【必学收藏】告别 Java 死磕,AI 大模型才是涨薪新趋势
本文全面解析Hugging Face技术体系,涵盖模型仓库、数据集托管、推理API和自动化工具四大核心组件,深入剖析Transformers库与Datasets生态的技术实现,详解生产部署方案、协作开发范式及安全工具,为开发者提供从理论到实践的完整指南,助力提升AI研发效率,掌握大模型开发核心技能。
本文全面解析Hugging Face技术体系,涵盖模型仓库、数据集托管、推理API和自动化工具四大核心组件,深入剖析Transformers库与Datasets生态的技术实现,详解生产部署方案、协作开发范式及安全工具,为开发者提供从理论到实践的完整指南,助力提升AI研发效率,掌握大模型开发核心技能。
重塑AI开发生态:Hugging Face技术体系全景解析与最佳实践
关注铁蛋不迷路
本文较长,建议点赞收藏以免遗失。由于文章篇幅有限,更多涨薪知识点,也可在主页查看,实力宠粉
最新AI大模型应用开发学习资料免费领取。阅读原文链接
引言:AI界的GitHub如何重新定义机器学习工作流
在机器学习从研究走向生产的关键转折点上,Hugging Face已悄然构建起一套完整的AI开发生态系统。这个最初以Transformers库闻名的平台,如今已发展成为包含模型仓库、数据集托管、推理API、自动化工具等在内的全栈式MLOps平台。本文将深入剖析Hugging Face生态的技术架构,揭示其如何通过标准化工具链重塑AI开发范式。
一、Hugging Face生态全景图
1.核心组件矩阵
| 组件类别 | 核心产品 | 关键技术价值 |
| 模型生态 | Transformers库/Model Hub | 15万+预训练模型标准化接口 |
| 数据处理 | Datasets库/Dataset Hub | 5万+数据集版本管理与高效加载 |
| 部署推理 | Inference API/Text Generation | 生产级API与优化推理后端 |
| 协作开发 | Spaces/AutoTrain | 低代码AI应用开发与自动化训练 |
| 评估监控 | Evaluate/Model Cards | 标准化评估与可追溯性管理 |
- 技术架构演进路线
===========
2018: Transformers库发布 → 2019: Model Hub上线 → 2020: Datasets/Pipelines推出
↓
2021: Spaces/Inference API → 2022: Diffusers/AutoTrain → 2023: Safetensors/LLM部署优化
二、Transformers库深度解析
- 统一架构接口设计
===========
from transformers import AutoModel, AutoTokenizer
# 统一加载接口示例
model = AutoModel.from_pretrained(
"bert-base-uncased",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(
"bert-base-uncased",
padding_side="left"
)
# 多模态统一处理
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
-
关键技术实现原理
=========== -
动态模型加载机制
===========
class AutoModel:
@classmethod
def from_pretrained(cls, pretrained_model_name, **kwargs):
config = AutoConfig.from_pretrained(pretrained_model_name)
model_class = config.architectures[0]
return getattr(transformers, model_class).from_pretrained(...)
