在隐写域中进行图像识别:不恢复隐私图像的深度隐藏与可识别模型解读
【摘要】本研究提出了一种创新的隐私图像保护框架,允许云端识别隐藏图像内容而不需解密原始数据。通过深度隐写技术,系统将隐私图像特征嵌入普通封面图像,生成视觉不可辨的伪装图像(PSNR达41.8dB),识别网络直接对隐藏图像分类,在MNIST测试中保持98.3%准确率。实验显示该方法在CelebA人脸数据集实现91.6%性别识别准确率,且残差分析无法还原隐私内容。这种"识别但不暴露"
论文题目:Hide and Recognize Your Privacy Image
发表期刊:IEEE Transactions on Network Science and Engineering(TNSE),2024年11-12月刊
作者团队:Zhiying Zhu、Hang Zhou、Haoqi Hu、Qingchao Jiang、Zhenxing Qian、Xinpeng Zhang 等
深度学习时代的隐私困境
当我们将医疗影像上传到云端做诊断、在人脸识别系统中验证身份、或将含有敏感信息的图像交给第三方 AI 模型处理时,一个永远绕不开的问题是:模型可能需要访问原始图像,这意味着隐私真实暴露给了云端提供方。
传统的隐私保护策略往往依赖强加密,例如同态加密、安全多方计算等算法,虽然安全性高,但计算成本极高,实际应用中往往会出现分类一次就要数秒甚至几小时的极限延迟。论文中引用的案例显示,使用同态加密进行 MNIST 图像分类,有研究甚至需要接近两小时才能完成一次推理,这显然难以实用。
这篇论文试图回答一个更有意思的问题:
有没有一种方式,既能让云端正确识别你的隐私图像,却永远无法看到图像内容本身?
作者的答案,是一种基于深度隐写(Deep Hiding)的全新思路。
一种新的图像隐私保护范式:隐藏后直接识别
论文提出了一个概念非常巧妙的框架:将隐私图像隐藏在一张不相关的普通图像(如街景、森林、海滩照片)中,然后直接对隐藏后的图像进行识别,而不必恢复隐私图像本身。
整个过程不需要图像解密,也不存在“还原隐私内容”的阶段,因此从传输到推理的全流程,隐私图像始终处于不可见状态。
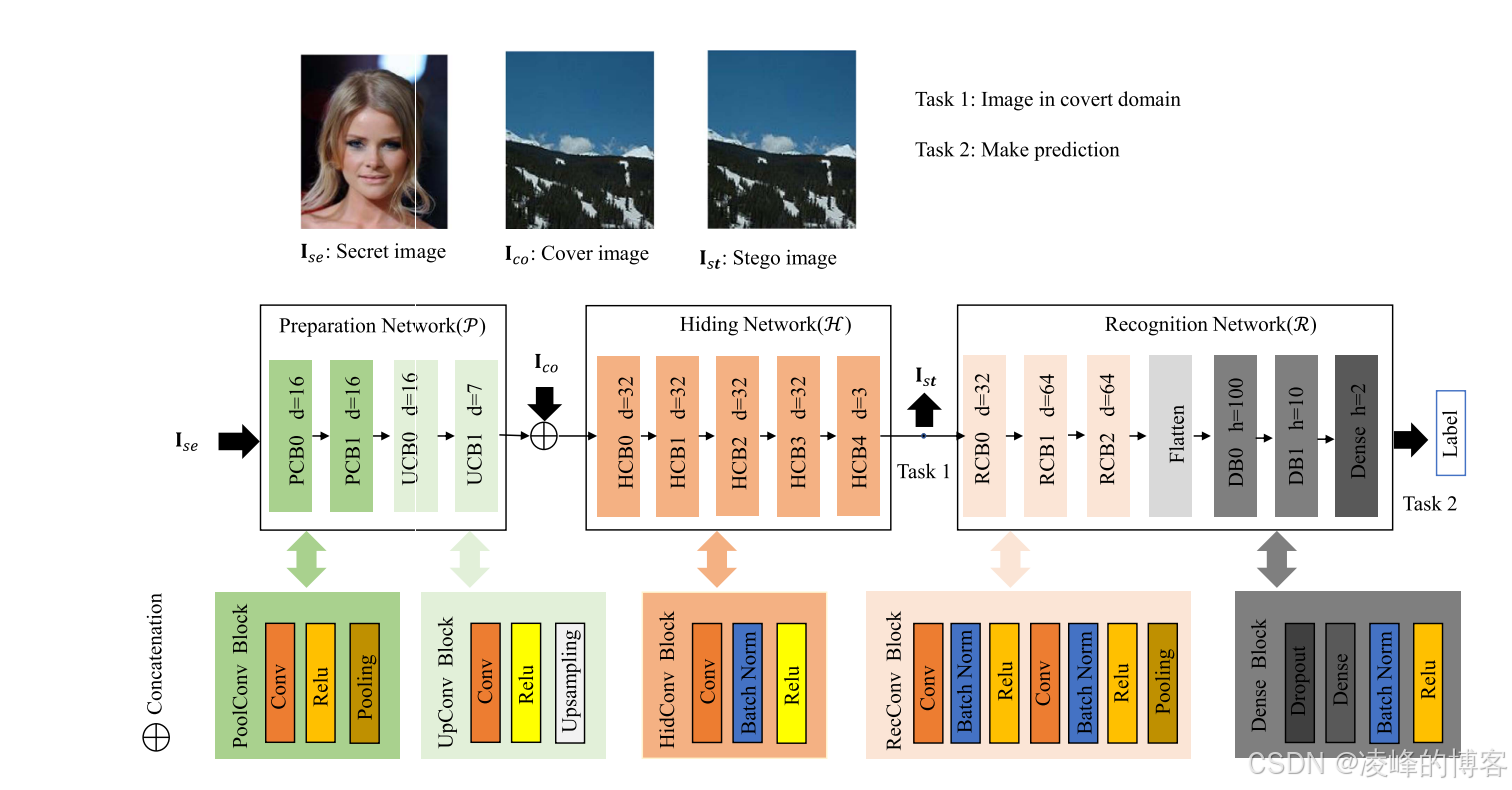
论文中的系统主要由两个神经网络组成:
第一部分是编码器(Encoder),作用类似“隐写者”。它将隐私图像压缩成只包含识别所需的特征,然后嵌入到一个封面图像中,使生成的伪装图像在视觉上几乎与封面一致,因此攻击者即便查看像素差异,也难以理解隐私内容。实验中隐写后的图像 PSNR 最高达到 41.8 dB,SSIM 高达 0.995,这意味着几乎肉眼无法区分隐藏前后的图像
