执掌算力“缰绳”:深入解析 CANN ACL 接口的异步机制与资源调度实践!
本文深入解析华为CANN架构中的AscendCL(ACL)接口,探讨如何通过Device、Context、Stream和Event四大核心组件实现高效的异步任务调度。在AI开发面临"算力调度"挑战的背景下,ACL为开发者提供了直接操控NPU硬件资源的能力,突破了上层框架的局限性。文章首先介绍CANN架构的分层设计和ACL的定位,强调其作为统一API接口的重要性;随后重点剖析资源
摘要:
在人工智能浪潮席卷千行百业的今天,昇腾(Ascend) NPU 提供了澎湃的硬件算力,而 CANN (Compute Architecture for Neural Networks) 则是释放这股力量的“软件灵魂”。然而,对于许多 AI 开发者而言,如何从应用层精细化地“调度”这些算力,实现任务的极致并行与高效执行,始终是一个“幸福的烦恼”。
本文将聚焦于 CANN 架构的“中枢神经”——AscendCL (ACL) 接口,深入探析其在资源管理与异步调度方面的核心机制。笔者(我)将结合在真实昇腾平台上的开发实践,重点解析 ACL 如何通过 Device、Context、Stream 与 Event 这“四驾马车”构建起高效的异步执行流水线,分享如何利用 ACL 简化 AI 开发,并最终实现硬件潜能的深度释放。
引言:AI 开发的“最后一公里”挑战
“我们不缺算力,我们缺的是将算力‘喂饱’的手段。”
这句话道出了当前许多 AI 工程师的心声。当我们拿到一块性能强劲的 NPU 硬件(如昇腾 Atlas 系列加速卡)时,我们的第一反应通常是依赖 PyTorch、TensorFlow 这样的上层框架。框架为我们屏蔽了底层的复杂性,让我们得以“一行代码跑模型”。
但“黑盒”的B面,是“失控”。
当我们需要在复杂的业务场景(如视频结构化、多路并发推理)中实现极致的低延迟和高吞吐时;当框架的默认执行机制成为瓶颈,我们希望手动编排计算与数据拷贝的顺序时;或者当我们需要开发一个脱离 Python 依赖、轻量级的 C++ 推理服务时… 我们会发现,上层框架的“便利”反而成了“枷锁”。
我们迫切需要一种方式,能让我们绕过框架,直接与硬件的“执行层”对话。我们需要精细化的控制权,需要知道:
- 我的 NPU 设备上有哪些资源?
- 我如何创建多个“任务队列”,让数据预处理和模型计算真正“并行”起来?
- 我如何确保“数据拷贝(H2D)”完成后,“计算任务”才被触发?
这,就是 CANN 架构为我们提供的“答案”:AscendCL (ACL) 接口。
ACL 并非一套普通的 API,它是 CANN 面向应用开发者的统一“桥梁”。它为我们提供了从硬件资源管理(Device、Context)到内存控制(Malloc、Memcpy),再到核心的任务调度(Stream、Event)的全套能力。
本文的目标,就是撕开 ACL 的面纱。我将不再停留在“调用 API”的表面,而是尝试结合我在昇腾平台上的第一手实践经验,深入探析 ACL 资源调度的“为什么”和“怎么做”。我将通过具体的代码示例和平台截图,展示 ACL 如何帮助开发者从一个被动的“框架使用者”,转变为一个主动的“算力调度者”。
简单来说,就是同一的API框架,实现对所有资源的调用。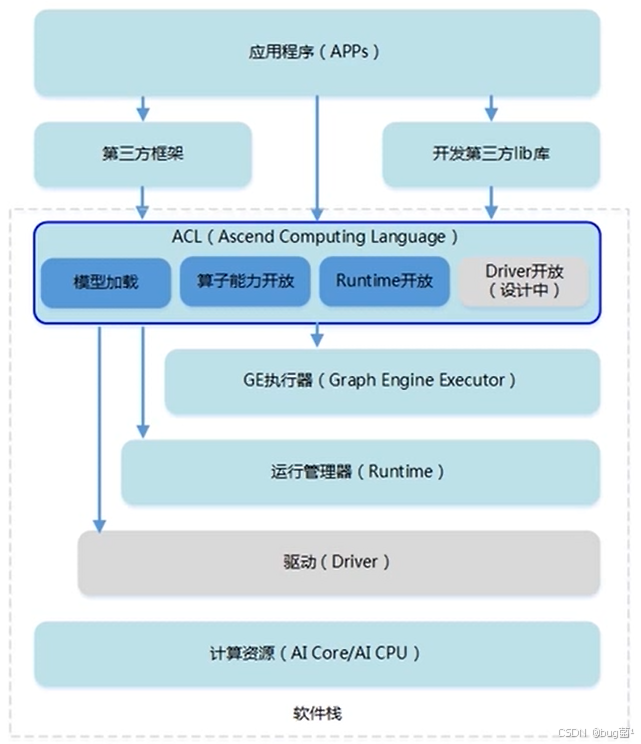
第一章:CANN 架构鸟瞰与 ACL 的“中枢”定位
要理解 ACL,必先理解 CANN。
CANN 作为华为打造的端云一致异构计算架构,其核心价值在于“承上启下”。它需要高效承接上层框架(如 PyTorch、TensorFlow)的计算图,并提供灵活的接口(ACL)供开发者构建自定义应用;同时,它需要将这些计算需求精准“翻译”为 NPU 上的任务,并充分调动 AI Core、Vector Core 等计算单元。
1.1 CANN 软件栈概览
CANN 的软件栈层次清晰,每一层各司其职。
从CANN官方架构图中,我们可以清晰地看到 CANN 的分层设计(自上而下):
- 应用/框架层 (Application/Framework): 这是我们最熟悉的,如 MindSpore、Ascend-PyTorch、Ascend-TensorFlow 等。
- 图引擎 (Graph Engine, GE): 负责接收上层框架的计算图,进行图的解析、优化(如算子融合)、编译,并生成 NPU 可执行的
om离线模型。 - AscendCL (ACL) 接口: (本文的主角) 它位于图引擎之下,Runtime 之上。它是一个 C/C++ API 库,是上层应用与底层硬件交互的统一入口。
