记录一次生产事故:kafka消息堆积(经典面试题)
摘要: AI应用开发中遇到Kafka消息阻塞事故。用户上传大文本文件后,向量化处理超时,引发Kafka消费者重复消费。排查发现:1)Kafka消费者处理时间超过30分钟阈值,触发重平衡;2)接口超时设置与Kafka超时冲突,导致catch块未执行;3)消费者被踢出组后循环重试。临时解决方案:特定文件跳过处理并手动标记成功。次日问题重现,日志显示ReadTimeoutException持续存在,需进
记一次kafka消息阻塞
1 背景
背景:在公司做了一款AI应用产品,功能跟千问、豆包等一样。知识库上传文件,AI对话时,大模型检索文件内容,根据文件内容来回答。其中知识库文件上传时需要进行向量化。不理解向量化的,理解成需要调用大模型接口,把文件传给他就行,怎么解析就是大模型的事了。
我的设计方案就是文件上传之后,数据库存储文件名等信息,然后存到minio,最后发送到Kafka,最后由Kafka消费者去minio获取文件,调用大模型接口,把文件传给它
2 事故
有一天,正在着急忙慌地赶工做其它需求,产品经理突然告诉我,有用户反馈文件上传后,向量化失败了(可以理解成调用大模型接口失败了)。本来这种问题遇到很多次了,几乎都是大模型的问题,我就直接转给了AI算法工程师的同事。同事排查后发现,虽然文件不大,只是一个9M的txt文件,但是txt里面全是文字,同事说有109万的文字。大模型读取文件内容、切块、向量化、存到向量库,耗费时间太长,超时了
我一听,不是我的问题,真好
