AI 编程:自动化代码生成、低代码 / 无代码开发与算法优化实践
本文系统探讨AI编程技术在软件开发中的应用,重点分析了自动化代码生成、低代码平台和算法优化三大领域。在代码生成方面,基于LLM的技术能根据自然语言描述生成功能完善的代码(如FastAPI用户管理系统),显著提升开发效率。低代码平台通过可视化界面和AI增强功能(如智能组件推荐),使非专业开发者也能快速构建应用。算法优化环节展示了AI如何自动改进排序算法,降低时间复杂度并提升性能。
目录
- 自动化代码生成技术与实践
- 低代码 / 无代码开发平台应用
- AI 驱动的算法优化实践
- 综合案例与未来趋势
1. 自动化代码生成技术与实践
自动化代码生成是 AI 编程领域的核心应用,通过自然语言描述、需求分析或示例代码,自动生成可执行程序。这一技术显著提升了开发效率,降低了人为错误。
1.1 技术原理与主流工具
自动化代码生成基于大语言模型 (LLM),通过预训练海量代码库学习编程语言语法、逻辑结构和最佳实践。主流工具包括 GitHub Copilot、Amazon CodeWhisperer、Google Codey 等。
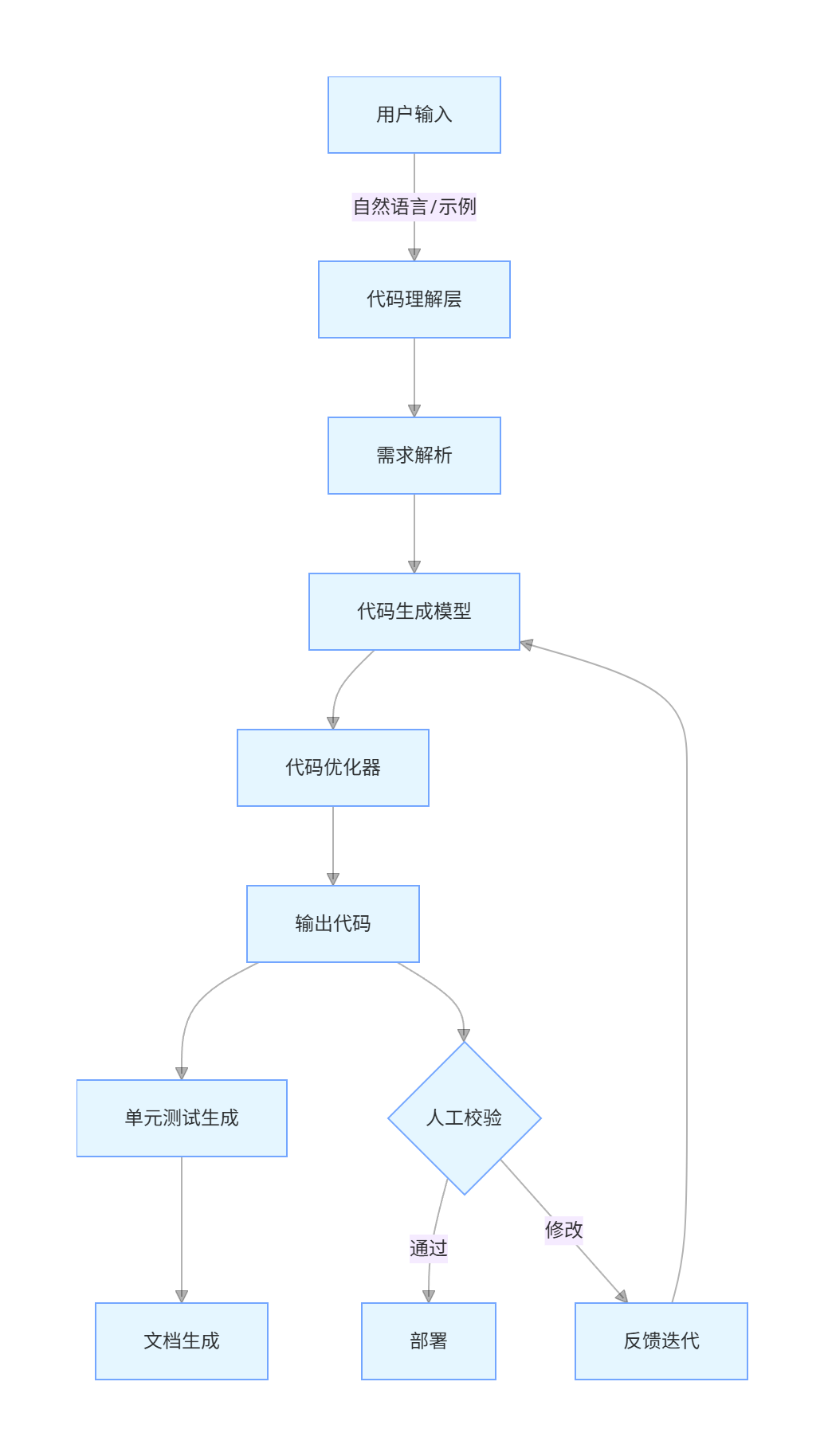
技术架构流程图:
graph TD
A[用户输入] -->|自然语言/示例| B[代码理解层]
B --> C[需求解析]
C --> D[代码生成模型]
D --> E[代码优化器]
E --> F[输出代码]
F --> G[单元测试生成]
G --> H[文档生成]
F --> I{人工校验}
I -->|通过| J[部署]
I -->|修改| K[反馈迭代]
K --> D
1.2 实践案例:API 接口生成
Prompt 示例:
plaintext
请生成一个基于Python FastAPI的用户管理API,包含以下功能:
1. 用户注册(用户名、邮箱、密码)
2. 用户登录(返回JWT令牌)
3. 获取用户信息(需要认证)
4. 更新用户信息(需要认证)
要求:
- 使用Pydantic进行数据验证
- 密码需要加密存储
- 实现基本的错误处理
- 包含必要的注释
生成的代码:
python
运行
from fastapi import FastAPI, Depends, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel, EmailStr
from datetime import datetime, timedelta
from jose import JWTError, jwt
from passlib.context import CryptContext
from typing import Optional, Dict, List
# 配置
SECRET_KEY = "your-secret-key-keep-it-safe-and-long-enough-for-production"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
app = FastAPI(title="User Management API")
# 密码加密上下文
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
# OAuth2配置
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
# 数据模型
class UserBase(BaseModel):
username: str
email: EmailStr