第二部分是识别网络(Recognizer),它并不恢复隐私图像,而是直接基于隐藏图像进行分类。例如在 MNIST 测试中,识别准确率达到 98.3%,比直接对原始图像识别的下降不到 1%
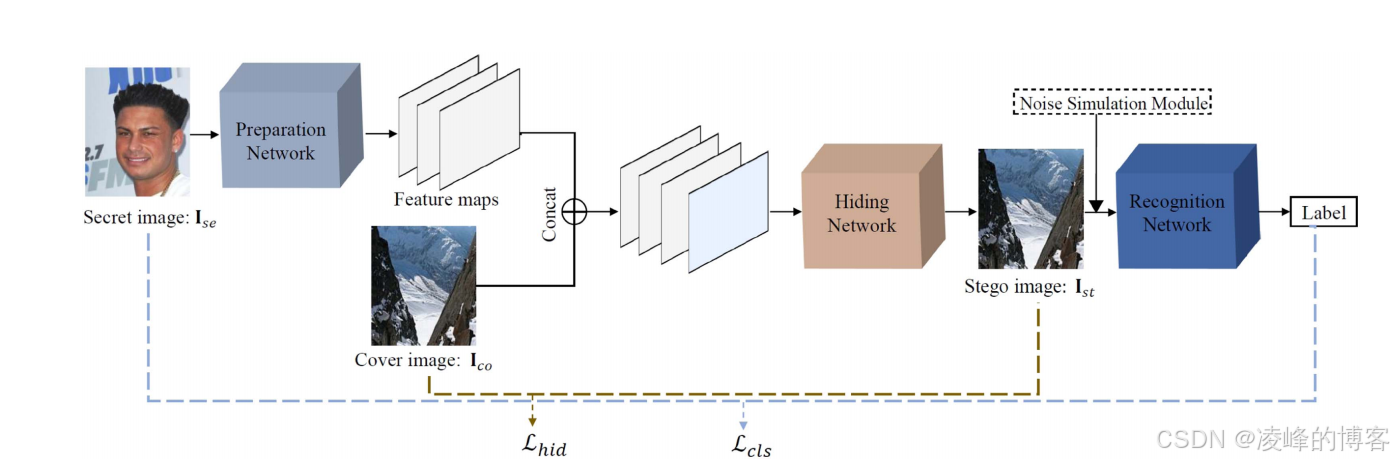
换句话说,它不是隐写 + 解密 + 分类,而是一次性完成:
隐写后的图像 → 直接识别 → 输出结果。
举一个非常形象的例子
假设 Alice 想用在线系统验证自己的身份,但她不希望服务器看到自己的真实照片。她手中有一张自拍,以及一张看似与她隐私无关的封面图像,例如一张城市夜景。
系统编码器将她的自拍特征融入夜景照片,生成一张看起来依旧是夜景、肉眼几乎无法察觉任何差异的图像。Alice 将这张图上传至云端,服务器中的识别网络读取到隐藏的身份特征,判断出这是 Alice,但从头到尾都无法重建她的真实面部。
云端看到的是夜景图,但识别结果仍然有效。
这是论文最核心的贡献之一:
让 AI 模型知道“你是谁”,却不让它“看到你是什么样”。
可解释的安全优势
论文强调了一个非常重要的安全现象:即便攻击者对封面图像与隐写图像做像素级差异放大,仍然难以辨认隐私内容。
研究者特别指出,当不使用特征压缩网络时,这类差异放大可能泄漏隐私,而加入准备网络后残差图中不再可见面部或结构信息。这一点比传统深度隐写模型安全性更高,也为隐私图像在云侧的可信应用提供了实际可能。
实验结果:几乎损失为零的识别能力
在多个数据集测试中,该方法展现了非常稳定的隐写质量与识别性能:
-
在 MNIST 与 CIFAR-10 组合实验中,伪装图像与封面的一致性非常高,而识别准确率达到 98.3%
-
在 CelebA 人脸数据集实验中,隐写后的性别识别准确率达到 91.6%,仍然接近明文识别效果。
作者还将系统与经典深度隐写方法对比,证明其隐私不可见性优势,在残差放大后仍无法观察到面部结构细节。

总结
《Hide and Recognize Your Privacy Image》提出了一种新颖且实际的解决方案,让隐私图像在不暴露内容的前提下被准确识别,为未来的隐私保护型 AI 推理提供了极具价值的方向。它让我们意识到:数据的价值不必依赖于可见性,隐私可以不以暴露为代价。这篇论文不仅解决了现实问题,更为隐私计算的未来提供了一种可被工程化的新思路。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)