正当我心花怒放的时候,同事突然惊呼:怎么你一直在调我的接口,一直在发送109万文字的txt文件。
瞬间我心头一紧,麻烦来了。。。
我只能去排查下,我的代码如下:不方便泄漏公司的代码,只能用伪代码来代替哈
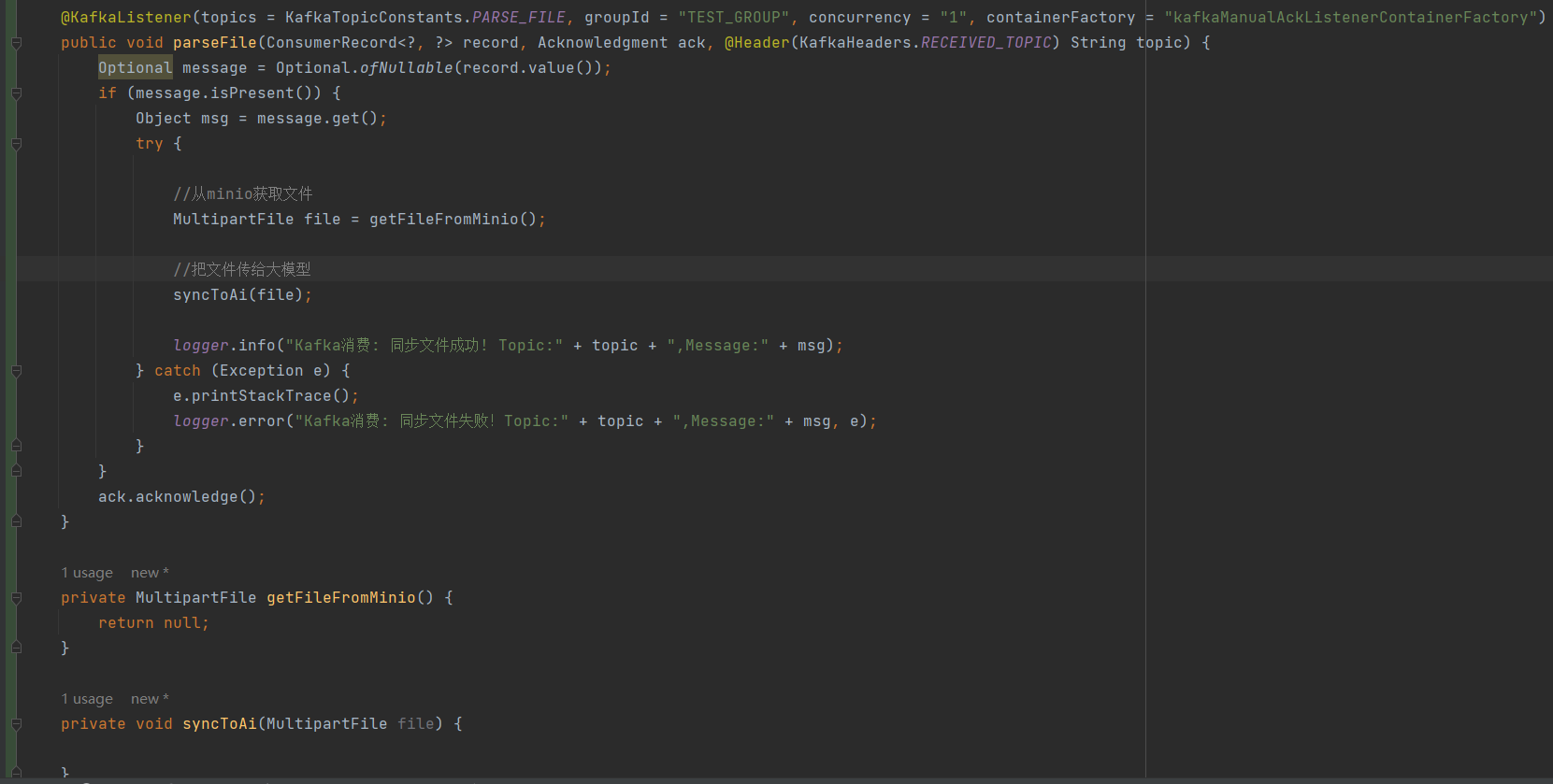
明明的我加了try catch,调用大模型接口,不管成功还是失败,都会被catch捕获到,我又没有抛异常,最后我还手动提交了offset。也就是说调用大模型的接口,不管成功还是失败,我都会提交offset,不会导致消息阻塞和消费重试。偏偏事与愿违
3 日志
我只能去看下服务器日志:
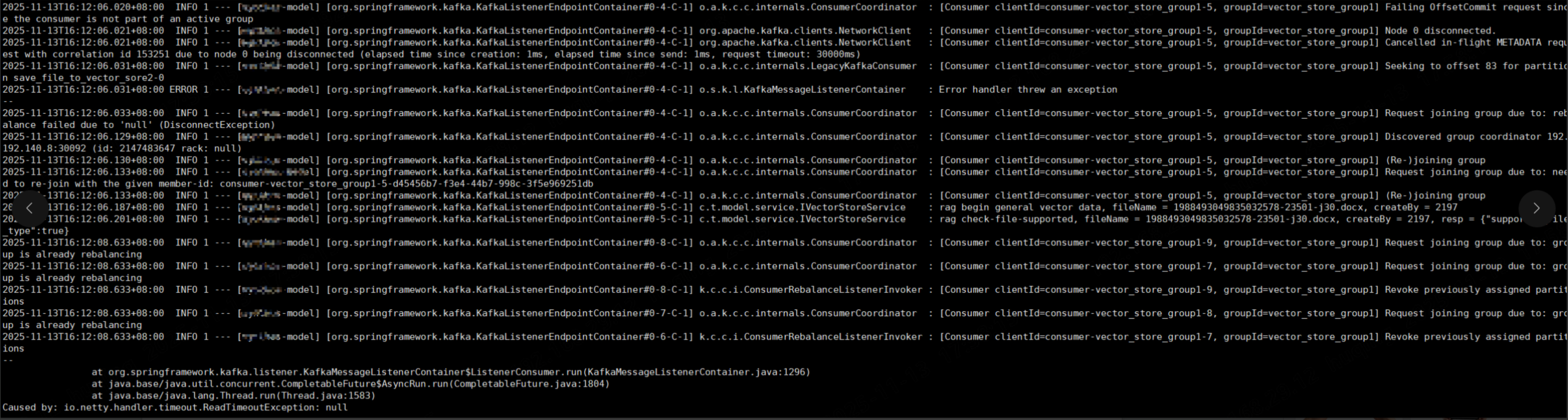
看到如下日志,我知道是Kafka消费超时了
at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:1296)
at java.base/java.util.concurrent.CompletableFuture$AsyncRun.run(CompletableFuture.java:1804)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: io.netty.handler.timeout.ReadTimeoutException: null
再看我在代码中打印的日志,上午上传的文件,下午Kafka消费者还在不断重试调用大模型接口,明明我加了try catch,最后还手动提交了offset,为什么还会重试呢?
