知识图谱02——知识图谱的表示
第1节什么是知识表示第2节AI历史长河中的知识表示方法第3节知识图谱的符号表示第4节知识图谱的向量表示
知识图谱 -02
第1节 什么是知识表示
知识表示(KR)是用计算机可处理的方式描述人脑知识的方法,核心是支持推理——这是它与数据格式、数据结构、编程语言的本质区别。
知识表示的五个核心用途
- 客观事物的机器标识(Surrogate):用机器可识别的形式指代现实对象。
- 一组本体约定和概念模型(Ontological Commitments):定义领域内的概念及关系规则。
- 支持推理的表示基础(Theory of Intelligent Reasoning):为机器推理提供逻辑依据。
- 用于高效计算的数据结构(Medium for Efficient Computation):适配机器快速处理。
- 人可理解的机器语言(Medium of Human Expression):兼顾机器处理与人类解读。
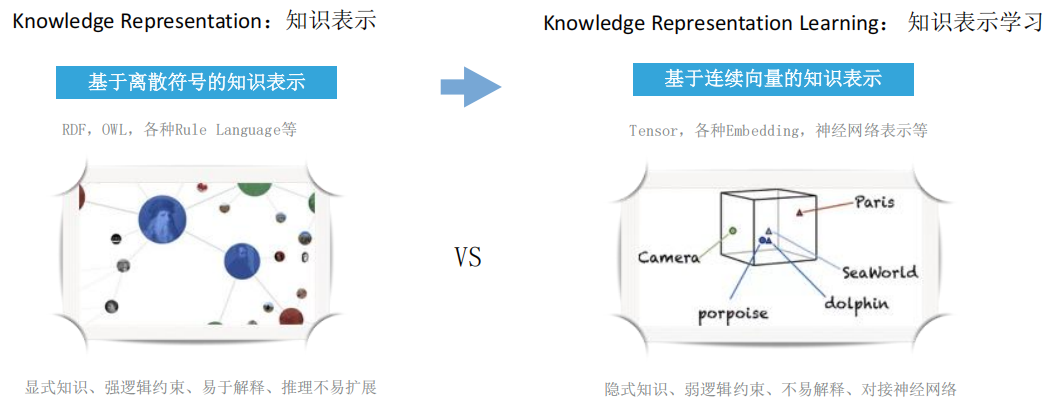
两种核心表示路径
- 符号表示:如RDF、OWL、规则语言,特点是显式知识、强逻辑约束、易于解释,但推理不易扩展。
- 向量表示:如Embedding、张量,特点是隐式知识、弱逻辑约束、不易解释,但能对接神经网络,支持多模态融合。
- 趋势:符号表示与神经网络结合,兼顾推理严谨性与扩展灵活性。
第2节 AI历史长河中的知识表示方法
知识表示是传统符号AI的核心,发展脉络清晰,关键方法各有侧重:
发展时间线
- 1960s-1970s:语义网络(Semantic Nets)——Quillian提出,模拟人类联想记忆。
- 1970s-1980s:产生式规则(Production Rules)+ 专家系统——落地于DENDRAL、MYCIN等经典系统。
- 1980s-1990s:框架系统(Framework)——Marvin Minsky提出,结构化描述对象属性。
- 1990s-2000s:描述逻辑(Description Logic)——一阶谓词逻辑的可判定子集,支撑本体建模。
- 2000s-2010s:语义网(RDF&OWL)——Tim Berners-Lee推动,成为Web语义数据标准。
关键方法详解
| 方法 | 核心要素 | 优点 | 缺点 |
|---|---|---|---|
| 描述逻辑 | 概念(领域子集)、关系(二元关系)、个体(实例);知识库分TBox(内涵知识)、ABox(外延知识) | 表达精准、支持推理,适配本体构建 | 复杂度较高,不易大规模落地 |
| Horn逻辑 | 原子、规则(H:-B1,B2…)、事实(无变量规则) | 表达简单、复杂度低,Prolog语言基础 | 表达能力有限,不适配复杂知识 |
| 产生式系统 | 规则(IF P THEN Q,含置信度CF) | 自然直观、模块化强,支持多种知识类型 | 效率低,易出现组合爆炸,不支持结构性知识 |
| 框架系统 | 框架(含槽、侧面、属性值) | 知识描述完整,支持数值计算 | 构建成本高,表达不灵活,难关联其他数据集 |
| 语义网络 | 节点(概念/实例)+ 边(语义关系),代表如WordNet | 结构化、联想性强,适配自然语言理解 | 无统一标准,推理正确性无保障,处理复杂 |
第3节 知识图谱的符号表示方法
符号表示是知识图谱的基础,核心有三种主流模型,各有适配场景:

1. 属性图(Property Graph)
- 定义:工业界常用(如Neo4J),由节点、边、标签、属性组成的有向图。
- 核心特点:节点和边均可带键值对属性,支持多元关系,查询效率高。
- 优势:表达灵活,适配工业界复杂业务场景,存储优化充分。
- 不足:无统一标准,不支持符号推理,语义表达较浅。
- 示例:节点“Tom Hanks”(属性:name=Tom Hanks, born=1956)通过“ACTED IN”边(属性:roles=[Forrest])连接节点“Forrest Gump”(属性:title=Forrest Gump, released=1994)。
2. RDF(资源描述框架)
RDF 代表 Resource Description Framework (资源描述框架)