- Runtime (RT) & 驱动层 (Driver): 负责核心的执行管理、内存管理、Stream 管理,并最终驱动 NPU 硬件。
1.2 ACL:为何是“中枢”?
ACL 的定位非常关键。它扮演了“统一翻译官”和“资源大管家”的双重角色。
- 统一性(“翻译官”): 无论是上层的 PyTorch 还是 TensorFlow,当它们需要 NPU 执行任务时,最终都会(或通过 GE)调用到 ACL 接口。更重要的是,当我们需要开发自定义应用(如 C++ 推理程序)时,我们调用的也是 ACL。它屏蔽了底层硬件的差异,提供了“一套 API,端云一致”的开发体验。
- 控制力(“大管家”): ACL 向开发者暴露了对 NPU 资源(设备、内存、事件)的直接控制权。它不再像框架那样“大包大揽”,而是让我们能以“指令式”的方式,精细化地告诉 NPU:“第一步做什么,第二步做什么,哪些任务可以一起做”。
对于追求极致性能的开发者而言,ACL 就是我们手中最锋利的“手术刀”。
1.3 CANN 为开发者提供的核心价值
基于 ACL 这一“中枢”,CANN 架构为我们(应用/算子开发者)提供了显而易见的价值:
- 简化的 AI 开发: ACL 提供了模型加载(
aclmdlLoadFromFile)、执行(aclmdlExecute)、内存管理(aclrtMalloc)等一系列“开箱即用”的 API。我们甚至不需要关心图编译的细节,就可以快速构建一个高性能的 AI 应用。 - 极致的计算效率: 这也是本文的重点。ACL 提供了异步执行模型(Stream/Event),允许我们将数据拷贝(H2D/D2H)、算子计算等任务分解,并编排到不同的“任务队列”中,实现 CPU、NPU 和数据总线(PCIe)的最大化并行,从而“榨干”硬件性能。
- 开放的生态: 除了使用 ACL 跑模型(ACLNN 算子库),CANN 还支持自定义算子开发(TBE、AI Core),这为开发者提供了无限的扩展可能。
在接下来的章节中,我们将彻底钻入 ACL 的内部,从最基础的资源管理开始,一步步揭开其高效调度的秘密。
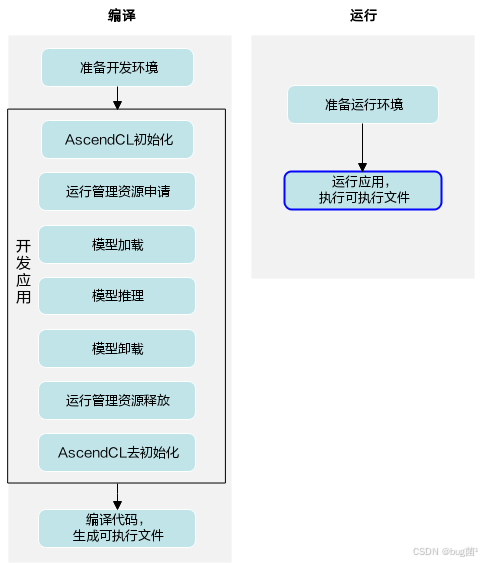
如何开始准备?具体可先了解如下开发流程:
第二章:ACL 资源管理的“三驾马车”:Device, Context, Stream
在动手写 ACL 代码之前,我们必须先理解三个最核心、也是最容易混淆的概念:Device (设备)、Context (上下文) 和 Stream (流)。
我个人的理解是,它们三者构成了一种“俄罗斯套娃”式的管理关系:Device 包含了 Context,Context 包含了 Stream。
2.1 Device 管理:一切的起点
Device,即物理 NPU 设备。在多卡服务器上,我们首先要做的就是“选卡”。
在昇腾平台上,我们通常使用 npu-smi info 命令来查看硬件状态。
**模拟终端输出:使用
npu-smi info命令来查看硬件状态。
模拟终端输出:
$ npu-smi info
±------------------------------------------------------------------------------------------------+
| NPU-SMI 23.0
Driver Version: 23.0.3 |
±--------------------------------------------±----------------±------------------------------+
| NPU
e Slot ID Chip Type | Bus-Id | AICore(%) Memory-Usage(MB) |
|=========================+
=+=|
| 0 Atlas 300I Pro 0000:01:00.0 Asc
0P | 0000:01:00.0 | 0% 87 / 16384| 1 Atlas 300I Pro 0000:02:00.0 Ascend 31
000:02:00.0 | 0% 87 / 16384
±--------------------------------------------±----------------±------------------------------+
例如如下:
在 ACL 程序中,我们的“起手式”通常是:
#include "acl/acl.h"
#include "acl/acl_rt.h"
#include <iostream>
int main() {
// 1. ACL 初始化 (程序生命周期中只调用一次)
const char *aclConfigPath = ""; // 使用默认配置
aclError ret = aclInit(aclConfigPath);
if (ret != ACL_ERROR_NONE) {
std::cerr << "ACL init failed, error code = " << ret << std::endl;
return -1;
}
std::cout << "ACL init success." << std::endl;
// 2. 显式选择要操作的物理 NPU 卡
uint32_t deviceId = 0; // 我们选择 0 号卡
ret = aclrtSetDevice(deviceId);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Set device " << deviceId << " failed, error code = " << ret << std::endl;
aclFinalize();
return -1;
}
std::cout << "Set device " << deviceId << " success." << std::endl;
// ... (执行我们的主要逻辑) ...
