同样是等待线程,为什么高手都用 join () 而不是 sleep ()?
文章摘要: Thread.join()是Java线程同步的核心方法,用于让调用线程等待目标线程执行完毕。其三种重载方法支持无限等待或超时控制,底层通过synchronized+wait()/notify()实现。与Thread.sleep()不同,join()会释放锁资源,适用于线程顺序执行、结果汇总等场景。关键区别在于:sleep()是单纯延时(不释放锁),而join()是线程间同步(释放锁)。
一、join () 核心作用:让 “调用线程” 等待 “被调用线程” 结束
join() 是 Thread 类的实例方法,核心功能是:让当前正在执行的线程(调用线程)暂停执行,等待目标线程(调用线程调用 join() 的线程)执行完毕后,再继续往下执行。
举个生活化的例子:
- 线程 A(比如主线程
main)调用线程 B 的B.join(),相当于 “线程 A 站在原地等线程 B 做完所有事,B 结束后 A 才继续走”。
关键结论:
- 谁调用
join()?→ 目标线程(比如threadB) - 谁等待?→ 调用
join()的那个线程(比如main线程) - 等待到什么时候?→ 目标线程执行完毕(
run()方法执行完)或等待超时。
二、join () 的三种重载方法(JDK 定义)
Thread 类提供了 3 个 join() 重载,覆盖 “无超时等待” 和 “有超时等待” 场景:
| 方法签名 | 作用 | 核心细节 |