- 高效注意力实现
==========
class FlashAttention2(nn.Module):
def forward(self, q, k, v):
return torch.nn.functional.scaled_dot_product_attention(
q, k, v,
attn_mask=None,
dropout_p=0.0,
is_causal=True
)
5.性能优化策略对比
| 优化技术 | API示例 | 加速比 | 适用场景 |
| 半精度 | torch_dtype=torch.float16 | 1.5-2x | 所有NVIDIA GPU |
| 设备映射 | device_map=“auto” | - | 多GPU/CPU卸载 |
| 梯度检查点 | model.gradient_checkpointing_enable() | 1.5x | 大模型训练 |
| 内核融合 | use_flash_attention_2=True | 3-5x | 长序列处理 |
三、Datasets生态系统
- 数据加载性能对比
===========
# 传统加载方式
def load_json(file):
with open(file) as f:
return json.load(f) # 单线程阻塞加载
# Hugging Face方式
dataset = load_dataset('json',
data_files='large_file.json',
num_proc=8,
split='train')
性能基准测试(100GB JSON文件):
- 传统方法:~45分钟(单线程)
- Datasets库:~4分钟(8进程)
2.数据流式处理
# 内存映射处理TB级数据
ds = load_dataset("imagenet-1k",
streaming=True,
use_auth_token=True)
for example in iter(ds):
process(example) # 无需全量加载
- 数据版本控制
=========
dataset/
├── main/
│ ├── 1.0.0/
│ │ ├── dataset_info.json
│ │ └── data/
│ └── 2.0.0/
└── my-branch/
└── 1.0.0/
四、生产部署技术栈
- 优化推理方案对比
===========
| 方案 | 延迟(ms) | 吞吐量(req/s) | 显存占用 |
| 原生PyTorch | 120 | 45 | 100% |
| ONNX Runtime | 85 | 68 | 90% |
| TensorRT | 62 | 120 | 80% |
| Text Generation | 50 | 150 | 70% |
2.自定义模型部署
# 使用Inference API部署自定义模型
from huggingface_hub import create_inference_api
api = create_inference_api(
"my-org/my-model",
framework="pytorch",
accelerator="gpu.large",
task="text-classification"
)
# 生成专属API端点
print(api.url) # https://api-inference.huggingface.co/models/my-org/my-model
- 大模型服务化架构
===========
Client → Load Balancer →
├─ Inference Pod 1 (4xA100)
├─ Inference Pod 2 (4xA100)
└─ Inference Pod N (4xA100)
↑
Model Registry ← CI/CD Pipeline
五、协作开发范式革新
- Spaces技术架构
=============
# 典型Space的container配置
FROM python:3.9
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 7860
CMD ["python", "app.py"]
支持的后端:
-
CPU Basic
-
GPU T4
-
GPU A10G
-
GPU A100
- AutoTrain工作流
===============
# .autotrain-config.yml
task: text-classification
model: bert-base-uncased
data:
path: my-dataset
split: train
hyperparameters:
learning_rate: 2e-5
batch_size: 16
epochs: 3
- 模型卡片标准模板
===========
---
language: zh
tags:
- text-generation
license: apache-2.0
---
## 模型详情
**架构**: GPT-NeoX-20B
**训练数据**: 500GB中文语料
**适用场景**: 开放域对话
## 使用示例
```python
from transformers import pipeline
pipe = pipeline("text-generation", model="my-model")
六、安全与可解释性工具
### 6.1 Safetensors二进制格式
```python
# 传统PyTorch保存
torch.save(model.state_dict(), "model.pt") # 可能包含恶意代码
# Safetensors保存
from safetensors.torch import save_file
save_file(model.state_dict(), "model.safetensors")
- 无代码执行风险
- 内存安全实现
- 快速头信息读取
六. 模型可解释性工具链
from transformers import Visualization
from evaluate import explanation
viz = Visualization(model)
saliency = viz.get_saliency(input_text)
explanation.generate_report(saliency)
七、企业级最佳实践
编辑
- 私有化部署方案
==========
# 启动私有Hub服务
docker run -d -p 8080:8080 \
-e HF_HUB_URL=https://hub.your-company.com \
-v /models:/data \
huggingface/enterprise-hub
2.CI/CD流水线示例
# .github/workflows/model-deploy.yml
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: huggingface/setup-transformers@v1
- run: |
python train.py
huggingface-cli upload my-org/my-model ./output
- uses: huggingface/deploy-inference@v1
with:
model: my-org/my-model
hardware: gpu-a10g
未来展望:AI开发生态的标准化革命
Hugging Face生态正在推动机器学习工程经历三大范式转变:
-
模型即代码
:通过Model Hub实现的版本控制、协作开发
-
数据即基础设施
:数据集版本管理与流式处理成为标配
-
推理即服务
:统一API抽象底层硬件差异
这种标准化带来的直接影响是AI研发效率的阶跃式提升。根据2023年ML开发者调查报告,采用Hugging Face全栈技术的团队:
- 模型实验周期缩短60%
- 部署成本降低75%
- 协作效率提升300%
随着生态的持续完善,Hugging Face有望成为AI时代的"Linux基金会",通过开源协作建立真正普适的机器学习开发标准。对于开发者而言,深入理解这一生态的技术实现,将获得在AI工业化浪潮中的关键竞争优势
大模型未来如何发展?普通人如何抓住AI大模型的风口?