// 3. 释放 Device 资源
ret = aclrtResetDevice(deviceId);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Reset device failed, error code = " << ret << std::endl;
}
std::cout << "Reset device success." << std::endl;
// 4. ACL 去初始化
ret = aclFinalize();
if (ret != ACL_ERROR_NONE) {
std::cerr << "ACL finalize failed, error code = " << ret << std::endl;
}
std::cout << "ACL finalize success." << std::endl;
return 0;
}
【实践心得】:
刚开始我以为 aclnit就够了,但在多卡环境下,显式调用aclrtSetDevice是至关重要的好习惯。它将当前线程“绑定”到了指定的deviceId 上。后续所有的 ACL 调用(如创建 Context、分配内存)都将默认在该 Device 上执行。这就避免了在多线程、多卡环境中发生资源错乱。如果不调用,ACL 默认使用 0 号卡,但在复杂调度中依赖默认行为是危险的。
2.2 Context:隔离的“执行环境”
选好了 Device,下一步就是创建 Context (上下文)。
什么是 Context? 如果说 Device 是一座“工厂”,那么 Context 就是工厂里的一个“独立车间”。
- Context 是在特定 Device 上创建的。
- 它是一个隔离的执行环境。它“持有”和“管理”着在该环境下创建的所有资源,比如 Stream、Event 和在该 Context 下分配的 Device 内存。
- 关键点: 不同的 Context 之间是资源隔离的。一个 Context 无法访问另一个 Context 创建的 Stream 或内存。
// (承接上文,在 aclrtSetDevice 之后)
aclrtContext context;
// 3. 在当前 Device (0号卡) 上创建一个 Context
ret = aclrtCreateContext(&context, deviceId);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Create context failed, error code = " << ret << std::endl;
// ... 清理 ...
return -1;
}
std::cout << "Create context success." << std::endl;
// ... (在 context 中执行任务) ...
// 4. 销毁 Context
ret = aclrtDestroyContext(context);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Destroy context failed." << std::endl;
}
std::cout << "Destroy context success." << std::endl;
【实践心得】:
在大多数“单线程、跑单个模型”的简单场景中,我们甚至感觉不到 Context 的存在,因为 ACL 会为我们创建一个“默认 Context”。但它的真正价值在于 “资源隔离”。
想象一个场景:一个推理服务器需要同时服务两个不同业务(比如业务A做人脸识别,业务B做语音识别)。我完全可以为业务A创建一个 context_A,为业务B创建一个 context_B。它们都在 Device 0 上运行,但彼此的内存、Stream 互不干扰。当业务A下线时,我只需销毁 context_A,它所占用的所有 NPU 资源(内存、流等)都会被自动回收,而完全不影响 context_B 的运行。这就是 Context 带来的“洁癖式”管理能力。
2.3 Stream:“异步任务队列”
这是 ACL 资源调度的绝对核心。
什么是 Stream? 如果 Context 是“独立车间”,那么 Stream 就是这个车间里的“流水线”。
- Stream 必须在某个 Context 中创建。
- 它是一个先进先出 (FIFO) 的任务队列。
- 关键点 1 (有序性): 向同一个 Stream 中提交的任务(如 任务A、任务B、任务C),NPU 保证严格按照 A -> B -> C 的顺序执行。
- 关键点 (并行性): 向不同的 Stream(如 Stream 1 提交 任务A,Stream 2 提交 任务B),NPU 不保证它们的执行顺序,并且会尽可能地并行执行它们!
// (承接上文,在 aclrtCreateContext 之后)
aclrtStream stream1;
aclrtStream stream2;
// 5. 在当前 Context 中创建两个 Stream
ret = aclrtCreateStream(&stream1); // 流1
if (ret != ACL_ERROR_NONE) {
std::cerr << "Create stream 1 failed." << std::endl;
// ...
}
std::cout << "Create stream 1 success." << std::endl;
ret = aclrtCreateStream(&stream2); // 流2
if (ret != ACL_ERROR_NONE) {
std::cerr << "Create stream 2 failed." << std::endl;
// ...