|---|---|---|
void join() |
调用线程无限期等待,直到目标线程执行完毕 | 本质是调用 join(0),0 表示 “无超时” |
void join(long millis) |
调用线程等待 最多 millis 毫秒,超时后不再等待 | 若目标线程在超时前结束,调用线程立即恢复;若超时未结束,调用线程直接继续执行 |
void join(long millis, int nanos) |
更精细的超时控制(毫秒 + 纳秒) | 实际中很少用,底层会转换为总毫秒数(nanos ≥ 500000 则进 1 毫秒) |
注意:
- 所有
join()方法都是 同步方法(被synchronized修饰),底层依赖Object的wait()实现等待,而非Thread.sleep()。 - 调用
join()前,目标线程必须已经调用start()启动(若目标线程未启动,join()会直接返回,相当于 “白等”)。
三、join () 的用法示例(从简单到复杂)
通过 3 个示例,逐步理解 join() 的实际作用:
示例 1:无超时 join ()(最常用)
需求:主线程启动子线程后,必须等子线程执行完,再打印 “主线程结束”。
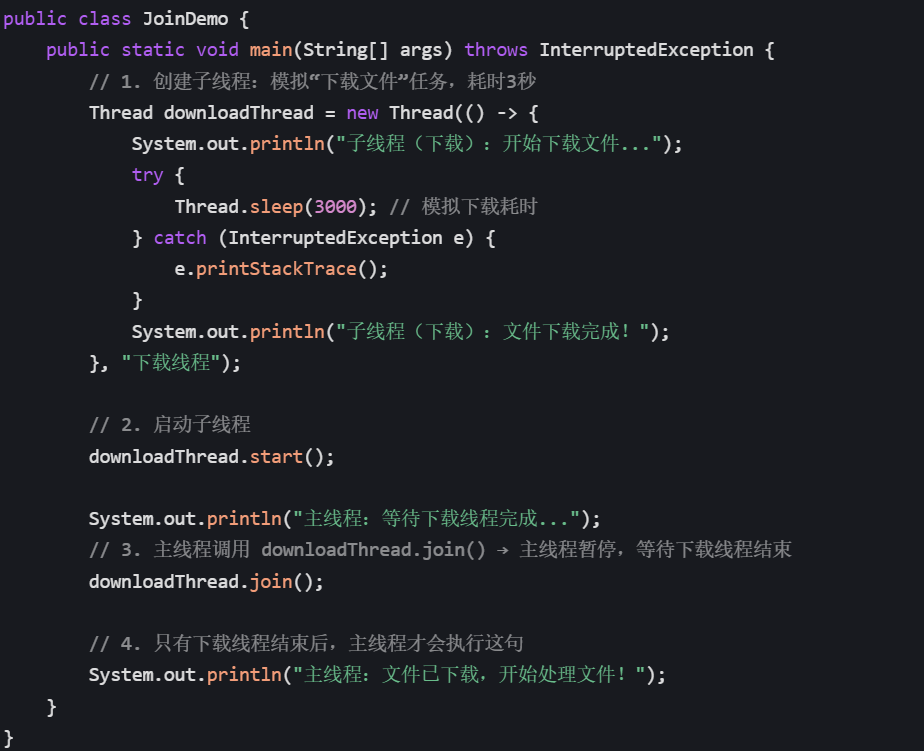

若不调用 join () 的执行结果(顺序混乱):
主线程不会等待,会直接执行最后一句,结果可能是:

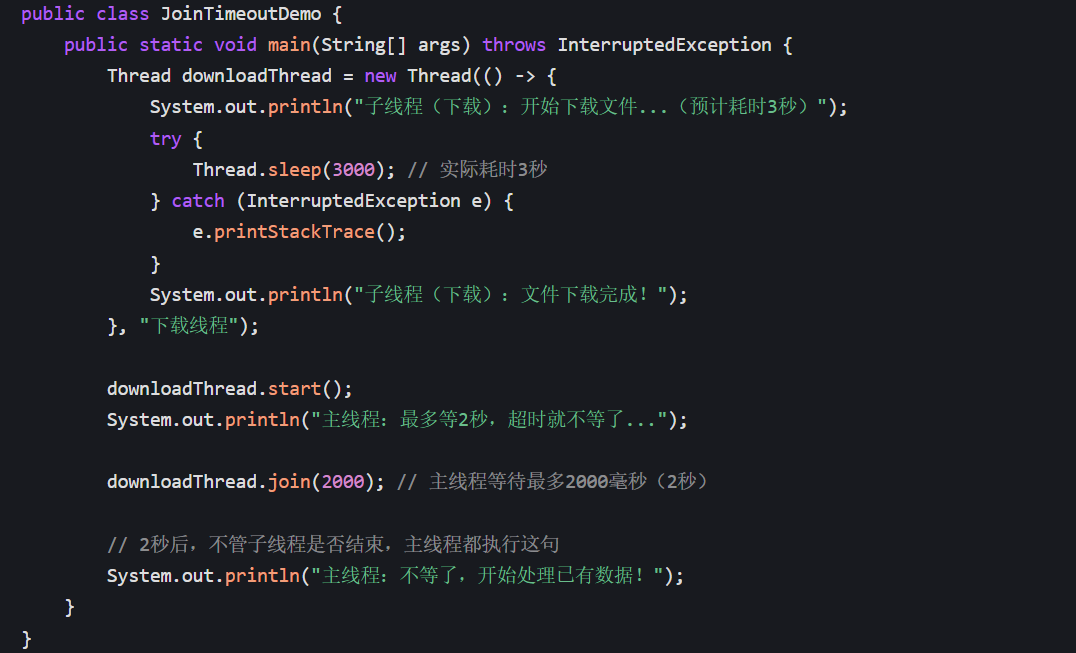
示例 2:带超时的 join (long millis)
需求:主线程最多等子线程 2 秒,超时后不管子线程是否结束,主线程都继续执行。

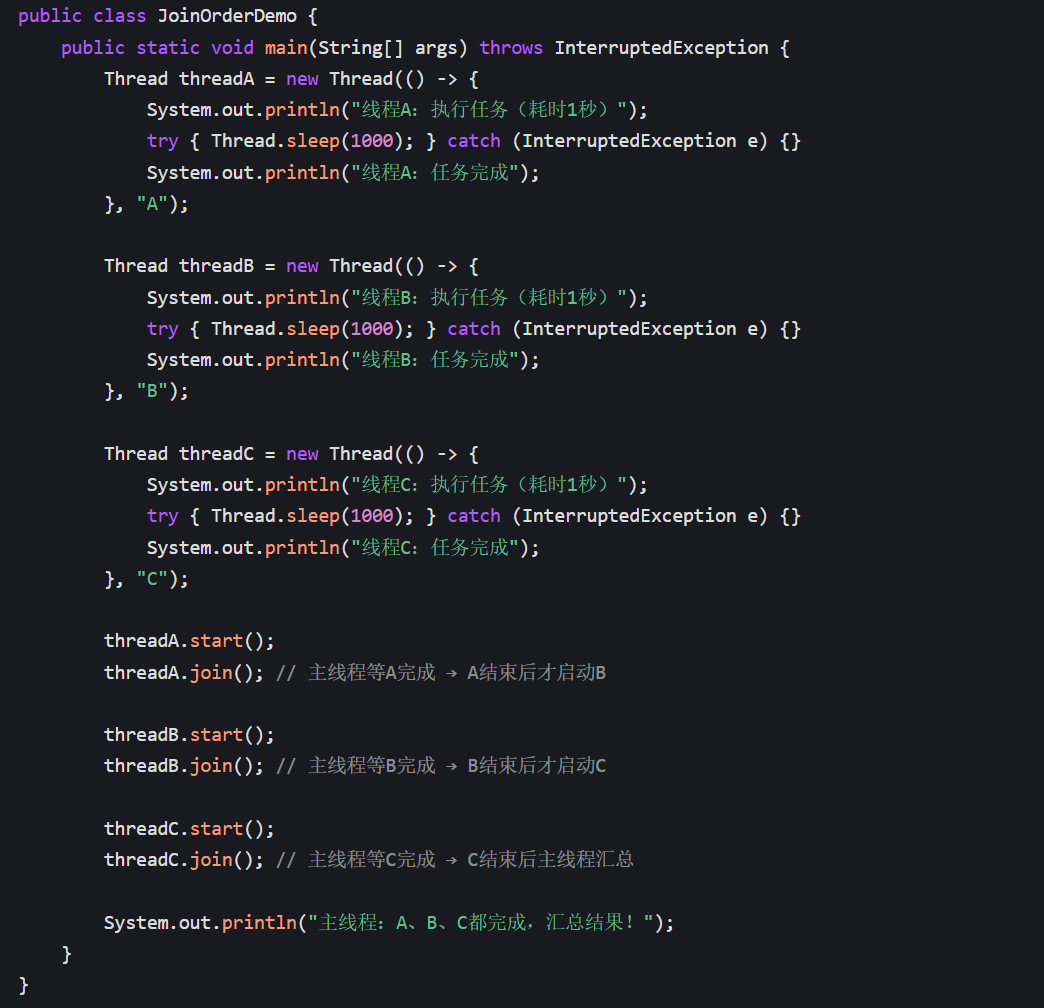
示例 3:多个线程的 join () 顺序
需求:主线程启动线程 A、B、C,要求 A 完成后执行 B,B 完成后执行 C,最后主线程汇总。

四、join () 的底层原理(源码级拆解)
要理解 join() 为什么能让调用线程等待,核心看其源码实现(JDK 8 为例):
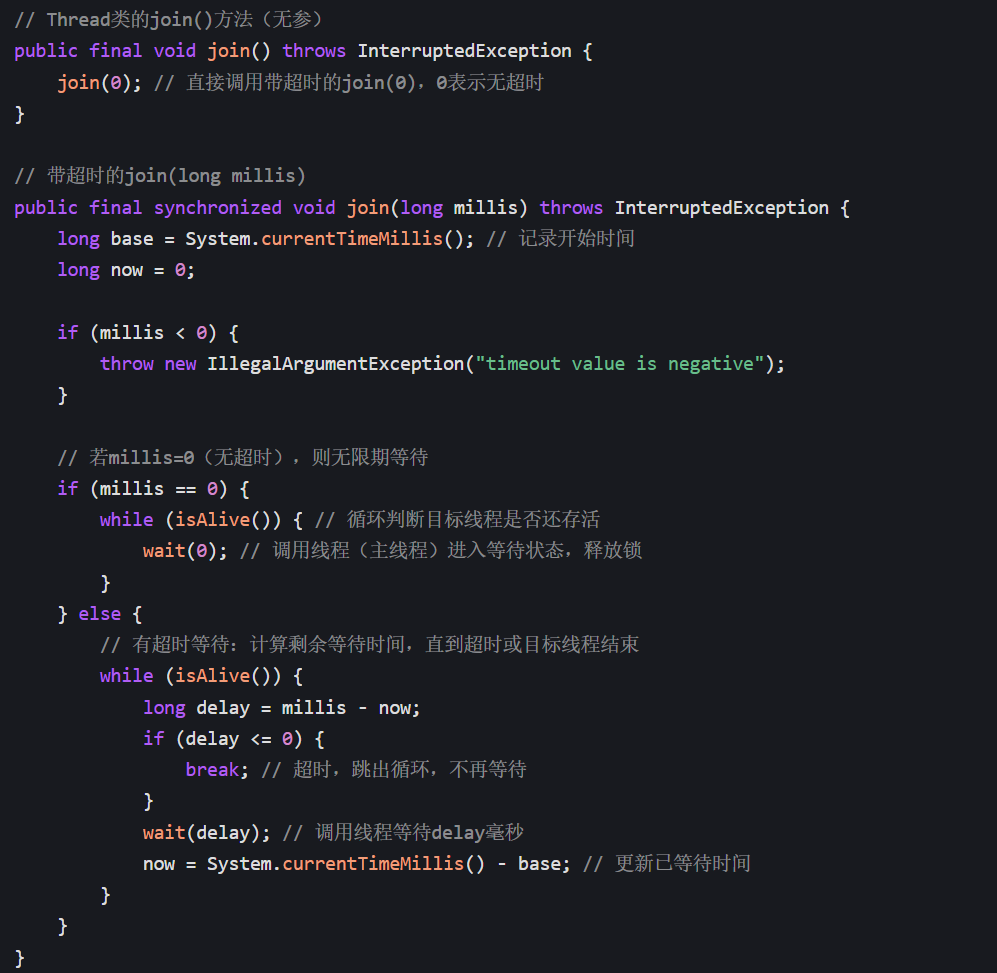
关键原理拆解:
synchronized修饰:join()是同步方法,锁对象是 目标线程实例(比如downloadThread)。调用downloadThread.join()时,调用线程(主线程)会先获取downloadThread的锁,才能进入方法体。isAlive()判断:循环检查目标线程是否还存活(run()方法是否执行完)。只要目标线程存活,调用线程就继续等待。wait()阻塞:调用线程(主线程)执行wait(0)或wait(delay),会释放downloadThread的锁,并进入 等待队列(阻塞状态)。- 唤醒机制:当目标线程执行完毕(
run()结束),JVM 会自动调用目标线程的notifyAll()方法,唤醒所有等待在该线程实例上的线程(即之前调用join()的线程),让其继续执行。