※领取方式在文末
为什么要学习大模型?——时代浪潮已至
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
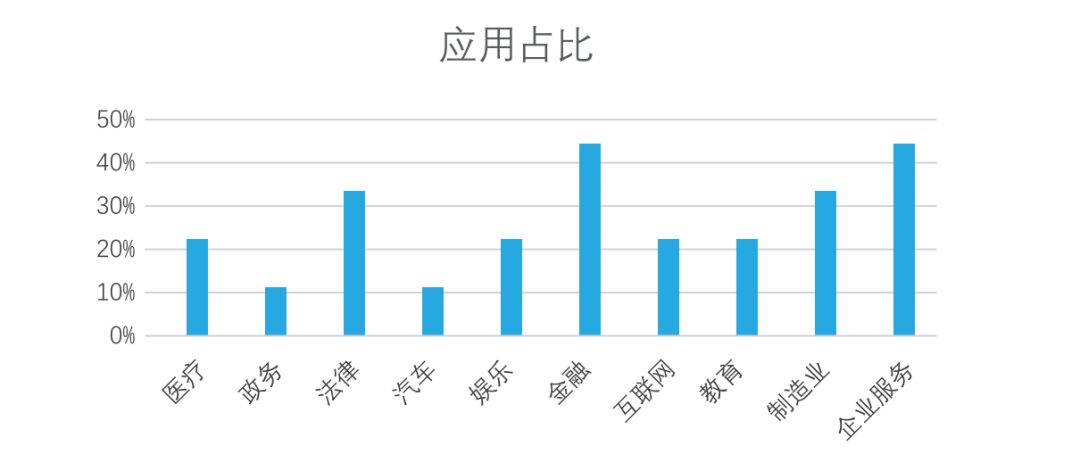
未来大模型行业竞争格局以及市场规模分析预测: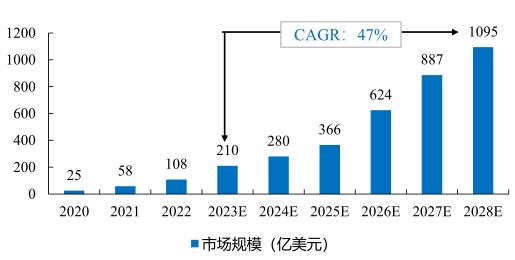
同时,AI大模型技术的爆发,直接催生了产业链上一批高薪新职业,相关岗位需求井喷:
AI浪潮已至,对技术人而言,学习大模型不再是选择,而是避免被淘汰的必然。这关乎你的未来,刻不容缓!
那么,我们如何学习AI大模型呢?