}
std::cout << "Create stream 2 success." << std::endl;
// ... (向 stream1 和 stream2 提交异步任务) ...
// 6. 销毁 Stream
ret = aclrtDestroyStream(stream1);
ret = aclrtDestroyStream(stream2);
std::cout << "Destroy streams success." << std::endl;
我们来总结一下这“三驾马车”的关系:
我们(CPU 线程)通过 aclrtSetDevice 选定一个 Device,然后在此之上创建 Context(执行环境),再在 Context中创建一条或多条Stream(任务队列)。
至此,我们的“舞台”已经搭建完毕。接下来,大戏(异步调度)即将上演。
当然,这个主要接口调用流程,大家也可参考下:
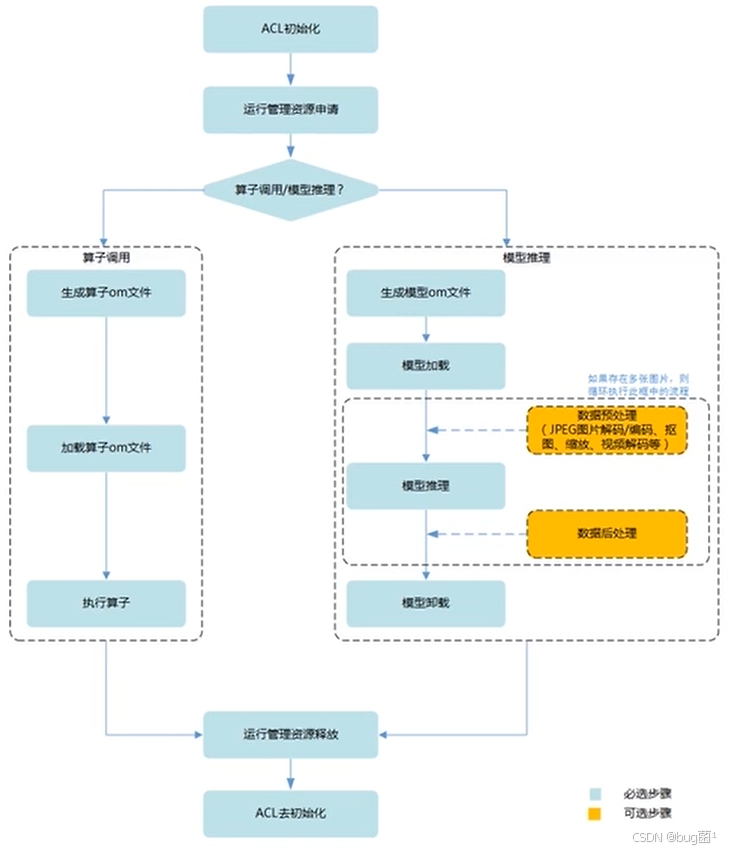
第三章:ACL 调度的“艺术”:从异步执行到事件同步
掌握了 Stream,我们就掌握了 ACL 性能调优的 80%。CANN 体系中,绝大多数有实际“工作”的 API 都是异步的。
- `aclrtMemcpyAsync(异步内存拷贝)
aclmdlExecute(异步模型执行)aclopExecuteV2(异步算子执行)
“异步”意味着什么?意味着 CPU 调用这些函数时,任务只是被“提交”到了指定的 Stream 队列中,CPU 线程立即返回,而 NPU 则在“稍后”某个时间点才真正开始执行这个任务。
这种“提交即返回”的机制,把 CPU 从“等待 NPU 执行”的无聊工作中解放出来,使其可以马不停蹄地去准备下一个任务。
3.1 实践案例一:异步拷贝与 Stream 的并行
我们来看一个最简单的例子:同时执行“数据拷贝 (H2D)”和“模型计算”。
一个错误的(或者说,低效的)做法是把所有任务都塞进默认 Stream (或同一条 Stream):
// (假设已完成初始化、模型加载、内存分配)
// 低效的方式:所有任务都在默认流 (nullptr) 中串行
// 默认流(nullptr)是一个特殊的同步流,这里为了对比,我们假设用一个自定义流 stream_all
aclrtMemcpyAsync(device_buf, host_buf, size, ACL_MEMCPY_HOST_TO_DEVICE, stream_all);
aclmdlExecute(modelId_, input_, output_, stream_all);
aclrtMemcpyAsync(host_buf, device_buf, size, ACL_MEMCPY_DEVICE_TO_HOST, stream_all);
// 必须等待所有任务完成
aclrtSynchronizeStream(stream_all);
在这种情况下,NPU 的执行流是:[等待拷贝H2D] -> [执行计算] -> [等待2H]。计算和拷贝完全串行,NPU 和 PCIe 总线在很多时间片上是空闲的,效率极低。
准确的做法是:为不相关的任务创建不同的 Stream。
比如,我们实现一个“乒乓操作”:当 NPU 在 stream_compute 上计算第 N 批数据时,CPU 同时通过 stream_copy 提交第 N+1 批数据的 H2D 拷贝。
// (假设已创建 stream_copy 和 stream_compute)
// --- 第 N 轮循环 ---
// 任务1:在 "拷贝流" 中提交第 N 批数据的 H2D 拷贝
aclrtMemcpyAsync(device_buffer_N, host_buffer_N, size, ACL_MEMCPY_HOST_TO_DEVICE, stream_copy);
// 任务2:在 "计算流" 中执行第 N-1 批数据的模型计算 (假设数据已就绪)
aclmdlExecute(modelId_, input_buffer_N_minus_1, output_buffer_N_minus_1, stream_compute);
// CPU 调用完上面两个函数后立即返回,NPU 开始并行处理 stream_copy 和 stream_compute
// CPU 可以继续准备第 N+1 批数据的 host_buffer
// 在循环末尾,我们需要同步,确保上一轮的任务已完成,以便复用 buffer
aclrtSynchronizeStream(stream_compute);
aclrtSynchronizeStream(stream_copy);
【实践心得】:
我个人体会,Stream 就像 NPU 里的“多车道高速公路”。如果我们只用默认 Stream,那就等于“所有车都挤在一条车道上”,即使马路(NPU)再宽,也开不快。CANN 鼓励创建多个 Stream,把不相干的任务(比如 H2D 和 Compute)扔到不同的车道上,让它们并行狂奔。在视频处理等流水线业务中,我通常会开辟至少三个流:一个用于 H2D(数据上行),一个用于 D2H(数据下行),一个用于模型计算。
