昇腾服务器AISBench+GPUStack提升大模型性能测试效率
AISBench与GPUStack协同提升昇腾NPU大模型测试效率 摘要:本文介绍了国产开源软件AISBench(性能测试工具)与GPUStack(模型部署管理工具)在昇腾NPU(910B)平台上的协同使用方法。通过华为Atlas 800IA2服务器(鲲鹏920 CPU/昇腾910B NPU)的实测验证,详细说明了两种工具的集成配置要点:1)在vllm-ascend容器中部署AISBench;2)
概述
AISBench是大模型性能测试的国产开源软件,GPUStack是大模型部署和管理的国产开源软件,两者都支持昇腾NPU卡(如910B),结合起来使用,可以使昇腾NPU卡大模型部署和大模型性能测试的效率倍增。
GPUStack下载地址:
AISBench下载地址:
AI 服务器:华为 Atlas 800I A2 推理服务器
|
组件 |
规格 |
|
CPU |
鲲鹏 920(5250) |
|
NPU |
昇腾 910B4(8X32G) |
|
内存 |
1024GB |
|
硬盘 |
系统盘:450GB |
|
操作系统 |
openEuler 24.03 (LTS-SP1) |
软件安装参考:(包括NPU驱动,FW,CANN,VLLM和GPUSTACK等)
AISBench和GPUStack配合可以提升大模型的部署和性能测试效率,经过验证,对AISBench测试脚本中的模型参数配置部分进行以下修改即可,包括GPUStack的模型权重目录,IP地址,端口,API_KEY,SSL验证等配置。
GPUStack部署vLLM格式模型文件
GPUStack安装好之后,可以直接通过网页下载modelscope.cn网站的vllm格式模型文件,后续的操作以vllm格式模型为例。
注:AISBench支持以vllm或mindie为后端的模型性能测试,暂不支持以llama-box和vox-box为后端的模型性能测试。
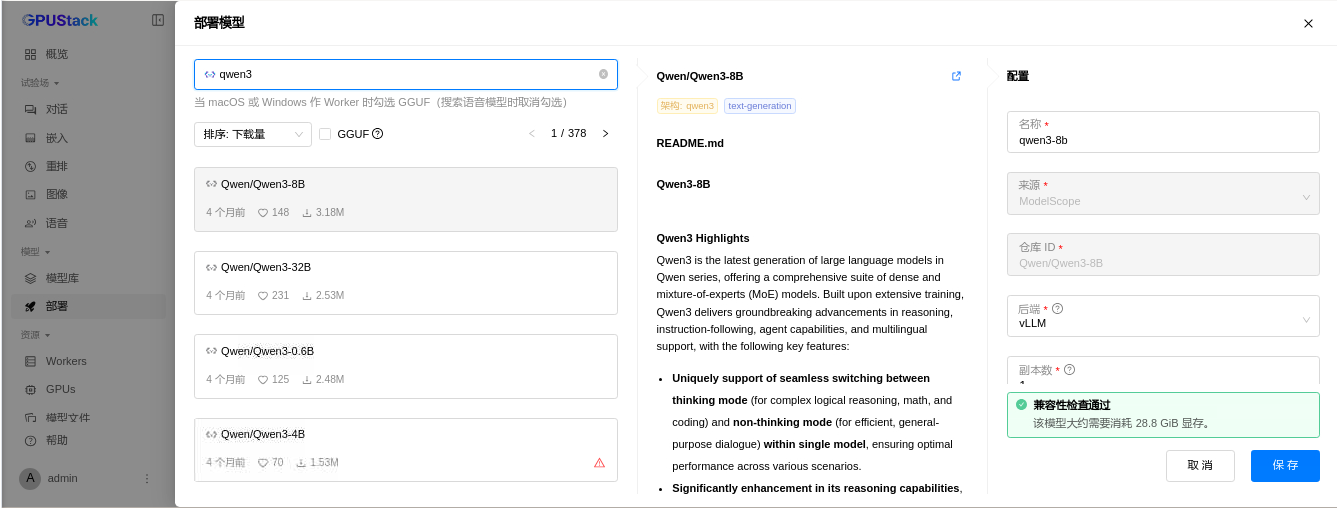
AISBench设置模型部署路径映射
首先部署vllm-ascend容器,安装步骤可以参考
安装完成后,可以通过docker ps查看容器名称,端口和状态等信息

