大厂集体押注 SDD!阿里、腾讯、亚马逊都在用的规范驱动开发,优势在哪?坑怎么避?
规范驱动开发(Spec-Driven Development,SDD)正成为 AI 编程中的新兴范式。本文深入探讨 SDD 的核心概念,将其划分为规范优先、规范锚定和规范即源码三个层次,分析该方法在实践中的优势与挑战,并审视其是否正在重演“模型驱动开发”(Model-Driven Development,MDD)的历史困境。
亚马逊 Kiro 因内置 Spec 工作流而出圈,阿里 Qoder 的 Quest Mode 是采用 Spec 驱动的 AI 自主编程,腾讯云 CloudBase AI Toolkit 同样集成了 Spec 工作流......随着越来越多头部厂商的采用,**规范驱动开发(Spec-Driven Development,SDD)**正成为 AI 编程中的新兴范式。本文深入探讨 SDD 的核心概念,将其划分为规范优先、规范锚定和规范即源码三个层次,分析该方法在实践中的优势与挑战,并审视其是否正在重演“模型驱动开发”(Model-Driven Development,MDD)的历史困境。本文作者 莫尔索,文章转载请联系作者。
欢迎订阅合集 AI 博客精选:精心编译海外技术厂商发布的高质量 AI 领域博客文章。
目录
- 什么是规范驱动开发?
- 规范 (spec) 到底是什么?
- 评估 SDD 工具的挑战
- 工具剖析:Kiro
- 工具剖析:spec-kit
- 工具剖析:Tessl 框架
- 观察和疑问
- 个人思考
什么是规范驱动开发?
