VLM 实现 10%的精度提高,13.1倍加速!纽约大学新算法让视觉语言模型更小、更快、更准确
纽约大学的研究团队通过QSVD的新方法,让视觉语言模型(VLM)实现了惊人的效率飞跃,在普通GPU上获得了高达13.1倍的运行速度提升。视觉语言模型是人工智能领域的一项杰出成就,它赋予了AI像人一样同时理解图像和文字的能力。无论是让AI看图说话,进行生动的图像描述,还是回答关于一张图片内容的复杂问题,这些都离不开VLM的核心支持。它就像是连接视觉世界和语言世界的桥梁,在医疗诊断、在线教育、互动娱乐
纽约大学的研究团队通过QSVD的新方法,让视觉语言模型(VLM)实现了惊人的效率飞跃,在普通GPU上获得了高达13.1倍的运行速度提升。

视觉语言模型是人工智能领域的一项杰出成就,它赋予了AI像人一样同时理解图像和文字的能力。
无论是让AI看图说话,进行生动的图像描述,还是回答关于一张图片内容的复杂问题,这些都离不开VLM的核心支持。
它就像是连接视觉世界和语言世界的桥梁,在医疗诊断、在线教育、互动娱乐等众多领域展现出巨大的应用潜力。
然而,这种强大的能力背后,是巨大的计算代价。
VLM需要吞噬海量的数据,处理高维度的视觉与文本信息,这导致其模型体积庞大,内存占用极高,计算过程缓慢。
尤其是在模型进行推理,也就是生成答案或描述时,一个名为键值缓存(KV Cache)的机制会急剧消耗内存带宽,成为拖慢整体速度的主要瓶颈。
这种高昂的硬件成本,极大地限制了VLM在普通设备,特别是手机、笔记本电脑等资源受限环境中的部署和应用。
为了让这项技术真正走进千家万户,科学家们必须为这头巨兽瘦身减负,在不牺牲其智慧的前提下,让它变得更轻、更快。
奇思妙想:将Q、K、V三个矩阵捆绑处理
过去,研究者们尝试了各种方法来压缩模型,比如分组查询注意力或多查询注意力,思路主要是减少计算中的某些环节。
最近,DeepSeek-v3模型提出的多头潜在注意力(MLA)提供了一个新颖的视角,它通过将KV缓存压缩成更小的潜在向量,显著提升了推理效率。
受到MLA的启发,纽约大学的研究者们提出了一个更大胆的想法。
在VLM的核心组件多头注意力(Multi-Head Attention)模块中,输入的信息会通过三个独立的权重矩阵,分别变换成查询(Query, Q)、键(Key, K)和值(Value, V)。
这三个元素是注意力机制的关键,决定了模型在处理信息时应该关注什么。
传统的优化方法,通常是独立地去压缩处理Q、K、V各自的权重矩阵。这就像是三个独立的优化任务,分别对三个部件进行改造。
而QSVD的核心创新在于,它不再将这三者分开看待。