class UserCreate(UserBase):
password: str
class UserUpdate(BaseModel):
email: Optional[EmailStr] = None
password: Optional[str] = None
class User(UserBase):
id: int
is_active: bool = True
class Config:
orm_mode = True
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Optional[str] = None
# 模拟数据库
fake_db: Dict[int, Dict] = {}
current_id = 1
# 工具函数
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
for user in db.values():
if user["username"] == username:
return User(**user)
return None
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, fake_db[user.id]["hashed_password"]):
return False
return user
def create_access_token(data: dict, expires_delta: Optional[timedelta] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
# API端点
@app.post("/register", response_model=User, status_code=status.HTTP_201_CREATED)
def register(user: UserCreate):
"""注册新用户"""
# 检查用户名是否已存在
if get_user(fake_db, user.username):
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="Username already registered"
)
global current_id
hashed_password = get_password_hash(user.password)
fake_db[current_id] = {
"id": current_id,
"username": user.username,
"email": user.email,
"hashed_password": hashed_password,
"is_active": True
}
user_data = fake_db[current_id]
current_id += 1
return user_data
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
"""用户登录并获取访问令牌"""
user = authenticate_user(fake_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_user)):
"""获取当前登录用户信息"""
return current_user
@app.put("/users/me", response_model=User)
async def update_user_me(
user_update: UserUpdate,