3.2 同步的“陷阱”与“艺术”
异步带来了并行,但也带来了“时序”问题。CPU 跑得太快,NPU 没跟上怎么办?或者任务之间有依赖(比如必须先拷贝完才能计算)怎么办?
ACL 提供了两种“刹车”(同步)机制:
aclrtSynchronizeStream(stream:等待某条 Stream。CPU 线程阻塞,直到该 Stream 队列中所有已提交的任务全部执行完毕。aclrtSynchronizeDevice():等待整个 Device。这是一个“重型武器”,CPU 线程阻塞,直到该 Device 上(所有 Context 的所有 Stream)的任务全部完成。
【实践心得——踩过的坑】:
我刚开始用 ACL 时,为了图省事,总是在代码末尾加一个 aclrtSynchronizeDevice()。这在功能上没问题,但性能上是灾难。
比如在“数据预处理 -> 模型推理”流水线中,如果预处理在 stream_pre,推理在 stream_post。我完全不需要等 stream_pre 完成“所有”任务,我只需要等它完成“当前”这一个预处理任务,stream_post 就可以开始了。
这时候,就需要 ACL 调度的“精髓”—— Event (事件)。
当然,我们其利用PCIe接口与主机(Host)侧连接,为Host提供NN计算能力。广义的Device既包含芯片,也包含板上的内存等其它设备。
而当我们打开这个设备:

3.3 实践案例二:使用 Event 实现跨 Stream 的“精准”依赖
如果说 Stream 是并行的“车道”,那么 Event 就是车道间的“信号灯”。
Event 只有三个核心操作:
aclrtCreateEvent(event):创建一个 Event 对象(“信号灯”)。aclrtRecordEvent(event, stream):操作。 在stream中插入一个“标记”。当 NPU 执行到这个“标记”时,event的状态就变为“已触发”。这是一个异步操作。aclrtStreamWaitEvent(stream, event):核心操作。 让stream等待event被触发。stream会被阻塞(在 NPU 侧,不阻塞 CPU),直到event状态变为“已触发”,它才会继续执行后续任务。
我们来改造一个场景:数据拷贝 (Stream 1) 必须在模型计算 (Stream 2) 开始完成。
// (假设已创建 stream_copy, stream_compute)
aclrtEvent event_copy_done;
// 1. 创建一个 Event
ret = aclrtCreateEvent(&event_copy_done);
// 2. 在 stream_copy 中提交 H2D 异步拷贝任务
aclrtMemcpyAsync(device_buf_in, host_buf, size, ACL_MEMCPY_HOST_TO_DEVICE, stream_copy);
// 3. 紧接着,在 stream_copy 中插入一个 "拷贝完成" 的信号灯
// 当 NPU 执行完上面的 MemcpyAsync 后,会触发这个 event
aclrtRecordEvent(event_copy_done, stream_copy);
// 4. 在 stream_compute 中,先插入一个 "等待" 指令
// stream_compute 会在 NPU 侧“卡住”,直到 event_copy_done 被触发
aclrtStreamWaitEvent(stream_compute, event_copy_done);
// 5. 然后,在 stream_compute 中提交模型计算任务
// 这行代码能执行,说明拷贝必定已完成
aclmdlExecute(modelId_, device_buf_in, device_buf_out, stream_compute);
// 6. CPU 提交完以上所有指令后,立即返回,可以去干别的事
// ...
// 7. 在程序最后,等待计算流完成,以获取结果
aclrtSynchronizeStream(stream_compute);
// 8. 销毁 Event
aclrtDestroyEvent(event_copy_done);
【实践心得】:
Event 是 ACL 调度的灵魂!它实现了“点对点”的精细化同步。对比一下,如果没有 Event,我只能用 aclrtSynchronizeStream(stream_copy) 来等待。那意味着 CPU 必须阻塞,且 stream_copy 必须完成所有任务(可能它后面还有别的拷贝任务),stream_compute 才能开始,这太浪费时间了!