接着接续看日志,发现下面的日志我看不懂
[Consumer clientId=consumer-vector_store_group1-9, groupId=vector_store_group1] Request joining group due to: group is already rebalancing
我就把日志发给了大模型,原来:
consumer-vector_store_group1-9:消费者ID,说明这是第9个消费者
groupId=vector_store_group1:消费者组ID
Request joining group due to: group is already rebalancing:说明消费者正在尝试加入消费者组,但是消费者组已经在进行rebalance(重平衡),所以它会等待当前的rebalance(重平衡)完成后再加入
我就好奇,怎么突然就触发rebalance(重平衡)呢?大模型告诉我:消费者处理消息的时间太长,导致心跳超时,被Kafka踢出消费者组,进而触发rebalance(重平衡)
看到这儿,我赶紧去看下Kafka配置,看设置的超时时间是多久。代码如下:
kafka:
#以逗号分隔的主机:端口对列表,用于建议与Kafka的连接
bootstrap-servers: 114.115.208.175:9092
producer:
# 发生错误后,消息重发的次数
retries: 3
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=1表示消息保存到分区leader后,就被视为已提交
acks: 1
consumer:
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# kafka默认自动提交,如果还没消费完就自动提交了,就有问题,所以改成手动提交
enable-auto-commit: false
# 消费者无法找到某个分区的初始偏移量时,从分区中最早的消息开始读取
auto-offset-reset: earliest
properties:
max.poll.interval.ms: 180000
listener:
# 创建几个消费者线程去消费
concurrency: 2
# 消费者ack模式配置,manual_immediate是立即手动确认方式,消费者在调用acknowledge()方法时,立即向kafka发送确认消息,这是为了配合手动提交
ack-mode: manual_immediate
# kafka启动时,未找到对应的topic不报错
missing-topics-fatal: false
发现Kafka的超时时间是30分钟(max.poll.interval.ms: 180000)。都30分钟了,接口没超时吗?为什么反而是Kafka超时呢?我就看了下接口超时时间设置,发现后端同事设置的接口超时时间也是30分钟
Kafka消费者在处理消息时,由于先做了一些查询动作(比如花了1分钟),最后才调用大模型接口(比如花了29分钟),也就是说消费者花了30分钟的时候,调用大模型才花了29分钟,这也是为什么接口没超时,而是Kafka先超时
看到这儿,我大概看明白了,Kafka消费者处理消息的时间太长,导致消费者被踢出消费者组,触发rebalance(重平衡)。创建新的消费者重新消费,又超时,陷入死循环,导致消息一直重复消费和消息堆积。尽管我加了try catch,但是接口没超时,所以catch里面的代码没执行,甚至最后的一行的ack.acknowledge();手动提交offset也没执行,Kafka消费者就超时了
最后,AI算法工程师的同事告诉我,文件他已经向量化成功了,但是没办法通过接口告诉我,而且我这边的Kafka还在不断调用接口