current_user: User = Depends(get_current_user)
):
"""更新当前登录用户信息"""
user_data = fake_db[current_user.id]
if user_update.email:
user_data["email"] = user_update.email
if user_update.password:
user_data["hashed_password"] = get_password_hash(user_update.password)
fake_db[current_user.id] = user_data
return user_data
1.3 代码生成质量评估
代码生成的质量可以从以下维度评估:
| 评估维度 | 描述 | 权重 |
|---|---|---|
| 功能性 | 代码是否实现了所有需求功能 | 30% |
| 正确性 | 代码是否可运行且无逻辑错误 | 25% |
| 安全性 | 代码是否存在安全漏洞 | 20% |
| 可读性 | 代码结构是否清晰,注释是否充分 | 15% |
| 可维护性 | 代码是否易于修改和扩展 | 10% |
质量优化策略:
- 提供更详细的 Prompt,包含具体要求和约束条件
- 采用多轮对话方式,逐步完善代码
- 结合单元测试验证生成代码
- 建立代码生成反馈机制
2. 低代码 / 无代码开发平台应用
低代码 / 无代码 (LCNC) 开发平台允许开发者通过图形化界面和配置而非传统编码来构建应用程序,AI 技术进一步增强了这些平台的能力。
2.1 平台架构与工作流程
现代 LCNC 平台通常包含可视化编辑器、预制组件库、集成引擎和部署管道。AI 增强功能包括智能组件推荐、自动化流程生成和错误检测。
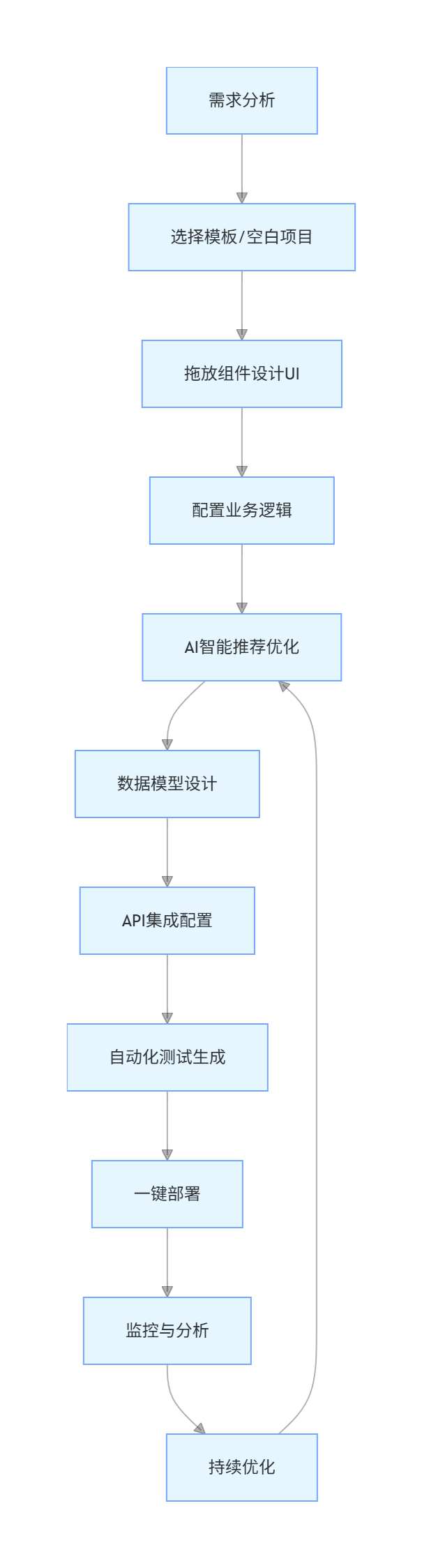
工作流程图:
graph TD
A[需求分析] --> B[选择模板/空白项目]
B --> C[拖放组件设计UI]
C --> D[配置业务逻辑]
D --> E[AI智能推荐优化]
E --> F[数据模型设计]
F --> G[API集成配置]
G --> H[自动化测试生成]
H --> I[一键部署]
I --> J[监控与分析]
J --> K[持续优化]
K --> E
2.2 实践案例:客户管理系统
使用 AI 增强的低代码平台构建客户管理系统的步骤:
- 选择模板:选择 CRM 模板作为基础
- 定制数据模型:
- 客户基本信息(姓名、公司、联系方式)
- 交互历史记录
- 销售机会管理
- 设计界面:
- 客户列表页(带筛选和搜索)
- 客户详情页
- 交互记录添加表单
- 配置业务逻辑:
- 客户分类自动化规则
- 跟进提醒设置
- 数据统计与报表生成
AI 辅助功能:
- 智能表单设计:根据数据模型自动推荐表单布局
- 自动化流程:根据业务场景推荐工作流,如 "新客户创建后自动分配销售代表"
- 异常检测:识别数据录入错误和潜在重复客户
平台对比表:
| 平台 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| Microsoft Power Apps | 与 Office 生态深度集成,AI 功能强大 | 高级功能需订阅,复杂逻辑有限制 | 企业内部工具,Office 集成应用 |
| Mendix | 支持复杂业务逻辑,团队协作功能强 | 学习曲线较陡,价格较高 | 中大型企业应用,复杂业务系统 |
| AppSheet | 完全无代码,易于上手,Google 生态集成 | 定制化程度有限 | 快速原型,简单业务应用 |