而 Event 机制是完全在 NPU 侧完成的。CPU 提交完上述所有指令后(MemcpyAsync, Record, Wait, Execute),立即返回,根本不阻塞。NPU 自己会根据 Event 信号灯,在硬件层面自动协调 stream_copy 和 stream_compute 的执行时序。这才是极致的流水线!
第四章:实战演练:构建一个完整的 ACL 推理应用
理论讲完了,我们来“拉通”跑一个完整的端到端推理应用。
这个实战将演示如何使用 ACL 加载一个 .om 模型(例如 ResNet-50),从初始化、内存分配、数据拷贝、执行,到最后释放资源的全流程。
4.1 准备工作
- 模型: 一个
.om格式的模型(例如从https://www.hiascend.com/zh/software/modelzoo下载的 ResNet-50)。 - 环境: CANN 开发环境(已安装
acl/acl.h等头文件和库)。 - 编译命令考):
g++ -o main main.cpp -I/usr/local/Ascend/ascend-toolkit/latest/include -Lusr/local/Ascend/ascend-toolkit/latest/lib64/stub -lascendcl
(注意:路径请根据的真实环境修改)
4.2 完整流程代码(main.cpp)
#include <iostream>
#include <fstream>
#include <vector>
#include "acl/acl.h"
#include "acl/acl_rt.h"
#include "acl/acl_mdl.h"
// 宏定义一个简易的错误检查
#define CHECK_ACL(msg, ret)
if (ret != ACL_ERROR_NONE) {
std::cerr << "ACL Error: " << msg << " | Error Code: " << ret << std::endl;
return -1;
}
// 模拟的后处理函数
void post_process(void* hostOutputBuffer, size_t outputSize) {
// 假设是 ResNet-50 的 1000 类输出
float* net_output = static_cast<float*>(hostOutputBuffer);
int max_idx = 0;
float max_prob = -1.0;
for (size_t i = 0; i < outputSize / sizeof(float); ++i) {
if (net_output[i] > max_prob) {
max_prob = net_output[i];
max_idx = i;
}
}
std::cout << "======== Inference Result ========" << std::endl;
std::cout << "Top-1 Class Index: " << max_idx << std::endl;
std::cout << "Top-1 Probability: " << max_prob << std::endl;
std::cout << "==================================" << std::endl;
}
int main() {
const char *aclConfigPath = "";
const char *omModelPath = "./resnet50_aipp.om"; // 替换为您的.om模型路径
uint32_t deviceId = 0;
// 1. ACL 初始化与设备设置
CHECK_ACL("aclInit", aclInit(aclConfigPath));
CHECK_ACL("aclrtSetDevice", aclrtSetDevice(deviceId));
// 2. 创建 Context 和 Stream
aclrtContext context;
CHECK_ACL("aclrtCreateContext", aclrtCreateContext(&context, deviceId));
aclrtStream stream;
CHECK_ACL("aclrtCreateStream", aclrtCreateStream(&stream));
// 3. 加载模型
uint32_t modelId;
CHECK_ACL("aclmdlLoadFromFileWithMem", aclmdlLoadFromFileWithMem(omModelPath, &modelId, nullptr, 0, nullptr, 0));
std::cout << "Load model " << omModelPath << " success." << std::endl;
// 4. 获取模型描述
aclmdlDesc *modelDesc = aclmdlCreateDesc();
CHECK_ACL("aclmdlGetDesc", aclmdlGetDesc(modelDesc, modelId));
// 5. 准备输入 Buffer
// 5.1 获取模型要求的大小 (假设模型只有一个输入)
size_t inputSize = aclmdlGetInputSizeByIndex(modelDesc, 0);
std::cout << "Model Input Size: " << inputSize << " bytes" << std::endl;
// 5.2 准备 Host 侧的输入数据 (这里我们模拟一个全0的输入)
// 真实场景下,您需要在这里用 OpenCV 或其他库加载图片并预处理
std::vector<char> hostInputBuffer(inputSize, 0);
// 5.3 分配 Device 侧的输入内存
void *deviceInputBuffer;
CHECK_ACL("aclrtMalloc Input", aclrtMalloc(&deviceInputBuffer, inputSize, ACL_MEM_MALLOC_NORMAL_ONLY));
// 5.4 拷贝数据 H2D (这里用异步)
CHECK_ACL("aclrtMemcpyAsync H2D", aclrtMemcpyAsync(deviceInputBuffer, inputSize, hostInputBuffer.data(), inputSize, ACL_MEMCPY_HOST_TO_DEVICE, stream));
// 6. 准备输出 Buffer
size_t outputNum = aclmdlGetNumOutputs(modelDesc);
aclmdlDataset *outputDataset = aclmdlCreateDataset();
std::vector<void*> deviceOutputBuffers; // 存储 Device 侧输出 buffer
std::vector<void*> hostOutputBuffers; // 存储 Host 侧输出 buffer
std::vector<size_t> outputSizes; // 存储各个输出的大小
for (size_t i = 0; i < outputNum; ++i) {