- 定义:W3C标准,基于三元组(S-P-O,主-谓-宾)的断言模型。
- 核心特点:结构简单,适配Web环境下的语义数据交换,支持跨数据源融合。
- 扩展:RDFS(简单词汇表),定义Class、subClassOf、Property等基础语义,支持简单推理(如“谷歌是AI公司”+“AI公司是高科技公司”→“谷歌是高科技公司”)。
- 优势:标准统一,语义严谨,支持推理,适配大规模数据交换。
- 不足:三元组表达复杂关系时较繁琐。

3. OWL(Web本体语言)
- 定义:基于描述逻辑,扩展RDFS的语义表达能力,是完备的本体语言。
- 核心表达构件:
- 等价性声明(如“运动员≡体育选手”);
- 属性特性(传递性、互反性、函数性、对称性);
- 属性约束(全称限定、存在限定、基数限定);
- 类操作(如“母亲=人∩有孩子”的交集类)。
- 语言家族:OWL 2 Full(不可判定)、OWL 2 DL(复杂度高)、OWL 2 RL(兼顾表达与效率)、OWL 2 EL(适配医疗等领域)、OWL 2 QL(适配大规模查询)。
- 优势:语义表达能力强,支持复杂推理,是知识图谱深度建模的核心。
- 不足:复杂度高,学习成本高。
OWL核心表达构件速查表
| 构件类别 | 构件名称 | 类型细分 | 核心作用 | 通俗示例 |
|---|---|---|---|---|
| 基础核心构件 | 类(Class) | - | 抽象概念集合,归类同类实例 | “动物”“学生”“书籍” |
| 个体(Individual) | - | 类的具体实例,对应现实对象 | “猫(动物类实例)”“小明(学生类实例)” | |
| 属性(Property) | 对象属性 | 关联两个不同类/个体,描述语义关系 | “属于”(学生→学校)、“朋友”(人→人) | |
| 数据属性 | 关联类/个体与具体数据,描述固有特征 | “年龄”(学生→20)、“书名”(书籍→《论语》) | ||
| 关系与约束构件 | 公理(Axiom) | - | 定义语义规则,规范类/属性的逻辑关系 | 等价(“医生”≡“医师”)、不相交(“植物”≠“动物”) |
| 限制(Restriction) | - | 约束属性取值范围/关联对象,精准限定语义 | “年龄>0且<150”“所属学校仅关联‘学校’类” | |
| 扩展辅助构件 | 数据类型(Datatype) | - | 限定数据属性的取值类型 | 整数(int)、字符串(string)、日期(date) |
| 注释构件(Annotation) | - | 为本体元素添加说明,不影响语义逻辑 | 给“学生类”标注“指在校接受教育的人” |
三者对比
- 属性图:工业界首选,侧重查询效率与灵活性,不支持推理。
- RDF:标准统一,侧重数据交换与简单推理,是语义网基础。
- OWL:侧重复杂语义表达与深度推理,适配需要严谨逻辑的场景。
第4节 知识图谱的向量表示方法
向量表示(知识图谱嵌入)是将实体和关系映射为低维稠密向量,适配神经网络处理,核心是“用数值计算替代符号推理”。
1. 基础:从词向量到图谱嵌入
- 词的表示局限:One-hot编码维度高、语义孤立(任意两词相似度为0);分布式表示(Word Embedding)通过上下文学习向量,解决语义关联问题(如“Rome”与“Paris”向量相似)。
- 图谱嵌入思路:将实体(如Rome、Italy)和关系(如is-capital-of)均映射为低维向量,用向量运算模拟语义关系。

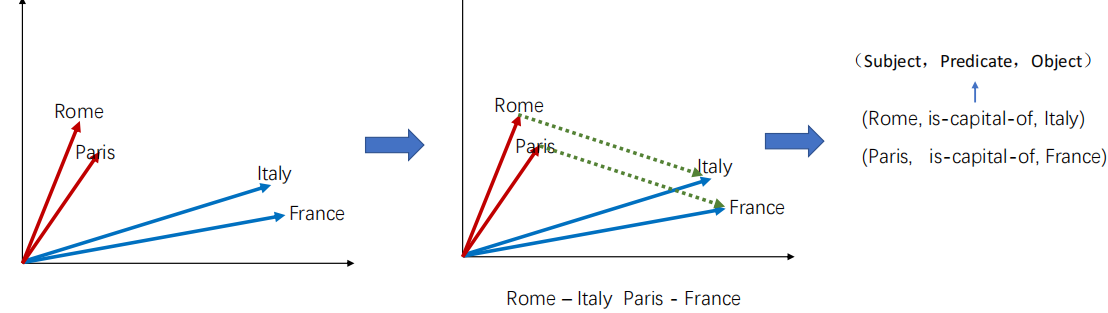
2. 核心嵌入模型
-
TransE(平移模型):
- 核心假设:h + r = t(头实体向量+关系向量=尾实体向量),如“Rome + is-capital-of = Italy”。
- 目标函数:最小化三元组(h,r,t)的向量距离||h+r-t||,通过负样本(替换h或t)优化。
- 优势:简单高效,适配1:1关系;不足:难以处理复杂关系(如1:N)。

-
DistMult(线性变换模型):
- 核心假设:h × Mᵣ = t(头实体向量×关系矩阵=尾实体向量)。
- 目标函数:最大化h×Mᵣ×tᵀ的得分,适配对称关系。