没办法,我只能改下代码,加几行判断逻辑:如果文件名是aaa.txt,则直接提交offset,不再调用大模型接口了。然后重新发个版,手动改下数据库的向量化状态,在页面上显示向量化成功。暂时把事情解决了,关机下班。。。
第二天上班,正在心情沉重地刷东方财富,看着我的粤传媒跌停。AI算法工程师的同事告诉我:Kafka又消息阻塞了。这让我本来沉重的心情更加沉重了
我就登录服务器看了下日志:
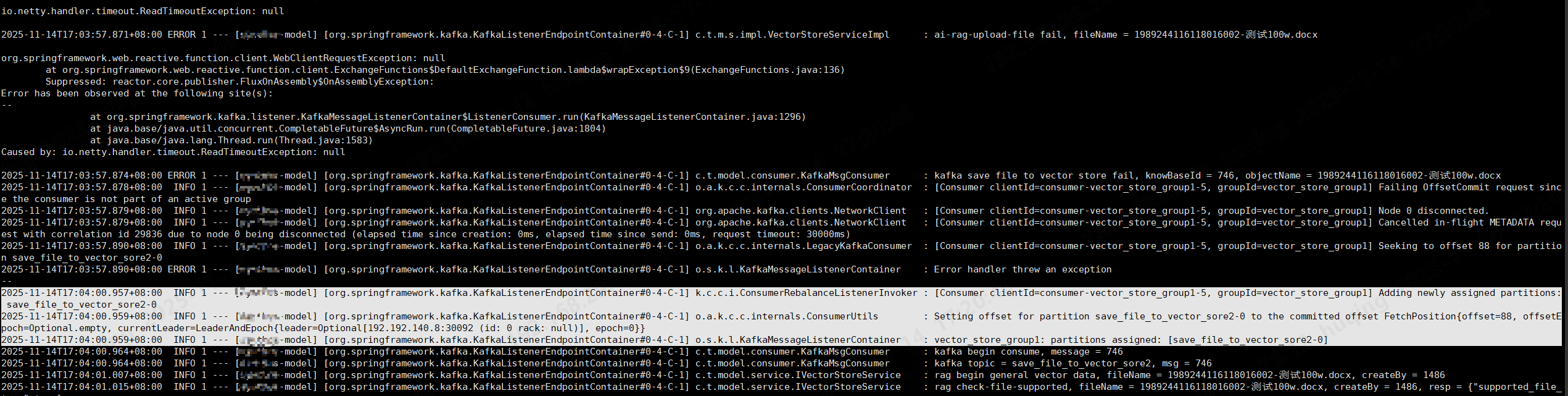
日志内容如下:
io.netty.handler.timeout.ReadTimeoutException: null
2025-11-14T17:03:57.871+08:00 ERROR 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] c.t.m.s.impl.VectorStoreServiceImpl : ai-rag-upload-file fail, fileName = 1989244116118016002-测试100w.docx
org.springframework.web.reactive.function.client.WebClientRequestException: null
at org.springframework.web.reactive.function.client.ExchangeFunctions$DefaultExchangeFunction.lambda$wrapException$9(ExchangeFunctions.java:136)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Error has been observed at the following site(s):
--
at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:1296)
at java.base/java.util.concurrent.CompletableFuture$AsyncRun.run(CompletableFuture.java:1804)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: io.netty.handler.timeout.ReadTimeoutException: null
2025-11-14T17:03:57.874+08:00 ERROR 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] c.t.model.consumer.KafkaMsgConsumer : kafka save file to vector store fail, knowBaseId = 746, objectName = 1989244116118016002-测试100w.docx
2025-11-14T17:03:57.878+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-vector_store_group1-5, groupId=vector_store_group1] Failing OffsetCommit request since the consumer is not part of an active group
2025-11-14T17:03:57.879+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] org.apache.kafka.clients.NetworkClient : [Consumer clientId=consumer-vector_store_group1-5, groupId=vector_store_group1] Node 0 disconnected.