vllm-ascend的docker部署,国内镜像可选用docker.1ms.run
安装脚本如下,增加容器内模型缓存目录/root/.cache映射到宿主机/mnt/data/root/.cache的配置
# Update --device according to your device (Atlas A2: /dev/davinci[0-7] Atlas A3:/dev/davinci[0-15]).
# Update the vllm-ascend image according to your environment.
# Note you should download the weight to /root/.cache in advance.
export IMAGE=quay.io/ascend/vllm-ascend:v0.11.0rc1 #可按docker.1ms.run路径修改
docker run --rm \
--name vllm-ascend \
--shm-size=1g \
--net=host \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /mnt/data/root/.cache:/root/.cache \ #模型缓存目录映射到宿主机3.5T的NVME盘/mnt/data/root目录
-it $IMAGE bash然后在vllm-ascend容器中部署AISBench,具体安装步骤可以参考
https://gitee.com/aisbench/benchmark#-%E5%B7%A5%E5%85%B7%E5%AE%89%E8%A3%85
如下图,AISBench安装在vllm-ascend容器的/home/benchmark目录下
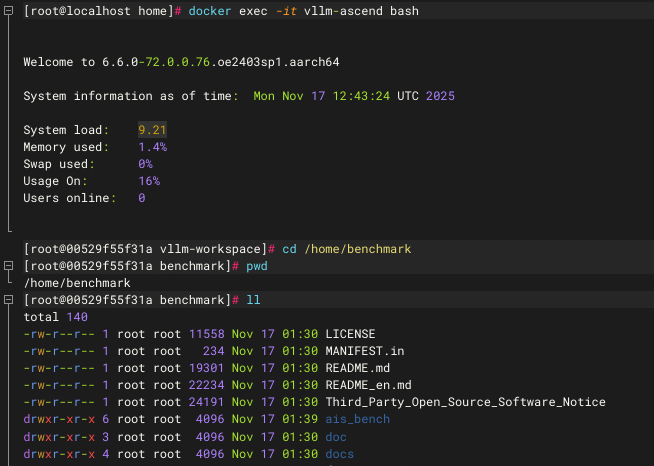
AISBench测试脚本的适配修改
精度测试
修改以下文件(按实际AISBench安装路径,例如/home/benchmark):
/home/benchmark/ais_bench/benchmark/configs/models/vllm_api/vllm_api_general_chat.py
主要修改或增加以下黄色背景内容,根据GPUStack大模型部署的参数进行修改。
from ais_bench.benchmark.models import VLLMCustomAPIChat
models = [
dict(
attr="service",
type=VLLMCustomAPIChat,
abbr='vllm-api-general-chat',
path="", # 指定模型序列化词表文件绝对路径(精度测试场景一般不需要配置)
base_url="172.23.69.222", # 新增参数,为gpustack模型地址
model="Qwen/Qwen3-8B", # 指定服务端已加载模型名称,依据实际VLLM推理服务拉取的模型名称配置(配置成空字符串会自动获取)
api_key="gpustack_fe...9gb" # 新增参数,为gpustack模型秘钥
request_rate = 0, # 请求发送频率,每1/request_rate秒发送1个请求给服务端,小于0.1则一次性发送所有请求
retry = 2, # 每个请求最大重试次数
host_ip = "172.23.69.222", # 指定推理服务的IP
host_port = 80, # 指定推理服务的端口
enable_ssl = False, # 新增参数,gpustack模型地址为http开头
max_out_len = 512, # 推理服务输出的token的最大数量
batch_size=1, # 请求发送的最大并发数
trust_remote_code = True, # gpustack模型远端执行
generation_kwargs = dict( # 模型推理参数,参考VLLM文档配置,AISBench评测工具不做处理,在发送的请求中附带