五、join () 与 InterruptedException(异常处理)
join() 方法声明抛出 InterruptedException,这和我们上一轮讲的 interrupt() 机制直接相关:
核心场景:
当 调用线程(比如主线程)正在等待 join() 时,如果其他线程调用了该调用线程的 interrupt() 方法,那么调用线程会从 wait() 阻塞中被唤醒,并抛出 InterruptedException,同时清除中断标志位。
示例:等待 join () 时被中断
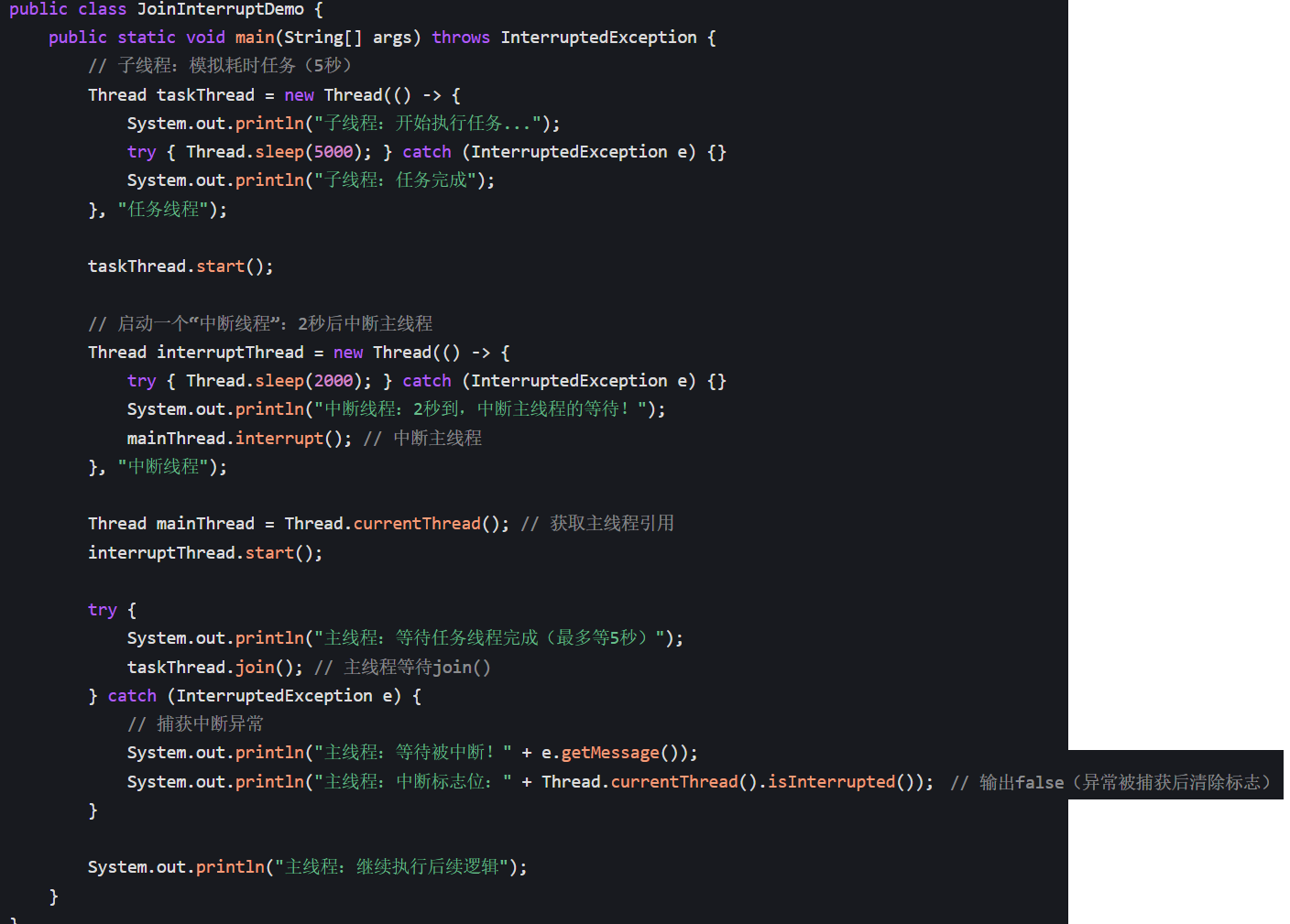

关键结论:
join()的中断是 “调用线程被中断”,而非目标线程被中断。- 捕获
InterruptedException后,中断标志位会被清除(所以示例中isInterrupted()返回false)。 - 异常处理逻辑由开发者决定:可以选择 “继续等待”“放弃等待” 或 “终止当前线程”。
六、join () 的常见使用场景
- 主线程等待子线程汇总结果:比如主线程启动多个子线程并行计算,需等待所有子线程计算完成后,汇总结果(类似 “分治编程”)。
- 保证线程执行顺序:比如必须先执行 “数据加载线程”,再执行 “数据处理线程”,最后执行 “数据存储线程”,通过
join()控制顺序。 - 超时等待避免无限阻塞:使用