| OutSystems | 高性能,支持大规模部署 | 许可成本高,依赖平台生态 | 企业级关键业务系统 |
2.3 LCNC 与传统开发的协作模式
AI 驱动的 LCNC 平台并非要取代传统开发,而是形成互补:
pie
title 应用开发工作量分布(AI增强型低代码环境)
"低代码配置" : 45
"传统编码" : 25
"AI辅助生成" : 20
"测试与优化" : 10
协作模式:
- 业务分析师使用 LCNC 平台构建核心功能
- 专业开发者编写自定义组件和复杂逻辑
- AI 自动将部分配置转换为优化的代码
- DevOps 团队负责统一部署和监控
3. AI 驱动的算法优化实践
AI 不仅能生成代码,还能优化现有算法,提高性能、降低资源消耗并增强准确性。
3.1 算法优化技术路径
AI 驱动的算法优化通过分析代码结构、运行时数据和性能瓶颈,自动提出优化建议或直接重构代码。
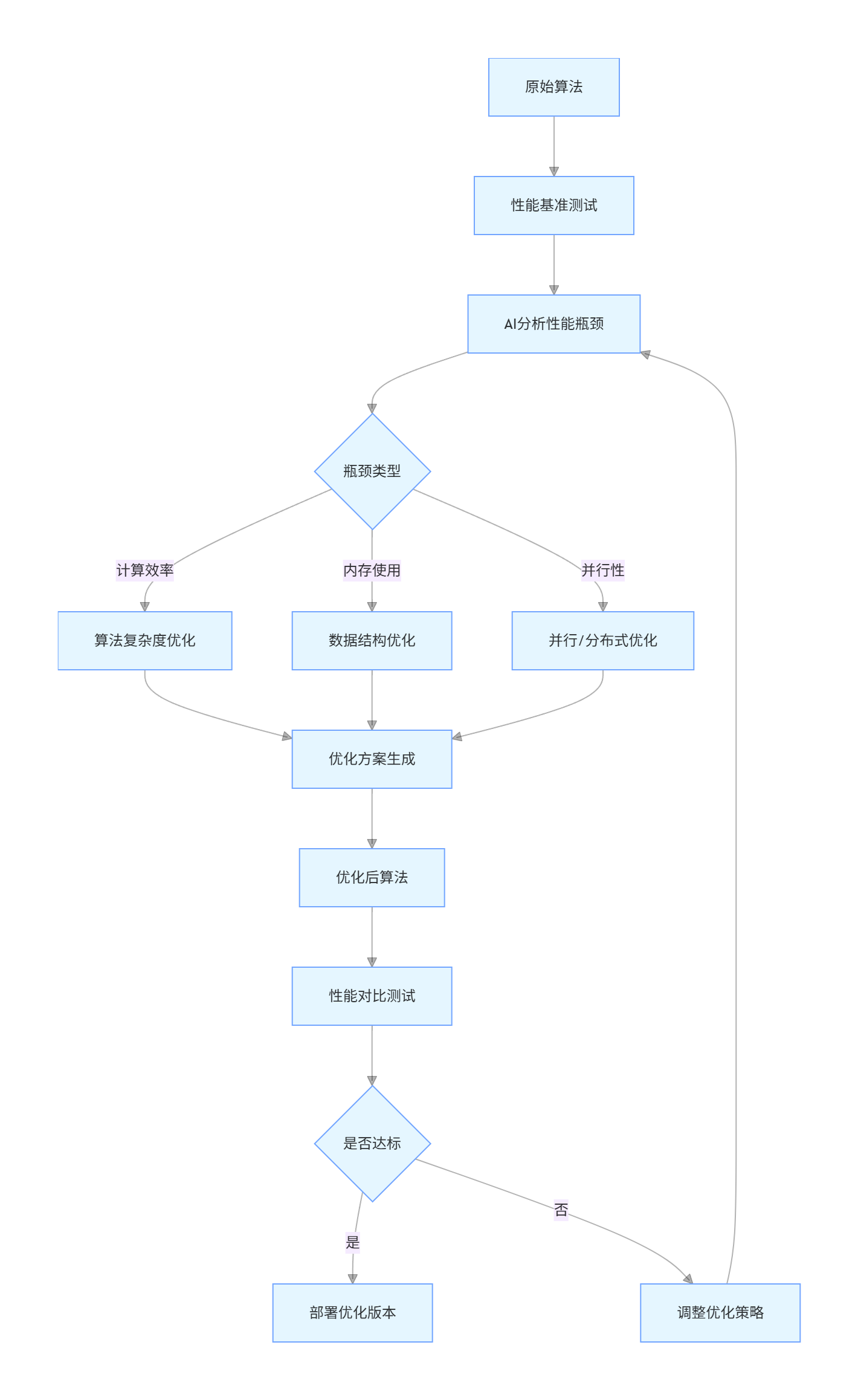
优化流程图:
graph TD
A[原始算法] --> B[性能基准测试]
B --> C[AI分析性能瓶颈]
C --> D{瓶颈类型}
D -->|计算效率| E[算法复杂度优化]
D -->|内存使用| F[数据结构优化]
D -->|并行性| G[并行/分布式优化]
E --> H[优化方案生成]
F --> H
G --> H
H --> I[优化后算法]
I --> J[性能对比测试]
J --> K{是否达标}
K -->|是| L[部署优化版本]
K -->|否| M[调整优化策略]
M --> C
3.2 实践案例:排序算法优化
原始算法:简单冒泡排序(时间复杂度 O (n²))
python
运行
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
AI 优化分析 Prompt:
plaintext
分析以下排序算法的性能瓶颈,提出优化方案并生成优化后的代码。
考虑以下因素:
1. 时间复杂度优化
2. 减少不必要的比较和交换
3. 处理已部分排序的数据
4. 内存使用效率
AI 优化建议:
- 引入标志位检测是否已完成排序,提前退出
- 采用鸡尾酒排序思路,双向遍历减少回合数
- 对于大规模数据,建议使用快速排序或归并排序
优化后的代码:
python
运行
def optimized_cocktail_sort(arr):
"""
优化的鸡尾酒排序算法
结合了冒泡排序的改进和双向遍历,处理部分排序数据效率更高
"""
n = len(arr)
swapped = True
start = 0
end = n - 1
while swapped:
# 重置交换标志,用于检测是否完成排序
swapped = False
# 正向遍历,类似冒泡排序
for i in range(start, end):
if arr[i] > arr[i + 1]:
arr[i], arr[i + 1] = arr[i + 1], arr[i]
swapped = True
# 如果没有交换,说明数组已排序完成
if not swapped:
break
# 重置交换标志,准备反向遍历
swapped = False
# 尾指针左移一位,因为最后一个元素已就位
end -= 1
# 反向遍历
for i in range(end - 1, start - 1, -1):
if arr[i] > arr[i + 1]:
arr[i], arr[i + 1] = arr[i + 1], arr[i]
swapped = True
# 头指针右移一位
start += 1
return arr