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
)
)
]
而后执行以下命令进行测试
ais_bench --models vllm_api_general_chat --datasets demo_gsm8k_gen_4_shot_cot_chat_prompt --debug成功调用GPUStack部署的模型,测试执行成功,得到精度87.5的结果:
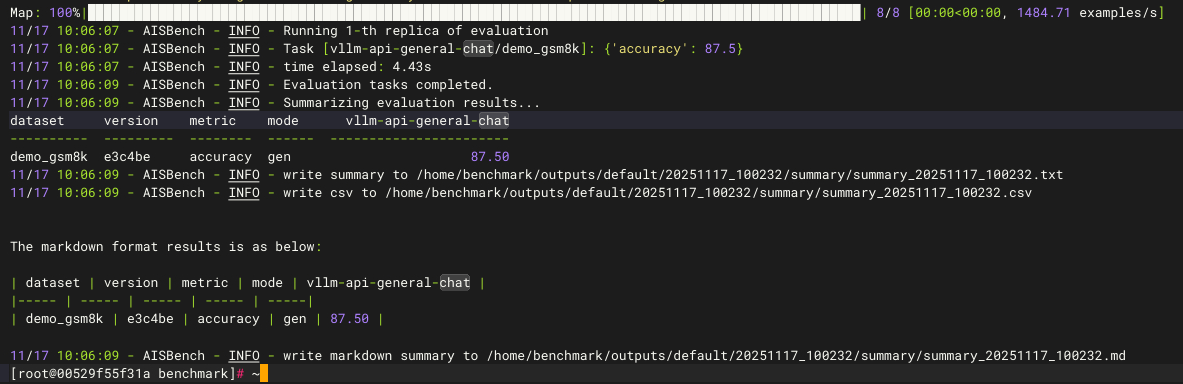
精度测试的更多参考:
https://gitee.com/aisbench/benchmark/blob/master/doc/users_guide/accuracy_benchmark.md
性能测试
性能测试必须要指定GPUStack部署模型的权重参数目录,否则会出现以下错误
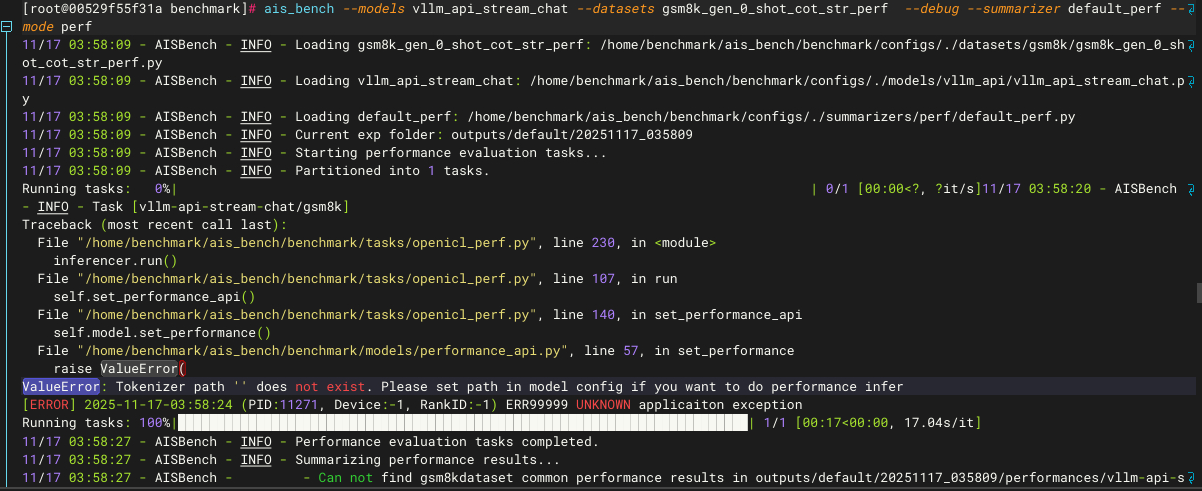
修改以下文件(按实际AISBench安装路径,例如/home/benchmark):
/home/benchmark/ais_bench/benchmark/configs/models/vllm_api/vllm_api_stream_chat.py
主要修改或增加以下黄色背景内容,根据实际GPUStack大模型部署的参数进行修改。
from ais_bench.benchmark.models import VLLMCustomAPIChatStream
from ais_bench.benchmark.utils.model_postprocessors import extract_non_reasoning_contentmodels = [
dict(
attr="service",
type=VLLMCustomAPIChatStream,
abbr='vllm-api-stream-chat',
path="/root/.cache/modelscope/hub/models/Qwen/Qwen3-8B", #根据gpustack模型权重参数目录进行配置
model="Qwen/Qwen3-8B",
api_key="gpustack_fe...9gb" # 新增参数,为gpustack模型秘钥
request_rate = 0,
retry = 2,
host_ip = "172.23.69.222", # 指定推理服务的IP
host_port = 80, # 指定推理服务的端口
enable_ssl = False, # 新增参数,gpustack模型地址为http开头
max_out_len = 512,
batch_size=1,
trust_remote_code = True, # gpustack模型远端执行
generation_kwargs = dict(
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
),
pred_postprocessor=dict(type=extract_non_reasoning_content)
)
]
而后执行以下命令进行测试
ais_bench --models vllm_api_general_chat --datasets demo_gsm8k_gen_4_shot_cot_chat_prompt --summarizer default_perf --mode perf成功调用GPUStack部署的模型,测试执行成功,得到E2EL、TTFT、TPOT、Token Throughput等结果:
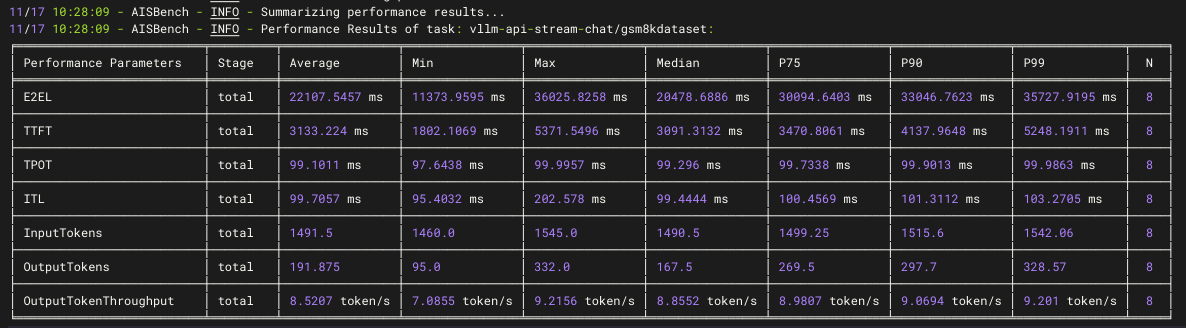
性能测试的更多参考:
https://gitee.com/aisbench/benchmark/blob/master/doc/users_guide/performance_benchmark.md

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)