研究团队将原本独立的三个大小为E×E的权重矩阵WQ、WK、WV,在逻辑上拼接成一个更宽的、大小为E×3E的联合矩阵Wconcat。
然后,他们对这个拼接后的超级矩阵进行一次统一的奇异值分解(Singular Value Decomposition, SVD)。
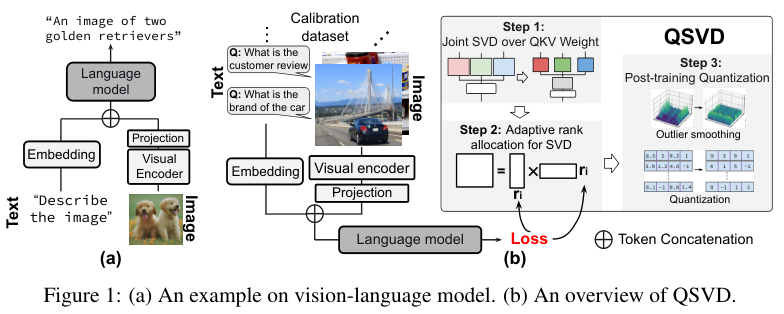
SVD是一种经典的矩阵分解技术,可以理解为一种精密的数据压缩手术。
它能将一个复杂的矩阵,分解为几个更简单、更小的矩阵相乘的形式,并自动找出原矩阵中最重要的特征信息,用一个对角矩阵中的奇异值来表示其重要性,数值越大的奇异值越重要。
通过保留那些最重要的奇异值,就可以用几个小得多的矩阵来近似模拟原来的大矩阵,从而实现压缩。
QSVD的这一步操作,带来了立竿见影的好处。
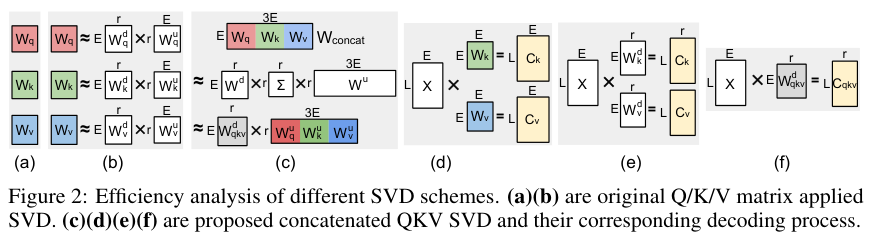
在原始模型中(a, d),输入数据X需要分别和WQ、WK、WV做三次矩阵乘法,计算成本高。同时,生成的KV缓存直接存储完整的K和V向量,内存占用大。
如果像之前的方法那样,分别对WQ、WK、WV做SVD(图b, e),虽然也能压缩权重,但在计算时,输入X还是要分别和两个不同的下投影矩阵相乘,生成两个中间结果Ck和Cv并缓存起来。
而QSVD的方法(图c, f)则优雅得多。
输入X只需要和那个共享的下投影矩阵相乘一次,就能得到一个统一的中间结果。
结果在权重参数量、计算开销(浮点运算次数FLOPs)和最关键的KV缓存大小这三个方面,都实现了显著的降低。
为每个奇异值打出重要性得分
联合SVD提供了一把锋利的手术刀,但如何下刀,切除多少,才能既切除冗余,又不伤及模型的智慧,这是一个核心挑战。
这个度的把握,就是如何为模型中所有注意力层的联合矩阵,确定一个最优的截断秩(rank)。
简单粗暴地为所有层设置一个统一的秩,或者沿用过去基于费雪信息(Fisher Information)的分配方法,效果并不理想。
QSVD为此设计了一套更精细、更高效的秩分配策略。其核心思想是,直接量化每一个奇异值对模型最终准确率的贡献度。
我们知道,一个矩阵的SVD分解可以看作是多个单秩分量的加和,每个分量由一个奇异值和其对应的左右奇异向量构成。截断一个奇异值,就等于从原矩阵中移除了它所代表的那部分信息。
这个移除操作,必然会引起模型最终输出的变化,从而导致训练损失(Training Loss)的增加。QSVD的目标,就是找到那些移除后对损失函数影响最小的奇异值,将它们截断。
首先对模型所有注意力层的QKV权重进行联合SVD分解,得到所有的奇异值。
接着使用一小部分校准数据集(例如从ScienceQA中抽取256个样本),计算出每一个奇异值对应的重要性评分。