2025-11-14T17:03:57.879+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] org.apache.kafka.clients.NetworkClient : [Consumer clientId=consumer-vector_store_group1-5, groupId=vector_store_group1] Cancelled in-flight METADATA request with correlation id 29836 due to node 0 being disconnected (elapsed time since creation: 0ms, elapsed time since send: 0ms, request timeout: 30000ms)
2025-11-14T17:03:57.890+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] o.a.k.c.c.internals.LegacyKafkaConsumer : [Consumer clientId=consumer-vector_store_group1-5, groupId=vector_store_group1] Seeking to offset 88 for partition save_file_to_vector_sore2-0
2025-11-14T17:03:57.890+08:00 ERROR 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] o.s.k.l.KafkaMessageListenerContainer : Error handler threw an exception
--
2025-11-14T17:04:00.957+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] k.c.c.i.ConsumerRebalanceListenerInvoker : [Consumer clientId=consumer-vector_store_group1-5, groupId=vector_store_group1] Adding newly assigned partitions: save_file_to_vector_sore2-0
2025-11-14T17:04:00.959+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] o.a.k.c.c.internals.ConsumerUtils : Setting offset for partition save_file_to_vector_sore2-0 to the committed offset FetchPosition{offset=88, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[110.110.110.5:30092 (id: 0 rack: null)], epoch=0}}
2025-11-14T17:04:00.959+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] o.s.k.l.KafkaMessageListenerContainer : vector_store_group1: partitions assigned: [save_file_to_vector_sore2-0]
2025-11-14T17:04:00.964+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] c.t.model.consumer.KafkaMsgConsumer : kafka begin consume, message = 746
2025-11-14T17:04:00.964+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] c.t.model.consumer.KafkaMsgConsumer : kafka topic = save_file_to_vector_sore2, msg = 746
2025-11-14T17:04:01.007+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] c.t.model.service.IVectorStoreService : rag begin general vector data, fileName = 1989244116118016002-测试100w.docx, createBy = 1486