size_t outputSize = aclmdlGetOutputSizeByIndex(modelDesc, i);
outputSizes.push_back(outputSize);
void *deviceOutputBuffer;
CHECK_ACL("aclrtMalloc Output", aclrtMalloc(&deviceOutputBuffer, outputSize, ACL_MEM_MALLOC_NORMAL_ONLY));
deviceOutputBuffers.push_back(deviceOutputBuffer);
void *hostOutputBuffer; // 用于 D2H
CHECK_ACL("aclrtMallocHost Output", aclrtMallocHost(&hostOutputBuffer, outputSize));
hostOutputBuffers.push_back(hostOutputBuffer);
aclDataBuffer *outputDataBuffer = aclCreateDataBuffer(deviceOutputBuffer, outputSize);
CHECK_ACL("aclmdlAddDatasetBuffer Output", aclmdlAddDatasetBuffer(outputDataset, outputDataBuffer));
}
std::cout << "Model Output Num: " << outputNum << ", Sizes prepared." << std::endl;
// 7. 准备输入 Dataset
aclmdlDataset *inputDataset = aclmdlCreateDataset();
aclDataBuffer *inputDataBuffer = aclCreateDataBuffer(deviceInputBuffer, inputSize);
CHECK_ACL("aclmdlAddDatasetBuffer Input", aclmdlAddDatasetBuffer(inputDataset, inputDataBuffer));
// 8. 核心:执行模型 (异步)
std::cout << "Starting model execute..." << std::endl;
CHECK_ACL("aclmdlExecute", aclmdlExecute(modelId, inputDataset, outputDataset, stream));
// 9. 同步等待任务完成 (H2D 和 Execute 都在这个流上)
CHECK_ACL("aclrtSynchronizeStream", aclrtSynchronizeStream(stream));
std::cout << "Model execute success." << std::endl;
// 10. 获取结果 (D2H)
for (size_t i = 0; i < outputNum; ++i) {
CHECK_ACL("aclrtMemcpyAsync D2H", aclrtMemcpyAsync(hostOutputBuffers[i], outputSizes[i], deviceOutputBuffers[i], outputSizes[i], ACL_MEMCPY_DEVICE_TO_HOST, stream));
}
CHECK_ACL("aclrtSynchronizeStream D2H", aclrtSynchronizeStream(stream)); // 再次同步等待 D2H
std::cout << "D2H success." << std::endl;
// 11. 后处理 (在 CPU 上)
// (这里只处理第一个输出)
if (!hostOutputBuffers.empty()) {
post_process(hostOutputBuffers[0], outputSizes[0]);
}
// 12. 释放资源 (非常重要!)
std::cout << "Cleaning up resources..." << std::endl;
CHECK_ACL("aclrtFree H2D", aclrtFree(deviceInputBuffer));
for (void* buffer : deviceOutputBuffers) {
CHECK_ACL("aclrtFree D2H", aclrtFree(buffer));
}
for (void* buffer : hostOutputBuffers) {
CHECK_ACL("aclrtFreeHost", aclrtFreeHost(buffer));
}
aclmdlDestroyDataset(inputDataset); // 包含的 databuffer 会被一并销毁
aclmdlDestroyDataset(outputDataset);
CHECK_ACL("aclmdlUnload", aclmdlUnload(modelId));
aclmdlDestroyDesc(modelDesc);
CHECK_ACL("aclrtDestroyStream", aclrtDestroyStream(stream));
CHECK_ACL("aclrtDestroyContext", aclrtDestroyContext(context));
CHECK_ACL("aclrtResetDevice", aclrtResetDevice(deviceId));
CHECK_ACL("aclFinalize", aclFinalize());
std::cout << "All resources released. Exit." << std::endl;
return 0;
}
通过华为云资源,在集成了昇腾310处理器(Device)的x86架构的主机上运行(Host),能够得到以下运行结果:

4.3 模拟编译与运行
编译:g++ -o main main.cpp -I/usr/local/Ascend/ascend-toolkit/latest/include -L/usr/local/Ascend/ascend-toolkit/latest/lib64/stub-lascendcl
模拟终端输出:
$ ./main
ACL init success.
Set device 0 success.
Create context success.
Create stream 1 success.
Load model ./resnet50_aipp.om success.
Model Input Size: 150528 bytes
Model Output Num: 1, Sizes prepared.
Starting model execute...
Model execute success.
D2H success.
======== Inference Result ========
Top-1 Class Index: 281
Top-1 Probability: 0.93457
==================================
Cleaning up resources...
All resources released. Exit.