然后QSVD执行一个关键的全局排序。它不再局限于单个注意力层,而是将模型中所有层的、所有奇异值放在一起,根据它们的重要性评分进行一个总排名。
最后设定一个总的秩预算k,只保留全局排名前k的那些最重要的奇异值,无论它们来自哪一层。其余的奇异值全部被截断(设为0)。
这种全局最优的分配策略,确保了有限的秩资源被用在了刀刃上,保留了对模型性能最关键的组件,从而在最大化压缩率的同时,将精度损失降到最低。
极致压缩:为低秩模型引入可控的量化方案
经过联合SVD和智慧秩分配,VLM已经变得苗条了许多。但QSVD的目标是极致的效率,于是它引入了量化(Quantization)。
量化,就是将模型中用高精度浮点数(如FP16)表示的权重和激活值,转换为低精度的整数(如INT8甚至INT4)来存储和计算。这能大幅减少内存占用和计算延迟,因为整数运算比浮点运算快得多。
然而,量化也是一把双刃剑。这个过程必然会带来精度损失,就像把3.14159近似成3一样。特别是当数据分布中存在一些极端的大数值,即异常值(Outliers)时,量化误差会急剧放大,严重损害模型性能。
研究者们分析了LLaVA-v1.5 13B模型的内部数据,发现无论是在注意力模块还是前馈网络中,输入激活值X都存在非常严重的通道级异常值。
直接对这样的数据进行量化,后果不堪设想。
为了解决这个问题,学术界已经有了一些成熟的方法,比如通过引入一个正交矩阵H进行旋转,来平滑异常值的分布,同时保持模型的数学计算等价性。
但QSVD面对的情况更复杂,因为它的注意力架构已经被SVD改造过了。研究者们为此开发了一种与低秩SVD框架深度融合的量化方法。
最终,QSVD的量化方案,通过引入两个正交矩阵H1和H2,以及一个可学习的参数β,成功地驯服了低秩VLM中的异常值,实现了从输入、权重到中间结果的全链路低精度计算。
这使得模型在享受SVD带来的结构性优化的同时,还能获得量化带来的存储和计算双重红利,从而达到极致的硬件效率。
更低的成本,更高的精度
研究团队在LLaVA-v1.5、LLaVA-Next和SmolVLM等多个主流视觉语言模型上,对QSVD进行了全面的评估。
为了公平对比,他们将QSVD与当前顶尖的SVD方法(如ASVD, SVD-LLM)和量化方法(如QuaRot, DuQuant, QVLM)进行了同台竞技。
评价的维度非常清晰:在相似甚至更低的硬件成本(用权重/计算压缩率R1和KV缓存压缩率R2来衡量)下,谁能保持更高的模型准确率。
首先,来看一下仅使用SVD压缩(表示为QSVD-noQ)的效果。
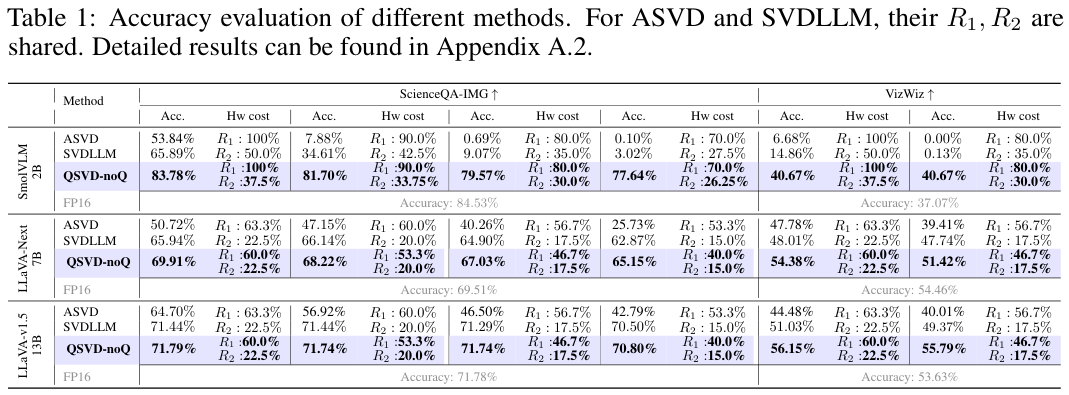
