当Agent学会“记笔记”:记忆管理工程如何重塑智能交互的效率
当Agent学会“记笔记”:记忆管理工程如何重塑智能交互的效率
在和AI助手频繁对话的日常里,你是否遇到过这样的场景:明明上周刚问过某家公司的销售数据,这周再问时,AI又得“从头再来”——重新调用工具、重新检索信息,仿佛完全不记得之前的交流。这种“健忘”背后,隐藏着Agent研发者们正在攻克的一个关键课题:Agent Memory Engineering。
一、记忆管理:上下文工程的“效率分支”
如果把AI的交互过程比作一场对话,那么“上下文”就是对话的背景和历史。而记忆管理工程,本质是上下文工程的一个细分领域,它聚焦的核心问题很现实:如何避免用户重复提问或智能体重复搜集信息,从而减少不必要的上下文消耗和成本支出。
想象一下,你某天想了解A公司9月份的销售情况,智能体为了回答你,调用了一堆工具——查数据库、爬行业报告、整合数据……忙得不亦乐乎。过了几个月到了年底,你想知道A公司全年的销售表现:
- 无记忆管理的传统路径:AI会像第一次遇到这个问题一样,重新推理逻辑、一步步调用工具,把“9月查询”的流程再走一遍,耗时耗力还耗资源。
- 有记忆管理的智能路径:AI会说“我已经习得了解A公司销售数据的方法”,直接调用之前沉淀的工具链和信息获取逻辑,精准拿到全年数据。
这就是记忆管理的魔力——让AI从“单次失忆”的工具,变成“持续积累”的助手。
二、从“单次交互”到“持续学习”:记忆管理的技术逻辑
如果把AI的记忆管理拆解开来,其实和人类积累经验的逻辑异曲同工,我们可以从这几个环节理解它: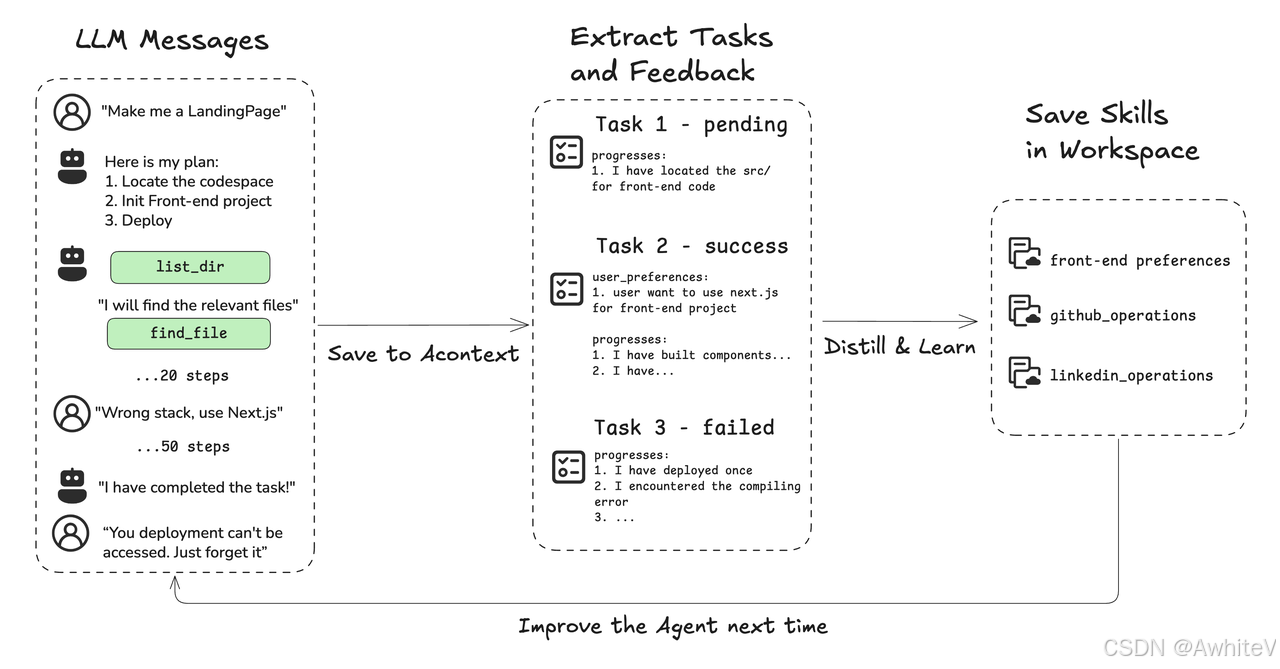
1. 「信息提取」:从对话中抓关键
就像如图提到的“LLM Messages→Extract Tasks”流程,AI需要先从海量的交互信息里,提取出可复用的“技能点”——比如“获取A公司销售数据的工具链”“用户对某类信息的偏好格式”。
2. 「记忆存储」:把技能存进“工作区”
这些提取出的技能,会被分类存储到AI的“记忆工作区”。比如像“前端偏好”“GitHub操作”一样,“A公司销售数据获取方法”也会成为其中一个“技能文件”,随时待命。
3. 「调用优化」:下次直接复用
当用户再次提出同类需求时,AI不再需要“从零开始思考”,而是直接调取记忆中的技能,跳过冗余的推理和工具调用步骤,效率直接拉满。
三、记忆管理的价值:不止于“省事儿”
对用户、对开发者、对整个AI生态,记忆管理都有着穿透性的价值:
- 对用户:告别“重复提问的无效等待”,AI越来越“懂你”,交互体验直线升级。
- 对开发者:减少不必要的上下文消耗(大模型的上下文窗口是宝贵资源),降低工具调用的费用(少调用一次工具,就少一次成本)。
- 对AI进化:记忆管理让AI真正具备“持续学习”的能力,每一次交互都在为下一次更智能的响应铺路,形成“交互-学习-迭代”的正向循环。
四、未来:当AI的记忆更“聪明”
现在的记忆管理还在“技能级复用”的阶段,但未来的想象空间更大:
- 多模态记忆:不仅记住“如何获取数据”,还能记住“用户喜欢的可视化风格”“某次对话的情感倾向”。
- 跨场景迁移:在“获取A公司销售数据”中习得的逻辑,能迁移到“分析B公司市场份额”的场景中。
- 主动记忆更新:当A公司的业务模式发生变化时,AI能主动识别并更新记忆中的“技能包”,避免用旧经验解决新问题。
AI的记忆管理,本质是在破解“智能的可持续性”难题。当AI不再是“用完即丢”的工具,而是能积累经验、持续成长的伙伴,我们和智能体的交互边界,也将被重新定义。或许不久的将来,我们评价一个AI是否“智能”,除了看它的回答质量,还要看它“记不记得”我们的过往——毕竟,真正的理解,从记忆开始。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)