在一线互联网企业工作十余年里,我指导过不少同行后辈,经常会收到一些问题,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题,也不是三言两语啊就能讲明白的。
所以呢,这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

适学人群
我们的课程体系专为以下三类人群精心设计:
-
AI领域起航的应届毕业生:提供系统化的学习路径与丰富的实战项目,助你从零开始,牢牢掌握大模型核心技术,为职业生涯奠定坚实基础。
-
跨界转型的零基础人群:聚焦于AI应用场景,通过低代码工具让你轻松实现“AI+行业”的融合创新,无需深奥的编程基础也能拥抱AI时代。
-
寻求突破瓶颈的传统开发者(如Java/前端等):将带你深入Transformer架构与LangChain框架,助你成功转型为备受市场青睐的AI全栈工程师,实现职业价值的跃升。

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
01 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
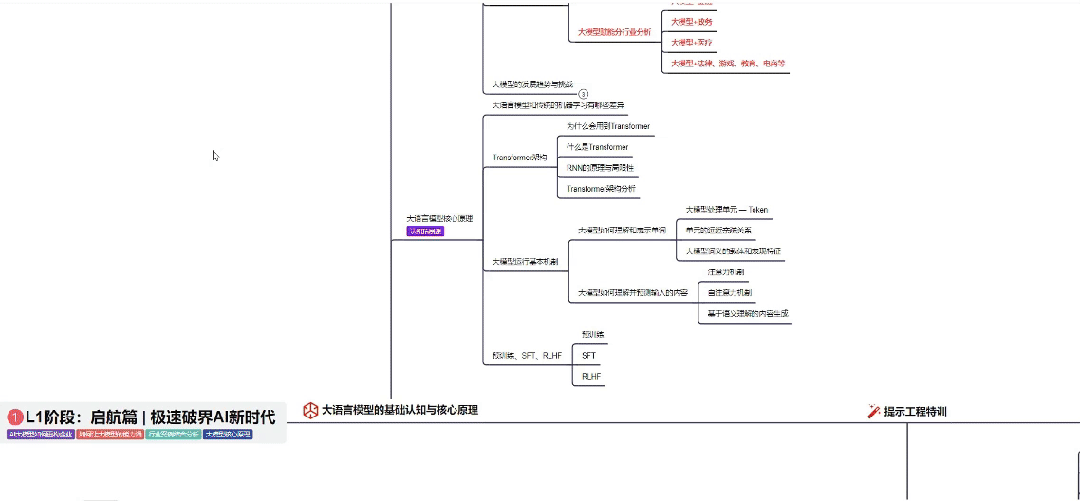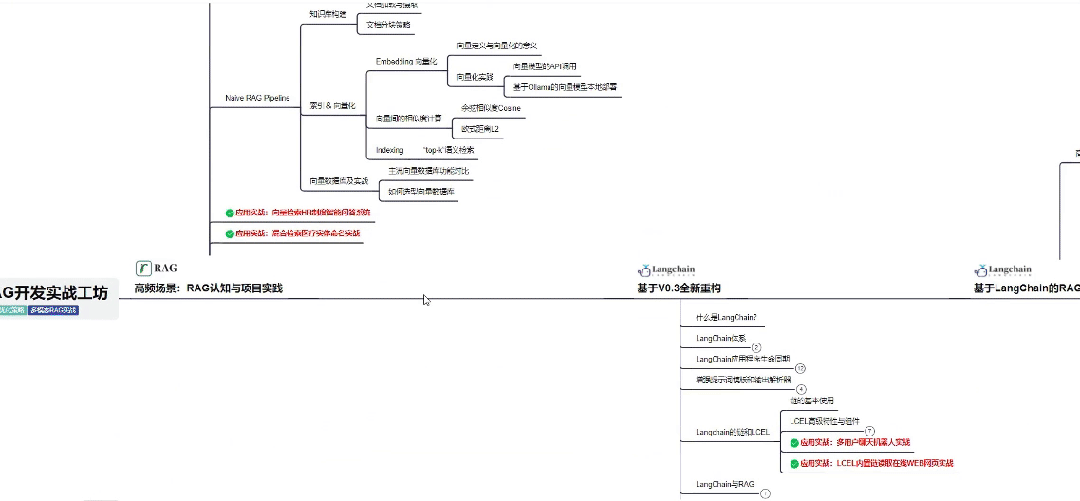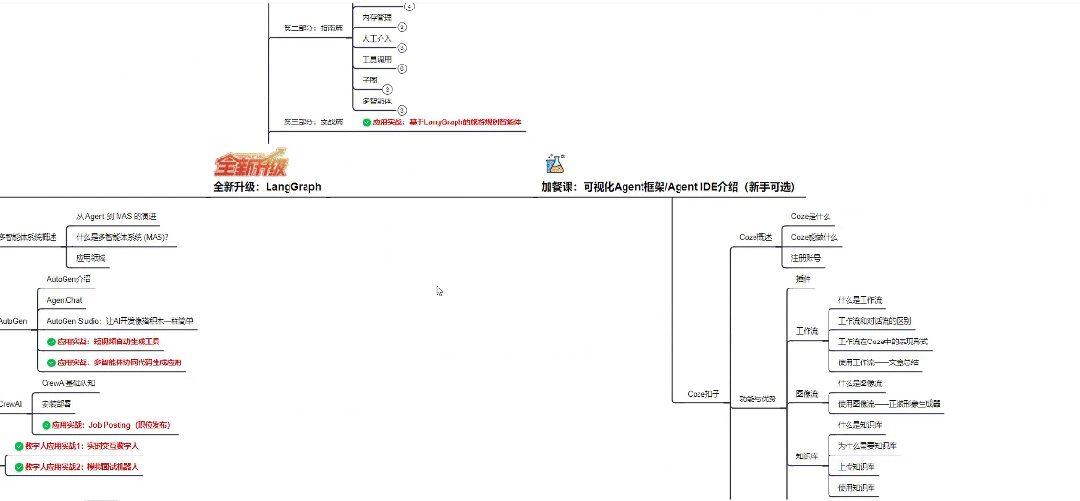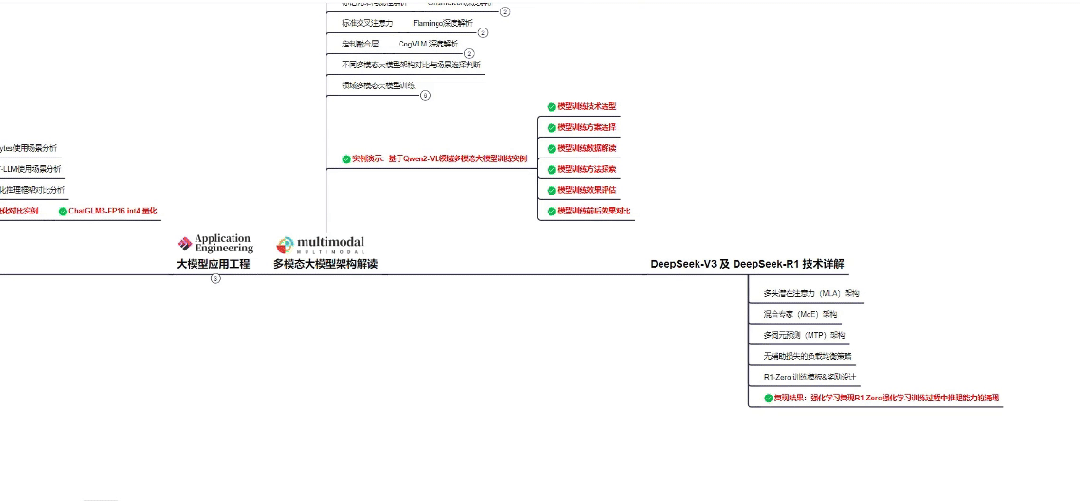