2025-11-14T17:04:01.015+08:00 INFO 1 --- [huqing-model] [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] c.t.model.service.IVectorStoreService : rag check-file-supported, fileName = 1989244116118016002-测试100w.docx, createBy = 1486, resp = {"supported_file_type":true}
分析一下日志内容:
消费者正在为分区save_file_to_vector_score2-0设置消费的起始偏移量(offset)
FetchPosition{offset=88, …}表示消费者将从偏移量88开始消费这个分区的消息
offsetEpoch=Optional.empty:表示这个偏移量没有与特定的Kafka消息版本(epoch)绑定
currentLeader=…:表示该分区当前的 Leader Broker 是 110.110.110.5:30092,ID为0,没有rack信息
epoch=0:表示该分区当前的Leader任期为0
先说明一下:消费者在开始消费某个分区之前,会从Kafka的offset提交日志中读取上次提交的offset,然后从那里继续消费,这是为了保证消息消费的连续性,避免重复消费或丢失消息
总结:这些日志表示的是:
Kafka消费者组 vector_store_group1 中的一个消费者(comsumer-vector_store_group1-5)被分配了分区 save_file_vector_store2-0,该消费者从偏移量88开始消费该分区的消息,当前该分区的Leader是110.110.110.5:30092。这是Kafka消费者组在rebalance(重平衡)期间的正常行为,通常发生在消费者加入或退出、分区数变化等场景
我就纳闷了,怎么又重平衡了,难道又有人在上传9M的109万文字的txt文件?我就随便问了AI算法工程师的同事:你怎么知道又阻塞了。同事告诉我:是我在上传昨天那个文件,复现一下问题。瞬间我心里1万个草泥马在奔腾。。。
4 Kafka可视化工具
给大家推荐一款Kafka可视化监控工具:Kafka Map。市面上有很多Kafka可视化监控工具,但是很多都需要安装MySQL,甚至还需要安装ES的。但是Kafka Map就非常轻便、小巧,页面也很简洁。不需要安装任何附属工具
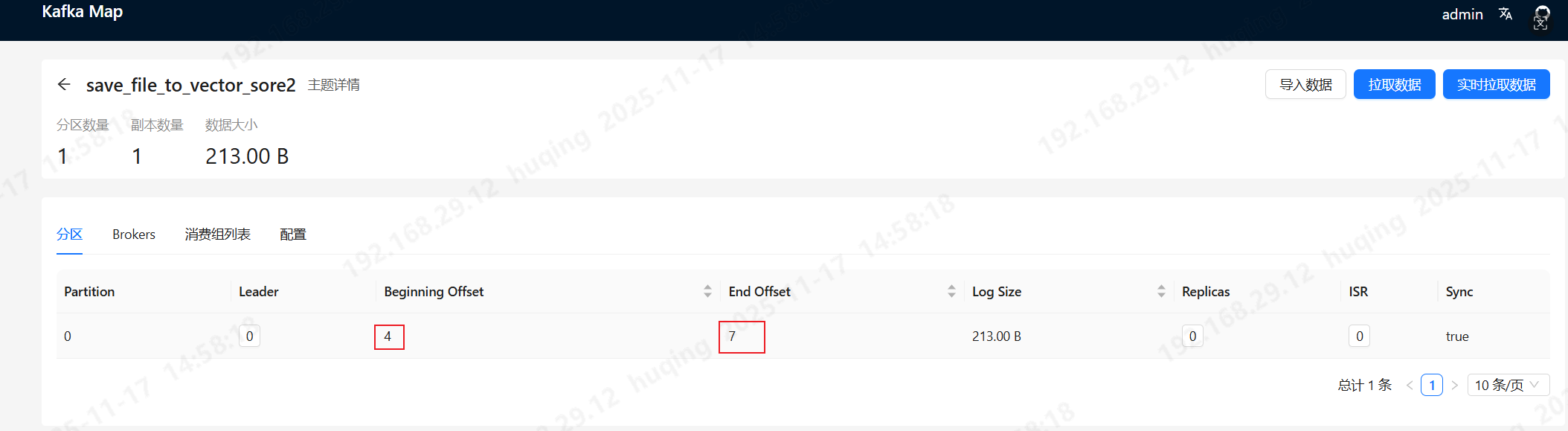
上图中可以看到,开始offse是4,结束offset是7,说明消费者已经消费到4了,但是5、6、7还没消费,但是过了一段时间,数值没变化,说明已经在阻塞了
5 面试题(经典)
到这儿就完了吗?写这篇文章的目的,就是想和大家分享日常工作中遇到的疑难杂症、排查思路和解决方案。有些同学可能会问:分享出来又有什么用呢?
同志们,面试的时候,面试官会问你Kafka发送消息是使用什么方法这么弱智的问题吗?他会问:如果Kafka消息堆积了,你怎么办?这是典型的场景问题,就考察你有没有深度使用过Kafka、以及解决问题的能力
可能你会说,增加机器、增加消费者不就行了吗。同志们,这是最笨的方法,而且千钧一发之际,你非要选择加机器这种耗时耗力的方法,面试官肯定pass了
正确的回答是什么?我遇到过一次,消息堆积了,首要要排查是哪里出了问题,导致消息堆积的。一般是消费者处理消息时失败了,没有提交offset,导致消费者一直重试,一直失败,后面的消息得不到消费机会。但是我遇到的情况有点不同,我的消费者调用大模型接口,调用接口没超时,但是我的Kafka消费者先超时了,Kafka认为它死掉了,从而触发重平衡,这才导致消息堆积
最后附加一个面试题:你是怎么判断你的Kafka消息堆积了?同学们,上图Kafka Map中介绍的开始offset为4,结束offset是7,这算不算堆积?如果结束offset在持续增加,而开始offset一直不变,说明生产者一直在发送消息,而消费者已经没再消费了,这明显是消费者的问题导致的消息堆积。如果开始offset也一直在增加,只是没有结束offset增加的快,说明生产者发送消息的速度太快了,消费者来不及消费,这时就得想办法提升消费者的消费速度了
最后,并不是说开始offset和结束offset相差很大才能算消息积压,即使4和7相差3个,这也算是消息积压,因为消费者已经不消费了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)