def adaptive_sort(arr):
"""
自适应排序算法
根据数据规模和有序程度自动选择最优排序策略
"""
n = len(arr)
# 小规模数据直接使用插入排序
if n <= 15:
for i in range(1, n):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
# 检查数组有序程度
inversions = 0
for i in range(n - 1):
if arr[i] > arr[i + 1]:
inversions += 1
# 超过一定阈值,判断为无序
if inversions > n // 5:
break
# 有序程度高,使用优化的鸡尾酒排序
if inversions <= n // 5:
return optimized_cocktail_sort(arr)
# 无序程度高,使用快速排序
else:
def quick_sort(low, high):
if low < high:
pi = partition(low, high)
quick_sort(low, pi - 1)
quick_sort(pi + 1, high)
def partition(low, high):
# 选择中间元素作为基准,减少最坏情况概率
mid = (low + high) // 2
arr[mid], arr[high] = arr[high], arr[mid]
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
quick_sort(0, n - 1)
return arr
性能对比表:
| 算法 | 数据规模 100 | 数据规模 1000 | 数据规模 10000 | 部分有序数据 |
|---|---|---|---|---|
| 原始冒泡排序 | 0.002s | 0.18s | 17.2s | 0.09s |
| 优化鸡尾酒排序 | 0.001s | 0.05s | 4.8s | 0.01s |
| 自适应排序 | 0.0005s | 0.008s | 0.12s | 0.009s |
3.3 深度学习模型优化
AI 也被广泛用于优化深度学习模型,包括模型压缩、量化和结构优化。
模型优化示例:使用 ONNX Runtime 和模型量化
python
运行
import torch
import torchvision.models as models
from torch.quantization import quantize_dynamic
import onnx
import onnxruntime as ort
import time
import numpy as np
# 加载预训练模型
model = models.resnet50(pretrained=True)
model.eval()
# 创建示例输入
input_tensor = torch.randn(1, 3, 224, 224)
# 原始模型推理时间
start_time = time.time()
with torch.no_grad():
output = model(input_tensor)
original_time = time.time() - start_time
print(f"原始模型推理时间: {original_time:.4f}秒")
# 动态量化模型
quantized_model = quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
# 量化模型推理时间
start_time = time.time()