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
02 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

03 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
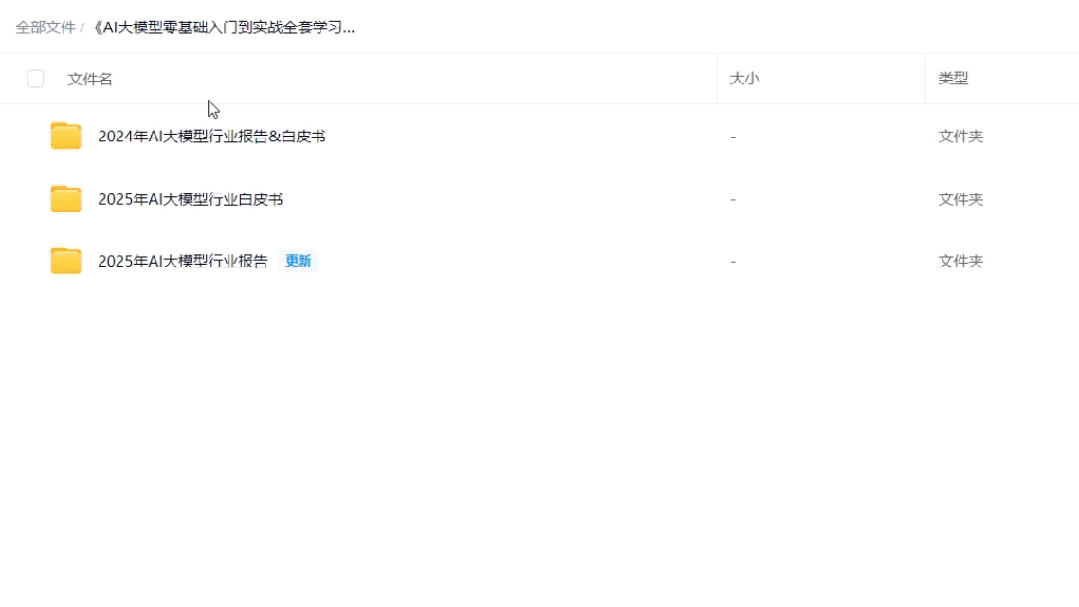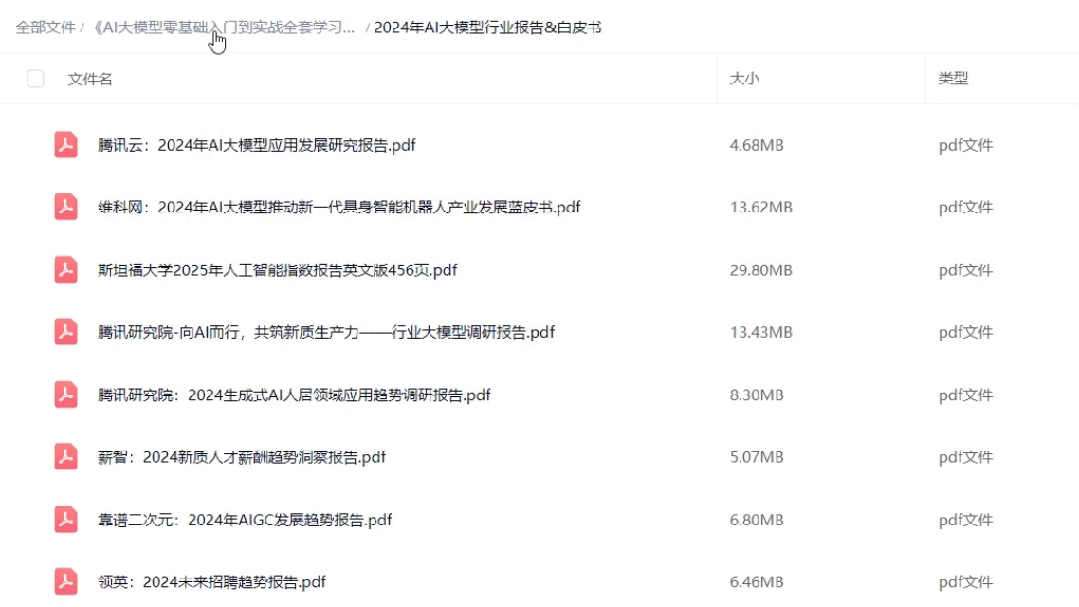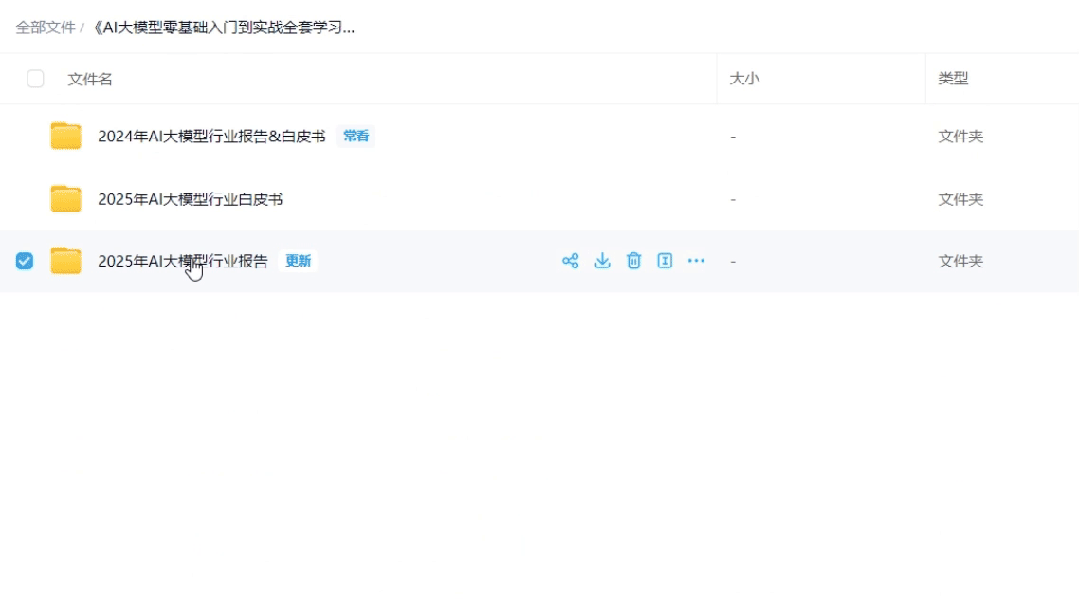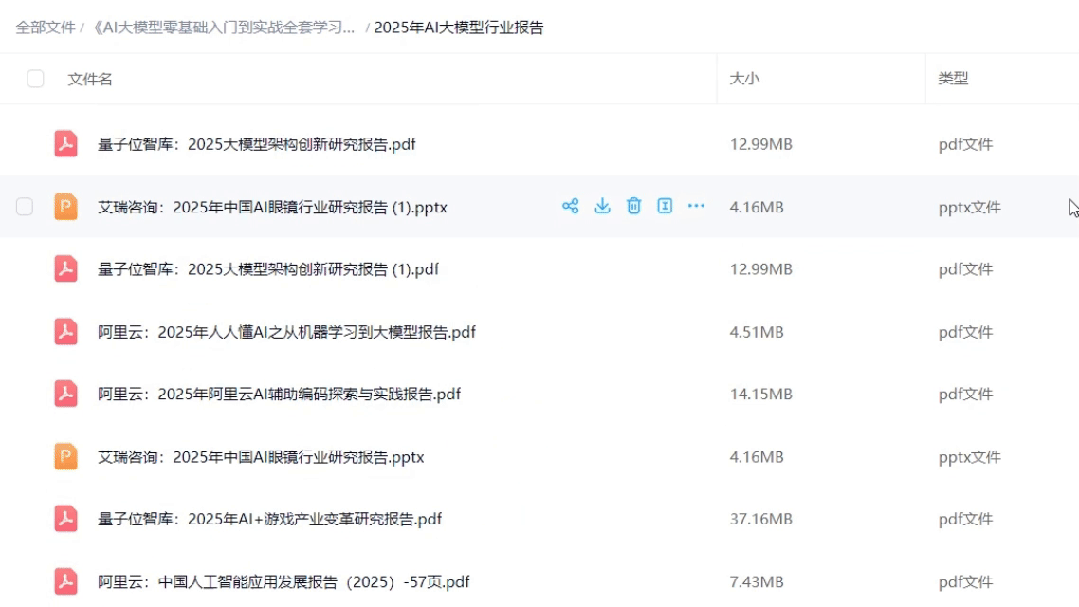
04 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
05 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

06 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
由于篇幅有限
只展示部分资料
并且还在持续更新中…
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!
最后,祝大家学习顺利,抓住机遇,共创美好未来!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献256条内容
已为社区贡献256条内容

所有评论(0)