join(long millis)防止目标线程卡死导致调用线程无限等待(比如下载文件时,最多等 10 秒,超时则提示失败)。
七、join () 的常见误区
1.调用未启动的线程的 join ():如果目标线程未调用 start(),isAlive() 会返回 false,join() 会直接返回,相当于 “没等”。

2.混淆 “调用线程” 和 “目标线程”:记住:A.join() 是 “调用 A.join() 的线程” 等待 “A 线 程”, 而非 “A 线程等待其他线程”。
3.join () 导致的死锁:如果两个线程互相调用对方的 join(),会导致死锁(比如线程 A 调用 B.join(),线程 B 调用 A.join(),两者都等待对方结束,永远阻塞)。
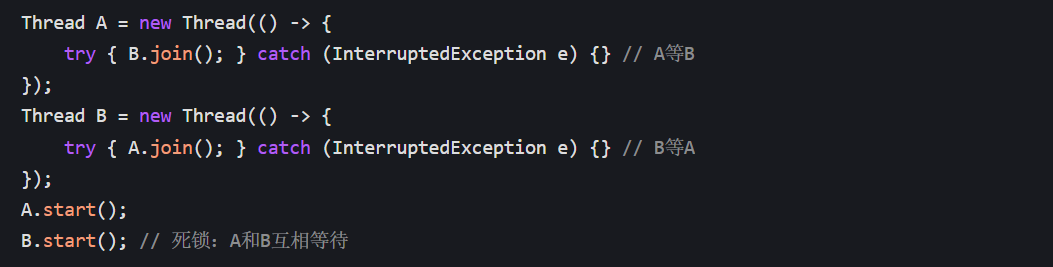
总结
join() 的核心是 “线程间的等待同步”,底层依赖 synchronized + wait() + notifyAll() 实现,是 Java 中控制线程执行顺序、等待子线程完成的核心方法。
关键要点:
- 谁调用
join()→ 目标线程;谁等待 → 调用线程。 - 无参
join()无限期等待,带参join(millis)超时等待。 - 等待期间调用线程会阻塞,且支持被
interrupt()中断(抛出InterruptedException)。 - 实际开发中优先用带超时的
join(),避免无限阻塞;同时注意避免死锁。
八、sleep () vs join () 到底差在哪?