在 AI 编程领域,规范驱动开发 (Spec-Driven Development, SDD) 是一个定义尚在变化中的新术语。根据目前的观察,SDD 的核心理念似乎是指在利用 AI 编写代码之前,首先编写一份规范(spec),即文档先行。这份规范将成为人类开发者与 AI 共同的事实来源。
不同的工具和平台对它有各自的理解。例如,GitHub 认为,在 AI 编程这个新世界里,维护软件意味着演进规范,软件的通用语言被提升到了一个更高的层次,而代码则成了“最后一英里”的实现方法。Tessl 则将其定义为一种开发方法,规范(而非代码)是主要的产物,规范使用结构化、可测试的语言来描述开发意图,然后由 AI 编码Agent生成与之匹配的代码。在研究了这些术语的用法和相关工具后,我认为 SDD 在实践中存在三个层次:
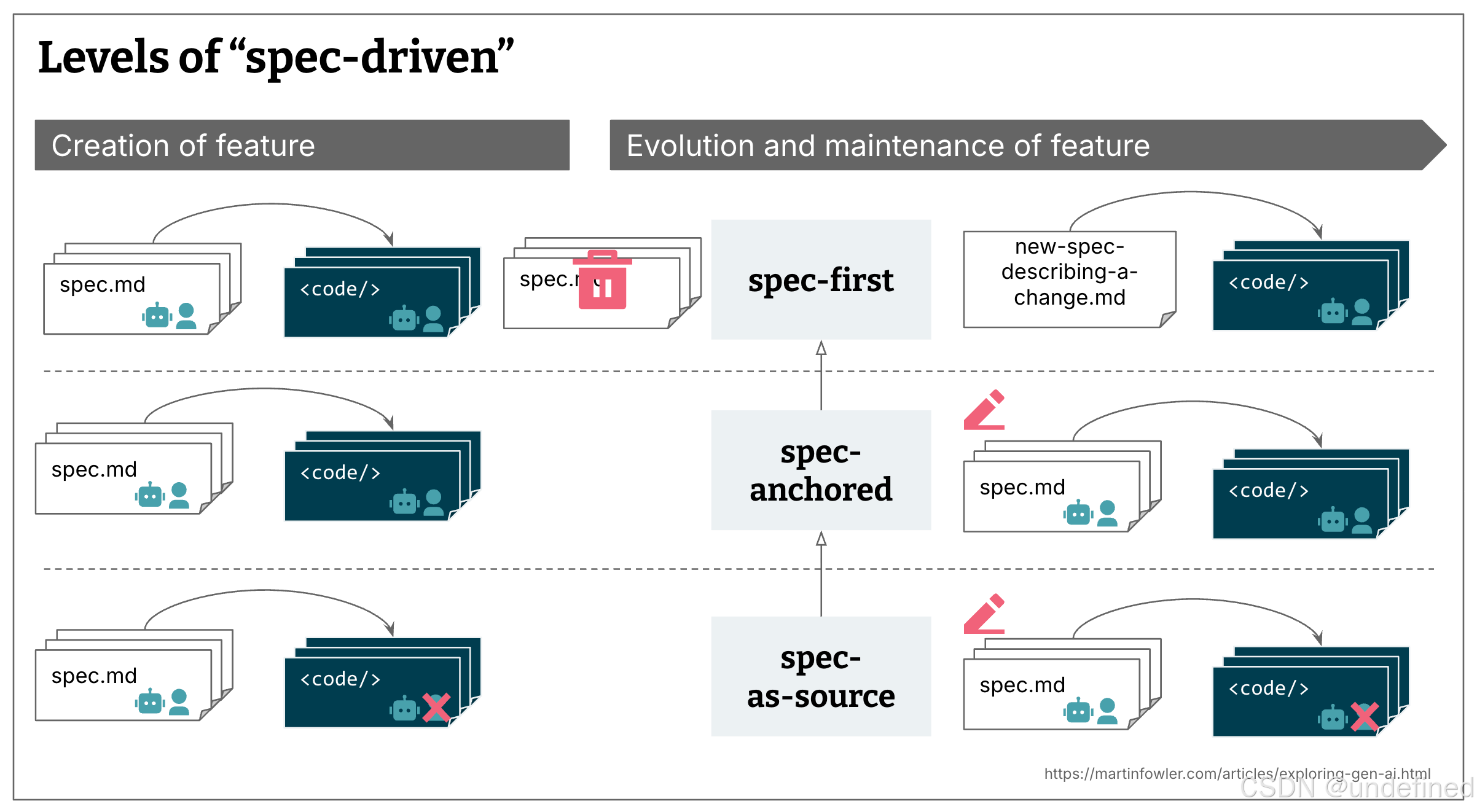
1. 规范优先 (Spec-first):这是最基础的层面,开发者首先编写一份深思熟虑的规范,然后在当前任务的 AI 辅助开发工作流中使用这份规范。 2. 规范锚定 (Spec-anchored):在任务完成后,规范并不会被丢弃,而是被保留下来,以便在后续对该功能进行演进和维护时继续使用。 3. 规范即源码 (Spec-as-source):这是最激进的层面,规范在时间推移中成为项目的主要源文件,人类开发者只编辑规范,永远不会直接修改代码。
并非所有工具都追求达到“规范锚定”或“规范即源码”的程度,目前所见的所有 SDD 方法和定义都属于“规范优先”,这些工具对于规范在长期维护中的策略,往往表述得含糊不清,或者完全开放。这三者是层层递进的关系:“规范锚定”建立在“规范优先”的基础上,而“规范即源码”又建立在“规范锚定”的基础上。
规范 (spec) 到底是什么?