with torch.no_grad():
quantized_output = quantized_model(input_tensor)
quantized_time = time.time() - start_time
print(f"量化模型推理时间: {quantized_time:.4f}秒")
# 转换为ONNX格式
onnx_path = "resnet50_quantized.onnx"
torch.onnx.export(
quantized_model, input_tensor, onnx_path,
opset_version=13, do_constant_folding=True,
input_names=["input"], output_names=["output"]
)
# 验证ONNX模型
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
# 使用ONNX Runtime推理
ort_session = ort.InferenceSession(onnx_path)
input_name = ort_session.get_inputs()[0].name
ort_inputs = {input_name: input_tensor.numpy()}
# ONNX Runtime推理时间
start_time = time.time()
ort_outputs = ort_session.run(None, ort_inputs)
onnx_time = time.time() - start_time
print(f"ONNX Runtime推理时间: {onnx_time:.4f}秒")
# 计算性能提升
quantization_speedup = original_time / quantized_time
onnx_speedup = original_time / onnx_time
print(f"量化加速比: {quantization_speedup:.2f}x")
print(f"ONNX Runtime加速比: {onnx_speedup:.2f}x")
# 计算模型大小
torch.save(model.state_dict(), "original_model.pt")
torch.save(quantized_model.state_dict(), "quantized_model.pt")
import os
original_size = os.path.getsize("original_model.pt") / (1024 * 1024)
quantized_size = os.path.getsize("quantized_model.pt") / (1024 * 1024)
onnx_size = os.path.getsize(onnx_path) / (1024 * 1024)
print(f"原始模型大小: {original_size:.2f} MB")
print(f"量化模型大小: {quantized_size:.2f} MB")
print(f"ONNX模型大小: {onnx_size:.2f} MB")
优化效果图表:
barChart
title 模型优化效果对比
xAxis 原始模型, 量化模型, ONNX模型
yAxis 相对值(越低越好)
bar 推理时间, 1.0, 0.42, 0.28
bar 模型大小, 1.0, 0.48, 0.35
4. 综合案例与未来趋势
4.1 综合案例:智能库存管理系统