一、核心差异:一张表分清两者本质
| 对比维度 | Thread.sleep(long millis) | Thread.join() / Thread.join(long millis) |
|---|---|---|
| 作用对象 | 让「当前执行线程」暂停(谁调用,谁休眠) | 让「调用线程」等待「目标线程」完成(谁调用 join,谁等目标线程) |
| 锁资源处理 | 不会释放已持有的锁(synchronized/ReentrantLock) | 会释放已持有的锁(等待期间让渡 CPU,不占用锁资源) |
| 唤醒机制 | 休眠时间到自动唤醒,或被 interrupt () 中断唤醒 | 目标线程执行完毕自动唤醒,或等待超时 / 被 interrupt () 中断唤醒 |
| 核心用途 | 简单延时(如轮询间隔、模拟等待) | 线程间同步(确保目标线程完成后,当前线程再继续) |
| 异常处理 | 必须捕获 InterruptedException(受检异常) | 必须捕获 InterruptedException(受检异常) |
| 底层实现 | 基于操作系统的时间片调度(native 方法) | 基于 Object.wait () 实现(依赖对象监视器锁,属于同步机制) |
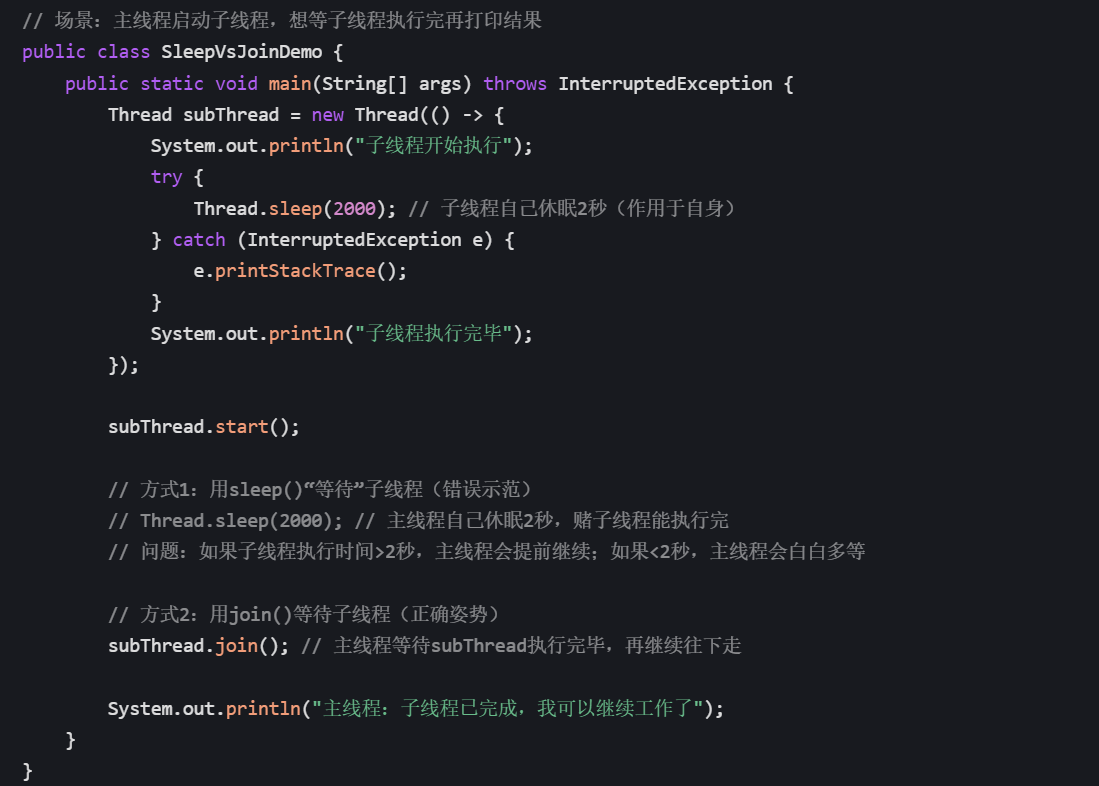
举个直观例子,帮你理解 “作用对象” 的核心区别:
二、底层原理拆解:为什么 join () 能精准同步?
1. Thread.sleep ():简单粗暴的 “时间休眠”
- 调用者:当前执行线程(比如主线程调用 Thread.sleep (1000),就是主线程休眠)。
- 底层逻辑:调用操作系统的