在 SDD 的讨论中,关键问题自然是:规范 (spec) 究竟是什么?目前似乎还没有一个公认的定义。我所见到的最接近一致的定义,是将规范比作一份产品需求文档 (Product Requirements Document)。
规范这个词目前被严重滥用了。根据我的尝试将其定义为:规范是一种结构化的、面向行为的产物(或一组相关产物),它使用自然语言编写,用以表达软件功能,并作为 AI 编码Agent的指导。 每种 SDD 的变体都会定义各自的规范结构、详细程度以及这些产物在项目中的组织方式。
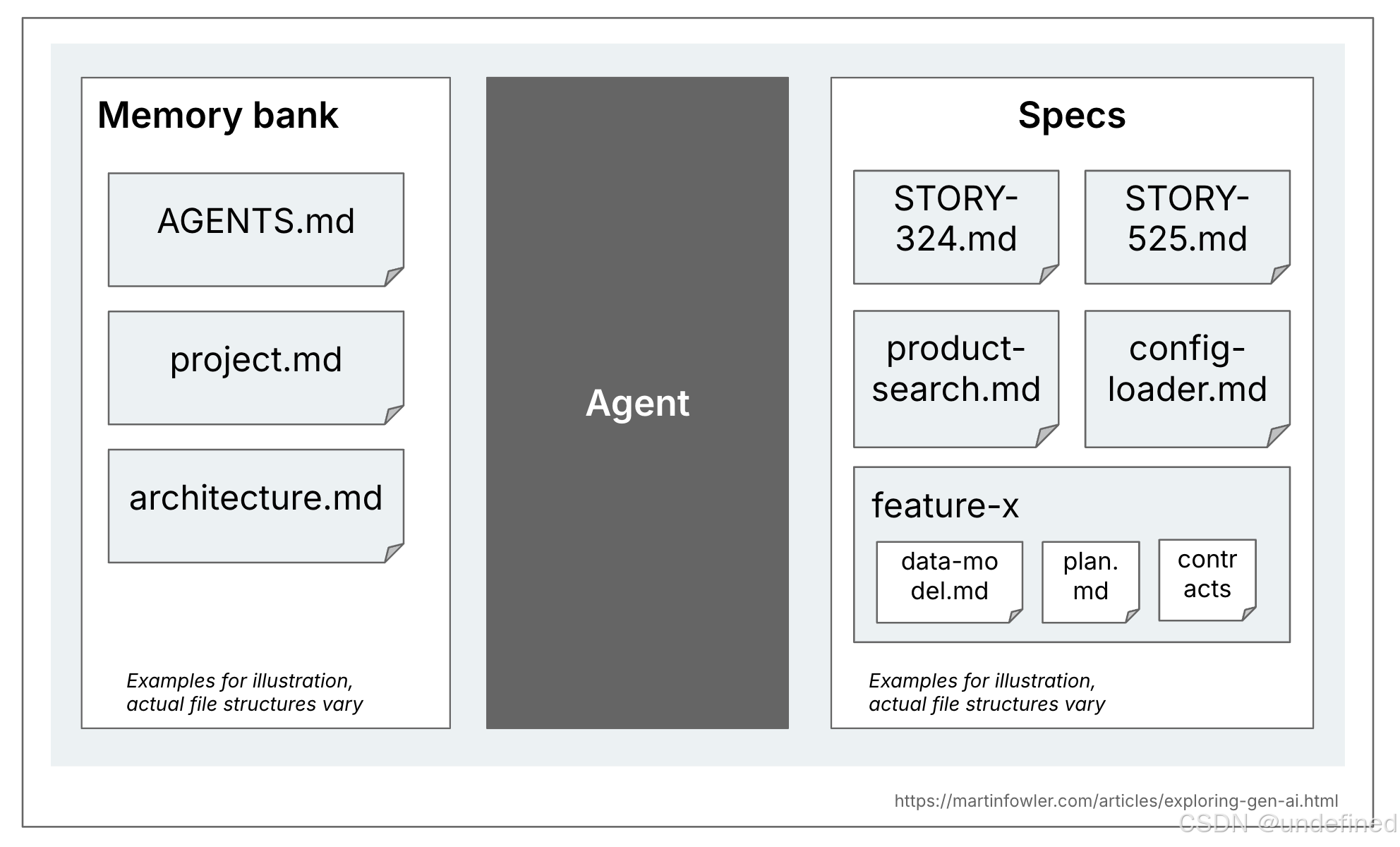
我认为,在规范与代码库的通用上下文文档之间做出区分是很有用的。通用上下文指的是诸如规则文件、产品的高阶描述或代码库架构说明等内容。有些工具将这种上下文称为记忆库(memory bank),因此这里也沿用这个叫法。这些记忆库文件与代码库中所有的 AI 编码会话都相关;而规范则不同,它只与那些创建或更改特定功能的特定任务相关。例如,记忆库可能包含 AGENTS.md 或 architecture.md 这样的文件,而规范可能是针对某个具体故事(如 Story-324.md)或某个特定功能(如 feature-x 文件夹下包含 data-model.md 和 plan.md)的文档。
评估 SDD 工具的挑战
事实证明,要以接近真实使用的方式来评估 SDD 工具及其方法,是相当耗时的。你必须在不同规模的问题上尝试它们,包括全新的项目( Greenfield Project)和已有的遗留项目(Brownfield Project),你还需要真正花时间去审查和修订那些中间产物,而不能只是粗略地扫一眼。正如 GitHub 关于 spec-kit 的博文所说:至关重要的是,你的角色不仅仅是引导,更是要验证。在每个阶段,你都需要反思和提炼。