- 优势:处理复杂关系能力优于TransE;不足:仅支持对称关系,表达局限。

TransE模型
优化逻辑,用于学习实体和关系的向量表示,让语义关系在向量空间中可量化计算。以下是详细拆解:
一、三元组得分函数(目标函数)
公式:fr(h,t)=∥h+r−t∥L1/L2\boxed{f_r(h,t) = \| \mathbf{h} + \mathbf{r} - \mathbf{t} \|_{L_1/L_2}}fr(h,t)=∥h+r−t∥L1/L2
- 含义:将头实体hhh、关系rrr、**尾实体ttt**映射为低维向量h,r,t∈Rd\mathbf{h}, \mathbf{r}, \mathbf{t} \in \mathbb{R}^dh,r,t∈Rd(ddd是向量维度),通过向量运算衡量三元组的“合理性”。
- 直观理解:希望“头实体向量 + 关系向量”尽可能接近“尾实体向量”,因此用L1L_1L1或L2L_2L2范数(距离)量化这种接近程度——范数越小,三元组越合理。
二、损失函数(模型优化目标)
公式:L=∑(h,r,t)∈S∑(h′,r,t′)∈S′max(0,fr(h,t)+γ−fr(h′,t′))\boxed{L = \sum_{(h,r,t) \in S} \sum_{(h',r,t') \in S'} \max\left(0, f_r(h,t) + \gamma - f_r(h',t')\right)}L=(h,r,t)∈S∑(h′,r,t′)∈S′∑max(0,fr(h,t)+γ−fr(h′,t′))
- 符号定义:
- SSS:正样本集合(知识图谱中真实存在的三元组,如“小明-朋友-小红”)。
- S′S'S′:负样本集合(通过“随机替换头实体hhh或尾实体ttt”构造的假三元组,如“小张-朋友-小红”,假设真实中不存在该关系)。
- γ\gammaγ:边际(Margin),是预设的正数,用于保证“正样本得分比负样本得分小至少γ\gammaγ”。
- 损失逻辑:采用边际排序损失(Margin Ranking Loss),强制模型学习“正样本的合理性得分远小于负样本”。若fr(h,t)+γ−fr(h′,t′)>0f_r(h,t) + \gamma - f_r(h',t') > 0fr(h,t)+γ−fr(h′,t′)>0,说明正样本和负样本的得分差距不足γ\gammaγ,模型产生损失,需更新实体和关系的向量以缩小该差距。

三、负样本构造
方法:随机替换头实体hhh或尾实体ttt。
- 示例:对于正三元组(h,r,t)=(小明,朋友,小红)(h, r, t) = (\text{小明}, \text{朋友}, \text{小红})(h,r,t)=(小明,朋友,小红),可替换头实体得到负样本(小张,朋友,小红)(\text{小张}, \text{朋友}, \text{小红})(小张,朋友,小红),或替换尾实体得到(小明,朋友,小李)(\text{小明}, \text{朋友}, \text{小李})(小明,朋友,小李)(假设这些三元组在真实图谱中不存在)。
核心作用
通过上述优化过程,TransE能学到蕴含语义的实体和关系向量:比如“父亲”的向量≈“母亲”的向量 + “配偶”的向量(因为“父亲=母亲的配偶”),从而支持知识图谱的补全、关系推理等任务。
3. 嵌入模型的应用
- 推理任务:尾实体预测(h,r,?)、头实体预测(?,r,t),通过向量相似度排序得到结果。
- 其他价值:支持多模态融合(语言、图像、图谱向量统一),适配神经网络下游任务。
4. 主流嵌入模型对比
核心差异体现在建模原理、复杂度、适配场景,如Trans系列侧重平移,Rescal/DistMult侧重线性变换,HolE兼顾两者优势但复杂度高;TransE适合简单图谱,TransR/TransD适合多关系复杂图谱。
5. 主流知识图谱表示方法对比表
| 表示方法类别 | 具体方法 | 核心思想 | 表示形式(核心公式/逻辑) | 核心优势 | 主要不足 | 适用场景 |
|---|---|---|---|---|---|---|