sleep()系统调用,让当前线程放弃 CPU 执行权,进入 “TIMED_WAITING” 状态。 - 关键特性:不释放锁—— 如果当前线程持有 synchronized 锁或 ReentrantLock,休眠期间其他线程无法获取该锁,会导致锁竞争加剧、性能下降。
- 适用场景:仅用于 “固定延时”,比如每隔 1 秒轮询一次接口,或模拟简单的等待场景(不依赖其他线程状态)。
2. Thread.join ():基于等待 / 通知机制的 “精准同步”
- 调用者:需要等待的线程(比如主线程调用 subThread.join (),就是主线程等待 subThread)。
- 底层逻辑:
join()方法内部调用了Object.wait(),核心源码简化如下:
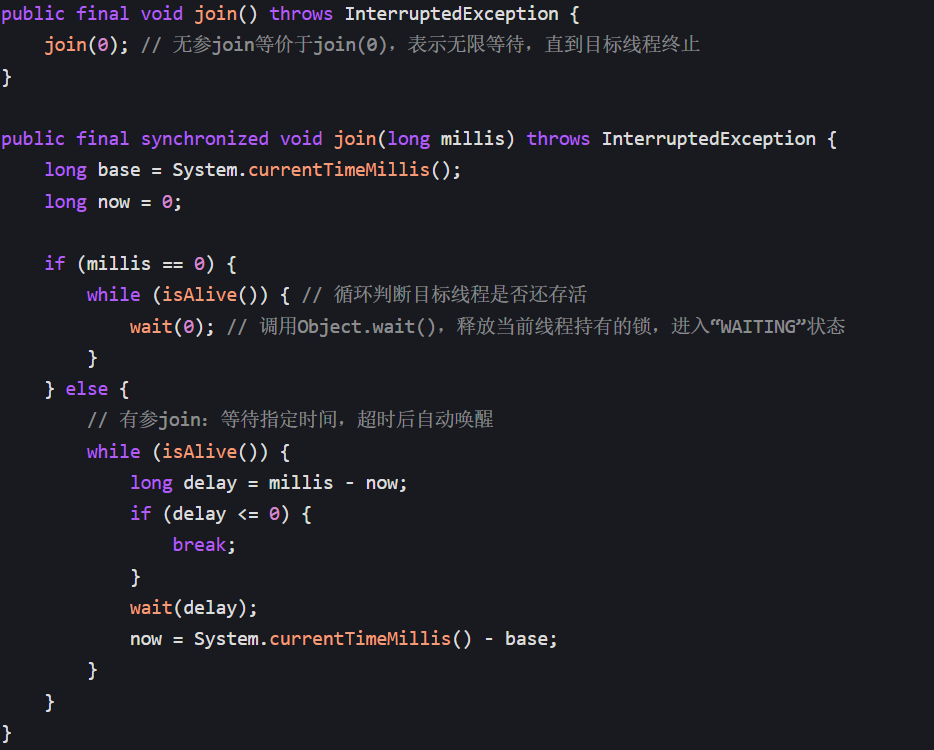
- 当目标线程(subThread)执行完毕时,JVM 会自动调用
targetThread.notifyAll(),唤醒所有等待该线程的线程(主线程),实现 “精准同步”。 - 关键特性:释放锁——join () 方法是 synchronized 修饰的(本质是锁定目标线程对象),调用 wait () 时会释放当前线程持有的所有锁,其他线程可以正常竞争锁资源,性能更优。
- 适用场景:线程间依赖同步,比如主线程必须等子线程计算完结果、写入文件后,再读取文件数据。
三、实战避坑:这 3 个场景绝对不能用 sleep () 替代 join ()
场景 1:多线程顺序执行(必须用 join ())
如果需要线程 A→线程 B→线程 C 依次执行,用 join () 能精准控制,用 sleep () 会因执行时间不确定导致顺序混乱:
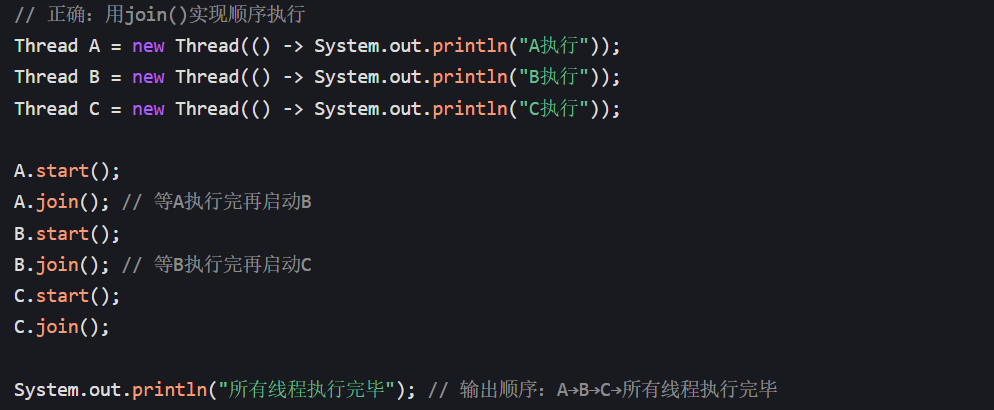
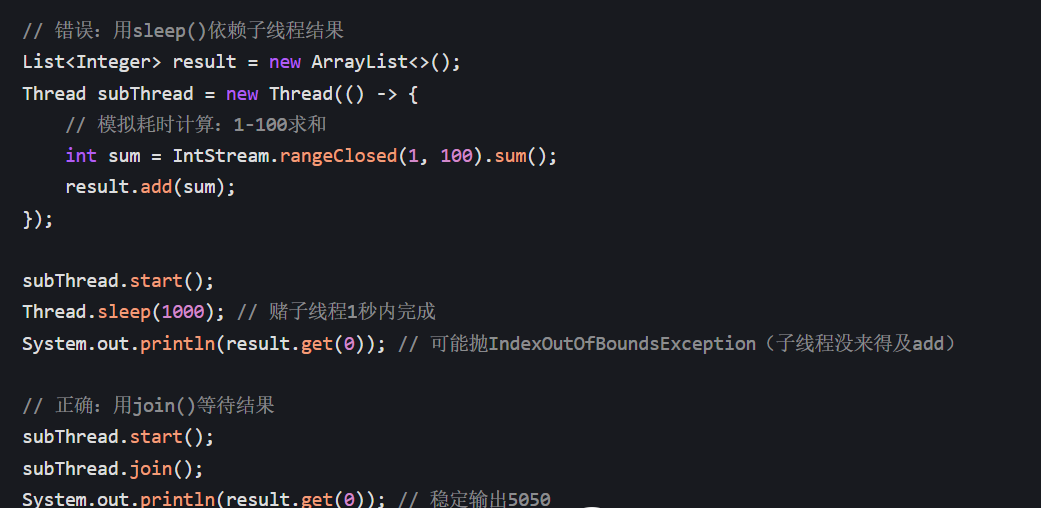