对于我尝试的三种工具中的两种来说,将它们引入现有的代码库似乎需要做更多的工作,这使得评估它们在遗留项目代码库中的用处变得更加困难,,我对这种模式在真实项目中如何运作仍然抱有许多疑问。
例如,评估者需要投入大量时间来学习工具的特定工作流,理解其规范的组织方式,并适应 AI 生成的中间产物。在遗留项目中,工具需要理解大量现有代码的上下文,这本身就是一个巨大的挑战。如果工具生成的规范或代码与现有逻辑不匹配,开发者需要花费更多时间去调试和修正,这个成本可能远高于传统开发方式。因此,缺乏来自真实、长期项目的反馈,使得我们很难判断 SDD 究竟是提高了效率,还是仅仅增加了不必要的复杂性。
工具剖析:Kiro
三种工具中,Kiro 是最简单(或最轻量级)的一个。它似乎主要停留在“规范优先”的层面。所有例子都只是用它来处理一个任务或一个用户故事,没有提到如何在多个任务中随时间推移,以“规范锚定”的方式来使用需求文档。
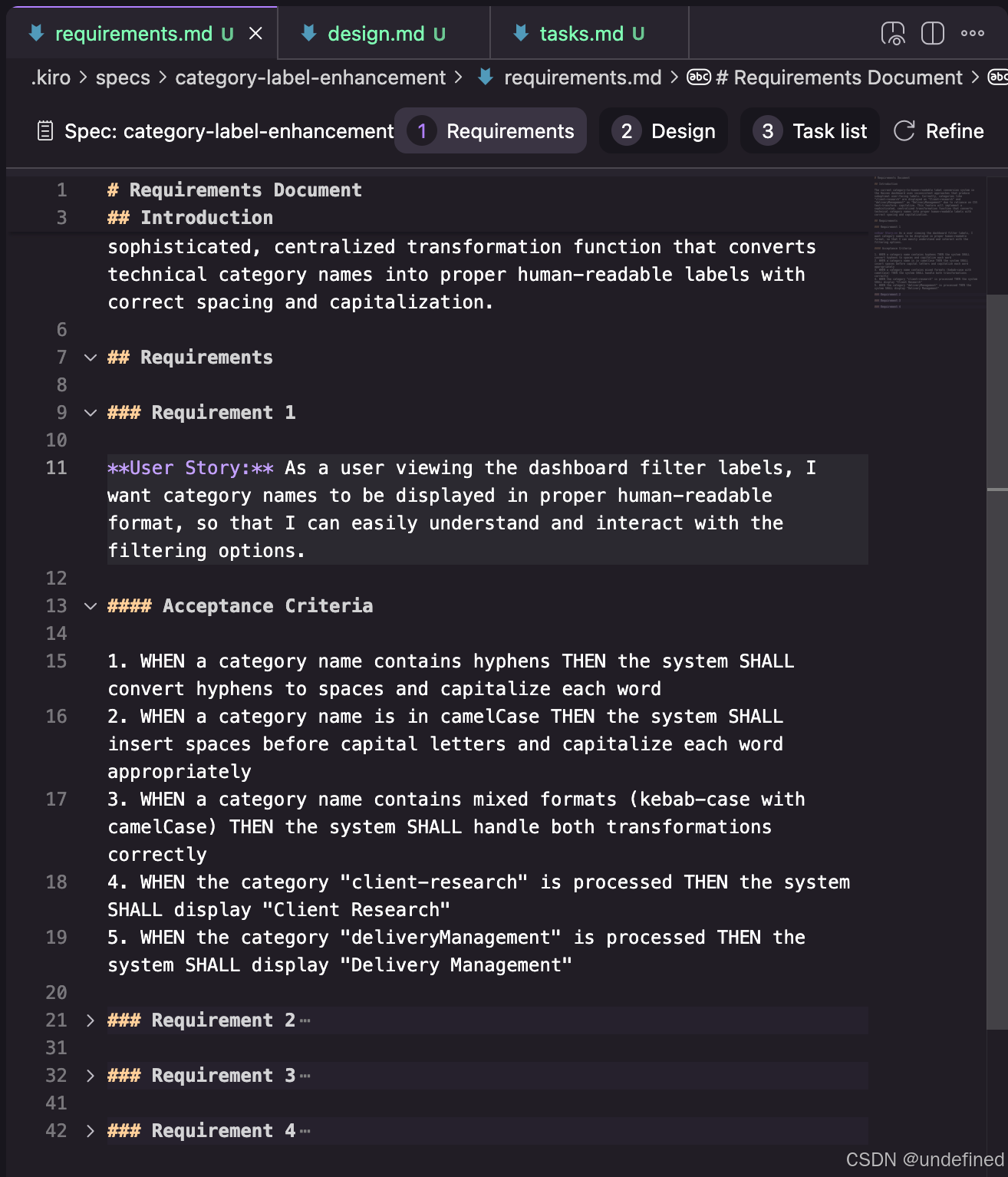
Kiro 的 spec 流程被设计为三个步骤:需求 (Requirements) → 设计 (Design) → 任务 (Tasks)。每个工作流步骤都由一个 Markdown 文档表示,Kiro 会在引导你完成这三个步骤。
首先是需求文档。它被构建为一个需求列表,每个需求代表一个“用户故事” (User Story),采用“作为...(As a...)”的格式。同时,每个需求都配有验收标准,采用“假如... (GIVEN...) 当... (WHEN...) 则... (THEN...)”的格式。