| 传统本体表示 | OWL(Web Ontology Language) | 基于逻辑规则,通过类、属性、公理定义概念及语义关系 | 无数学公式,核心是“类-属性-个体-公理”的逻辑框架(如子类关系、等价公理、属性约束) | 语义表达精准,支持严格逻辑推理,可解释性强 | 不支持数值计算,难以适配深度学习模型 | 本体构建、语义检索、规则型推理(如学术图谱、行业标准图谱) |
| 经典平移类嵌入 | TransE | 将关系视为“头实体向量到尾实体向量的平移”,满足 h+r≈t\mathbf{h} + \mathbf{r} \approx \mathbf{t}h+r≈t | 得分函数:fr(h,t)=∣h+r−t∣L1/L2f_r(h,t) = | \mathbf{h} + \mathbf{r} - \mathbf{t} |_{L_1/L_2}fr(h,t)=∣h+r−t∣L1/L2 | 模型简单高效,训练速度快,适配简单关系 | 难以处理一对多/多对一/多对多关系(如“属于”“合作”) | 简单关系为主的图谱(如一对一属性关联、基础分类关系) |
| 经典平移类嵌入 | TransH | 为每个关系定义专属超平面,实体向量投影到超平面后再进行平移运算 | 投影向量:h⊥=h−wrThwr\mathbf{h}_\perp = \mathbf{h} - \mathbf{w}_r^T\mathbf{h}\mathbf{w}_rh⊥=h−wrThwr(wr\mathbf{w}_rwr为超平面法向量),得分函数同TransE | 解决TransE的复杂关系适配问题 | 未区分实体和关系的语义空间,表达能力有限 | 含一对多/多对一关系的图谱(如“作者-发表-论文”) |
| 经典平移类嵌入 | TransR | 为实体和关系分别构建独立空间,实体向量先映射到关系空间再进行平移 | 空间映射:hr=Mrh\mathbf{h}_r = \mathbf{M}_r \mathbf{h}hr=Mrh(Mr\mathbf{M}_rMr为映射矩阵),得分函数同TransE | 区分实体/关系空间,复杂关系表达能力强 | 模型复杂度高,训练参数多,计算成本大 | 复杂关系密集的图谱(如社交网络、商业合作图谱) |
| 语义匹配类嵌入 | DistMult | 将关系视为“实体向量的双边乘法映射”,通过矩阵乘法建模语义匹配度 | 得分函数:fr(h,t)=hTdiag(r)tf_r(h,t) = \mathbf{h}^T \text{diag}(\mathbf{r}) \mathbf{t}fr(h,t)=hTdiag(r)t(diag(r)\text{diag}(\mathbf{r})diag(r)为关系向量对角矩阵) | 模型简洁,适配对称关系,训练效率高 | 仅支持对称关系,无法表达反对称关系(如“父子”) | 对称关系为主的图谱(如“朋友”“同事”“合作”关系) |
| 语义匹配类嵌入 | ComplEx | 引入复数空间,利用复数乘法的共轭特性,同时适配对称和反对称关系 | 得分函数:fr(h,t)=Re(hTdiag(r)t‾)f_r(h,t) = \text{Re}(\mathbf{h}^T \text{diag}(\mathbf{r}) \overline{\mathbf{t}})fr(h,t)=Re(hTdiag(r)t)(t‾\overline{\mathbf{t}}t为尾实体向量共轭) | 兼容对称/反对称关系,表达能力强 | 复数运算增加轻微计算成本 | 混合关系类型的通用图谱(如综合型知识图谱、多领域融合图谱) |
| 深度学习增强嵌入 | ConvE | 采用卷积神经网络(CNN)提取实体-关系的局部交互特征,建模语义匹配 | 特征拼接:将h\mathbf{h}h和r\mathbf{r}rreshape后拼接,通过CNN提取特征,最终输出匹配得分 | 捕捉局部语义交互,泛化能力强 | 模型结构复杂,解释性弱于平移类模型 | 大规模复杂图谱、需要深度语义挖掘的场景(如推荐系统、问答系统) |
- 核心区分维度:传统本体表示(逻辑型)vs 嵌入表示(数值型),前者侧重“语义严谨性”,后者侧重“数值可计算性”。
- 选择逻辑:简单场景优先TransE/DistMult,复杂关系优先TransR/ComplEx,需要逻辑推理优先OWL,深度学习场景优先ConvE。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)