场景 2:依赖子线程结果(必须用 join ())
主线程需要子线程的计算结果(如统计数据、网络请求返回值),用 sleep () 无法保证子线程已完成计算,会导致 “空指针” 或 “数据错误”:
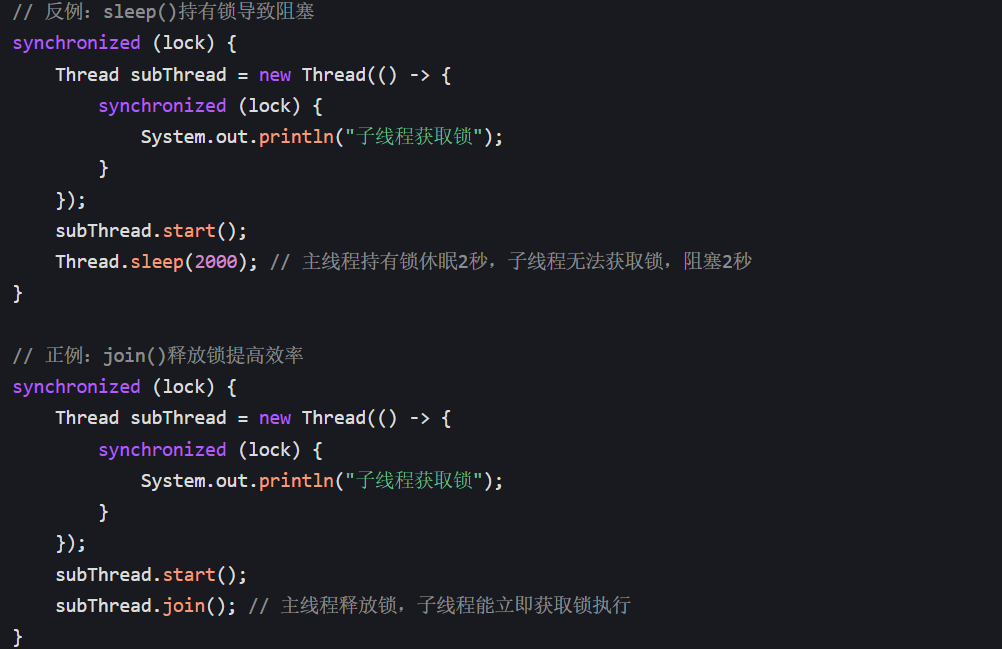
场景 3:避免锁浪费(优先用 join ())
如果等待期间持有锁,用 sleep () 会导致锁长时间占用,其他线程阻塞;用 join () 会释放锁,提高并发效率:
四、终极总结:什么时候用 sleep ()?什么时候用 join ()?
用 Thread.sleep () 的情况:
- 不需要依赖其他线程状态,仅需要 “固定延时”(如轮询、模拟耗时);
- 不持有锁,或持有锁但不影响其他线程(如单线程环境下的延时)。
用 Thread.join () 的情况:
- 需要等待目标线程执行完毕(如顺序执行、依赖子线程结果);
- 等待期间需要释放锁,避免锁竞争(如多线程并发执行时的同步);
- 希望 “精准同步”,不依赖预估的执行时间(如子线程执行时间不确定)。
核心口诀:
- 「延时用 sleep,同步用 join」;
- 「不依赖线程用 sleep,依赖线程用 join」;
- 「持有锁等待用 join,无锁延时用 sleep」。
记住:多线程等待的核心是 “同步” 而非 “延时”,join () 是为同步设计的专用 API,而 sleep () 只是简单的延时工具。用 sleep () 替代 join () 本质是 “赌运气”,看似能运行,实则隐藏着时序 bug,这也是很多开发者写多线程总踩坑的根源!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)