接下来是设计文档。。。。
欢迎订阅合集 AI 博客精选:精心编译海外技术厂商发布的高质量 AI 领域博客文章。本文作者 莫尔索,文章转载请联系作者。
观察和疑问
这三种工具都自称为规范驱动开发的实现,但它们彼此之间差异很大。因此,在谈论 SDD 时,首先要记住的是,它指的并不是某一个事物,我在试用后,产生了一些关键的观察和疑问。
一个工作流能适应所有规模吗?
Kiro 和 spec-kit 都提供了各自固定的工作流,但我很确定它们都不适用于现实生活中绝大多数的编码问题。特别是,我不清楚它们如何能满足不同问题规模的需求,以至于能被普遍适用。 当我让 Kiro 修复一个我过去用来测试 Codex 的小 bug 时,
。。。。。。
欢迎订阅合集 AI 博客精选:精心编译海外技术厂商发布的高质量 AI 领域博客文章。
个人思考
在我个人使用 AI 辅助编程的过程中,我也经常会花时间先精心制作某种形式的规范,然后交给编码Agent。因此,在许多情况下,“规范优先”的总体原则绝对是有价值的。目前,从业者最常问的问题就是:“我该如何构建我的记忆库?”以及“我该如何为 AI 编写一份好的规范和设计文档?”。
关于尝试过的这些工具,我对它们在现实世界中的实用性提出了许多疑问。我在想,它们中的一些是否正试图把我们现有的工作流过于字面地“喂”给 AI 编码 Agent,最终放大了现有的挑战,如审查过载和AI 幻觉。尤其是那些依赖大量细碎文件的方法,我不禁想到德语中的一个复合词——“Verschlimmbesserung”:我们是否在试图改进某个流程时,却适得其反,使其变得更糟?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)