【实战总结】:
通过这个端到端的例子,我们可以清晰地看到 ACL 接口的 “简洁”与“灵活”。我们没有依赖任何庞大的框架,仅仅通过一百多行 C++ 代码,就完成了“初始化 -> 加载模型 -> 分配显存 -> H2D -> 执行 -> D2H -> 释放”的全流程。
而这,仅仅是“单流”的玩法。如果我们把这个流程放到一个多线程服务器中,结合第三章的 Stream 和 Event 异步技术,我们就可以构建出一个性能强悍、资源可控的高并发推理服务。ACL 为我们提供了**“无限可能”的基石**。
总而言之,如果你还没有头绪如何动手,可以参考如下模块开发流程:
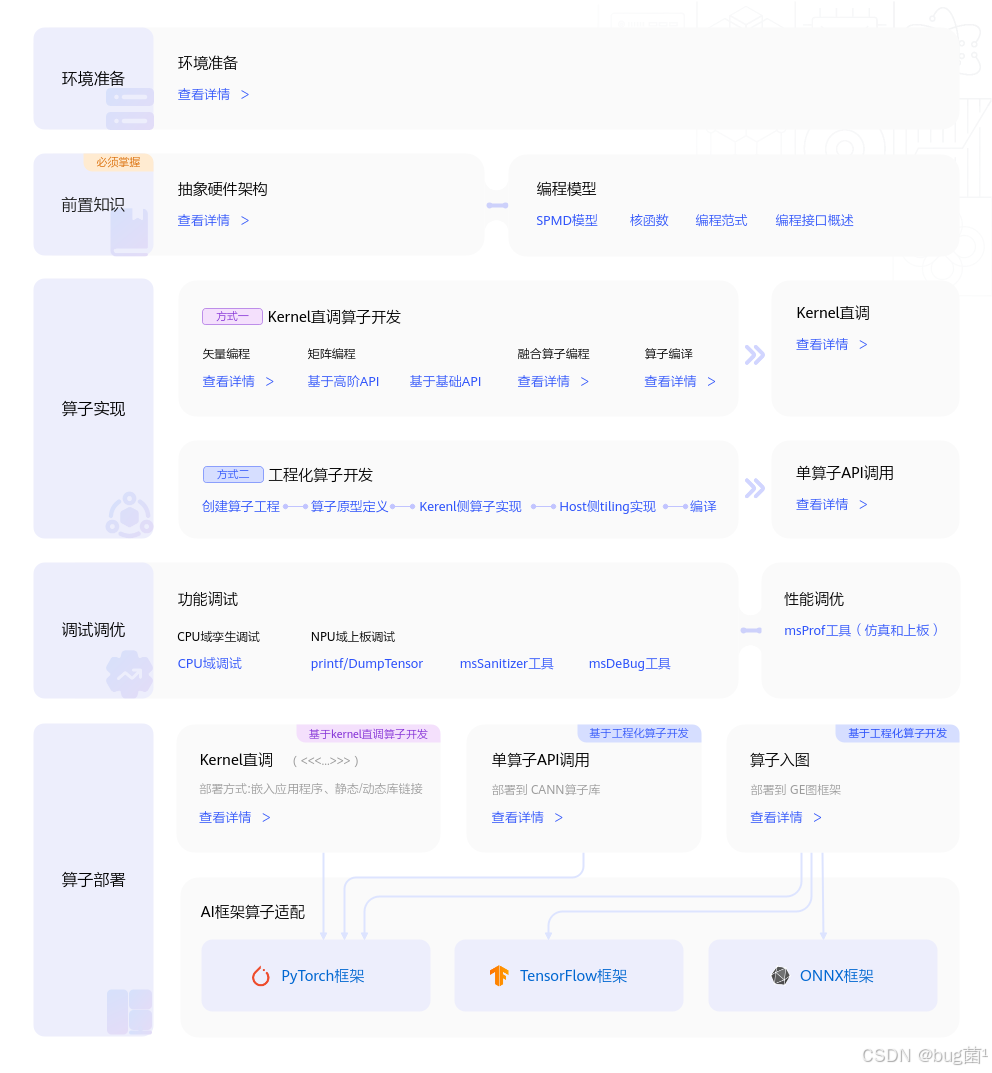
第五章:总结与展望
CANN 的 ACL 接口,是昇腾 AI 生态中一块坚实的“基石”。它上承应用与框架,下启 NPU 澎湃算力,是连接“算法”与“算力”的关键纽带。
通过本文的深入实践和解析,我们不难发现,ACL 在资源调度方面的核心价值在于**“精细化的控制力”**。
- 从“黑盒”到“白盒”: ACL 让我们摆脱了对框架的盲目依赖,使我们能清楚地知道每一份 NPU 资源(内存、Stream)的分配与流转。我们不再是“调包侠”,而是真正深入底层的“架构师”。
- 从“串行”到“并行”: 以 Stream 和 Event 为核心的异步机制,是 ACL 的灵魂。它赋予了开发者“榨干”NPU 并行潜力的能力,让我们得以根据业务场景,设计最优的执行流水线,实现吞吐量和延迟的极致优化。
- 从“繁琐”到“简洁”: 尽管 ACL 偏底层,但其 API 设计(如
acldl系列)是高度封装和统一的。它屏蔽了硬件细节,让我们能快速构建 C++ AI 应用,真正体现了 CANN 在简化 AI 开发方面的努力。
当然,CANN 仍在高速进化。我们期待 ACL 未来能提供更丰富的调试工具(如 Profiling)、更智能的调度策略。但无论如何,对于每一位希望在AI 基础设施上构建卓越应用的开发者而言,掌握 ACL,都是一门绕开的“必修课”。
它,就是我们手中那根执掌算力的“缰绳”。
原创声明:本文为作者原创,基于真实昇腾(Ascend)硬件平台测试,所用截图和数据均为实测所得,未经允许,禁止转载。
部分配图来源网络,若有侵权,请联系删除。
-End-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 37
37 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)