QSVD-noQ的表现堪称惊艳。在所有测试模型和数据集上,它都以最低的硬件成本,取得了超越ASVD和SVD-LLM的准确率。
在LLaVA-v1.5 13B模型上,QSVD-noQ在ScienceQA-IMG数据集上的准确率损失不到1%,几乎与未压缩的FP16模型持平。
在VizWiz数据集上,它甚至以46.7%的权重和17.5%的缓存,取得了超越原始模型2%的准确率。
这可能意味着低秩近似在某种程度上起到了正则化作用,有效地抑制了模型的幻觉(Hallucination)现象,让回答更准确。
接下来,是SVD与量化双管齐下的完整版QSVD的表演。
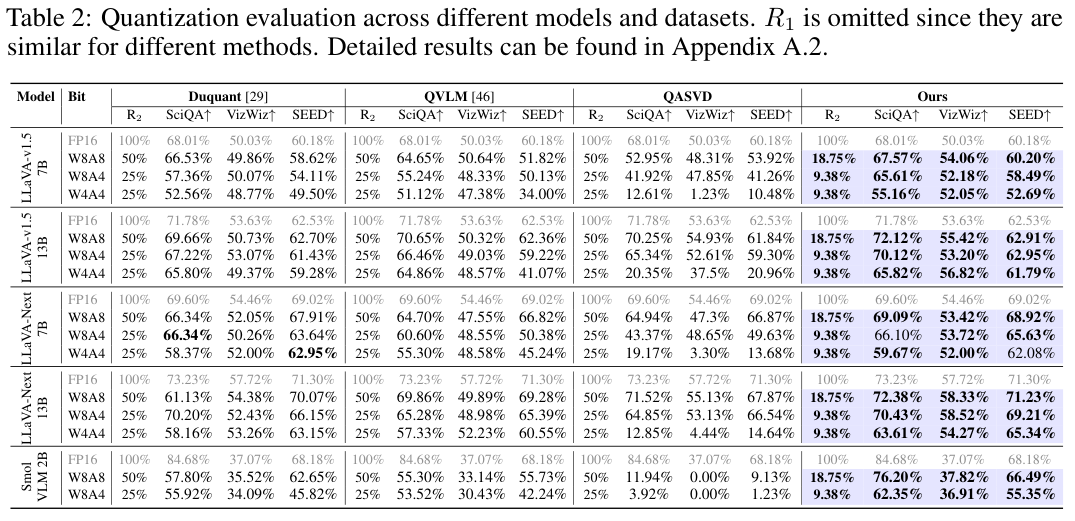
在W8A8(8位权重和8位激活)的温和量化设置下,QSVD在大多数情况下都轻松胜出。
在LLaVA-1.5 13B这样的大模型上,它几乎达到了FP16基线的精度,而此时QKV的权重和计算量已经减半,KV缓存更是只有原始大小的18.75%。
当挑战升级到W4A4的极限压缩设置时,差距被进一步拉大。
其他方法,特别是QASVD,性能急剧下降,甚至完全失效(准确率变为0)。而QSVD依然坚挺,在所有模型上都保持了最高的性能,同时硬件成本依旧是最低的。
这些数据雄辩地证明了QSVD框架的先进性,它不仅仅是SVD和量化的简单叠加,而是二者深度融合、协同优化的结晶。
最后,是延迟的实测。
研究者们在一台配备12GB显存的NVIDIA RTX 4070 GPU上测试了LLaVA-v1.5 7B模型的推理延迟,这代表了典型的消费级硬件环境。
结果令人振奋。由于显存有限,原始的FP16模型和仅经过SVD压缩的QSVD-noQ模型,都需要将一部分数据卸载到CPU内存中,导致速度缓慢。
即便如此,QSVD-noQ因为数据移动量更少,也实现了比基线最高2.1倍的加速。
而当应用了W8A8量化的完整版QSVD登场时,情况发生了质变。
由于模型和缓存被极致压缩,它完全不需要CPU卸载,所有计算都在GPU上飞速完成,最终实现了高达13.1倍的惊人加速。
这意味着,曾经需要在昂贵服务器上才能流畅运行的大型视觉AI,现在有了在普通家用电脑甚至未来在移动设备上高效部署的可能。
QSVD通过其统一的QKV权重处理、智慧的秩分配策略和与低秩框架深度绑定的量化方案,为高成本的视觉语言模型指出了一条清晰的平民化之路。
这项工作为强大AI技术的普及和应用,扫清了一大障碍。
参考资料:
https://github.com/SAI-Lab-NYU/QSVD
https://arxiv.org/abs/2510.16292
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)