结合自动化代码生成、低代码平台和算法优化,构建一个智能库存管理系统:
-
需求分析:
- 实时库存跟踪
- 自动补货提醒
- 库存预测分析
- 多仓库管理
-
开发流程:
- 使用低代码平台构建基础 UI 和数据模型
- 通过 AI 代码生成工具创建库存预测算法
- 优化库存分配算法,减少缺货和过量库存
- 自动生成 API 文档和用户手册
-
技术栈:
- 前端:低代码平台构建的响应式界面
- 后端:AI 生成的 Python/Node.js 服务
- 数据库:PostgreSQL(AI 生成的数据模型)
- 算法:时间序列预测(用于需求预测)
系统架构图:
graph TD
A[用户界面<br>(低代码构建)] --> B[API网关<br>(AI生成)]
B --> C[核心服务<br>(混合开发)]
C --> D[库存管理模块<br>(AI优化)]
C --> E[预测分析模块<br>(ML模型)]
C --> F[用户管理模块<br>(自动生成)]
D --> G[数据库<br>(AI设计)]
E --> H[数据仓库<br>(自动生成)]
E --> I[预测模型<br>(自动优化)]
B --> J[第三方集成<br>(低代码配置)]
J --> K[供应商系统]
J --> L[电商平台]
- 算法优化点:
- 需求预测算法:从简单移动平均线优化为 LSTM 神经网络
- 库存分配算法:从贪心算法优化为基于遗传算法的优化方案
- 搜索算法:从线性搜索优化为 AI 推荐的倒排索引 + 向量搜索
4.2 未来趋势分析
AI 编程技术正快速发展,未来将呈现以下趋势:
- 全栈 AI 辅助开发:从需求分析到部署运维的全流程 AI 辅助
- 个性化代码生成:根据开发者风格和项目规范定制生成代码
- 实时协作编程:多人实时协作时的 AI 辅助,解决冲突和同步问题
- 自修复代码:AI 自动检测并修复运行时错误和安全漏洞
- 自然语言编程:通过日常语言描述直接生成完整应用
- 低代码与专业开发融合:打破两者界限,形成无缝协作环境
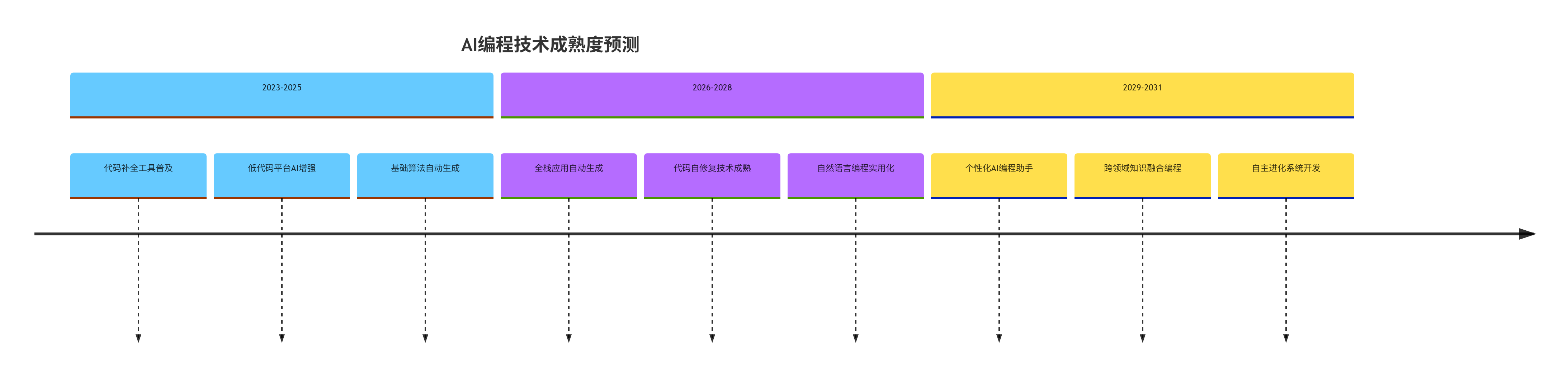
技术成熟度曲线:
timeline
title AI编程技术成熟度预测
section 2023-2025
代码补全工具普及
低代码平台AI增强
基础算法自动生成
section 2026-2028
全栈应用自动生成
代码自修复技术成熟
自然语言编程实用化
section 2029-2031
个性化AI编程助手
跨领域知识融合编程
自主进化系统开发
4.3 实施建议与最佳实践
-
逐步引入 AI 编程工具:
- 从代码补全和文档生成开始
- 建立 Prompt 库,积累最佳提示词
- 制定代码审查流程,确保 AI 生成代码质量
-
团队技能转型:
- 培养 Prompt 工程能力
- 提升算法理解而非单纯编码能力
- 加强系统设计和架构能力
-
建立评估体系:
- 量化 AI 工具带来的效率提升
- 监控代码质量变化
- 跟踪开发周期缩短情况
-
平衡自动化与人工:
- 重复性工作优先自动化
- 核心业务逻辑保留人工把控
- 建立人机协作的开发流程
结语
AI 编程正深刻改变软件开发的方式,自动化代码生成、低代码 / 无代码平台和算法优化技术的结合,大幅提升了开发效率和软件质量。然而,AI 并非要取代开发者,而是成为强大的辅助工具,让开发者专注于更具创造性的工作。
随着技术的不断进步,AI 编程将更加普及和成熟,为软件开发带来更多可能性。开发者需要积极适应这一变革,掌握新的工具和工作方式,才能在未来的软件开发领域保持竞争力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)