入完成后我们还可以验证一下执行是否成功
-- 统计总条数
SELECT COUNT(*) FROM employees;
-- 查看前 5 条数据样例
SELECT * FROM employees LIMIT 5;
4.4 使用视图:简化复杂查询
在数据库查询中,视图(View)可以将常用的复杂查询逻辑封装起来,简化重复操作,这里我们假设经常需要查询 “薪资高于 30000 的男性员工全名及薪资”,来使用用视图简化 “复杂查询”。
-- 创建视图:筛选高薪男性员工的全名和薪资
CREATE VIEW vw_high_salary_male ASSELECT
emp_id,
first_name || ' ' || last_name AS full_name, -- 拼接全名(名+姓)
gender,
salary
FROM employees
WHERE
gender = 'M'
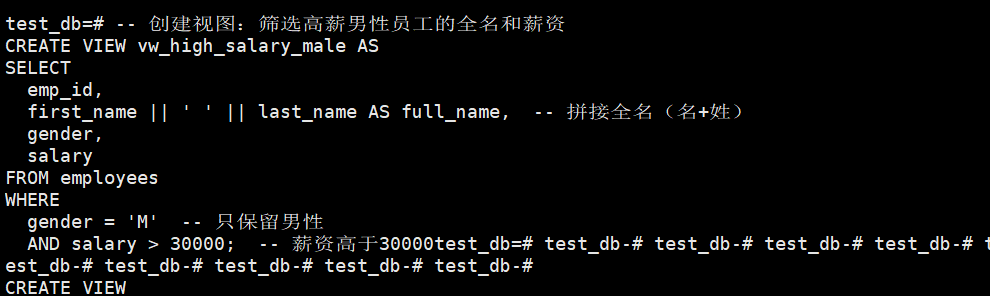
- 创建视图后,我们想查询“薪资高于 30000 的男性员工全名及薪资” 时无需重复写
WHERE条件和字段拼接,直接查询视图即可
SELECT * FROM vw_high_salary_male;
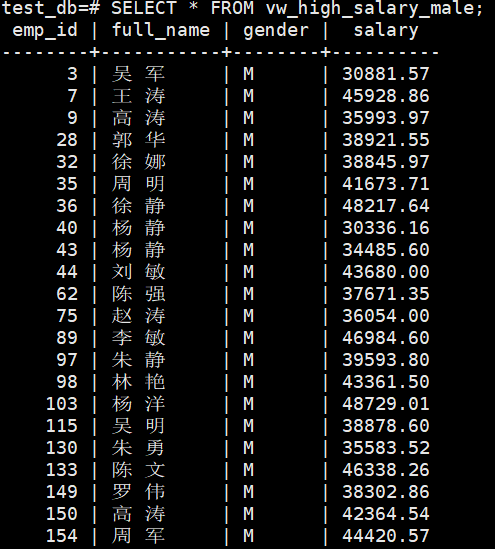
五、openGauss应用场景
截至目前,openGauss 开源数据库凭借 高可用性、高性能、高安全性、易运维 四大核心优势,已成功在金融、电信、政务、互联网等多个行业实现规模化落地。同时,它深度融合分布式架构、人工智能优化等前沿技术,进一步强化了在复杂场景下的适配能力与核心竞争力。
5.1 行业案例一:金融行业
兴业银行股份有限公司系统客户基数超过5000万, 使用openGauss 成功支持了 80 套重要业务系统的跨机房部署。成功支持行内百余套业务系统在业务跨机房高可用保障、数据安全防护以及运维管理优化等关键层面,彰显出极为强劲的实力。其部署范围已覆盖行内管理系统、交易系统以及分析类系统等多个重要领域。

5.2 行业案例二:互联网行业
钉钉(中国)有限公司在面对当前互联网企业的AI 化转型中,对 “事务数据存储 + AI 模型训推 + 向量检索” 的一体化融合需求 需求时,采用 openGauss 数据库与 DataVec 向量数据库的一体化解决方案:通过同一数据库既能满足 TP(事务处理)场景的数据存取场景,又可支持模型训练与推理场景,大幅简化了应用的部署与运维流程;该方案在鲲鹏算力底座上实现原生适配,借助通过 NUMA 绑核、casal 原子指令等技术显著显著显著提升数据库性能;同时,DataVec 向量数据库借助 NEON 和 SVE 指令对热点函数进行 SIMD 加速,实现向量数据的并行处理,充分释放鲲鹏多核算力优势,整体性能提升 20%。

5.3 行业案例三:制造行业
比亚迪作为中国高端制造的代表,在数字化智能制造的浪潮之中,一直走在行业前列。其采用openGauss发行版海量数据Vastbase作为MES(制造执行系统)底层数据管理平台。凭借openGauss强大的高并发性能和大数据吞吐能力满足MES对于数据并行大批量写入和实时查询的诉求。同时openGauss从单点、主备、异地灾备等高可用性保证比亚迪MES连续服务。集群故障自动恢复实现RTO<10s,保障数据资产安全性。

总结
openGauss 7.0 依托 Bypass 机制、MMAP 技术等核心特性,实现了性能与功能的双重突破;同时通过 Docker 轻量化部署方案大幅降低入门门槛,从数据库创建、数据操作到视图封装的全流程实操,充分彰显其易用性与高性能优势。如今,它已在金融、运营商、互联网、制造、能源、DBV、ISV、教育、大企业、医疗等多个领域实现规模化落地,进一步验证了其在企业级场景的稳定可靠性。无论是开发者还是企业用户,都可从部署环境入手,快速体验 openGauss 的技术价值,共同助力openGauss数据库生态的蓬勃发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 90
90 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)